歡迎關注『youcans論文精讀』系列
本專欄內容和資源同步到 GitHub/youcans
【youcans論文精讀】弱監督深度檢測網絡 WSDDN
- 0. 弱監督檢測的開山之作
- 0.1 論文簡介
- 0.2 WSDNN 的步驟
- 0.3 摘要
- 1. 引言
- 2. 相關工作
- 3. 方法
- 3.1 預訓練網絡
- 3.2 弱監督深度檢測網絡
- 3.3 WSDDN訓練
- 3.4 空間正則化器
- 4. 實驗
- 4.1 基準數據集
- 4.2 實驗設置
- 4.3 檢測結果
- 4.4 分類結果
- 5. 結論
- 6. 參考文獻
弱監督目標檢測(Weakly Supervised Object Detection, WSOD),是指使用少量或不精確的標注數據進行有效的目標檢測。
傳統的目標檢測方法,即強監督學習,依賴于大量精確標注的數據,這在實際應用中往往是昂貴且耗時的。弱監督學習處理的是帶有噪聲或不精確標注的數據。弱監督學習的目標是在標注信息不完整或不精確的情況下,訓練出性能良好的模型。
弱監督目標檢測的挑戰:
- 不精確的標注:WSOD通常使用圖像級別的標注,即只知道圖像中是否包含特定類別的目標,而不知道目標的具體位置。
- 類別不平衡:在實際應用中,數據集中的正樣本(含目標的圖像)和負樣本(不含目標的圖像)可能存在顯著的不平衡。
- 泛化能力:WSOD模型需要能夠泛化到新的、未見過的數據上,即使這些數據的標注信息同樣不精確。
0. 弱監督檢測的開山之作
0.1 論文簡介
弱監督檢測任務(WSD,Weakly Supervised Detection ) 是指僅使用圖像的類別標簽來實現目標檢測任務。
2016年,牛津大學 H. Bilen 等發表論文 “Weakly Supervised Deep Detection Networks(弱監督深度檢測網絡)”,是 弱監督檢測領域 的開山之作。
H. Bilen and A. Vedaldi, “Weakly Supervised Deep Detection Networks,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 2846-2854, doi: 10.1109/CVPR.2016.311.
【論文下載】:ieeexplore, arxiv
【GitHub地址】:Github-wsddn,Github-hbilen

0.2 WSDNN 的步驟
論文提出一種弱監督的深度檢測架構WSDDN,只利用圖像級別的標注,就可以實現區域選擇和分類任務。
WSDDN 分為三步:
- 獲取在 ImageNet 1K 上預訓練的 CNN;
- 構建WSDDN模型;
- 在目標數據集上僅使用圖像級標注訓練/fine-tune WSDDN,達到當時的 state-of-the-art。
0.3 摘要
弱監督目標檢測學習是圖像理解領域的一個重要問題,但目前仍未得到令人滿意的解決方案。
本文通過利用基于大規模圖像分類任務預訓練的深度卷積神經網絡,提出了一種弱監督深度檢測架構。該架構通過改造現有網絡使其在圖像區域層面運作,能夠同步執行區域選擇與分類任務。
雖然以圖像分類器形式進行訓練,但該架構在 PASCAL VOC 數據集上隱含學習到的目標檢測器性能優于其他弱監督檢測系統。這個簡潔優雅的端到端架構在圖像分類任務中也超越了標準數據增強和微調技術的表現。
1. 引言
近年來,卷積神經網絡(CNN)[20]已成為圖像識別領域最先進的深度學習框架。其成功的關鍵在于能夠從海量標注數據中學習真實物體的復雜外觀特征。CNN最引人注目的特性之一,是其學習到的通用視覺特征可遷移至多種任務。特別是基于ImageNet ILSVRC等數據集預訓練的CNN,已在跨領域識別[8]、目標檢測[12]、語義分割[13]、人體姿態估計[31]等任務中展現出卓越性能。
本文探索如何將CNN的強大能力應用于弱監督檢測(WSD)——即僅利用圖像級標簽學習目標檢測器的任務。
弱監督學習能力的重要性體現在兩方面:
首先,圖像理解需要學習日益增長的復雜視覺概念(如ImageNet中數十萬物體類別);
其次,CNN訓練依賴大量數據。
因此,通過輕量級監督學習復雜概念,可顯著降低圖像分割、描述生成或目標檢測等任務的標注成本。
我們的研究基于以下假設:
既然預訓練CNN能出色遷移至眾多任務,其必然蘊含數據的本質表征。
例如,有證據表明[36],圖像分類CNN會隱式學習物體及其部件的代理特征。值得注意的是,這些概念的獲取完全未依賴圖像中目標位置的顯式標注。這意味著,圖像分類CNN可能已隱式包含目標檢測所需的大部分信息。
我們并非首個用CNN解決WSD的研究。Wang等[34]的方法使用預訓練CNN提取區域特征,將物體類別建模為視覺主題。雖然該方法當前代表弱監督檢測的最高水平,但其包含CNN之外的多個組件且需大量調參。
本文提出一種基于預訓練CNN的端到端弱監督目標檢測方法——弱監督深度檢測網絡(WSDDN)(圖1)。
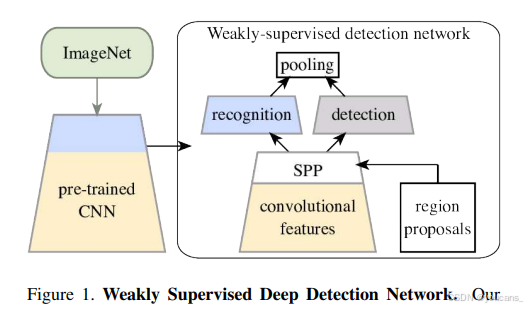
圖1. 弱監督深度檢測網絡。
我們的方法始于在大規模數據集(如ImageNet)上預訓練的圖像分類CNN,通過改造使其能夠高效處理圖像區域,并分支出識別流與檢測流雙路架構。最終形成的網絡僅需圖像級標注即可在目標數據集上微調,實現當前最優的弱監督目標檢測性能。
該方法(第3節)以AlexNet等預訓練網絡為基礎,通過空間金字塔池化層[14,11]高效提取圖像區域描述符 ? ( x ; R ) \phi(x;R) ?(x;R)。網絡隨后分叉為雙流架構:識別流為每個區域生成類別分數φ_c(x;R),檢測流則計算區域概率分布φ_d(x;R)以定位最顯著結構。最終通過聚合區域分數實現圖像級分類,從而注入弱監督信號。
與傳統多示例學習(MIL)[7]相比,我們的方法存在本質差異:MIL使用同一外觀模型交替進行區域選擇與模型更新,而WSDDN通過獨立的檢測分支進行區域選擇,避免了MIL易陷入局部最優的缺陷。
多示例學習(MIL),是一種監督學習的子領域。在 MIL 中,訓練數據被組織成"袋子",每個"袋子"包含多個實例(樣本)。訓練的目標是確定整個"袋子"的標簽(例如,正類或負類),而不是確定單個實例的標簽。
我們的雙流架構與Lin等[21]的"雙線性"網絡存在微弱關聯。雖然兩者都受人類視覺腹側流(識別)與背側流(定位)啟發,但關鍵區別在于:Lin的方案中雙流完全對稱,而我們的檢測分支通過顯式區域比較打破對稱性。此外,Lin的研究未涉及WSD或檢測性能評估。
經上述改造后,網絡僅需圖像級標簽、區域提議和反向傳播即可在目標數據集上微調。第4節實驗表明,在PASCAL VOC數據集上,該架構以純CNN機制實現了當前最優的弱監督檢測性能[34],其訓練測試效率與全監督Fast R-CNN[11]相當。作為副產品,該方法還產生了優于標準微調技術的圖像分類器。第5節將總結這些發現。
2. 相關工作
現有弱監督檢測(WSD)方法大多采用多示例學習(MIL)框架。該框架將圖像視為區域包:若圖像標記為正樣本,則假定至少一個區域緊密包含目標物體;若為負樣本,則所有區域均不包含目標。學習過程交替進行兩個步驟:(1) 基于當前外觀模型從正樣本包中選擇可能包含目標的區域,(2) 根據選定區域更新物體外觀模型。
MIL策略導致非凸優化問題,求解過程易陷入局部最優,解的質量高度依賴初始化。相關研究主要聚焦兩類改進:一是初始化策略優化[18,5,30,4],二是優化問題正則化[29,1]。Kumar等[18]提出自步學習策略,逐步將困難樣本加入初始小規模訓練集;Deselaers等[5]基于物體性評分初始化目標位置;Cinbis等[4]采用訓練數據多重劃分避免局部最優;Song等[29]將Nesterov平滑技術[22]應用于隱變量SVM[10],提升對劣質初始化的魯棒性;Bilen等[1]提出平滑版MIL,通過軟標簽替代硬性選擇最高分區域,并基于對稱性和互斥原則對異常目標位置施加正則約束。
**另一類WSD研究[29,30,34]著眼于圖像部件相似性挖掘。**Song等[29]提出基于判別性圖模型的算法,選擇與正樣本圖像中最近鄰窗口相連的窗口子集;文獻[30]進一步擴展該方法以發現多組共現部件配置;Wang等[34]采用潛在語義分析(pLSA)對正樣本窗口進行迭代聚類,根據分類性能選擇最具判別力的類別簇;Bilen等[2]提出聯合學習框架,通過判別性凸聚類算法同步優化分類模型并保持選定區域相似性。
**近期研究[23,24]探索了無需位置標注的弱監督定位方法以提升CNN分類性能。**Oquab等[23]利用預訓練CNN生成PASCAL VOC圖像的中層表示;后續工作[24]改造CNN架構,在預測標簽時實現目標的粗粒度定位。Jaderberg等[15]提出包含圖像預變換子網絡的CNN架構,該"變換網絡"通過端到端訓練將物體對齊至標準參考系(可視為檢測代理)。
我們的架構包含一種機制預選可能包含對象的圖像區域,也以端到端的方式進行訓練;雖然這看起來可能非常不同,但這種機制也可以被視為學習轉換(將檢測到的區域映射到規范參考系的轉換)。然而,在我們和他們的網絡中,區域預選過程的性質是非常不同的。
3. 方法
本節介紹我們提出的弱監督深度檢測網絡(WSDDN)方法。
整體思路包含三個步驟:
- 首先,獲取在大規模圖像分類任務上預訓練的CNN(第3.1節);
- 其次,通過對該CNN進行架構修改構建WSDDN(第3.2節);
- 最后,在目標數據集上僅使用圖像級標注再次訓練/微調WSDDN(第3.3節)。
本節剩余部分將詳細討論這三個步驟。
3.1 預訓練網絡
我們的方法基于在ImageNet ILSVRC 2012數據集[26]上預訓練的CNN構建,該預訓練過程僅使用圖像級監督(即不包含邊界框標注)。所用CNN架構的具體細節將在第4節說明。
3.2 弱監督深度檢測網絡
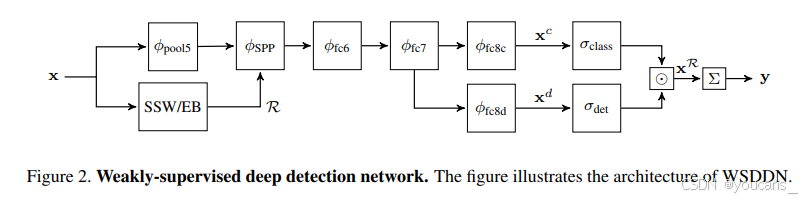
給定預訓練CNN,我們通過引入三個修改將其轉化為WSDDN(另見第3節)。
(1)首先,我們將最后一個卷積塊(通常稱為relu5和pool5)中緊接ReLU層后的最后一個池化層替換為空間金字塔池化(SPP)層[19,14]。這將產生一個以圖像x和區域(邊界框)R作為輸入,并輸出特征向量或表示 ? ( x ; R ) \phi(x; R) ?(x;R) 的函數。重要的是,該函數可分解為:
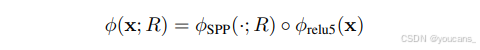
其中 ? r e l u 5 ( x ) \phi_{relu5}(x) ?relu5?(x) 僅需對整個圖像計算一次,而 ? S P P ( ? ; R ) \phi_{SPP}(·; R) ?SPP?(?;R) 對任意給定區域 R 都能快速計算。實際應用中,空間金字塔池化(SPP)被配置為與網絡的首個全連接層(即 fc6)兼容。需要注意的是,如文獻[11]所述,SPP以網絡層的形式實現,從而支持端到端的系統訓練(同時保證效率)。
(2)給定輸入圖像 x,候選目標區域的列表 R = ( R 1 , . . . , R n ) R = (R_1, ..., R_n) R=(R1?,...,Rn?) 通過區域提議機制(RPM)獲得。本實驗采用兩種方法進行測試:選擇性搜索窗口(SSW)[32]和邊緣框(EB)[37]。
參照文獻[11]的方法,我們將 SPP 層修改為可接受整個區域列表 R 作為輸入,而非單一區域;具體而言, ? ( x ; R ) \phi(x; R) ?(x;R) 被定義為沿第四維度拼接的 ? ( x ; R 1 ) , . . . , ? ( x ; R n ) \phi(x; R1), ..., \phi(x; Rn) ?(x;R1),...,?(x;Rn) (因為每個獨立的 ? ( x ; R ) \phi(x; R) ?(x;R)都是三維張量)。
(3)在網絡架構上,區域級特征會繼續由兩個全連接層 ? f c 6 \phi_{fc6} ?fc6? 和 ? f c 7 \phi_{fc7} ?fc7? 進行處理,每個全連接層包含線性映射和 ReLU 激活。從最后一個全連接層的輸出開始,我們分支出兩個數據流,具體描述如下:
-
分類數據流。
第一個數據流通過對各個區域進行分類處理,將其映射為 C維類別分數向量(假設系統被訓練用于檢測C個不同類別)。這是通過計算線性映射 ? f c 8 c \phi_{fc8c} ?fc8c? 實現的,最終生成數據矩陣 x c ∈ R C × ∣ R ∣ x^c \in R^{C×|R|} xc∈RC×∣R∣,其中包含每個區域的類別預測分數。隨后,該矩陣通過 softmax 運算符進行處理,其定義如下:
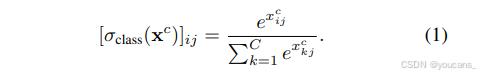
-
檢測數據流。
第二個數據流執行檢測任務,通過對不同區域進行相互比較評分。該過程基于類別特異性實現,通過第二個線性映射 ? f c 8 d \phi_{fc8d} ?fc8d? 計算,同樣生成得分矩陣 x d ∈ R C × ∣ R ∣ x^d \in R^{C×|R|} xd∈RC×∣R∣。隨后該矩陣通過另一個 softmax 運算符處理,其定義如下:

盡管兩個數據流結構高度相似,但分類流中的 σ c l a s s \sigma_{class} σclass? 非線性變換與檢測流中的 σ d e t \sigma_{det} σdet? 非線性變換是關鍵區別,這使得它們分別執行分類和檢測功能。具體而言:在分類流中,softmax 運算符獨立地對每個區域的類別分數進行比較;而在檢測流中,softmax 運算符則獨立地對每個類別下的不同區域分數進行比較。因此,第一分支預測區域所屬類別,第二分支篩選可能包含有效圖像片段的區域。
- 區域分數融合與檢測。
通過兩個評分矩陣的逐元素(Hadamard)乘積 x R = σ c l a s s ( x c ) ⊙ σ d e t ( x d ) x^R = \sigma_{class}(x^c) ⊙ \sigma_{det}(x^d) xR=σclass?(xc)⊙σdet?(xd) 獲得每個區域的最終分數。隨后,這些分數被用于根據目標中心可能性對圖像區域進行排序(每個類別獨立處理),并通過標準非極大值抑制(迭代移除與已選區域交并比 IoU 超過40%的區域)來獲取圖像中各類別的最終檢測結果。
這種雙流分數融合方式與文獻[21]的雙線性網絡相似,但存在三個關鍵差異:首先,不同的 softmax 運算符顯式打破了雙流的對稱性;其次,我們計算的是逐元素乘積 σ c l a s s ( x r c ) ⊙ σ d e t ( x r d ) \sigma_{class}(x^c_r)⊙ \sigma_{det}(x^d_r) σclass?(xrc?)⊙σdet?(xrd?) 而非外積 σ c l a s s ( x r c ) ? σ d e t ( x r d ) \sigma_{class}(x^c_r)? \sigma_{det}(x^d_r) σclass?(xrc?)?σdet?(xrd?)(參數數量呈平方級減少);第三,分數計算針對特定圖像區域 r 而非固定網格位置。這些差異使得我們可以明確解釋 σ d e t ( x d ) \sigma_{det}(x^d) σdet?(xd) 為區域排序項, σ c l a s s ( x c ) \sigma_{class}(x^c) σclass?(xc) 為類別排序項,而文獻[21]中雙流的功能界定則較為模糊。
- 圖像級分類分數。
至此,WSDDN已計算出區域級分數 x R x^R xR 。通過對區域分數求和,可將其轉化為圖像級類別預測分數:
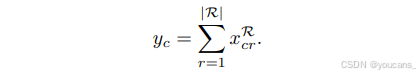
需要注意的是, y c y_c yc? 是經過 softmax 歸一化分數在 ∣ R ∣ |R| ∣R∣ 個區域上的逐元素乘積之和,因此其取值范圍為 (0,1)。在此階段不執行 softmax 運算,因為圖像可能包含多個物體類別(而單個區域應僅包含一個類別)。
3.3 WSDDN訓練
前文已闡述WSDDN架構,本節說明模型訓練方法。訓練數據為圖像集合 x i ( i = 1 , . . . , n ) x_i (i=1,...,n) xi?(i=1,...,n) 及其圖像級標簽 y i ∈ { ? 1 , 1 } C y_i \in \{-1,1\}^C yi?∈{?1,1}C。定義 ? y ( x ∣ w ) \phi^y(x|w) ?y(x∣w) 為完整架構,將圖像 x 映射為類別分數向量 y ∈ R C y \in R^C y∈RC,其中參數 w 包含卷積層和全連接層所有濾波器系數與偏置項。
采用帶動量的隨機梯度下降法優化能量函數:
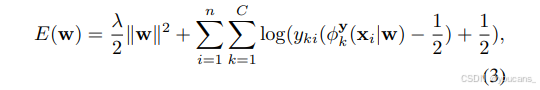
該式優化 C 個二元對數損失項之和(每個類別對應一項)。由于 ? k y ( x i ∣ w ) ∈ ( 0 , 1 ) \phi^y_k(x_i|w) \in (0,1) ?ky?(xi?∣w)∈(0,1),可視為圖像 x i x_i xi? 中存在類別 k 的概率 p ( y k i = 1 ) p(y_{ki}=1) p(yki?=1)。當真實標簽為正值時,二元對數損失為 l o g ( p ( y k i = 1 ) ) log(p(y_{ki}=1)) log(p(yki?=1));負值時則為 l o g ( 1 ? p ( y k i = 1 ) ) log(1-p(y_{ki}=1)) log(1?p(yki?=1))。
3.4 空間正則化器
WSDDN 針對圖像級類別標簽優化,無法保證空間平滑性(即高分區域相鄰重疊區域也應獲得高分)。全監督檢測中,Fast-RCNN[11]將與真實框 IoU≥50% 的區域提案作為正樣本,并學習回歸至對應真實邊界框。由于本方法無法獲取真實框,我們采用軟正則化策略:在訓練期間懲罰 fc7 層特征圖中最高分區域與IoU≥60% 區域(即 KaTeX parse error: Unknown accent ' ?' at position 8: r \in |R???|)的差異:
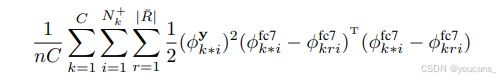
其中 N k + N^+_k Nk+?為類別 k 的正樣本圖像數, ? = a r g m a x r ? k r i y *=argmax_r \phi^y_{kri} ?=argmaxr??kriy? 表示類別 k 在圖像 i 中的最高分區域。將此正則項加入公式(3) 的成本函數。
4. 實驗
本節我們將對WSDDN及其各組件在弱監督目標檢測和圖像分類任務上進行全面實驗驗證。
4.1 基準數據集
我們在 PASCAL VOC 2007 和 2010 數據集[9]上評估方法性能,這兩個數據集是弱監督目標檢測領域最廣泛使用的基準。VOC 2007 數據集包含2501張訓練圖像、2510張驗證圖像和5011張測試圖像,涵蓋20個物體類別的邊界框標注;VOC 2010 數據集則包含4998張訓練圖像、5105張驗證圖像和9637張測試圖像,類別數量相同。實驗采用官方推薦的訓練/驗證集劃分方案,所有結果均在測試集上報告。我們同時評估了方法在PASCAL VOC目標檢測和圖像分類兩個任務上的表現。
-
針對檢測任務,我們采用兩種性能指標:遵循標準PASCAL VOC協議,以檢測框與真實框的交并比(IoU)達到50%時的平均精度(AP)作為主要指標;同時報告弱監督檢測常用指標CorLoc[6],該指標表示在包含目標類別的圖像中,置信度最高的檢測框與任一真實實例IoU≥50%的圖像占比。需注意的是,AP在PASCAL測試集上計算,而CorLoc則在訓練集與驗證集的聯合集上評估。
-
對于分類任務,我們采用標準PASCAL VOC協議報告AP值。
4.2 實驗設置
我們參照文獻[11]的方法,采用三種預訓練CNN模型進行全面評估:
- VGG-CNN-F[3](記為S-小型網絡):結構與AlexNet[17]類似,但減少了卷積濾波器數量;
- VGG-CNN-M-1024(記為M-中型網絡):深度與S相同,但第一卷積層步長更小;
- VGG-VD16[28](記為L-大型網絡):深層架構。
這些模型在ImageNet ILSVRC 2012[26]上預訓練(未使用邊界框信息),單中心裁剪的top-5準確率分別為18.8%、16.1%和9.9%。
根據第3.1節所述,我們對網絡進行以下改造:
- 將最后池化層pool5替換為與首全連接層兼容的SPP層[14];
- 在分類分支旁添加并行檢測分支(含全連接層+softmax層);
- 通過逐元素乘積融合雙流分數后跨區域求和,輸入二元對數損失層。
(注:該層同時評估20個類別,但每個類別作為獨立二分類問題處理,以適配PASCAL VOC的多標簽特性)
WSDDN模型在PASCAL VOC訓練集和驗證集上進行全層微調訓練,這是一種被廣泛采用的提升CNN在目標領域性能的技術[3]。在本研究中,微調發揮著學習分類流和檢測流的關鍵功能,使得網絡能夠僅通過弱圖像級監督就有效地學習目標檢測。分20個epoch訓練,前10個 epoch學習率 1 0 ? 5 10^-5 10?5,后10個epoch 降為 1 0 ? 6 10^-6 10?6。每個 minibatch 包含單張圖像的所有區域提案。
為了生成與我們的網絡配合使用的候選區域,我們評估了兩種區域提議方法:使用快速配置的選擇性搜索窗口(SSW)[32]和邊緣框(EB)[37]。除了區域提議外,EB還基于完全包圍的輪廓數量為每個區域提供物體性評分。我們通過WSDDN中的縮放層將特征圖 ? S P P \phi_{SPP} ?SPP? 與其評分按比例相乘來利用這一額外信息,并將此配置標記為 B o x S c Box Sc BoxSc。由于我們使用SPP層來聚合每個區域的描述符,圖像不需要像原始預訓練模型那樣調整為特定尺寸。相反,我們保持圖像的原始長寬比不變,并按照[14]的方法將它們縮放到五種不同尺寸(將其寬度或高度的最大值分別設置為{480, 576, 688, 864, 1200})。在訓練期間,我們對圖像應用隨機水平翻轉并隨機選擇一個尺寸作為抖動或數據增強的形式。在測試時,我們對10張圖像(即5種尺寸及其翻轉版本)的輸出取平均。我們使用公開可用的CNN工具箱MatConvNet[33]進行實驗,并共享我們的代碼、模型和數據【1】(https://github.com/hbilen/WSDDN)。
當對圖像進行評估時,WSDDN會為每個目標類別 c 和圖像 x 生成:
- 每個類別c的區域級分數 x r R = S c ( x ; r ) x^R_r = S_c(x; r) xrR?=Sc?(x;r)
- 圖像級聚合分數 y c = S c ( x ) y_c = S_c(x) yc?=Sc?(x)。
應用40% IoU閾值的非極大值抑制后,綜合計算檢測AP與CorLoc指標。
(實現基于MatConvNet工具箱[33],代碼與模型已開源)
4.3 檢測結果
基準方法。
我們首先設計了一個單流分類-檢測網絡作為WSDDN的對比基線。該架構部分設計與WSDDN相似——我們將VGG-CNN-F模型的 pool5 層替換為SPP層。但不同之處在于,我們沒有分支出雙數據流,而是直接在最后一個全連接層( ? f c 8 c \phi_{fc8c} ?fc8c?)后添加了以下損失層:

其中 l o g ∑ r = 1 ∣ R ∣ e x p ( x c r R ) log∑^{|R|}_{r=1} exp(x^R_{cr}) log∑r=1∣R∣?exp(xcrR?)項是 m a x r x c r R max_r x^R_{cr} maxr?xcrR?運算符的軟近似,實驗表明其性能優于直接使用最高分區域。該現象在文獻[1]中也有報道。需要注意的是,此非線性變換必不可少,否則基于區域的分數聚合將會累加大量無信息區域的分數。該損失函數仍是C個二元鉸鏈損失之和(每個類別對應一個)。該基線方法在PASCAL VOC測試集上獲得21.6%的mAP檢測分數,遠低于當前最優水平(文獻[34]中的31.6%)。
預訓練CNN架構評估。
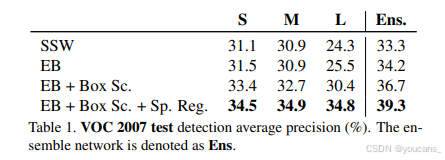
我們采用S、M、L三種模型評估方法性能,并通過簡單平均分數的方式報告模型集成結果。表1顯示,單獨使用S和M模型的WSDDN已達到當前最優方法[34]的水平,而模型集成在VOC 2007數據集上超越了此前最佳成績。與全監督檢測方法(如[11])不同,WSDDN的檢測性能并未隨網絡寬度或深度增加而提升。相反,L模型表現顯著遜于S和M模型(見表1),這源于L模型更傾向于聚焦物體局部而非整體實例——由于其更小的卷積步長、更高分辨率和更深層架構,仍能將局部特征與物體類別關聯。
物體提議方法比較。
我們進一步比較兩種主流物體提議方法SSW[32]和EB[37]的檢測性能。雖然兩種區域提議質量相當,但利用EB的邊界框分數(表1中記為Box Sc)使S/M模型提升2%mAP,L模型提升達5%。
空間正則化效果。
我們標注了引入額外空間正則項的訓練設置(表1中記為Sp. Reg.)。最終,該正則化使S/M/L模型分別獲得1、2、4個mAP點的提升。這些改進表明,較大網絡能從高置信度區域的空間不變性約束中獲得更大收益。
與現有技術的比較。
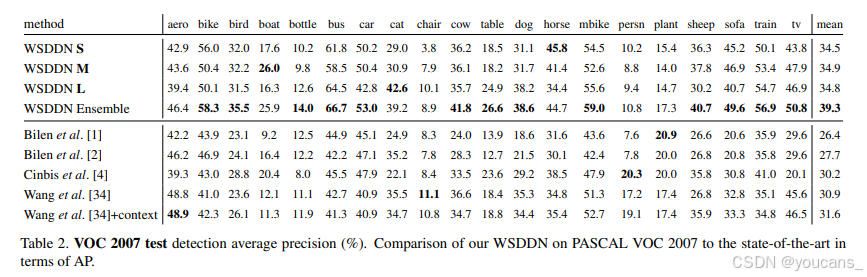
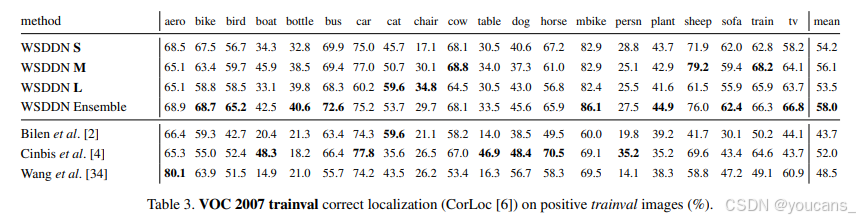
在完成設計決策評估后,我們采用最佳配置(表1最后一行),分別在表2和表3(VOC 2007數據集)以及表5和表6(VOC 2010數據集)中將WSDDN與弱監督檢測領域的先進方法進行對比。結果表明,我們的方法在使用單一模型時已顯著優于現有方案,而模型集成進一步提升了性能。多數前人研究[29,30,1,35,2]將Caffe參考CNN模型[16](相當于本文的S模型)作為黑盒特征提取器處理SSW提議。Cinbis等[4]除CNN特征外,還結合了Fisher向量[25]及Zitnick與Dollar的EB物體性度量[37]。與這些工作不同,WSDDN僅通過對原始CNN架構進行簡單修改,并基于目標數據通過反向傳播微調實現。
進一步分析實驗結果可見,雖然我們的方法在大多數類別上顯著領先,但在椅子、人物和盆栽植物類別表現稍遜。圖3展示了典型失敗與成功案例。值得注意的是,當前系統最主要的失敗模式是將物體局部(如人臉)誤檢為整體目標。這源于"人臉"等局部特征通常具有更強的判別性且外觀變化較小。需說明,這種失敗模式的根本原因在于我們與多數研究者相同,將物體定義為對給定類別最具預測性的圖像區域——這些區域可能不包含完整物體。解決該問題需要在模型中引入額外線索以學習"整體物體"概念。
我們的模型輸出也可作為現有弱監督檢測方法的輸入(這些方法將CNN作為黑盒特征提取器)。該方向的探索將留待未來工作。

4.4 分類結果
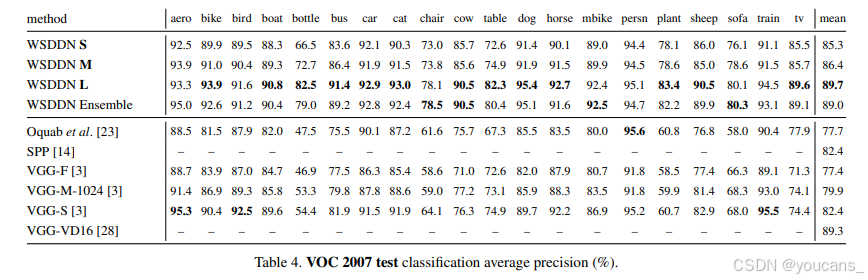
盡管WSDDN主要針對弱監督目標檢測設計,但其最終通過圖像分類任務進行訓練。因此,評估其分類性能也具有重要意義。我們在PASCAL VOC 2007基準測試中,將WSDDN與CNN常用的標準微調技術進行對比(結果見表6)。文獻[3,14,23]已對這些技術進行過深入研究:Chatfield等[3]特別分析了包括擴展數據增強在內的多種微調變體,實驗采用VGG-F、VGG-M和VGG-S三種架構——其中VGG-F速度最快,另兩個網絡較慢但更精確。如4.2節所述,我們分別用預訓練的VGG-F和VGG-M-1024初始化WSDDN S/M,因此它們應視為合理基線。實驗表明,WSDDN S/M相較對應基線分別提升8分和7分。
我們還對比了采用4級空間金字塔池化{6×6,3×3,2×2,1×1}的SPP-net[14](基于Overfeat-7[27]的全監督檢測框架)。雖然未進行微調,但其空間池化層在PASCAL VOC 2007分類任務中達到82.4%的最佳性能。最后,WSDDN L與高性能VGG-VD16[28]對比——后者同樣通過多位置多尺度的全連接層激活聚合來利用粗粒度局部信息。值得注意的是,WSDDN L以0.4個百分點的優勢超越這一強勁基線。

5. 結論
本文提出了WSDDN——通過對預訓練圖像分類CNN進行簡單改造,使其能夠執行弱監督檢測任務。該方法僅需通過反向傳播、區域提議和圖像級標簽在目標數據集上微調,即可顯著超越現有弱監督檢測方法的性能。由于基于SPP層實現,其在訓練和測試階段均保持高效。實驗還表明,在圖像分類任務中,WSDDN對預訓練CNN的性能提升優于傳統微調技術。
我們指出,將物體局部誤檢為整體是該方法的典型失敗模式,這影響了特定類別的檢測性能。經分析,該問題源于當前物體識別的主要判定標準(即選擇高區分度的圖像區域)。目前,我們正在探索能夠促進完整物體檢測的互補線索。
6. 參考文獻
[1] H. Bilen, M. Pedersoli, and T. Tuytelaars. Weakly supervised object detection with posterior regularization. In Proc.
BMVC., 2014.
[2] H. Bilen, M. Pedersoli, and T. Tuytelaars. Weakly supervised object detection with convex clustering. In Proc. CVPR,
2015.
[3] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC., 2014.
[4] R. G. Cinbis, J. Verbeek, and C. Schmid. Weakly supervised object localization with multi-fold multiple instance learning. arXiv preprint arXiv:1503.00949, 2015.
[5] T. Deselaers, B. Alexe, and V. Ferrari. Localizing objectswhile learning their appearance. In Proc. ECCV, pages 452–466, 2010.
[6] T. Deselaers, B. Alexe, and V. Ferrari. Weakly supervised localization and learning with generic knowledge. IJCV, 100(3):275–293, 2012.
[7] T. G. Dietterich, R. H. Lathrop, and T. Lozano-Perez. Solving the multiple instance problem with axis-parallel rectangles. Artificial Intelligence, 89(1-2):31–71, 1997.
[8] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang,E. Tzeng, and T. Darrell. Decaf: A deep convolutional
activation feature for generic visual recognition. CoRR, abs/1310.1531, 2013.
[9] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes (VOC) challenge. IJCV, 88(2):303–338, 2010.
[10] P. F. Felzenszwalb, R. B. Grishick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part
based models. IEEE PAMI, 2010.
[11] R. Girshick. Fast r-cnn. In Proc. ICCV, 2015.
[12] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic
segmentation. In Proc. CVPR, 2014.
[13] B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. Simul-taneous detection and segmentation. In Proc. ECCV, pages
297–312, 2014.
[14] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In
Proc. ECCV, pages 346–361, 2014.
[15] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. 2015.
[16] Y. Jia. Caffe: An open source convolutional architecture for fast feature embedding. http://caffe.berkeleyvision.org/, 2013.
[17] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In
NIPS, pages 1106–1114, 2012.
[18] M. P. Kumar, B. Packer, and D. Koller. Self-paced learning for latent variable models. In NIPS, pages 1189–1197, 2010.
[19] S. Lazebnik, C. Schmid, and J. Ponce. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural
Scene Categories. In Proc. CVPR, 2006.
[20] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation
applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
[21] T. J. Lin, A. RoyChowdhury, and S. Maji. Bilinear cnn models for fine-grained visual recognition. In Proc. ICCV, 2015.
[22] Y. Nesterov. Smooth minimization of non-smooth functions. Mathematical programming, 103(1):127–152, 2005.
[23] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks. In Proc. CVPR, 2014.
[24] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Is object localization for free?–weakly-supervised learning with convolutional neural networks. In CVPR, pages 685–694, 2015.
[25] F. Perronnin, J. Sanchez, and T. Mensink. Improving the Fisher kernel for large-scale image classification. In Proc.
ECCV, 2010.
[26] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, S. Huang, A. Karpathy, A. Khosla, M. Bernstein,
A. Berg, and F. Li. Imagenet large scale visual recognition challenge. IJCV, 2015.
[27] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization
and detection using convolutional networks. arXiv preprint arXiv:1312.6229, 2013.
[28] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In International
Conference on Learning Representations, 2015.
[29] H. O. Song, R. Girshick, S. Jegelka, J. Mairal, Z. Harchaoui, and T. Darrell. On learning to localize objects with minimal supervision. In Proc. ICML, pages 1611–1619, 2014.
[30] H. O. Song, Y. J. Lee, S. Jegelka, and T. Darrell. Weaklysupervised discovery of visual pattern configurations. In
NIPS, pages 1637–1645, 2014.
[31] A. Toshev and C. Szegedy. DeepPose: Human pose estimation via deep neural networks. arXiv preprint arXiv:1312.4659, 2013.
[32] K. van de Sande, J. Uijlings, T. Gevers, and A. Smeulders. Segmentation as selective search for object recognition. In Proc. ICCV, 2011.
[33] A. Vedaldi and K. Lenc. Matconvnet – convolutional neural networks for matlab. In Proceeding of the ACM Int. Conf. on
Multimedia, 2015.
[34] C. Wang, W. Ren, K. H., and T. Tan. Weakly supervised object localization with latent category learning. In Proc.ECCV, volume 8694, pages 431–445, 2014.
[35] J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang, J. Philbin, B. Chen, and Y. Wu. Learning fine-grained image similarity with deep ranking. In Proc. CVPR, 2014.
[36] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Object detectors emerge in deep scene CNNs. In ICLR, 2015.
[37] C. L. Zitnick and P. Dollar. Edge boxes: Locating object proposals from edges. In Proc. ECCV, pages 391–405, 2014.
【本節完】
版權聲明:
歡迎關注『youcans論文精讀』系列
轉發請注明原文鏈接:
【youcans論文精讀】弱監督深度檢測網絡(Weakly Supervised Deep Detection Networks)
Copyright 2025 youcans, XIDIAN
Crated:2025-04

(二):雙親委派機制)


Gin后端框架)



)
)



.getDecorView().setSystemUiVisibility(...)設置狀態欄屬性)





基礎語法)