1 什么是Sqoop?
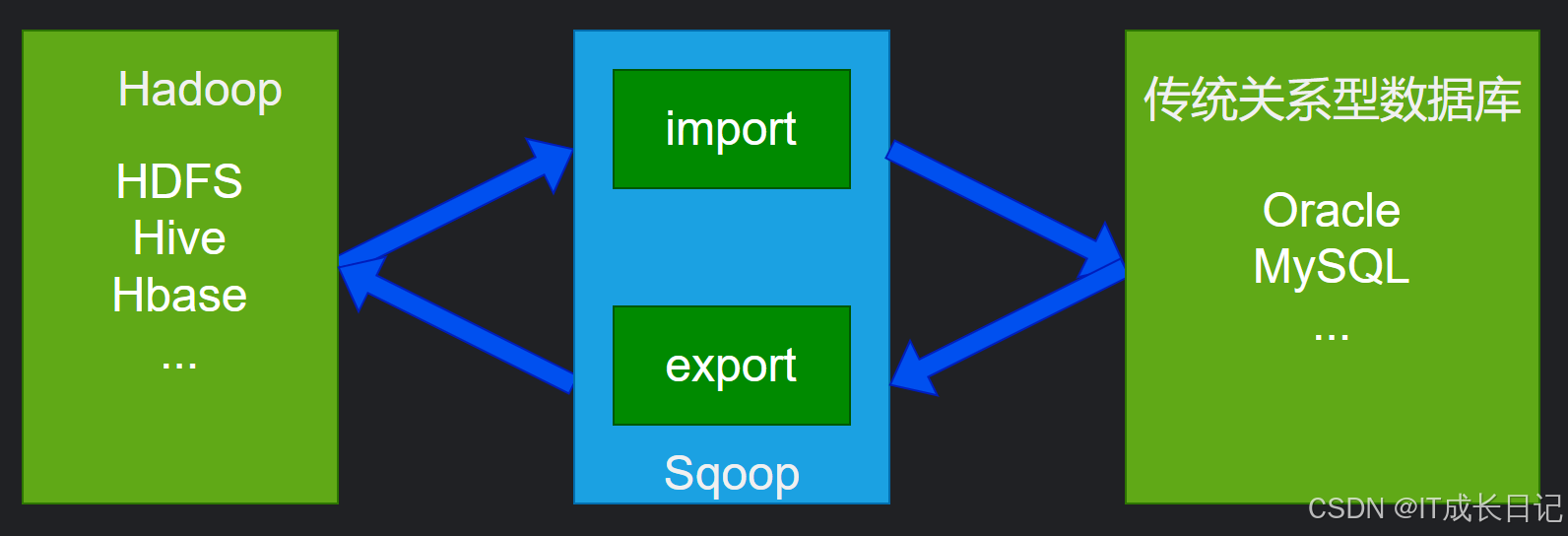
在企業的數據架構中,關系型數據庫與Hadoop生態系統之間的數據流動是常見且關鍵的需求。Apache Sqoop(SQL-to-Hadoop)正是為解決這一問題而生的高效工具,它專門用于在結構化數據存儲(如RDBMS)和Hadoop生態系統(如HDFS、Hive、HBase)之間 雙向傳輸大規模數據集。Sqoop的核心功能:
- 數據導入:將關系型數據庫中的數據導入到Hadoop生態系統中,如HDFS、Hive或HBase
- 數據導出:將Hadoop生態系統中的數據導出到關系型數據庫中
- 支持全量與增量導入:既可以一次性導入全部數據,也可以只導入新增或更新的數據,滿足不同的業務需求
- 并行處理:利用MapReduce的并行處理能力,提高數據傳輸的速度和效率
- 數據格式轉換:在導入導出過程中,支持多種數據格式的轉換,如TextFile、Avro、Parquet等
2 Sqoop的核心價值
Sqoop(SQL-to-Hadoop)的核心價值主要體現在以下幾個方面,這些價值點緊密圍繞大數據處理與遷移的需求,為企業在數據整合、分析及應用方面提供了強有力的支持:
高效數據遷移:
- 跨平臺支持:在關系型數據庫(MySQL、Oracle等)與Hadoop生態(HDFS、Hive、HBase)間高效傳輸數據,支持全量和增量同步
- 高性能:基于并行處理與優化算法,顯著提升海量數據遷移效率
簡化數據集成:
- 自動化工具:通過命令行快速完成數據遷移,減少復雜腳本開發需求
- 降低人工成本:最小化手動操作,提高數據準確性與可靠性
多格式多存儲兼容:
- 靈活格式:支持TextFile、Avro、Parquet等格式,適配不同分析場景
- 廣泛存儲支持:兼容HDFS、Hive、HBase及云存儲
數據安全保障:
- 傳輸加密:保障敏感數據遷移過程中的安全性
- 權限管控:細粒度訪問控制,限制未授權操作
生態集成與擴展性:
- 無縫對接Hadoop:與Hive、MapReduce等組件協同,構建完整數據處理鏈路
- 高可擴展:適應企業數據規模增長需求
成本優化:
- 開源免費:無許可費用,降低企業技術投入
- 資源高效利用:通過優化遷移流程,最大化集群資源利用率
3 工作原理剖析
Sqoop通過生成MapReduce作業來實現數據的導入和導出。具體過程如下:
導入過程:
- Sqoop連接到關系型數據庫,獲取元數據(如表結構、字段類型等)
- 根據指定的條件(如查詢條件、分區列等),生成MapReduce作業
- MapReduce作業從數據庫中讀取數據,經過處理后寫入到HDFS或其他Hadoop組件中
導出過程:
- Sqoop從Hadoop生態系統中讀取數據
- 根據目標數據庫的結構,生成相應的插入或更新語句
- 將數據寫入到關系型數據庫中
4.1 數據導入
sqoop import \--connect jdbc:mysql://localhost:3306/mysql_db \ # 源數據庫JDBC連接URL--username root \ # 數據庫用戶名--password 123456 \ # 數據庫密碼--table mysqltable \ # 要導入的源表名--target-dir /data/ \ # HDFS目標目錄(存儲導入數據)--fields-terminated-by '\t' # 字段分隔符(默認逗號,此處指定為制表符)- 關鍵參數說明
| 參數 | 說明 |
| --connect | 指定源數據庫的JDBC連接字符串 |
| --table | 要導入的關系型數據庫表名 |
| --target-dir | HDFS上存儲導入數據的目錄(需不存在,否則報錯) |
| --fields-terminated-by | 生成文件的分隔符(如\t,,等) |
| --lines-terminated-by | 行分隔符(默認\n) |
| --null-string | 替換NULL字符串的占位符(如\\N) |
4.2 數據導出
sqoop export \--connect jdbc:mysql://localhost:3306/data_warehouse \ # 目標數據庫JDBC連接--username user \ # 目標數據庫用戶名--password pwd \ # 目標數據庫密碼--table tablename \ # 目標表名(需提前創建)--export-dir /results/ \ # HDFS源數據目錄--input-fields-terminated-by ',' # 輸入文件字段分隔符- 關鍵參數說明
| 參數 | 說明 |
| --export-dir | HDFS中待導出數據的路徑 |
| --input-fields-terminated-by | 輸入文件的分隔符(需與導入時一致) |
| --update-key | 指定更新主鍵(如id,實現增量更新) |
| --update-mode | 更新模式(allowinsert或updateonly) |
4.3 高級功能
- 增量導入(Incremental Import):僅同步新增或修改的數據,避免全量導入
sqoop import \--connect jdbc:mysql://localhost:3306/mydb \--table orders \--check-column order_id \ # 增量檢查列(通常為時間戳或自增ID)--last-value "210001" \ # 上次導入的最大值--incremental append \ # 增量模式(append或lastmodified)--target-dir /data
- Hive集成:直接導入數據到Hive表,自動創建表結構
sqoop import \--connect jdbc:mysql://localhost:3306/mydb \--table products \--hive-import \ # 啟用Hive導入--hive-table ads_hive_h # 指定Hive數據庫和表名
- 壓縮支持:減少存儲空間和I/O開銷
--compress \ # 啟用壓縮(默認Gzip)
--compression-codec org.apache.hadoop.io.compress.SnappyCodec # 指定Snappy壓縮
- 自定義查詢:通過SQL語句靈活篩選源數據
sqoop import \--connect jdbc:mysql://localhost:3306/retail_db \--query "SELECT * FROM tablename" \--target-dir /data5 Sqoop與傳統ETL工具對比
| 對比維度 | Sqoop | 傳統ETL工具 (如Informatica/Talend/DataStage) |
| 設計定位 | 專為Hadoop與關系數據庫批量傳輸優化 | 企業級數據集成平臺,支持復雜業務流程 |
| 架構特點 | 輕量級命令行工具,基于MapReduce/YARN | 可視化開發環境,集中式調度服務器 |
| 數據處理能力 | 結構化數據批處理 | 支持結構化/半結構化/非結構化數據,批處理+流處理 |
| 性能表現 | 大數據量并行傳輸優勢明顯(TB級) | 中小數據量事務處理更優,依賴硬件配置 |
| 擴展性 | 天然適配Hadoop生態橫向擴展 | 垂直擴展為主,集群部署成本高 |
| 開發效率 | 簡單場景配置快捷 | 復雜邏輯可視化開發效率高 |
| 調度管理 | 需外接調度系統(如Airflow) | 內置完善的任務調度和監控 |
| 數據轉換能力 | 僅支持簡單字段映射 | 提供豐富的數據清洗轉換組件 |
| 實時能力 | 批處理為主(需結合Kafka等實現準實時) | 部分工具支持CDC實時同步 |
| 學習成本 | 命令行操作,技術門檻較低 | 需要掌握專用IDE和概念體系 |
| 成本投入 | 開源免費 | 商業授權費用高昂(部分提供社區版) |
| 典型適用場景 | Hadoop生態數據灌入/導出 | 企業級數據倉庫建設,跨系統復雜集成 |
6 典型應用場景
數據倉庫與數據湖構建:
場景需求:將關系型數據庫歷史數據遷移至Hadoop集群,建立分析型數據存儲
Sqoop方案:支持全量/增量數據高效導入HDFS/Hive/HBase,為分析平臺提供數據基礎
大數據分析支持:
場景需求:為實時/離線分析提供數據源
Sqoop方案:定期同步業務數據到Hadoop生態,與Spark/Flink等計算引擎無縫集成
典型應用:機器學習特征工程,用戶行為分析,實時報表生成
數據災備方案:
場景需求:構建安全可靠的數據備份體系
Sqoop方案:利用Hadoop分布式存儲特性實現數據庫全量/增量備份
核心價值:3-2-1備份策略支持,PB級數據存儲可靠性,快速恢復能力
系統遷移與整合:
場景需求:多源異構數據統一管理
Sqoop方案:跨數據庫類型遷移(如Oracle→MySQL→HDFS)
實施優勢:schema自動轉換,數據一致性保證,最小化停機時間
準實時數據同步:
場景需求:業務系統與數據分析系統數據對齊
Sqoop方案:結合CDC工具實現分鐘級延遲的數據管道
技術組合:Kafka+Sqoop+Spark Streaming架構,變更數據捕獲(CDC)
多格式數據管理:
場景需求:適應不同分析場景的存儲需求
Sqoop方案:
存儲格式:支持Text/JSON/Parquet/Avro等
存儲系統:兼容HDFS/Hive/HBase/云存儲
業務價值:列式存儲優化查詢,壓縮節省空間,schema演進支持
7 最佳實踐建議
- 分區策略優化:選擇高基數列作為拆分列
- 批量大小調整:平衡內存使用與性能
- 格式選擇:生產環境推薦使用列式存儲(如Parquet)
- 增量導入:對變化數據使用--incremental參數
- 錯誤處理:合理設置--num-mappers和錯誤容忍度
8 性能優化技巧
- 并行度控制:根據數據庫負載能力調整mapper數量
- 直接模式:對MySQL使用--direct選項
- 緩存調優:適當增加fetch size減少網絡往返
- 連接池配置:避免頻繁創建數據庫連接
- 壓縮傳輸:減少I/O和網絡開銷
9 總結
Apache Sqoop作為Hadoop生態系統中數據橋梁的關鍵組件,在企業數據架構中仍然扮演著不可替代的角色。它簡單而專注的設計理念,使其在特定場景下(特別是大規模批量數據傳輸)仍然保持著性能和可靠性的優勢。


)















)
