面向新冠肺炎的社會計算應用
1 任務目標
1.1 案例簡介
新冠肺炎疫情牽動著我們每一個人的心,在這個案例中,我們將嘗試用社會計算的方法對疫情相關的新聞和謠言進行分析,助力疫情信息研究。本次作業為開放性作業,我們提供了疫情期間的社交數據,鼓勵同學們從新聞、謠言以及法律文書中分析社會趨勢。(提示:運用課上學到的方法,如情感分析、信息抽取、閱讀理解等分析數據)
1.2 數據說明
https://covid19.thunlp.org/ 提供了與新冠疫情相關的社交數據信息,分別為疫情相關謠言 CSDC-Rumor、疫情相關中文新聞 CSDC-News和疫情相關法律文書 CSDC-Legal。
疫情相關謠言 CSDC-Rumor
這一部分的數據集收集了:
(1)自 2020 年 1 月 22 日開始的微博不實信息數據,包括被認定為不實信息的微博的內容、發布者,以及舉報者、審理時間、結果等信息,截至 2020 年 3 月 1 日共 324 條微博原文,31,284 條轉發和 7,912 條評論,用于幫助各位研究者分析研究疫情期間的不實信息傳播;
(2)自 2020 年 1 月 18 日開始的騰訊謠言驗證平臺以及丁香園不實信息數據,包括被認定為正確或不實信息的謠言內容、時間以及用以判斷是否為謠言的依據等信息,截至 2020 年 3 月 1 日共 507 條謠言數據,其中事實性數據 124 條,數據分布為,負例:420 正例:33 不確定:54。
疫情相關中文新聞 CSDC-News
這一部分的數據集收集了自 2020 年 1 月 1 日開始的新聞數據,包含了新聞的標題、內容、關鍵詞等信息,截至 2020 年 3 月 16 日共收集 148,960 條新聞以及 1,653,086 條對應評論,用于幫助各位研究者分析研究疫情期間的新聞數據。
疫情相關法律文書 CSDC-Legal
該數據為對從 CAIL 收集的經匿名化的法律文書數據中篩選出的歷史上與疫情相關的部分,共 1203 條,每條數據包含了文書標題、案號以及文書全文,供研究者用于進行疫情期間相關法律問題的研究。
1.3 參考思路
- 謠言檢測:如何準確快速地識別社交媒體上的謠言是社會計算領域中的一個重要問題,在我們提供的疫情相關謠言數據集上,同學們可以嘗試不同的謠言檢測方法,比如基于特征[1]、基于神經網絡[2, 3]或基于傳播模型的方法[4],綜述[5]總結了謠言檢測的相關技術。
- 新聞情感分析:參考我們的情感分析作業,可以通過關鍵詞識別[6]等技術對疫情相關的中文新聞進行情感分析,并找出情感背后蘊含的社會學原因。
- http://weibo.com/n/%E6%B8%85%E5%8D%8E%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86 清華自然語言處理實驗室微博中給出了一些可視化例子,同學們也可以用統計學和語言學方法對文本進行分析和可視化。
1.4 評分標準
本次作業為開放性作業,我們會從
- 選題的合理性和新穎性
- 采用方法的合理性和技術含量
- 作業的完成度和工程量
- 報告和社會學分析的完整性和深入程度
等方面為作業進行評分。
1.5 參考資料
[1] Information credibility on twitter. in Proceedings of WWW, 2011.
[2] Detecting rumors from microblogs with recurrent neural networks. in Proceedings of IJCAI, 2016.
[3] A convolutional approach for misinformation identification. in Proceedings of IJCAI, 2017.
[4] The spread of true and false news online. Science, 2018.
[5] False information on web and social media: A survey. arXiv preprint, 2018.
[6] Characterization of the Affective Norms for English Words by Discrete Emotional Categories. Behavior Research Methods, 2007.
2 疫情相關謠言數據分析
? 本次實驗提供了疫情相關謠言數據集 CSDC-Rumor,通過對數據集內容分析,選擇首先對數據集進行定量統計分析,之后使用聚類實現謠言的語義分析,最后設計一個謠言檢測系統。
2.1 數據處理
-
數據格式
本次實驗提供了疫情相關謠言數據集 CSDC-Rumor,收集了微博不實信息數據,與辟謠數據。數據集包含以下內容。
rumor │ fact.json │ ├─rumor_forward_comment │ 2020-01-22_K1CaS7Qxd76ol.json │ 2020-01-23_K1CaS7Q1c768i.json ... │ 2020-03-03_K1CaS8wxh6agf.json └─rumor_weibo2020-01-22_K1CaS7Qth660h.json2020-01-22_K1CaS7Qxd76ol.json...2020-03-03_K1CaS8wxh6agf.json微博不實信息分別由
rumor_weibo和rumor_forward_comment中的兩個同名json文件所描述。rumor_weibo中的json具體字段如下:rumorCode: 該條謠言的唯一編碼,可以通過該編碼直接訪問該謠言舉報頁面。title: 該條謠言被舉報的標題內容。informerName: 舉報者微博名稱。informerUrl: 舉報者微博鏈接。rumormongerName: 發布謠言者的微博名稱。rumormongerUr: 發布謠言者的微博鏈接。rumorText: 謠言內容。visitTimes: 該謠言被訪問次數。result: 該謠言審查結果。publishTime: 該謠言被舉報時間。related_url: 與該謠言相關的證據、規定等鏈接。
rumor_forward_comment中的json具體字段如下:uid: 發表用戶 ID。text: 評論或轉發附言文字。date: 發布時間。comment_or_forward: 二值,要么是comment,要么是forward,表示該條信息是評論還是轉發附言。
騰訊與丁香園不實信息內容格式為:
date: 時間explain: 謠言類型tag: 謠言標簽abstract: 用以驗證謠言的內容rumor: 謠言
-
數據預處理
通過
json.load()分別提取謠言微博數據weibo_data與 謠言評論轉發數據forward_comment_data,然后將其轉換為 DataFrame 格式。其中二者同名的文件,微博文章與微博評論轉發相對應,在處理rumor_forward_comment文件夾中的數據時,添加rumorCode以便后續匹配。# 文件路徑 weibo_dir = 'data/rumor/rumor_weibo' forward_comment_dir = 'data/rumor/rumor_forward_comment'# 初始化數據列表 weibo_data = [] forward_comment_data = []# 處理rumor_weibo文件夾中的數據 for filename in os.listdir(weibo_dir):if filename.endswith('.json'):filepath = os.path.join(weibo_dir, filename)with open(filepath, 'r', encoding='utf-8') as file:data = json.load(file)weibo_data.append(data)# 處理rumor_forward_comment文件夾中的數據 for filename in os.listdir(forward_comment_dir):if filename.endswith('.json'):filepath = os.path.join(forward_comment_dir, filename)with open(filepath, 'r', encoding='utf-8') as file:data = json.load(file)# 提取rumorCoderumor_code = filename.split('_')[1].split('.')[0]for comment in data:comment['rumorCode'] = rumor_code # 添加rumorCode以便后續匹配forward_comment_data.append(comment)# 轉換為DataFrame weibo_df = pd.DataFrame(weibo_data) forward_comment_df = pd.DataFrame(forward_comment_data)
2.2 謠言的定量統計分析
? 本節通過定量統計分析,使得對疫情謠言微博數據分布有具體的了解。
-
謠言被訪問次數統計
統計
weibo_df['visitTimes']訪問次數分布,并繪制對應的柱狀圖,結果如下。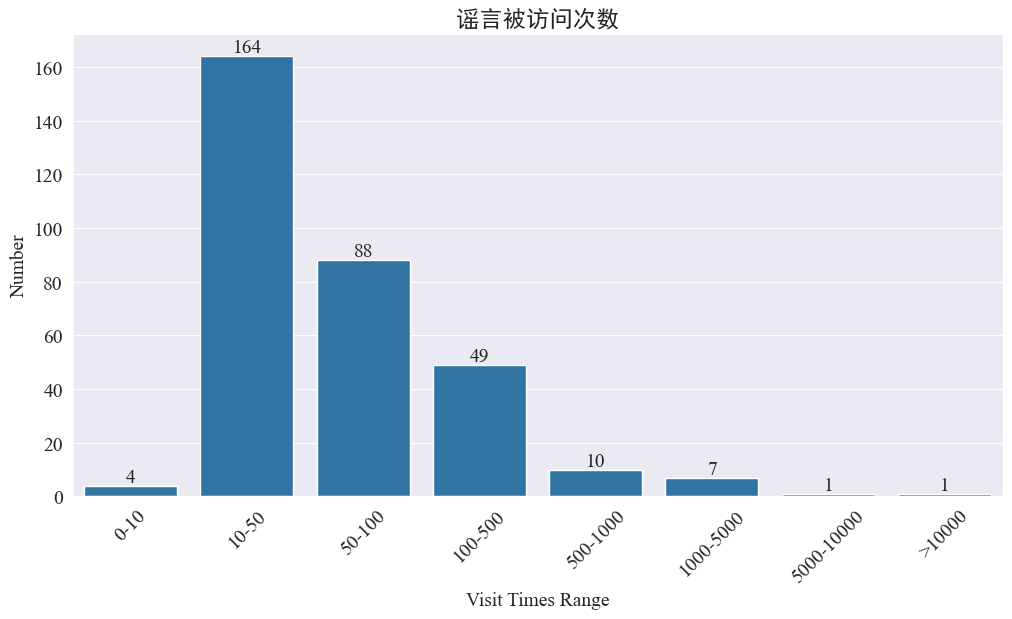
通過微博訪問次數得知,大部分疫情謠言微博訪問次數都在500次以內,其中10-50次的占比最多。但是也存在訪問大于5000次的謠言微博,屬于造成嚴重影響,在法律上達到 “情節嚴重” 的地步。
-
造謠者與舉報者出現次數統計
通過統計
weibo_df['rumormongerName']與weibo_df['informerName']得到每個發布謠言者發布謠言的數量與每個舉報者舉報謠言的數量,結果如下。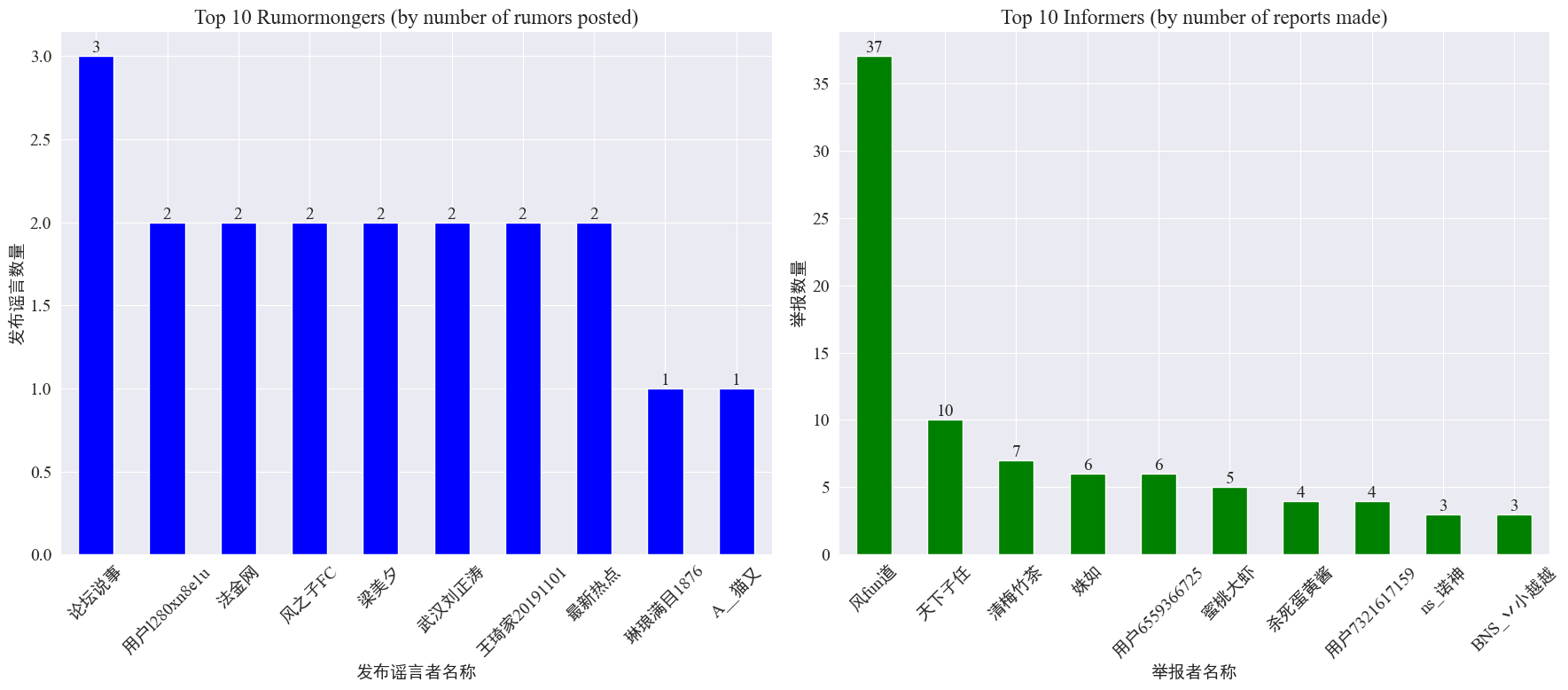
可以看到,發布造謠者發布謠言數量并不是集中在某幾個人上,而是比較平均,發布謠言最多的賬號發布了3篇謠言微博。而 Top10 舉報者每人至少舉報了而3篇謠言文章,其中舉報者 風fun道 舉報造謠微博數量顯著高于其他用戶,達到37篇。
根據以上數據,可以重點觀眾舉報謠言數量多的賬號,方便對謠言的偵測。
-
謠言轉發評論量分布統計
通過統計謠言轉發量與評論量分布,得到以下分布圖像。

可以看到,大部分謠言微博的評論與轉發數量都在10次以內,評論量最多不超過500個,而轉發量最多達到了10000以上。根據網絡管理法,謠言轉發量大于500,屬于 “情節嚴重” 情況。
2.3 謠言語義分析
-
謠言文本聚類分析
本部分通過對微博謠言文本進行數據預處理,分詞后,進行聚類分析,看看微博謠言集中在哪些方面。
-
數據預處理
首先對謠言數據文本進行清洗,去除缺省值,與
<>括起來的鏈接內容。# 去除缺失值 weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])def clean_text(text):# 定義正則表達式模式,匹配 <>pattern = re.compile(r'<.*?>')# 使用 sub 方法刪除匹配的部分cleaned_text = re.sub(pattern, '', text)return cleaned_textweibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)然后加載中文停用詞,停用詞采用 cn_stopwords ,利用
jieba實現對數據的分詞處理,并進行文本向量化。# 加載停用詞文件 with open('cn_stopwords.txt', encoding='utf-8') as f:stopwords = set(f.read().strip().split('\n'))# 分詞和去停用詞函數 def preprocess_text(text):words = jieba.lcut(text)words = [word for word in words if word not in stopwords and len(word) > 1]return ' '.join(words)# 應用到數據集 weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)# 文本向量化 vectorizer = TfidfVectorizer(max_features=10000) X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text']) -
確定最佳聚類
通過使用肘部法,確定最佳聚類。
肘部法(Elbow Method)是一種用于確定聚類分析中最佳聚類數目的方法。它基于誤差平方和(SSE,Sum of Squared Errors)與聚類數目之間的關系。SSE是聚類中所有數據點到其所屬聚類中心的歐氏距離的平方和,它反映了聚類的效果:SSE越小,表示聚類效果越好。
# 使用肘部法確定最佳聚類數量 def plot_elbow_method(X):sse = []for k in range(1, 21):kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')kmeans.fit(X)sse.append(kmeans.inertia_)plt.plot(range(1, 21), sse, marker='o')plt.xlabel('Number of clusters')plt.ylabel('SSE')plt.title('Elbow Method For Optimal k')plt.show()# 繪制肘部法圖 plot_elbow_method(X_tfidf)肘部法通過尋找“肘部”來確定最佳聚類數量,即在曲線上尋找一個點,這個點之后SSE下降的速率明顯減慢,這個點就像胳膊的肘部一樣,因此得名“肘部法”。這個點通常被認為是最佳的聚類數目。
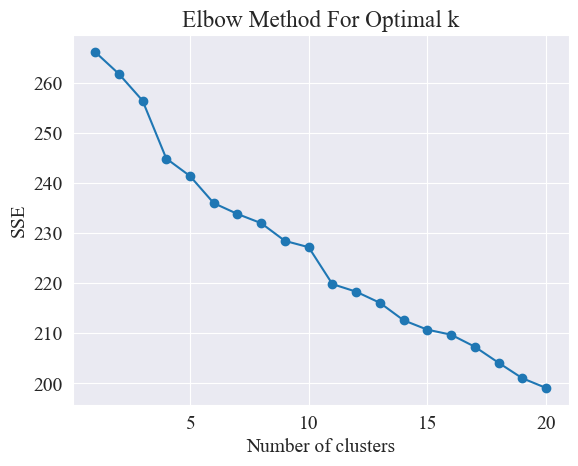
由上圖,確定肘部的聚類值為 11,繪制相應散點圖,結果如下。
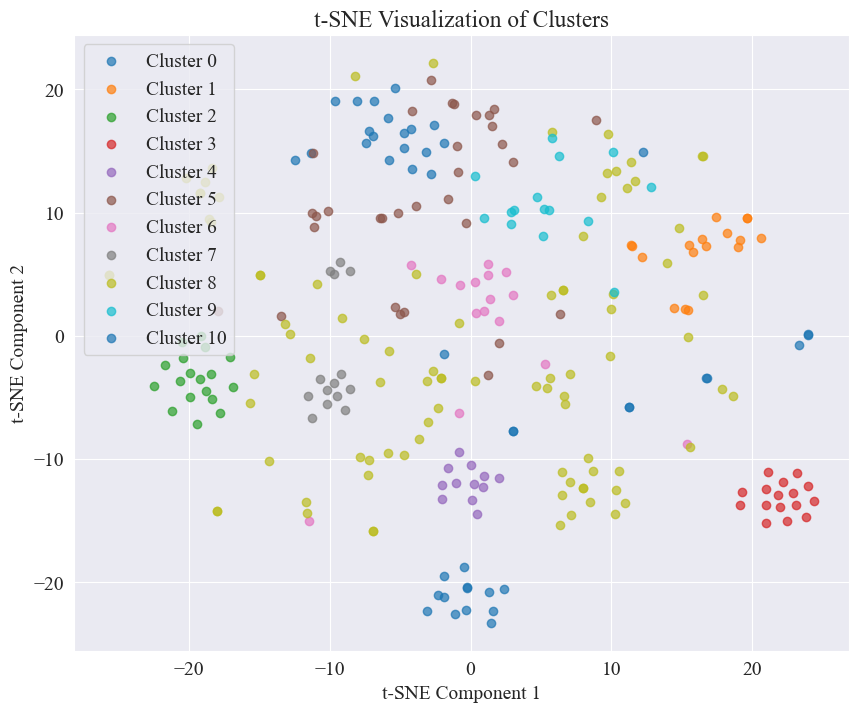
可以看出,大部分謠言微博進行了較好的聚類,3號與4號;也有的分布比較廣,沒有十分好的聚類,如5號,8號。
-
聚類結果
為了明顯的表示每個類都聚類了哪些謠言,將每個類都繪制一副云圖,結果如下。

打印出一些聚類較好的謠言微博內容,結果如下。
Cluster 2: 13 #封城日記#我的城市是湖北最后一個被封城的城市,金庸筆下的襄陽,郭靖黃蓉守城戰死的地方。至此... 17 #襄陽封城#最后一座城被封,自此,湖北封省。在這大年三十夜。春晚正在說,為中國七十年成就喝彩... 18 #襄陽封城#過會襄陽也要封城了,到O25號0點,湖北省全省封省 ,希望襄陽的疑似患者能盡快確... 19 截止2020年1月25日00:00時?湖北最后一個城市襄陽,整個湖北所有城市封城完畢,無公交... 21 #襄陽封城# 湖北省最后的一個城市于2020年1月25日零點零時零分正式封城至此,湖北省,封... Name: rumorText, dtype: objectCluster 3: 212 希望就在眼前…我期待著這一天早點到來。一刻都等不及了…西安學校開學時間:高三,初三,3月2日... 213 學校開學時間:高三,初三,3月2日開學,高一,高二,初一,初二,3月9日開學,小學4一6年級... 224 #長春爆料#【馬上要解放了?真的假的?】長春學校開學時間:高三,初三,3月2日開學,高一,高... 225 有誰知道這是真的嗎??我們這些被困湖北的外地人到底什么時候才能回家啊!(市政府會議精神,3月... 226 山東鄒平市公布小道消息公布~:學校開學時間:高三,初三,3月2日開學,高一,高二,初一,初二... Name: rumorText, dtype: object
-
-
謠言審查結果聚類分析
通過謠言文本內容聚類可能對謠言內容分析表示還沒那么好,于是選擇對謠言審查結果聚類分析。
-
確定最佳聚類
使用肘部圖,確定最佳聚類。
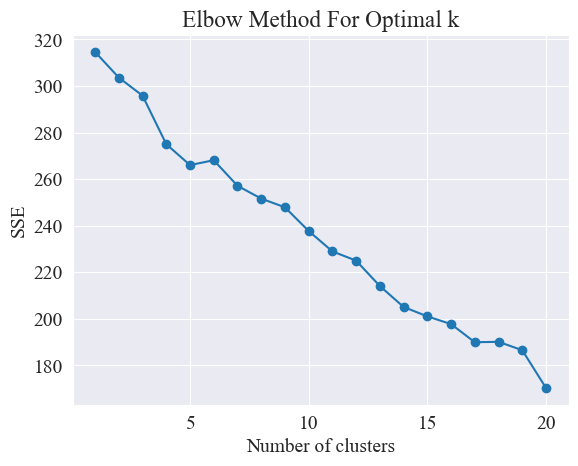
由以上肘部圖,可以確定兩個肘部,一個是在聚類為5時,一個是聚類位20時,我選擇20進行聚類。
聚20類得到的散點圖如下。
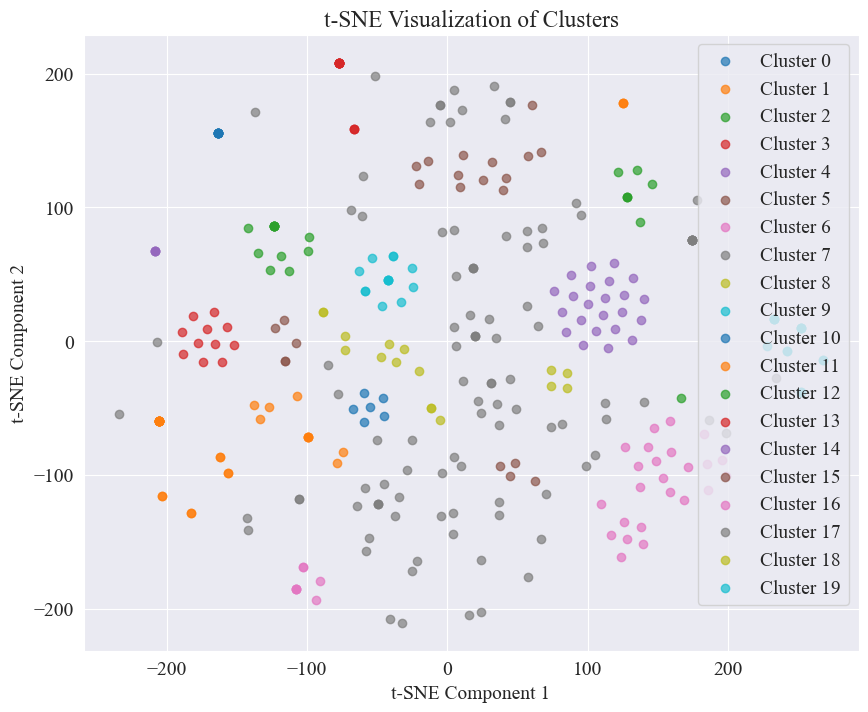
可以看到,大部分得到了很好聚類,但是第7類和17類沒有很好聚類。
-
聚類結果
為了明顯的表示每個類都聚類了哪些謠言審查結果,將每個類都繪制一副云圖,結果如下。

打印出一些聚類較好的謠言審查結果內容,結果如下。
Cluster 4: 52 從武漢撤回來的日本人,迎接他們的是每個人一臺救護車,206人=206臺救護車 53 從武漢撤回來的日本人,迎接他們的是每個人一臺救護車,206人=206臺救護車 54 從武漢撤回來的日本人,迎接他們的是每個人一臺救護車,206人=206臺救護車 55 從武漢撤回來的日本人,迎接他們的是每個人一臺救護車,206人=206臺救護車 56 從武漢撤回來的日本人,迎接他們的是每個人一臺救護車,206人=206臺救護車 Name: result, dtype: objectCluster 10: 214 所有被啃噬、機化的肺組織都不會再恢復了,愈后會形成無任何肺功能的瘢痕組織 215 所有被啃噬、機化的肺組織都不會再恢復了,愈后會形成無任何肺功能的瘢痕組織 216 所有被啃噬、機化的肺組織都不會再恢復了,愈后會形成無任何肺功能的瘢痕組織 217 所有被啃噬、機化的肺組織都不會再恢復了,愈后會形成無任何肺功能的瘢痕組織 218 所有被啃噬、機化的肺組織都不會再恢復了,愈后會形成無任何肺功能的瘢痕組織 Name: result, dtype: objectCluster 15: 7 在福州,里面坐的是周杰倫 8 周杰倫去福州自備隔離倉 9 周杰倫去福州自備隔離倉 10 周杰倫福州演唱會,給自己整了個隔離艙 12 周杰倫福州演唱會,給自己整了個隔離艙 Name: result, dtype: object
-
2.4 謠言檢測
? 本次謠言檢測,選擇采用已經辟謠的數據集 fact.json 中的辟謠謠言與真實謠言進行對比相似度,選擇與謠言微博相似度最高的辟謠文章,作為謠言檢測的依據。
-
加載微博謠言數據和辟謠數據集
# 定義一個空的列表來存儲每個 JSON 對象 fact_data = []# 逐行讀取 JSON 文件 with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:for line in f:fact_data.append(json.loads(line.strip()))# 創建辟謠數據的 DataFrame fact_df = pd.DataFrame(fact_data) fact_df = fact_df.dropna(subset=['title']) -
使用預訓練的語言模型將微博謠言和辟謠標題編碼成嵌入向量
本次實驗使用
bert-base-chinese作為預訓練模型,進行模型訓練。并采用SimCSE模型,通過對比學習來提升句子語義的表示和相似度度量。# 加載SimCSE模型 model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2') # 加載到 GPU model.to('cuda')# 加載預訓練的NER模型 ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0) -
計算相似度
計算相似度選擇采用了SimCSE模型的句子嵌入和命名實體相似度計算綜合相似度。
-
extract_entities函數使用NER模型提取文本中的命名實體。# 提取命名實體 def extract_entities(text):entities = ner_pipeline(text)return {entity['word'] for entity in entities} -
entity_similarity函數計算兩個文本之間的命名實體相似度。# 計算命名實體相似度 def entity_similarity(text1, text2):entities1 = extract_entities(text1)entities2 = extract_entities(text2)if not entities1 or not entities2:return 0.0intersection = entities1.intersection(entities2)union = entities1.union(entities2)return len(intersection) / len(union) -
combined_similarity函數結合SimCSE模型的句子嵌入和命名實體相似度計算綜合相似度。# 結合句子嵌入相似度和實體相似度 def combined_similarity(text1, text2):embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()entity_sim = entity_similarity(text1, text2)return 0.5 * embed_sim + 0.5 * entity_sim
-
-
實現謠言檢測
通過對比相似度,實現謠言檢測機制。
def debunk_rumor(input_rumor):# 計算輸入謠言與所有辟謠標題的相似度similarity_scores = []for fact_text in fact_df['title']:similarity_scores.append(combined_similarity(input_rumor, fact_text))# 找到最相似的辟謠標題most_similar_index = np.argmax(similarity_scores)most_similar_fact = fact_df.iloc[most_similar_index]# 輸出辟謠判斷及依據print("微博謠言:", input_rumor)print(f"辟謠判斷:{most_similar_fact['explain']}")print(f"辟謠依據:{most_similar_fact['title']}")weibo_rumor = "據最新研究發現,此次新型肺炎病毒傳播途徑是華南海鮮市場進口的豺——一種犬科動物攜帶的病毒,然后傳給附近的狗,狗傳狗,狗傳人。狗不生病,人生病。人生病后又傳給狗,循環傳染。" debunk_rumor(weibo_rumor)輸出結果如下:
微博謠言: 據最新研究發現,此次新型肺炎病毒傳播途徑是華南海鮮市場進口的豺——一種犬科動物攜帶的病毒,然后傳給附近的狗,狗傳狗,狗傳人。狗不生病,人生病。人生病后又傳給狗,循環傳染。 辟謠判斷:尚無定論 辟謠依據:狗能感染新型冠狀病毒成功找到辟謠依據,給出辟謠判斷。
3 疫情相關中文新聞數據分析
3.1 數據處理
-
數據格式
本次實驗提供了疫情相關新聞數據集 CSDC-News,收集了2020年上半年的新聞與評論內容。數據集包含以下內容。
news │ ├─comment │ 01-01.txt │ 01-02.txt ... │ 03-08.txt └─data01-01.txt01-02.txt...08-31.txt數據文件夾中總共分為三個部分包括:
data,comment。data文件夾中包含了若干個文件,每個文件對應某個日期的數據,格式為json。這部分的內容對應新聞的正文數據(會隨著日期逐步更新),其中的字段包括:time:新聞發布的時間。title:新聞的標題。url:新聞的原地址鏈接。meta:新聞的正文信息,其中包括以下字段:content:新聞的正文內容。description:新聞的簡短描述。title:新聞的標題。keyword:新聞關鍵詞。type:新聞的類型。
comment文件夾中包含了若干個文件,每個文件對應某個日期的數據,格式為json。這部分的內容對應新聞的評論數據(評論數據和新聞正文數據之間可能會有一周左右的延遲),其中的字段包括:time:新聞發布的時間,與data文件夾內數據相對應。title:新聞的標題,與data文件夾內數據相對應。url:新聞的原地址鏈接,與data文件夾內數據相對應。comment:新聞的評論信息,該字段為一個數組,數組每一個元素包含如下信息:area:評論人地區。content:評論內容。nickname:評論人昵稱。reply_to:評論人回復對象,若無則代表不是回復。time:評論時間。
-
數據預處理
在對新聞文章數據
data數據預處理過程中,需要把meta中的內容釋放出來,存儲為DataFrame格式。# 加載新聞數據 def load_news_data(data_dir):news_data = []files = sorted(os.listdir(data_dir))for file in files:if file.endswith('.txt'):with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:daily_news = json.load(f)for news in daily_news:news_entry = {'time': news.get('time', 'NULL'),'title': news.get('title', 'NULL'),'url': news.get('url', 'NULL'),'content': news.get('meta', {}).get('content', 'NULL'),'description': news.get('meta', {}).get('description', 'NULL'),'keyword': news.get('meta', {}).get('keyword', 'NULL'),'meta_title': news.get('meta', {}).get('title', 'NULL'),'type': news.get('meta', {}).get('type', 'NULL')}news_data.append(news_entry)return pd.DataFrame(news_data)在對評論數據
comment數據預處理過程中,需要把comment中的內容釋放出來,存儲為DataFrame格式。# 加載評論數據 def load_comment_data(data_dir):comment_data = []files = sorted(os.listdir(data_dir))for file in files:if file.endswith('.txt'):with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:daily_comments = json.load(f)for comment in daily_comments:for com in comment.get('comment', []):comment_entry = {'news_time': comment.get('time', 'NULL'),'news_title': comment.get('title', 'NULL'),'news_url': comment.get('url', 'NULL'),'comment_area': com.get('area', 'NULL'),'comment_content': com.get('content', 'NULL'),'comment_nickname': com.get('nickname', 'NULL'),'comment_reply_to': com.get('reply_to', 'NULL'),'comment_time': com.get('time', 'NULL')}comment_data.append(comment_entry)return pd.DataFrame(comment_data) -
加載數據集
根據以上數據預處理函數,加載數據集。
# 數據文件夾路徑 news_data_dir = 'data/news/data/' comment_data_dir = 'data/news/comment/'# 加載數據 news_df = load_news_data(news_data_dir) comment_df = load_comment_data(comment_data_dir)# 展示加載的數據 print(f"新聞數據長度:{len(news_df)},評論數據:{len(comment_df)}")打印結果顯示,新聞數據長度:502550,評論數據:1534616。
3.2 新聞內容數據分析
-
新聞時間分布統計
分別統計
news_df的每月新聞文章數量與每時新聞文章數量,用柱狀圖與折線圖表示,結果如下。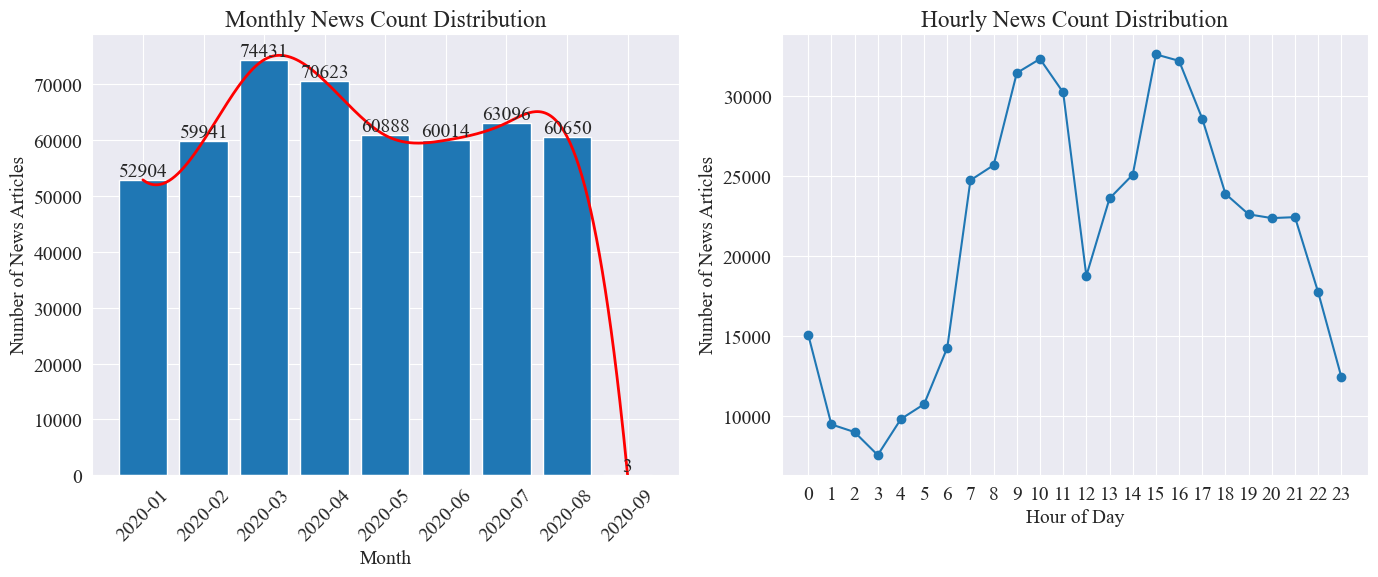
由上圖可知,隨著疫情的爆發,新聞數量逐月增加,在3月份達到頂峰,有7.4萬篇新聞,之后逐漸下降平穩到6萬篇每月,其中9月份數據為0點時的3篇,可不計入統計。
根據每小時新聞數量分布可知,每日的10點與15點是新聞發布的峰值,各發布了3萬篇以上。而12點為午休時間,新聞發布數呈現峰谷。每日0點到5點新聞發布數量最少,其中3點為最小點。
-
新聞熱點追蹤
本實驗打算采取提取新聞關鍵詞的方式,來對這8個月的新聞熱點進行追蹤。通過統計現有的關鍵詞分布,并繪制柱狀圖,結果如下。
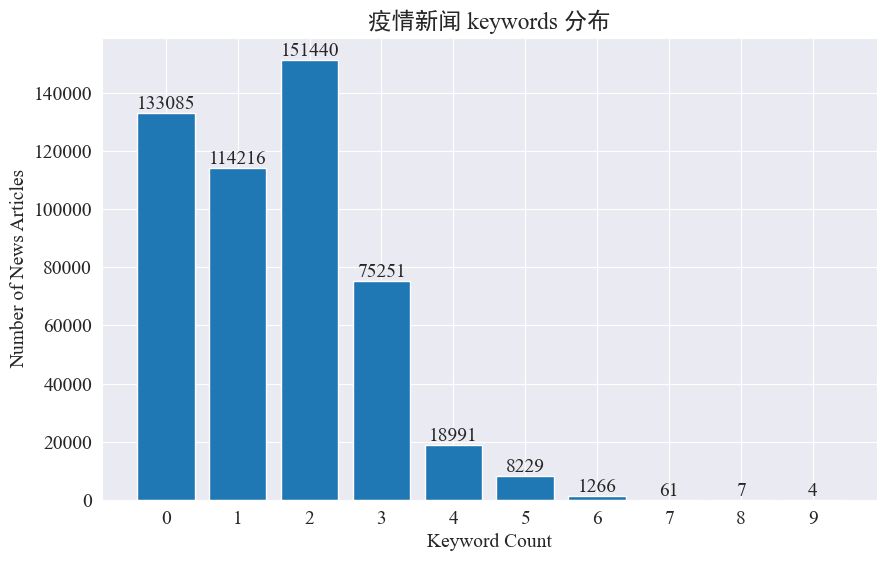
可以看出,大部分新聞文章的關鍵詞都在3個以內,甚至有大比例的文章沒有關鍵詞。因此,需要自己統計總結關鍵詞,用于進行熱點追蹤。本次使用
jieba.analyse.textrank()來統計關鍵詞。import jieba import jieba.analysedef extract_keywords(text):# 基于jieba的textrank算法實現keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)return ' '.join([keyword[0] for keyword in keywords])news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x)) keyword_data = news_df[['time','keyword','keyword_new']] keyword_data統計出5個新的關鍵詞,存到 keyword_new 中,然后將 keyword 與其合并,并去除重復的詞。
# 合并并去除重復的詞 def merge_keywords(row):# 將keyword列和keyword_new列合并keywords = set(row['keyword']) | set(row['keyword_new'].split())return ' '.join(keywords)keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1) keyword_data合并后打印
keyword_data,打印出的結果如下。
為了追蹤熱點,統計所有出現詞匯的詞頻,并統計到
keyword_data['rolling_keyword_freq']。# 按時間排序 keyword_data = keyword_data.sort_values(by='time')# 計算滾動頻率 def get_rolling_keyword_freq(df, window=7):rolling_keyword_freq = []for i in range(len(df)):start_time = df.iloc[i]['time'] - timedelta(days=window)end_time = df.iloc[i]['time']mask = (df['time'] > start_time) & (df['time'] <= end_time)recent_data = df.loc[mask]keywords = ' '.join(recent_data['merged_keywords']).split()keyword_counter = Counter(keywords)top_keywords = keyword_counter.most_common(20)rolling_keyword_freq.append(dict(top_keywords))return rolling_keyword_freqkeyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0) keyword_df = keyword_df.astype(int)# 將原始的時間列合并到新的DataFrame中 result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)# 保存為CSV文件 result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)然后根據以上統計數據,繪制每天的熱點詞匯變化圖。
# 讀取數據 file_path = './data/news/output/keyword_frequency.csv' data = pd.read_csv(file_path, parse_dates=['time'])# 聚合數據,按日期合并統計 data['date'] = data['time'].dt.date daily_data = data.groupby('date').sum().reset_index()# 準備顏色列表,確保每個關鍵詞都有不同的顏色 colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}def update(frame):plt.clf()date = daily_data['date'].iloc[frame]day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).Tday_data.columns = ['count']day_data = day_data.sort_values(by='count', ascending=False).head(10)bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])plt.xlabel('Count')plt.title(f'Keyword Frequency on {date}')for bar in bars:plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')plt.gca().invert_yaxis()# 創建動畫 fig = plt.figure(figsize=(10, 6)) anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)# 保存動畫 anim.save('keyword_trend.gif', writer='imagemagick')最終得到疫情新聞關鍵詞變化gif圖,結果如下。
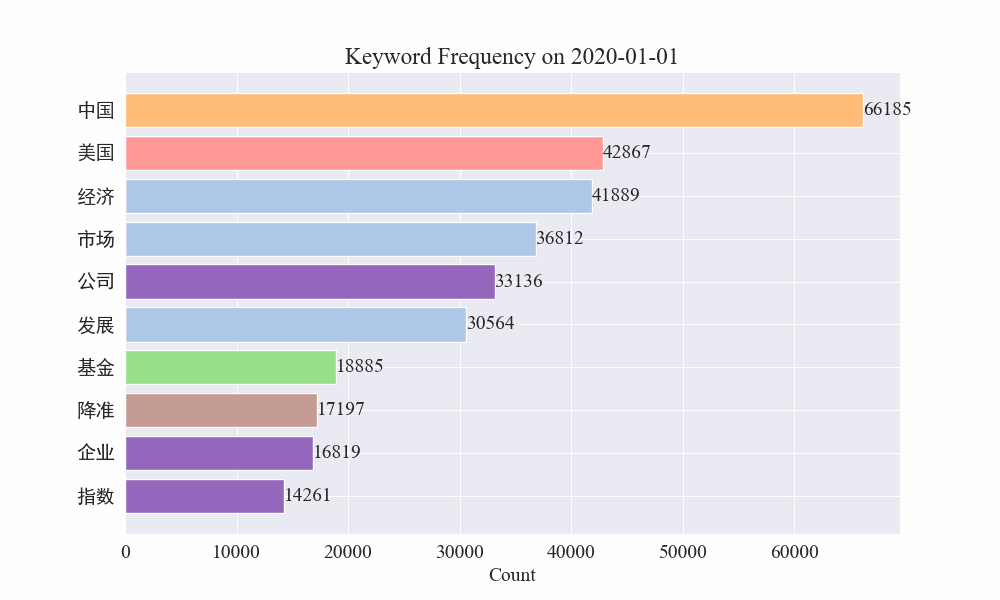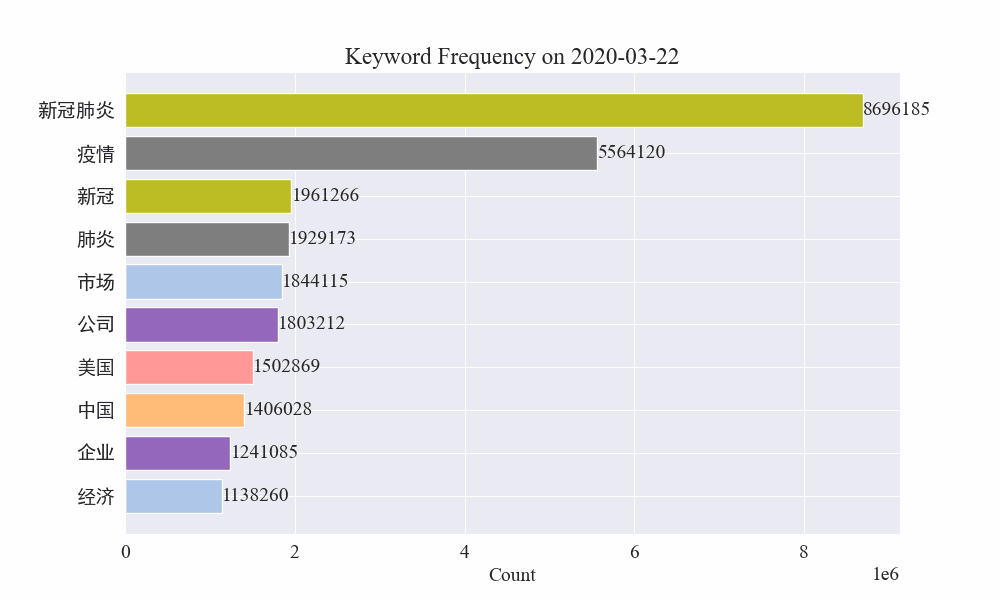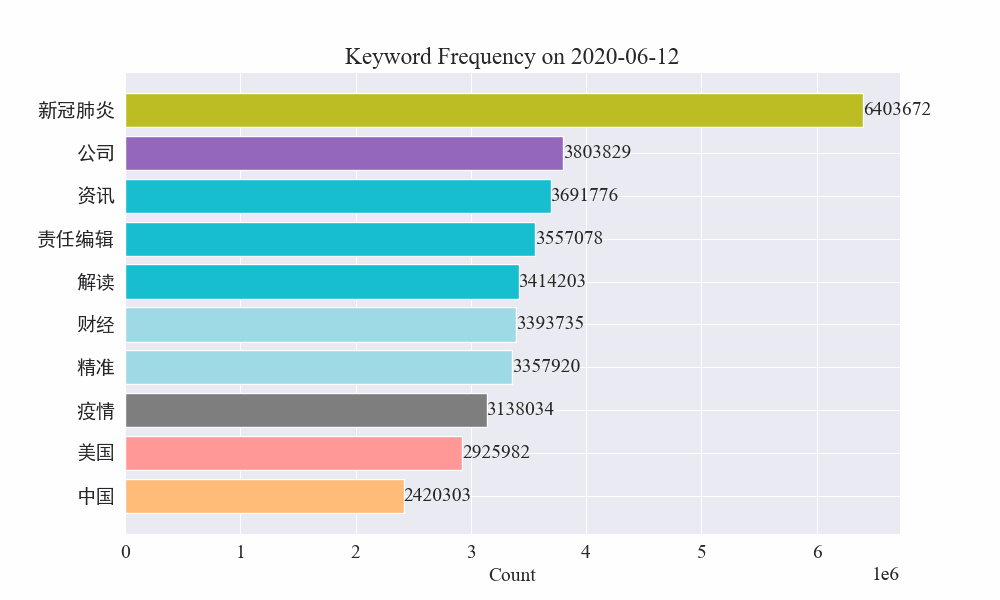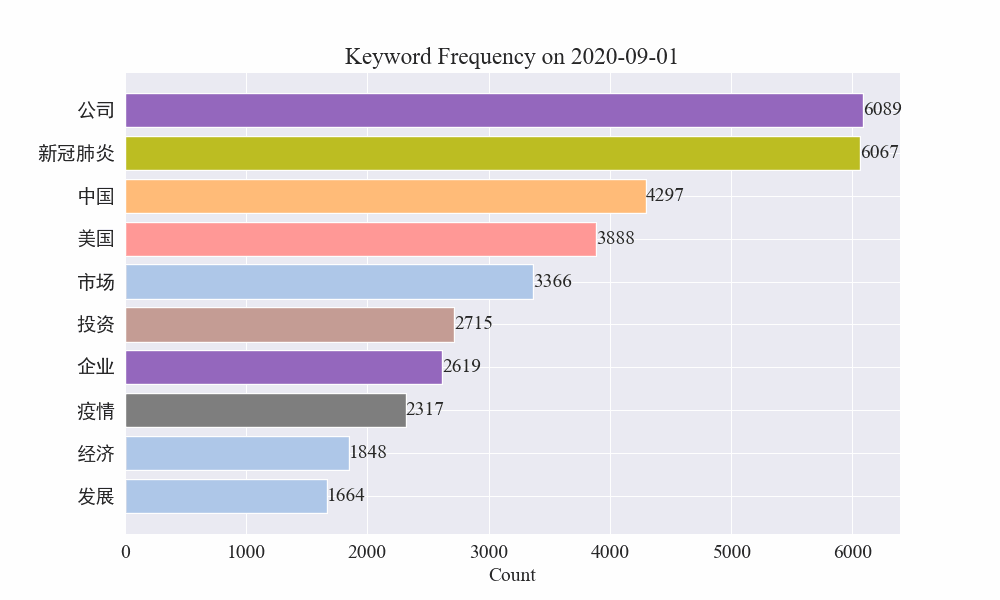
在疫情爆發之前,“公司”與“伊朗”詞條保持在高位。可以看到從疫情爆發之后,2月份開始疫情相關新聞數量飆升,之后"新冠肺炎"詞條飆升,持續保持在第一,直到8月底,第一波疫情放緩,變為第二。
3.3 新聞評論數據分析
? 本節對新聞評論先是進行定量統計分析,然后對不同評論進行情感分析。
-
每日新聞評論數量統計
統計新聞評論數量的走勢,用柱狀圖表示,并繪制近似曲線,代碼如下。
# 提取日期和小時信息 dates = [] hours = []for time_str in comment_df['news_time']:try:time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')dates.append(time_obj.strftime('%Y-%m-%d')) hours.append(time_obj.hour)except ValueError:pass# 統計每日新聞數量 daily_comment_counts = Counter(dates) daily_comment_counts = dict(sorted(daily_comment_counts.items()))# 統計每小時新聞數量 hourly_news_count = Counter(hours) hourly_news_count = dict(sorted(hourly_news_count.items()))# 繪制每月新聞數量分布柱狀圖 plt.figure(figsize=(14, 6))days = list(daily_comment_counts.keys()) comment_counts = list(daily_comment_counts.values()) bars = plt.bar(days, comment_counts, label='Daily Comment Count') plt.xlabel('Date') plt.ylabel('Comment Count') plt.title('Daily Comment Counts on News') plt.xticks(rotation=80, fontsize=10)# 繪制近似曲線 x = np.arange(len(days)) y = comment_counts spl = UnivariateSpline(x, y, s=100) xs = np.linspace(0, len(days) - 1, 500) ys = spl(xs) plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')plt.show()繪制得到每日新聞評論數量統計圖如下。
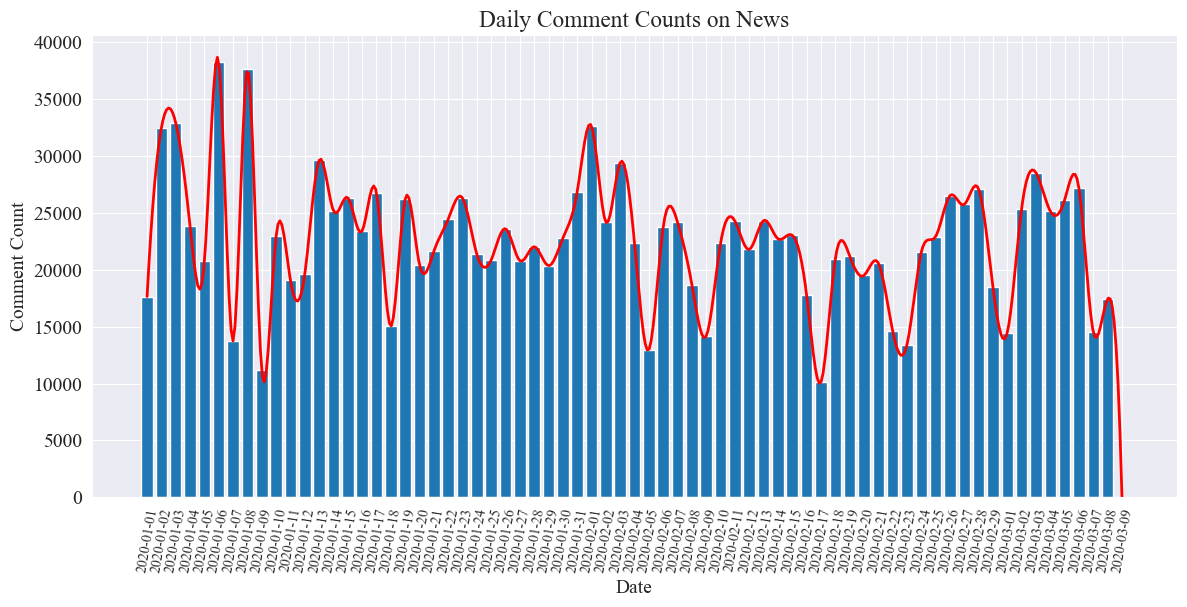
可以看到,疫情期間新聞評論數量在1萬到4萬之間波動,平均每日約為2萬條評論。
-
疫情新聞按地區統計
通過按照省份
comment_df['province']統計每省的新聞數量,統計各省疫情新聞評論數量。首先需要通過對
comment_df['province']提取省份信息。# 統計包含全國34個省、直轄市、自治區名稱的地域數據 province_name = ['北京', '天津', '上海', '重慶', '河北', '河南', '云南', '遼寧', '黑龍江', '湖南', '安徽', '山東', '新疆','江蘇', '浙江', '江西', '湖北', '廣西', '甘肅', '山西', '內蒙古', '陜西', '吉林', '福建', '貴州', '廣東','青海', '西藏', '四川', '寧夏', '海南', '臺灣', '香港', '澳門']# 提取省份信息 def extract_province(comment_area):for province in province_name:if province in comment_area:return provincereturn Nonecomment_df['province'] = comment_df['comment_area'].apply(extract_province)# 過濾出省份不為空的行 comment_df_filtered = comment_df[comment_df['province'].notnull()]# 統計每個省份的評論數量 province_counts = comment_df_filtered['province'].value_counts().to_dict()然后根據統計數據,繪制各省份新聞評論數量占比的餅狀圖。
# 計算總評論數量 total_comments = sum(province_counts.values())# 計算各省份評論數量占比 provinces = [] comments = [] labels = [] for province, count in province_counts.items():if count / total_comments >= 0.02:provinces.append(province)comments.append(count)labels.append(province + f" ({count})")# 繪制餅圖 plt.figure(figsize=(10, 8)) plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140) plt.title('各省疫情新聞評論數量占比') plt.axis('equal') # 保證餅圖是圓形 plt.show()
本次實驗,還采用
pyecharts.charts的Map組件,繪制了中國地圖按省份的評論數量分布圖。from pyecharts.charts import Map from pyecharts import options as opts# 省份簡稱到全稱的映射字典 province_full_name = {'北京': '北京市','天津': '天津市','上海': '上海市','重慶': '重慶市','河北': '河北省','河南': '河南省','云南': '云南省','遼寧': '遼寧省','黑龍江': '黑龍江省','湖南': '湖南省','安徽': '安徽省','山東': '山東省','新疆': '新疆維吾爾自治區','江蘇': '江蘇省','浙江': '浙江省','江西': '江西省','湖北': '湖北省','廣西': '廣西壯族自治區','甘肅': '甘肅省','山西': '山西省','內蒙古': '內蒙古自治區','陜西': '陜西省','吉林': '吉林省','福建': '福建省','貴州': '貴州省','廣東': '廣東省','青海': '青海省','西藏': '西藏自治區','四川': '四川省','寧夏': '寧夏回族自治區','海南': '海南省','臺灣': '臺灣省','香港': '香港特別行政區','澳門': '澳門特別行政區' }# 將省份名稱替換為全稱 full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}# 創建中國地圖 map_chart = (Map(init_opts=opts.InitOpts(width="1200px", height="800px")).add("評論數量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china").set_global_opts(title_opts=opts.TitleOpts(title="中國各省疫情新聞評論數量分布"),visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))) )# 渲染圖表為 HTML 文件 map_chart.render("comment_area_distribution.html")得到的HTML中,中國各省疫情新聞評論數量分布圖如下。
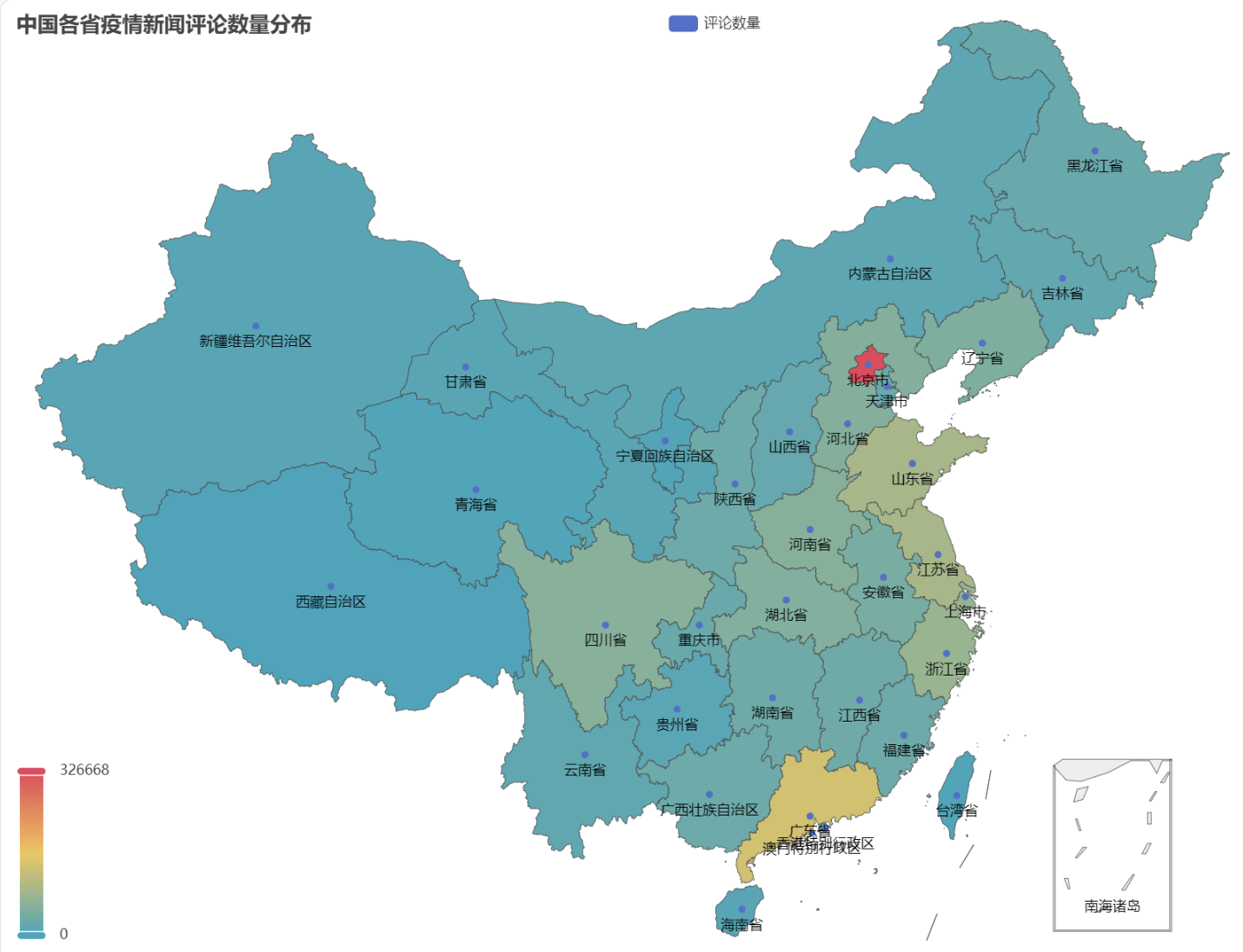
可以看到,疫情期間北京地區的評論數量占比最高,其次為廣東省,其他省份評論數量較為平均。
-
疫情評論情感分析
本次實驗通過使用用于處理中文文本的NLP庫
SnowNLP,實現中文情感分析,通過分析每一條評論,給出相應的sentiment值,該值在0到1之間,越接近1越積極,越接近0越消極。from snownlp import SnowNLP# 定義一個函數來計算情感得分,并處理可能的錯誤 def sentiment_analysis(text):try:s = SnowNLP(text)return s.sentimentsexcept ZeroDivisionError:return None# 對每條評論內容進行情感分析 comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)# 刪除情感得分為 None 的評論 comment_df = comment_df[comment_df['sentiment'].notna()]# 將評論按正向(sentiment > 0.5)和負向(sentiment < 0.5)分類 comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')本次實驗將0.5作為閾值,大于該值的為積極評論,小于該值的為消極評論。通過編寫代碼,繪制每日新聞評論情感分析圖,統計每日新聞的積極評論數與消極評論數,積極數量為正值,消極為負值。
# 提取新聞日期 comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date# 統計每一天的正向和負向評論數量 daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)# 繪制柱狀圖 plt.figure(figsize=(14, 8))# 繪制正向評論數量的柱狀圖 plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')# 繪制負向評論數量的柱狀圖(負數,以使其在 x 軸下方顯示) plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')# 添加標簽和標題 plt.xlabel('Date') plt.ylabel('Number of Comments') plt.title('Daily Sentiment Analysis of Comments') plt.legend()# 設置x軸刻度旋轉 plt.xticks(rotation=45)# 顯示圖表 plt.tight_layout() plt.show()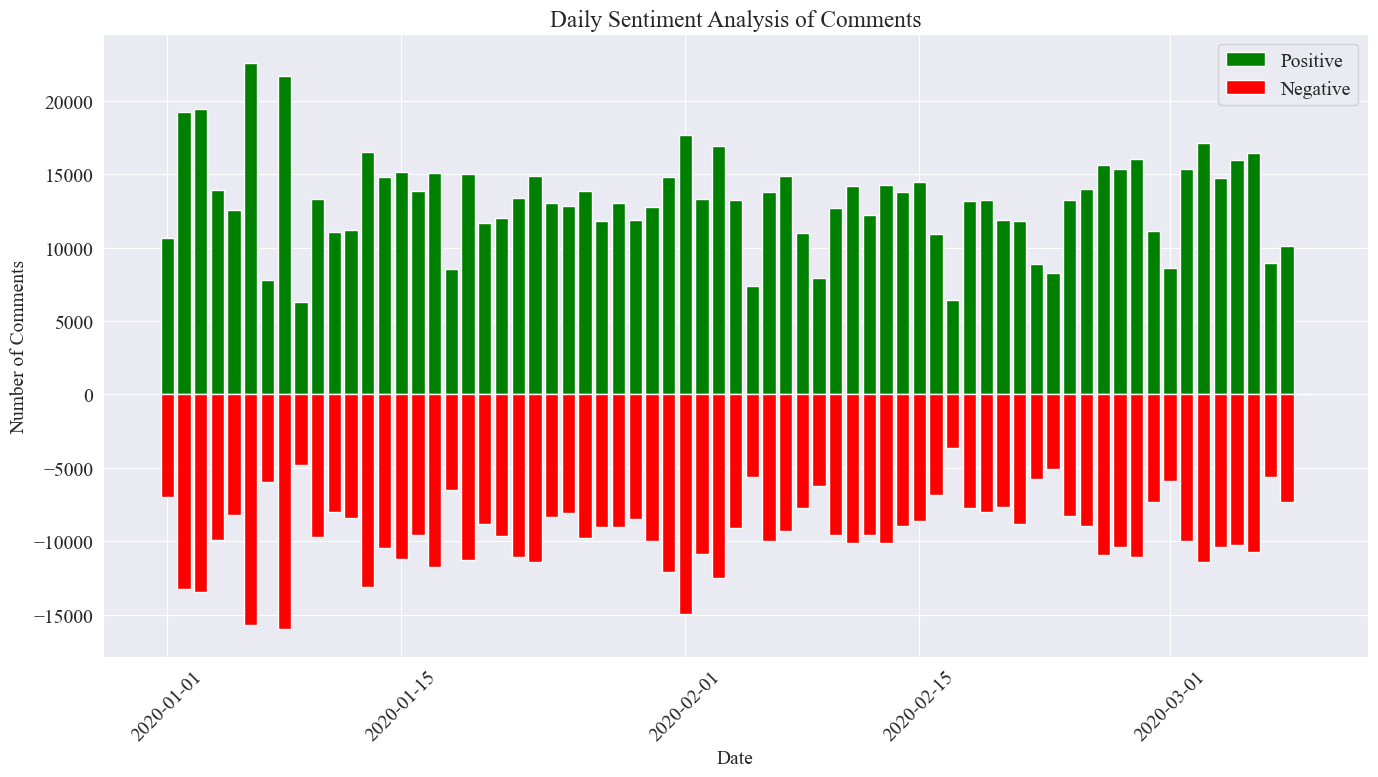
得到最終統計圖像如上,可以看出疫情期間積極評論略微高于消極評論,通過統計積極評論占比,得知積極評論占比為58.63%,說明民眾對疫情態度較為積極。
-
各地區評論情感分析
通過統計各省份地區發布評論的積極評論占比,得到各地區積極評論占比圖。
# 計算各地區的積極評論數量和總評論數量 area_sentiment_stats = comment_df.groupby('province').agg(total_comments=('comment_content', 'count'),positive_comments=('sentiment', lambda x: (x > 0.5).sum()) )# 計算各地區的積極評論占比 area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']# 繪制柱狀圖 plt.figure(figsize=(14, 7)) plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue') plt.xlabel('地區') plt.ylabel('積極評論占比') plt.title('各地區的積極評論占比') plt.xticks(rotation=90) plt.tight_layout() plt.show()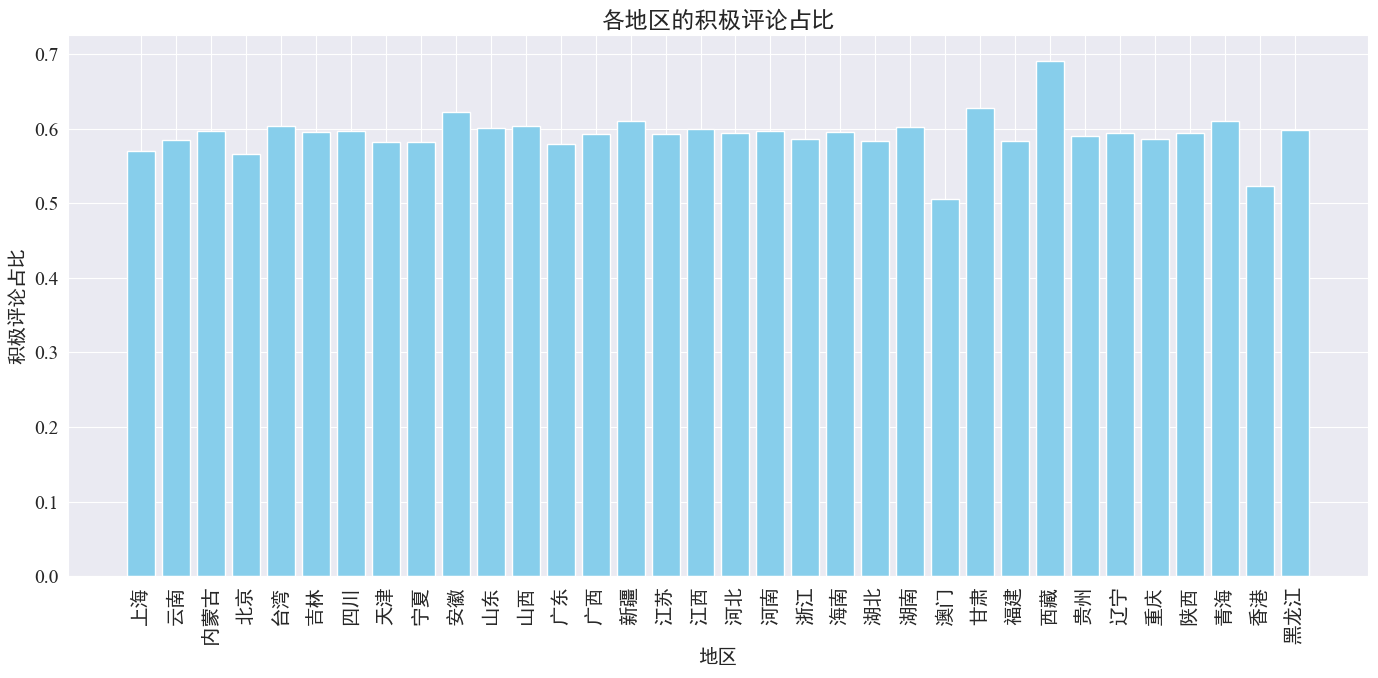
由上圖可知,大多數省份的積極評論占比在60%左右,其中香港、澳門的積極評論占比最低,約為50%,而西藏的積極評論占比最高,接近70%。
通過以上評論分布占比可知,大陸地區評論多為積極評論,而港澳地區消極評論明顯增多,其中西藏積極評論最高可能是因為西藏地區樣本量較少導致的誤差。
-
新聞評論詞云圖繪制
分別統計所有評論、積極評論與消極評論的詞云圖,在詞云圖繪制中,將積極評論列為0.6以上,消極評論列為0.4以下,以下為繪制的三張詞云圖。

可以看出,大部分人的疫情期間評論比較簡單,如“哈哈”、“good”等,積極評論中,可以看到“中國加油”,“武漢加油”等鼓勵文字,而消極評論中則有“呵呵”、“發國難財”等批評文字。


)

)



)




![[米聯客-安路飛龍DR1-FPSOC] FPGA基礎篇連載-14 SPI MASET發送程序設計](http://pic.xiahunao.cn/[米聯客-安路飛龍DR1-FPSOC] FPGA基礎篇連載-14 SPI MASET發送程序設計)
)


)
在3GPP系統中的增強支持(八)-通過無人機進行無線接入)
