
資料來源:火山引擎-開發者社區
DeepSeek Smallpond 介紹
Smallpond 是一套由 DeepSeek 推出的 、針對 AI 領域,基于 Ray 和 DuckDB 實現的輕量級數據處理引擎,具有以下優點:
1.輕量級
2.高性能
3.支持規模大
4.無需運維
5.Per Job 的資源調度
快速開始
Smallpond 提供了兩套 API(具體介紹見下文),一套是 High-level 的 Dataframe API,一套是 Low-level 的Logicalplan API。前者簡單、易理解,使用上非常類似 Pandas、PySpark 等引擎;后者靈活度高,可以實現更加復雜的數據處理邏輯。
·Dataframe API
import smallpond
sp = smallpond.init()
df = sp.read_parquet("path/to/dataset/*.parquet")
df = df.repartition(10)
df = df.map("x + 1")
df.write_parquet("path/to/output")
當前 Dataframe API 功能還比較薄弱,針對一些高級場景,比如定義 Ray 運行參數、GPU等尚無法設置。
·LogicalPlan API
from smallpond.logical.dataset import ParquetDataSet
from smallpond.logical.node import Context, DataSourceNode, DataSetPartitionNode, SqlEngineNode, LogicalPlan
from smallpond.execution.driver import Driver
def my_pipeline(input_paths: List[str], npartitions: int):
ctx = Context()
dataset = ParquetDataSet(input_paths)
node = DataSourceNode(ctx, dataset)
node = DataSetPartitionNode(ctx, (node,), npartitions=npartitions)
node = SqlEngineNode(ctx, (node,), "SELECT * FROM {0}")
return LogicalPlan(ctx, node)
if name == "__main__":
driver = Driver()
driver.add_argument("-i", "--input_paths", nargs="+")
driver.add_argument("-n", "--npartitions", type=int, default=10)
plan = my_pipeline(**driver.get_arguments())
driver.run(plan)
python script.py -i "path/to/.parquet" -n 10 Ray # Ray 引擎 python script.py -i "path/to/.parquet" -n 10 scheduler # built-in 引擎
注意,Smallpond 支持兩種分布式引擎(具體介紹見下文),一種是 Ray 引擎,一種是 Built-in 引擎。使用方式見上文腳本所示。
架構介紹
下圖為 Smallpond 架構:
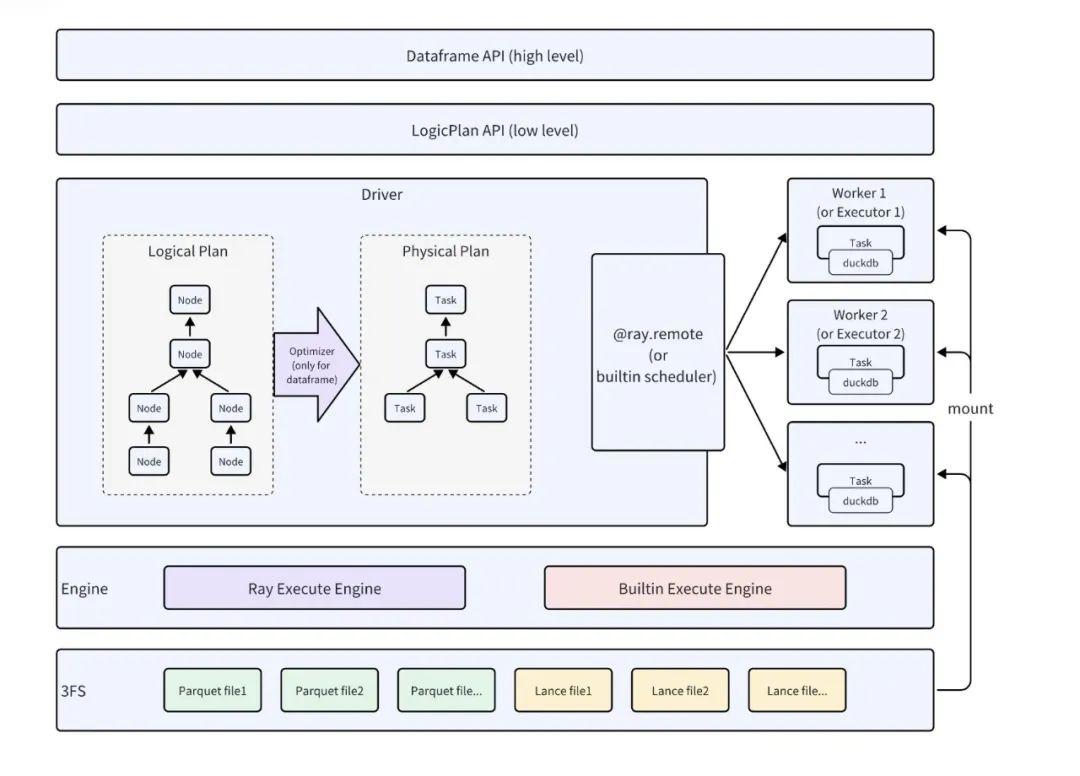
整體架構類似于 Spark 的架構,其組件 Dataframe、Logicalplan、Physicalplan、Scheduler 等 Spark 都有對應,是一個典型的??批處理形式?SQL?內核架構?。
1.DataFrame 的接口目前只能支持 Ray Engine。
2.最底層是 存儲層 。這個存儲有兩個作用:
·作為源數據和中間執行數據的存儲,可以被 mount 到本地路徑;
·如果選用 Built-in 執行引擎,這個存儲還是 task 的序列化存儲用于從 driver 節點向 executor 節點派發任務。除了?3FS?存儲,Smallpond 還支持 fsspec 接口 ,從而對接其他存儲。
3.引擎層 。這里有兩個選項,一個是 Ray,一個是 Built-in (run driver 的時候通過 mode 來指定,如果選項是 Ray,走 Ray 引擎,如果選項是 Scheduler,走 Built-in 引擎)。官方說兩套引擎是歷史原因,未來會逐漸合并。
4.執行層 。完全類似 Spark 的實現,有 Logicalplan,如果選用 Dataframe 接口,還有優化器支持。最后的物理計劃生成 task,會被調度器扔到遠端的 worker 計算。task 的執行有兩種選擇:DuckDB 和 Arrow(官方文檔未給出)。
5.API 層 。支持 High-level 與 Low-level 的 API。
主要特點
特點 1:使用 Ray 做分布式調度和執行
Smallpond 使用 Ray 作為其分布式執行引擎之一,另一種為 Built-in 引擎。根據筆者測試,Ray 引擎相較于 Built-in 引擎有明顯的性能方面的優勢。一個可能重要的原因是,在 Built-in 引擎中,driver 向 executor 發送序列化任務不是通過 RPC 進行,而是通過共享存儲方式進行,這個過程 task 序列化需要落共享存儲。另外 Ray 相比有非常高效的 task 調度能力。
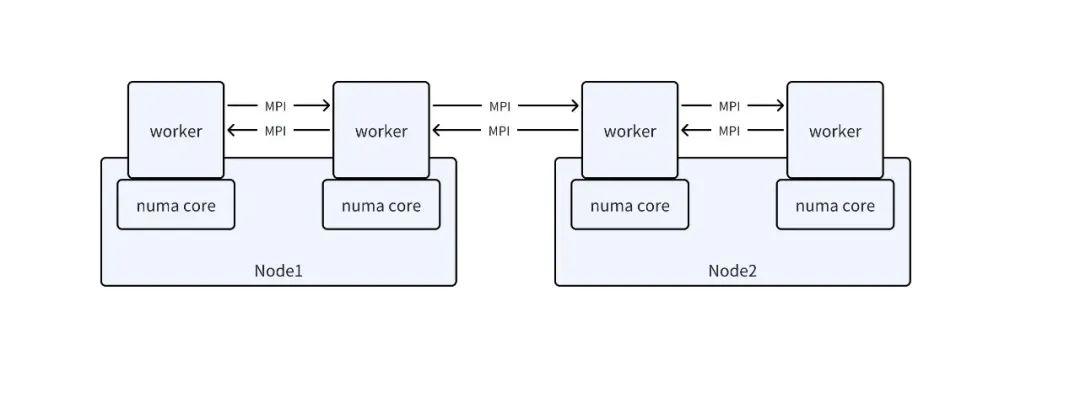
特點 2:MPI?的支持與?numa?綁定
這是一個可能容易被忽視的創新點:借助 MPI 框架,用戶可以自定義任務,使用 MPI 做高效的集合通信。上文已經說到,用戶完全可以自定義自己的 Python 腳本,而用戶可以在自己的 Python 腳本里寫 MPI 程序,從而使用 MPI 做高效的集合通信。
同時,worker 也做了 NUMA 綁定,做到更加高效的內存存取。
另外,代碼中設置了 openmp 的環境變量。用戶可以使用單核多線程來加速程序。
特點 3:極具靈活性的 Low Level?API
通過 Low Level API,用戶不但可以自己定義 map、filter 等典型的 SQL 類型算子,也可以定義非 SQL 算子,例如可以定義 PythonScriptNode,用于執行 Python 腳本。
這樣做的好處在于, 極大地增強了數據處理的靈活性 :某些數據處理需求可能不方便使用類似 Dataframe 的 map 算子來處理,就可以寫 Python 代碼自由地處理這些任務了。
從這個角度看,這個 Logicalplan 已經超出了 Spark Logicalplan 的范疇 ,兼具了一些類似于“ 工作流調度 ”的能力,可以調度進程。
特點 4:與 3FS 的結合
Smallpond 將 3FS 掛載到本地,可以利用 3FS 的性能優勢,結合 DuckDB 的優秀處理能力,達到很高的處理效率。
不過,筆者認為與 3FS 的結合不能作為一個創新點來看待,因為兩者是松耦合的(非深度結合),只是說運行在 3FS 上會使得 Smallpond 運行地更快,而掛載 filesystem 到本地實現分布式計算也是一個常規的行為。
火山引擎?AI 數據湖 LAS 介紹
總體架構
隨著 LLM 和多模態 AI 技術的飛速發展,非結構化數據量呈指數級增長,這極大地增加了數據管理、計算和存儲的復雜性。傳統的數據湖解決方案已難以適應 AI 場景下對數據的新需求。為了應對這一挑戰,新一代數據湖必須解決以下多模態數據帶來的關鍵問題:
·數據管理 :傳統數據管理側重于庫表結構,而面對多模態非結構化數據,如何實現高效管理。
·數據計算 :如何從非結構化數據中挖掘潛在價值,如何提高CPU和GPU利用率,如何使用模型來處理數據。
·數據存儲 :傳統數據湖格式在非結構化數據存儲方面存在局限,是否可實現全模態數據的統一湖格式存儲。
·AI 場景支撐 :多模態數據湖如何支撐 預訓練、后訓練、知識庫、AI 搜索、智能體、安全合規 等場景的智能化應用。
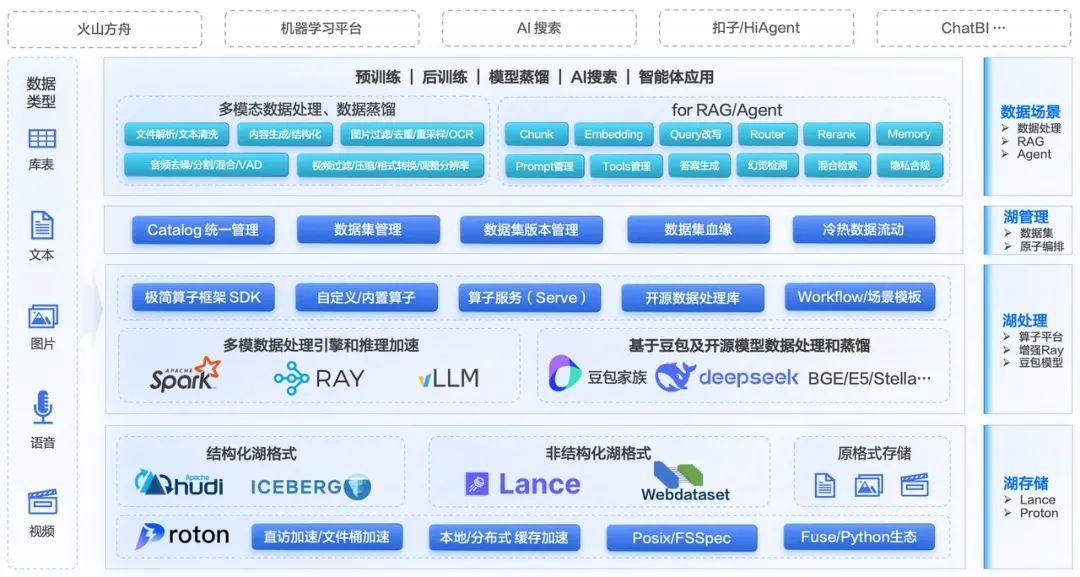
火山引擎基于內外部客戶的實踐,推出了一款面向?AI?場景的多模態數據湖服務 。總體架構如下:
功能介紹
LAS 提供了如下功能:
1.數據集管理 。用戶可以根據數據的使用場景創建不同類型的數據集。比如,針對大規模預訓練場景的大規模數據集,可以使用 LAS 的分布式處理能力;對于后訓練階段的 SFT 場景,LAS 推出了數據洞察以及細粒度的數據編輯功能。此外,LAS 還支持數據集多版本,滿足算法人員在不同數據版本之間做對比實驗的需求。
2.統一 Catalog 。用戶可以將自己的數據注冊為 catalog table,即能夠使用平臺提供的針對格式化數據的計算與分析工具。
3.豐富的算子支持 。LAS 提供了針對文本、圖片、視頻、音頻、文檔等類型的 100+ 算子,用戶可以一鍵調用,標準化自己的數據處理流程。
4.工作流支持 。通過工作流,用戶可以提交各種類型的數據處理作業,比如除了內置的算子標準化作業,還支持用戶提交 Python 作業、Spark 作業、Ray 作業等等。
5.多數據湖格式/數據源 。支持 lance、Iceberg、Parquet、Json、CSV、VikingDB、Opensearch 等,滿足各種場景需求。例如,針對訓練或者微調過程,需要有高性能的點查需求,用戶可以選擇 lance;針對線上業務數據回流場景,可以選擇 Iceberg;針對 RAG 場景,可以選擇 VikingDB 作為數據 sink。
6.存算分離架構與分布式數據緩存 。LAS 推薦使用存算分離架構,以減少存儲成本,提升計算的可擴展性。同時,LAS 針對存算分離場景提供了 Proton 緩存服務,以加速對 TOS 數據的訪問。
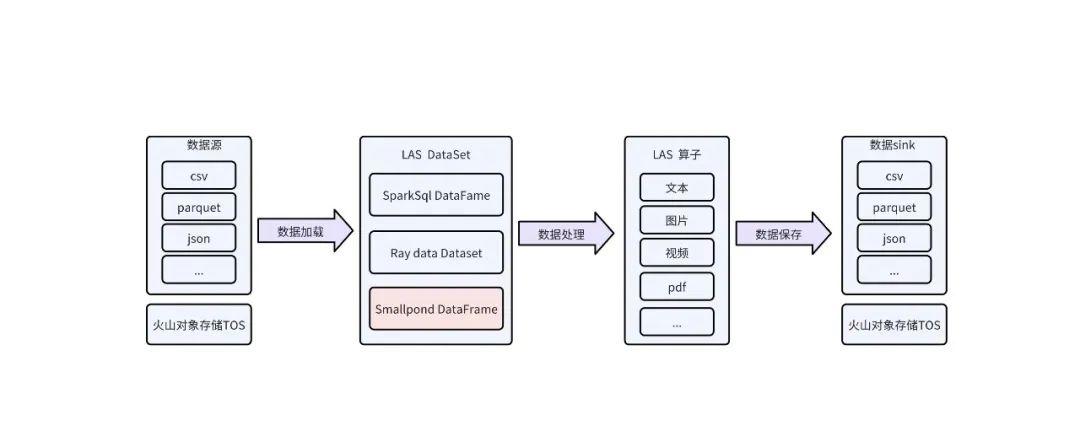
Smallpond DataFrame + LAS Ray 計算資源組
當前,有很多客戶在云上運行他們的計算解決方案的同時,也希望能夠在云上用上 Smallpond。為此,LAS 提出了基于 Ray 的云上方案,如下圖所示:
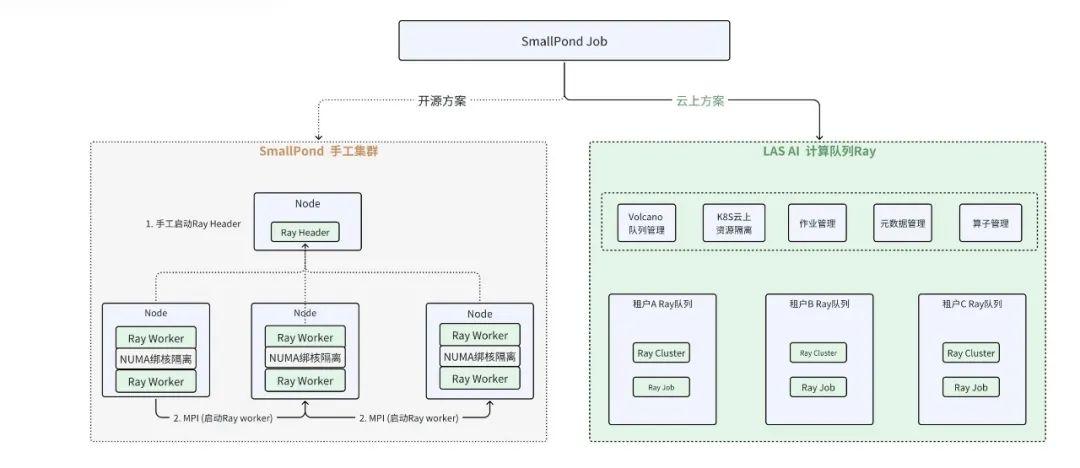
該云上方案具備五大優點:
·環境準備簡單:無需用戶需手工添加節點,打通 SSH,構建 MPI 集群。
·資源隔離:支持對 IO/網絡/內存等更加嚴格的資源條件。
·認證鑒權:對資源的申請做用戶鑒權。
·資源統一管理:用戶無需手動管理計算資源,開箱即用。
·K8s 調度:完全交由平臺運維解決,支持排隊,搶占等。
在該方案中,LAS 中的集群能夠無縫的與 Smallpond 融合,只需要在云上開通資源 ,將 ray_address 設置成已開通的資源隊里,其余邏輯無需改造,就可以完成數據預處理。
sp = smallpond.init(ray_address= "ray://192.xxxx:10001")
Smallpond 基于 Proton/TOS-FS 對接云存儲
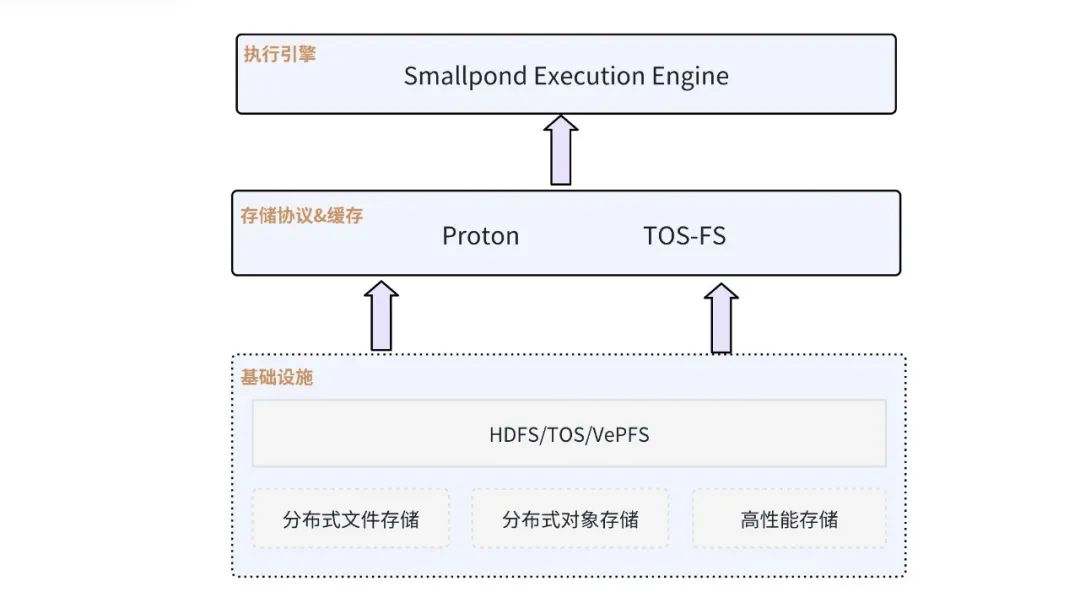
Smallpond 不僅支持 3FS 協議的存儲,還支持 fuse 和 fsspec 的接口。因此,我們可以針對大規模數據處理的場景,將數據存儲在 TOS 對象存儲上(LAS 支持 TOS 的 fsspec 協議訪問),而將訓練場景的數據放置到 vePFS 存儲中。
擴展 Datasource-Lance 多模態數據湖
Lance 是新一代的列式存儲結構,它被設計用來存儲視頻,圖像,音頻以及普通列式數據。它可以被存儲在任何 POSIX 文件系統以及像 S3,TOS 等云存儲上。Lance 允許數據被隨機訪問,在隨機訪問場景下它比 Parquet 性能快 100 倍。同時它具備向量檢索,零拷貝的能力,并且與 Pyarrow,DuckDB 生態緊密結合。
Lance 的主要能力:
1.多版本管理 : Lance 是數據湖, 提供了 多版本的能力 , 能夠快速的實現增刪查改以及結構變更的需求, 也提供 time travel 的能力。
2.多維分析 : Lance 能夠對接分布式計算引擎, 例如 Spark/Ray, 完成大規模數據分析需求。
3.隨機檢索 : Lance 構建了 主鍵索引和二級索引 , 能夠實現快速的隨機檢索。
4.向量檢索 : Lance 上實現了 IVF-PQ 和 IVF-HNSW 向量索引, 以及全文索引, 具有 混合搜索能力 。
5.多模數據 : Lance 自定義了底層文件格式, 能夠寫入大寬表和大寬列, 直接在表字段中存儲多模數據, 例如文本/圖像。
6.開放生態 : Lance 支持 Python/Java 客戶端, 內存采用 arrow 格式, 適配了很多AI生態的引擎和大數據計算引擎。
LAS 中提供了完整的產品化的 Lance 湖服務能力,包括元數據管理,小文件合并服務, 而 Smallpond 也是能夠無縫的接入lance的數據源。
以下是 Smallpond支持 Lance 的實踐樣例:
import lance
import arrow
from smallpond.logical.dataset import ArrowTableDataSet
從 Lance 格式的文件中讀取數據
lance_ds = lance.dataset("example.lance")
將數據轉換為 Arrow 的 Table
arrow_table = lance_ds.to_table()
將arrow_table轉換成smallpond的dataset
smallpond_dataset = ArrowTableDataSet()
集成 LAS 的算子
Smallpond 支持 map/map_batches 的并行算子邏輯,其接口方式跟 Ray類似。而火山引擎 LAS 的算子服務能力接口是可以同時兼容 Spark/Ray。因此 LAS Built-in 的算子也都能夠直接跑在 Smallpond 上。
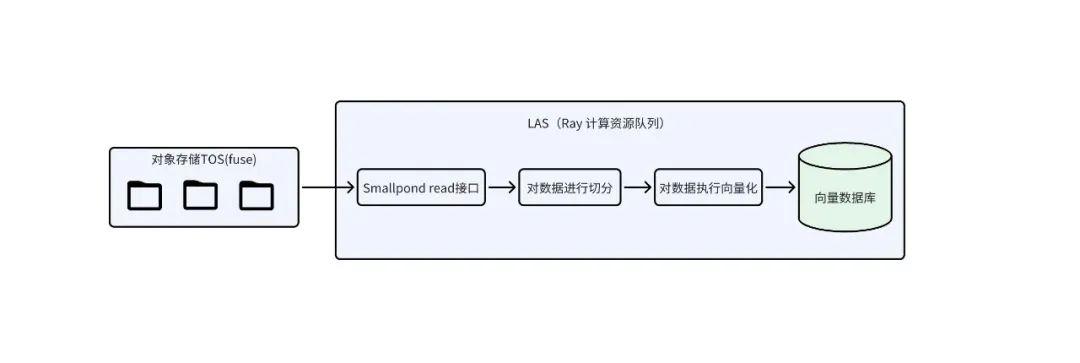
實踐示例
場景描述:在 RAG 架構的離線入庫場景,通過 LAS 產品提供的 分布式計算能力 Smallpond,實現從對象存儲到向量數據庫的全流程優化。在該鏈路中,讀取數據后,利用 Smallpond 高效完成數據的切分(chunk)和向量化處理,并最終將向量數據批量入庫至向量數據庫。
同時,LAS 提供有 Chunk 和 Embedding 的算子,平臺產品界面中,有對算子進行詳細和介紹和 Demo 示例,便于用戶快速搭建該鏈路。此外,也支持自定義算子。
以下按照自定義算子示例:
Step 1:創建 LAS 計算資源
在 LAS 平臺中提供有 CPU 和 GPU 的計算資源隊列。由于 Embedding 消耗的算力較大,建議采用 GPU 計算資源。
Step 2:實現該流程的代碼
定義三種處理器:Chunk、Embedding、寫向量數據庫。由于SmallPond未提供寫入向量數據庫的接口,可以利用map_batches方法實現。
import copy
import logging
import pyarrow as pa
import smallpond
from FlagEmbedding import FlagModel
from llama_index.core import Document
from llama_index.core.node_parser import SentenceSplitter
from volcengine.viking_db import Data, VikingDBService
class ChunkProcessor:
"""將文本切分成chunk片段,用于文本檢索等場景。"""

class EmbeddingProcessor:
"""使用 BGE 系列模型計算文本的 embedding。"""

class VikingdbSinkProcessor:
""" 將數據寫入到火山的向量數據庫VikingDB中 """

if?name?== "__main__":
初始化
sp = smallpond.init()
數據處理流水線?
sp.read\_csv(paths, schema)\ .flat\_map(ChunkProcessor(input\_col\_name = "index"))\ .map\_batches(EmbeddingProcessor(input\_col\_name = "chunk"))\ .map\_batches(VikingdbSinkProcessor(collection\_name = vikingdb\_dataset))\ .take\_all()??
Step 3:在 LAS 平臺提交該示例代碼
LAS 平臺提供直接運行 Python 腳本的能力。
1.在 LAS 平臺中,算子管理菜單中 上傳上述代碼,以及代碼依賴的鏡像。也可以使用 LAS 平臺提供的鏡像。LAS 平臺提供的鏡像有 LAS 算子執行的鏡像,也提供含 PyTorch 基礎鏡像等等。
2.LAS 平臺中,工作流中通過拖拽式方式,將該算子拖到畫布中點擊執行按鈕,便可啟動任務。界面上可以查看到執行日志和進度。
小結與規劃
Smallpond 是 DeepSeek 開源的一個優秀的輕量級、高性能 AI 場景數據處理框架,一經推出便引起了業界的關注,項目 Star 數快速增長。其優點以及創新點上文已經有了詳細的介紹,但由于項目處于開源初期,仍有很多問題有待解決,比如:
1.支持已有 Ray Cluster的接入方式;
2.數據源需要支持 S3 協議、TOS 等其他對象存儲的協議;
3.適配更多的數據格式,尤其是面向多模的數據格式,例如 Lance,LMDB,Webdataset,Pickle 等。
相信隨著時間的推移,上述這些問題都能得到很好的解決。
根據項目介紹,Smallpond 的目標是解決 AI 場景靈活的數據處理需求,這與火山引擎 LAS 多模數據湖的目標是相同的。LAS 數據湖配套有自己的數據處理框架,以及大量的用于多模數據處理的算子,用戶可以開箱使用。而如果用戶選擇使用類似 Smallpond 的數據處理框架,通過 LAS 也能很好的支持,同時也能很好的發揮云的優勢。
在未來,火山引擎 LAS會考慮 結合 Smallpond 優秀的架構能力與云低成本、易運維、以及生態協同的優勢 ,為用戶提供更加強大的 AI 數據處理功能。




:圖)



)








)

