文章目錄
- 前言
- 1. 位置編碼(Positional Encoding)
- 2. 多頭注意力機制(Multi-Head Attention)
- 3. 前饋網絡與殘差連接(Position-Wise FFN & AddNorm)
- 3.1 基于位置的前饋網絡(PositionWiseFFN)
- 3.2 殘差連接和層規范化(AddNorm)
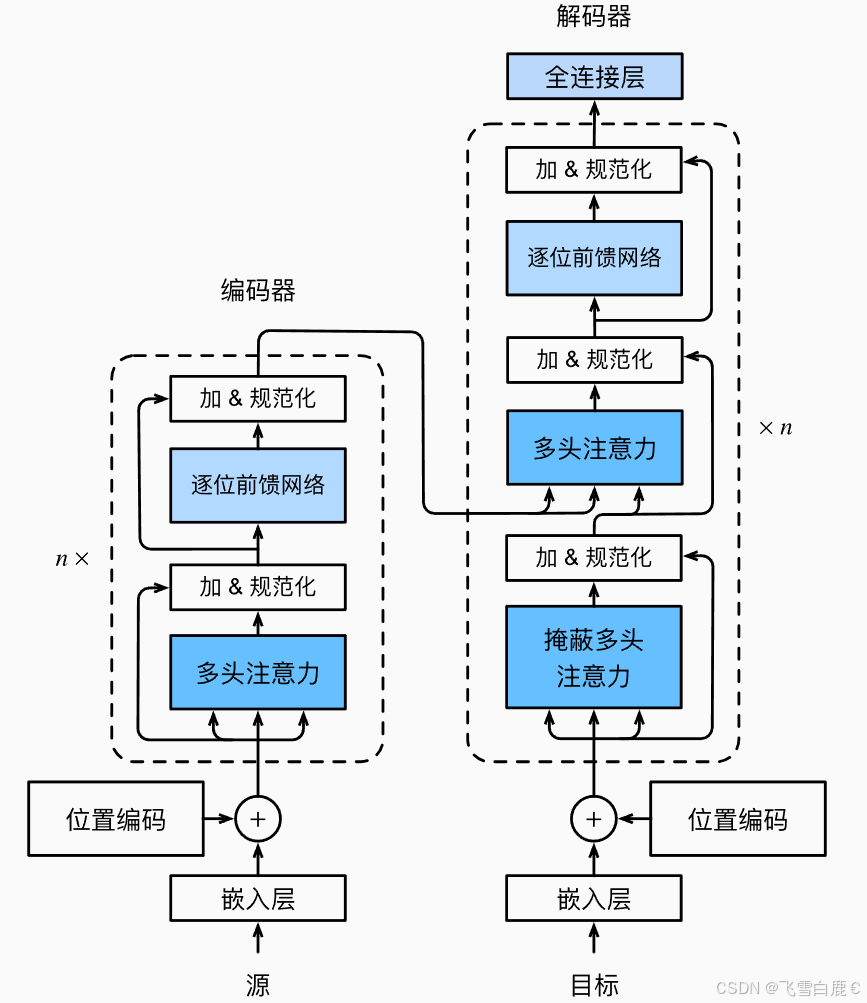
- 4. 編碼器(Encoder)
- 4.1 編碼器塊(EncoderBlock)
- 4.2 Transformer 編碼器(TransformerEncoder)
- 5. 解碼器(Decoder)
- 5.1 解碼器塊(DecoderBlock)
- 5.2 Transformer 解碼器(TransformerDecoder)
- 6. 完整 Transformer 模型
- 使用示例
- 總結
前言
Transformer 模型自 2017 年在論文《Attention is All You Need》中提出以來,徹底改變了自然語言處理(NLP)領域,并在計算機視覺等其他領域展現了強大的潛力。與傳統的 RNN 和 LSTM 相比,Transformer 通過自注意力機制(Self-Attention)實現了并行計算,極大地提高了訓練效率和模型性能。本博客將通過 PyTorch 實現的 Transformer 模型代碼,深入剖析其核心組件,包括多頭注意力機制、位置編碼、編碼器和解碼器等。我們將結合代碼和文字說明,逐步拆解 Transformer 的實現邏輯,幫助讀者從代碼層面理解這一經典模型的精髓。
本文基于提供的代碼文件(PE.py、EnDecoder.py、MHA.py 和 Transformer.ipynb),完整呈現 Transformer 的 PyTorch 實現,并通過清晰的目錄結構和代碼注釋,帶領大家從零開始學習 Transformer 的構建過程。關于訓練和可視化部分,這里忽略掉,但是你仍然可以在下面的鏈接里找到所有的源代碼,其中提供了豐富的注釋。無論你是深度學習初學者還是希望深入理解 Transformer 的開發者,這篇博客都將為你提供一個清晰的學習路徑。
完整代碼:下載鏈接
1. 位置編碼(Positional Encoding)
Transformer 的自注意力機制不包含序列的位置信息,因此需要通過位置編碼(Positional Encoding)為每個詞元添加位置信息。以下是 PE.py 中實現的位置編碼類,它通過正弦和余弦函數生成固定位置編碼。
import torch
import torch.nn as nnclass PositionalEncoding(nn.Module):"""位置編碼在Transformer中,由于自注意力機制不含位置信息,需要額外添加位置編碼在位置嵌入矩陣P中,行代表詞元在序列中的位置,列代表位置編碼的不同維度"""def __init__(self, num_hiddens, dropout, max_len=1000):"""初始化位置編碼參數:num_hiddens (int): 隱藏層維度,即位置編碼的維度dropout (float): dropout概率max_len (int, 可選): 最大序列長度,默認為1000"""super(PositionalEncoding, self).__init__()# 初始化丟棄層self.dropout = nn.Dropout(dropout)# 創建位置編碼矩陣P,形狀為(1, max_len, num_hiddens)self.P = torch.zeros((1, max_len, num_hiddens))# 計算位置編碼的正弦和余弦函數輸入# X形狀: (max_len, num_hiddens/2)X = torch.arange(max_len, dtype=torch.float32).reshape(-1, 1) / torch.pow(10000, torch.arange(0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)# 偶數維度賦值正弦,奇數維度賦值余弦self.P[:, :, 0::2] = torch.sin(X)self.P[:, :, 1::2] = torch.cos(X)def forward(self, X):"""前向傳播參數:X (torch.Tensor): 輸入張量,形狀為(batch_size, seq_len, embed_dim)返回:torch.Tensor: 添加位置編碼后的張量,形狀為(batch_size, seq_len, embed_dim)"""# 將位置編碼加到輸入X上,截取與X長度匹配的部分X = X + self.P[:, :X.shape[1], :].to(X.device)# 應用丟棄并返回結果return self.dropout(X)
代碼解析:
- 初始化:
PositionalEncoding類根據隱藏層維度(num_hiddens)和最大序列長度(max_len)生成一個位置編碼矩陣P。該矩陣的每一行表示一個位置,每一列對應一個編碼維度。 - 正弦和余弦編碼:通過正弦(
sin)和余弦(cos)函數為不同位置和維度生成編碼值,公式為:
P E ( p o s , 2 i ) = sin ? ( p o s 1000 0 2 i / d ) , P E ( p o s , 2 i + 1 ) = cos ? ( p o s 1000 0 2 i / d ) PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d}}\right), \quad PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d}}\right) PE(pos,2i)=sin(100002i/dpos?),PE(pos,2i+1)=cos(100002i/dpos?)
其中pos是位置索引,i是維度索引,d是隱藏層維度。 - 前向傳播:將輸入張量
X與位置編碼矩陣P相加,并應用 dropout 以增強模型的魯棒性。
位置編碼的作用是將序列的位置信息嵌入到詞嵌入中,使得 Transformer 能夠區分相同詞元在不同位置的語義。
2. 多頭注意力機制(Multi-Head Attention)
多頭注意力機制是 Transformer 的核心組件,允許模型并行計算多個注意力頭,從而捕獲序列中不同方面的依賴關系。以下是 MHA.py 中實現的多頭注意力機制。
import math
import torch
from torch import nn
import torch.nn.functional as Fdef sequence_mask(X, valid_len, value=0):"""在序列中屏蔽不相關的項,使超出有效長度的位置被設置為指定值"""maxlen = X.size(1)mask = torch.arange(maxlen, dtype=torch

-第十六天)





)










