1. Transformer 整體流程概述
Transformer 模型的整個處理流程可以概括為從自注意力(Self-Attention)到多頭注意力,再加上殘差連接、層歸一化、堆疊多層的結構。其核心思想是利用注意力機制對輸入進行并行計算,從而避免傳統 RNN 逐步依賴導致的并行化困難問題。
在 Transformer 模型中,編碼器(Encoder) 和 解碼器(Decoder) 均由若干相同的層堆疊而成。模型的基本構成單元如下:
- 自注意力層(Self-Attention Layer):計算輸入中各個 token 之間的相關性,為每個 token 提供上下文表示。
- 多頭注意力機制(Multi-Head Attention):并行計算多個注意力頭,每個頭學習不同的特征(例如,有的關注實體信息,有的關注語法信息)。
- 前饋神經網絡層(Feed-Forward Layer):在每個注意力模塊后面添加一個全連接的前饋網絡,引入非線性變換。
- 殘差連接和層歸一化(Residual Connection & Layer Normalization):通過加法將輸入與輸出相加,保證梯度能夠高效傳回,并利用層歸一化穩定訓練過程。
2. 多頭注意力機制
2.1 為什么使用多頭注意力
多頭注意力機制將單一注意力分成多個“頭”,每個頭在不同的線性子空間中并行計算注意力,有以下優勢:
- 捕獲多種語義信息:例如,某一個注意力頭可能專注于實體信息(entity focused),而另一個頭可能捕捉句法結構(syntax focused)。
- 提高模型表達能力:通過并行多個注意力頭,模型能夠同時從多個角度學習輸入數據的特征。
2.2 多頭注意力公式
假設輸入為查詢 Q、鍵 K和值 V,單個注意力頭的計算如下:
Attention ( Q , K , V ) = softmax ( Q K ? d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dk??QK??)V
其中:
- dk 為鍵的維度,做縮放是為了緩解點積隨維度增加過大帶來的數值不穩定性;
- softmax 后得到的注意力權重用于對 V 進行加權平均。
多頭注意力的計算為對多個獨立注意力頭計算后,將它們拼接,再通過一個輸出矩陣 WO 得到最終的輸出:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1?,…,headh?)WO head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi?=Attention(QWiQ?,KWiK?,VWiV?)
其中 WiQ, WiK, WiV 為各頭的線性變換矩陣。
3. 縮放點積注意力
3.1 為什么使用縮放
在高維空間下,如果直接用點積 計算注意力得分,因向量維度增加,點積值通常會變得很大,導致 softmax 函數會輸出極端分布,進而使得梯度變小,不利于訓練。因此,引入縮放因子,即除以 d k \sqrt{d_k} dk?? 來緩解這種情況。
3.2 縮放點積注意力公式
完整公式如下:
e x p ? ( e i j ′ ) α i j = exp ? ( e i j ) ∑ j ′ exp ? ( e i j ′ ) α i j = ∑ j ′ e x p ( e i j ′ ) exp?(eij′)\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{j'} \exp(e_{ij'})}αij=∑j′exp(eij′) exp?(eij′)αij?=∑j′?exp(eij′?)exp(eij?)?αij=∑j′exp(eij′)
其中:
- eij 是未歸一化的注意力得分;
- αij 是歸一化后的權重;
- zi 是輸出的向量表示。
4. 殘差連接與層歸一化
4.1 殘差連接(Residual Connection)
殘差連接用于緩解深層網絡中的梯度消失問題,同時鼓勵模型捕捉接近恒等映射的信息。其作用在于讓輸入信息能夠直接流傳至后續層,從而“學習”在原始表示上做出小的修改(即“學習小編輯”)。
公式表示為:
y = LayerNorm ( x + F ( x ) ) y = \text{LayerNorm}(x + F(x)) y=LayerNorm(x+F(x))
其中:
- x 為輸入向量,
- F(x) 為經過注意力或前饋網絡后的輸出,
- LayerNorm 表示層歸一化操作。
4.2 層歸一化(Layer Normalization)
層歸一化通過計算輸入向量的均值和標準差,對向量進行歸一化處理,從而穩定訓練。具體步驟如下:
給定向量 x=[x1,x2,…,xd]
- 計算均值:
μ = 1 d ∑ i = 1 d x i \mu = \frac{1}{d} \sum_{i=1}^{d} x_i μ=d1?i=1∑d?xi?
- 計算標準差(加上一個很小的 ?\epsilon? 防止除零):
σ = 1 d ∑ i = 1 d ( x i ? μ ) 2 + ? \sigma = \sqrt{\frac{1}{d} \sum_{i=1}^{d} (x_i - \mu)^2 + \epsilon} σ=d1?i=1∑d?(xi??μ)2+??
- 歸一化和線性變換:
LayerNorm ( x ) i = γ i x i ? μ σ + e + β i \text{LayerNorm}(x)_i = \gamma_i \frac{x_i - \mu}{\sigma+e} + \beta_i LayerNorm(x)i?=γi?σ+exi??μ?+βi?
其中 γ 和 β 是可學習的參數,分別用于重新縮放和平移歸一化后的輸出。e是一個小的值,以防止被零除
5. Transformer 中的解碼器(Decoder)
5.1 解碼器與編碼器的相似性
解碼器與編碼器的基本構建塊相似,都包含自注意力、多頭注意力、前饋網絡、殘差連接與層歸一化。然而,解碼器有兩個關鍵的區別:
-
因果(Masked)自注意力:
為防止未來信息泄露,解碼器中計算自注意力時對未來的位置做屏蔽。e i j = { q i ? k j d k , j ≤ i ? ∞ , j > i e_{ij} = \begin{cases} \frac{q_i^\top k_j}{\sqrt{d_k}}, & j \leq i \\ -\infty, & j > i \end{cases} eij?={dk??qi??kj??,?∞,?j≤ij>i?
然后軟化為:
α i j = exp ? ( e i j ) ∑ j ′ = 1 i exp ? ( e i j ′ ) \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{j'=1}^{i} \exp(e_{ij'})} αij?=∑j′=1i?exp(eij′?)exp(eij?)?
-
跨注意力(Cross-Attention):
除了自注意力外,解碼器還包含跨注意力層,用于結合編碼器的輸出信息。在跨注意力中:- 查詢(Query, Q) 來自解碼器當前的隱藏狀態;
- 鍵(Key, K) 和 值(Value, V) 來自編碼器的隱藏狀態;
相應公式與前述縮放點積注意力類似:
CrossAttention ( Q , K , V ) = softmax ( Q K ? d k ) V \text{CrossAttention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V CrossAttention(Q,K,V)=softmax(dk??QK??)V
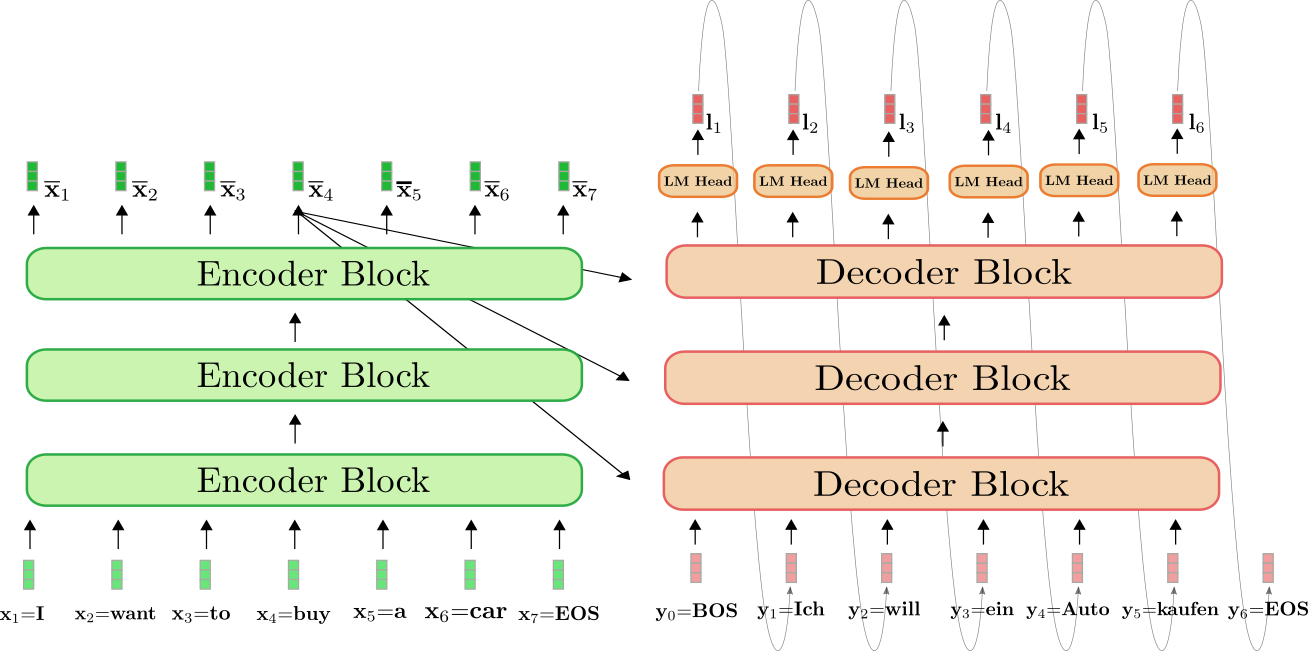
5.2 解碼器的結構總結
解碼器的一個典型層可以總結為:
- Masked Self-Attention:計算當前解碼器輸入的自注意力并屏蔽未來信息;
- 跨注意力(Encoder-Decoder Attention):利用編碼器輸出為解碼器生成當前輸出提供上下文信息;
- 前饋網絡(Feed-Forward Network):對注意力輸出進行非線性變換;
- 殘差連接與層歸一化:確保訓練中梯度穩定并促進模型學習細微調整。
6. Transformer 總結及殘差視角
從整體角度看,Transformer 模型的核心操作可以概括為:
- 多次并行注意力計算:通過多頭注意力,模型同時關注不同角度的信息。
- 添加殘差連接:讓每一層學習輸入上的小修正(“編輯”),從而保留原始信息。
- 加入層歸一化:使各層輸入分布保持穩定,提高訓練效率。
- 堆疊多層結構:重復上述模塊,多層堆疊能捕捉到更加抽象的特征。
從殘差視角來觀察,Transformer 的核心是詞嵌入,隨后每一層做的是在原始表示上學習微小的調整,從而“編輯”出更符合任務需求的表示。
核心區別總結表:
| 模塊 | Encoder Layer | Decoder Layer |
|---|---|---|
| Attention 1 | Multi-Head Self-Attention | Masked Multi-Head Self-Attention |
| Attention 2 | 無 | Cross-Attention(Query 來自 Decoder,Key/Value 來自 Encoder) |
| FFN | 有(相同) | 有(相同) |
| 殘差&歸一化 | 有 | 有 |
📌 為什么 Decoder 需要 Masked Self-Attention?
為了保證**自回歸(Autoregressive)**生成,只能看到前面的詞,不能偷看將來的詞。
舉例:
- 當前生成到位置 3,不能讓 Decoder 看到位置 4 的詞。
- 所以在 Attention 的 softmax 權重矩陣中,強行 mask 掉未來位置。
🤯 記憶小技巧:
| Encoder | Decoder |
|---|---|
| 自我理解 | 自我生成 + 看懂輸入 |
| “我看整句,理解上下文” | “我邊生成邊回看 Encoder 給的提示” |




Linux下SpringBoot項目自動部署)







)






)