# 定義路由,分類書籍列表@category_bp.route('/filters')
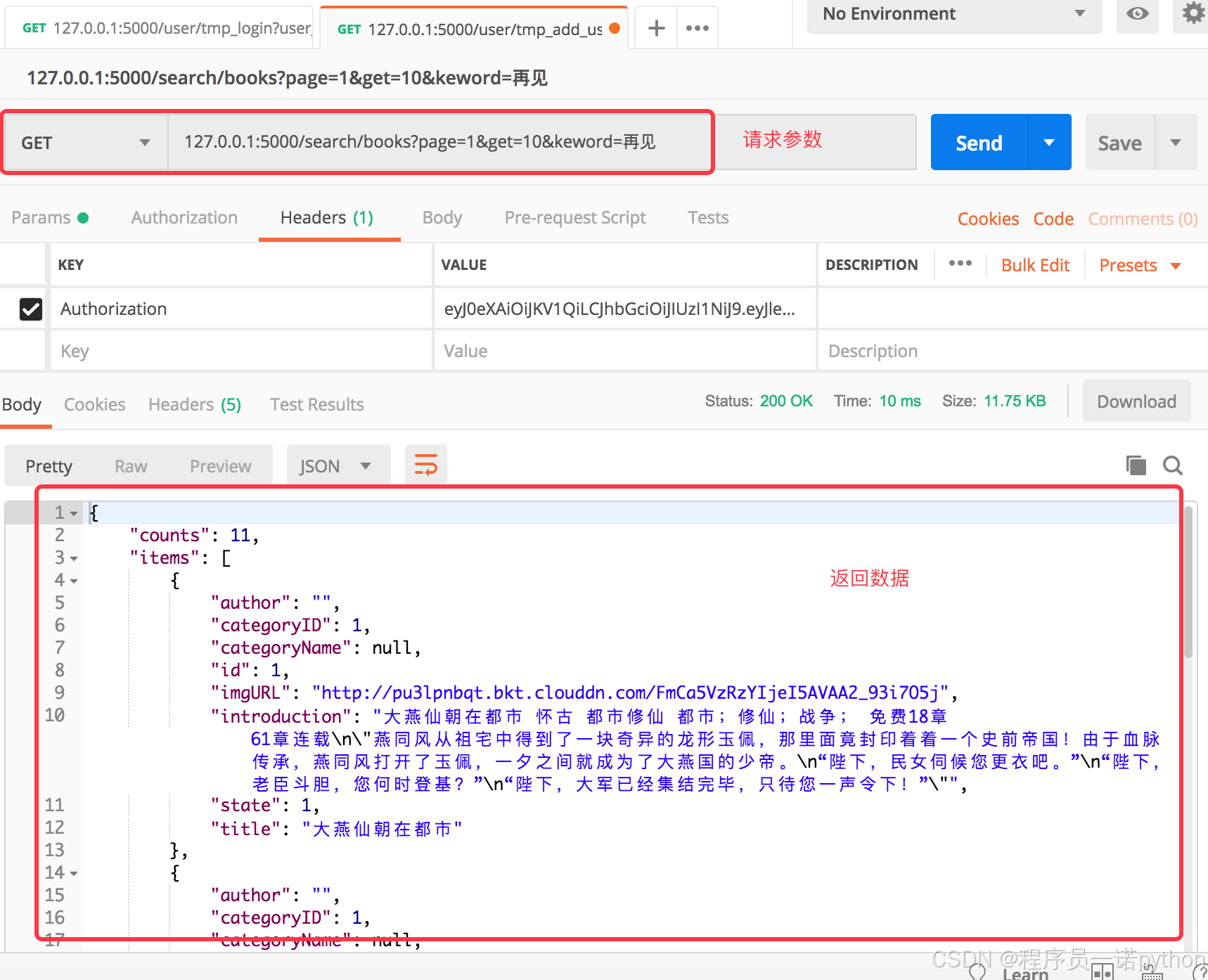
def category_book_list():# 1.獲取參數:page/pagesize/category_id/words/orderpage = request.args.get('page',1,int)pagesize = request.args.get('pagesize',10,int)category_id = request.args.get('category_id',0,int)# 字數類型說明:0表示所有,1表示50萬字以下,2表示50~100萬字,3表示100萬字以上words = request.args.get('words',-1,int)# 排序條件說明:1表示按熱度,2表示按收藏order = request.args.get('order',1,int)# 參數判斷if not category_id:return jsonify(msg='缺少分類id'),400# 2.根據分類條件category_id,查詢數據,查詢書籍大分類數據categories = BookBigCategory.query.get(category_id)# 3.判斷查詢結果,根據大分類數據,使用關系引用,獲取二級分類數據# 使用列表推導式,使用set集合seconds_id = set([i.cate_id for i in categories.second_cates])# 4.根據分類數據,查詢書籍表,獲取分類范圍內的書籍數據# -----過濾查詢:保存的是查詢結果對象,因為,后續需要對數據進行再次查詢的操作query = Book.query.filter(Book.cate_id.in_(seconds_id))# 5.根據字數條件words查詢書籍數據# -----1表示50萬字以下,2表示50~100萬字,3表示100萬字以上if words == 1:query = query.filter(Book.word_count < 500000)elif words == 2:query = query.filter(Book.word_count.between(500000,1000000))elif words == 3:query = query.filter(Book.word_count > 1000000)# 6.根據排序條件order,按照最熱、收藏數量進行排序查詢# -----1表示按熱度,2表示按收藏if order == 1:query = query.order_by(Book.heat.desc())elif order == 2:query = query.order_by(Book.collect_count.desc())else:return jsonify(msg='錯誤的排序選項'),400# 7.對查詢結果進行分頁處理,paginate# -----paginate函數表示分頁:返回結果為分頁的對象# 第一個參數表示頁數,第二個參數表示每頁的條目數,第三個參數False表示分頁異常不報錯paginate = query.paginate(page,pagesize,False)# items表示獲取分頁后的數據、page表示當前頁數、# pages表示每頁數據條目數total表示分頁的總頁數books_list = paginate.itemsitems = []# 8.遍歷分頁數據,獲取每頁數據、總頁數for item in books_list:items.append({'id':item.book_id,'title':item.book_name,'introduction':item.intro,'author':item.author_name,'state':item.status,'category_id':item.cate_id,'category_name':item.cate_name,'imgURL':'})# 9.轉成json,返回數據data = {'counts':paginate.total,'pagesize':pagesize,'pages':paginate.pages,'page':paginate.page,'items':items}return jsonify(data)










)



程編程——(1)前置知識)







