語言模型真的能用于時序預測嗎?根據貝特里奇頭條定律(任何以問號結尾的新聞標題,都能夠用「不」來回答),答案應該是否定的。事實似乎也果然如此:強大如斯的 LLM 并不能很好地處理時序數據。
時序,即時間序列,顧名思義,是指一組按照時間發生先后順序進行排列的數據點序列。
在很多領域,時序分析都很關鍵,包括疾病傳播預測、零售分析、醫療和金融。在時序分析領域,近期不少研究者都在研究如何使用大型語言模型(LLM)來分類、預測和檢測時間序列中的異常。這些論文假設擅長處理文本中順序依賴關系的語言模型也能泛化用于時間序列數據中的順序依賴關系。這個假設并不令人意外,畢竟語言模型是現在機器學習領域的香餑餑。
那么,語言模型究竟能給傳統時序任務帶去多大助益?
近日,弗吉尼亞大學和華盛頓大學一個團隊嘗試解答了這一問題,并最終給出了一個簡單卻又重要的主張:對于時序預測任務,使用語言模型的常用方法的表現都接近或劣于基本的消融方法,但前者所需的計算量比后者多幾個數量級。

- 論文標題:Are Language Models Actually Useful for Time Series Forecasting?
- 論文地址:https://arxiv.org/pdf/2406.16964
這些發現是該團隊通過大量消融研究得到的,其中揭示出當前時序預測研究中存在一個「令人擔憂的趨勢」。
但該團隊也表示:「我們的目標并不是暗示語言模型永遠無法用于時間序列。」事實上,近期一些研究表明語言和時間序列之間具有很好的互動潛力,可以處理時間序列推理和社交理解等任務。
相反,他們的目標是強調這一驚人發現:對于已有的時間序列任務,現有方法幾乎沒有用到預訓練語言模型那與生俱來的推理能力。
實驗設置
該團隊使用了三種最先進的時間序列預測方法,并為 LLM 提出了三種消融方法:w/o LLM、LLM2Attn、LLM2Trsf。
為了評估 LLM 在時間序列預測任務上的有效性,他們在 8 個標準數據集上對這些方法進行了測試。
用于語言模型和時間序列的參考方法
他們實驗了三種近期的使用 LLM 進行時間序列預測的方法。見表 2,這些方法使用的基礎模型為 GPT-2 或 LLaMA,同時使用了不同的對齊和微調策略。

OneFitsAll:OneFitsAll(有時也被稱為 GPT4TS)方法會先對輸入時間序列使用實例歸一化和 patching 技術,然后將其饋送給一個線性層,以獲得用于語言模型的輸入表征。在訓練期間,語言模型的多頭注意力和前饋層會被凍結,而位置嵌入和層歸一化會得到優化。最終層的作用是將語言模型的最終隱藏狀態轉換成預測結果。
Time-LLM:使用 Time-LLM 時,輸入時間序列會被 patching 技術 token 化,并且多頭注意力會將其與詞嵌入的低維表征對齊。之后,將這個對齊過程的輸出與描述性統計特征的嵌入一起輸送給一個凍結的預訓練語言模型。然后,將該語言模型的輸出表征展平,并使其通過一個線性層,從而得到預測結果。
LLaTA:LLaTA 嵌入輸入時間序列的方式是將每個通道都視為一個 token。該架構的一半是「文本分支」,其使用交叉注意力來將時間序列表征與語言模型的詞嵌入的低維表征對齊。然后將該表征傳遞給一個凍結的預訓練語言模型,得到一個「文本式預測」。同時,該架構的「時間」分支會基于輸入時間序列為預訓練語言模型學習一個低秩適應器,從而得到一個用于推理的「時間預測」。該模型包含考慮這些表征之間的相似度的額外損失項。
該團隊提出的消融方法
對于基于 LLM 的預測器,為了將 LLM 的影響隔離開,該團隊提出了三種消融方法:移除 LLM 組件或將其替換成一個簡單模塊。
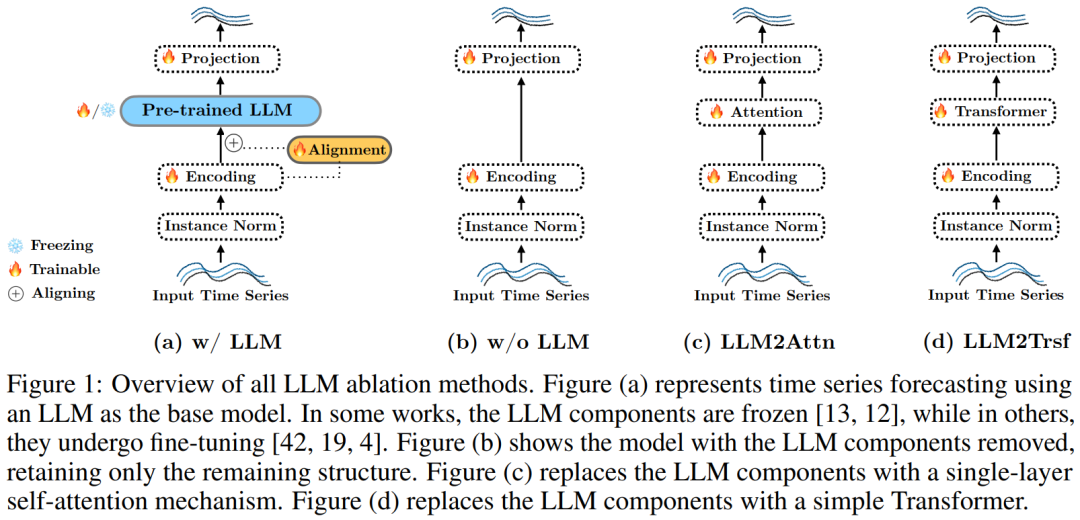
具體來說,對于上述三種方法中的每一種,他們都進行了以下三項修改:
w/o LLM,見圖 1b。完全移除語言模型,直接將輸入 token 傳遞給參考方法的最終層。
LLM2Attn,見圖 1c。將語言模型替換成單個隨機初始化的多頭注意力層。
LLM2Trsf,見圖 1d。將語言模型替換成單個隨機初始化的 Transformer 模塊。
在上述消融研究中,預測器的其余部分都保持不變(可訓練)。比如,如圖 1b 所示,在移除了 LLM 之后,輸入編碼會被直接傳遞給輸出映射。而如圖 1c 和 1d 所示,在將 LLM 替換成注意力或 Transformer 后,它們會與原始方法的剩余結構一起獲得訓練。
數據集和評估指標
基準數據集。評估使用了以下真實世界數據集:ETT(其包含 4 個子集:ETTm1、ETTm2、ETTh1、ETTh2)、Illness、Weather、Traffic、Electricity。表 1 給出了這些數據集的統計情況。另外還有 Exchange Rate、Covid Deaths、Taxi (30 min)、NN5 (Daily) 和 FRED-MD。

評估指標。該研究報告的評估指標是預測時序值和真實時序值之間的平均絕對誤差(MAE)和均方誤差(MSE)。
結果
具體來說,該團隊探究了以下研究問題(RQ):
- (RQ1)預訓練語言模型是否有助于提升預測性能?
- (RQ2)基于 LLM 的方法是否值得其消耗的計算成本?
- (RQ3)語言模型預訓練是否有助于執行預測任務的性能?
- (RQ4)LLM 能否表征時間序列中的順序依賴關系?
- (RQ5)LLM 是否有助于少樣本學習?
- (RQ6)性能從何而來?
預訓練語言模型是否有助于提升預測性能?(RQ1)
實驗結果表明,預訓練 LLM 對時間序列預測任務來說還不是很有用。
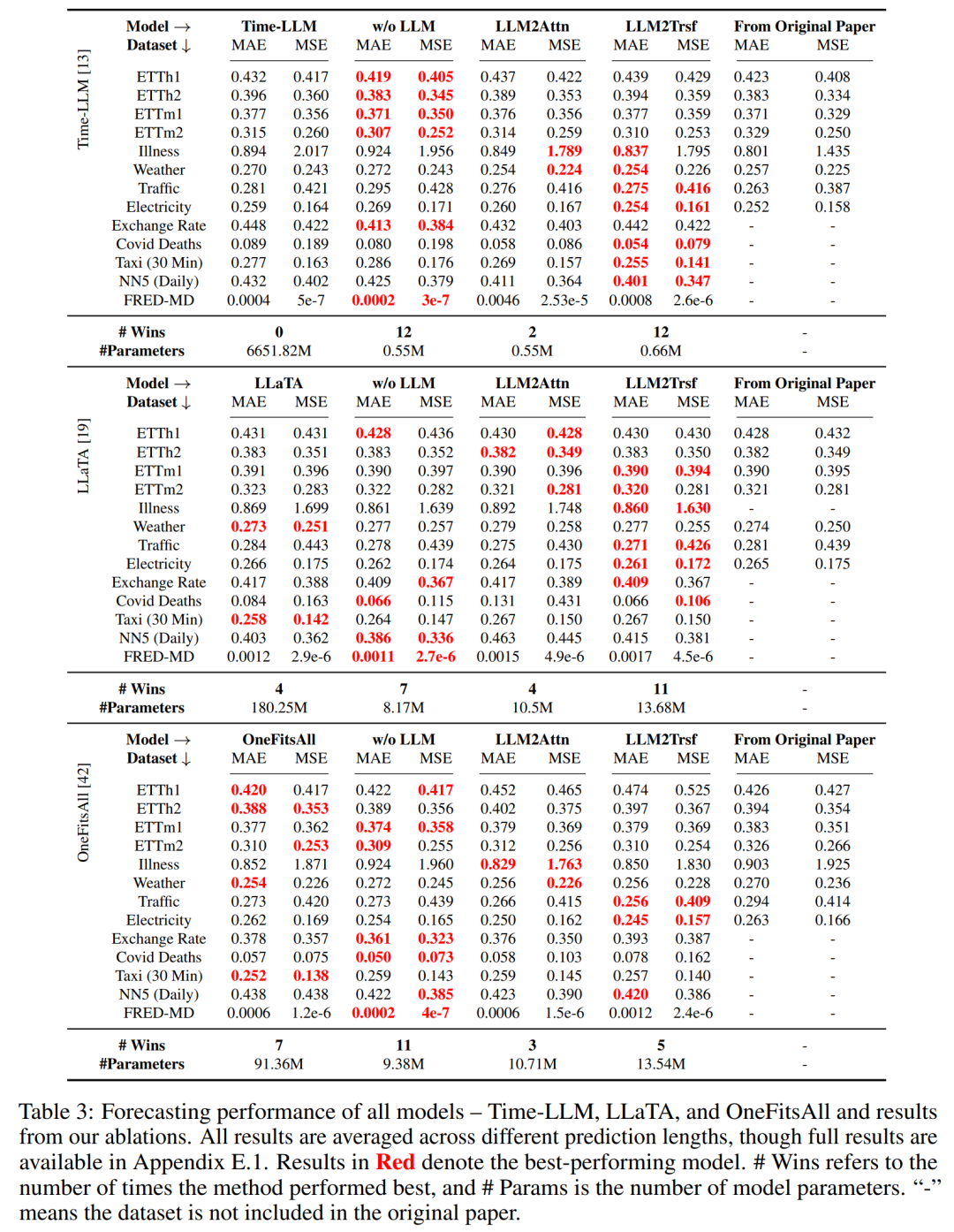

總體而言,如表 3 所示,在 8 個數據集和 2 個指標上,消融方法在 26/26 案例中優于 Time-LLM 方法,在 22/26 案例中優于 LLaTA,在 19/26 案例中優于 OneFitsAll。
總之,很難說 LLM 可以有效地用于時間序列預測。
基于 LLM 的方法是否值得其消耗的計算成本?(RQ2)
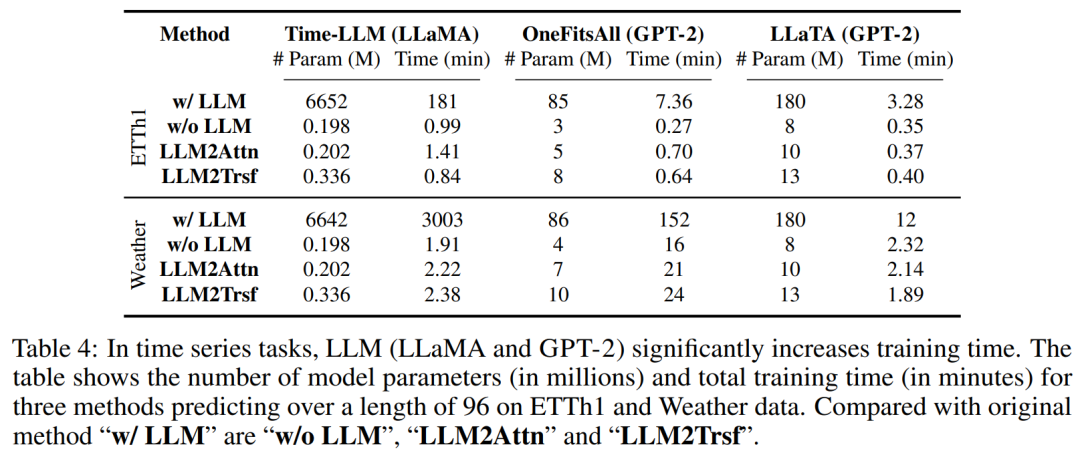
這里,根據這些方法的名義性能來評估它們的計算強度。參考方法中的語言模型使用了數億乃至數十億參數來執行時間序列預測。即使當這些語言模型的參數凍結時,它們在訓練和推理時依然會有很大的計算開銷。
舉個例子,Time-LLM 有 6642 M 參數,在 Weather 數據集上耗時 3003 分鐘才完成訓練,而消融方法僅有 0.245 M 參數,平均訓練時間僅有 2.17 分鐘。表 4 給出了在 ETTh1 和 Weather 數據集上訓練其它方法的相關信息。
至于推理時間,這里的做法是除以最大批量大小,以估計每個示例的推理時間。平均而言,相比于修改后的模型,Time-LLM、OneFitsAl、LLaTA 所用的推理時間多 28.2、2.3、1.2 倍。
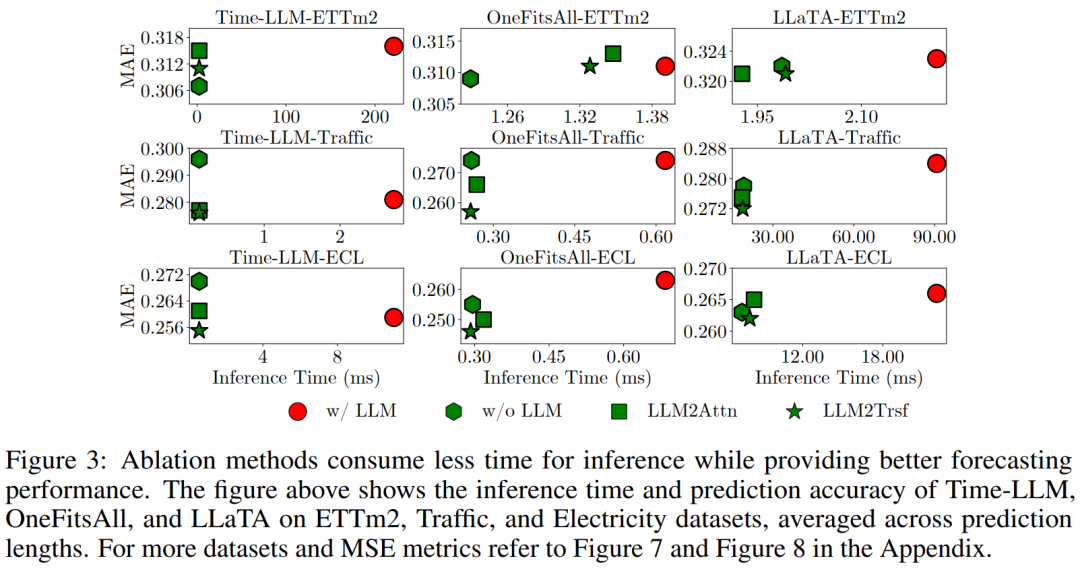
圖 3 給出了一些示例,其中綠色標記(消融方法)通常低于紅色標記(LLM),并且集中于左側,這說明它們計算成本更低但預測性能更好。
總之,在時間序列預測任務上,LLM 的計算強度無法為性能帶來相應的提升。
語言模型預訓練是否有助于執行預測任務的性能?(RQ3)
評估結果表明,對于時間序列預測任務而言,使用大型數據集進行預訓練實在沒有必要。為了檢驗預訓練期間學到的知識能否給預測性能帶來有意義的提升,該團隊實驗了在時間序列數據上,對 LLaTA 進行不同組合的預訓練和微調的效果。
- 預訓練 + 微調(Pre+FT):這是原始方法,即在時間序列數據上微調預訓練語言模型。對于這里的 LLaTA,做法是凍結基礎語言模型,學習一個低秩適應器(LoRA)。
- 隨機初始化 + 微調(woPre+FT):預訓練得到的文本知識是否有助于時間序列預測?這里,隨機初始化語言模型的權重(由此清除了預訓練的效果),再在微調數據集上從頭開始訓練 LLM。
- 預訓練 + 不使用微調(Pre+woFT):在時間序列數據上進行微調又能給預測性能帶來多大提升呢?這里是凍結語言模型,同時放棄學習 LoRA。這能反映語言模型自身處理時間序列的性能。
- 隨機初始化 + 無微調(woPre+woFT):很明顯,這就是將輸入時間序列隨機投射到一個預測結果。該結果被用作與其它方法進行比較的基準。
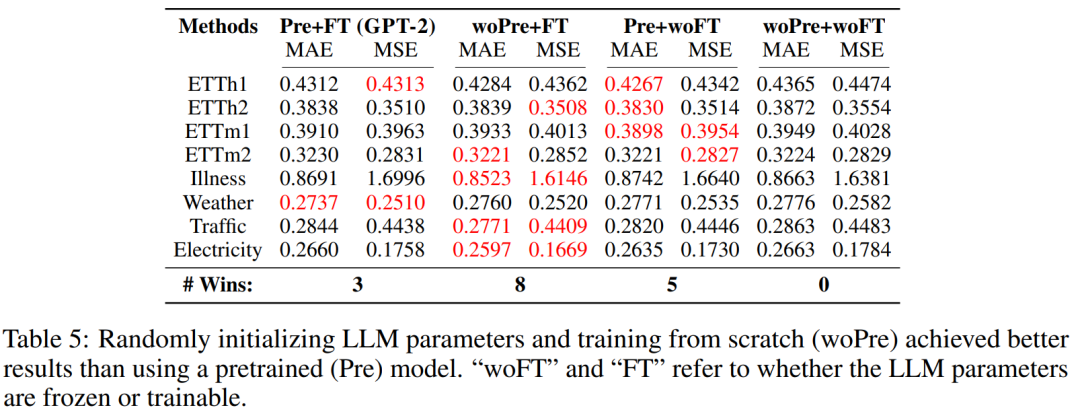
整體結果見表 5。在 8 個數據集上,依照 MAE 和 MSE 指標,「預訓練 + 微調」有三次表現最佳,而「隨機初始化 + 微調」獲得了 8 次最佳。這說明語言知識對時間序列預測的幫助有限。但是,「預訓練 + 無微調」與基準「隨機初始化 + 無微調」各自有 5 和 0 次最佳,這說明語言知識對微調過程的幫助也不大。
總之,預訓練得到的文本知識對時間序列預測的幫助有限。
LLM 能否表征時間序列中的順序依賴關系?(RQ4)
大多數使用 LLM 來微調位置編碼的時間序列預測方法都有助于理解序列中時間步驟的位置。該團隊預計,對于一個有優良位置表征的時間序列模型,如果將輸入的位置打亂,那么其預測性能將會大幅下降。他們實驗了三種打亂時間序列數據的方法:隨機混洗整個序列(sf-all)、僅隨機混洗前一半序列(sf-half)、交換序列的前半和后半部分(ex-half)。結果見表 6。
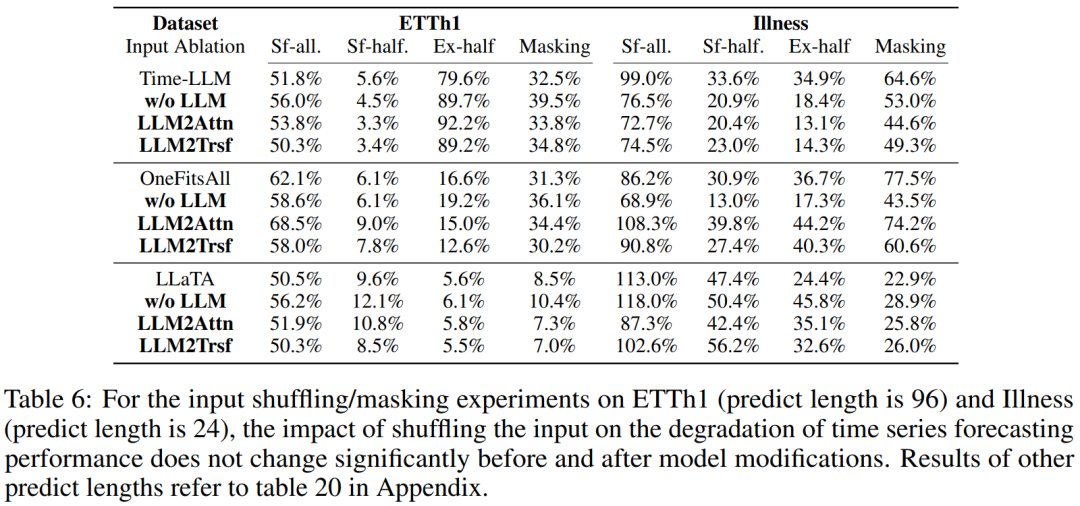
輸入混洗對基于 LLM 的方法與其消融方法的影響差不太多。這說明 LLM 在表征時間序列中的順序依賴關系方面并沒有什么突出能力。
LLM 是否有助于少樣本學習?(RQ5)
評估結果表明,LLM 對少樣本學習場景而言意義不大。
他們的評估實驗是取用每個數據集的 10%,再訓練模型及其消融方法。具體來說,這里評估的是 LLaMA(Time-LLM)。結果見表 7。
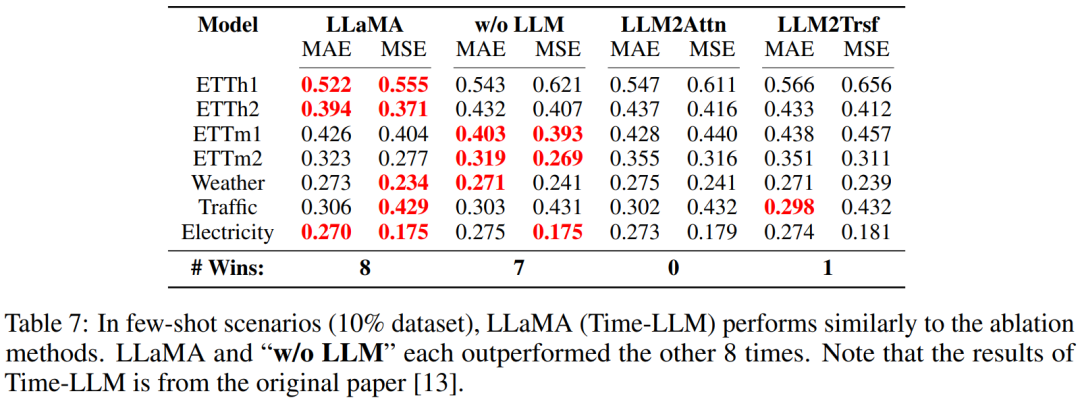
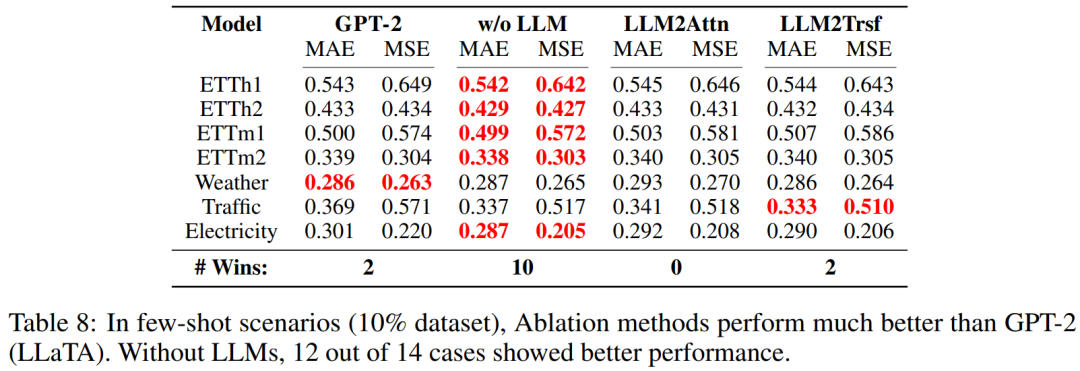
可以看到,有無 LLM 的表現差不多 —— 各自都有 8 個案例表現更好。該團隊也使用基于 GPT-2 的方法 LLaTA 進行了類似的實驗。結果見表 8,這里消融方法在少樣本場景中的表現還優于 LLM。
性能從何而來?(RQ6)
這一節評估的是 LLM 時間序列模型中常用的編碼技術。結果發現,將 patching 和單層注意力組合起來是一種簡單卻有效的選擇。
前面發現對基于 LLM 的方法進行簡單的消融并不會降低其性能。為了理解這一現象的原因,該團隊研究了 LLM 時間序列任務中常用的一些編碼技術,比如 patching 和分解。一種基本的 Transformer 模塊也可用于輔助編碼。
結果發現,一種組合了 patching 和注意力的結構在小數據集(時間戳少于 100 萬)上的表現優于其它大部分編碼方法,甚至能與 LLM 方法媲美。
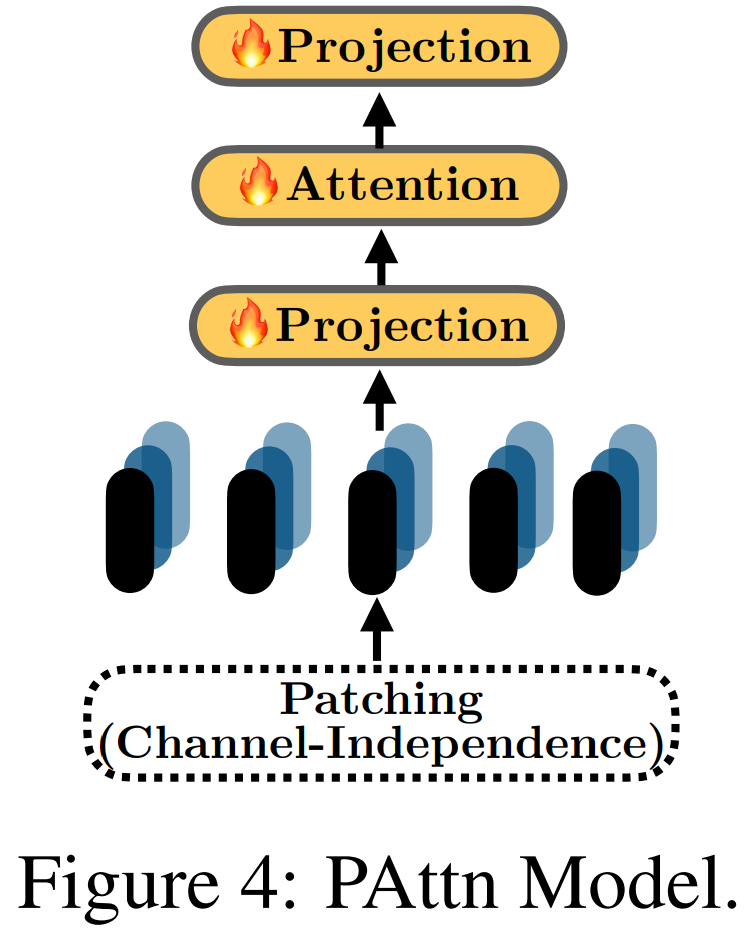
其詳細結構如圖 4 所示,其中涉及將「實例歸一化」用于時間序列,然后進行 patching 和投射。然后,在 patch 之間使用一層注意力進行特征學習。對于 Traffic(約 1500 萬)和 Electricity(約 800 萬)等更大的數據集,則使用了基本 Transformer 的單層線性模型的編碼表現更優。在這些方法中,最后還要使用單層線性層來投射時間序列嵌入,從而得到預測結果。
總之,patching 對編碼而言非常重要。此外,基本的注意力和 Transformer 模塊也能為編碼帶來有效助益。
如何學習大模型 AI ?
由于新崗位的生產效率,要優于被取代崗位的生產效率,所以實際上整個社會的生產效率是提升的。
但是具體到個人,只能說是:
“最先掌握AI的人,將會比較晚掌握AI的人有競爭優勢”。
這句話,放在計算機、互聯網、移動互聯網的開局時期,都是一樣的道理。
我在一線互聯網企業工作十余年里,指導過不少同行后輩。幫助很多人得到了學習和成長。
我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。

第一階段(10天):初階應用
該階段讓大家對大模型 AI有一個最前沿的認識,對大模型 AI 的理解超過 95% 的人,可以在相關討論時發表高級、不跟風、又接地氣的見解,別人只會和 AI 聊天,而你能調教 AI,并能用代碼將大模型和業務銜接。
- 大模型 AI 能干什么?
- 大模型是怎樣獲得「智能」的?
- 用好 AI 的核心心法
- 大模型應用業務架構
- 大模型應用技術架構
- 代碼示例:向 GPT-3.5 灌入新知識
- 提示工程的意義和核心思想
- Prompt 典型構成
- 指令調優方法論
- 思維鏈和思維樹
- Prompt 攻擊和防范
- …
第二階段(30天):高階應用
該階段我們正式進入大模型 AI 進階實戰學習,學會構造私有知識庫,擴展 AI 的能力。快速開發一個完整的基于 agent 對話機器人。掌握功能最強的大模型開發框架,抓住最新的技術進展,適合 Python 和 JavaScript 程序員。
- 為什么要做 RAG
- 搭建一個簡單的 ChatPDF
- 檢索的基礎概念
- 什么是向量表示(Embeddings)
- 向量數據庫與向量檢索
- 基于向量檢索的 RAG
- 搭建 RAG 系統的擴展知識
- 混合檢索與 RAG-Fusion 簡介
- 向量模型本地部署
- …
第三階段(30天):模型訓練
恭喜你,如果學到這里,你基本可以找到一份大模型 AI相關的工作,自己也能訓練 GPT 了!通過微調,訓練自己的垂直大模型,能獨立訓練開源多模態大模型,掌握更多技術方案。
到此為止,大概2個月的時間。你已經成為了一名“AI小子”。那么你還想往下探索嗎?
- 為什么要做 RAG
- 什么是模型
- 什么是模型訓練
- 求解器 & 損失函數簡介
- 小實驗2:手寫一個簡單的神經網絡并訓練它
- 什么是訓練/預訓練/微調/輕量化微調
- Transformer結構簡介
- 輕量化微調
- 實驗數據集的構建
- …
第四階段(20天):商業閉環
對全球大模型從性能、吞吐量、成本等方面有一定的認知,可以在云端和本地等多種環境下部署大模型,找到適合自己的項目/創業方向,做一名被 AI 武裝的產品經理。
- 硬件選型
- 帶你了解全球大模型
- 使用國產大模型服務
- 搭建 OpenAI 代理
- 熱身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地計算機運行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何優雅地在阿里云私有部署開源大模型
- 部署一套開源 LLM 項目
- 內容安全
- 互聯網信息服務算法備案
- …
學習是一個過程,只要學習就會有挑戰。天道酬勤,你越努力,就會成為越優秀的自己。
如果你能在15天內完成所有的任務,那你堪稱天才。然而,如果你能完成 60-70% 的內容,你就已經開始具備成為一名大模型 AI 的正確特征了。
這份完整版的大模型 AI 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】

多功能TinUIxml編輯器)










在3GPP系統中的增強支持(十三)-更換無人機控制器)

![[計網初識2]web的3個核心標準html,url,http](http://pic.xiahunao.cn/[計網初識2]web的3個核心標準html,url,http)
詳解)


)

)