

-
作者:Congcong Wen, Yisiyuan Huang, Hao Huang ,Yanjia Huang, Shuaihang Yuan, YuHao, HuiLin and Yi Fang
-
單位:紐約大學阿布扎比分校具身人工智能與機器人實驗室,紐約大學阿布扎比分校人工智能與機器人中心,紐約大學坦登工程學院,中國科學技術大學,清華大學軟件學院
-
論文標題:Zero-Shot Object Navigation with Vision-Language Models Reasoning
-
論文鏈接:https://link.springer.com/chapter/10.1007/978-3-031-78456-9_25
-
項目主頁:https://vlt-lzson.github.io/
主要貢獻
-
提出了 Vision Language 模型與 Tree-of-thought 網絡相結合的 VLTNet,用于語言驅動的零樣本目標導航(L-ZSON)任務,該模型能夠使機器人在沒有特定訓練數據的情況下與未知物體交互。
-
創新性地將 Tree-of-Thought(ToT)推理框架應用于機器人探索過程中的導航前沿選擇,使模型具備多路徑推理過程和必要時的回溯能力,從而實現更準確的全局決策。
-
通過在 PASTURE 和 RoboTHOR 兩個基準測試中的實驗,證明了模型在處理復雜的自然語言指令作為目標指示的 L-ZSON 任務中的出色性能,特別是在涉及復雜自然語言指令的場景中。
研究背景
-
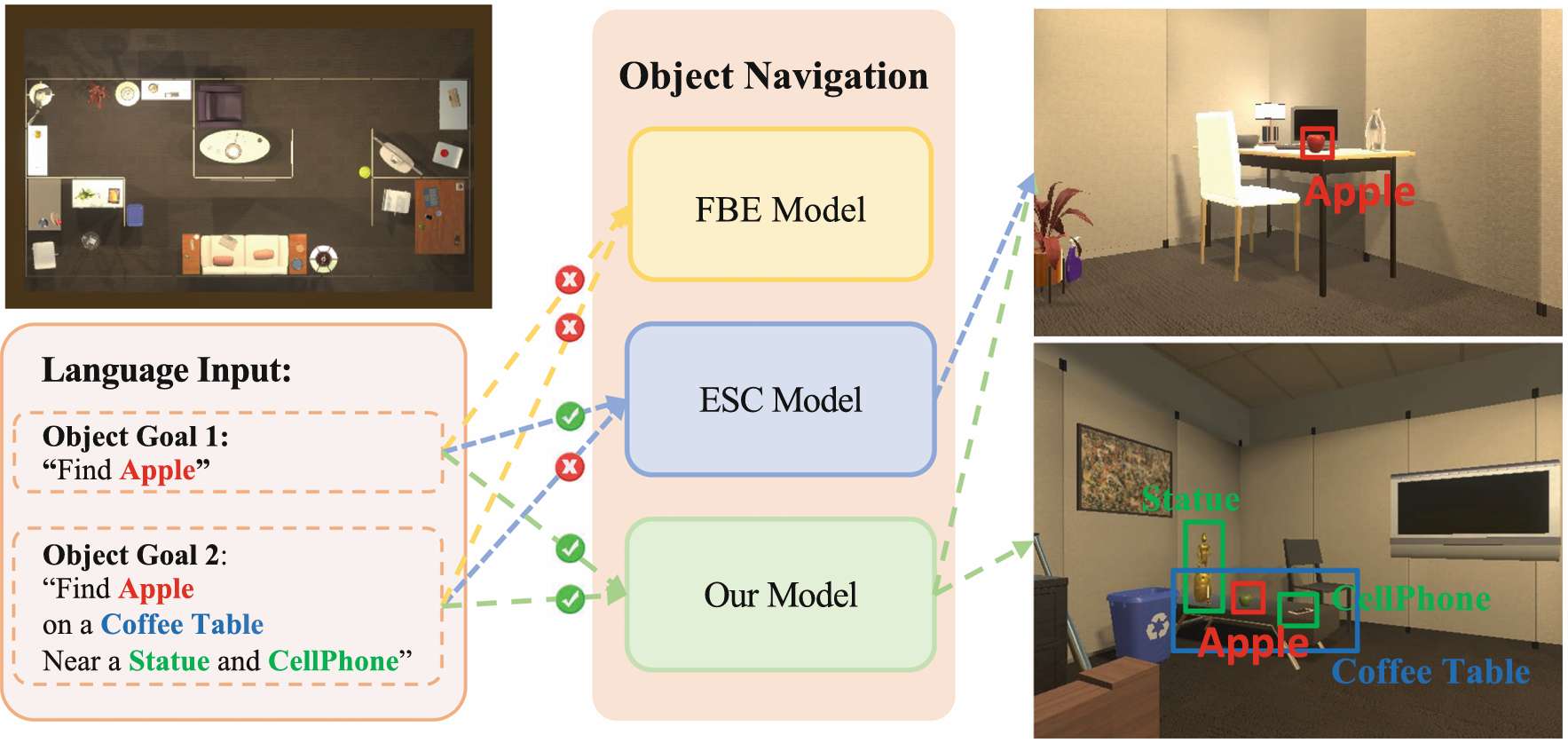
傳統的機器人目標導航方法依賴于大量的視覺訓練數據,包含環境中的標記物體,這限制了它們在未知和非結構化環境中的泛化能力。
-
零樣本目標導航(ZSON)旨在解決這一問題,讓機器人能夠與未知物體進行導航和交互,但在需要復雜交互和通信的場景中仍存在不足。
-
語言驅動的零樣本目標導航(L-ZSON)通過自然語言指令引導智能體,但現有方法只能處理明確包含物體類別的指令,難以處理描述未知物體或具有空間、視覺屬性的物體的指令。
研究方法
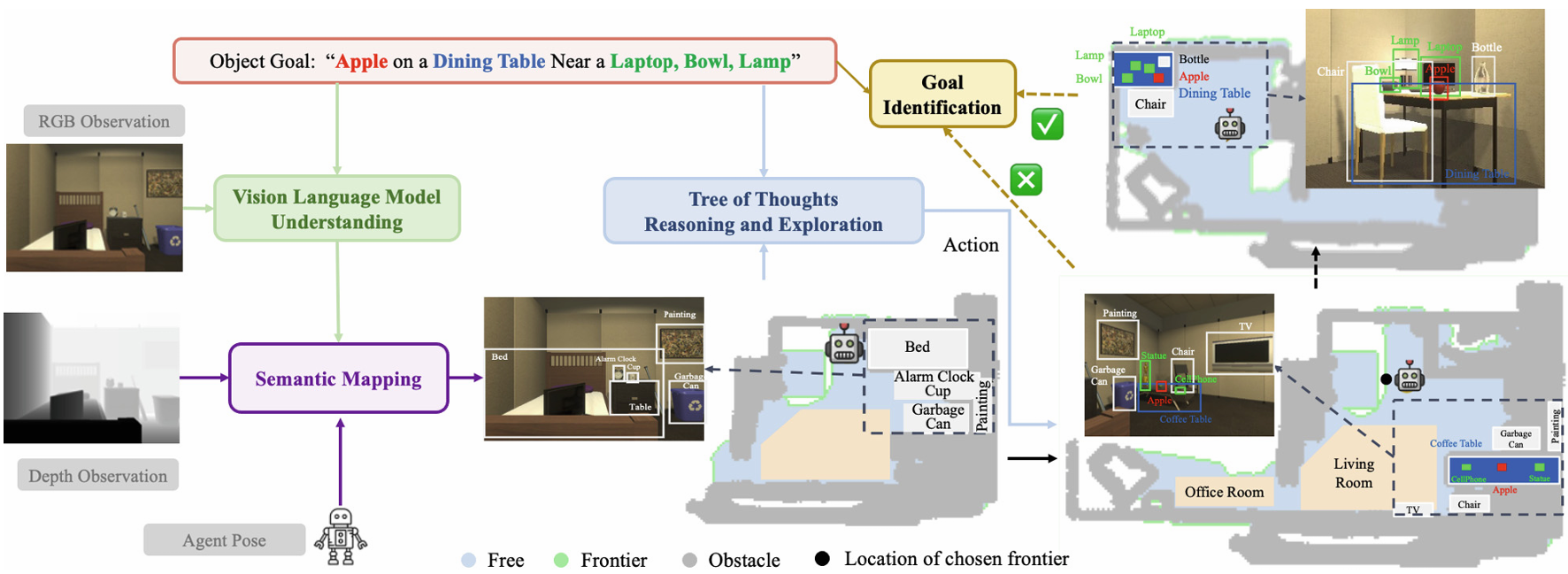
VLTNet 模型由四個核心模塊組成,包括視覺語言模型理解模塊、語義映射模塊、樹狀思維推理與探索模塊以及目標識別模塊。
-
視覺語言模型理解模塊 :利用預訓練的視覺語言模型(如 GLIP)對觀測到的 RGB 圖像進行語義解析,識別圖像中的物體和房間等信息,增強模型對環境語義的理解。
-
語義映射模塊 :結合視覺語言模型理解模塊生成的語義解析圖像、智能體捕獲的深度圖像以及智能體姿態,構建包含物體、房間和前沿的語義導航地圖,為智能體在復雜環境中的導航決策提供支持。
-
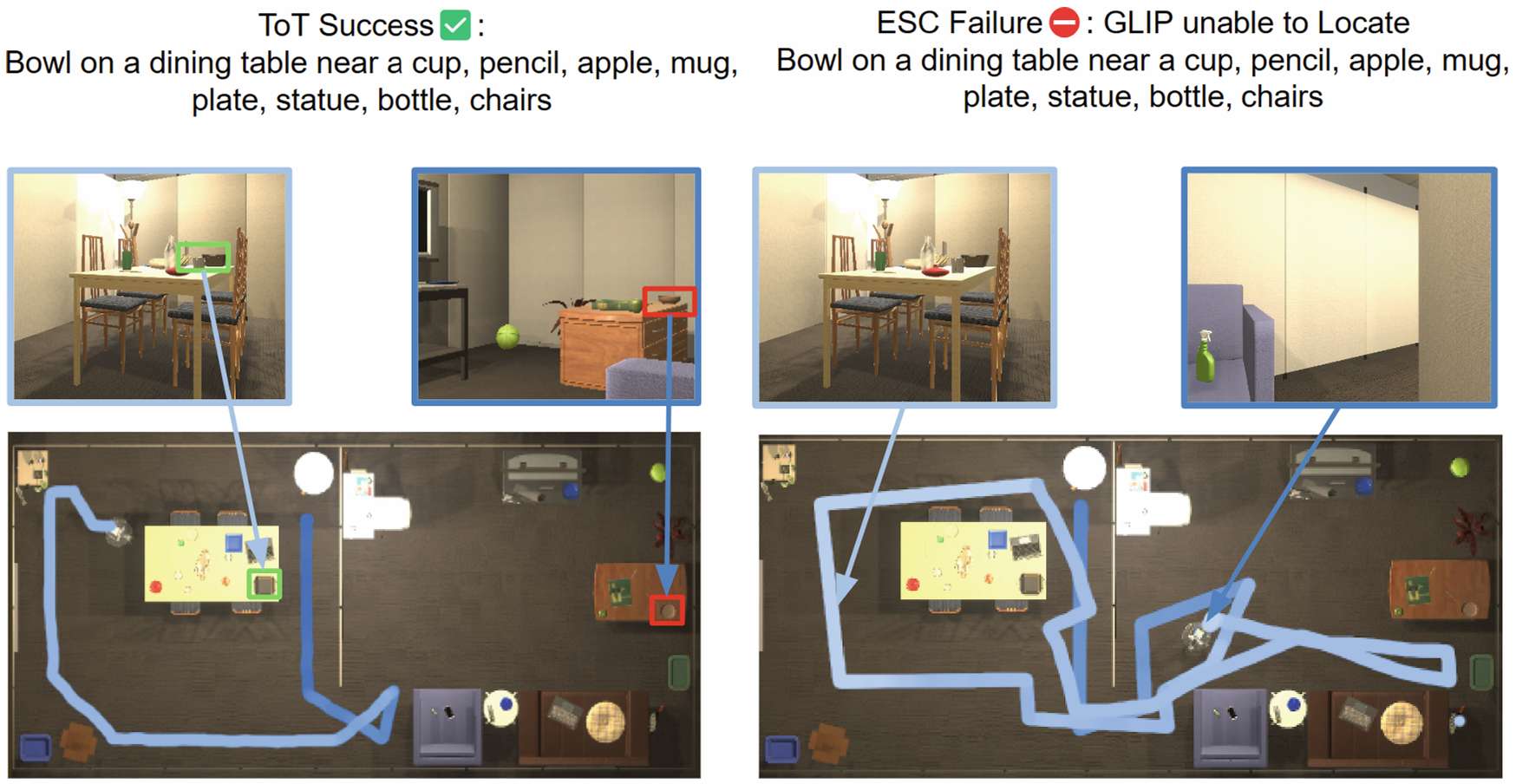
樹狀思維推理與探索模塊 :是 VLTNet 的核心組件,創新性地將 ToT 推理框架應用于導航前沿選擇。與傳統方法不同,ToT 推理框架通過模擬多個專家對問題的討論,逐步達成共識,使模型能夠進行多路徑推理和自我評估,從而選擇最優的前沿進行探索,提高導航決策的準確性和全局性。
-
目標識別模塊 :用于確定智能體當前接近的物體是否與指令中指定的目標物體匹配,不僅考慮物體類別,還結合空間和外觀描述等復雜信息,通過視覺語言模型將當前場景轉化為語言表達,再利用大型語言模型(如 GPT-3.5)進行分析,實現對場景上下文與目標描述之間一致性的準確評估。
實驗
-
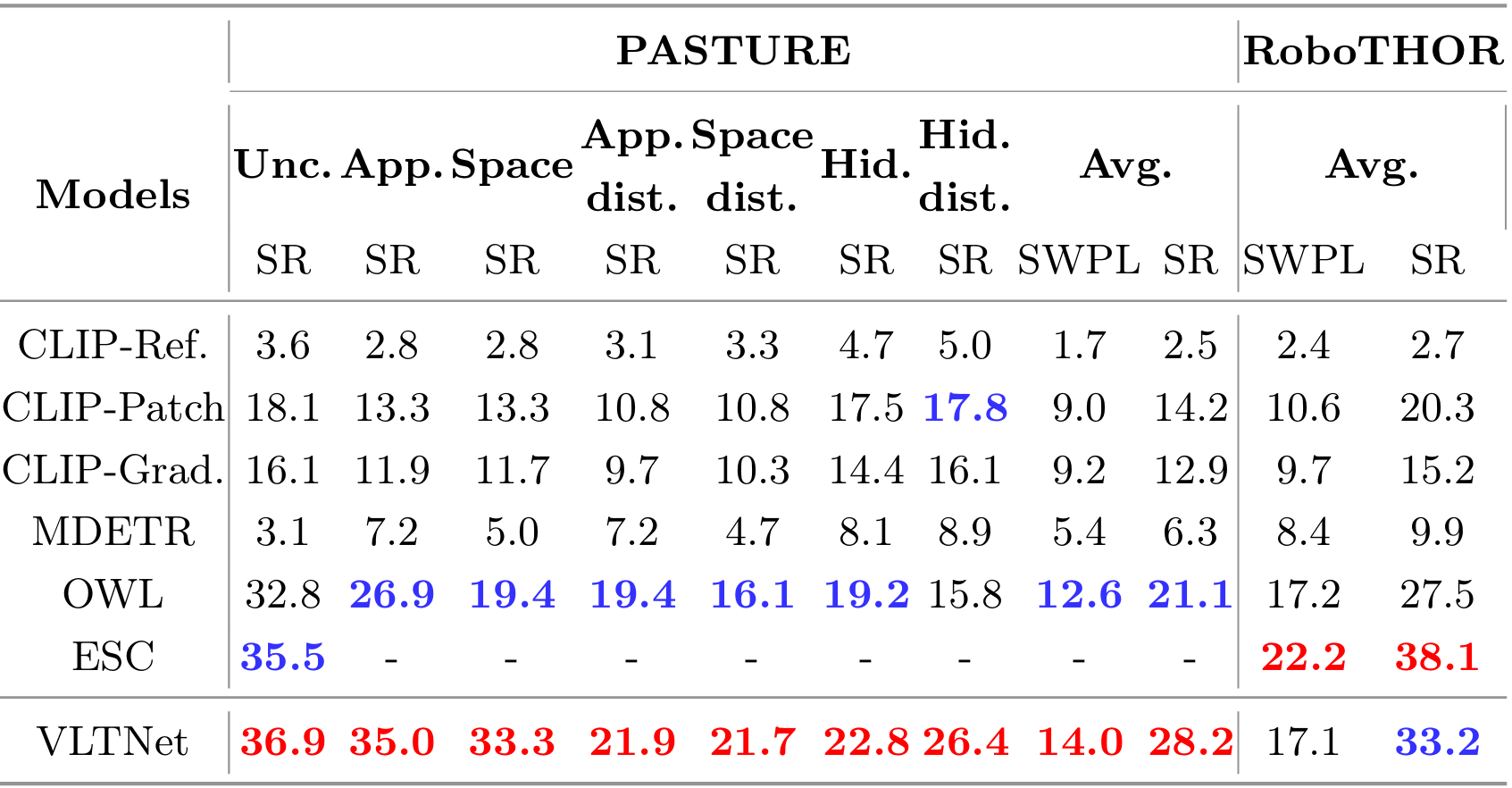
實驗環境與數據集 :在 PASTURE 和 RoboTHOR 兩個基準測試上評估 VLTNet 的性能。PASTURE 數據集包含多種獨特的導航挑戰,如不常見物體、外觀復雜的物體等;RoboTHOR 則基于真實世界室內環境,提供精確的 3D 環境表示。
-
評估指標 :采用成功率(SR)和路徑長度加權成功率(SWPL)作為評估指標,SR 衡量智能體在最大步數內成功導航到目標物體的比例,SWPL 則同時考慮導航的成功性和路徑的最優性。
-
基線模型 :與多個最先進的模型進行對比,包括 CoW 及其變體(如 CLIPRef、CLIP-Patch 等)、ESC 等。
-
實驗結果 :在 PASTURE 數據集上,VLTNet 模型在所有指標上均優于其他模型,在外觀類別中的成功率達到 35.0%,在空間類別中的成功率為 33.3%;在 RoboTHOR 數據集上,VLTNet 的成功率為 33.2%,SWPL 為 17.1%,優于 CoW 等模型。此外,消融實驗表明,使用 ToT 提示的模型在前沿選擇上優于沒有 ToT 提示的模型,證明了 ToT 推理的有效性;在目標識別模塊中,使用 GPT-3.5 的模型在驗證目標對象與空間提示的一致性方面表現最佳。
討論與未來工作
-
論文指出,盡管 VLTNet 在 L-ZSON 任務中取得了顯著的性能提升,但仍存在一些局限性,例如在處理某些復雜的自然語言指令時可能還需要進一步優化模型的推理過程和語義理解能力。
-
未來的工作可以探索如何進一步改進 ToT 推理框架,以更好地處理復雜的導航場景和更豐富的語言指令。
-
此外,還可以研究如何將 VLTNet 與其他技術(如強化學習、模擬真實世界環境的高保真仿真等)相結合,以進一步提高機器人的導航性能和泛化能力,使其能夠在更接近真實世界的環境中更有效地執行任務。





—— 49.字符異位詞分組題解)







)





)
