Redis 的多路IO復用
多路I/O復用是一種同時監聽多個文件描述符(如Socket)的狀態變化,并能在某個文件描述符就緒時執行相應操作的技術。在Redis中,多路I/O復用技術主要用于處理客戶端的連接請求和讀寫操作,以實現高并發、高性能的服務。Redis支持多種多路I/O復用機制,包括select、poll、epoll和kqueue等。其中,epoll是Linux系統下性能最好的一種機制,Redis在Linux系統下默認使用epoll。
-
select機制?
select是最早的多路I/O復用機制,通過調用select函數來監視多個文件描述符的狀態變化。但是,select機制存在性能瓶頸和文件描述符數量限制的問題。在高并發場景下,select機制的性能會受到較大影響。
-
poll機制?
poll機制是對select機制的改進,解決了文件描述符數量限制的問題。但是,poll機制在大量文件描述符的情況下仍然存在性能瓶頸。
-
epoll機制?
epoll是Linux特有的I/O多路復用機制,采用事件驅動的方式,通過epoll_ctl函數注冊文件描述符的事件,然后通過epoll_wait函數等待I/O事件的發生。epoll機制在處理大量連接時具有更好的擴展性和性能。Redis在Linux系統下默認使用epoll機制。
Redis 單線程抗高QPS的原因
Redis作為一個單線程的內存數據庫,卻能夠抗住如此高的QPS(每秒查詢率),這主要得益于以下幾個方面:
-
非阻塞I/O與多路I/O復用?
Redis采用了非阻塞I/O與多路I/O復用技術,使得單個線程可以同時處理多個客戶端的連接請求和讀寫操作。當某個文件描述符就緒時,Redis會立即執行相應的操作,而不會阻塞整個線程。這種機制大大提高了Redis的并發處理能力。
-
純內存操作?
Redis的所有數據都存儲在內存中,因此讀寫操作都非常快。相比于磁盤數據庫,Redis的讀寫性能要高出幾個數量級。這也是Redis能夠抗住高QPS的重要原因之一。
-
高效的?數據結構
Redis內部使用了多種高效的數據結構,如哈希表、跳表、整數集合等。這些數據結構在存儲和查詢數據時都具有較高的性能。同時,Redis還針對這些數據結構進行了大量的優化,以確保在高并發場景下仍然能夠保持穩定的性能。
-
單線程避免了?線程切換和加鎖的開銷
雖然多線程可以提高系統的并行處理能力,但同時也帶來了線程切換和加鎖的開銷。Redis采用單線程模型,避免了這些開銷,使得Redis在處理單個請求時更加高效。此外,單線程模型也使得Redis的編程模型相對簡單,易于維護和管理。
Redis在實際應用中抗住高QPS的關鍵在于其內部設計、數據結構的高效利用以及配置優化。
1. 內部設計
多路I/O復用
- ?機制:Redis通過多路I/O復用技術(如epoll在Linux系統中)實現同時監聽多個客戶端連接,當某個連接準備就緒時,Redis會立即處理,無需等待或輪詢其他連接。
- 假設Redis服務器同時處理1萬個客戶端連接,當有100個連接同時發送請求時,Redis不會逐一檢查每個連接,而是通過epoll機制立即處理這100個連接,從而實現高效并發。
單線程模型
- ?Redis采用單線程模型,避免了多線程間的競爭和鎖的開銷,使得每個請求都能得到快速處理。
- 在高并發場景下,多線程模型可能因為線程切換和鎖的競爭而導致性能下降。而Redis的單線程模型能夠確保每個請求都在同一線程中處理,從而避免了這些開銷。?
2. 數據結構的高效利用
合理選擇數據結構
-
Redis提供了多種數據結構,如字符串、列表、哈希、集合和有序集合。根據業務需求選擇合適的數據結構能夠大大提高性能。例如,使用哈希表存儲用戶信息,可以通過用戶ID快速定位到用戶數據。
縮短鍵值對存儲長度
-
縮短鍵值對的存儲長度可以減少內存占用和網絡傳輸開銷,從而提高性能。例如,可以使用更短的key和value,或者對數據進行壓縮后再存儲。
3. 配置優化
使用Pipeline
- ?機制:Pipeline允許客戶端將多個命令打包成一個請求發送給Redis服務器,從而減少網絡往返時間。
- 假設客戶端需要執行10個命令,如果使用普通的請求-響應模式,需要發送10次請求和接收10次響應;而使用Pipeline,只需要發送一次請求和接收一次響應,從而大大提高了性能。?
啟用持久化
- ?機制:Redis提供了RDB和AOF兩種持久化方式,以確保數據在服務器重啟后不會丟失。
- 根據業務需求選擇合適的持久化方式,并調整相關參數以優化性能。例如,可以關閉不必要的持久化功能,或者調整AOF的刷新頻率和文件大小等參數。?
監控和優化
- ?機制:定期監控Redis的性能指標,如內存使用、QPS、響應時間等,并使用Redis自帶的INFO命令或第三方監控工具進行分析和優化。
- 如果發現Redis的內存使用率過高,可以通過增加內存、優化數據結構或調整緩存策略等方式來降低內存占用;如果發現某個命令的響應時間過長,可以通過優化該命令或調整相關參數來提高性能。?
Redis Big Key的定位以及解決方案
Redis最常見的用途就是緩存數據來提高系統的性能。但是如果緩存使用不當,如下場景:
- 業務中使用了不恰當的redis數據結構。如使用String的value存儲某個較大二進制文件數據。
- 業務預估不準確;如規劃的時候沒有對key的成員進行合理的拆分,導致key的成員數據量過多。
- 沒有及時清理無用的數據;如List結構中數據持續增加而沒有彈出數據的機制,那么數據會越來越多。
- 某個key存放的數據突然的波動很大;如存放某個明星熱點粉絲列表或者評論的列表由于明星出軌或者離婚導致熱點數據量激增,也就是value存放過多數據。
以上情況都會導致key對應的value數據量比較大,也就是value所占的內存空間較大,這就是所謂的big key問題。針對Redis的big key一般的判定標準如下:
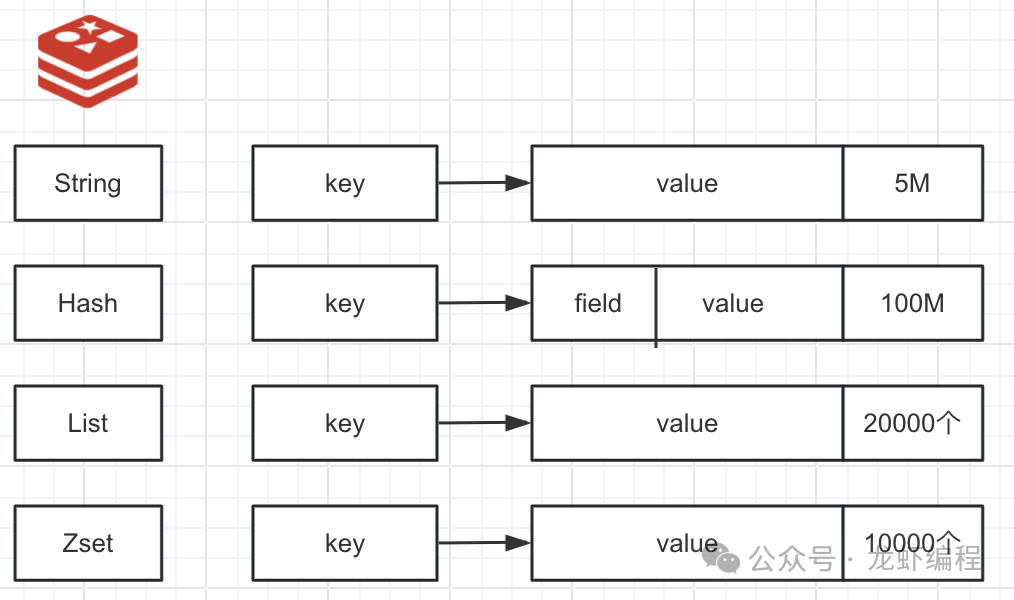
總結起來其實就分成兩類,一類是字符型,一類是非字符型(Hash、List、Set、Zset),針對字符型是判斷value值大小,針對字符型就是判斷其存放的元素個數,如下圖的整理:

上面是判定big key的一般標準,具體到每個系統的判斷標準還需要根據自身的業務場景來確定。
1、Big Key的常見場景
- ?排行榜:?在排行榜系統中,可能會使用Redis的
Sorted Set數據結構來存儲用戶的分數和排名。如果用戶數量非常多,那么這個Sorted Set的大小就會非常大,從而形成大Key。 - 在線課程系統:?在線課程系統可能會使用Redis來存儲每個課程的學生列表。如果一個課程的學生數量非常多,那么這個列表就可能會形成大Key。
- 直播系統:?直播系統可能會使用Redis來存儲每個直播間的觀眾列表。如果一個直播間的觀眾數量非常多,那么這個列表就可能會形成大Key。
- 社交網絡:?社交網絡可能會使用Redis來存儲用戶的好友列表或者粉絲列表。如果一個用戶的好友或者粉絲數量非常多,那么這個列表就可能會形成大Key。
- 實時計算:?在實時計算場景中,可能會使用Redis來存儲中間計算結果。如果這些結果的數據量非常大,那么就可能會形成大Key。?
2、Big Key的危害
- ?內存占用過大:?Redis是基于內存的數據存儲系統,大Key會占用大量的內存空間,可能導致內存不足,影響系統的正常運行。
- 性能下降:?當Redis需要對大Key進行操作時,如讀取、寫入、刪除等,都會消耗大量的CPU和內存資源,導致Redis的性能下降。
- 阻塞問題:?Redis是單線程模型,對大Key的操作可能會阻塞其他的請求,導致Redis服務的響應時間增加。
- 數據備份和恢復問題:?如果Redis中存在大Key,那么在進行數據備份和恢復時,可能會因為單個Key的數據過大而導致備份和恢復過程變得非常慢。
- 網絡帶寬壓力:?當Redis需要將大Key的數據傳輸到客戶端時,可能會占用大量的網絡帶寬,影響網絡的性能。
- 內存分配不均勻:?集群架構下,某個數據分片的內存使用率遠超其他數據分片,無法使數據分片的內存資源達到均衡。?
3、Big Key的檢測
Redis大Key的檢測可以通過以下幾種方式進行:
1). 使用Redis自帶命令進行檢測
keys *:這個命令可以列出所有的key(全量掃描,生產環境不建議)randomkey:這個命令可以隨機返回一個key,可以通過這個命令多次執行來隨機檢查key的大小。debug object key:這個命令可以查看指定key的詳細信息,包括它的大小。(開銷較大、不建議)STRLEN、LLEN、HLEN、SCARD、ZCARD、XLEN?等命令,返回對應Key的列表長度或數量。
2). 使用第三方工具進行檢測
- Redis-cli:Redis的命令行工具,可以通過腳本來批量檢查key的大小。
- Redis-rdb-tools:這是一個Python的庫,可以解析Redis的dump.rdb文件,然后分析出大Key。
- Redis-sampler:這是一個可以抽樣分析Redis數據的工具,也可以用來檢測大Key。
3). 實時監控系統的設計與實現
- 可以通過定期執行腳本,將Redis中的key和它們的大小信息發送到監控系統,然后在監控系統中設置閾值,當key的大小超過閾值時,發送告警通知。
- 可以使用開源的監控系統,如Prometheus和Grafana,或者商業的監控系統,如Datadog和New Relic,來實現Redis的實時監控。
4、Big Key 的預防與處理
1. 數據結構優化
-
根據實際的業務需求,選擇更合適的數據結構。例如,如果數據具有唯一性,可以使用
Set代替List;如果數據具有鍵值對關系,可以使用Hash代替String。 -
對于
Hash類型的數據,如果field數量非常多,可以考慮將一個大Hash拆分成多個小Hash。
2. 數據存儲策略調整
-
對于大量的小數據,可以考慮使用
Hash類型進行存儲,將多個小Key合并成一個大Key,減少Key的數量,提高存儲效率。 -
對于大數據,可以考慮使用分片的方式進行存儲,將一個大Key拆分成多個小Key,每個小Key存儲一部分數據。
3. 數據清理機制的設計與實現
-
對于不再需要的數據,應及時清理,避免占用過多的內存空間。
-
可以設置Key的過期時間,讓Redis自動清理過期的數據。
-
可以設計定期清理的機制,通過腳本或者定時任務,定期檢查和清理大Key。
Redis 不實時刪除過期數據原因
設置過期時間的作用
內存是有限且珍貴的,如果不對緩存數據設置過期時間,那內存占用就會一直增長,最終可能會導致 OOM 問題。通過設置合理的過期時間,Redis 會自動刪除暫時不需要的數據,為新的緩存數據騰出空間。Redis 自帶了給緩存數據設置過期時間的功能,比如:
expire?key?60?#?數據在?60s?后過期
(integer)?1
setex?key?60?value?#?數據在?60s?后過期?(setex:[set]?+?[ex]pire)
OK
127.0.0.1:6379>?ttl?key?#?查看數據還有多久過期
(integer)?56注意:Redis 中除了字符串類型有自己獨有設置過期時間的命令?
setex?外,其他方法都需要依靠?expire?命令來設置過期時間 。另外,?persist?命令可以移除一個鍵的過期時間。
很多時候,業務只需要某個數據只在某個時間段內存在,比如短信驗證碼可能只在 1 分鐘內有效,用戶登錄的 Token 可能只在 1 天內有效。如果使用傳統的數據庫來處理的話,通常都是自己判斷過期,這樣更麻煩并且性能要差很多。
Redis 判斷數據是否過期
Redis 通過一個叫做過期字典(可以看作是 hash 表)來保存數據過期的時間。過期字典的鍵指向 Redis 數據庫中的某個 key(鍵),過期字典的值是一個 long long 類型的整數,這個整數保存了 key 所指向的數據庫鍵的過期時間(毫秒精度的 UNIX 時間戳)。

Redis 過期字典
過期字典是存儲在 redisDb 這個結構里的:
typedef?struct?redisDb?{...dict?*dict;?????//數據庫鍵空間,保存著數據庫中所有鍵值對dict?*expires???//?過期字典,保存著鍵的過期時間...
}?redisDb;
在查詢一個 key 的時候,Redis 首先檢查該 key 是否存在于過期字典中(時間復雜度為 O(1)),如果不在就直接返回,在的話需要判斷一下這個 key 是否過期,過期直接刪除 key 然后返回 null。
Redis 過期 key 刪除策略
- 惰性刪除:只會在取出/查詢 key 的時候才對數據進行過期檢查。這種方式對 CPU 最友好,但是可能會造成太多過期 key 沒有被刪除。
- 定期刪除:周期性地隨機從設置了過期時間的 key 中抽查一批,然后逐個檢查這些 key 是否過期,過期就刪除 key。相比于惰性刪除,定期刪除對內存更友好,對 CPU 不太友好。
- 延遲隊列:把設置過期時間的 key 放到一個延遲隊列里,到期之后就刪除 key。這種方式可以保證每個過期 key 都能被刪除,但維護延遲隊列太麻煩,隊列本身也要占用資源。
- 定時刪除:每個設置了過期時間的 key 都會在設置的時間到達時立即被刪除。這種方法可以確保內存中不會有過期的鍵,但是它對 CPU 的壓力最大,因為它需要為每個鍵都設置一個定時器。
Redis 采用的刪除策略
Redis 采用的是?定期刪除+惰性/懶漢式刪除?結合的策略,這也是大部分緩存框架的選擇。定期刪除對內存更加友好,惰性刪除對 CPU 更加友好。
Redis 的定期刪除
Redis 的定期刪除過程是隨機的(周期性地隨機從設置了過期時間的 key 中抽查一批),所以并不保證所有過期鍵都會被立即刪除。這也就解釋了為什么有的 key 過期了,并沒有被刪除。并且,Redis 底層會通過限制刪除操作執行的時長和頻率來減少刪除操作對 CPU 時間的影響。
另外,定期刪除還會受到執行時間和過期 key 的比例的影響:
- 執行時間已經超過了閾值,那么就中斷這一次定期刪除循環,以避免使用過多的 CPU 時間。
- 如果這一批過期的 key 比例超過一個比例,就會重復執行此刪除流程,以更積極地清理過期 key。相應地,如果過期的 key 比例低于這個比例,就會中斷這一次定期刪除循環,避免做過多的工作而獲得很少的內存回收。
Redis 7.2 版本的執行時間閾值是?25ms,過期 key 比例設定值是 **10%**。
#define?ACTIVE_EXPIRE_CYCLE_FAST_DURATION?1000? /*?Microseconds.?*/
#define?ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC?25? /*?Max?%?of?CPU?to?use.?*/
#define?ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE?10?/*?%?of?stale?keys?after?which we?do?extra?efforts.?*/
每次隨機抽查數量是多少?
expire.c中定義了每次隨機抽查的數量,Redis 7.2 版本為 20 ,也就是說每次會隨機選擇 20 個設置了過期時間的 key 判斷是否過期。
#define?ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP?20? /*?Keys?for?each?DB?loop.?*/
如何控制定期刪除的執行頻率?
在 Redis 中,定期刪除的頻率是由?hz?參數控制的。hz 默認為 10,代表每秒執行 10 次,也就是每秒鐘進行 10 次嘗試來查找并刪除過期的 key。hz 的取值范圍為 1~500。增大 hz 參數的值會提升定期刪除的頻率。如果你想要更頻繁地執行定期刪除任務,可以適當增加 hz 的值,但這會加 CPU 的使用率。根據 Redis 官方建議,hz 的值不建議超過 100,對于大部分用戶使用默認的 10 就足夠了。

類似的參數還有?dynamic-hz,這個參數開啟之后 Redis 就會在 hz 的基礎上動態計算一個值。Redis 提供并默認啟用了使用自適應 hz 值的能力,這兩個參數都在 Redis 配置文件?redis.conf中:
# 默認為 10
hz 10
# 默認開啟
dynamic-hz yes
除了定期刪除過期 key 這個定期任務之外,還有一些其他定期任務例如關閉超時的客戶端連接、更新統計信息,這些定期任務的執行頻率也是通過 hz 參數決定。
為什么定期刪除不把所有過期 key 都刪除?
這樣會對性能造成太大的影響。如果我們 key 數量非常龐大的話,挨個遍歷檢查是非常耗時的,會嚴重影響性能。Redis 設計這種策略的目的是為了平衡內存和性能。
為什么 key 過期之后不立馬刪掉,以避免浪費內存空間?
這種刪除方式的成本太高了。假如使用延遲隊列作為刪除策略,這樣存在下面這些問題:
- 隊列本身的開銷可能很大:key 多的情況下,一個延遲隊列可能無法容納。
- 維護延遲隊列太麻煩:修改 key 的過期時間就需要調整期在延遲隊列中的位置,并且,還需要引入并發控制。
Redis 大量 key 集中過期處理
如果存在大量 key 集中過期的問題,可能會使 Redis 的請求延遲變高。可以采用下面的可選方案來應對:
- 盡量避免 key 集中過期,在設置鍵的過期時間時盡量隨機一點。
- 對過期的 key 開啟 lazyfree 機制(修改?
redis.conf?中的?lazyfree-lazy-expire參數即可),這樣會在后臺異步刪除過期的 key,不會阻塞主線程的運行。
實現 Redis 和 MySQL 數據雙寫一致性
在實際開發中,可使用redis緩存一些常用的數據(如熱點數據)用來提高系統的吞吐量。
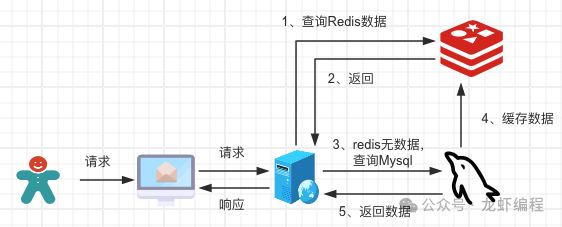
但是不可以避免的出現了數據的修改場景,這就導致了數據庫中的數據和Redis中出現不一致性的情況。如何保證數據一致性就顯得非常重要了,下面介紹一下保證數據的雙寫一致性的方案。
1、先刪緩存再操作數據庫方案
在redis一般寫的場景下對數據的更新操作是不推薦使用的,推薦使用刪除緩存數據的操作,因為刪除操作的效率更高。下圖展示先刪除緩存再操作數據庫的過程圖:
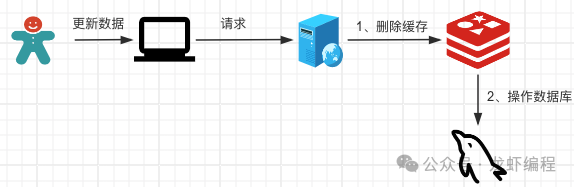
在這種方式下會存在數據不一致的問題,如下圖所示:
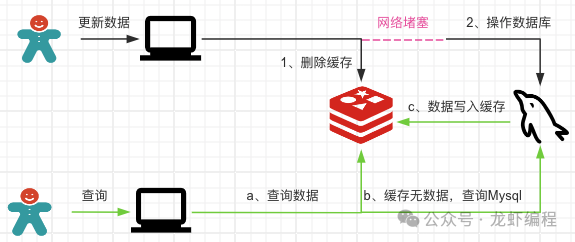
(1)線程1要更新數據,它先刪除redis中的緩存數據,然后由于網絡堵塞導致暫短的停頓,沒有繼續執行操作數據庫。?
(2)線程2要查詢數據,首先查詢數據庫,但是由于Redis中的數據已經被線程1刪除了,那么它會去數據庫中查詢數據X并且要將數據X同步到Redis中。
(3)線程1網絡堵塞結束,執行了數據庫操作將數據X更改為Y。
經過上述的過程就導致了Redis的數據和數據庫中的數據不一致了,即就是Redis中存放的依據是老數據。為了解決上述的問題,我們采用緩存延遲雙刪的策略,如下圖所示的緩存延遲雙刪的過程:
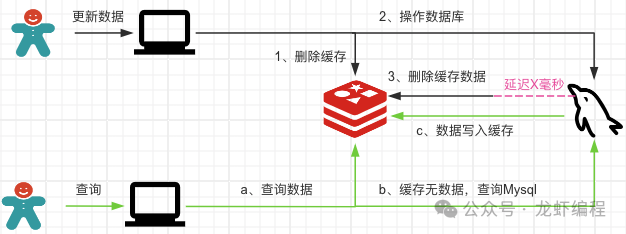
采用緩存延遲雙刪策略最多在X毫秒內讀取的數據是老數據,在X毫秒之后讀取的數據都是最新的數據。X的具體值如何確定那就需要根據自身的業務了來確定。延遲雙刪策略只能保證最終的一致性,不能保證強一致性。由于對Redis的操作和Mysql的操作不是原子性操作,所以如果想保證數據的強一致性就需要加鎖控制,如下圖所示:
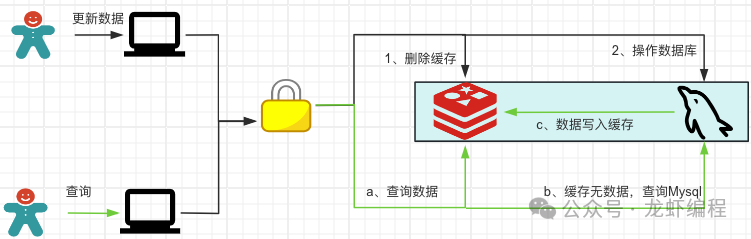
????加鎖之后勢必會帶來系統的吞吐量的下降,所以需要衡量利弊來確定是否使用加鎖。
2、先操作數據庫再刪除緩存方案

此方案就是先操作數據庫,數據庫寫入成功之后再來刪除Redis緩存中的數據。多個線程之間的數據讀取和更新如下圖所示:
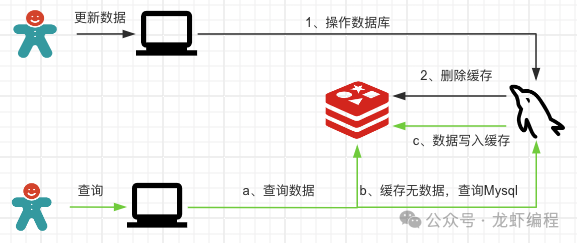
這種方案下,在數據庫更新成功后到刪除Redis緩存數據之前的這段時間中,其他線程讀取的數據都是舊數據,等Redis刪除緩存后會重新從數據庫中讀取最新數據同步到Redis,這樣可以在一定程度上保證數據的最終一致性。極端情況下會出現數據不一致的情況,如下圖所示:
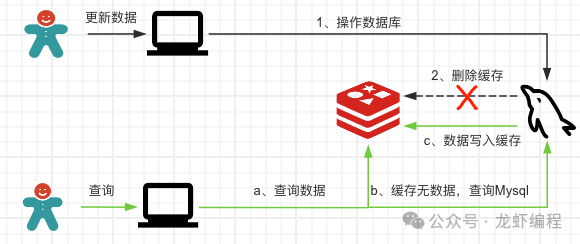
(1)線程1先成功的更新數據到數據庫中,然后執行刪除Redis緩存中的數據的時候失敗了。
(2)線程2要讀取數據,此時優先從Redis中查詢數據,由于此時Redis中老數據沒有刪除,所以線程2可以拿到舊數據直接返回。直到Redis中緩存的數據過期之后才可以從數據庫中獲取最新的到Redis中。
3、刪除重試機制
無論是先刪除緩存再操作數據還是先操作數據庫再刪除緩存的機制,都有可能會出現刪除緩存失敗的情況,如下圖所示:

為了應對刪除緩存失敗的情況發生,于是加入了刪除重試機制,如下圖所示:
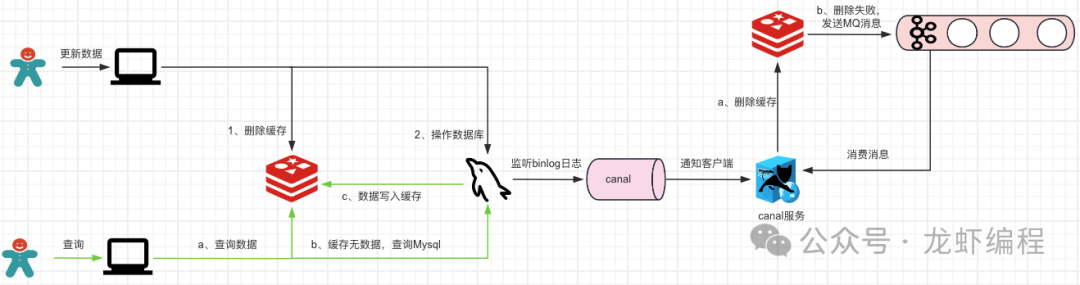
通過canal監聽binlog感知數據的變動后,canal客戶端執行刪除Redis緩存數據,如果緩存數據刪除失敗那么發送一條MQ消息讓canal客戶端繼續執行刪除操作,這樣可以保證數據的最終一致性。但是這樣也增加了系統的復雜性。
總結
(1)實際開發中推薦使用先操作數據庫再刪除緩存的方案,因為此方案最大程度上保證了數據的一致性并且實現也最簡單。
(2)無論是先操作數據庫再刪除緩存還是先刪除緩存再操作數據庫都有可能會出現刪除緩存失敗的情況,所以需要加入刪除重試機制。
(3)如果想要Redis和MySQL的數據強一致性,可以考慮使用加鎖的方式實現。
Redis?延遲隊列
1、通過過期key通知實現

實現思路:首先開啟redis的key過期通知,然后在業務中給key設置過期時間,到了過期時間后redis會自動的將過期的key消息推送給監聽者,從而實現延遲任務。
核心的代碼實現:
#1、開始redis的過期通知
notify-keyspace-events Ex#2、監聽redis的過期key
@Component
@Slf4j
public class RedisExpireKeyService extends KeyExpirationEventMessageListener {public RedisExpireKeyService(RedisMessageListenerContainer listenerContainer) {super(listenerContainer);}/*** 監聽過期的key**/@Overridepublic void onMessage(Message message, byte[] pattern) {String expireKey = message.toString();//執行具體的業務System.out.println("監聽到key=" + expireKey + ",已經過期");}
}生產環境是不推薦使用此方案,原因Redis 的過期策略采用的是惰性刪除和定期刪除相結合的方式,redis并不保證 key 在過期時會被立即刪除操作。
2、通過Zset+定時任務實現
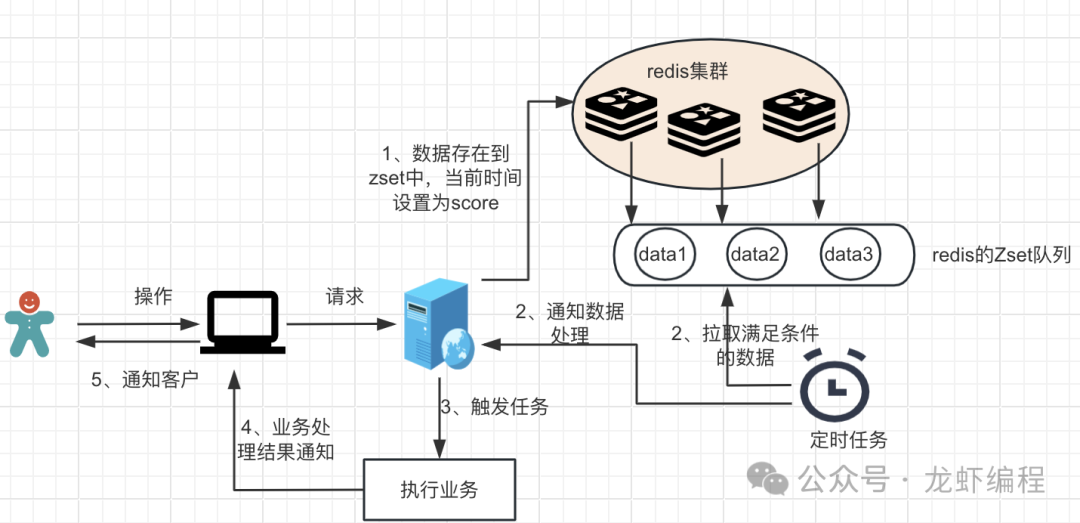
實現思路:ZSet 是一種有序集合類型,它可以存儲不重復的元素,并且給每個元素賦予一個 double 類型的排序權重值(score),所以可以將元素的過期時間作為分值,通過定時任務掃描的方式判斷是否達到過期時間,從而實現延遲隊列。
核心的代碼實現:
#使用xxl-job
@JobName("consumerTaskJob")
public?void?consumerTaskJob()?{String?expireKey?=?"ExPIRE_KEY";try?{//獲取當前時間double?currentTime?=?System.currentTimeMillis();//獲取超時的數據Set<String> expiredMemberSet = redisTemplate.opsForZSet().rangeByScore(expireKey, Double.MIN_VALUE, currentTime);//過期keyfor (String expiredMember : expiredMemberSet) {//todo 做實際的延遲任務//從ZSet中移除數據redisTemplate.opsForZSet().remove(expireKey, expiredMember);}?}?catch?(Exception?e)?{log.error("數據處理失敗",e);}}Zset+定時任務的實現延遲任務的方式雖然比監聽過期key方案合理一些,但是它還是存在一定的缺陷,如無重試機制、延遲時間固定化(依賴定時任務的執行時間)、不適用于大規模的延遲任務。
3、Redisson實現延遲隊列
Redisson是一個操作Redis的 Java 客戶框架,它提供了RDelayedQueue 接口和 RQueue 接口可以實現延遲隊列(Redisson 提供的延遲隊列底層也是基于 Zset 數據結構實現的)。
核心的代碼實現:
#2、添加數據到隊列中
//創建RedissonClient實例
RedissonClient?redissonClient?=?Redisson.create();
//創建阻塞隊列
RBlockingDeque<String>?queue?=?redissonClient.getBlockingDeque("delayQueue");
//創建延遲隊列并關聯到阻塞隊列
RDelayedQueue<String>?delayedQueue?=?redissonClient.getDelayedQueue(queue);
//添加延遲任務
delayedQueue.offer("Task1",?5000,?TimeUnit.MILLISECONDS);#3、消費數據
while (true) {try?{//獲取并移除隊首元素,如果隊列為空,則阻塞等待String?task?=?queue.take();System.out.println("Task:?"?+?task);}?catch?(Exception?e)?{log.error("消費失敗",e);}
}Redis實現的延遲隊列適用于處理一些比較簡單的業務,如發送郵件、發送通知等,對于復雜的業務不適用于Redis的延遲任務方案。
Redis 緩存預熱
- 把需要緩存的方法寫在系統初始化的方法中,這樣系統在啟動的時候就會自動的加載數據并緩存數據;
- 把需要緩存的方法掛載到某個頁面或后端接口上,手動觸發緩存預熱;
- 設置定時任務,定時自動進行緩存預熱。
Redis 緩存雪崩
緩存雪崩是指在某個時間段內,大量的緩存數據同時過期失效,導致大量的請求直接擊穿至數據庫,引起數據庫壓力驟增,甚至引起宕機的現象。這種現象類似于雪崩,一旦開始,就會迅速擴散并嚴重影響系統的穩定性和可用性。
原因分析
- 緩存失效時間同步:當多個緩存數據的失效時間設置相同時,它們可能會在同一時間點同時過期,導致大量請求涌入數據庫。
- 熱點數據訪問集中:在高并發情況下,某些熱點數據的訪問量非常大,當這些熱點數據同時失效時,大量的請求會集中在數據庫上,造成數據庫壓力激增。
解決方案
- 設置合理的過期時間:緩存中的數據過期時間應該分散設置,避免在同一時間大量數據同時過期。
- 使用熱點數據預加載:提前加載熱點數據到緩存中,避免在緩存失效時大量請求同時訪問數據庫。
- 使用備份機制:在緩存失效時,可以通過備份機制或從其他緩存源加載數據,減輕對數據庫的直接壓力。
- 限流和降級:在高峰期采取限流策略,控制請求的并發量,避免緩存雪崩的發生。同時,考慮在極端情況下采取緩存降級策略,直接訪問數據庫以保證系統的可用性。
- 加鎖排隊:加鎖排隊可以起到緩沖的作用,防止大量的請求同時操作數據庫,但它的缺點是增加了系統的響應時間,降低了系統的吞吐量,犧牲了一部分用戶體驗。加鎖排隊的代碼實現,如下所示:
// 緩存 key
String cacheKey = "userlist";
// 查詢緩存
String data = jedis.get(cacheKey);
if (StringUtils.isNotBlank(data)) {// 查詢到數據,直接返回結果return data;
} else {// 先排隊查詢數據庫,在放入緩存synchronized (cacheKey) {data = jedis.get(cacheKey);if (!StringUtils.isNotBlank(data)) { // 雙重判斷// 查詢數據庫data = findUserInfo();// 放入緩存jedis.set(cacheKey, data);}return data;}
}以上為加鎖排隊的實現示例,讀者可根據自己的實際項目情況做相應的修改。
-
設置二級緩存
二級緩存指的是除了 Redis 本身的緩存,再設置一層緩存,當 Redis 失效之后,先去查詢二級緩存。例如可以設置一個本地緩存,在 Redis 緩存失效的時候先去查詢本地緩存而非查詢數據庫。
Redis 緩存穿透
緩存穿透是指惡意或非法請求訪問不存在于緩存中的數據,導致請求直接訪問數據庫,增加數據庫負載。這種情況下,大量的無效請求會直接穿透緩存層,導致數據庫被頻繁訪問,影響系統的性能和穩定性。
原因分析
- 惡意查詢:惡意用戶可能會發起針對不存在數據的查詢請求,導致緩存無法命中,直接訪問數據庫。
- 業務邏輯缺陷:在沒有對用戶輸入進行有效過濾的情況下,某些用戶可能會發起非法或無效的請求,導致緩存穿透。
解決方案
- 布隆過濾器(Bloom Filter):使用布隆過濾器對請求進行預先過濾,判斷請求是否有效,有效則繼續訪問緩存,無效則直接拒絕,避免訪問數據庫。
- 空對象緩存:將數據庫中不存在的鍵也緩存起來,設置一個較短的過期時間,防止惡意請求頻繁查詢。
- 合理校驗和處理:在業務邏輯層對用戶輸入進行校驗,排除非法請求,避免將無效請求傳遞給緩存層。
Redis 緩存并發
緩存并發是指大量請求同時訪問同一緩存資源,可能引發緩存雪崩、緩存擊穿等問題。在高并發的情況下,如果沒有有效的并發控制機制,會導致緩存失效或緩存命中率下降,進而影響系統的性能和穩定性。
原因分析
- 熱點數據訪問:某些熱點數據的訪問量較大,在高并發情況下,大量請求會同時訪問同一緩存資源。
- 緩存失效策略不當:緩存的失效策略過于簡單,導致大量請求在緩存失效后同時訪問數據庫
解決方案
- 分布式鎖:使用分布式鎖控制對緩存資源的并發訪問,確保同一時間只有一個請求能夠更新緩存。
- 限流控制:實施限流算法來限制對緩存的并發訪問數量,避免過多請求同時訪問緩存
Redis 緩存擊穿
緩存擊穿是指某個熱點數據突然失效或過期,導致大量請求直接訪問數據庫,增加數據庫負載。與緩存雪崩不同的是,緩存擊穿通常是針對某個特定的緩存鍵失效,而不是整個緩存層失效。
原因分析
- 熱點數據失效:熱點數據的訪問量較大,當這些數據的緩存失效時,大量請求會直接訪問數據庫,造成數據庫壓力激增。
解決方案
- 對于熱點數據,可以設置其永不過期,或設置較長的過期時間,避免頻繁的緩存失效。
- 在緩存失效時,使用互斥鎖阻止大量請求同時訪問數據庫,等待緩存數據更新后再釋放鎖。
-
加鎖排隊
此處理方式和緩存雪崩加鎖排隊的方法類似,都是在查詢數據庫時加鎖排隊,緩沖操作請求以此來減少服務器的運行壓力。
Redis 緩存降級
緩存降級是指在系統壓力過大或緩存失效時,暫時關閉或降級緩存功能,直接訪問數據庫,保證系統的穩定性。
原因分析
- 系統壓力過大:在系統高峰期或異常情況下,緩存無法承受大量請求的同時訪問。
- 緩存失效:緩存失效或緩存層出現故障,無法提供正常的緩存服務
解決方案
- 備用方案:在緩存失效或壓力過大時,設置備用方案直接訪問數據庫,保證系統的可用性。
- 自動降級:使用自動降級策略根據系統負載情況自動調整緩存功能,避免系統崩潰或性能下降。
Redis pipeline(管道)
Redis pipeline 使得客戶端可以一次性將要執行的多條命令封裝成塊一起發送給服務端。
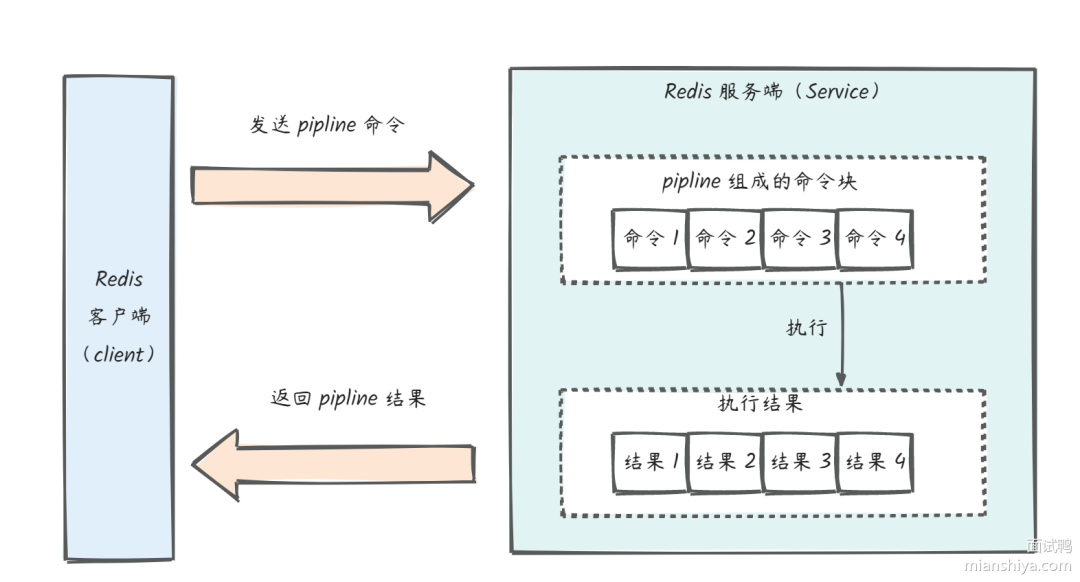
Redis 服務端在收到來自管道發送的多條命令之后,會先把這些命令按序執行,并將執行結果保存到緩存中,直到最后命令執行完成,再把命令執行的結果一起返回給客戶端。Redis 使用 pipeline 主要有以下兩個好處:
- 節省了 RTT
RTT(Round Trip Time)即往返時間。Redis 客戶端將要執行的多條指令一次性給客戶端,顯然減少了往返時間。
- 減少了上下文切換帶來的開銷
當服務端需要從網絡中讀寫數據時,都會產生一次系統調用,系統調用是非常耗時的操作。其中涉及到程序由用戶態切換到內核態,再從內核態切換回用戶態的過程。當我們執行 100 條 Redis 指令的時候,就發生 100 次用戶態到內核態之間上下文的切換,但是如果使用管道的話,其將多條命令一同發送給服務端,就只需要進行一次上下文切換就好了,這樣就可以節約性能。
這里需要注意 pipeline 不宜包裝過多的命令,因為會導致客戶端長時間的等待,且服務器需要使用內存存儲響應,所以官方推薦最多一次 10k 命令。還有一點需要注意 pipeline 命令執行的原子性不能保證,如果要保證原子性則使用?lua?腳本或者事務。
Redis 應用場景
緩存:Redis 可以作為應用程序的緩存層,減少數據庫的讀取壓力,提高數據訪問速度。
會話存儲:在 Web 應用中,Redis 可以用來存儲用戶的會話信息,如登錄狀態、購物車內容等。
排行榜和計數器:Redis 支持原子操作,非常適合實現實時排行榜、點贊數、訪問計數等功能。
消息隊列:Redis 可以作為消息隊列系統,用于處理異步任務,例如郵件發送、后臺任務處理等。使用Redis的發布/訂閱功能來實現任務隊列。
實時分析:Redis 可以用于實時分析,如用戶行為分析、實時統計信息等。使用Redis的Sorted Set來實現用戶在線時長統計和分析功能。
分布式鎖:在分布式系統中,Redis 可以用于實現分布式鎖,確保在多個節點之間共享資源的一致性。使用Redisson作為客戶端來實現分布式鎖。
發布/訂閱:Redis 提供了發布/訂閱模式,可以用于實現消息廣播,例如實時通知系統。
限流:Redis 可以用于實現限流功能,防止系統過載,如 API 調用頻率限制。
數據過期:Redis 支持設置數據的過期時間,自動清理過期數據,適用于臨時數據存儲。
全頁緩存:Redis 可以緩存整個頁面的輸出,減少數據庫查詢和頁面渲染時間。
社交功能:在社交網絡應用中,Redis 可以用于存儲好友關系、用戶狀態更新等。
實時推薦系統:Redis 可以用于存儲用戶的行為數據和偏好,實現實時推薦。
地理位置信息:Redis 支持 Geospatial 索引,可以用于實現地理位置相關的查詢和推薦。
時間序列數據:Redis 可以存儲時間序列數據,用于監控和分析。
任務調度:Redis 可以用于任務調度,例如定時任務的執行。使用Redis的延遲隊列特性來實現任務調度。
數據共享:在微服務架構中,Redis 可以作為服務間共享數據的媒介。
持久化:雖然 Redis 是內存數據庫,但它也支持數據持久化,可以在系統故障后恢復數據。使用Spring的@Scheduled注解與Redisson結合來實現任務調度。
Redis緩存常用設計模式?
寫操作
以Redis統一視圖為準:先更新緩存,后更新數據庫。
1) Write Through Pattern 直寫模式
首先將數據寫入緩存,再將數據立即同步到數據庫。
優點:
數據一致性:每次寫操作都要同時更新緩存和數據庫,保證了緩存和數據庫之間的數據一致性。
即時的數據訪問:由于緩存始終保持最新狀態,讀取操作可以立即從緩存中獲取最新的數據,提高了數據訪問的速度。
缺點:
寫操作延遲:對于寫操作頻繁的場景,每次寫操作都要同時更新緩存和數據庫,導致寫操作延遲。
資源消耗:緩存和數據庫的同步更新會消耗更多的計算和內存資源。
適用場景:
適用于對數據一致性要求較高,寫操作不頻繁的場景。
例如:電商平臺的訂單處理,當用戶下單時,訂單信息既寫入緩存,也同步寫入數據庫,保證了數據的實時性和一致性。
2) Write Behind Pattern 寫后模式
首先將數據寫入緩存,再將數據異步的批量同步到數據庫。
優點:
提高寫操作性能:寫操作首先發生在緩存中,通常比寫入數據庫快得多。
減輕數據庫負載:異步批量寫入數據庫,減少對數據源的即時寫操作。
提高響應時間:寫操作首先發生在緩存中,可以更快的響應寫請求。
缺點:
數據一致性問題:由于數據是異步寫入數據庫的,導致緩存和數據庫之間在一定時間內的數據不一致。
適用場景:
適用于寫操作遠多于讀操作,且對數據一致性要求不高的場景。
例如:用戶行為日志收集,用戶在網站上的點擊行為被記錄在緩存中,然后異步批量寫入到日志數據庫。
寫操作不經過緩存。
3) Write Around Pattern 繞寫模式
數據直接寫入數據庫,不經過緩存。
優點:
提高緩存效率:寫操作不需要同步到緩存,緩存不會應為寫操作而頻繁的失效或更新。
提高內存利用率:防止那些不會再次被讀取到的數據占用緩存空間,提高資源利用率。
缺點:
無法保障數據一致性:如果更新的數據同時存在于緩存和數據庫中,則會造成緩存和數據庫中的數據不一致。由于緩存數據沒有被及時更新,導致從緩存中獲取到臟數據。
適用場景:
適用于數據寫入后很少被讀取的場景。
例如:對于數據備份操作直接寫入到備份存儲中,不經過緩存;或者是針對報告、歸檔信息的操作。
讀操作
4)Read Through Pattern 讀穿透
如果緩存未命中,緩存層自動從數據庫中獲取數據,然后將數據寫入緩存中,最終由緩存返回數據給應用程序。緩存系統自動處理數據加載,使得數據的讀寫操作對應用更加透明,通常與write Through結合使用,這意味這所有的操作都會通過緩存層。
優點:
降低數據庫的負載:一旦數據被加載到緩存中,后續的讀取請求將直接從緩存中獲取數據,減少了對數據庫的直接訪問。
提高系統的性能和并發讀取能力:讀操作從緩存中進行,緩存的讀取速度快,從而提高了系統的性能。
缺點:
高并發請求下的數據不一致:連續兩次寫入請求,由于寫入操作存在先后順序問題,當數據被更新時,其它并發請求可能還在讀取緩存中的舊數據,導致數據不一致。
回源延遲:如果緩存未命中,回源操作(緩存未命中,緩存系統就需要從原始數據源(如數據庫或遠程服務器)獲取這個數據項,然后再提供給請求者)會導致數據的獲取有一定的延遲,特別是當數據量較大時,延遲會更加明顯。
解決方案:
設置合適的緩存數據過期時間,采用適當的緩存數據過期策略和緩存淘汰策略確保緩存的有效性。
“定期刪除+惰性刪除”策略:用于刪除過期的緩存數據。?
內存淘汰策略:用于在內存不足時,選擇要淘汰的緩存數據。
適用場景:
適用于讀取頻繁、寫入較少,對數據一致性要求不高,對速度和性能要求較高的場景。
緩存中放的是當前在線用戶的活躍數據,例如游戲中的換皮膚、換裝備,用戶登錄系統后,用戶的所有行為在緩存中生成副本(統一視圖)。
讀寫操作
5)Cache Aside Pattern 旁路模式
緩存操作是由應用程序顯式控制的,開發者可以根據特定業務需求來自定義管理緩存數據,更加靈活可控。
優點:
確保緩存中存放的是真熱點數據:只有在實際需要時,才加載數據到緩存,避免緩存中填充未使用或很少使用的數據,保證緩存中存放的是當前窗口的活躍數據。
內存占用小:只緩存真正的熱點數據,減少緩存空間的浪費,更有效的利用緩存空間。
提高靈活性:緩存操作是由應用程序顯式控制的,開發者可以根據特定業務需求來管理緩存數據。
缺點:
代碼復雜性:需要額外的代碼邏輯去處理緩存的加載和失效。
數據一致性問題:由于緩存更新依賴于應用程序邏輯,如果處理不當,可能會導致緩存和數據庫之間的數據不一致。
適用場景:
適用于讀多寫少,對數據實時性要求不高的場景。
例如:新聞內容展示、博客文章的閱讀。
Redis過期策略、內存淘汰機制
緩存中存儲當前的熱點數據,Redis為每個key值都設置了過期時間,以提高緩存命中率。假設你設置了一批key只能存活2個小時,那么當這批key過期后,Redis選擇“定期刪除+惰性刪除”策略。如果該策略失效,Redis內存使用率會越來越高,一般應采用內存淘汰機制來解決。
定期刪除??
Redis默認每隔100ms就隨機抽取一些設置了過期時間的key,檢查其是否過期,如果有過期就刪除。
隨機抽取:是因為假如redis存了幾十萬個key,每隔100ms就遍歷所有設置了過期時間的key,cpu的負載會很高。
“定期”而不是“定時”:是因為定時刪除需要用一個定時器來負責監視key,過期則自動刪除。雖然內存及時釋放,但是在高并發請求下,cpu應該把更多的時間用在處理請求上,而不是浪費在刪除key上。
惰性刪除??
定期刪除可能會導致很多過期的key到了時間并沒有被刪除掉,此時就要用到惰性刪除。在你請求某個key的時候,redis會檢查這個key是否設置了過期時間,并判斷是否過期了,如果過期就刪除。
- 定時刪除:用cpu的性能換取內存空間(以時間換空間)
- 定期刪除:可能會導致過期的key沒被刪除
- 惰性刪除:用內存換取cpu的處理時間(以空間換時間)
定期刪除+惰性刪除的問題??
如果定期刪除漏掉了很多過期的key,這些key還占用著內存。然后也沒即時去請求key,即惰性刪除也沒生效。這種場景下,Redis默認的“定期刪除+惰性刪除”策略就失效了。此時,如果大量過期的key堆積在內存中,Redis內存使用率會越來越高,最后導致Redis的內存塊耗盡。對此,可采用內存淘汰機制解決。
Redis中的緩存淘汰策略??
當Redis使用的內存達到maxmemory參數配置的閾值時,Redis就會根據配置的內存淘汰策略把key從內存中移除。
1.?LRU 最近最少使用?---?基于緩存中數據的訪問順序
使用一個鏈表來跟蹤key的訪問順序,當key被訪問時將其移動到鏈表前面。
2.?LFU 最不經常使用?----基于緩存中每個數據的使用頻率
更加關注緩存的使用頻率,使用計數器來記錄每個key的訪問次數,哈希表用于快速查找key。
3.?Random?隨機淘汰策略
4.?TTL?生存時間:從設置了過期時間的key里面,挑選出即將要過期的key優先移除。
序號 淘汰策略 策略說明 1 noeviction 當內存不足以容納新寫入數據時,寫入操作會報錯(一般不用) 2 volatile-lru 對設置了過期時間的key使用LRU算法,最近最少使用的淘汰
緩存數據有明顯的冷熱之分,即數據的訪問頻率相差較大3 volatile-lfu 對設置了過期時間的key使用LFU算法,最不經常使用的淘汰
緩存需要關注數據的歷史訪問頻率4 volatile-random 對設置了過期時間的key使用隨機刪除 5 volatile-ttl 從設置了過期時間的key里面,挑選出快要過期的key淘汰 6 allkeys-lru 對所有的key使用LRU算法,最近最少使用的淘汰 7 allkeys-lfu 對所有的key使用LFU算法,最不經常使用的淘汰 8 allkeys-random 對所有的key使用隨機刪除
緩存數據沒有明顯的冷熱之分,即數據的訪問頻率差距不大總結??
“定期刪除+惰性刪除”策略:用于刪除過期的緩存數據。
內存淘汰策略:用于在內存不足時,選擇要淘汰的緩存數據。
Redis 內存分析
1、Redis默認內存
在 64bit 系統下,默認不限制內存大小,不設置內存大小和maxmemory = 0表示不限制 Redis 內存使用
2、查看Redis最大內存
-
命令行
127.0.0.1:6379>?config?get?maxmemory
1)?"maxmemory"
2)?"0"
-
配置文件 redis.conf
# maxmemory <bytes>
3、查看Redis內存使用情況
127.0.0.1:6379>?info?memory
4、內存配置和修改
-
臨時方案,通過命令修改
127.0.0.1:6379>?config?set?maxmemory?104857600
OK
127.0.0.1:6379>?config?get?maxmemory
1)?"maxmemory"
2)?"104857600"
-
永久方案,通過配置文件

5、生產環境內存配置
建議:一般取物理內存的3/4。
Redis 過期鍵刪除
1、立刻刪除
立即刪除能保證過期鍵值會在過期后馬上被刪除,其所占用的內存也會隨之釋放。但是刪除操作會占用cpu的時間,造成CPU額外的壓力。redis.conf 中,通過調整過期鍵的檢測頻率:
#?The?range?is?between?1?and?500,?however?a?value?over?100?is?usually?not
#?a?good?idea.?Most?users?should?use?the?default?of?10?and?raise?this?up?to
#?100?only?in?environments?where?very?low?latency?is?required.
hz?10
但是這會產生大量的性能消耗,同時也會影響數據的讀取操作。
2、惰性刪除
數據到達過期時間,不做處理。等下次訪問該數據時,
- 如果未過期,返回數據 ;
- 發現已過期,刪除,返回不存在。
惰性刪除策略的缺點是,它對內存是最不友好的。如果一個鍵已經過期,而這個鍵又仍然保留在redis中,那么只要這個過期鍵不被刪除,它所占用的內存就不會釋放。
#開啟憜性淘汰
lazyfree-lazy-eviction=yes
3、定期刪除
這種方案有效規避上述兩種極端情況, 定期刪除策略的難點是確定刪除操作執行的時長和頻率:
- 如果刪除操作執行得太頻繁或者執行的時間太長,定期刪除策略就會退化成立即刪除策略。
- 如果刪除操作執行得太少,或者執行的時間太短,定期刪除策略又會和惰性刪除束略一樣,出現浪費內存的情況。
- 因此,如果采用定期刪除策略的話,服務器必須根據情況,合理地設置刪除操作的執行時長和執行頻率。
Redis 內存淘汰策略
- 定期刪除時,從來沒有被抽查到
- 惰性刪除時,也從來沒有被點中使用過
上述兩個步驟,依然會有大量過期的key堆積在內存中,導致redis內存空間緊張或者很快耗盡。因此,需要更好的兜底方案,淘汰策略。
1、LRU 和 LFU 的區別
LRU(Least Recently Used,最近最少使用頁面置換算法)
假設我們有一個容量為3的LRU緩存,訪問數據的順序如下:
- 訪問數據1,緩存中現在有:[1]
- 訪問數據2,緩存中現在有:[1, 2]
- 訪問數據3,緩存中現在有:[1, 2, 3]
- 再次訪問數據1,緩存中現在有:[2, 3, 1](因為1被重新訪問,它被移到了列表的末尾)
- 訪問數據4,由于緩存已滿,最不常用的數據2將被淘汰,緩存中現在有:[3, 1, 4]
-
原理:如果數據最近被訪問過,那么在不久的將來它很可能再次被訪問。因此,LRU會淘汰最長時間未被訪問的數據。
-
適用場景:適用于最近被訪問的數據在未來某個時間點很可能再次被訪問。
LFU(Least Frequently Used,最近最不常用頁面置換算法)
假設我們有一個容量為3的LFU緩存,訪問數據的順序如下:
- 訪問數據1,計數器:{1: 1}
- 訪問數據2,計數器:{1: 1, 2: 1}
- 訪問數據1,計數器:{1: 2, 2: 1}
- 訪問數據3,計數器:{1: 2, 2: 1, 3: 1}
- 訪問數據1,計數器:{1: 3, 2: 1, 3: 1}
- 訪問數據4,由于緩存已滿,訪問次數最少的數據2將被淘汰,計數器:{1: 3, 3: 1, 4: 1}
-
原理:LFU算法會跟蹤每個頁面在特定時間段內被訪問的頻率。當需要淘汰頁面時,LFU算法會淘汰在該時間段內訪問次數最少的頁面。
-
適用場景:LFU算法適用于那些訪問模式可能隨時間變化的場景,或者訪問頻率能夠較好地反映頁面重要性的情況。
總結
- LRU關注數據的最近訪問
時間,淘汰最長時間未被訪問的數據。 - LFU關注數據的訪問
頻率,淘汰訪問次數最少的數據。
2、Redis 的淘汰策略
redis.config 配置文件中,
#?volatile-lru?->?Evict?using?approximated?LRU,?only?keys?with?an?expire?set.
#?allkeys-lru?->?Evict?any?key?using?approximated?LRU.
#?volatile-lfu?->?Evict?using?approximated?LFU,?only?keys?with?an?expire?set.
#?allkeys-lfu?->?Evict?any?key?using?approximated?LFU.
#?volatile-random?->?Remove?a?random?key?having?an?expire?set.
#?allkeys-random?->?Remove?a?random?key,?any?key.
#?volatile-ttl?->?Remove?the?key?with?the?nearest?expire?time?(minor?TTL)
#?noeviction?->?Don't?evict?anything,?just?return?an?error?on?write?operations.
解釋下:
volatile-lru:使用近似的最近最少使用(LRU)算法淘汰鍵。但是,只有那些設置了過期時間的鍵(即“volatile”鍵)才會被考慮淘汰。allkeys-lru:使用近似的LRU算法淘汰任何鍵,無論它們是否設置了過期時間。volatile-lfu:使用近似的最少頻率使用(LFU)算法淘汰鍵。同樣,只有設置了過期時間的鍵會被考慮。allkeys-lfu:使用近似的LFU算法淘汰任何鍵,不考慮它們是否設置了過期時間。volatile-random:隨機淘汰一個設置了過期時間的鍵。allkeys-random:隨機淘汰任何鍵,不論它們是否設置了過期時間。volatile-ttl:淘汰具有最短剩余生存時間(TTL)的鍵,即那些最接近過期時間的鍵。noeviction:不淘汰任何鍵。當內存達到最大容量時,Redis將不會進行任何淘汰操作,而是在寫入新數據時返回錯誤。
3、生產如何選擇淘汰策略?
在生產環境中選擇緩存淘汰策略時,通常需要根據應用的具體需求和數據特性來定。這里給出常見案例:
電商平臺的商品推薦
電商平臺需要為用戶展示個性化的商品推薦,其中熱門商品的訪問頻率較高。可選擇:LFU(Least Frequently Used)
redis-cli?config?set?maxmemory-policy?allkeys-lfu
因為LFU策略可以保留訪問頻率高的商品,確保推薦列表中展示用戶最可能感興趣的商品。
金融交易平臺的實時數據
金融交易平臺需要提供實時的股票價格和交易數據,數據的實時性至關重要。過期的時價被淘汰。
可選擇:TTL(Time To Live)結合LRU(Least Recently Used)
redis-cli?config?set?maxmemory-policy?volatile-lru
TTL確保數據在一定時間后自動過期,而LRU保證最近訪問的數據被優先保留。
電信運營商的用戶數據管理
電信運營商需要處理和緩存大量用戶的通話記錄、短信記錄等,用戶通常更關心最近的通信記錄。
可選擇:LRU(Least Recently Used)
redis-cli?config?set?maxmemory-policy?allkeys-lru
因為LRU策略可以確保最近生成的通話記錄和短信記錄被優先緩存。
社交媒體平臺的用戶動態
社交媒體平臺需要為用戶展示好友的最新動態和帖子,用戶通常對最新動態感興趣。
可選擇:LRU
redis-cli?config?set?maxmemory-policy?allkeys-lru
因為LRU可以保證最新的帖子被優先展示。
Redis Big/Hot Key
-
大 key?指的是一個鍵中包含了大量的數據。(總結一個字就是大)
占用空間:大key?通常指的是一個鍵包含了大量的數據,使得該鍵對應值的占用的內存超出了正常范圍。這個大小的閾值并不是固定的,而是相對于 Redis 實例的可用內存而言。當一個鍵的大小超出了 Redis 實例可用內存時,就可以認為它是一個大key。
操作耗時:如果對一個 key 的操作所需的時間過長,導致性能下降或者影響其他請求的處理速度,也可以說這個 key 是?大key?。因為這種情況通常是由于該 key 下包含了大量的數據。
-
熱 key?指的是頻繁訪問的鍵。(總結就是熱,訪問頻繁。)
頻繁訪問:在某一段時間內被頻繁訪問的 key 就是?熱key?。
業務方面:比如商城促銷的場景下,某個商品的緩存可能就會成為?熱key。這種情況下?熱key?反應的不僅是該鍵的訪問頻率高,還反映了用戶對某個業務功能的熱度。
性能方面:熱key?的頻繁訪問造成 Redis 的 CPU 占用率過高,造成響應時間延長或者請求阻塞,從而造成系統崩潰。
key?的大與不大,熱與不熱要根據自己的業務,從實際情況進行評估。
大 key?的影響
-
內存消耗:在進行緩存時降低緩存的效率,占用大量的內存空間,使得 Redis 的內存消耗急劇增加,還可能導致 Redis 實例的內存資源不足,甚至出發內存淘汰策略,從而影響系統的正常運行。
-
性能下降:處理大的 key,會耗費更多的 CPU 時間以及帶寬,導致 Redis 性能下降。由于 Redis 還是單線程的,處理?
大key?的操作進而會阻塞其他請求的處理,從而影響系統性能。 -
持久化效率降低:在進行持久化操作時,
AOF與RDB都會因為該?大key?耗費更多的時間,從而延遲持久化時間,分布式環境下甚至會造成緩存不一致。 -
網絡傳輸延遲:
大key?在進行網絡傳輸時會增加網絡傳輸的延遲,在分布式環境下進行數據同步時可能會造成數據的不一致。
熱 key?的影響
-
CPU占用率高:因為是?
熱key,所以 CPU 一直占用,進而導致Redis實例的CPU負載增加。 -
請求阻塞:如果 key 有訪問優先級,
熱key?的存在可能導致請求隊列中其他的請求被阻塞。 -
響應時間延長:因為?
熱key?,其他的請求被阻塞了造成響應時間延長。 -
性能不均衡:流量訪問造成突刺,系統性能的不均衡。
大key?與?熱key?都會給 Redis 實例造成一系列的影響,如內存占用過高,CPU 負載增加,持久化時間變長,性能下降等。
大 key?產生的原因
產生?大key?的原因有很多種,下面咱就一起看一下工作中經常遇到的這幾種。
存儲大量數據
存儲了大量數據也是我們經常遇到?大key?的最多的原因了。
比如?String?類型直接保存了一個大的文本或者二進制數據;Hash?結構中存儲大量的鍵值對。
-
String
SET zuiyu_large_text_key "very large text content..."-
Hash
HMSET zuiyu_large_hash_key field1 value1 field2 value2 ... fieldN valueN緩存時間設置不合理
緩存時間設置不合理這個造成?大key?的原因大概是個隱藏挺深的老 bug,有的業務場景,使用 Redis 緩存數據,業務是定時往該 key 上寫數據,由于該 key 是沒有設置緩存時間的造成這個 key 隨著時間的流逝,占用的內存越來越多,對于該點,只需要設置一個合理的過期時間即可。
前提是多次寫入
不是覆蓋,而是追加才會有該問題。
SETEX zuiyu_key_with_expiry value 3600 # 設置過期時間為3600秒數據結構使用不當
在使用 List 數據結構存儲數據時,重復的添加數據,造成該 key 越來越大,實際上業務是不需要有重復的數據存在的。
-
List
LPUSH zuiyu_large_list_key value大key?的產生根本原因就是在一個 key 下面存儲的數據多了。
熱 key?產生的原因
熱門數據
熱key?的產生一般意味著系統訪問火爆了,但是火爆的只是其中一個點或者n個點。類似微博中某個明星的瓜,當上頭條的時候,大量的人去訪問,造成了該明星所對應的 key 成為?熱key。
頻繁的更新
某些業務場景,單位時間內一直頻繁的對 key 進行更新,該 key 也會成為?熱key。
熱門搜索
類似于第一中的熱門數據,產生了熱門數據,該數據對應的熱門關鍵詞也被大量的用戶去搜索,造成該關鍵詞被頻繁訪問,最終導致該 key 也稱為?熱key。
熱key?的產生無外乎熱門數據,熱門數據產生的熱門關鍵詞以及對同一個 key 在某段時間內的頻繁訪問。
大key的解決方案
- 合理的數據結構
- 合理的緩存時間
大key?進行拆分為多個?小key- 定期對?
大key?進行清理
熱key的解決方案
- 合理的緩存淘汰策略
- 熱點數據分片
將熱點數據分散到不同的Redis實例,提升系統的吞吐量。
- 緩存預熱
在系統啟動或者活動高峰開啟之前進行緩存預熱,提前將需要的數據加載到緩存,減少熱點數據首次訪問的時間。
- 隨機緩存失效時間
避免大量的key同一時間批量失效,造成緩存雪崩與緩存穿透。
- 緩存穿透
使用布隆過濾器進行緩存請求過濾,防止無效請求進入到緩存層。
針對?大key?我們要盡可能的避免同一個 key 下大量的數據。針對?熱key?我們要合理設置過期時間,增加布隆過濾器等技術實現無效請求過濾,對即將到來的數據進行緩存預熱、熱點數據分片處理。



:16S+代謝組解析腸道菌群代謝物改善高脂飲食誘導的胰島素抵抗機制)



地圖數據)


)

學習總結)


——深度Q學習)

在3GPP系統中的增強支持(十四)-無人機操控關鍵績效指標(KPI)框架)

:優化性能并為應用程序添加狀態)