目錄
一、圖的存儲方式(千奇百怪)
1)鄰接表
2)鄰接矩陣
3)其他
4)推薦存儲方式(代碼)
二、圖的遍歷
(1)寬度優先遍歷
(2)深度優先遍歷
?編輯?三、拓撲排序算法
四、kruskal與prim(針對無向圖)
(1)kruskal算法
(2)prim算法
五、Dijkstra算法
一、圖的存儲方式(千奇百怪)
1)鄰接表

2)鄰接矩陣

3)其他
也可以用數組表示圖:
Q:一個數組arr,存儲一個沒有環的特殊圖,其每個位置上的數字代表其父節點(eg:arr[0] = 5表示0的父節點是5),以此類推可得到下面的圖:

使用小數組表示圖:
一個數組中每一個位置都存放著一個數組,它依次存儲【權重,起始點,中止點】,因此 [3, 0, 2] 就代表著有一條權重為3,從0開始,指到2的邊,其余以此類推:

由于表達圖的方式?千 奇 百 怪?,所以推薦:
(1)選擇一種習慣的圖表示方法,用該種表示方式來實現所有的圖的算法;
(2)想辦法將題中所給出來的圖轉化為自己熟悉的圖的表示方法,再運用寫好的算法即可!
4)推薦存儲方式(代碼)
一種供參考的圖的存儲方式:



轉化示例:

二、圖的遍歷

(1)寬度優先遍歷
區別二叉樹的寬度優先遍歷,因為圖中可能含有環!
仍然借助隊列實現(二叉樹的寬度優先遍歷也是借助隊列):?

結合畫圖理解:

tips:若需要進一步減少常數級別的耗時,可以采用數組來替換哈希表,因為數組的查詢比哈希表更快一些;?
(2)深度優先遍歷
借助棧和哈希表來實現:

結合下圖來理解:
棧中保存的是DFS的路線!

?三、拓撲排序算法
適用范圍:要求有向圖,且有入度為0的節點,沒有環。
常用環境:編譯順序
如下圖所示,假設編譯文件A需要先編譯文件BCD,編譯文件B又需要先編譯文件CDE,請問應該以什么樣的順序編譯整個文件?

算法思路:
? ? ? ? 1、先找到一個入度為0的點,記錄該點,并刪除其“影響”(此處指有向邊);
? ? ? ? 2、重復上述過程直到沒有未記錄的節點;

四、kruskal與prim(針對無向圖)
作用:生成最小生成樹(在保證連通性的情況下,確保邊的權值總和最小);

(1)kruskal算法
從“ 邊 ”的角度出發考慮,對于所有邊,按照權重排序;依次連線上最小的邊,若會形成環,則去掉這條邊。
檢查是否形成環會用到“并查集”的概念,該部分實現將會在后續課程涉及。
例1:

?例2:是否成環 == in節點和out節點是否屬于同一個集合中

并查集的簡單替換:(比并查集慢)
思路:定義一個setMap,里面存儲著每個節點和它所屬的集合;為主函數提供兩個方法——一個用于判斷from和to節點是否處于同一個集合中,另一個用于實現合并集合的操作。


有了上述的并查集結構后,我們可以實現k算法:
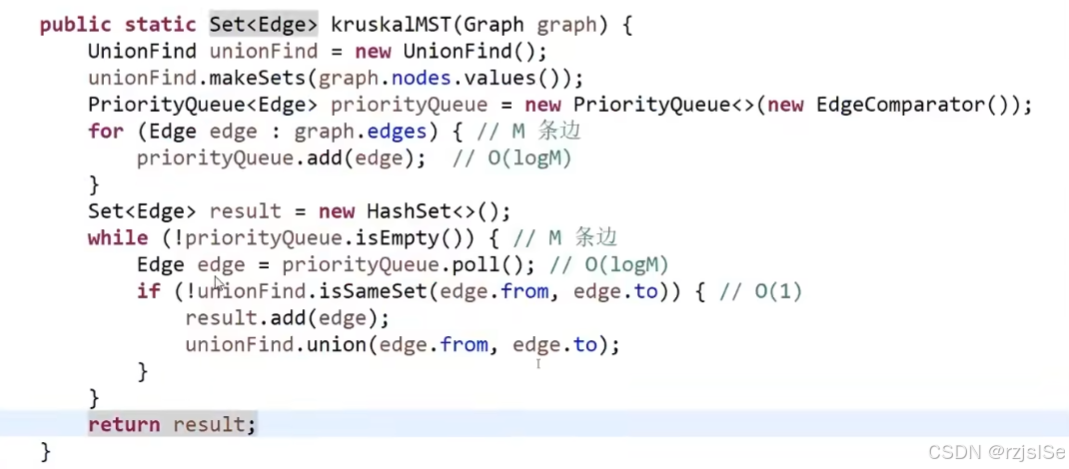
(2)prim算法
從“ 點 ”的角度出發考慮,從任意的點開始,標記該點使用過,對于該點可達的邊標記為解鎖狀態;選擇當前解鎖邊中兩側點不全出現過且權值最小的一條,將其標記為使用過,并標記該邊連接的另一個節點為使用過;重復上述直到用過所有點。
例:假設從A開始,解鎖AB6、AC1、AD5三條邊;選擇AC1邊,解鎖CB5、CE6、CF4、CD5邊;選擇CD4邊,解鎖FE5、FD2邊;選擇FD2邊,無需解鎖;此時【ACFD】已經被使用,故只能選擇CB5而非CD5、AD,解鎖AB6、BE3;選擇BE3,已經遍歷所有點,p算法結束。

思考:為什么k算法需要并查集(集合查詢結構)而p算法不需要?
k算法可能出現已經連成將節點兩小片后再將兩邊相連成一大片的情況;而p算法總是選擇相鄰(已解鎖)的邊,使用哈希表即可。

代碼實現:

結合圖像理解:當A選擇B時,AB、AC會被添加,但是由于A、B兩點已經被食用過,所以會直接跳過AB邊而尋找其他邊!

五、Dijkstra算法
適用范圍:可以有權值為負數的邊,但是不能有累加和為負數的環!
作用:指定一個點,給出從該節點出發到所有其他點的最短距離。
算法流程:初始化一個距離表,將初始節點置為0,初始節點到其他節點的距離置為正無窮;每次從距離表中選取距離最近的節點,檢查其所有邊的權重,若從原點通過該點到達下一個點的距離更小,則更新距離表,否則不做處理;重復上述過程直至完成對所有點的遍歷。
例:
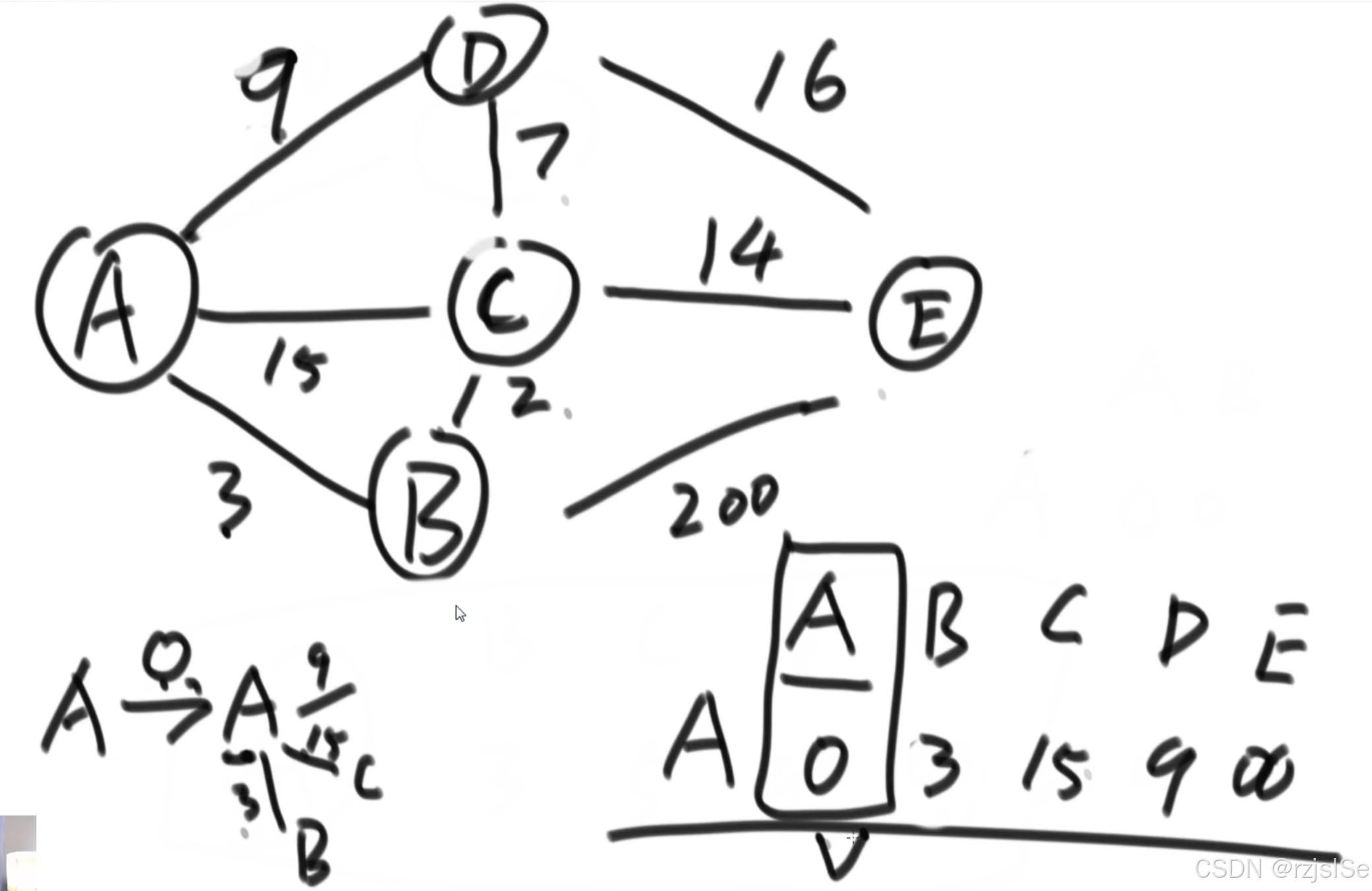

代碼實現:


堆優化思路:之前尋找最小值使用遍歷的方法,所以較慢,所以考慮使用堆來存儲數據;但是當權值更新后,不一定還能滿足堆的順序,此時需要對于其進行手動調整,只有這樣是最快的方式。



)








)


)



