一、Tair KVCache 簡介
Tair KVCache 是阿里云瑤池旗下云數據庫 Tair 面向大語言模型推理場景推出的 KVCache 緩存加速服務。
隨著互聯網技術的演進與流量規模的激增,緩存技術逐漸成為系統架構的核心組件。該階段催生了 Redis 等開源緩存數據庫,阿里巴巴基于自身業務需求自主研發了 Tair 分布式緩存系統。歷經十年技術沉淀,該系統已支撐阿里云百萬企業客戶及阿里巴巴集團雙11等核心場景的超高并發需求。
當前大語言模型(LLM)推理的快速發展推高了算力需求,與此同時,推理過程中的 KVCache 技術所需的巨大顯存消耗成為顯著瓶頸。KVCache 技術通過緩存歷史 Token 的 Key/Value 向量矩陣避免重復計算,雖將時間復雜度從 O(n2) 降至 O(n),卻導致顯存占用隨生成長度線性暴增,成為制約長文本生成和批量推理的核心瓶頸。
Tair KVCache 通過構建顯存-內存-存儲三級緩存體系,實現 KVCache 動態分層存儲,將 KVCache 由“純顯存駐留”升級為“分級緩存架構”,在提升計算效率的同時顯著擴展上下文長度,成為加速 LLM 推理的核心組件。
二、AI 場景對內存的需求
(一) HBM容量瓶頸
當前人工智能模型的規模擴張已徹底脫離硬件發展的線性軌道,存儲容量與算法需求間的代際鴻溝日益凸顯。以 Transformer 架構為核心的尖端模型(如 DeepSeek-R1、ChatGPT4.5)正以兩年 240 倍的指數級速度突破參數邊界,逐步挺進萬億參數時代,而同期主流AI硬件的高帶寬存儲器(HBM)容量卻僅能維持兩年約 1.8 倍的緩慢爬升(如 NVIDIA GPU 從 A100 的 80GB 到 H100 的 141GB)。這意味著:容量增速脫節 —— 模型參數量增速達 240 倍/兩年 vs. HBM 容量增速僅 1.8 倍/兩年,二者相差超過 130 倍;硬件與算法間的失衡發展,成為了 AI 算力進化的基礎性約束條件。
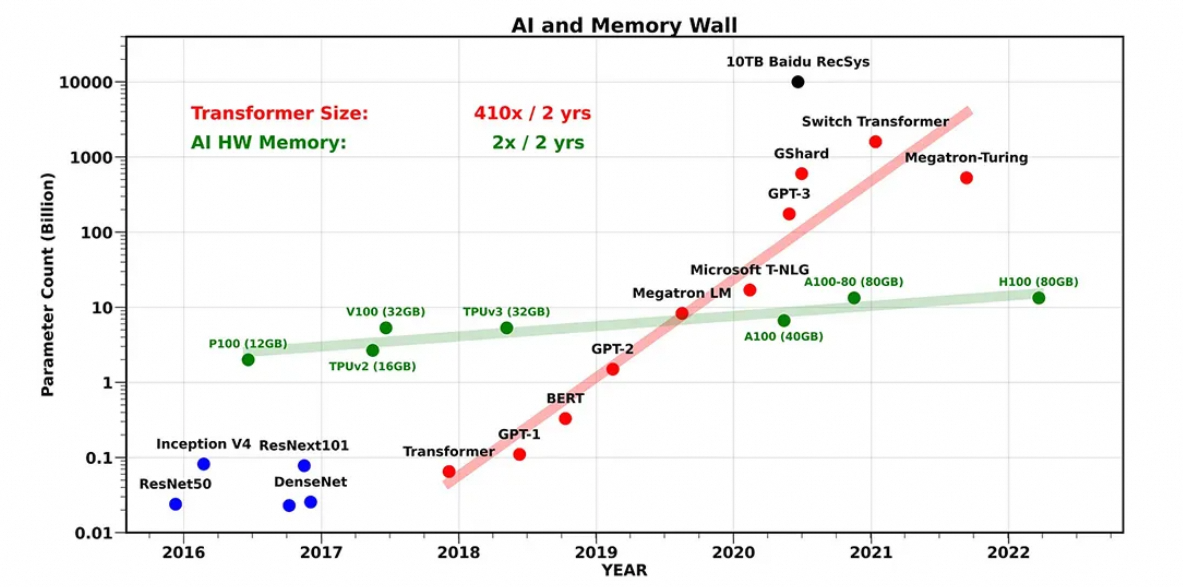
圖1:AI和內存墻 [1]
(二)帶寬瓶頸
在大語言模型推理場景中,當嘗試將部分計算數據從高速 HBM 內存擴展到本地DRAM、SSD 或通過 RDMA 協議擴展至遠端存儲時,帶寬資源的約束成為核心挑戰。由于模型參數和推理過程中動態生成的 KVCache 通常優先駐留在 HBM 中,當模型規模超出 HBM 容量上限時,數據被迫向 DRAM 或 SSD 換入換出,此類低速存儲介質的帶寬(例如 SSD 帶寬僅為 HBM 的百分之一)會嚴重拖累推理效率。若存儲層級間的帶寬不足,會導致計算單元頻繁因數據等待而空閑,顯著降低硬件利用率。
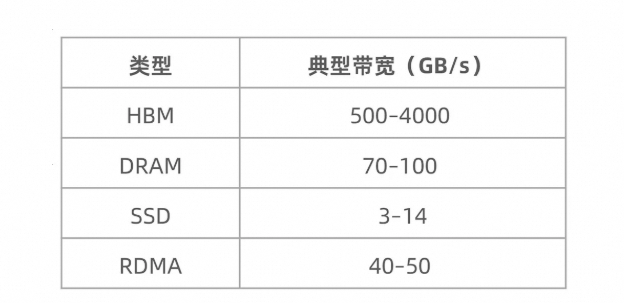
表1:存儲介質帶寬
為應對這一矛盾,如何基于有限帶寬充分挖掘 DRAM 和 SSD 的容量潛力以加速推理服務,成為亟待突破的技術難點。即使通過本地資源擴展技術緩解容量壓力,仍可能面臨以下問題:
- 資源利用率不均衡:不同負載場景下易出現局部資源閑置;
- 本地容量天花板:超大規模模型仍需跨節點資源協同;
- 分布式擴展代價:構建資源池化架構雖能提升彈性,但會加劇網絡帶寬競爭,需通過數據親和性調度優化通信路徑。
(三)產品服務化內存加速需求
當推理服務從單機擴展到分布式提供產品化服務,通常還需要使用相關的內存加速服務:
- 隊列化負載均衡:由于單個推理請求特別是 Reason 類的模型執行耗時較長(秒級至分鐘級),需通過內存隊列實現請求緩沖。
- 分布式協同開銷:多節點推理需同步處理任務切分、中間狀態同步、結果聚合,跨節點通信延遲易成為吞吐量提升的瓶頸。
- 多輪對話緩存:針對 LLM 生成式任務(文本續寫、多輪問答),需在內存中維持會話狀態緩存(Session Cache),支持歷史上下文快速檢索以保障前端交互流暢性。
- 動態限流控制:基于令牌桶之類算法實施請求速率限制,防止惡意高頻請求(如 DDoS 攻擊)過度搶占 GPU 計算資源。
三、面向 AI 推理的 KVCache
Tair KVCache 通過軟硬協同設計的池化實現,完成顯存容量的靈活擴展與計算資源的高效解耦;同時上層的調度組件充分利用內存的加速能力,支持如限流、親和性調度、對話緩存加速、執行預測等產品化服務需求。基于通用的模型和推理引擎,無縫兼容主流大語言模型架構,達成端到端百 GB 級 KVCache 吞吐與毫秒級響應,滿足高并發、低延遲的生成式 AI 場景需求。

圖2:Tair KVCache 介紹
(一)分布式內存池化
Tair KVCache 利用 GPU 集群空閑內存組成分布式內存池, 按需計費節省單機空閑內存,同時可以突破單機內存瓶頸。
分布式內存池化的核心目標是通過統一管理多級存儲資源(GPU 顯存、CPU 內存、SSD、遠端存儲),實現顯存容量擴展 與 計算資源解耦。
KVCache 是 Transformer 推理中除權重以外顯存占用主體,其 Offload 設計直接影響大模型推理效率:
- 通過將 KVCache 卸載至分布式池化存儲,單卡顯存僅需保留熱數據,達到支持:
1)更大 Batch Size:實驗顯示批處理規模提升 5-10 倍;
2)長上下文處理:如百萬 Token 級輸入(需數百 GB KVCache)。
- 計算與帶寬優化,以存代算:復用歷史 KVCache(如對話緩存),減少重復計算,加速推理,TTFT(首 Token 時間)縮短為原來的 1/10。
(二)多級 KVCache 分配管理
Tair KVCache 通過軟硬協同設計實現存儲資源的最優調度。核心圍繞三大目標展開:易用性統一抽象、性能極致優化、架構前瞻擴展,結合分層存儲特性與新型硬件協議,打造適應大模型推理的高吞吐多級 KVCache 池化方案。
- 易用性:提供統一的調用接口與錯誤處理接口,屏蔽底層物理差異,支持上層 Cache 調度與管理。
- 高性能:內存熱點 Locality 感知,與調度器結合,提高內存資源利用率,充分發揮 KVCache 復用的性能優勢,提高算力效率;根據底層互聯特性,提供高效數據交互機制實現高帶寬的 KVCache 共享。
- 可擴展:隨著后續物理介質和互聯協議的持續發展,能充分利用底層內存語義介質(AliSCM)和互聯協議(Alink)系統平滑遷移,為 KVCache 提供極致高帶寬與低成本,同時支持多樣拓撲與分級 KVCache 的調度和管理機制。
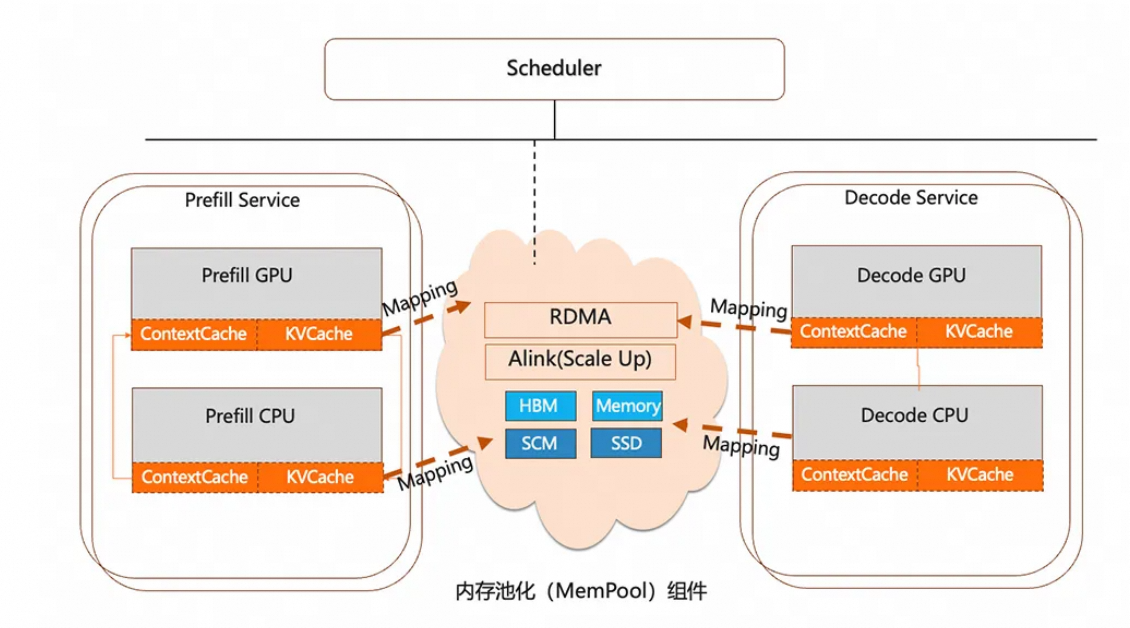
圖3:內存池化 MemPool 系統
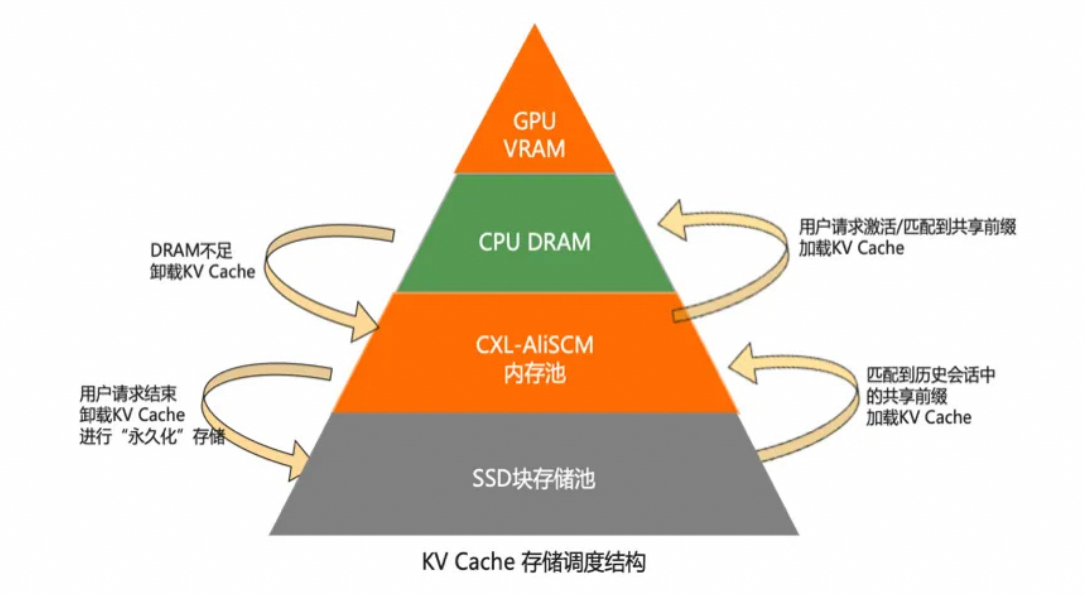
圖4:多級 KVCache 分配管理
(三)服務化支持
接著繼續看看如何用基于內存的 Redis 語義接口來支持分布式服務,例如隊列負載均衡、多輪對話緩存和動態限流控制。
1. 隊列化負載均衡
利用內存隊列 Stream 可以把推理任務投遞到 Stream 中,推理引擎做為消費者使用 XREADGroup 命令從所屬任務組中按需拉取任務。支持阻塞式讀取(等待新任務到達)或批量拉取,避免頻繁輪詢。多個推理引擎消費者屬于同一任務時,Stream 自動將消息分配給不同的消費者,實現并行處理。每個消費者獨立維護未確認(Pending)消息列表,確保任務不會被重復消費。
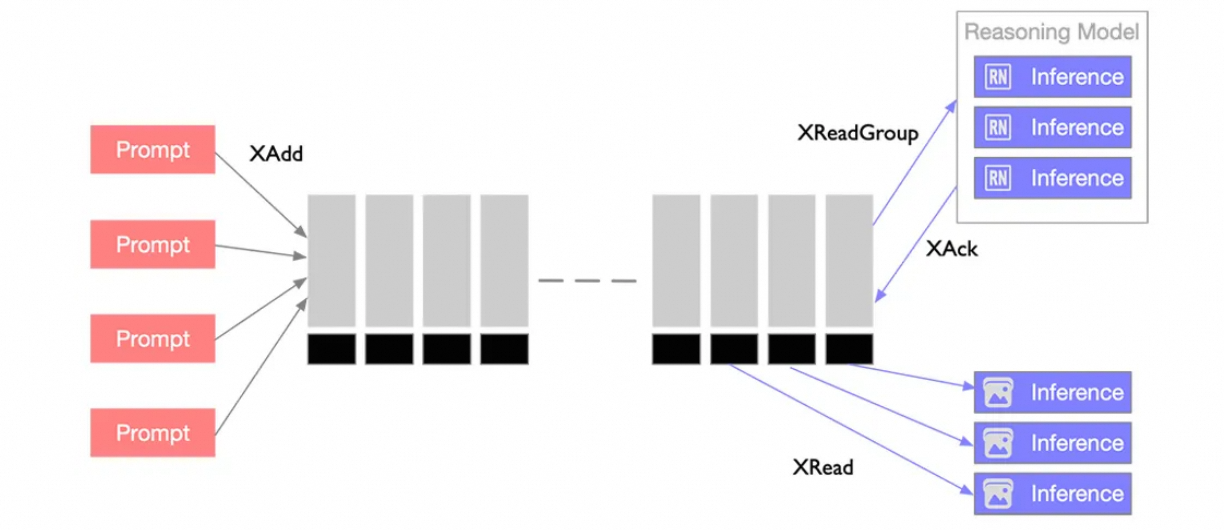
圖5:隊列推理負載均衡
2.多輪對話緩存
在多輪對話場景(如聊天機器人、客服系統)中,大模型推理服務需要依賴歷史上下文生成連貫回復。可以利用內存的Hash結構來滿足:1)快速存取——毫秒級響應,避免對話卡頓;2)上下文關聯——支持按會話 ID(Session ID)快速檢索完整歷史;3)高并發支持——應對海量用戶同時發起對話。
- 初始化會話生成唯一對話標識符
session_id。 - 創建 Hash 結構并設置初始元數據,如
HSET session:123 metadata '{"user_id": "abc", "model": "XXX"}'。 - 設置 TTL 實現自動過期,如
EXPIRE session:123 3600。 - 存儲多輪對話,如
SET session:123:turn:5 "What's the capital of France?"。
3. 限流控制
以恒定速率處理請求,超出桶容量的請求被丟棄或排隊。用于:1)防止資源過載:避免計算資源被惡意或異常流量耗盡。2)保障服務質量:確保高優先級請求(如付費用戶)的響應時間符合 SLA。
使用List結構模擬漏桶:
- 入隊:新請求通過
LPUSH加入隊列。 - 出隊:通過定時任務以固定速率
PROP處理請求。 - 溢出控制:檢查隊列長度(LLEN),超過容量則拒絕新請求。
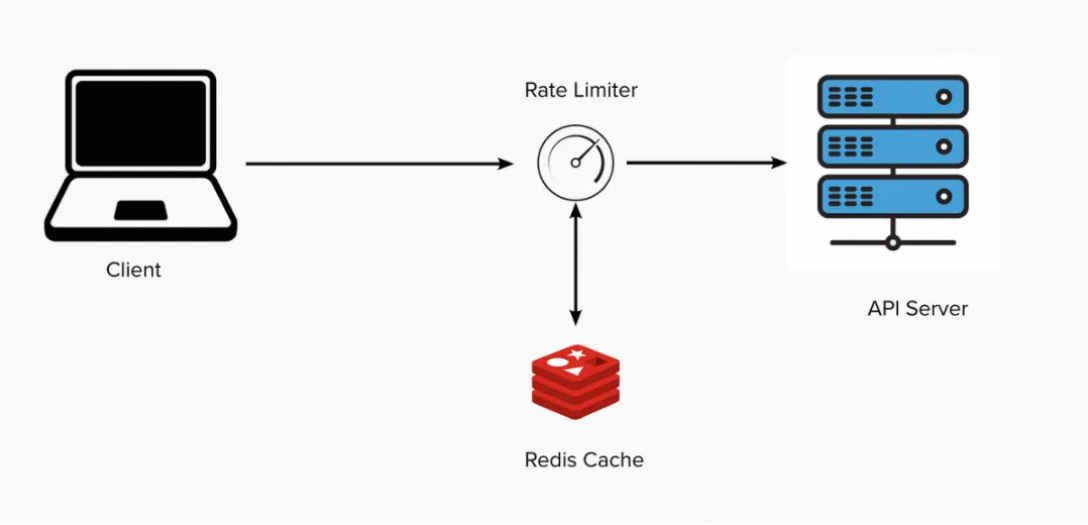
圖6:限流服務
(四)兼容性
Tair KVCache 提供內存語義的訪問接口,可以通過類似 Jemalloc 的內存分配器進行管理和分配,主流推理引擎如 TensorRT-LLM、vLLM、SGLang 均可以進行方便的適配。
四、總結
作為阿里云數據庫為大語言模型推理場景量身打造的技術產品,Tair KVCache 憑借其創新的分布式內存池化和分級緩存體系,成功突破了大語言模型推理中的顯存墻與帶寬瓶頸問題。
通過軟硬協同設計,Tair KVCache 實現了顯存容量的靈活擴展與計算資源的高效解耦,支持更大 Batch Size 和長上下文處理,顯著提升了推理效率和資源利用率。同時,其服務化支持與兼容性設計,為分布式推理場景提供了統一的 Redis 語義接口,能夠輕松適配主流推理引擎。
Tair KVCache,不僅為萬億參數模型的高效推理提供了技術保障,也為 AI 算力的持續進化和規模化應用開辟了新的可能。

分頁效果)

機制精要)
的兩種解法)














