原創?快樂王子HP?快樂王子AI說?2025年04月03日 23:54?廣東
前面安裝了vscode[1]同時也安裝了Coninue的相關插件[2],現在想用它們來閱讀一下open-r1項目的代碼[3]。
首先,從啟動訓練開始(以GRPO為例子)
第一步,使用TRL的vLLM后端
CUDA_VISIBLE_DEVICES=0?trl vllm-serve --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B第二步,啟動GRPO
CUDA_VISIBLE_DEVICES=1,2,3,4,5,6,7?ACCELERATE_LOG_LEVEL=info \ ? ? accelerate launch --config_file recipes/accelerate_configs/zero2.yaml --num_processes?7?\ ? ? src/open_r1/grpo.py --config recipes/DeepSeek-R1-Distill-Qwen-1.5B/grpo/config_demo.yaml查看vllm的服務啟動幫助文檔
usage: trl vllm-serve?[-h] --model MODEL [--revision REVISION] [--tensor_parallel_size TENSOR_PARALLEL_SIZE] [--host HOST] [--port PORT] [--gpu_memory_utilization GPU_MEMORY_UTILIZATION] [--dtype DTYPE] ? ? ? ? ? ? ? ? ? ? ? [--max_model_len MAX_MODEL_LEN] [--enable_prefix_caching ENABLE_PREFIX_CACHING]關于zero2.yaml文件
(https://github.com/huggingface/open-r1/blob/main/recipes/accelerate_configs/zero2.yaml)
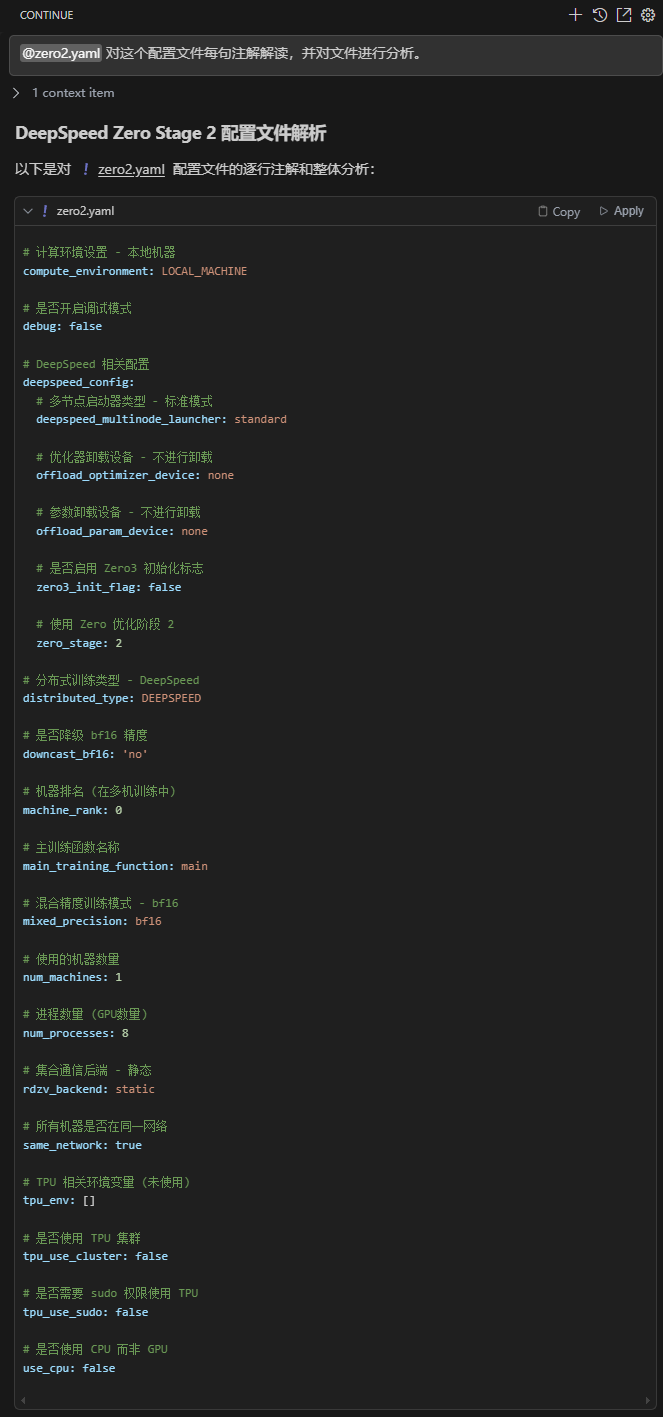
1.核心配置:? ? - 使用 DeepSpeed 的 Zero Stage 2 優化 (zero_stage: 2)? ? - 混合精度訓練采用 bf16 (mixed_precision: bf16)? ? - 單機 8 GPU 訓練 (num_machines: 1, num_processes: 8)2.Zero Stage 2 特點:? ? - 優化器狀態分區,減少內存占用? ? - 沒有啟用參數或優化器卸載 (offload_optimizer_device: none, offload_param_device: none)? ? - 比 Stage 3 內存效率稍低,但通信開銷更小3.硬件配置:? ? - 純 GPU 訓練 (use_cpu: false)? ? - 不涉及 TPU (tpu_* 相關配置均為 false)? ? - 適合具有 8 個 GPU 的單個節點4.使用場景:? ? - 中等規模模型訓練? ? - 當 GPU 內存足夠容納模型參數和激活值時? ? - 需要比 Zero Stage 1 更高的內存效率,但不想承受 Stage 3 的通信開銷5.性能考慮:? ? - bf16 混合精度可以在支持它的硬件上提供良好的訓練速度和內存效率? ? - 8 個 GPU 的配置適合大多數單節點服務器這個配置文件適合在單個多 GPU 節點上訓練中等規模模型,在內存效率和通信開銷之間取得平衡。
recipes/DeepSeek-R1-Distill-Qwen-1.5B/grpo/config_demo.yaml文件分析
(https://github.com/huggingface/open-r1/blob/main/recipes/DeepSeek-R1-Distill-Qwen-1.5B/grpo/config_demo.yaml)
1.模型架構:? - 基于1.5B參數的蒸餾版Qwen模型? - 使用Flash Attention 2優化注意力計算? - bfloat16混合精度訓練2.訓練策略:? - 采用GRPO(可能是一種強化學習優化算法)訓練方法? - 結合三種獎勵函數:準確性、格式正確性和標簽計數? - 使用vLLM加速推理過程3.數據處理:? - 專門設計的復雜對話模板? - 數學領域專用數據集(OpenR1-Math-220k)? - 要求模型以和標簽分步輸出4.資源利用:? - 梯度檢查點和梯度累積優化顯存使用? - 適中的batch size(16)和上下文長度(512/2048)5.監控與部署:? - 完整的訓練日志記錄(W&B)? - 模型自動推送至HuggingFace Hub? - 嚴格的模型保存策略
grpo.py文件
(https://github.com/huggingface/open-r1/blob/main/src/open_r1/grpo.py)
```mermaidgraph?TD? ??A[開始]?-->?B[設置隨機種子]? ??B?--> C[配置日志系統]? ? C --> D[檢查檢查點]? ? D --> E[初始化WandB]? ? E --> F[加載數據集]? ? F --> G[加載tokenizer]? ? G --> H[獲取獎勵函數]? ? H -->?I[格式化對話數據]? ??I?--> J[初始化模型參數]? ? J --> K[創建GRPOTrainer]? ? K --> L{是否有檢查點?}? ? L -- 是 --> M[從檢查點恢復訓練]? ? L -- 否 --> N[開始新訓練]? ? M --> O[訓練模型]? ? N --> O? ? O -->?P[保存模型和指標]? ??P?-->?Q{是否評估?}? ??Q?-- 是 --> R[執行評估]? ??Q?-- 否 --> S? ? R --> S[保存評估結果]? ? S --> T{是否推送至Hub?}? ? T -- 是 --> U[推送模型]? ? T -- 否 --> V[結束]? ? U --> V```
rewards.py
(https://github.com/huggingface/open-r1/blob/main/src/open_r1/rewards.py)
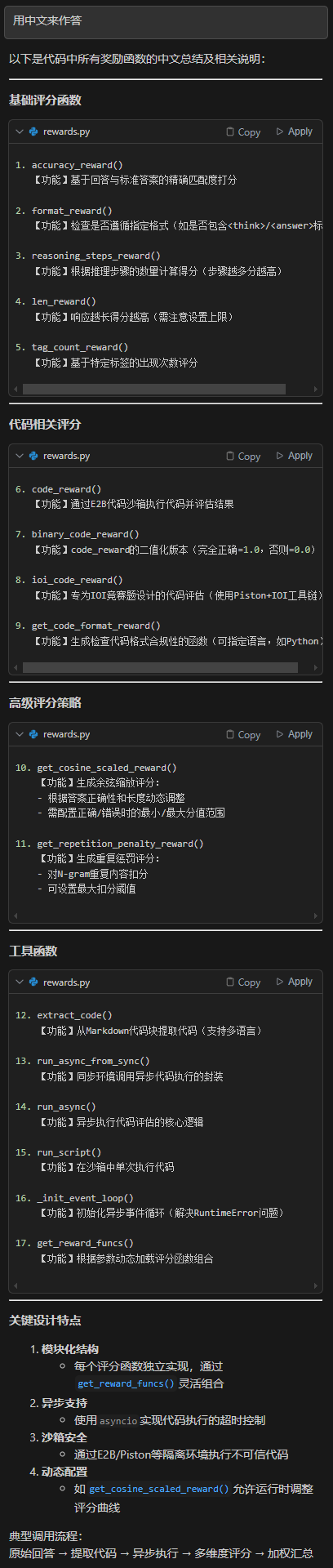
結合醫學場景來探索

def?medical_accuracy_reward(response:?str, golden_answer:?str) ->?float:? ??"""評估醫學準確性,需要與標準醫學答案對比"""? ??# 這里可以集成醫學知識庫或NLP模型進行專業評估? ? medical_terms_score = calculate_medical_terms_match(response, golden_answer)? ? treatment_score = evaluate_treatment_correctness(response, golden_answer)? ??return?0.6?* medical_terms_score +?0.4?* treatment_scoredef?safety_reward(response:?str) ->?float:? ??"""安全性評估:檢查是否有危險建議"""? ? dangerous_keywords = ["自行停藥",?"未經醫生",?"高劑量",?"隨意服用"]? ??for?keyword?in?dangerous_keywords:? ? ? ??if?keyword?in?response:? ? ? ? ? ??return?0.0??# 發現危險建議直接0分? ??return?1.0def?citation_reward(response:?str) ->?float:? ??"""參考文獻引用評估"""? ? citation_formats = ["[1]",?"(Smith et al., 2020)",?"根據最新指南"]? ??return?1.0?if?any(fmt?in?response?for?fmt?in?citation_formats)?else?0.5def?patient_language_reward(response:?str) ->?float:? ??"""患者友好語言評估"""? ? complex_terms = ["病理學",?"分子機制",?"流行病學"]? ? simplified_explanations = ["簡單說",?"通俗理解",?"換句話說"]? ??? ? complex_count =?sum(term?in?response?for?term?in?complex_terms)? ? simple_count =?sum(term?in?response?for?term?in?simplified_explanations)? ??? ??if?complex_count ==?0:?? ? ? ??return?1.0? ??return?simple_count / (complex_count +?1) ?# 確保至少解釋了部分復雜術語def?empathy_reward(response:?str) ->?float:? ??"""同理心評估"""? ? empathy_keywords = ["理解您",?"不用擔心",?"建議咨詢",?"我們會幫助"]? ??return?min(1.0,?0.2?*?sum(kw?in?response?for?kw?in?empathy_keywords))
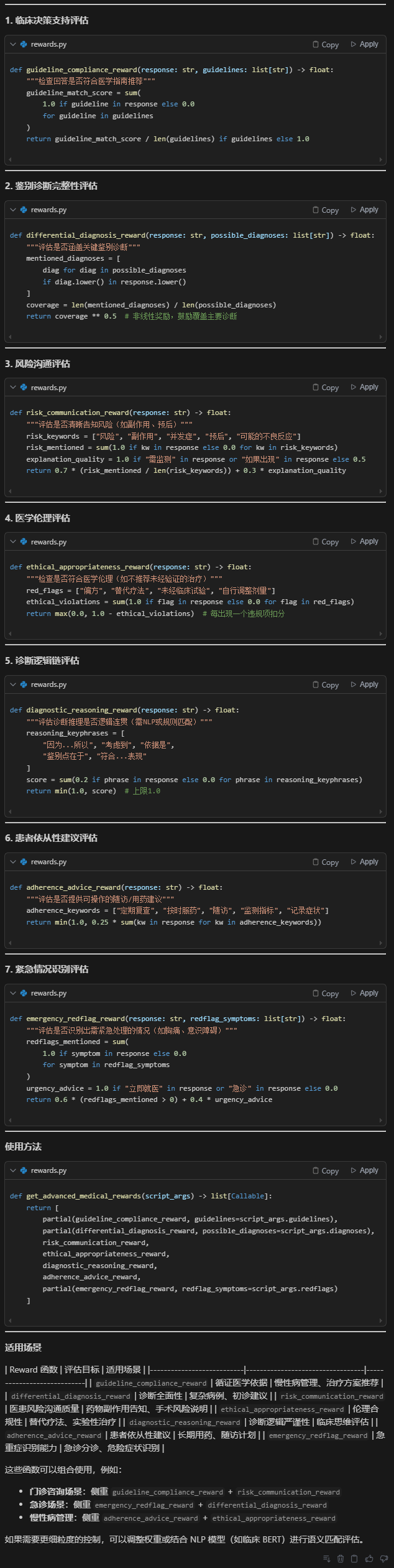
參考:
[1]vscode安裝:https://mp.weixin.qq.com/s/FvqSUrJFFXSVxFpZ6Q2-jg
[2]vscode上安裝Coninue的相關插件:
https://mp.weixin.qq.com/s/cD-BHkCWQxfeedL3eboaBA
[3]open-r1項目:https://mp.weixin.qq.com/s/BDDUe1RyIVutucUVA9Yuzg,https://github.com/huggingface/open-r1]
(二):雙親委派機制)


Gin后端框架)



)
)



.getDecorView().setSystemUiVisibility(...)設置狀態欄屬性)





基礎語法)
