- 模型權重文件:存儲訓練好的模型參數,也就是w和b,是模型推理和微調的基礎
.pt、.ckpt、.safetensors、gguf
- 配置文件:確保模型架構的一致性,使得權重文件能夠正確加載
config.json、generation_config.json
- 詞匯表文件:保證輸入輸出的一致性
tokenizer.json、tokenizer_config.json
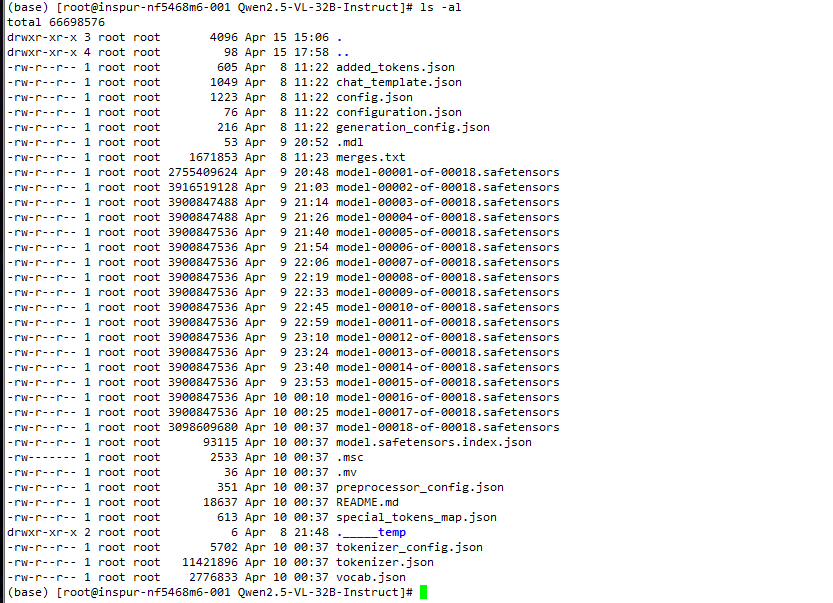
1、模型權重文件
- 模型權重文件是存儲訓練好的模型參數,是模型推理和微調的基礎 ,常見的有.pt、.ckpt、.safetensors
- 不同的框架(如TensorFlow、PyTorch)使用不同的模型文件格式
例如:
- safetensors:適配多種框架,支持transformers庫的模型加載
- PyTorch:選擇下載.pt或.bin格式的模型文件。
- TensorFlow:選擇下載.ckpt或.h5格式的模型文件。
1.1 safetensors是什么?
- .safetensors是由Hugging Face提出的一種新型的模型權重文件格式,有以下特點:
- 安全性:.safetensors采用了加密和校驗機制,防止模型文件被篡改或注入惡意代碼
- 性能:優化了數據加載和解析速度
- 跨框架支持:有多種深度學習框架的兼容性,便于在不同環境中使用
- .safetensors中,大模型可被分為多個部分,格式類似modelname-0001.safetensors、modelname-0002.safetensors
- model.safetensors.index.json是索引文件,記錄了模型的各個部分的位置和大小信息
2、配置文件
- config.json、generation_config.json
2.1 config.json
- config.json包含模型的配置信息(如模型架構、參數設置等),可能包含隱藏層的數量、每層的神經元數、注意力頭的數量等
- config.json的基本結構如下:
(base) [root@inspur-nf5468m6-001 Qwen2.5-VL-32B-Instruct]# cat config.json
{"architectures": ["Qwen2_5_VLForConditionalGeneration"],"attention_dropout": 0.0,"eos_token_id": 151645,"hidden_act": "silu","hidden_size": 5120,"image_token_id": 151655,"initializer_range": 0.02,"intermediate_size": 27648,"max_position_embeddings": 128000,"max_window_layers": 64,"model_type": "qwen2_5_vl","num_attention_heads": 40,"num_hidden_layers": 64,"num_key_value_heads": 8,"pad_token_id": 151643,"rms_norm_eps": 1e-06,"rope_scaling": {"mrope_section": [16,24,24],"rope_type": "default","type": "default"},"rope_theta": 1000000.0,"sliding_window": 32768,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.49.0","use_cache": true,"use_sliding_window": false,"video_token_id": 151656,"vision_config": {"hidden_size": 1280,"in_chans": 3,"intermediate_size": 3456,"model_type": "qwen2_5_vl","out_hidden_size": 5120,"spatial_patch_size": 14,"tokens_per_second": 2,"torch_dtype": "bfloat16"},"vision_end_token_id": 151653,"vision_start_token_id": 151652,"vision_token_id": 151654,"vocab_size": 152064
}- 例如architectures字段指定了模型的架構,hidden_act字段指定了隱藏層的激活函數,hidden_size字段指定了隱藏層的神經元數
- num_attention_heads字段指定了注意力頭的數量,max_position_embeddings字段指定了模型能處理的最大輸入長度等
2.2 generation_config.json
generation_config.json是用于生成文本的配置文件,包含了生成文本時的參數設置,如max_length、temperature、top_k等generation_config.json的基本結構如下:
(base) [root@inspur-nf5468m6-001 Qwen2.5-VL-32B-Instruct]# cat generation_config.json
{"bos_token_id": 151643,"pad_token_id": 151643,"do_sample": true,"eos_token_id": [151645,151643],"repetition_penalty": 1.05,"temperature": 0.000001,"transformers_version": "4.49.0"
}- 例如bos_token_id字段指定了開始標記的ID,eos_token_id字段指定了結束標記的ID,do_sample字段指定了是否使用采樣,temperature字段用于控制生成文本的隨機性,max_length字段指定了生成文本的最大長度,top_p字段指定了采樣的概率等
- config.json 和 generation_config.json 都可能包含 "bos_token_id"(Beginning of Sequence Token ID)和 "eos_token_id"(End of Sequence Token ID)。在config.json中,這兩個字段用于模型的加載和訓練,而在generation_config.json中,這兩個字段用于生成文本時的參數設置
- config.json 提供模型的基本信息,而 generation_config.json 則細化為生成任務的具體需求
3、詞匯表文件
詞匯表文件包含了模型使用的詞匯表或標記器信息,是自然語言處理模型理解和生成文本的基礎。
tokenizer.json、tokenizer_config.json
3.1 tokenizer.json
tokenizer.json包含了模型使用的詞匯表信息,如詞匯表的大小、特殊標記的ID等tokenizer.json的基本結構如下:
{"version": "1.0","truncation": {"max_length": 128,"strategy": "longest_first"},"padding": {"side": "right","pad_id": 0,"pad_token": "[PAD]"},"added_tokens": [{"id": 128010,"content": "[CUSTOM]"}],"normalizer": {"type": "NFD","lowercase": true,"strip_accents": true},"pre_tokenizer": {"type": "ByteLevel","add_prefix_space": true},"post_processor": {"type": "AddSpecialTokens","special_tokens": {"cls_token": "[CLS]","sep_token": "[SEP]"}},"decoder": {"type": "ByteLevel"},"model": {"type": "BPE",...}
}
- 其中truncation是定義截斷策略,用于限制輸入序列的最大長度,padding用于統一輸入序列的長度,added_tokens列出分詞器額外添加到詞匯表中的特殊標記或自定義標記
- normalizer用于定義文本標準化的步驟和規則,用于在分詞前對輸入文本進行預處理,pre_tokenizer定義分詞器如何將輸入文本分割為初步的tokens,post_processor定義分詞后處理的步驟
- decoder定義如何將tokens ID 序列解碼回原始文本,model定義了分詞器的模型信息,如詞匯表、合并規則(對于 BPE)等
3.2 tokenizer_config.json
tokenizer_config.json是用于生成文本的配置文件,包含了生成文本時的參數設置,如max_length、temperature、top_k等tokenizer_config.json的基本結構如下:
{"added_tokens_decoder": [],"bos_token": "begin_of_text |>","clean_up_tokenization_spaces": true,"eos_token": "<|end_of_text|>","model_input_names": ["input_ids", "attention_mask"],"model_max_length": 1000000,"tokenizer_class": "PreTrainedTokenizerFast"
}
- 其中added_tokens_decoder定義分詞器在解碼(將 token ID 轉換回文本)過程中需要額外處理的特殊標記或自定義標記
- bos_token、eos_token定義開始、結束標記,clean_up_tokenization_spaces定義了是否清除分詞后的多余空格等
- tokenizer.json和tokenizer_config.json的區別:tokenizer.json側重于分詞器的訓練和加載,而tokenizer_config.json更側重于生成文本時的參數設置
為什么很多模型都沒有 vocab.txt 了?現代分詞器采用了更為豐富和靈活的文件格式,如 tokenizer.json,以支持更復雜的分詞策略和特殊標記處理
一、背景介紹
在AI模型部署領域,模型格式的選擇直接影響推理效率、內存占用和跨平臺兼容性。Safetensors和GGUF作為兩種重要格式,分別服務于不同的應用場景:
- Safetensors
- 基于protobuf的二進制格式,提供安全的張量存儲
- 支持分片(sharding)和加密功能
- 廣泛用Hugging Face生態系統
- 典型應用:模型微調、分布式訓練
- GGUF
- 基于GGML生態的新型格式(GGML v2)
- 針對CPU推理優化的內存布局
- 支持多種量化模式(4/5/8bit)
- 典型應用:邊緣設備部署、低資源環境
本文將詳細講解如何通過Transformers框架將Safetensors模型轉換為GGUF格式,并深入探討轉換過程中的關鍵技術細節。
二、轉換原理與核心流程
2.1 格式轉換的本質
Safetensors到GGUF的轉換本質是: 1. 張量數據的序列化格式轉換 2. 內存布局的優化重組 3. 可選的量化參數調整
2.2 核心轉換流程
graph TDA[Safetensors模型] --> B[加載模型權重]B --> C[轉換為PyTorch張量]C --> D[執行量化操作]D --> E[生成GGUF格式文件]E --> F[驗證輸出文件]三、環境準備
3.1 依賴安裝
# 安裝Transformers庫
pip install transformers# 安裝GGUF工具鏈
pip install llama-cpp-python3.2 硬件要求
- CPU:Intel/AMD x86-64架構(推薦支持AVX2指令集)
- 內存:至少為模型未量化狀態的2倍
- 存儲:SSD推薦(處理大模型時提升速度)
公司環境 .
四、轉換步驟詳解
4.1 加載Safetensors模型
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "Qwen/Qwen2.5-VL-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="gpu")
tokenizer = AutoTokenizer.from_pretrained(model_name)4.2 初始化GGUF轉換器
from llama_cpp import GGUFConverterconverter = GGUFConverter(model=model,tokenizer=tokenizer,max_seq_len=2048,target_format="ggufv2"
)4.3 執行轉換操作
output_path = "Qwen2.5-VL-32B-Instruct.gguf"
converter.convert(output_path=output_path,quantization="q4_0", # 可選量化模式force=True # 覆蓋已有文件
)4.4 驗證轉換結果
from llama_cpp import Llamallm = Llama(model_path=output_path,n_ctx=2048,n_threads=8
)prompt = "你好,我是jettech"
output = llm(prompt, max_tokens=512)
print(output["choices"][0]["text"])五、高級配置選項
5.1 量化參數設置
| 參數名稱 | 說明 | 推薦值 |
|---|---|---|
| quantization | 量化模式 | "q4_0" |
| group_size | 量化分組大小(影響精度) | 128 |
| use_mmap | 使用內存映射加速加載 | True |
5.2 內存優化策略
# 啟用內存優化模式
converter = GGUFConverter(...,memory_friendly=True,temp_dir="/tmp/gguf_conversion"
)六、常見問題與解決方案
6.1 轉換失敗處理
- 錯誤信息:
Invalid tensor shape
解決方案:檢查模型架構是否兼容(需為CausalLM類型) - 錯誤信息:
Out of memory
解決方案:分塊處理模型(使用chunk_size參數)
七、格式對比與應用場景
7.1 關鍵指標對比
| 指標 | Safetensors | GGUF |
|---|---|---|
| 典型文件大小 | 原始浮點數 | 量化后1/4-1/8 |
| 加載速度 | 較慢(需反序列化) | 極快(內存映射) |
| 推理速度 | CPU/GPU優化 | CPU極致優化 |
| 跨平臺支持 | 全平臺 | x86/ARM |
7.2 適用場景推薦
- Safetensors:模型訓練、GPU推理、云服務部署
- GGUF:邊緣設備、低功耗CPU、嵌入式系統
八、未來發展趨勢
- 多模態支持:GGUF計劃支持圖像/音頻模型
- 動態量化:運行時自適應量化技術
- 生態整合:Hugging Face官方可能提供直接轉換工具

Swift安裝)






)



)





-HTTP請求數據)
