計算機視覺與圖像分類概述:計算機視覺發展簡史
計算機視覺(Computer Vision)作為人工智能領域的重要分支,是一門研究如何使機器"看"的科學,更具體地說,是指用攝影機和計算機代替人眼對目標進行識別、跟蹤和測量等機器視覺,并進一步做圖形處理,使計算機處理成為更適合人眼觀察或傳送給儀器檢測的圖像。
1.基本概念與定義
這一交叉學科涉及計算機科學、數學、物理學、神經科學和認知心理學等多個領域,旨在通過算法和技術手段讓計算機從數字圖像或視頻中獲得高層次的理解。
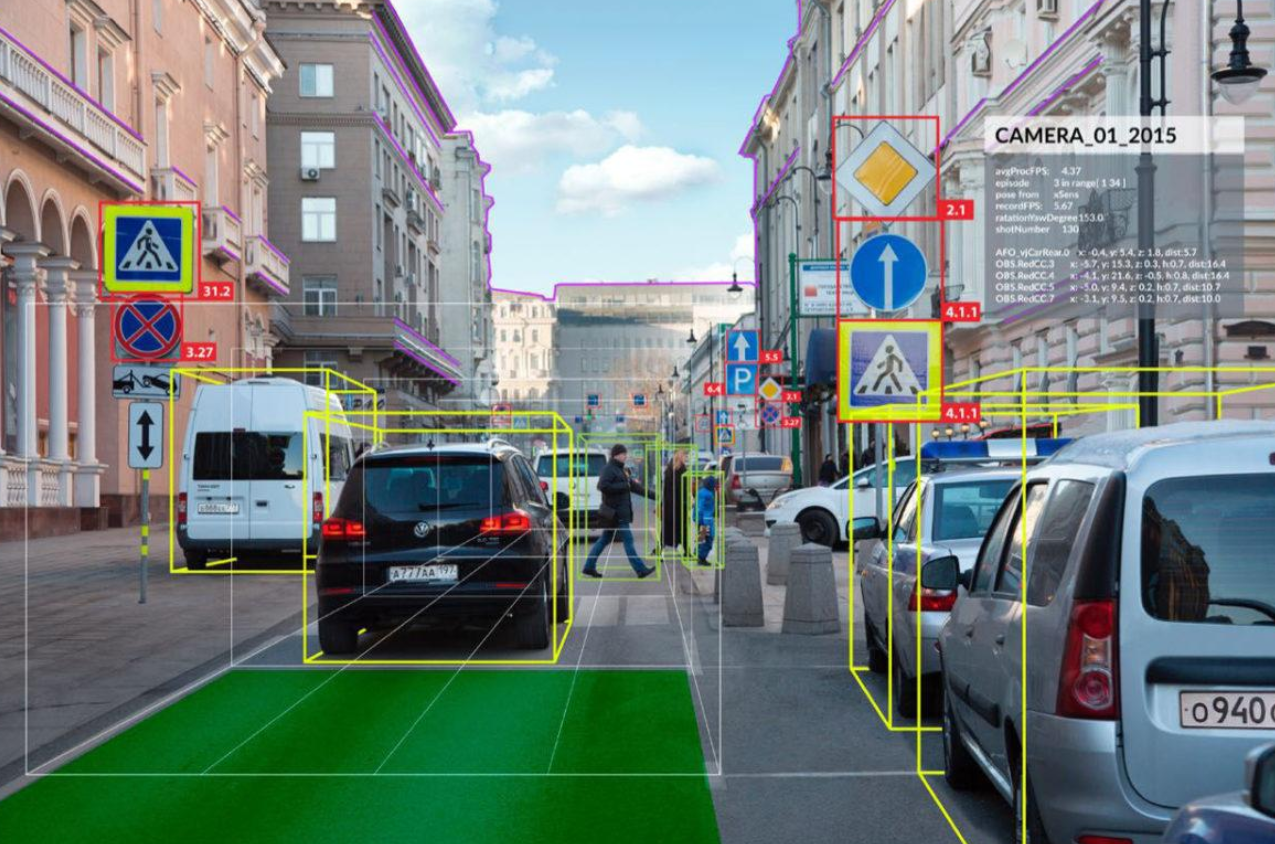
圖像分類(Image Classification)作為計算機視覺中最基礎也最核心的任務之一,指的是根據圖像中描繪的內容為其分配一個或多個類別標簽的過程。
這一過程模擬了人類視覺系統識別和理解圖像內容的能力,是許多高級視覺任務如目標檢測、圖像分割、場景理解等的基礎。傳統圖像分類方法通常包括特征提取和分類器設計兩個主要步驟,而現代深度學習方法則能夠端到端地完成這一任務。

計算機視覺系統的典型工作流程包括圖像獲取、預處理、特征提取、檢測/分割、高級處理和決策制定等環節。
圖像獲取階段通過各種傳感器(如CCD、CMOS相機)將光信號轉換為數字信號
預處理階段可能包括去噪、增強、歸一化等操作
特征提取階段識別圖像中的關鍵信息
檢測/分割階段定位感興趣區域
高級處理階段則進行識別、分類等復雜任務
最后的決策制定階段根據應用需求輸出結果。
與人類視覺系統相比,計算機視覺既有優勢也有局限。計算機可以處理人眼無法感知的頻譜(如紅外、X光圖像),能夠長時間穩定工作而不疲勞,處理速度在某些特定任務上遠超人類。
然而,計算機視覺系統在泛化能力、上下文理解、常識推理等方面仍遠不及人類,特別是在處理遮擋、光照變化、視角變化等復雜情況時表現尚不理想。
這種差距正是推動計算機視覺研究不斷前進的動力之一。
2.早期發展(1960s-1980s)
計算機視覺的起源可以追溯到20世紀60年代,當時的研究主要受到神經科學和心理學關于人類視覺系統研究的啟發。
1966年,MIT的人工智能實驗室創始人之一Marvin Minsky給學生布置了"夏季視覺項目"(Summer Vision Project),要求他們用幾個月時間解決"計算機視覺"問題。這個現在看來過于樂觀的項目標志著計算機視覺作為獨立研究領域的誕生。雖然項目未能達到預期目標,但它確立了計算機視覺作為一個需要長期研究的科學問題。
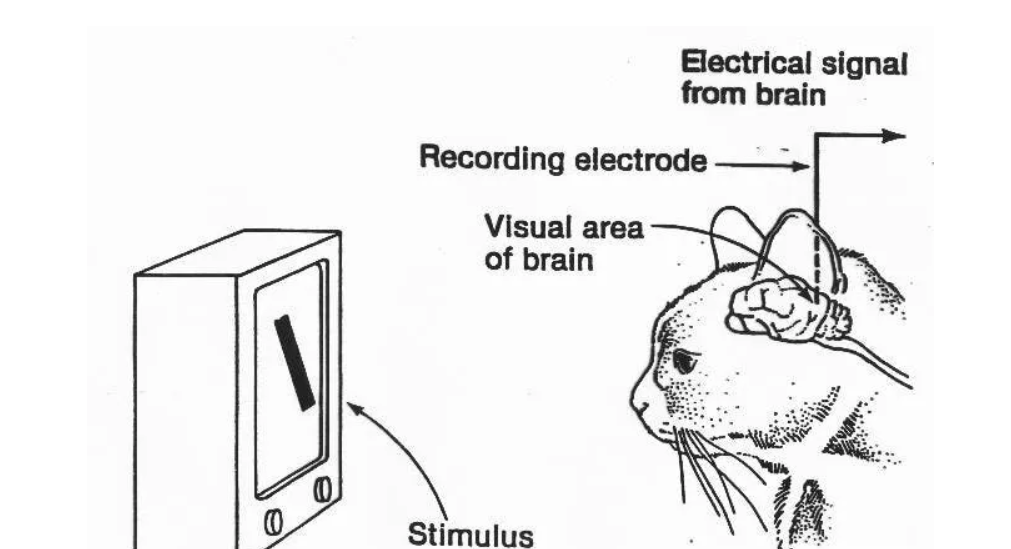
70年代是計算機視覺算法奠基的重要時期。David Marr在這一時期提出了影響深遠的視覺計算理論,他在《Vision: A Computational Investigation》一書中系統闡述了視覺信息處理的三個階段:
- 初始草圖(提取邊緣、紋理等基本特征)
- 2.5維草圖(恢復表面和深度信息)
- 三維模型表示(構建物體的三維描述)。
這一理論框架為后續計算機視覺研究提供了方法論指導。與此同時,Lawrence Roberts在1963年發表的關于三維物體識別的論文被認為是計算機視覺領域的開山之作,他提出了從二維圖像中恢復三維幾何信息的基本思路。

80年代見證了計算機視覺從理論走向應用的轉變。日本在這一時期率先將機器視覺技術應用于工業檢測和質量控制,開啟了計算機視覺的產業化進程。
1982年,David Marr的學生Shimon Ullman提出了"結構從運動"(Structure from Motion)算法,能夠從一系列二維圖像中恢復三維場景結構,這一技術至今仍是計算機視覺的重要研究方向。同年,日本學者福島邦彥提出的Neocognitron神經網絡模型,模仿生物視覺系統的層次結構,成為后來卷積神經網絡(CNN)的前身。
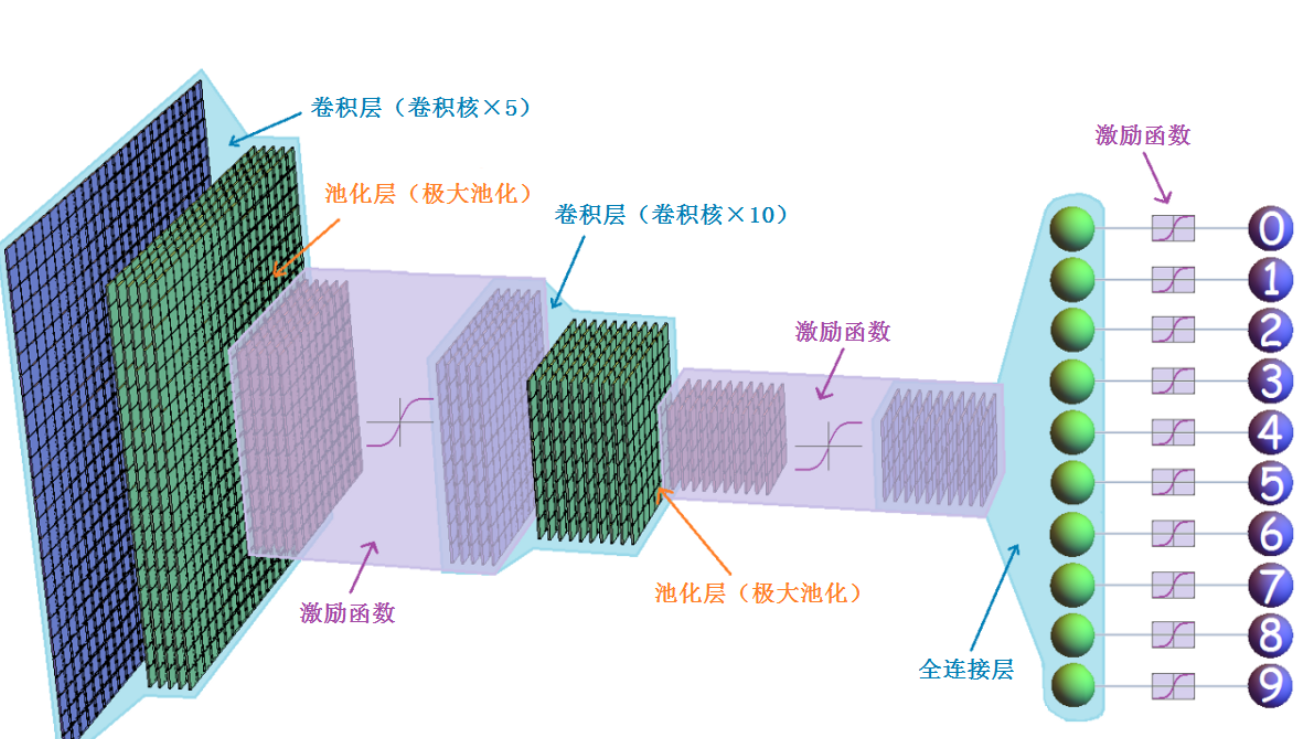
早期的圖像分類方法主要基于手工設計的特征和傳統機器學習算法。這些方法通常包括兩個階段:特征提取和分類器訓練。
常用的特征包括顏色直方圖、紋理特征(如LBP、Gabor濾波器)、形狀特征(如HOG)以及更復雜的特征描述符(如SIFT、SURF)。
分類器則多采用支持向量機(SVM)、隨機森林(Random Forest)或AdaBoost等算法。
這些方法在特定領域的應用中取得了一定成功,但由于手工特征的設計需要大量領域知識且泛化能力有限,圖像分類的性能遇到了瓶頸。

3.從傳統方法到現代計算機視覺(1990s-2000s)
90年代是計算機視覺算法多樣化和實用化的發展階段。
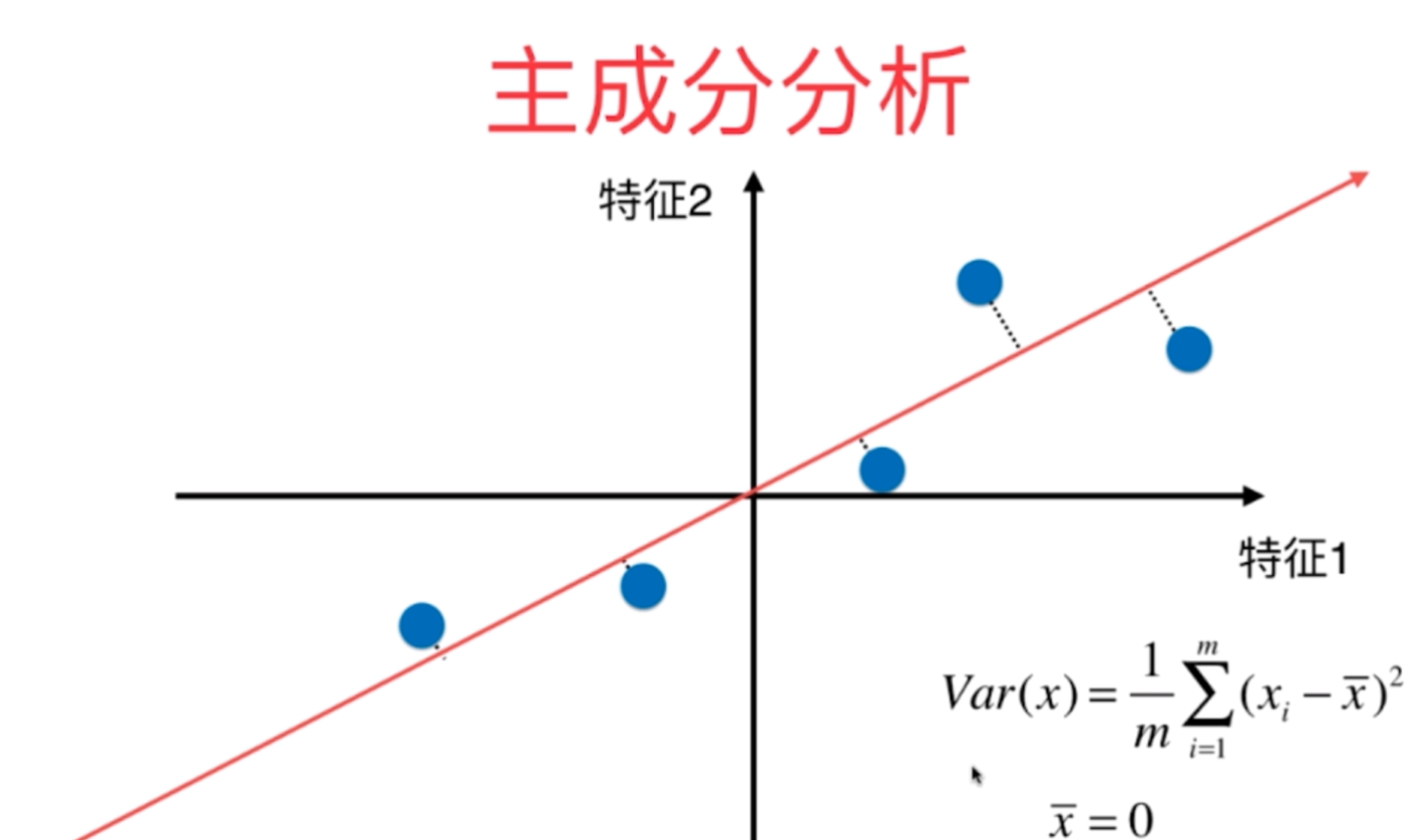
1991年,Turk和Pentland提出的特征臉(Eigenfaces)方法首次將主成分分析(PCA)應用于人臉識別,開辟了基于統計學習的視覺分析方法。1997年,Shi和Malik提出的歸一化割(Normalized Cuts)算法將圖論方法引入圖像分割,顯著提升了分割質量。1999年,David Lowe提出的尺度不變特征變換(SIFT)成為首個具有尺度、旋轉和光照不變性的局部特征描述符,在圖像匹配和物體識別中得到廣泛應用。
這一時期,計算機視覺開始與其他學科深度融合。1995年,MIT媒體實驗室的Rosalind Picard提出"情感計算"概念,將計算機視覺與情感識別相結合。1998年,微軟研究院開發的"虛擬鼠標"系統首次實現了基于視覺的人機交互。同時,醫學影像分析、遙感圖像處理等專業領域的視覺技術也取得了長足進步。2001年,Paul Viola和Michael Jones提出的實時人臉檢測框架將積分圖(Integral Image)、AdaBoost和級聯分類器(Cascade Classifier)相結合,首次實現了視頻流中的實時人臉檢測,這一突破性成果被廣泛應用于數碼相機、智能手機等消費電子產品。

2000年代初,隨著互聯網的普及和數字圖像數據的爆炸式增長,計算機視覺研究面臨著新的挑戰和機遇。2004年,David Lowe進一步完善了SIFT算法,使其成為事實上的局部特征標準。同年,Intel推出的開源計算機視覺庫OpenCV開始流行,大大降低了計算機視覺研究和應用的門檻。2005年,Navneet Dalal和Bill Triggs提出的方向梯度直方圖(HOG)特征在人臉檢測和行人檢測中表現出色,進一步推動了基于手工特征的視覺算法發展。

2006年,Fei-Fei Li開始構建ImageNet數據集,這一雄心勃勃的計劃旨在為計算機視覺研究提供大規模標注圖像資源。ImageNet的建立源于一個深刻認識:計算機視覺系統的性能提升不僅需要更好的算法,更需要大規模、多樣化的訓練數據。這一理念在深度學習時代被證明具有前瞻性。與此同時,PASCAL VOC(Visual Object Classes)挑戰賽于2005年啟動,為物體識別、檢測和分割等任務提供了標準化的評估平臺,促進了不同研究團隊之間的比較和交流。
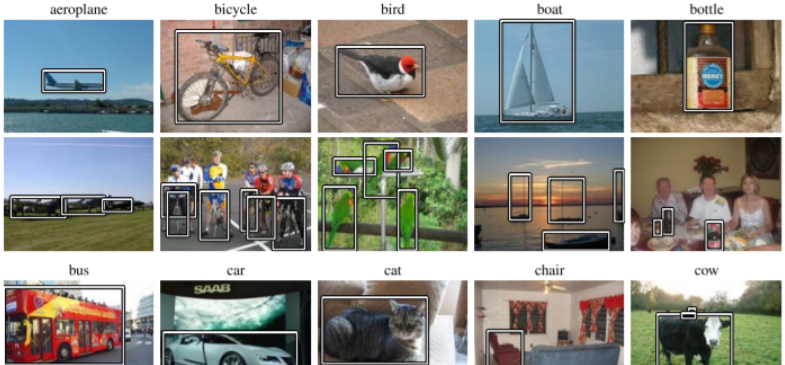
在這一階段末期,傳統計算機視覺方法已經發展到了相當成熟的水平,但在處理復雜、多變的真實世界圖像時仍面臨巨大挑戰。手工設計特征的局限性日益明顯,研究者們開始探索新的技術路徑。2006年,Geoffrey Hinton等人提出的深度信念網絡(DBN)開啟了深度學習復興的先河,為計算機視覺的革命性突破埋下了伏筆。2009年,ImageNet項目正式發布,包含超過320萬張標注圖像,為即將到來的深度學習革命準備好了戰場。

4.深度學習革命與計算機視覺新時代(2010s至今)
2012年成為計算機視覺發展的分水嶺。在當年的ImageNet大規模視覺識別挑戰賽(ILSVRC)中,Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton提出的AlexNet以壓倒性優勢奪冠,將Top-5錯誤率從上一年的26%大幅降至15.3%。這一突破性成果的關鍵在于:首次在大規模圖像分類任務中成功應用了深度卷積神經網絡(CNN);采用ReLU激活函數緩解梯度消失問題;使用GPU加速訓練過程;引入Dropout正則化防止過擬合。AlexNet的成功標志著計算機視覺正式進入深度學習時代。

2012年后,卷積神經網絡架構不斷創新,推動圖像分類性能持續提升。2014年,牛津大學提出的VGGNet通過使用更深的網絡(16-19層)和小尺寸卷積核(3×3),進一步提高了分類準確率,其簡潔統一的結構成為后續研究的重要基礎。同年,Google提出的GoogLeNet(Inception v1)引入"Inception模塊",通過多尺度卷積和降維操作,在增加網絡深度的同時控制了計算量。2015年,微軟研究院提出的ResNet通過殘差連接(Residual Connection)成功訓練了152層的超深網絡,將ImageNet分類錯誤率降至3.57%,首次超越人類水平(約5%)。

隨著深度學習的普及,計算機視覺研究范式發生了根本性轉變。傳統的手工特征設計被端到端的特征學習取代,研究者們更加關注網絡架構的設計和優化。注意力機制、殘差連接、批量歸一化等創新技術不斷涌現。2017年,Google提出的Transformer架構最初應用于自然語言處理,但很快被引入計算機視覺領域。2020年,Vision Transformer(ViT)證明純Transformer架構在大規模圖像分類任務上可以超越CNN,開辟了視覺表征學習的新方向。與此同時,自監督學習、對比學習等新型學習范式減少了對于大規模標注數據的依賴,提高了模型的泛化能力。
深度學習也推動了計算機視覺應用場景的極大擴展。人臉識別技術已達到商用水平,廣泛應用于安防、金融、零售等領域。2014年,Face++在人臉識別測評(LFW)上首次超越人類識別準確率。自動駕駛汽車依靠計算機視覺進行環境感知,特斯拉的Autopilot系統能夠實時處理多個攝像頭輸入。醫學影像分析中,深度學習算法在肺結節檢測、糖尿病視網膜病變篩查等任務上達到甚至超過專業醫師水平。增強現實(AR)技術如蘋果的ARKit、谷歌的ARCore都深度依賴計算機視覺進行場景理解和跟蹤。

近年來,計算機視覺與其他AI技術的融合成為新趨勢。多模態學習將視覺與語言、語音等模態相結合,OpenAI的CLIP模型能夠實現圖像與文本的跨模態理解。生成對抗網絡(GAN)和擴散模型(Diffusion Model)可以生成高質量圖像,DALL-E、Stable Diffusion等系統能夠根據文本描述生成創意圖像。邊緣計算和輕量級網絡設計使計算機視覺應用能夠部署到移動設備和物聯網終端。聯邦學習等隱私保護技術則解決了視覺數據中的隱私和安全問題。
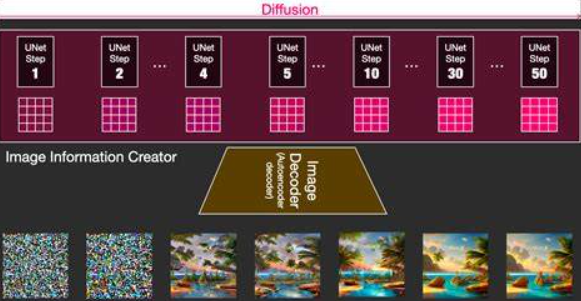
計算機視覺的研究前沿正朝著更加通用、魯棒和可解釋的方向發展。視覺-語言預訓練模型如谷歌的PaLM-E展示了多模態大模型的強大能力。三維視覺、神經渲染(如NeRF)技術正在重塑數字內容創作方式。自監督學習和元學習有望降低對標注數據的依賴。可解釋AI技術試圖揭開深度學習"黑箱",提高模型決策的透明度。隨著技術的不斷進步,計算機視覺正在從狹義的圖像理解向廣義的場景理解、從被動感知向主動交互、從專用系統向通用智能的方向發展。
5.計算機視覺的技術分支與應用領域
現代計算機視覺已經發展出眾多技術分支,每項分支針對不同的視覺理解任務。圖像分類作為最基礎的任務,旨在為整張圖像分配一個或多個類別標簽,其技術進步直接推動了深度學習在計算機視覺中的應用。目標檢測則不僅要識別圖像中的物體類別,還要確定它們的位置和范圍,代表性算法包括R-CNN系列、YOLO和SSD等。圖像分割分為語義分割(為每個像素分配類別標簽)和實例分割(區分同類物體的不同實例),全卷積網絡(FCN)、U-Net和Mask R-CNN是這一領域的里程碑工作。
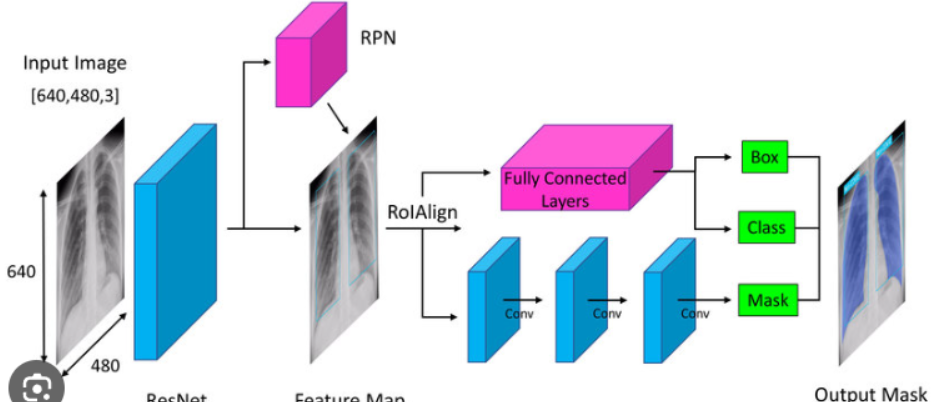
三維計算機視覺致力于從二維圖像中恢復三維場景信息,包括立體匹配、深度估計、三維重建等任務。運動分析與視覺跟蹤研究視頻序列中物體的運動規律和行為模式,在監控、自動駕駛中有重要應用。光流估計計算相鄰幀之間的像素級運動,是許多視頻分析任務的基礎。場景理解則試圖對圖像中的物體、它們之間的關系以及場景的語義進行整體解釋,是計算機視覺的終極目標之一。

計算機視覺的應用已經滲透到各行各業。在醫療領域,計算機視覺輔助醫學影像分析(X光、CT、MRI)能夠早期發現疾病征兆,病理切片分析、手術導航等應用正在改變醫療實踐。在自動駕駛中,視覺系統與雷達、激光雷達等多傳感器融合,實現車道檢測、交通標志識別、行人避障等功能。工業檢測中,機器視覺系統以遠超人類的速度和精度完成產品質量檢驗、缺陷檢測等任務。
安防監控是計算機視覺的傳統應用領域,人臉識別、行為分析、人群計數等技術大大提高了公共安全水平。零售行業利用視覺技術進行客流分析、貨架管理、無人結算等。農業中,無人機結合計算機視覺實現作物健康監測、精準施藥和產量預測。在文化娛樂領域,人臉濾鏡、動作捕捉、虛擬試衣等應用豐富了用戶體驗。遙感圖像分析則服務于城市規劃、環境監測、災害評估等宏觀決策。

新興應用場景不斷拓展計算機視覺的邊界。在增強現實(AR)和虛擬現實(VR)中,視覺技術實現空間定位、手勢交互和虛實融合。人機交互通過手勢識別、視線跟蹤等方式提供更自然的交互體驗。智能手機中的計算攝影技術如夜景模式、人像模式、超分辨率等都依賴于先進的計算機視覺算法。社交媒體中的內容審核、圖像搜索、自動標注等功能也離不開視覺技術的支持。

計算機視覺與其他技術的交叉融合催生了許多創新方向。視覺-語言多模態學習使機器能夠理解圖像內容并生成自然語言描述,或根據文字描述檢索、生成圖像。機器人視覺賦予機器人感知和理解環境的能力,是實現自主操作的基礎。腦機接口中的視覺刺激和反饋建立人腦與計算機之間的直接通信渠道。量子計算有望解決計算機視覺中的某些復雜優化問題,而神經形態計算則模仿生物視覺系統的工作原理,開發更高效的視覺處理硬件。
6.計算機視覺面臨的挑戰與未來趨勢
盡管取得了顯著進展,計算機視覺仍面臨諸多挑戰。數據偏差與泛化能力是首要問題,在特定數據集上訓練的模型往往難以適應真實世界的多樣性,當測試數據與訓練數據分布不一致時性能會顯著下降。對抗樣本暴露了深度學習模型的脆弱性,精心設計的微小擾動可以導致完全錯誤的分類結果,這對安全關鍵應用構成嚴重威脅。模型可解釋性不足限制了在醫療、司法等領域的應用,用戶難以理解模型做出特定決策的原因。
計算資源需求是另一大挑戰,訓練最先進的視覺模型需要大量GPU/TPU資源和電力消耗,既不環保也不普惠。隱私問題日益突出,人臉識別等技術引發了對個人數據保護的廣泛關注。實時性與準確性的權衡在移動設備和邊緣計算場景中尤為明顯。多物體遮擋、小樣本學習、長尾分布等問題在實際應用中經常遇到,但現有方法處理起來仍有困難。三維視覺中的光度一致性、幾何一致性等約束條件增加了問題復雜度。

未來計算機視覺的發展將呈現以下趨勢:通用視覺模型的研究受到越來越多的關注,如微軟的Swin Transformer、谷歌的Vision Transformer等試圖建立統一的視覺表征框架。自監督學習通過設計巧妙的預訓練任務(如圖像修復、拼圖游戲)從未標注數據中學習可遷移的特征表示,減少對人工標注的依賴。神經符號結合將深度學習的感知能力與符號系統的推理能力相結合,有望實現更高層次的視覺理解。
多模態融合成為提升視覺系統性能的重要途徑,語言、聲音、觸覺等其他模態信息可以提供補充線索。邊緣智能推動計算機視覺算法向輕量化、低功耗方向發展,使其能夠部署在終端設備上。聯邦學習等隱私保護技術允許在數據不離開本地的情況下協同訓練模型,符合日益嚴格的數據保護法規。仿真環境和高保真合成數據將幫助解決真實數據獲取困難和標注成本高的問題。

腦科學與計算機視覺的交叉研究可能帶來革命性突破,對生物視覺系統的深入理解可以啟發更高效的視覺算法。量子計算機視覺探索量子計算在圖像處理、模式識別中的潛在優勢。可解釋AI技術旨在揭開深度學習黑箱,提供直觀的決策依據和錯誤診斷。持續學習使視覺系統能夠在不遺忘舊知識的情況下學習新任務,更接近人類的學習能力。
計算機視覺的長期目標是構建具有人類水平甚至超人類水平的通用視覺系統,能夠像人類一樣靈活地理解和解釋視覺世界。實現這一目標需要算法、數據、算力和理論的多方面突破。隨著技術的進步,計算機視覺將繼續深刻改變我們的生活和工作方式,在醫療、教育、交通、制造等各個領域創造價值,同時也將帶來倫理、隱私、安全等方面的新挑戰,需要技術開發者、政策制定者和公眾共同應對。
7.結語
回顧計算機視覺從20世紀60年代至今的發展歷程,我們見證了這一領域從簡單的邊緣檢測到復雜的場景理解、從依賴手工特征到自動學習表征、從受限實驗室環境到開放真實世界的驚人進步。這一演變過程不僅是技術的累積,更是研究范式的轉變——從模仿生物視覺到建立數學和計算理論,再到數據驅動的大規模學習。
圖像分類作為計算機視覺的基礎問題,其發展軌跡折射出整個領域的變遷。早期的模板匹配和特征工程讓位于深度神經網絡,而今天的Transformer架構又正在挑戰CNN的主導地位。性能指標從最初的勉強可用到超越人類水平,應用場景從學術研究擴展到工業界的方方面面。這一進步的背后是算法創新、數據積累和計算硬件三者協同演進的結果。

當前,計算機視覺正處于前所未有的繁榮時期,同時也站在新的十字路口。一方面,現有技術已經能夠解決許多特定任務,催生了龐大的應用市場;另一方面,通用視覺智能的實現仍面臨根本性挑戰。未來的發展需要在追求性能提升的同時,關注模型的魯棒性、可解釋性、公平性和能效比,在技術進步與社會價值之間取得平衡。
計算機視覺的未來發展將更加注重與實際應用的緊密結合,在解決具體行業問題的過程中不斷完善技術。同時,基礎研究的突破仍至關重要,特別是在理解深度學習工作原理、建立更完備的視覺理論方面。跨學科合作將成為常態,神經科學、認知心理學、物理學等領域的見解將繼續為計算機視覺提供新鮮靈感。
作為人工智能感知世界的重要窗口,計算機視覺的發展不僅關乎技術本身,也將深刻影響人機交互方式和社會運行模式。我們有理由期待,在不遠的將來,計算機視覺技術將更加智能、普惠和可靠,真正成為人類認識世界和改造世界的得力助手。這一進程需要全球研究者的共同努力,也需要社會各界的理解和支持,以確保技術發展始終服務于人類的整體利益。



:數據完整性保障的不二之選)





)









