大模型技術的發展和應用,預示著更加智能化、個性化未來的到來。如果將大模型比喻為正在疾馳的科技列車,語料便是珍貴的“燃料”。本次世界人工智能大會期間,合合信息為大模型打造的“加速器”解決方案備受關注。
在大模型訓練的上游階段,“加速器”中的文檔解析引擎將助力大模型突破在書籍、論文、研報等文檔中的版面解析障礙,從源頭為模型訓練與應用輸送純凈的“燃料”,助力大模型跑得更快;“加速器”還加載了行業領先的acge文本向量化模型,助力大模型解決“已讀亂回”的“幻覺”問題,讓大模型在正確的航線上行駛得更遠。
TextIn是合合信息旗下的智能文檔處理平臺,在智能文字識別領域深耕17年,致力于圖像處理、模式識別、神經網絡、深度學習、STR、NLP、知識圖譜等人工智能領域研究。憑借行業領先的技術實力,為掃描全能王、名片全能王等智能文字識別產品提供強大的底層技術支持,并對企業、開發者、個人用戶提供智能文字識別引擎、產品、云端服務。
立足AI時代,TextIn以深厚的技術積累為基礎,接連推出通用文檔解析、通用文本向量等技術,賦能大模型文檔應用落地、RAG與Agent開發,成為大模型的“加速器”。

文檔解析引擎:百頁文檔秒級處理,為大模型發展輸送更加純凈的“燃料”
大模型如火如荼發展的背后,高質量的語料正在被急速消耗。對于中國的大模型企業而言,語料短缺問題更為嚴峻:當前大模型數據集主要為英文,全球通用的50億大模型數據訓練集里,中文語料占比極低。大批高價值語料數據“沉睡”在報告、論文、報紙等文檔里,復雜的版面結構制約了大模型的訓練語料處理及大模型文檔問答的應用能力,使之無法被提取。
現階段,無線表、跨頁表格、復雜公式等元素的處理仍是大模型語料處理中的“攔路虎”。合合信息文檔解析引擎“動能”強大,最快1.5秒可解析百頁長文檔中的文本、表格、圖像等非結構化數據,系現階段市面上同類文檔解析引擎中處理速度最快的產品之一;引擎還具備優秀的文檔“理解力”,可智能還原文檔閱讀順序,加速了模型在預訓練、開發、使用落地等多方面的流程。
在現場,參觀者可選擇物理、醫學、金融、社會學等多個知識領域的文檔,向大模型提問專業問題,例如對特定表格內容的總結、關鍵要素的分析等。對比測試結果顯示,加載了文檔解析引擎的大模型,在回答問題的速度、詳細程度、準確度上更勝一籌。
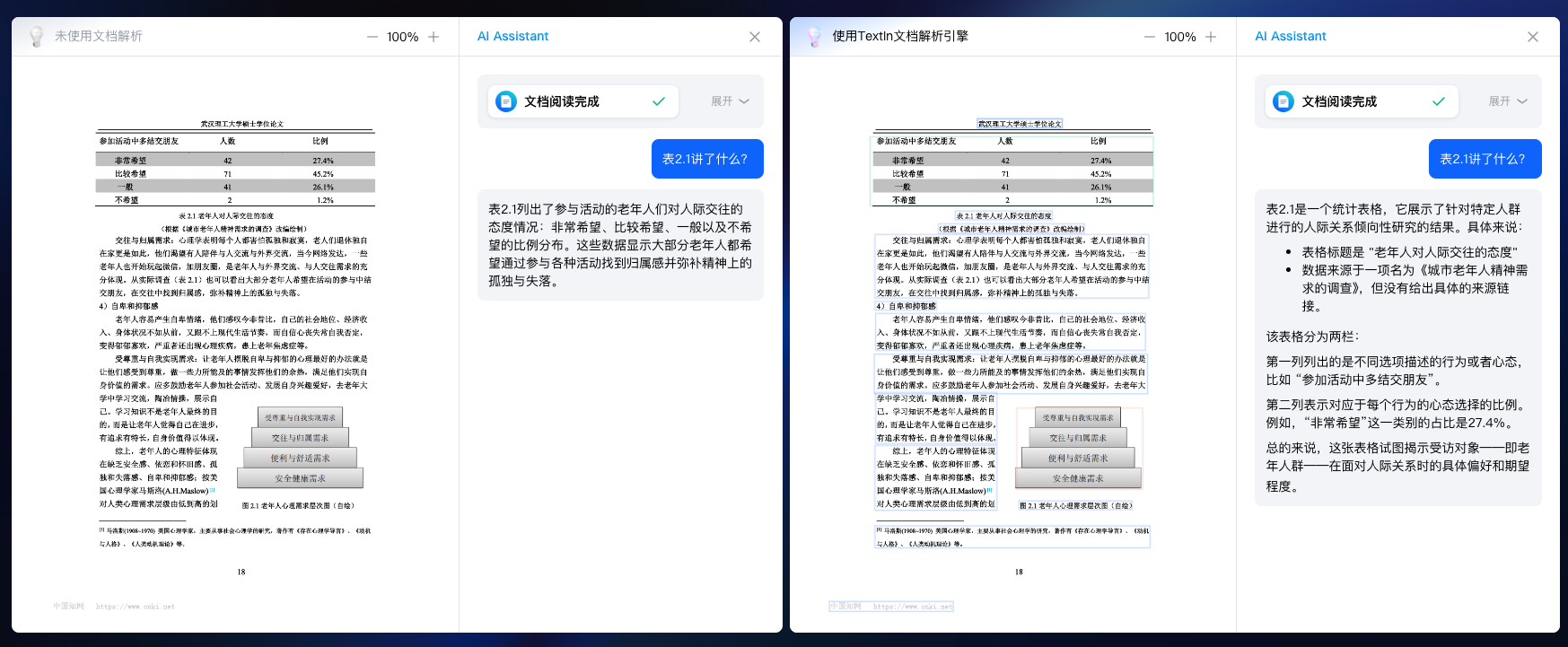
圖:大模型使用文檔解析引擎之前(左框)和之后(右框)的效果對比。使用后大模型具備了更快速、優秀的文檔要素分析、表格內容識別能力。
文檔解析引擎的“理解力”從對于圖表等對象的處理能力可見一斑。目前,市面上大多數大模型尚不具備對于圖表內容的識別、解析能力,文檔解析引擎可對研報、論文等文檔中的柱狀圖、折線圖、餅圖、雷達圖等十余種常見圖表進行“還原”,將其拆解為大模型能“讀懂”的markdown格式。
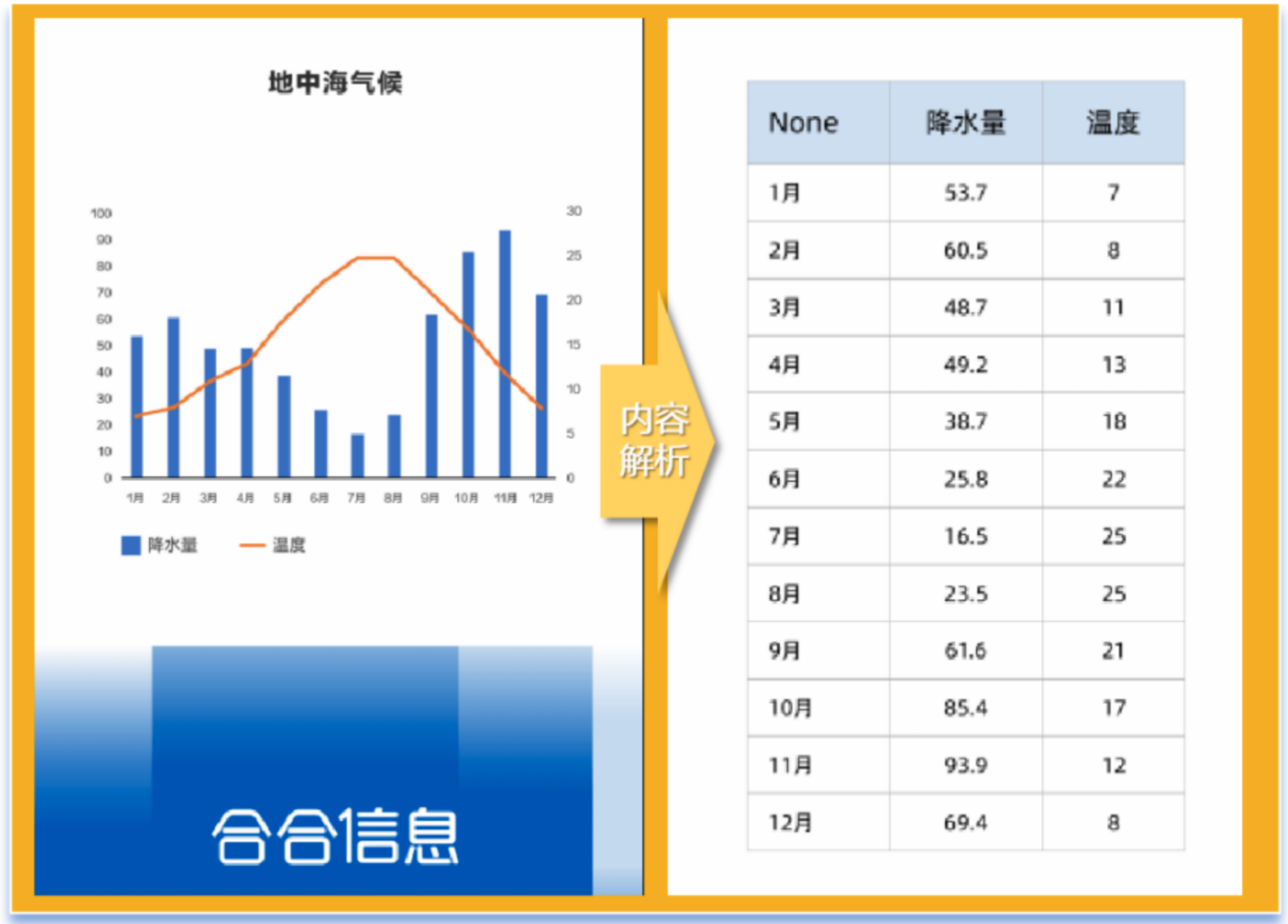
圖:文檔解析引擎將地中海氣候圖表解析為帶有具體數值的Excel表格
在文檔解析引擎的幫助下,大模型可以直接獲取圖表原始的結構化數據,高效地學習理解商業研報和學術論文等專業文檔中的論證邏輯,提升語言理解、數據處理、知識推理分析的效率和準確性,滿足更高價值的金融和學術等應用場景的需要。此外,文檔解析引擎也能做到在圖表不顯示具體數值的情況下,僅依據坐標軸區間估算具體數值,實現了行業級突破。
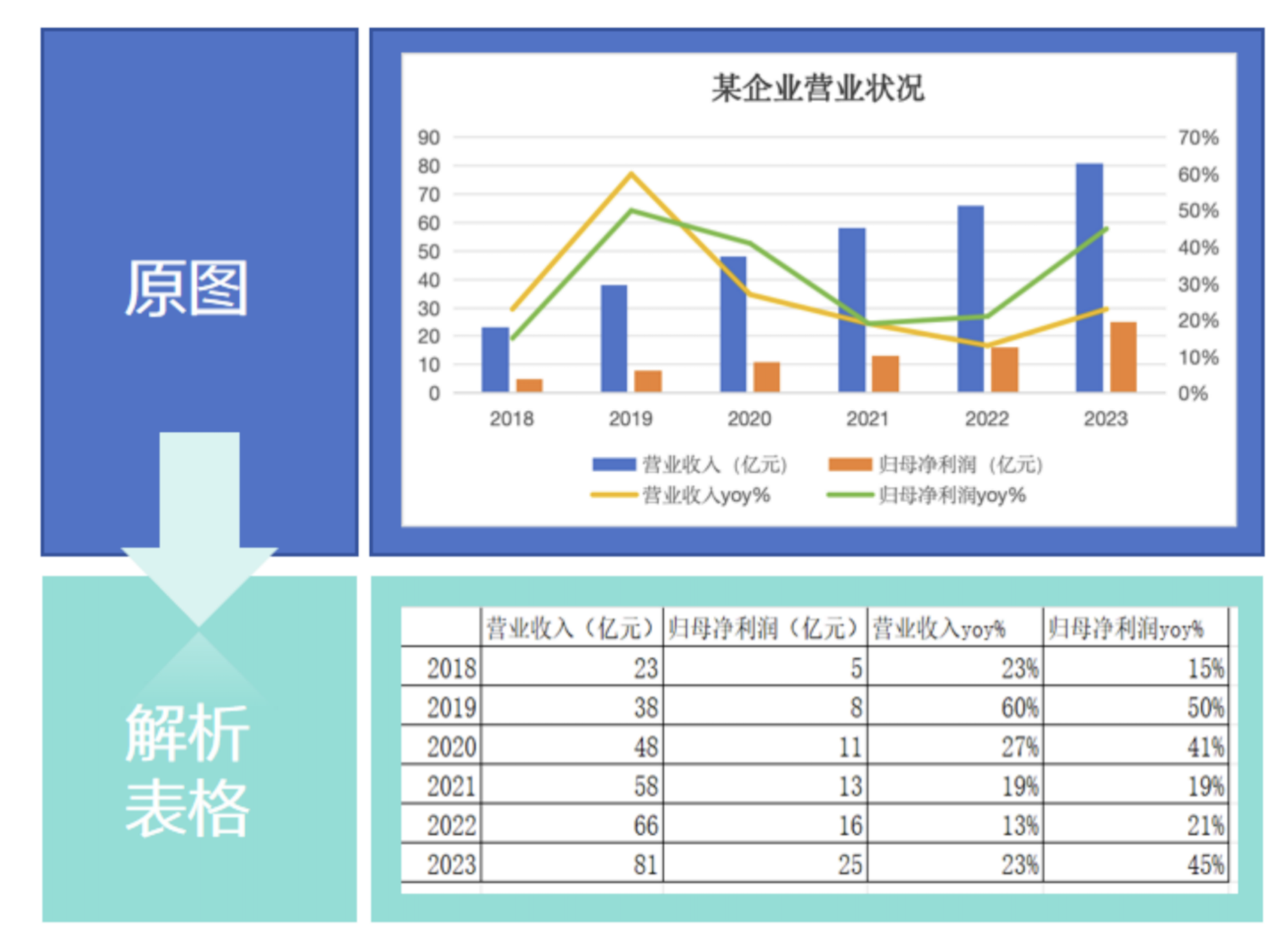
圖:文檔解析引擎基于坐標軸區間,對不顯示具體數據的圖表進行數值估算。
acge模型:為大模型發展打造“指南針”
除了語料質量問題,制約大模型發展的另一個關鍵點在于“幻覺”現象的產生。合合信息大模型“加速器”加載了acge_text_embedding模型(簡稱“acge模型”),通過對大量中文文本數據的深入學習,能夠在應用中顯著提高大模型信息搜索和問答的質量、效率和準確性,讓搜索和問答引擎不再只是匹配文字,而是可以真正理解人的意圖的特性。
如果將大模型比喻為一艘正在行駛的船,acge模型則充分發揮了“指南針”的作用,幫助大模型快速定位通往正確“思路”的航向,在信息的海洋里快速“撈針”,讓大模型更準確地理解專業問題。acge模型具備廣泛的應用場景,從相似性搜索、信息檢索到推薦系統,模型均可提供強有力的技術支撐,極大地提升系統的性能和體驗。
此外,acge模型還引入持續學習訓練方式,克服了神經網絡存在災難性遺忘的問題,可幫助大模型在多個行業中快速創造價值,為構建新質生產力提供強有力的技術支持。
當前,acge模型已在多個應用場景下展現其優勢:
(a) 文檔分類:通過ocr技術精確識別圖片、文檔等場景中的文字,利用acge強大的文本編碼能力,結合語義相似度匹配技術,構建通用分類模型;
(b) 長文檔信息抽取:通過文檔解析引擎與層級切片技術,利用acge生成向量索引,檢索抽取內容塊,提升長文檔信息抽取模型精度;
? 知識問答:通過文檔解析引擎與層級切片技術,利用acge生成向量索引,定位文件內容,實現精準問答。
目前,合合信息大模型“加速器”已被應用于多家頭部大模型廠商的預訓練流程。此外,“加速器”有望在金融、財經、建筑、醫療等數據密集型領域中建立起“行業級知識庫”,幫助企業實現知識資產管理、搜索效率提升,優化業務溝通流程,讓大模型在“源頭活水”的哺育下,更快速地潤澤千行百業。
行業應用:百川智能
在金融報表、行業報告等高知識密度的文檔中,表格的含義是最精華的數據指標。失之毫厘差之千里,一個單元格的理解問題,可能導致整個表格的識別結果產生誤差,而表格的還原準確率,直接影響著模型問答的效果。本次世界人工智能大會現場,合合信息與百川智能攜手,穿透雙欄、多欄、表格、圖片等復雜的版式,從金融、社科等多領域文檔圖像中快速提取關鍵信息,精準地回答用戶“刁鉆”的專業問題,引起了業內人士的關注。
百川智能是一家研發通用人工智能并提供相關服務的公司,核心業務是打造基礎大模型及顛覆性上層應用。在大模型文檔處理場景中,合合信息與百川共同探索技術應用新范式,破解困擾大模型產業已久的多文檔元素識別、版面分析難題,將對百頁文檔的整體處理速率提升超過10倍。
在表格內容還原、復雜樣本處理、多語言文檔識別等方面,合合信息大模型“加速器”具備高準確性和穩定性,大幅提升了模型的理解力,并通過其強大的多語言識別、多類型支持能力,為多個行業提供了高效、準確、實用的文檔解析服務。目前,大模型“加速器”已被多家大模型廠商應用于金融、醫學、財經、媒體等多領域的文檔的解析中,助力大模型更順利地接軌“專業課”。

)















![[數倉]三、離線數倉(Hive數倉系統)](http://pic.xiahunao.cn/[數倉]三、離線數倉(Hive數倉系統))

 網絡訓練對輸入向量進行分類)