節前,我們組織了一場算法崗技術&面試討論會,邀請了一些互聯網大廠朋友、今年參加社招和校招面試的同學。
針對大模型技術趨勢、算法項目落地經驗分享、新手如何入門算法崗、該如何準備面試攻略、面試常考點等熱門話題進行了深入的討論。
總結鏈接如下:
《大模型面試寶典》(2024版) 發布!
本文介紹LLM知識問答中文本分塊的相關內容。
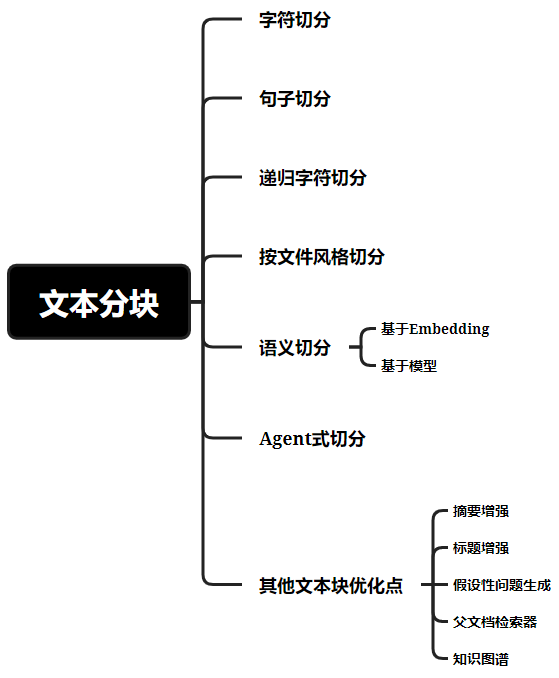
一、字符切分
Langchain的CharacterTextSplitter,直接按給定的chunk_size(塊內最大字符數量)去生硬切分文本塊,不考慮文本結構,為了保證文本塊之間的上下文聯系,基于chunk_overlap(塊重疊字符數量)去控制文本塊之間的重疊字數,注意,在英文里是按字母數考慮字符數量。當然,也能設置分隔符separator去分割。
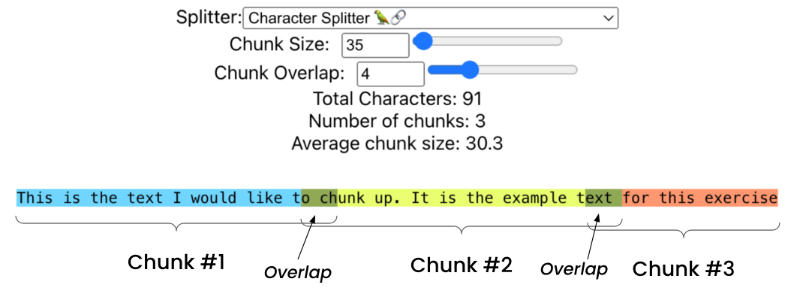
圖:字符切分
二、句子切分
Llama_index的SentenceSplitter,針對句子層面切分文本塊,并且還提供父子節點關系。
三、遞歸字符切分
Langchain的RecursiveCharacterTextSplitter,默認分割符:[“\n\n”, “\n”, " ", “”](分別代表段落分隔符、換行符、空格、字符),拆分器首先查找兩個換行符(段落分隔符)。一旦段落被分割,它就會查看塊的大小,如果塊太大,那么它會被下一個分隔符分割。如果塊仍然太大,那么它將移動到下一個塊上,以此類推。因為某些書寫系統沒有單詞邊界,例如中文、日語和泰語等,所以可以增加以下分隔符:[‘\n\n’, ‘\n’, ’ ', ‘.’, ‘,’, ‘\u200b’, ‘,’, ‘、’, ‘.’, ‘。’, ‘’]。

圖:遞歸字符切分
四、按文件風格切分
除了簡單的平文本文檔,對于其他不同格式的文件(比如HTML, Markdown, PDF等),采用不同的方式切分。比如:
- Markdown: 可以按照#來判斷標題級別進行切分,也可以標題塊下疊加字符切塊;
- Python等代碼文件: 可以按照class、def等切分出不同塊;
- PDF: 用Unstructured庫解析PDF文件,除文本外,表格也能很好抽取出來,由于表格向量化不具備較好的語義信息,一般開發者會將抽取出的表格先做總結,將表格總結向量化加入檢索池中,若檢索到該表格,則將原始表格喂入LLM內。
- 圖片: 有好多做法,比如如果圖片具有文本信息,可以直接OCR識別后的文字作為該圖片的文本塊。如果該圖片不具備文本信息,可以用多模態大模型對圖片生成圖片描述或總結,當然也能用圖片embedding,如CLIP。這里不太屬于文本分塊的討論范疇,后面會再做分享;
- HTML: 按元素級別拆分文本,并給每個文本塊添加元素級別的元數據,能將具有相同元數據的元素組合再一起。
五、語義切分
1、基于Embedding
Langchain的SemanticChunker,由Greg Kamradt提出[1],有2種方式:
(1)具有位置獎勵的層次聚類: Greg想看句子嵌入的層次聚類會如何。但由于發現他選擇按句子進行拆分時,有時會在長句子之后出現短小句子。這些尾隨的短小句子可能可以改變一個塊的含義,所以他添加了一個位置獎勵,如果它們是彼此相鄰的句子,則更有可能形成聚類。最終結果還不錯,但調整參數很慢且不理想;
(2)在連續句子之間找到語義斷點: 這是一種遍歷方法。先從第一個句子開始,得到向量,然后將其與句子2進行比較,然后比較2和3等等。如果出現向量距離大的斷點,如果它高于閾值,那么認為它是一個新語義部分的開始。最初Greg嘗試對每個句子進行向量化,但結果發現噪音太大。所以最終選取了3個句子的組(一個窗口),然后得到一個嵌入,然后刪除第一個句子,并添加下一個句子。這樣效果會好一點。
作者推崇的第二種辦法,我總結其主要步驟如下:
1)按分隔符切分出句子sentence;
2)對每個句子,把其前后的句子一起合并成一個窗口的句子組合(即上下文關聯,單個句子擴充至3個句子combined_sentence);
3)將combined_sentence向量化,得到combined_sentence_embedding;
4)計算位置i和位置i+1之間的combined_sentence_embedding的余弦距離distance_to_next,
5)根據余弦距離的分布設置分割閾值,獲取斷點;
6)基于斷點合并句子進文本塊中。
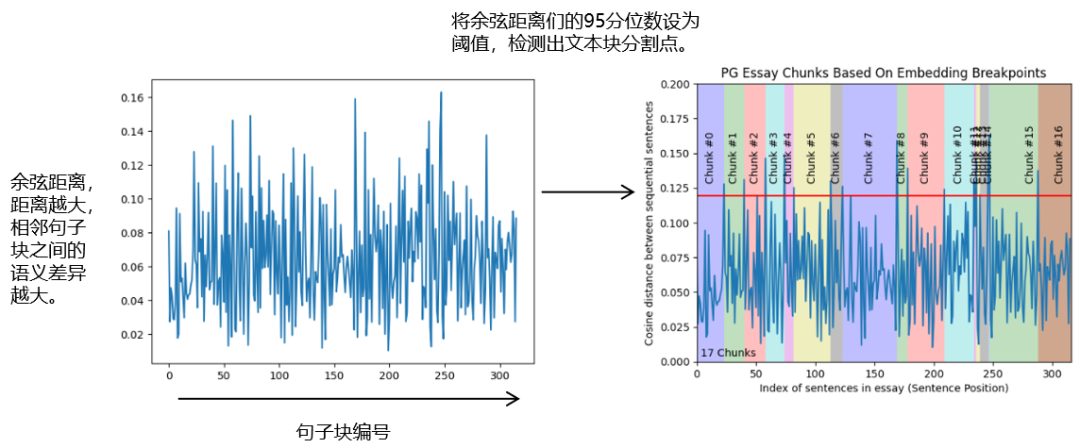
圖:基于embedding的語義切分
但實際使用還是小心,因為閾值設置不當,容易發送塊內字數過多的問題,對后續LLM檢索和回答很不利,建議可以根據文檔字數,計算number_of_chunks,然后用此參數去調整語義斷點的閾值。
2、基于模型
可以用下一句預測(Next Sentence Prediction, NSP)二分類任務的BERT模型,輸入前后兩個句子,預測句子彼此之間相鄰的可能性,若分數低于閾值,說明語義不太相關,可以分割。我們也知道BERT的預訓練目標就是MLM(掩碼語言建模)和NSP(下一句預測),其中NSP是用[CLS]做二分類預測,所以我們可以直接調用Google的BERT模型 [4]完成基于模型的語義切分方案。
關于利用BERT做文本分割(Text Segmentation)還有很多其他研究,比如:
(1)2020年Google Research提出的《Text segmentation by cross segment attention》:用BERT獲取句子表征,然后再輸入BiLSTM或Transformer預測每個句子是否為分割邊界;
圖:《Text segmentation by cross segment attention》
(2)2021年阿里語音實驗室在提出的SeqModel模型《Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken Document Segmentation》: 如下圖所示,先分句,然后對句子分詞,獲取token、segment、position embedding后做element-wise求和,再加上發音embedding后喂入BERT編碼器,對輸出做平均池化,接入softmax輸出分類判斷每個句子是否為段落邊界。為什么加入發音embedding?因為該模型提出的出發點是解決對長會議ASR生成的文本缺乏段落結構的問題。像ASR會出現寫轉寫錯誤,比如發音相似但含義不同的聲學混淆詞等。所以把字的發音信息(通過中文發音表查)來增強文本分割模型輸入的表征向量(即phone embedding)。
同時,提出了自適應滑窗提升推理速度,就是基于模型預測的段落分割點,去滑動窗口,如下圖所示。
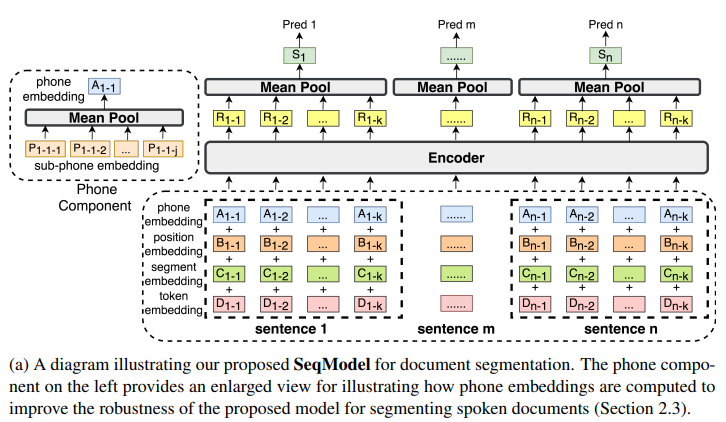
圖:《Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken Document Segmentation》
以上阿里的SeqModel開源了,我用過SeqModel,說實話一些細節上的體驗不是很好,比如帶小數點的數字會被誤切分。
六、Agent 式切分
我用可以嘗試使用LLM做語義切分,其中被討論最多是騰訊AI Lab在2023年提出的Propositionizer [2],它好處在于能解決文本中指代消解的問題,比如"it", “he”, “she”, “they”, “this”, "that”指代的實體全稱是什么,而且分解成比句子還更細粒度且信息稠密的命題(Proposition),加入文本分塊。效果如下圖所示:

圖:在Wikipedia文本上,三種不同細粒度的檢索單元(其中,a)段落塊不超過100個字,句子by句子的添加進段落塊,確保句子不被強行字符分割,最后一個塊少于50字,會和歷史句子合并,避免過于小的段落塊。b)句子塊用Python的SpacCy en_core_web_lg模型做分句,c)命題塊則使用Propositionizer模型)
作者實現Propositionizer的步驟如下:
1)從英文Wikipedia拉取2021-10-13至今的數據;
2)對GPT-4做指令微調(Proposition定義和1-shot展示),將段落塊作為輸入,要求LLM輸出一系列命題;
3)將獲取并過濾后的4.3萬對”段落-to-命題“,作為種子集微調Flan-T5-large模型。
可惜的是,開源的Propositionizer受限于訓練語料,僅支持英文。
七、其他文本塊優化點
在實踐中,我們常發現一些問題,比如:
(1)上下文的關聯信息跨度大或信息稀疏,導致文本塊內信息密度低。 舉例:聊天記錄,或某文章分點記錄各內容時,用戶向該文章提問有哪些分點內容或層次結構。
(2)標題信息過短,導致文本塊向量化后,標題語義信息被文本塊內其他內容給模糊了。 具體:某文本塊內包含標題5個字,標題下內容有300字。
(3)用戶提問內容涉及跨多個文件做檢索和整合回答時,大多數文本分塊方法不具備跨文件關聯。
為了解決以上問題,也有對應一些優化手段。
1、摘要增強
用較大chunk_size去字符切分文本,然后對大文本塊用LLM做總結,作為摘要塊加入向量數據庫中。能在一定程度解決前面提到的問題1。
2、標題增強
將標題下的相應文本塊,都加入標題前綴,并且重復多幾次標題。如:block = concat(’#’.join([title]*3), content_under_title)。能解決前面提到的問題2。
3、假設性問題生成
基于給定的文本塊,生成假設性問題,將生成的問題和對應文本塊加入檢索內容中。Langchain有個Hypothetical Queries方法[3]可調用。能解決前面提到問題1中的聊天記錄場景下的信息稀疏問題。其實說直白了,不就是QA對的生成嗎?往往好的QA對比文本塊更容易被檢索到。想要往這方面深入擴展,可以參考Ragas的TestsetGenerator(一套用LLM生成QA的Prompts工程)。
4、父文檔檢索器
其實父文檔檢索器簡單理解是利用不同chunk_size去分塊,先將原始文檔拆分成較大塊,再對較大塊拆分成較小塊,然后對較小塊進行索引向量檢索,最后返回的是相似度高的較小塊下的父文本較大塊。這樣的好處是:較小塊語義含義更精準,其父文本塊又能保留到足夠長的上下文信息。能解決前面提到的問題1。Langchain有ParentDocumentRetriever,llama_index有HierarchicalNodeParser。
5、知識圖譜
如果你的數據具有豐富的實體和實體間的關系,建議轉換成知識圖譜。如果不想手動整理圖譜,可以用Langchain的LLMGraphTransformer,利用LLM解析和分類文本中的實體和實體間的關系。能解決前面提到的問題3。
參考資料
[1] 5_Levels_Of_Text_Splitting - Greg Kamradt, 代碼:https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting.ipynb
[2] Dense X Retrieval: What Retrieval Granularity Should We Use? 論文: [2312.06648] Dense X Retrieval: What Retrieval Granularity Should We Use? (arxiv.org),代碼:https://github.com/chentong0/factoid-wiki
[3] Hypothetical Queries, 文檔:MultiVector Retriever | 🦜?🔗 LangChain
[4] Bert - Google, 代碼:google-bert/bert-base-uncased ·擁抱臉 (huggingface.co)

)

- 線性回歸模型)






)


 MQTT基礎知識)





