一、基礎教程
創建項目命令
?scrapy startproject mySpider --項目名稱
創建爬蟲文件?
scrapy genspider itcast "itcast.cn"? --自動生成?itcast.py? 文件
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?爬蟲名稱 爬蟲網址
運行爬蟲
scrapy crawl baidu(爬蟲名)?
使用終端運行太麻煩了,而且不能提取數據,
我們一個寫一個run文件作為程序的入口,splite是必須寫的,
目的是把字符串轉為列表形式,第一個參數是scrapy,第二個crawl,第三個baidu
?
from scrapy import cmdlinecmdline.execute('scrapy crawl baidu'.split())
創建后目錄大致頁如下
|-ProjectName ? ? ? ? ? ? ?#項目文件夾
? ?|-ProjectName ? ? ? ? ? #項目目錄
? ? ? |-items.py ? ? ? ? ? ? ? #定義數據結構
? ? ? |-middlewares.py ? ?#中間件
? ? ? |-pipelines.py ? ? ? ? ?#數據處理
? ? ? |-settings.py ? ? ? ? ? ?#全局配置
? ? ? |-spiders ? ? ? ? ? ? ??
? ? ? ? ? |-__init__.py ? ? ? #爬蟲文件
? ? ? ? ? |-itcast.py? ? ? ? ? ?#爬蟲文件??
? ?|-scrapy.cfg ? ? ? ? ? ? ? #項目基本配置文件
全局項目配置文件?settings.py?
- BOT_NAME:項目名
- USER_AGENT:默認是注釋的,這個東西非常重要,如果不寫很容易被判斷為電腦,簡單點洗一個Mozilla/5.0即可
- ROBOTSTXT_OBEY:是否遵循機器人協議,默認是true,需要改為false,否則很多東西爬不了
- CONCURRENT_REQUESTS:最大并發數,很好理解,就是同時允許開啟多少個爬蟲線程
- DOWNLOAD_DELAY:下載延遲時間,單位是秒,控制爬蟲爬取的頻率,根據你的項目調整,不要太快也不要太慢,默認是3秒,即爬一個停3秒,設置為1秒性價比較高,如果要爬取的文件較多,寫零點幾秒也行
- COOKIES_ENABLED:是否保存COOKIES,默認關閉,開機可以記錄爬取過程中的COKIE,非常好用的一個參數
- DEFAULT_REQUEST_HEADERS:默認請求頭,上面寫了一個USER_AGENT,其實這個東西就是放在請求頭里面的,這個東西可以根據你爬取的內容做相應設置。
ITEM_PIPELINES:項目管道,300為優先級,越低越爬取的優先度越高
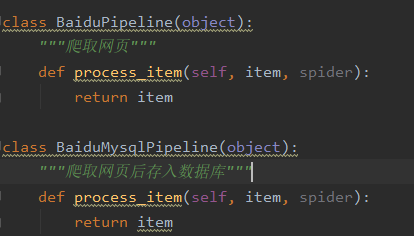
?比如我的pipelines.py里面寫了兩個管道,一個爬取網頁的管道,一個存數據庫的管道,我調整了他們的優先級,如果有爬蟲數據,優先執行存庫操作。
ITEM_PIPELINES = {'scrapyP1.pipelines.BaiduPipeline': 300,'scrapyP1.pipelines.BaiduMysqlPipeline': 200, }
二、案例:豆瓣電影
1. item.py 數據信息類
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass GoogleTrendsCrawlerItem(scrapy.Item):passclass doubanitem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field() #電影名稱genre = scrapy.Field() #電影評分# pass
douban.py 爬取信息文件
import scrapy
from ..items import doubanitemclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['douban.com']start_urls = ['https://movie.douban.com/top250?start={}&filter=']def start_requests(self):for i in range(0, 121, 25):url = self.url.format(i)yield scrapy.Request(url=url,callback=self.parse)def parse(self, response):items = doubanitem()movies = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li')for movie in movies:items["title"] = movie.xpath('./div/div[2]/div[1]/a/span[1]/text()').extract_first()items["genre"] = movie.xpath('./div/div[2]/div[2]/div/span[2]/text()').extract_first()# 調用yield把控制權給管道,管道拿到處理后return返回,又回到該程序。這是對第一個yield的解釋yield items
pipelines.py? 處理提取的數據,如存數據庫
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
# useful for handling different item types with a single interface
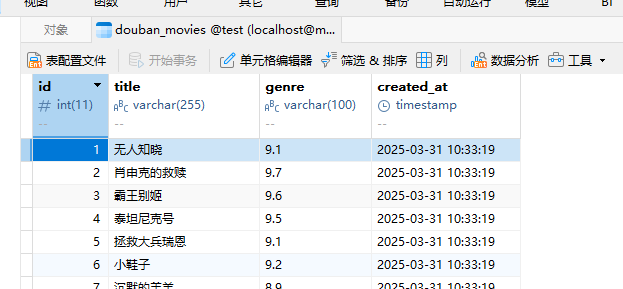
from itemadapter import ItemAdapterfrom google_trends_crawler.items import doubanitemclass GoogleTrendsCrawlerPipeline:def __init__(self):# 初始化數據庫連接self.conn = pymysql.connect(host='localhost', # MySQL服務器地址user='root', # 數據庫用戶名password='root', # 數據庫密碼database='test', # 數據庫名charset='utf8mb4',cursorclass=pymysql.cursors.DictCursor)self.cursor = self.conn.cursor()# 創建表(如果不存在)self.create_table()def create_table(self):create_table_sql = """CREATE TABLE IF NOT EXISTS douban_movies (id INT AUTO_INCREMENT PRIMARY KEY,title VARCHAR(255) NOT NULL,genre VARCHAR(100),created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)"""self.cursor.execute(create_table_sql)self.conn.commit()def process_item(self, item, spider):if isinstance(item, doubanitem): # 檢查是否是doubanitem# 插入數據到MySQLsql = """INSERT INTO douban_movies (title, genre)VALUES (%s, %s)"""self.cursor.execute(sql, (item['title'], item['genre']))self.conn.commit()spider.logger.info(f"插入數據: {item['title']}")return itemdef close_spider(self, spider):# 爬蟲關閉時關閉數據庫連接print('爬取完成')self.cursor.close()self.conn.close()結果展示



.getDecorView().setSystemUiVisibility(...)設置狀態欄屬性)





基礎語法)





)
![[論文筆記] Deepseek技術報告解讀: MLAMTP](http://pic.xiahunao.cn/[論文筆記] Deepseek技術報告解讀: MLAMTP)


React Hooks)
