在當今數字化和智能化的時代,大語言模型(LLM)的應用正以前所未有的速度改變著各個領域的工作方式和用戶體驗。Dify 作為一個開源的大語言模型應用開發平臺,為開發者們提供了便捷且強大的工具,助力構建從基礎智能體到復雜人工智能工作流程的各類大語言模型應用。其核心優勢在于集成了檢索增強(RAG)引擎,通過對海量數據的智能檢索與分析,能夠精準地為大語言模型提供相關信息,極大地提升模型輸出的準確性和相關性。 本文著重介紹如何部署Dify,并使用openGauss DataVec向量數據庫作為RAG引擎語料庫,從而搭建出高效智能的助手平臺。
Dify部署
獲取Dify源碼
要開啟Dify的部署之旅,首先需要獲取其源碼。Dify自1.1.0版本起,對openGauss提供了有力支持。因此,本文以 Dify1.1.0版本作為示例進行講解。你可以通過訪問鏈接https://github.com/langgenius/dify/archive/refs/tags/1.1.0.zip,輕松下載該版本的源碼壓縮包。
配置參數
在獲取源碼壓縮包后,需要創建特定目錄并解壓源碼。具體操作如下:
mkdir?/usr/local/difyunzip?1.1.0.zip -d /usr/local/dify/cd?/usr/local/dify/dify-1.1.0/docker
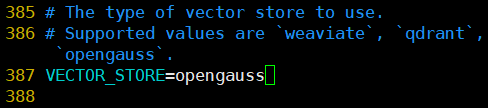
接下來的關鍵步驟是配置環境變量。在此過程中,需要修改.env文件,將VECTOR_STORE設置為opengauss。執行以下命令進行文件復制和編輯:???????
cp?.env.example .envvim .env
啟動容器
完成上述配置后,執行以下命令,系統將自動拉取對應的Docker鏡像,并啟動Dify服務:
docker-compose up -d容器啟動完畢后,為了確保各項服務均正常運行,可以執行docker ps命令。若一切順利,你將看到類似下圖所示的運行狀態:

AI服務集成
創建用戶并登陸
當Dify服務成功啟動后,在瀏覽器中訪問本地部署的Dify web服務頁面:
http://your_server_ip在該頁面,你可以創建管理員用戶。只需輸入有效的郵箱及自定義密碼即可完成創建并登錄:
接入大模型
在主界面點擊右上角用戶名,然后點擊“設置”進入設置頁面,單擊“模型供應商”,選擇“Ollama”單擊“安裝”按鈕。(ollama服務及大模型部署參考:
openGauss-RAG實踐)
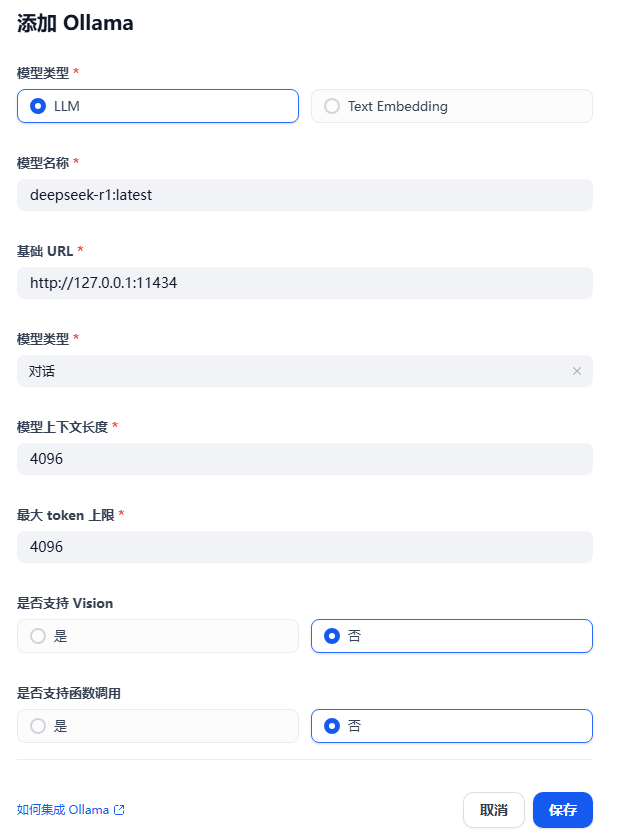
安裝完成后,在添加模型頁面,“模型類型”選擇“LLM”,配置如下:
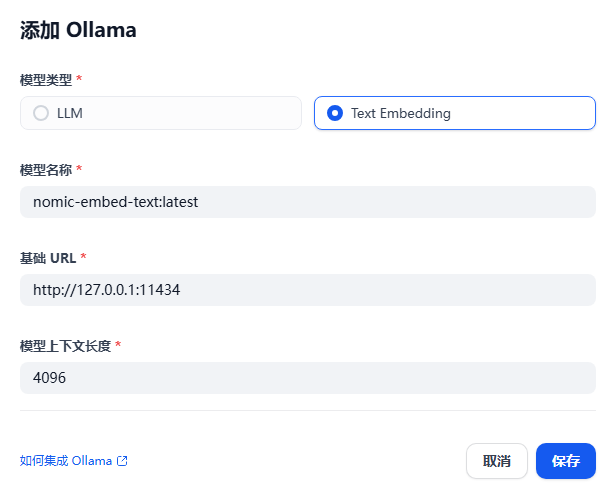
接著選擇“Text Embeding”,配置如下:
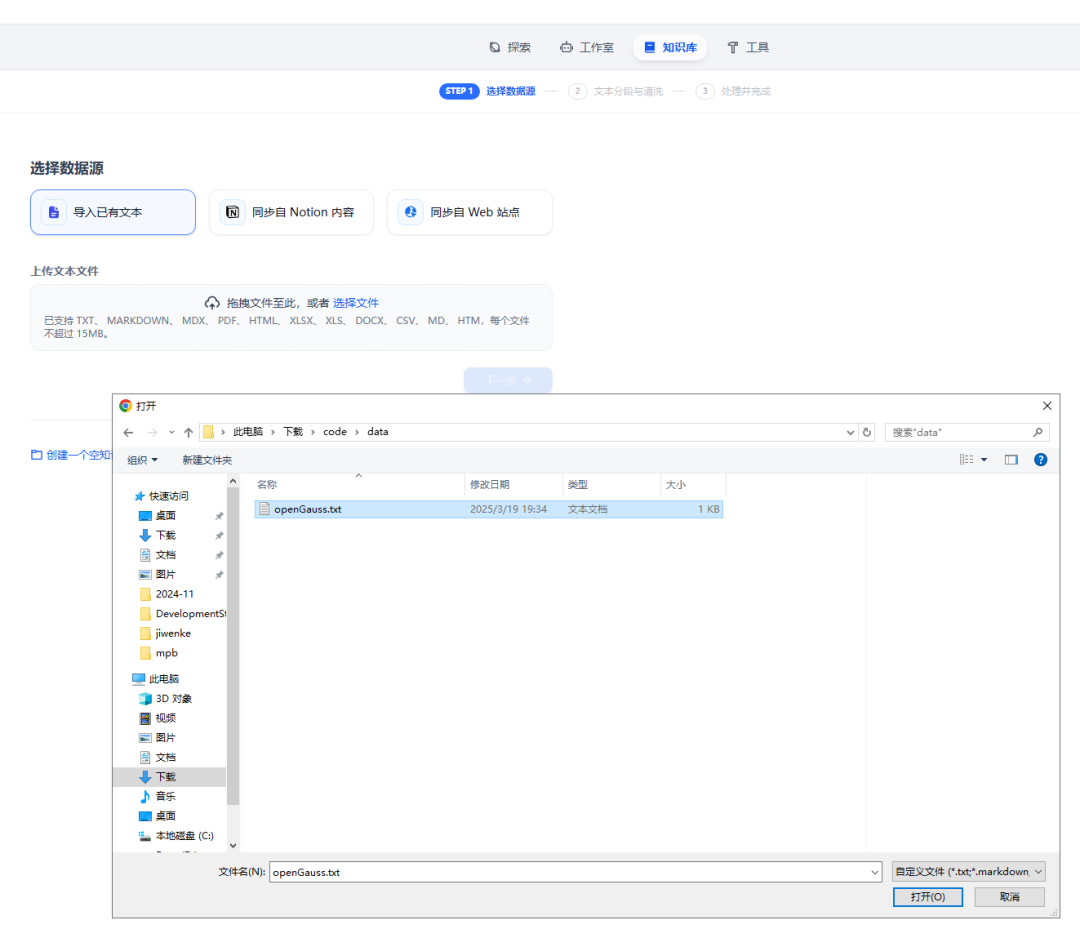
導入語料
本文以openGauss語料知識為例,為你展示如何導入語料。在頁面中單擊 “知識庫” 標簽,選擇 “導入已有文本” 選項,即可將本地準備好的語料導入到系統中:
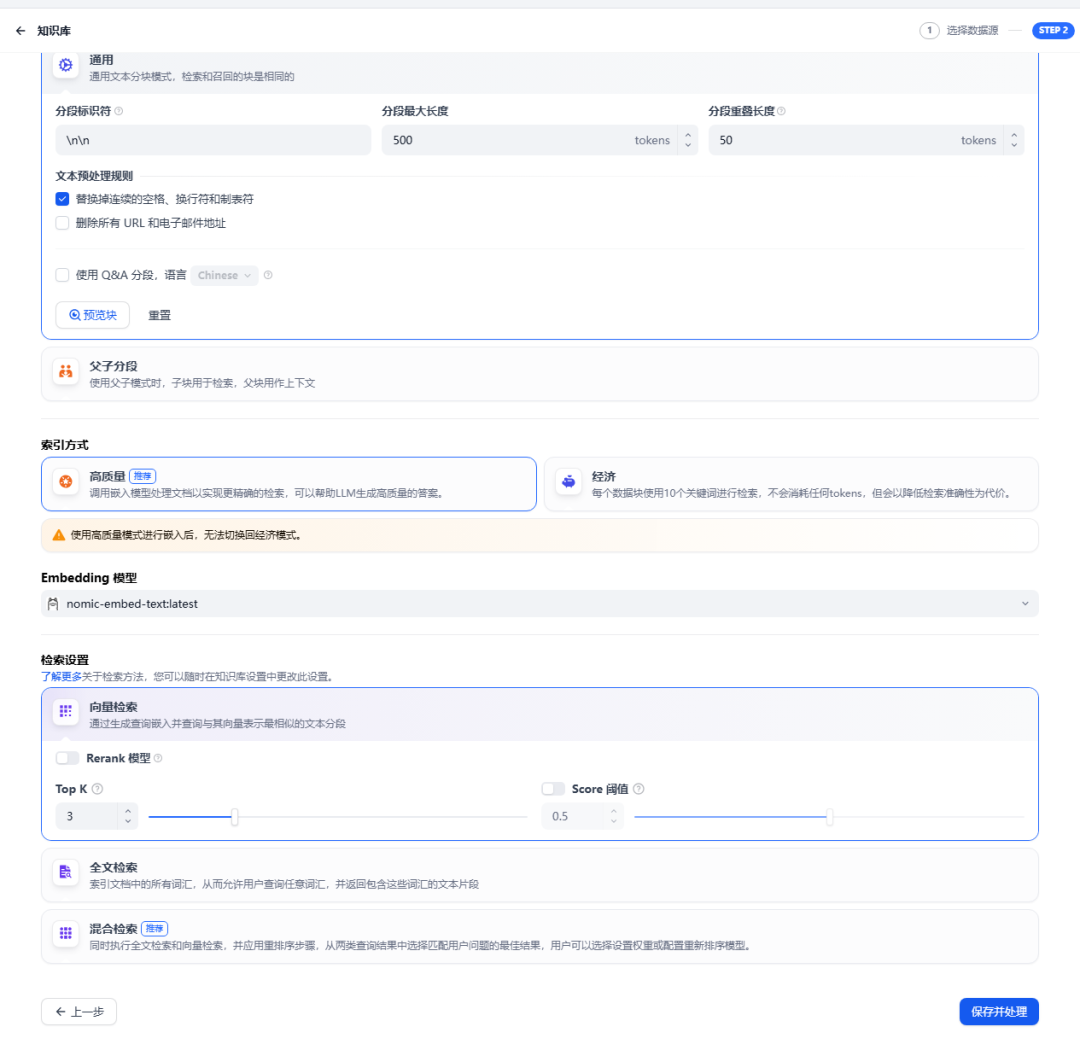
導入時,“Embeding 模型” 需選擇之前配置好的模型,然后單擊 “保存并處理” 按鈕:
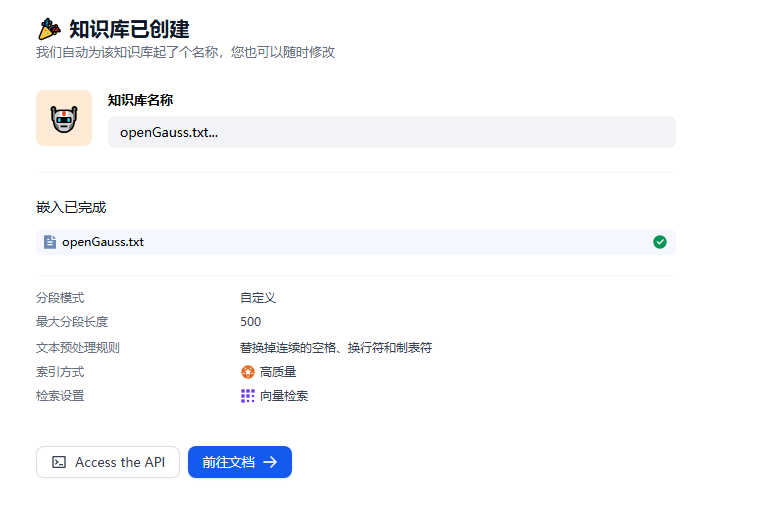
此時,系統將自動處理語料,并將其存入 openGauss 向量數據庫。你只需耐心等待處理完成,當看到類似下圖的提示時,就表明語料已經成功存儲:
對話
完成上述所有設置后,就可以開啟聊天窗口進行對話測試了。在聊天窗口中輸入問題,然后等待系統回答:
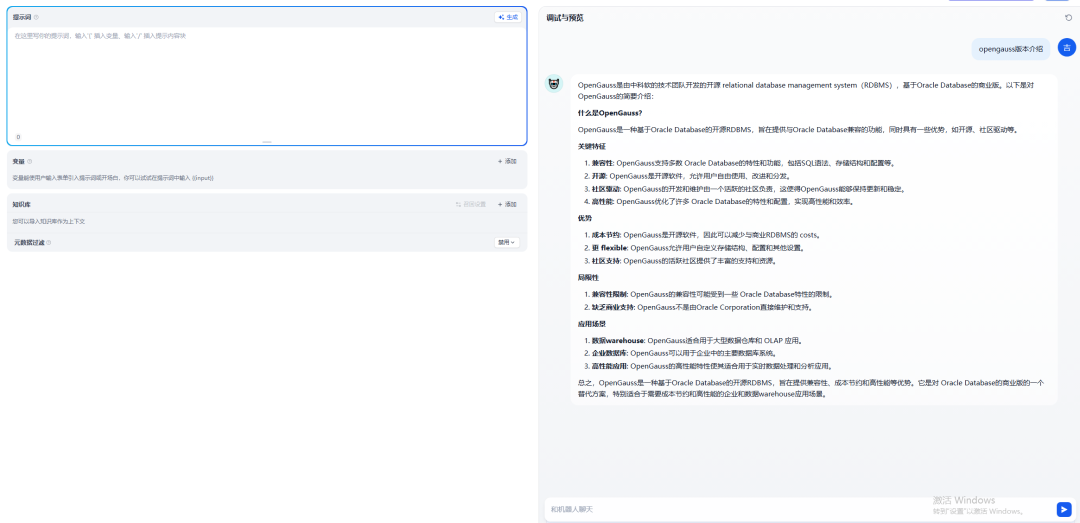
從首次回答結果可以看出,回答質量較低,描述并不準確。接下來,我們引入之前導入的openGauss語料庫作為上下文,再次進行問答:
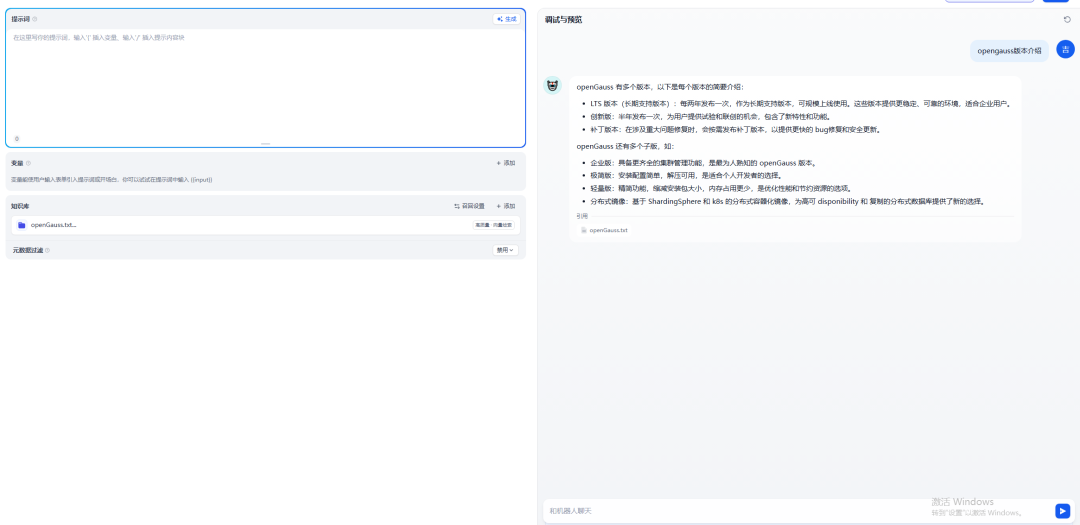
可以清晰地看到,借助于openGauss語料庫,系統給出了更為準確的答案。至此,基于openGauss向量數據庫的Dify RAG引擎搭建圓滿完成。






)

--力扣129、814、230、257)






)



