

前引:在進入本篇文章之前,我們經常在使用某個應用時,會出現【商品名稱、最受歡迎、購買量】等等這些榜單,這里面就運用了我們的排序算法,作為剛學習數據結構的初學者,小編為各位完善了以下幾種排序算法,包含了思路拆解,如何一步步實現,包含了優缺點分析、復雜度來歷,種類很全,下面我們開始穿梭算法排序的迷霧,尋求真相!
堆排序
說到堆排序,我們又需要重溫樹的神奇了,大家先別畏懼,區區堆排序小編將帶著大家解構它,讓它毫無保留的展現給大家!在學習之前,我們需要知道兩種思想結構:物理結構、邏輯結構
堆實現的邏輯結構就是一顆完全二叉樹:
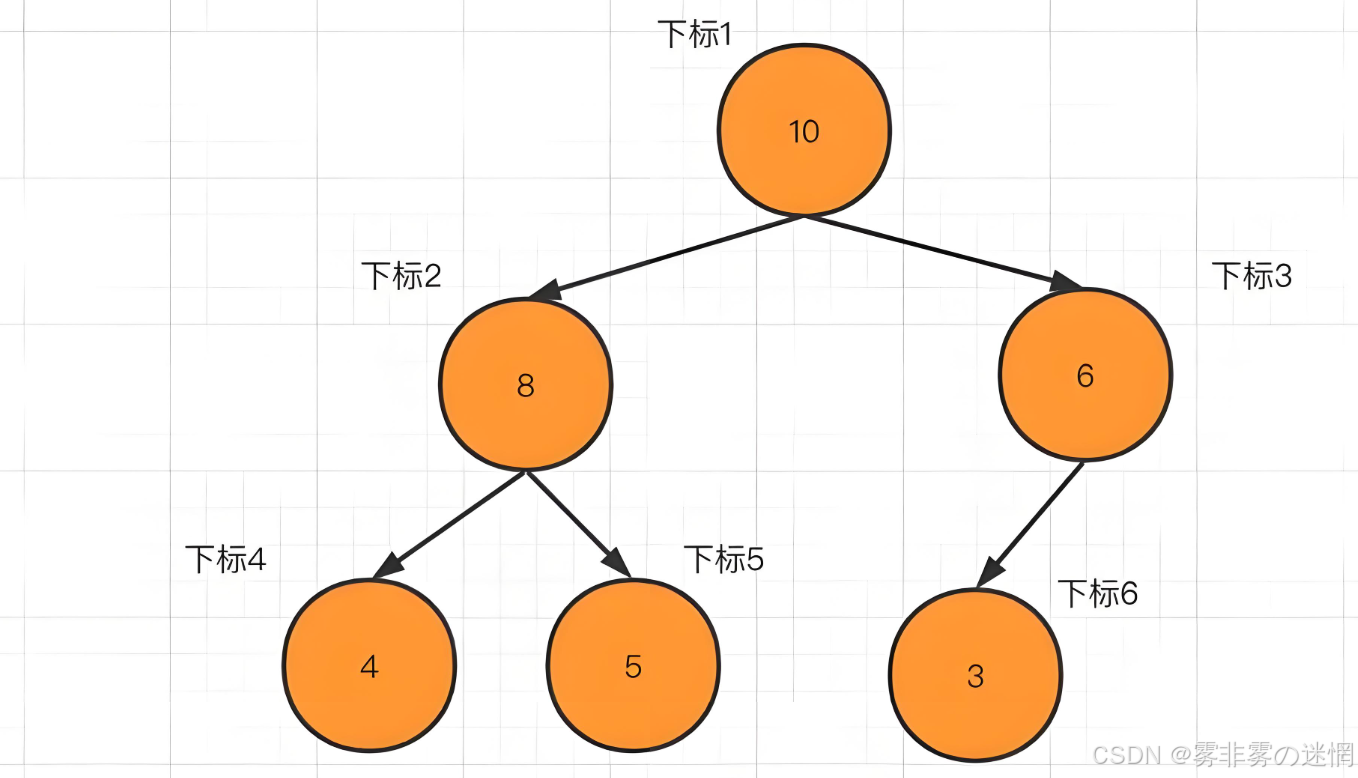
?但是咱們是用數組實現的,只是借助邏輯結構去完成物理結構,大家對比兩幅圖,就明白了!

?算法思路:
在看算法思路之前,我們需要知道什么是大頂堆,什么是小頂堆
大頂堆:每個節點的值都大于或等于其子節點的值,堆頂為最大值
小頂堆:每個節點的值都小于或等于其子節點的值,堆頂為最小值
咱們的堆本質是一顆用數組實現的完全二叉樹,下面我以數組下標從1開始存儲為例,如需更多的參考以及深入學習堆,可以參考小編主頁的【堆】哦!下面是各節點下標換算的關系:
左子節點:2 * i ? ? ? 右子節點:2 * i + 1? ? ?父節點:i(若已知子節點 k ,則父節點為 k / 2)
堆的算法思路就是:利用堆的性質,來實現對數據的排序
(白話文理解:利用堆結構關系,對數據按照最大堆/最小堆提取堆頂元素來實現排序,因為堆頂是這組數組的最值,咱每次提取出來,不就是達到了排序效果嗎!)
實現步驟:
咱們堆排序以實現堆為主,因此需要先手搓一個堆,堆的實現包含以下步驟:(實現有詳細說明)
初始化? ?存儲? ?上浮調整? ?移除堆尾元素? ?下沉調整
復雜度分析:
堆分為建堆、排序堆兩個階段,因此需要分別說明,參考如下理解
建堆階段:從最后一個非葉子節點開始調整,時間復雜度為O(n)
排序堆階段:每次調整堆的時間復雜度為O(logn),共需要調整n-1次,因此總時間復雜度為O(nlogn)
綜合起來就是O(nlogn)
空間復雜度為O(1)。因為堆排序是原地排序算法,僅僅需要常數級的額外空間
代碼實現:
建堆:
咱們按照堆排序的步驟,第一步需要先建立堆,咱們先建立一個結構體,參考如下代碼:
#define MAX 10typedef struct Pile
{//存儲的數組空間int* space;//當前堆存儲數量int size;//當前最大存儲量int max;
}Pile;
下面我們對堆進行初始化操作,開辟空間、設置初始變量,參考以下代碼:
//初始化堆
void Preliminary(Pile* pilestruct)
{assert(pilestruct);pilestruct->size = 0;pilestruct->max = MAX;//開辟空間pilestruct->space = (int*)malloc(sizeof(int) * MAX);if (pilestruct->space == NULL){perror("malloc");return;}
}
接下來咱們進行數據存儲進堆,來實現存儲的代碼:
//存儲
void Storage(Pile* pilestruct,int data)
{assert(pilestruct);//先判斷是否存滿,是則擴容if ((pilestruct->size+1) == pilestruct->max){int* pc = (int*)realloc(pilestruct->space, sizeof(int) * (pilestruct->max) + MAX);if (pc == NULL){perror("realloc");return;}pilestruct->space = pc;//更新maxpilestruct->max += MAX;}//存儲數據pilestruct->size++;pilestruct->space[pilestruct->size] = data;//上浮調整Adjust(pilestruct->space, pilestruct->size);
}
存儲之后需要數據滿足最大堆的性質,所以咱們還需要一個調整函數,其思想如下:
將此數據與其父節點進行比較,如果這個數據較大,交換父節點與其位置,反之不交換,代碼如下
//上浮調整
void Adjust(int * space, int child)
{//父節點下標int parent = child / 2;while (child > 1){if (space[child] > space[parent]){Exchange(&space[child], &space[parent]);//更新child,parentchild = parent;parent = (child ) / 2;}elsebreak;}
}現在咱們的建堆就寫完了,我存儲了幾個數字,大家可以看看效果:

排序堆:
將堆頂元素(最大值)與堆的最后一個元素交換,然后size--,這樣我們就去除了堆頂元素(最大值),注意:這里的去除只是將堆元素個數減一,并不是刪除。然后我們就一直重復這樣的操作,直到將所有元素調整完,我們堆的元素原來是9 8 6 1 0 2,調整之后是:0 1 2 5 6 8 9
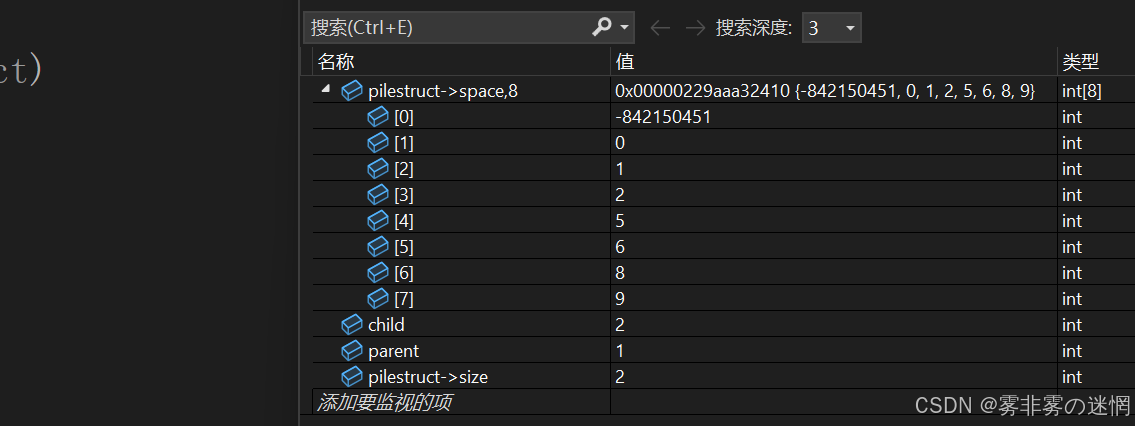
核心思想(重點):利用多次下沉調整每次將最大值放到末尾,這樣就達到了有序數據?
void Pilesort(Pile* pilestruct)
{assert(pilestruct);//parent下標int parent = 1;//child下標int child = 2*parent;//最后一個節點和根節點換位Exchange(&pilestruct->space[pilestruct->size], &pilestruct->space[1]);//移除根節點pilestruct->size--;//下沉調整while (child <= pilestruct->size)// 注意點1{//找到左右孩子節點的最大值// 注意點2if (child < pilestruct->size && pilestruct->space[child] < pilestruct->space[child+1]){child++;}//看是否交換其與父節點// 注意點3if (child<=pilestruct->size && pilestruct->space[child] > pilestruct->space[parent]){Exchange(&pilestruct->space[child], &pilestruct->space[parent]);//更新父、孩子節點下標parent = child;child = 2 * parent;}elsebreak;}
}
在上面的代碼中,有3個需要注意的地方(上圖標出來了),為哈3個判斷條件需要注意?
注意點1:當堆最后只有2個元素的時候,還要發生一次交換(0與1),因此可以取等號
注意點2:這個 if 條件需要注意,當最后兩個元素0與1時,1在根節點,0在子節點,雖然滿足中國? ? ? ? ? ? ? ? ? 判斷條件,但是所以這兩個數字不能發生交換,所以不能取等號
注意點3:還是跟上個判斷條件一樣,0在根節點,1在子節點,滿足判斷條件,需要交換
總結:堆的實現需要兩次調整。一次是存儲數據時需要滿足最大堆的性質,需要做上浮調整。而? ? ? ? ? ? ? ?每次交換根節點元素 和 尾節點元素之后,還是需要保持大頂堆的性質,因此需要下沉調整
下面我們已經將這組數據利用下沉調整完全實現了有序,只需要再依次拿出來就行了?
優缺點分析:
堆排序屬于原地排序,對大規模數據排序效率較高,并且不會因為數據量增大導致性能急劇下降,但是堆排序同時也是非穩定排序,相同元素的相對順序可能會改變,最大的問題就需要手動寫一個堆,需要對指針、數組之間的邏輯、物理關系的相互轉化
冒泡排序
“冒泡”排序的實現思路很簡單,咱們先看一個圖:

當各種小泡泡從魚嘴里面吐出來到達最上面的水層,泡泡是最大的,因此咱們冒泡排序的實現也是,每次排序將最大值向后面靠,話不多說,進入正題!
算法思路:
?通過重復遍歷列表,比較相鄰元素并看是否進行交換,將最大的元素逐漸“冒泡”到列表末尾
實現步驟:
記住咱們的排序先從單趟寫,由里向外。
單趟的實現:通過? for? 循環將第一次遍歷的最大值通過比較移到末尾即可
單趟實現完后,咱們已經排序完了一個元素,那么只需要將剩余的 n-1 個元素排序完成就行了

復雜度分析:
最好最壞都是遍歷(可以參看“代碼實現”),所以時間復雜度都是O(n^2)?
空間復雜度:冒泡屬于原地排序,所以為O(1)
代碼實現:
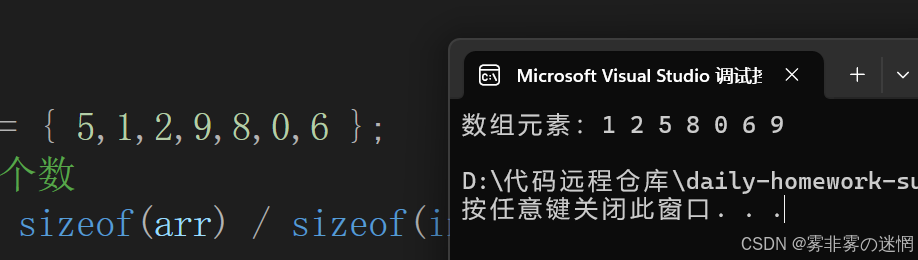
按照實現步驟,咱們先實現單趟:(對比左右兩幅圖,我們已經將 9 排序到了最后)
//單趟
for (int i = 0; i < size - 1; i++)
{//如果前一個元素比后一個元素大if (arr[i] > arr[i + 1]){Exchange(&arr[i], &arr[i + 1]);}
}
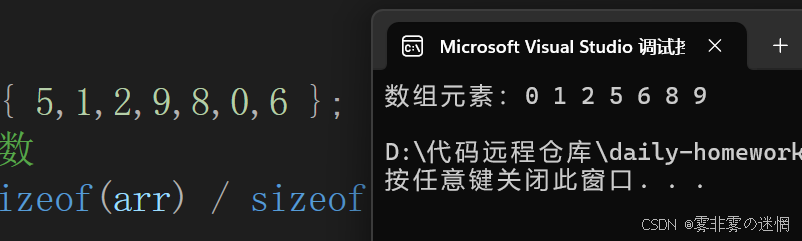
?我們已經排序完了一個元素,下面我們再套個循環,排序剩余的 n-1 個元素:
for (int j = 1; j < size - 1; j++)
{//單趟for (int i = 0; i < size - 1; i++){//如果前一個元素比后一個元素大if (arr[i] > arr[i + 1]){Exchange(&arr[i], &arr[i + 1]);}}
}
代碼優化:
?我們在優化之前不管后面的元素是否已經有序,都需要遍歷,導致重復了無用的次數,優化如下
如果我們開始假設整組元素都是有序的,也就是 false = -1 ,如果發生了交換,那么 false = 1 ,那么就表明需要進行下一次的循環判斷,否則直接退出循環,因為遍歷一遍結束之后,false如果還為-1,就表明數組已經是有序的了,代碼如下:
for (int j = 1; j < size - 1; j++)
{//假設整組數據有序int false = -1;//單趟for (int i = 0; i < size - 1; i++){//如果前一個元素比后一個元素大if (arr[i] > arr[i + 1]){Exchange(&arr[i], &arr[i + 1]);//假設不符合false = 1;}}if (false == -1){break;}
}優缺點分析:
冒泡排序是穩定的排序算法,相等的元素在排序之后依然保持原來的相對順序,但是時間復雜度原先很高,達到了O(n^2),但是我們通過優化,提高了一定的算法效率,在處理數據時可以排除有序數據,表現更好
Hoare排序
Hoare排序是快速排序的一種經典實現,由Tony Hoare于1960年提出,核心思想是基于分治策略,通過Hoare分區方法將數組分為兩部分,遞歸的再對子數組排序,看不懂沒有關系,咱們學習Hoare排序肯定要知道它咋來的,以上是術語,下面我們進行學習!(特別提醒!很不好理解!)
算法思路:
Hoare排序的關鍵在于Hoare分區方法,其特點是通過雙指針從數組兩端向中間掃描,減少冗余交換,尤其擅長處理重復的元素,整體分治思路如下:
劃分:選擇一個基準值(pivot),將數組分為兩部分,左半部分元素 <= pivot ,右半部分元素 >= pivot?
遞歸:對左右兩部分分別遞歸調用Hoare排序

復雜度分析:
?每次遞歸將數組分為兩部分,遞歸深度為 log n ,每層處理時間為 O(n),因此平均時間復雜度為(n logn)
當每次分區完全逆序,遞歸深度為 n ,最壞情況達到了 O(n^2)
實現步驟:
首先咱們來講解單趟的實現(重點):
(1)假設我們開始有一個數組,將它的最左邊的值?6?作為基準值 pivot?

(2)現在我們再設置這個數組的最左邊的值 和 最右邊的值分別為 left 和? right??
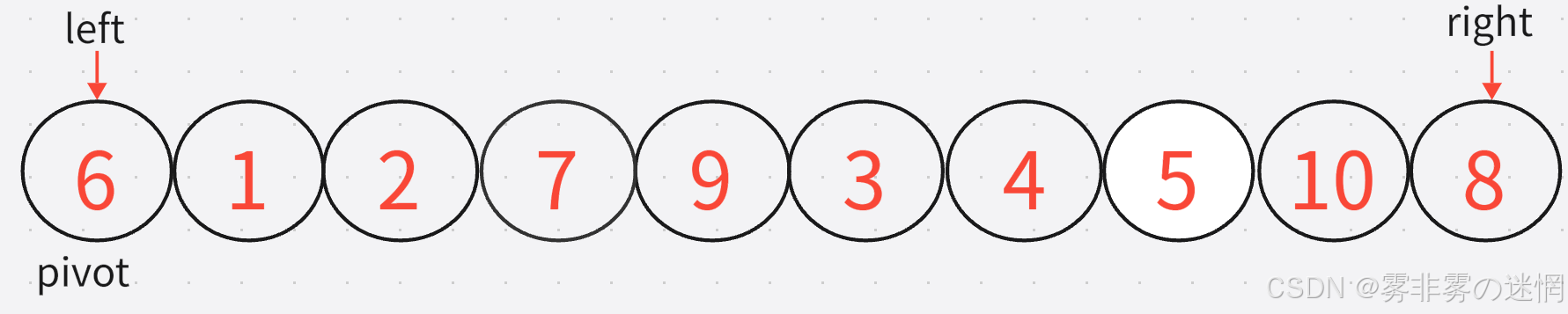
(3)下面我們通過循環找:左邊大于等于基準值的元素(找大),右邊小于等于基準值的元素(找小),因為我們需要讓大于基準值的元素摞到右邊,小于基準值的移到左邊?
注意事項:我們的初衷是大的在右邊,小的在左邊,因此需要從右邊開始移動,只有這樣,才能保證小于基準值的移到左邊來。反之,如果基準值在右邊,就從左邊開始移動 。?如下:?

(4)將找到的滿足條件的元素進行交換 ,如下圖:

(5)繼續循環找到滿足條件的兩個元素,直到兩者相遇,然后交換相遇的元素與基準值元素?

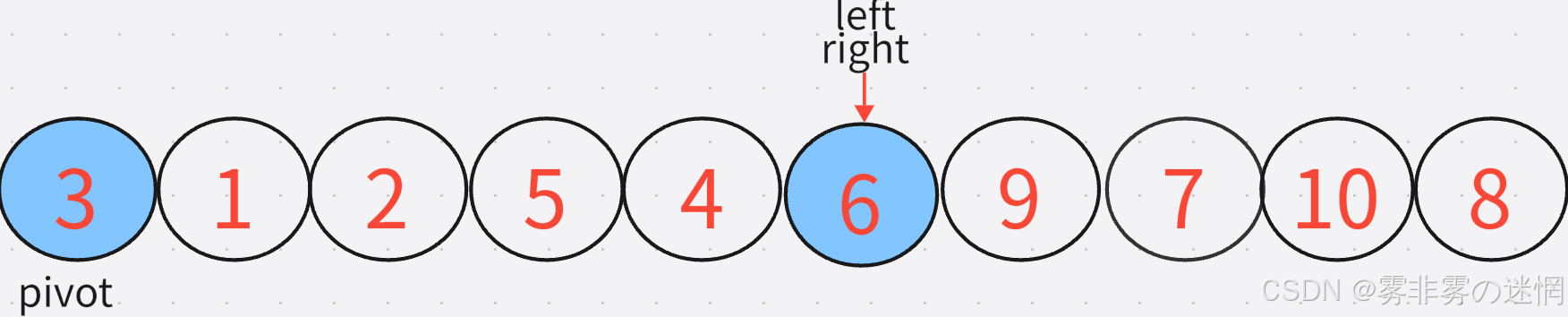
?(6)現在我們把數組分為了兩組,以 6 為分界線,左邊的數字小于等于6,右邊的數字大于等于6
然后我們采用遞歸,兩端采用分組進行Hoare排序,隨著遞歸函數的調用,這兩個組又會分為幾個小組,因此我們必須要弄清楚單趟的思路。注意left、right、pivot需要更新,
通俗理解:理解成數,樹根就是一整個數組,它會分為很多個子數組(這就是對這里分組的理解)

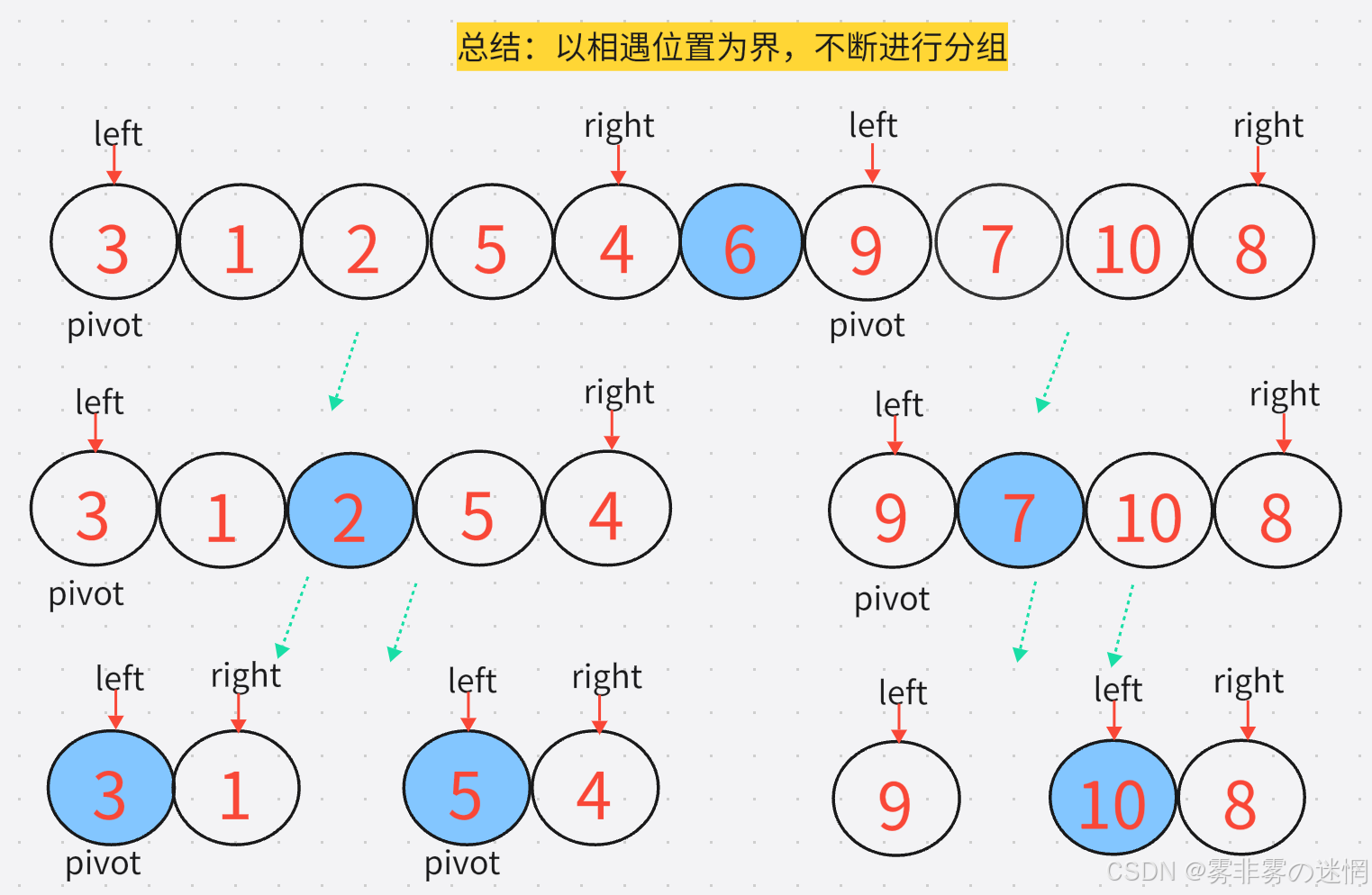
代碼實現:
按照上面的思路,我們先實現單趟,也就是先排序一個元素:(我再強調一下注意點)
(1)pivot 作為下標開始是 left 的位置,這里不要寫死為0,因為我們遞歸是需要靈活變化的,? ? ? ? ? ? ?pivot的開始位置應該是 left 的位置
(2)基準值在左邊,就從右邊開始找;基準值在右邊,就從左邊開始找
(3)大循環條件就是它們相遇停止;下面的兩個子循環:首先判斷大小我就不解釋了,之所以加? ? ? ? ? ?上 left < right ,是因為避免left 與 right 一直走,出界(建議畫圖最好理解)
(4)記得更新相遇位置為新的 pivot
int pivot = left;
//單趟
while (left < right)
{//左邊找大于等于基準值的元素(找大)while (left<right && arr[right]>=arr[pivot]){right--;}//右邊找小于等于基準值的元素(找小)while (left<right && arr[left]<=arr[pivot]){left++;}//找到之后進行交換Exchange(&arr[left], &arr[right]);
}
//交換基準值和相遇的元素
Exchange(&arr[left], &arr[pivot]);
pivot = left;上面我們已經實現了單趟, 下面我們來實現遞歸,這里有2個注意要點:
(1)我們的left--? right++? 每次排序已經移到了一起,但是我們每次遞歸需要從原先的位置開始(這里我不好用語言形容,大家看下面的圖!)所以咱們需要記錄left right的初始位置,每次調用函數可以初始化
(2)我們遞歸需要有結束條件,這個結束條件就是left <= right ,我們循環的條件剛好是left > right,反過來就行!
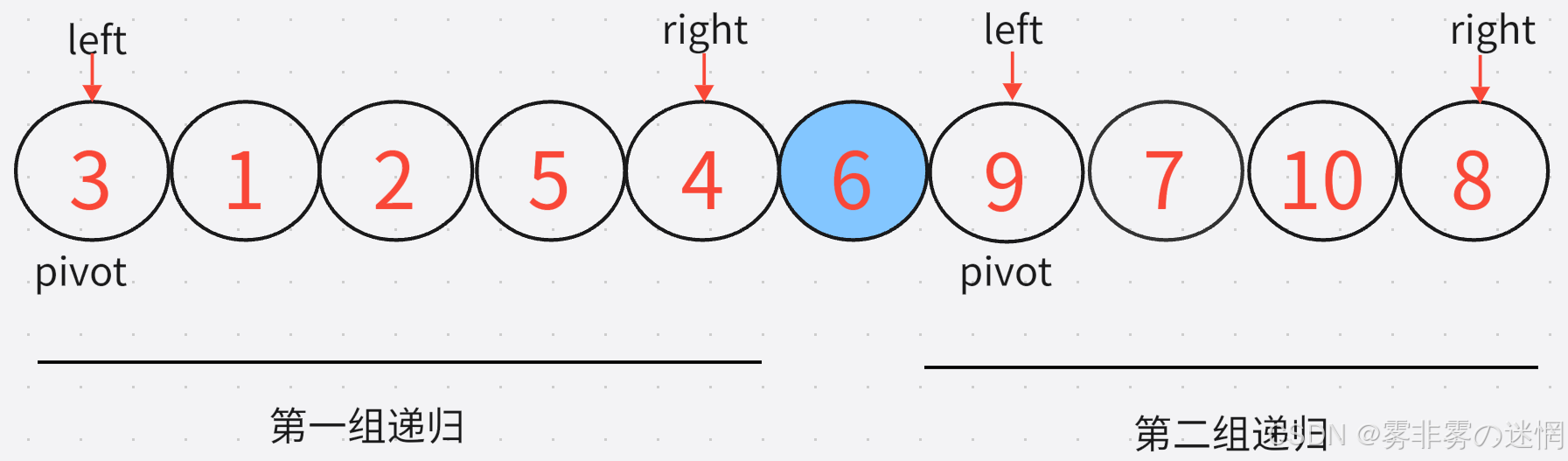
遞歸的實現,我們知道第一組結束之后,我們左邊的分組起始地點是left,末尾是pivot-1;我們右邊的分組初始為pivot+1,末尾是right(如下圖理解)
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 第一次排序結束?

? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?第n次排序開始?

void Hoare(int* arr, int left, int right, int size)
{assert(arr);//遞歸結束if (left >= right){return;}//記錄int begin = left;int end = right;int pivot = left;//單趟......//調用遞歸//左邊Hoare(arr, begin, pivot - 1, size);//右邊 Hoare(arr, pivot + 1, end, size);
}
代碼優化:
首先我們看下面這個問題:
每次選 pivot? 都是選的數組的初始位置,然后不論有序還是無序,每次分區只能減少一個元素,導致遞歸深度為O(n),時間復雜度寫死了為O(n^2)
優化方式:如果我們隨機選擇 pivot?那么可以使得最壞情況發生的概率為 n^2 / 1,從而保證平均時間復雜度為 O(n logn)
解釋:為哈選擇隨機位置之后需要交換 pivot 處的數據與數據開始的位置?
(1)簡化邏輯分區,我們是將基準值的位置作為分區的起點,左分區從【left? ,pivot-1】開始移動,尋找大于等于基準值的元素;右分區從【pivot+1 , right】開始移動,找小于等于基準值的元素
(2)避免額外判斷,如果基準值保留在原位置,分區時需要處理pivot跨越數組界限的問題,交換到初始位置后,分區邏輯只需要關注左右left right的移動
//記錄
int begin = left;
int end = right;//隨機生成下標
int randIndex = left + rand() % (right - left + 1);
//交換生成的下標與數組初始位置
Exchange(&arr[left], &arr[randIndex]);int pivot = left;優缺點分析:
?Hoare排序是一種高效的平均O(n logn )排序算法,原地排序,適合大數據,但是它屬于不穩定排序,未優化之前可能出現O(n^2)的時間復雜度,總的來說優化性能更佳,處理重復元素表現更好
小編寄語
數據排序的精妙還未結束,【上篇】的算法對比【中篇】,難度又提升了!但是小編已經將思路進行了拆分講解,相信看幾遍也可以理解,再也不用擔心自己在哪個細節會犯錯了!隨著難度的升級,【下篇】將更加精彩,是指針排序?還是又是你從未見過的新排序?關注我,帶你揭開【下篇】的面紗!
與 Trunk 端口的區別詳解)
綜述篇)




)

)

(二):雙親委派機制)


Gin后端框架)



)
)
