目錄
- 2025年泰迪杯數據挖掘挑戰賽A題
- 完整論文:建模與求解Python代碼
- 1問題一的思路與求解
- 1.1 問題一的思路
- 1.1.1對統計數據進行必要說明:
- 1.1.2統計流程:
- 1.1.3特殊情況的考慮:
- 1.2 問題一的求解
- 1.2.1代碼實現
- 1.2.2 問題一結果
- 代碼分享
- 2 問題二的思路與求解
- 2.1 問題二的思路
- 2.1.1檢測方法的設計:
- 2.1.2統計流程:
- 2.1.3特殊情況的考慮:
- 2.1.4 問題二模型的建立
- 1. 單棵決策樹的構建(CART算法)
- 2. 隨機森林集成
- 3. 特征重要性計算
- 4. 概率輸出(Soft Voting)
- 5. 模型決策規則
- 2.2 問題二的求解
- 2.2.1特征工程
- 2.2.2代碼實現
2025年泰迪杯數據挖掘挑戰賽A題
完整論文:建模與求解Python代碼

1問題一的思路與求解
1.1 問題一的思路
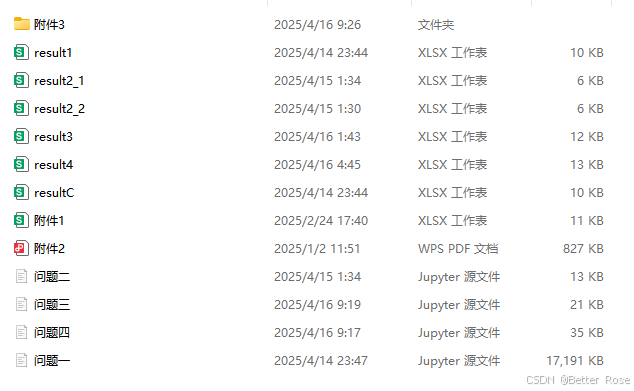
首先,題目要求對競賽論文的基本信息進行統計,保存到result1.xlsx中。附件1提供了參賽隊伍的信息,其中加密號對應附件3的文件名。
根據附件4中的result1.xlsx模板,需要統計的列包括論文標題、總頁數、總字數、摘要頁數和字數、目錄頁數、正文頁數和字數,還有圖片數、表格數、獨立公式數、參考文獻數量等。此外,還包括一些比例,比如圖片所占比例,以及平均句子數和平均字數等。
1.1.1對統計數據進行必要說明:
- 總頁數:PDF文件的總頁數,使用PyPDF2或pdfplumber獲取。
- 總字數:提取所有文本后統計字符數(包括空格和標點)。
- 摘要頁數與字數:定位包含“摘要”或“Abstract”的頁面,統計其頁數和字數。
- 目錄頁數:定位“目錄”或“Contents”部分,統計其頁數。
- 正文頁數與字數:正文起始頁為目錄結束頁+1,結束于參考文獻起始頁-1,統計頁數和字數。
- 正文圖片數:統計正文中所有Image對象的數量。
- 正文圖片所占比例:正文圖片數 / 總圖片數。
- 正文表格數:使用pdfplumber提取表格數量。
- 正文獨立公式數:正則表達式匹配LaTeX公式塊(如[…])。
- 正文段落平均句子數與字數:使用句號、問號、感嘆號分句,計算句子數和平均字數。
- 參考文獻數量:統計參考文獻部分的條目數(以[數字]開頭)。
1.1.2統計流程:
(1)讀取PDF文件:使用Python庫如PyPDF2、pdfplumber或PyMuPDF來讀取PDF內容,提取文本、圖片、表格等信息。
(2)提取元數據:獲取總頁數。
(3)分部分統計頁數和字數:
- 摘要:識別摘要部分,通常位于開頭,可能有“摘要”或“Abstract”作為標題。需要找到該部分的起始頁和結束頁,統計該部分的頁數和字數。
- 目錄:查找“目錄”或“Contents”部分,統計其頁數和字數。
- 正文:正文可能從引言開始,直到參考文獻之前。需要確定正文的起始和結束位置。
(4)統計圖片數:遍歷每一頁,檢測PDF中的圖片對象,統計總數。
(5)統計表格數:檢測PDF中的表格結構,可能需要使用pdfplumber的表格提取功能。
(6)統計獨立公式數:可能需要分析文本中的公式模式,如識別被括號包圍的公式編號,或者使用正則表達式匹配公式結構。
(7)參考文獻數量:找到參考文獻部分,統計條目數量,通常每個條目以編號或作者開頭。
(8)計算平均句子數和平均字數:以句號、問號、感嘆號作為句子分隔符,對正文文本進行分句和分詞統計。
1.1.3特殊情況的考慮:
- 摘要和目錄的靈活匹配:有些論文可能將“摘要”寫成“摘 要”或“摘 要”等變體形式,存在空格或其他格式變化。
解決方案:使用正則表達式模糊匹配,忽略空格和特殊字符。例如,匹配“摘\s要”或“目\s錄”。 - 正文范圍的優化:若參考文獻起始頁與正文最后一頁同一頁時,以參考文獻的前一頁推算正文頁數的方法可能錯誤地將部分正文頁排除。
解決方案:定位參考文獻起始段落的位置,而不是整個頁面。例如,找到“參考文獻”所在的段落起始位置,正文結束于該段落的開始位置。 - 獨立公式數的統計優化:表格中的公式可能未被檢測。
解決方案:在提取表格內容后,對表格內的文本也進行公式匹配。 - PDF為圖片型文檔的處理:對于整個頁面為圖片的PDF,無法提取文本,導致字數統計為0。
解決方案:使用OCR工具(如Tesseract)對圖片型PDF進行文本提取。 - 標題跨行:如果標題跨越多行,不進行特殊處理只會獲取到第一行,標題不完整。
解決方案:提取第一頁的所有行,合并從第一行開始,直到遇到分隔線、空行或特定關鍵詞(如“摘要”)。 - 正文頁數的判定:若論文格式不規范,當論文沒有目錄或參考文獻時,正文頁數會統計錯誤。
解決方案:修改判斷邏輯:
正文起始頁判定:①如果存在目錄,正文從目錄頁后一頁開始;②如果沒有目錄,則嘗試從摘要后的頁面開始正文;③如果連摘要也未找到,默認正文從第一頁開始(假設標題頁后即為正文)。
正文結束頁判定:①仍然以參考文獻或附錄作為結束標志;②若無參考文獻或附錄,則以總頁數為結束頁。
1.2 問題一的求解
1.2.1代碼實現
Step1:使用pandas讀取附件1.xlsx,創建字典,鍵為加密號,值為參賽隊號和其他信息,從而獲取加密號與參賽隊號的對應關系。
Step2:遍歷附件3中的PDF文件,對于每個PDF文件:
a. 使用pdfplumber打開,獲取總頁數。
b. 提取所有頁面的文本,并存儲每頁的文本和對象(圖片、表格等)。
c. 定位摘要、目錄、正文、參考文獻部分:
- 摘要:搜索頁面中的“摘要”或“Abstract”,確定其起始頁和結束頁(可能摘要僅在一頁)。
- 目錄:同樣通過關鍵詞定位。
- 正文:可能從目錄后的頁面開始,或者根據章節標題判斷。
- 參考文獻:找到“參考文獻”或“References”部分,統計條目數。
d. 統計圖片數:遍歷每頁的images屬性,統計總數。
e. 統計表格數:使用pdfplumber的extract_tables(),統計所有頁面的表格數量。
f. 獨立公式數:使用正則表達式匹配公式塊,同時結合公式編號進行考慮。
g. 參考文獻數量:統計參考文獻部分的條目數。
h. 計算總字數:所有文本的總字符數,或者分詞后的詞語數。
i. 計算平均句子數和平均字數:對正文文本進行處理。
Step3:保存結果到result1.xlsx:使用pandas將統計結果寫入Excel文件。
1.2.2 問題一結果
注意:本文檔使用示例數據求解
展示部分輸出結果:
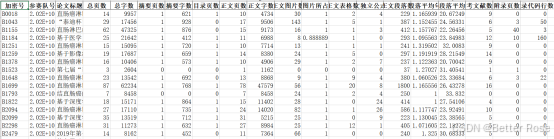
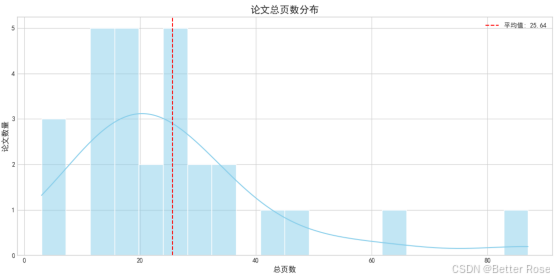
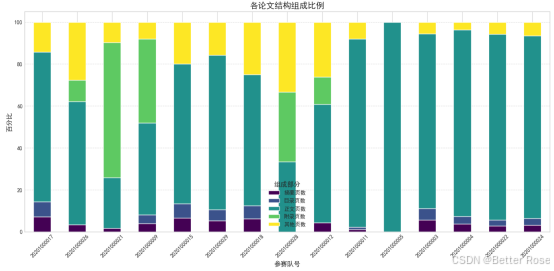
對結果可視化:給大家提供了很多種圖像參考,如果圖像繪制出來后不明白如何分析,可以將代碼和輸入數據上傳給AI,讓它給出建議。
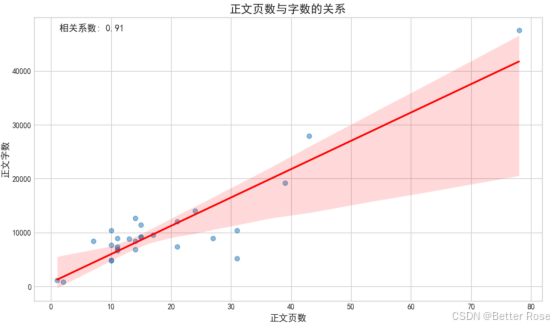
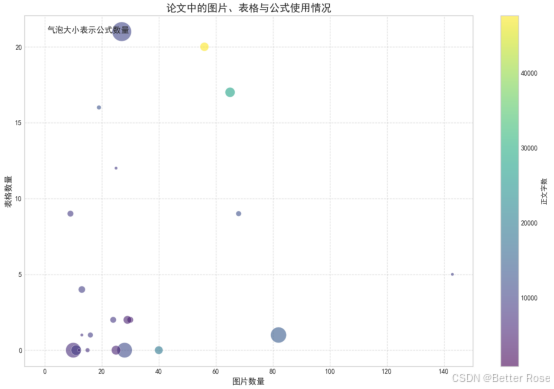
代碼分享
import os
import pandas as pd
import pdfplumber
import re
from PyPDF2 import PdfReader
from pdf2image import convert_from_path
import pytesseractdef flexible_keyword_match(text, keywords):pattern = r'[\s\u3000]*'.join(list(keywords))return re.search(pattern, text or '') is not Nonedef ocr_pdf(pdf_path):images = convert_from_path(pdf_path)full_text = []for img in images:text = pytesseract.image_to_string(img, lang='chi_sim+eng')full_text.append(text)return full_textdef extract_title(first_page_text):"""提取論文標題,更準確地區分標題與摘要等其他內容"""if not first_page_text:return '無標題'# 按行分割lines = first_page_text.split('\n')non_empty_lines = [line.strip() for line in lines if line.strip()]# 檢查是否有明確的"摘要"標記,這常常是標題與摘要的分界線abstract_index = -1for i, line in enumerate(non_empty_lines):if re.search(r'^摘\s*要$|^摘\s*[要約][\s\::]|^ABSTRACT$|^Abstract$', line):abstract_index = ibreak# 如果找到了摘要標記,則摘要標記之前的行(最多2行)可能是標題if abstract_index > 0:# 一般標題在摘要之前的1-2行potential_title_lines = non_empty_lines[max(0, abstract_index-2):abstract_index]# 過濾掉明顯不是標題的行title_lines = []for line in potential_title_lines:# 過濾掉包含特定關鍵詞的行,如學院、作者等if not re.search(r'(學院|大學|指導老師|作者|姓名|學號|導師|系|專業|年級|班級)', line):title_lines.append(line)if title_lines:# 取最長的一行作為標題,或者合并多行if len(title_lines) == 1 or len(title_lines[0]) > 15: # 如果只有一行或第一行夠長return title_lines[0]else:return ' '.join(title_lines) # 合并多行標題# 如果沒有找到摘要標記,或者摘要標記之前沒有合適的標題行# 嘗試查找文檔最開始的幾行中可能的標題# 1. 論文標題通常是文檔開頭的1-3行中最長的那一行(長度適中,不會太短也不會太長)potential_titles = []for i, line in enumerate(non_empty_lines[:5]): # 只考慮前5行line_length = len(line)if 4 < line_length < 50 and not re.search(r'(摘要|abstract|關鍵詞|keywords|目錄|contents)', line.lower()):# 根據行長度和位置計算可能性得分 - 通常標題比較靠前且長度適中score = (5-i) + min(line_length, 30)/10 # 位置越靠前分數越高,長度適中加分potential_titles.append((line, score))# 按得分排序potential_titles.sort(key=lambda x: x[1], reverse=True)if potential_titles:return potential_titles[0][0] # 返回得分最高的行# 2. 如果上述方法失敗,嘗試更簡單的方法:取文檔第一個非空行if non_empty_lines:first_line = non_empty_lines[0]# 確保第一行不是太長,如果太長可能是段落而非標題if len(first_line) < 100:return first_linereturn first_line[:50] + "..." # 截斷過長的行# 3. 實在找不到合適的標題return "無標題"def count_code_lines(text):"""計算代碼行數"""total_lines = 0# 查找代碼塊code_blocks = re.findall(r'```.*?```', text, re.DOTALL)for block in code_blocks:lines = block.split('\n')# 減去代碼塊標記total_lines += max(0, len(lines) - 2)# 查找附錄中的代碼行 - 搜索常見的代碼模式code_patterns = [r'^\s*function\s+\w+', # 函數定義r'^\s*def\s+\w+', # Python函數定義r'^\s*for\s+\w+\s*=', # for循環r'^\s*if\s+', # if語句r'^\s*else', # else語句r'^\s*while\s+', # while循環r'^\s*switch\s+', # switch語句r'^\s*case\s+', # case語句r'^\s*try\s*{', # try塊r'^\s*catch\s*{', # catch塊r'^\s*import\s+', # import語句r'^\s*#include', # include語句r'^\s*return\s+', # return語句r'^\s*\w+\s*=\s*\w+\(', # 函數調用賦值r'^\s*\w+\s*\+=|\-=|\*=|/=', # 運算賦值r'^\s*\w+\s*\+\+|\-\-', # 自增自減r'^\s*//|^\s*#|^\s*%', # 注釋行r'^\s*\w+\s*:\s*$', # 標簽行r'^\s*\w+\s*\[.+\]\s*=', # 數組賦值]# 檢查文本行lines = text.split('\n')for line in lines:line = line.strip()# 如果行不在已識別的代碼塊中,檢查是否匹配代碼模式if any(re.match(pattern, line) for pattern in code_patterns):total_lines += 1return total_linesdef detect_formulas(text):"""識別文本中的獨立數學公式"""formula_count = 0# 查找標準公式模式 (LaTeX風格的公式)latex_formulas = re.findall(r'\$\$.*?\$\$|\\\[.*?\\\]', text, re.DOTALL)formula_count += len(latex_formulas)# 按行分析文本lines = text.split('\n')i = 0while i < len(lines):line = lines[i].strip()# 跳過空行或太短的行if not line or len(line) < 3:i += 1continue# 跳過標題、章節號等if re.match(r'^[【(\[【\d\.]|^參考文獻|^附錄|^表\s|^圖\s', line):i += 1continue# 檢查是否是獨立公式行(前后都是空行或段落分隔)is_isolated_line = Falseif i > 0 and i < len(lines) - 1:prev_line = lines[i-1].strip()next_line = lines[i+1].strip()is_isolated_line = (not prev_line or prev_line.endswith('.')) and (not next_line or re.match(r'^[A-Z\u4e00-\u9fff]', next_line))# 獨立公式行的特征檢查if is_isolated_line:# 1. 包含典型數學符號has_math_symbols = bool(re.search(r'[+\-*/=()[\]{}∫∑∏??]|?|?', line))# 2. 包含典型公式結構(如變量和運算符的組合)has_formula_structure = bool(re.search(r'[a-zA-Z][\s]*[+\-*/=><]', line))# 3. 有公式編號或居中對齊has_formula_numbering = bool(re.search(r'\(\d+\)$|\[\d+\]$', line))# 4. 行只包含公式相關內容(不含普通文本的整句)is_formula_only = not re.search(r'[。,;:?!""()]', line) and len(line.split()) <= 5# 公式需滿足的條件組合if has_math_symbols and has_formula_structure and (has_formula_numbering or is_formula_only):formula_count += 1i += 1continue# 檢查連續的多行公式(當前行和下一行都有數學符號且沒有普通句子標點)if i < len(lines) - 1:next_line = lines[i+1].strip()if (re.search(r'[+\-*/=()[\]{}]', line) and re.search(r'[+\-*/=()[\]{}]', next_line) and not re.search(r'[。,;:?!""()]', line) andnot re.search(r'[。,;:?!""()]', next_line)):# 確認是否為延續性公式(一般公式比普通文本短,且兩行都沒有完整句)if len(line) < 60 and len(next_line) < 60 and not line.endswith('。'):formula_count += 1i += 2 # 跳過下一行,因為它是公式的一部分continuei += 1return formula_countdef detect_appendix_pages(full_text):"""識別附錄頁面并計算附錄頁數"""appendix_start = None# 查找附錄開始的頁碼for i, text in enumerate(full_text):if re.search(r'^附錄\s*$|^附錄[::\s]|^\d+[\s\.、]*附錄', text.strip()) or re.search(r'附\s*錄', text[:20]):appendix_start = ibreak# 如果找不到明確的"附錄"標題,嘗試查找"參考文獻"之后的內容if appendix_start is None:ref_end = Nonefor i, text in enumerate(full_text):if re.search(r'^參考文獻\s*$|^參考文獻[::\s]|^\d+[\s\.、]*參考文獻', text.strip()):ref_end = i# 在參考文獻之后查找可能是附錄的內容for j in range(ref_end + 1, len(full_text)):if re.search(r'附錄\s*\d+|^附\s*\d+|程序代碼|附\s*代碼|附表|附圖|附\s*[A-Za-z]', full_text[j]):appendix_start = jbreakbreak# 如果仍然找不到附錄,查找最后一個"參考文獻"之后的所有內容if appendix_start is None:for i in reversed(range(len(full_text))):if re.search(r'^參考文獻\s*$|^參考文獻[::\s]|^\d+[\s\.、]*參考文獻', full_text[i].strip()):# 確保參考文獻不是最后一頁if i + 1 < len(full_text):appendix_start = i + 1break# 如果找到了附錄開始頁if appendix_start is not None and appendix_start < len(full_text):appendix_pages = len(full_text) - appendix_start# 檢查是否是真正的附錄內容appendix_content = ' '.join(full_text[appendix_start:])has_appendix_content = (re.search(r'附錄\s*\d+|附\s*\d+|附表|附圖|程序代碼|代碼清單|function|def\s+\w+|import\s+|#include|void\s+\w+\s*\(', appendix_content) orlen(re.findall(r'\b(for|if|while|return|print|int|float|char|string)\b', appendix_content)) > 3)if has_appendix_content:return appendix_pages, appendix_start# 默認情況下返回0(沒有找到附錄)和None(沒有找到附錄開始頁)return 0, Nonedef count_references(text):"""統計參考文獻數量,考慮多種常見引用格式"""# 定義可能的參考文獻格式模式patterns = [r'[\[\(]\d+[\]\)]', # 匹配[1]、(1)等標準格式r'【\d+】', # 匹配【1】等中文方括號格式r'^\s*\[\d+\]', # 匹配行首的[1]等(適用于參考文獻列表)r'^\s*【\d+】', # 匹配行首的【1】等r'^\s*\(\d+\)', # 匹配行首的(1)等r'^\s*\d+\.\s' # 匹配行首的"1. "等格式]# 將參考文獻文本分割成行,便于處理行首模式lines = text.split('\n')# 對于行首模式(最后三種模式),直接在行中計數line_count = 0for line in lines:if (re.match(r'^\s*\[\d+\]', line) or re.match(r'^\s*【\d+】', line) or re.match(r'^\s*\(\d+\)', line) or re.match(r'^\s*\d+\.\s', line)):if re.search(r'[A-Za-z\u4e00-\u9fff]', line): # 確保有實際內容line_count += 1# 如果通過行首模式找到了參考文獻,直接返回if line_count > 0:return line_count# 否則使用第一種和第二種模式進行全文搜索# 注意:這種方法可能會過度計數,因為正文中也可能有[1]這樣的引用pattern_count = len(re.findall(r'[\[\(]\d+[\]\)]', text)) + len(re.findall(r'【\d+】', text))# 還可以嘗試查找格式化的參考文獻格式,如"[1] 作者名"formatted_count = len(re.findall(r'([\[\(]\d+[\]\)]|【\d+】)\s+[A-Za-z\u4e00-\u9fff]', text))# 根據實際情況返回更合理的計數if formatted_count > 0:return formatted_countreturn pattern_count# 讀取參賽隊信息
df_teams = pd.read_excel('附件1.xlsx', sheet_name='Sheet1')
team_mapping = df_teams.set_index('加密號')['參賽隊號'].to_dict()results = []
pdf_folder = '附件3/'for filename in os.listdir(pdf_folder):if not filename.endswith('.pdf'):continueencryption_code = filename.split('.')[0]team_number = team_mapping.get(encryption_code, '未知')pdf_path = os.path.join(pdf_folder, filename)with pdfplumber.open(pdf_path) as pdf:# OCR處理判斷first_page_text = pdf.pages[0].extract_text()if not first_page_text:full_text = ocr_pdf(pdf_path)else:full_text = [page.extract_text() or '' for page in pdf.pages]total_pages = len(pdf.pages)total_words = sum(len(text) for text in full_text)# 摘要統計abstract_pages, abstract_words = 0, 0for i, text in enumerate(full_text):if flexible_keyword_match(text, '摘要') or flexible_keyword_match(text, 'Abstract'):abstract_pages += 1abstract_words += len(text)break # 假設摘要只占一頁# 目錄統計toc_pages, toc_words = 0, 0for i, text in enumerate(full_text):if flexible_keyword_match(text, '目錄') or flexible_keyword_match(text, 'Contents'):toc_pages += 1toc_words += len(text)break# 修改正文起始頁的判定邏輯body_start = None# 情況1:存在目錄for i, text in enumerate(full_text):if flexible_keyword_match(text, '目錄') or flexible_keyword_match(text, 'Contents'):body_start = i + 1break# 情況2:沒有目錄,但存在摘要if body_start is None:for i, text in enumerate(full_text):if flexible_keyword_match(text, '摘要') or flexible_keyword_match(text, 'Abstract'):# 假設摘要可能跨多頁,正文從摘要最后一頁的下一頁開始abstract_end = ibody_start = abstract_end + 1break# 情況3:既無目錄也無摘要,默認正文從第一頁開始if body_start is None:body_start = 0 # 或根據實際情況跳過標題頁(如 body_start = 1)# 查找參考文獻部分ref_start_page = Nonefor i, text in enumerate(full_text):if (re.search(r'^參考文獻\s*$|^參考文獻[::\s]|^\d+[\s\.、]*參考文獻', text.strip()) or re.search(r'^References\s*$|^REFERENCES\s*$', text.strip())):ref_start_page = ibreak# 找不到明確的"參考文獻"標題,嘗試其他方法查找if ref_start_page is None:# 搜索包含參考文獻的行for i, text in enumerate(full_text):if re.search(r'參\s*考\s*文\s*獻', text[:50]): # 只在頁面開頭部分查找ref_start_page = ibreak# 從參考文獻開始到結束的所有頁面中提取文本ref_count = 0if ref_start_page is not None:# 獲取參考文獻部分至文檔結束的文本ref_text = '\n'.join(full_text[ref_start_page:])# 嘗試限定參考文獻部分(避免計算后續章節)next_section_match = re.search(r'\n(附錄|appendix|附\s*錄|APPENDIX)\s*\n', ref_text, re.IGNORECASE)if next_section_match:ref_text = ref_text[:next_section_match.start()]# 計算參考文獻數量ref_count = count_references(ref_text)# 如果數量不合理(例如太大),嘗試使用更嚴格的計數方法if ref_count > 50: # 假設超過50篇引用不太常見ref_text_lines = ref_text.split('\n')strict_count = 0for line in ref_text_lines:# 只計算那些看起來像參考文獻條目開頭的行if (re.match(r'^\s*\[\d+\]', line) or re.match(r'^\s*【\d+】', line) or re.match(r'^\s*\(\d+\)', line) or re.match(r'^\s*\d+\.\s', line)):if re.search(r'[A-Za-z\u4e00-\u9fff]', line): # 確保有實際內容strict_count += 1if strict_count > 0:ref_count = strict_count# 使用新的附錄檢測函數appendix_pages, appendix_start = detect_appendix_pages(full_text)# 確定正文結束頁 - 需要考慮參考文獻和附錄的位置body_end = total_pages # 默認正文結束于最后一頁# 如果找到參考文獻,正文結束于參考文獻開始頁if ref_start_page is not None and ref_start_page > body_start:body_end = ref_start_page# 如果找到附錄且附錄在正文起始頁之后,正文結束于附錄開始頁elif appendix_start is not None and appendix_start > body_start:body_end = appendix_start# 確保body_start和body_end合法,避免負數頁數if body_start is None:body_start = 0if body_end <= body_start:body_end = body_start + 1 # 至少保證有1頁正文body_pages = body_end - body_startbody_words = sum(len(full_text[i]) for i in range(body_start, body_end))# 計算附錄代碼行數appendix_code_lines = 0if appendix_start is not None:# 獲取附錄文本appendix_text = ''.join(full_text[appendix_start:])# 計算代碼行數:包括代碼塊和直接在文本中顯示的代碼行appendix_code_lines = count_code_lines(appendix_text)# 如果沒有明確的代碼塊,通過關鍵詞和縮進來識別代碼行if appendix_code_lines == 0:lines = appendix_text.split('\n')for line in lines:# 檢查是否有代碼行的特征,如function、for、if、end等關鍵詞if (re.search(r'^\s*(function|for|if|while|switch|case|else|end|return|try|catch)', line.strip()) orre.search(r'[{}();=%]', line) orre.search(r'^\s*[a-zA-Z0-9_]+\s*=', line)):appendix_code_lines += 1# 圖片統計(全文和正文)total_image_count = 0for i in range(total_pages):total_image_count += len(pdf.pages[i].images)body_image_count = 0for i in range(body_start, body_end):if i < total_pages: # 確保索引不超出范圍body_image_count += len(pdf.pages[i].images)# 計算正文圖片所占比例image_ratio = body_image_count / total_image_count if total_image_count > 0 else 0# 表格和公式統計(只統計正文)body_tables = 0body_formula_count = 0# 提取正文文本用于公式識別body_text = ''.join(full_text[body_start:body_end])body_formula_count = detect_formulas(body_text)# 統計表格數量for i in range(body_start, body_end):if i < total_pages: # 確保索引不超出范圍page = pdf.pages[i]tables = page.extract_tables()body_tables += len(tables)# 檢查表格內容中的公式for table in tables:if table:for row in table:if row:for cell in row:if cell:table_formula_count = detect_formulas(str(cell))body_formula_count += table_formula_count# 參考文獻數量ref_count = 0if ref_start_page is not None:ref_text = full_text[ref_start_page]# 查找常見的參考文獻標記格式ref_patterns = [r'\[\d+\]', # [1], [2], ...r'【\d+】', # 【1】, 【2】, ...r'\(\d+\)', # (1), (2), ...r'^\d+\.\s', # 1. , 2. , ... (每行開頭)r'^\[\d+\]\s', # [1] , [2] ... (每行開頭)r'^\d+\s[A-Z]', # 1 Author, 2 Author, ... (數字開頭的引用)]# 分行處理以便更好地識別每個文獻條目lines = ref_text.split('\n')for line in lines:line = line.strip()for pattern in ref_patterns:if re.search(pattern, line):ref_count += 1break # 找到一個匹配就跳出內層循環,避免重復計數# 如果仍未找到參考文獻,嘗試在全文本中查找if ref_count == 0 and ref_start_page < len(full_text) - 1:# 查看參考文獻頁之后的一頁或幾頁for i in range(ref_start_page, min(ref_start_page + 3, len(full_text))):additional_text = full_text[i]lines = additional_text.split('\n')for line in lines:line = line.strip()for pattern in ref_patterns:if re.search(pattern, line):ref_count += 1break# 正文段落統計body_text = ''.join(full_text[body_start:body_end]) if body_start is not None else ''# 根據換行符分割段落,每個換行符代表一個新段落paragraphs = re.split(r'\n', body_text)paragraphs = [p.strip() for p in paragraphs if p.strip()]paragraph_count = len(paragraphs)# 統計句子數和字數total_sentences = 0for para in paragraphs:sentences = re.split(r'[。!?]', para)sentences = [s.strip() for s in sentences if s.strip()]total_sentences += len(sentences)avg_sentences_per_para = total_sentences / paragraph_count if paragraph_count > 0 else 0avg_words_per_para = body_words / paragraph_count if paragraph_count > 0 else 0# 保存結果results.append({'加密號': encryption_code,'參賽隊號': team_number,'論文標題': extract_title(full_text[0]) if full_text else '無標題','總頁數': total_pages,'總字數': total_words,'摘要頁數': abstract_pages,'摘要字數': abstract_words,'目錄頁數': toc_pages,'正文頁數': body_pages,'正文字數': body_words,'正文圖片數': body_image_count,'正文圖片所占比例': image_ratio,'正文表格數': body_tables,'正文獨立公式數': body_formula_count,'正文段落數': paragraph_count,'正文段落平均句子數': avg_sentences_per_para,'正文段落平均字數': avg_words_per_para,'參考文獻數量': ref_count,'附錄頁數': appendix_pages,'附錄代碼行數': appendix_code_lines,})# 輸出到Excel
pd.DataFrame(results).to_excel('resultC.xlsx', index=False)
2 問題二的思路與求解
2.1 問題二的思路
題目要求從所有競賽論文中篩選出包含參賽隊信息的論文,判斷正文內容是否與賽題無關,以及識別無實質內容的論文。問題分解為三個子任務:
1.篩選包含參賽隊信息的論文:需要驗證論文中是否包含附件1中的參賽隊信息,比如隊號、隊員姓名等。
2.判斷正文是否與賽題無關:需要對比論文內容與附件2中的賽題描述,確認論文是否圍繞賽題展開。
3.識別無實質內容的論文:需要分析論文是否有足夠的實際內容,比如是否包含具體的方法、數據分析和結果,而不僅僅是重復題目或背景信息。
2.1.1檢測方法的設計:
針對每個子任務,需要設計相應的檢測方法:
- 包含參賽隊信息的檢測:
需要將附件1中的參賽隊信息作為關鍵詞,然后在論文中搜索這些關鍵詞。通過正則表達式匹配附件1中的參賽隊號、隊員姓名、指導教師等信息。例如,附件1中的參賽隊號格式為“20201000001”,隊員姓名可能以中文或特定編號形式出現。 - 判斷正文是否與賽題無關:
需要判斷論文內容是否涉及直腸癌、淋巴結轉移、CT影像分割等關鍵詞,使用自然語言處理技術(如TF-IDF或BERT)提取論文的關鍵詞和主題,嵌入模型計算論文與賽題的相似度。設定相似度閾值,低于閾值則判定為與賽題無關(相似度可以設定為論文中提取的關鍵詞與題目關鍵詞的相似度)。例如,B5978.pdf的內容是關于運輸車輛安全駕駛的,明顯與賽題無關。 - 識別無實質內容的論文:
(1)分析論文的結構完整性(是否包含研究方法、數據分析、結果等),檢查是否包含數學公式、圖表、算法描述等專業內容。這里可以利用問題一生成的result1.xlsx中的統計信息來增強判斷的準確性。
(2)評估內容的原創性,例如,B1523的論文內容完全復制了賽題描述,沒有自己的研究內容,因此屬于無實質內容。要識別這類論文,可能需要檢測論文中是否存在大量重復的賽題內容,或者是否有足夠的原創內容。例如,可以計算論文正文與賽題描述(附件2)的相似度,如果相似度過高,則可能無實質內容。
注意:需要區分實質性內容與模板化描述,例如目錄、參考文獻等部分可能不包含實際分析。
2.1.2統計流程:
- 判斷是否包含參賽隊信息:
(1)提取附件1中的所有參賽隊信息,包括隊號、學校名、指導教師、隊員等。
(2)對每篇論文的全文進行文本提取,并檢查是否包含這些信息中的任意一個。
(3)如果存在匹配,則標記為1,否則為0。 - 判斷是否與賽題無關:
(1)提取賽題(附件2)的關鍵詞,如直腸癌、淋巴結、CT、分割、影像特征等。
(2)對論文進行文本分析,提取關鍵詞或主題,計算與賽題關鍵詞的相似度。
(3)如果相似度低于某個閾值,則標記為1(無關),否則為0。 - 判斷是否無實質內容:
(1)分析論文的結構,如是否有摘要、方法、實驗、結果等部分。
(2)檢測論文中是否大量復制賽題內容,比如與附件2中的描述高度重復。
(3)如果論文的原創內容過少,或者大部分內容與賽題描述重復,則標記為1。
2.1.3特殊情況的考慮:
- 需要處理不同格式的參賽隊信息,例如隊號可能以不同方式書寫,隊員姓名可能存在錯別字或縮寫。
- 參賽隊信息可能分散在論文的不同位置(如頁眉、頁腳或正文),需要全面掃描整個文檔。
- 賽題描述可能包含專業術語,需要確保模型能準確識別相關主題,避免誤判。
- 賽題無關的判斷可能受論文結構影響,例如有些論文可能包含少量相關關鍵詞但整體不相關。
- 無實質內容的論文可能包含大量重復內容或模板文字,需要設計有效的特征來捕捉這些模式。
2.1.4 問題二模型的建立
1. 單棵決策樹的構建(CART算法)
2. 隨機森林集成
3. 特征重要性計算
4. 概率輸出(Soft Voting)
5. 模型決策規則
2.2 問題二的求解
2.2.1特征工程
2.2.2代碼實現
Step1:讀取附件1中的所有參賽隊信息,生成一個關鍵詞列表,然后使用PDF文本提取工具(如PyPDF2或pdfplumber)提取每篇論文的文本,進行關鍵詞匹配。
Step2:需要構建賽題的關鍵詞列表,然后計算論文中的關鍵詞頻率,或者使用文本相似度方法(如余弦相似度)來比較論文內容與賽題描述。
Step3:可能需要計算論文與賽題文本的重復比例。例如,使用文本相似度檢測,如Jaccard相似度或TF-IDF向量化后的余弦相似度。如果相似度過高,說明論文大量復制賽題內容,屬于無實質內容。此外,還可以檢查論文字數,如果正文過短,可能內容不足。
完整論文與代碼,請看下方

)





-HTTP請求數據)





帶論文文檔1萬字以上,文末可獲取,系統界面在最后面。)


——建模學習記錄)

)
