學習一個知識,要先了解它的來源
1.?模糊測試的誕生:Barton Miller 的故事
“Fuzz”一詞起源于1988年,由威斯康星大學麥迪遜分校的Barton Miller教授及其研究生團隊在一個高級操作系統課程項目中提出 。這個概念的誕生頗具戲劇性。Miller教授在一次雷雨天氣中通過撥號連接遠程操作Unix計算機時,發現程序因線路干擾導致的輸入失真而反復崩潰 。令他驚訝的是,即使是他認為健壯的程序也無法優雅地處理這些意外輸入,而是直接崩潰 。 ?
這一偶然的發現揭示了現實世界中不可預測的外部因素能夠暴露軟件漏洞的重要性。這不僅僅是關于“錯誤輸入”,更是關于“意外環境條件”對系統穩定性的影響。這種刻意引入混亂以測試系統彈性的概念,與現代“混沌工程”的核心原則不謀而合。模糊測試從其誕生之初,就隱含地認識到系統不僅要能抵御惡意輸入,還要能抵御任何形式的意外或“噪音”數據,這反映了現實世界操作的不可預測性。這使得模糊測試成為一種基本的彈性測試技術,而不僅僅是安全測試技術。
Miller的團隊隨后對Unix、Windows和Macintosh應用程序進行了廣泛研究,通過注入“噪音”輸入,導致了大量程序故障 。模糊測試最初的目標是測試Unix工具的健壯性,通過向其提供隨機輸入數據 。早期模糊測試的一個關鍵貢獻是其簡單的“預言機”:如果程序在隨機輸入下崩潰或掛起,則視為失敗,否則視為通過 。這種簡單而通用的度量標準使得早期模糊測試變得實用,盡管由于其“無紀律性”的方法,它最初遭到了傳統軟件工程界的強烈抵制 。 ?
1.2. Go 語言內置模糊測試機制
Go 語言自 1.18 版本起,將模糊測試作為其標準 testing 包的一部分。
Go 1.19 的改進進一步增強了 ?libFuzzer 模式的檢測能力,從而為變異提供了更好的信號,更有效地探索了被測試代碼。
2.為什么我們還需要一種新的測試方式?
在 Go 語言中,我們離不開單元測試和集成測試,它們幫我們驗證了大量代碼的正確性。但是,它們真的能覆蓋所有情況嗎?
傳統測試方法,如單元測試和集成測試,依賴于已知的輸入和預期的輸出 。開發人員手動編寫測試用例,這可能耗時且容易出錯 。
單元測試:
其核心是“已知輸入 -> 預期輸出”。我們手動設計測試用例,涵蓋正常流程、邊界條件甚至一些已知錯誤場景。
優點:
它非常高效,能快速反饋代碼邏輯是否符合預期。
局限性:
依賴于開發者的想象力。不可能窮舉所有可能的輸入
集成測試:
是驗證多個模塊、組件或外部系統之間協同工作是否正確。
優點:
可以驗證真實交互邏輯,更接近生產環境行為。
局限性:
運行速度慢, 依賴外部環境,穩定性差,調試困難,無法把控所有情況
共同問題:不能發現發現邊界外的未知錯誤和安全漏洞。
很多 Bug 和安全漏洞并非源于業務邏輯的錯誤,而是隱藏在代碼處理異常或惡意輸入的邊緣路徑中。這些路徑在正常流程中幾乎不會被觸發,卻可能導致:
程序崩潰 (Panic): 空指針解引用、數組越界、棧溢出等。
無限循環或資源耗盡: 導致程序掛死,拒絕服務。
內存泄露: 長期運行后性能逐漸下降。
安全漏洞: 例如緩沖區溢出可能被惡意利用進行代碼注入。
模糊測試:
模糊測試:是為了解決“你沒想到的輸入,會不會讓程序崩潰”這一核心問題
案例分析:
模糊測試的作用到底體現在什么地方
案例 1:JSON 反序列化中的棧溢出:
json.Unmarshal包在處理深度嵌套的 JSON 結構時,如果遞歸層級過深,可能導致棧溢出進而引發程序崩潰。
如:{"a": {"b": {"c": {"d": ... }}}} // 嵌套 10000 層
傳統測試:幾乎不會構造一個嵌套上千層的對象來測試。
模糊測試:自動生成深度嵌套的 JSON 輸入。
案例 2:空指針解引用:
驗證一個消息對象是否符合預期的格式和規則。
type Message struct {Header *HeaderBody []byte
}func (m *Message) IsValid() bool {return m.Header.Version > 0 && m.Header.Length == len(m.Body)
}
傳統測試:可能忽略Header為nil。
模糊測試:自動生成數據去驗證。
3.模糊測試:自動化探索代碼的“無人區”
Fuzzing 概覽:它到底是什么,為什么這么強大?
模糊測試 (Fuzzing / Fuzz Testing) 是一種自動化測試技術。它的核心思想很簡單:不斷向你的程序提供大量隨機的、畸形的、非預期的輸入數據,然后觀察程序是否會崩潰、死循環、泄露資源或出現其他異常行為。
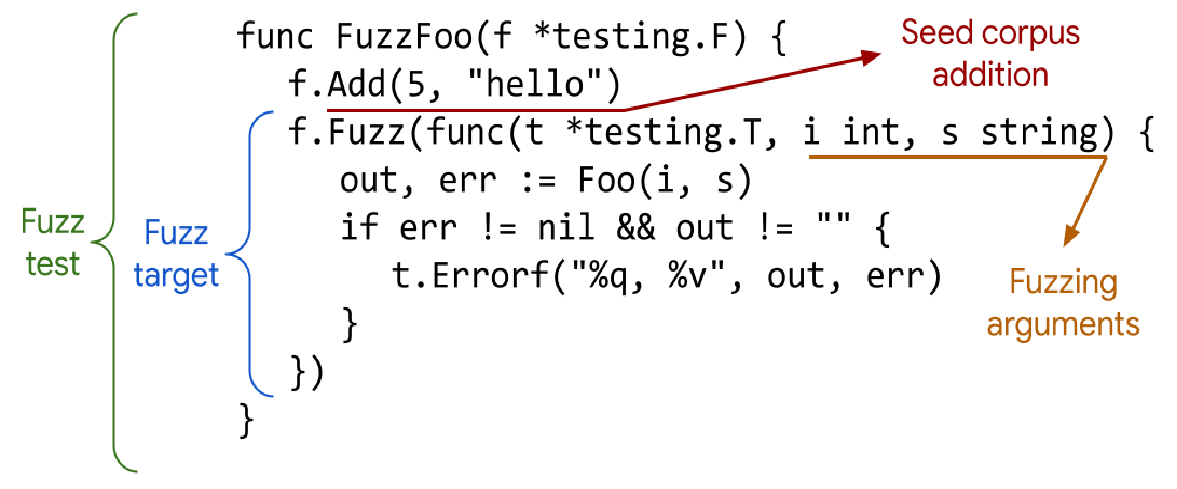
?模糊測試案例:
先說一個概念
什么是“有趣”?
就是導致新代碼路徑、失敗或panic的輸入
func FuzzReverse(f *testing.F) {// 1. 種子語料庫testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}// 2. 模糊測試回調函數f.Fuzz(func(t *testing.T, orig string) {// 3. 待測試的代碼和不變量檢查rev := Reverse(orig)doubleRev := Reverse(rev)if orig != doubleRev {t.Errorf("Before: %q, after: %q", orig, doubleRev)}if utf8.ValidString(orig) && !utf8.ValidString(rev) {t.Errorf("Reverse produced invalid UTF-8 string %q", rev)}})
}1. 種子語料庫(f.Add() )
種子語料庫是模糊測試的“起點”。它由你手動提供的一組初始輸入組成,通常是有效、典型或已知的邊緣情況。
作用: 模糊測試器不是從零開始隨機生成輸入,而是以這些種子語料為基礎,進行變異。提供高質量的種子語料可以幫助模糊測試器更快地探索到代碼中的有趣路徑。
存儲: Go 會將這些種子語料自動存儲在 testdata/fuzz/FuzzReverse 目錄下,并以文件的形式保存。
對應到代碼就是
testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}2. 基線覆蓋率
基線覆蓋率是指模糊測試器在正式開始變異之前,通過運行種子語料庫中的所有輸入所能達到的代碼覆蓋率。它像一張初始地圖,標記了模糊測試已知的探索區域。
工作流程:
1.運行模糊測試
2.模糊測試器首先會執行 f.Fuzz 的回調函數,但輸入只會是 {"Hello, world", " ", "!12345"} 這三個種子。
3.它會監控你的 Reverse 函數在處理這三個輸入時,執行了哪些代碼行和分支。
4.這部分代碼所覆蓋的路徑,就是基線覆蓋率。
作用: 基線覆蓋率是模糊測試器判斷一個新變異輸入是否“有趣”的參照物。只有當新輸入能夠觸發超出基線范圍的代碼路徑時,模糊測試器才會認為它有價值。
3. 生成語料庫
生成語料庫是在模糊測試運行過程中,由模糊測試器自動創建和維護的。它包含所有能夠觸發新代碼路徑或導致程序異常的輸入。
作用:
持續學習: 模糊測試器會優先從生成語料庫中選擇輸入進行變異,而不是只依賴你最初的種子。這讓測試變得越來越智能。
Bug 復現: 如果模糊測試發現一個 Bug,它會把導致 Bug 的具體輸入保存為一個文件。這個文件就是生成語料庫的一部分,你可以用它來精確地復現問題。
4. 模糊引擎(Fuzzing Engine)
模糊引擎,也叫模糊測試器,是執行模糊測試的核心工具。它不像單元測試那樣依賴你預先編寫的固定輸入,而是能夠自動化地、智能地生成大量隨機、畸形或非預期的輸入數據,并將其注入到你的程序中,以尋找那些導致崩潰、掛死或安全漏洞的隱藏 Bug。
組層:
1. 輸入生成器:
這是模糊引擎的起點,負責產生最初的測試數據。
-
種子語料庫 (Seed Corpus): 模糊引擎通常會從一個初始的種子語料庫開始。這些語料是你預先提供的一些“好的”或典型的輸入樣本。高質量的種子語料能幫助引擎更快地探索到有趣的代碼路徑。
-
變異器 (Mutator): 這是引擎最關鍵的組件。它會從語料庫中選取一個輸入,然后對其進行一系列隨機的、智能的“變異”操作來生成新的輸入。常見的變異操作包括:
-
位/字節翻轉: 隨機改變輸入中的某個位或字節。
-
插入/刪除: 在輸入中隨機插入或刪除一些字節。
-
拼接: 將兩個不同的輸入拼接在一起。
-
替換: 用一個預設的“魔術值”(如
0x00、0xFF、"AAA"等)替換輸入中的某個部分。 這些操作旨在創造出各種“意想不到”的輸入,從而挑戰程序的健壯性。
-
2. 代碼插樁器:
為了讓模糊引擎“知道”它生成的輸入是否有效,它需要能夠監控程序的行為,主要就是監控作用。
如:
覆蓋率收集:
-
基本代碼塊(Basic Block): 編譯器會將程序分解成一個個基本代碼塊。如,
if語句的true和false分支,以及循環體,都是不同的基本代碼塊。 -
插樁過程: 插樁器會在每個基本代碼塊的入口處插入一段輕量級的代碼。這段代碼通常只有一個目的:向一個全局共享的、固定大小的數組(例如
cov_map)中寫入數據。-
這個數組的每個元素都代表代碼中的一個基本代碼塊。
-
當一個基本代碼塊被執行時,插入的代碼會將其對應的數組元素值增加。
-
-
反饋機制: 模糊引擎在運行程序后,會檢查這個
cov_map數組。通過對比新舊數組的狀態,它就能判斷新生成的輸入是否執行了之前未探索過的基本代碼塊,從而實現了代碼覆蓋率引導。
崩潰檢測是如何實現的?
模糊引擎會在運行你的程序之前,為其注冊自定義的信號處理器。當程序發生崩潰時,操作系統會發送一個信號。當程序遇到這些信號后,程序就會執行我們自定義的處理代碼。
性能監控是如何實現的?
性能監控主要用于檢測無限循環或資源耗盡等問題,這些問題雖然不會直接導致崩潰,但會使程序無法正常響應,從而構成拒絕服務攻擊(DoS)的威脅。
-
超時機制(Timeout): 模糊引擎會為每次程序執行設置一個超時時間。如果程序在規定的時間內沒有返回結果,引擎就會判定它可能陷入了死循環,并強制終止該進程。
-
內存使用量監控: 模糊引擎會監控程序運行時的內存使用量。如果內存消耗超過了預設的閾值,引擎就會認為程序可能存在內存泄露,并終止這次測試。
3. 反饋循環
這是模糊引擎最智能的部分。
-
優勝劣汰: 模糊引擎會運行變異后的輸入,然后分析代碼覆蓋率。如果一個輸入觸發了之前從未執行過的新代碼路徑,它就會被視為一個“有趣”的輸入。
-
語料庫更新: 引擎會將這個“有趣”的輸入保存到語料庫中。這樣,語料庫就會不斷地“進化”,變得越來越擅長探索代碼的盲區。
-
智能進化: 下一次,引擎會優先從這個包含“有趣”輸入的新語料庫中選取輸入進行變異。通過這個持續的反饋循環,引擎能夠高效地、有目的地探索代碼,而不僅僅是盲目地隨機測試。
4. 調度器
對于并發的模糊引擎,調度器負責管理模糊測試的并行化。
-
多核心利用: 它會在多個 CPU 核心上同時運行多個模糊測試進程(或 Goroutine)。
-
資源協調: 它負責在不同的進程之間同步語料庫,確保每個進程都能利用其他進程發現的“有趣”輸入。
4.親手體驗:編寫與運行
條件:
1.安裝 Go 1.18 或更高版本
2.支持模糊測試的環境。模糊覆蓋范圍 儀器目前僅適用于 AMD64 和 ARM64 架構。
3.文件名必須以 _test.go 結尾。模糊測試函數必須定義在*_test.go 文件中。
4.模糊測試只能測試接收基本類型參數的函數,如string,int ,uint,float32/64,bool,[]byte
5.函數名以 Fuzz 開頭,接收 *testing.F 參數。
?支持參數類型:
| 類型分類 | 具體類型 |
| 字符串/字節 | string, byte |
| 整型 | int, int8, int16, int32 (rune), int64 |
| 無符號整型 | uint, uint8 (byte), uint16, uint32, uint64 |
| 浮點型 | float32, float64 |
| 布爾型 | bool |
?這里以反轉字符為例,演示如何進行模糊測試
func main() {input := "The quick brown fox jumped over the lazy dog"rev := Reverse(input)doubleRev := Reverse(rev)fmt.Printf("original: %q\n", input)fmt.Printf("reversed: %q\n", rev)fmt.Printf("reversed again: %q\n", doubleRev)
}func Reverse(s string) string {b := []byte(s)for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {b[i], b[j] = b[j], b[i]}return string(b)
}這里先以單元測試為例;
對于輸入的測試都能夠通過,但是我們的代碼真正沒有問題嗎?
func TestReverse(t *testing.T) {testcases := []struct {in, want string}{{"Hello, world", "dlrow ,olleH"},{" ", " "},{"!12345", "54321!"},}for _, tc := range testcases {rev := Reverse(tc.in)if rev != tc.want {t.Errorf("Reverse: %q, want %q", rev, tc.want)}}
}運行結果:=== RUN TestReverse
--- PASS: TestReverse (0.00s)
PASS
?我們再通過模糊測試進行測試:
當模糊測試出現問題后回自動生成一個testdata目錄,并把問題數據放在生成的文件里,并作為種子語料庫的一部分,在下次運行使用。
出現問題的數據也會自動生成在FuzzReverse包下。
從運行結果看,我們的代碼是有問題的。
一些字符可能是需要幾個字節,逐字節反轉字符串會使很多字節字符無效
func FuzzReverse(f *testing.F) {testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}f.Fuzz(func(t *testing.T, orig string) {rev := Reverse(orig)doubleRev := Reverse(rev)if orig != doubleRev {t.Errorf("Before: %q, after: %q", orig, doubleRev)}if utf8.ValidString(orig) && !utf8.ValidString(rev) {t.Errorf("Reverse produced invalid UTF-8 string %q", rev)}})
}運行結果:
=== RUN FuzzReverse
=== RUN FuzzReverse/seed#0
--- PASS: FuzzReverse/seed#0 (0.00s)
=== RUN FuzzReverse/seed#1
--- PASS: FuzzReverse/seed#1 (0.00s)
=== RUN FuzzReverse/seed#2
--- PASS: FuzzReverse/seed#2 (0.00s)
=== RUN FuzzReverse/758a9fa2ed45b2dcreverse_test.go:35: Reverse produced invalid UTF-8 string "\x81\xd7"
--- FAIL: FuzzReverse/758a9fa2ed45b2dc (0.00s)=== RUN FuzzReverse/96274f756243ca07
--- PASS: FuzzReverse/96274f756243ca07 (0.00s)
--- FAIL: FuzzReverse (0.02s)FAIL
改進一下Reverse()方法,按字符進行遍歷。
func Reverse(s string) string {r := []rune(s)for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {r[i], r[j] = r[j], r[i]}return string(r)
}模糊測試運行:=== RUN FuzzReverse
=== RUN FuzzReverse/seed#0
--- PASS: FuzzReverse/seed#0 (0.00s)
=== RUN FuzzReverse/seed#1
--- PASS: FuzzReverse/seed#1 (0.00s)
=== RUN FuzzReverse/seed#2
--- PASS: FuzzReverse/seed#2 (0.00s)
=== RUN FuzzReverse/758a9fa2ed45b2dcreverse_test.go:32: Before: "\x81\xd7", after: "��"
--- FAIL: FuzzReverse/758a9fa2ed45b2dc (0.00s)--- FAIL: FuzzReverse (0.00s)FAIL再次進行模糊測試,還是出現了問題。Before: "\x81\xd7", after: "��" 說明在對"\xda"(一個無效的 UTF-8 序列)反轉出現問題
改進一下Reverse()方法,如果是非法utf8字符直接返回。
func Reverse(s string) (string, error) {if !utf8.ValidString(s) {return s, errors.New("input is not valid UTF-8")}r := []rune(s)for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {r[i], r[j] = r[j], r[i]}return string(r), nil
}func FuzzReverse(f *testing.F) {testcases := []string{"Hello, world", " ", "!12345"}for _, tc := range testcases {f.Add(tc)}f.Fuzz(func(t *testing.T, orig string) {rev, err1 := Reverse(orig)if err1 != nil {return}doubleRev, err2 := Reverse(rev)if err2 != nil {return}if orig != doubleRev {t.Errorf("Before: %q, after: %q", orig, doubleRev)}if utf8.ValidString(orig) && !utf8.ValidString(rev) {t.Errorf("Reverse produced invalid UTF-8 string %q", rev)}})
}運行結果:
=== RUN FuzzReverse
=== RUN FuzzReverse/seed#0
--- PASS: FuzzReverse/seed#0 (0.00s)
=== RUN FuzzReverse/seed#1
--- PASS: FuzzReverse/seed#1 (0.00s)
=== RUN FuzzReverse/seed#2
--- PASS: FuzzReverse/seed#2 (0.00s)
=== RUN FuzzReverse/758a9fa2ed45b2dc
--- PASS: FuzzReverse/758a9fa2ed45b2dc (0.00s)
--- PASS: FuzzReverse (0.00s)
PASS
總結: 模糊測試利用其種自動化測試技術。不斷向你的程序提供大量隨機的、畸形的、非預期的輸入數據。
我們在經過一次次模糊測試中一步步更改代碼,直到正確,這是單元測試中很難做到的事情
?5.Fuzzing vs. 單元測試:亦敵亦友,相輔相成
模糊測試和單元測試不是相互替代的關系,而是高度互補的。它們在軟件質量保障中扮演著不同的角色。
目的不同:功能驗證 vs. 健壯性探索
| 特性 | 單元測試 (Unit Testing) | 模糊測試 (Fuzz Testing) |
| 核心目的 | 驗證代碼在已知、預期輸入下的功能正確性。 | 發現代碼在未知、異常輸入下的健壯性和安全性問題。 |
| 輸入來源 | 開發者手動編寫,基于對需求的理解。 | 模糊器自動化生成,智能變異現有語料。 |
| 輸入范圍 | 有限、典型、邊界條件。 | 海量、隨機、畸形、邊緣情況。 |
| 關注點 | 行為符合預期 (即輸出與預期一致)。 | 程序不崩潰、不死循環、不泄露資源。 |
| 發現問題 | 邏輯錯誤、功能缺失、API 契約不符。 | 程序崩潰、死循環、內存/資源泄露、拒絕服務、安全漏洞。 |
| 運行速度 | 快,適合頻繁運行和 CI/CD。 | 慢,通常需要長時間運行才能發揮效果。 |
| 適用場景 | 幾乎所有代碼,尤其適用于業務邏輯的精確驗證。 | 處理外部輸入的模塊(解析器、編解碼器、網絡協議等)。 |
| 提交版本控制 | TestXxx 測試代碼。 | FuzzXxx 測試代碼和語料庫。 |
價值互補:共同構建無懈可擊的代碼防線
- 單元測試是基礎: 它是你代碼正確性的第一道防線。在編寫任何功能時,首先要通過單元測試來確保其在正常和預期場景下是可靠的。
- 模糊測試是加強: 它是你代碼健壯性的第二道防線。它彌補了單元測試的覆蓋盲區,幫助你發現那些隱藏最深、最難以預測的 Bug,尤其是在安全性和穩定性方面。
最佳實踐:如何讓它們發揮最大效能?
- 單元測試先行: 始終遵循測試驅動開發或至少在編寫功能后立即編寫單元測試,確保核心邏輯的正確性。
- 為關鍵模塊引入模糊測試: 識別項目中那些與外部、不可信數據打交道的組件(如協議解析、數據轉換、文件讀取器),它們是模糊測試的理想目標。
- 設計高質量的種子語料: 提供少量但能覆蓋不同分支的有效輸入作為種子,能顯著提高模糊測試的效率。
6.參考來源:
Tutorial: Getting started with fuzzing - The Go Programming Language
Go Fuzzing - The Go Programming Language







![C語言-指針[指針數組和數組指針]](http://pic.xiahunao.cn/C語言-指針[指針數組和數組指針])





免安裝中文版)





