模版引擎

數組join法(字符串)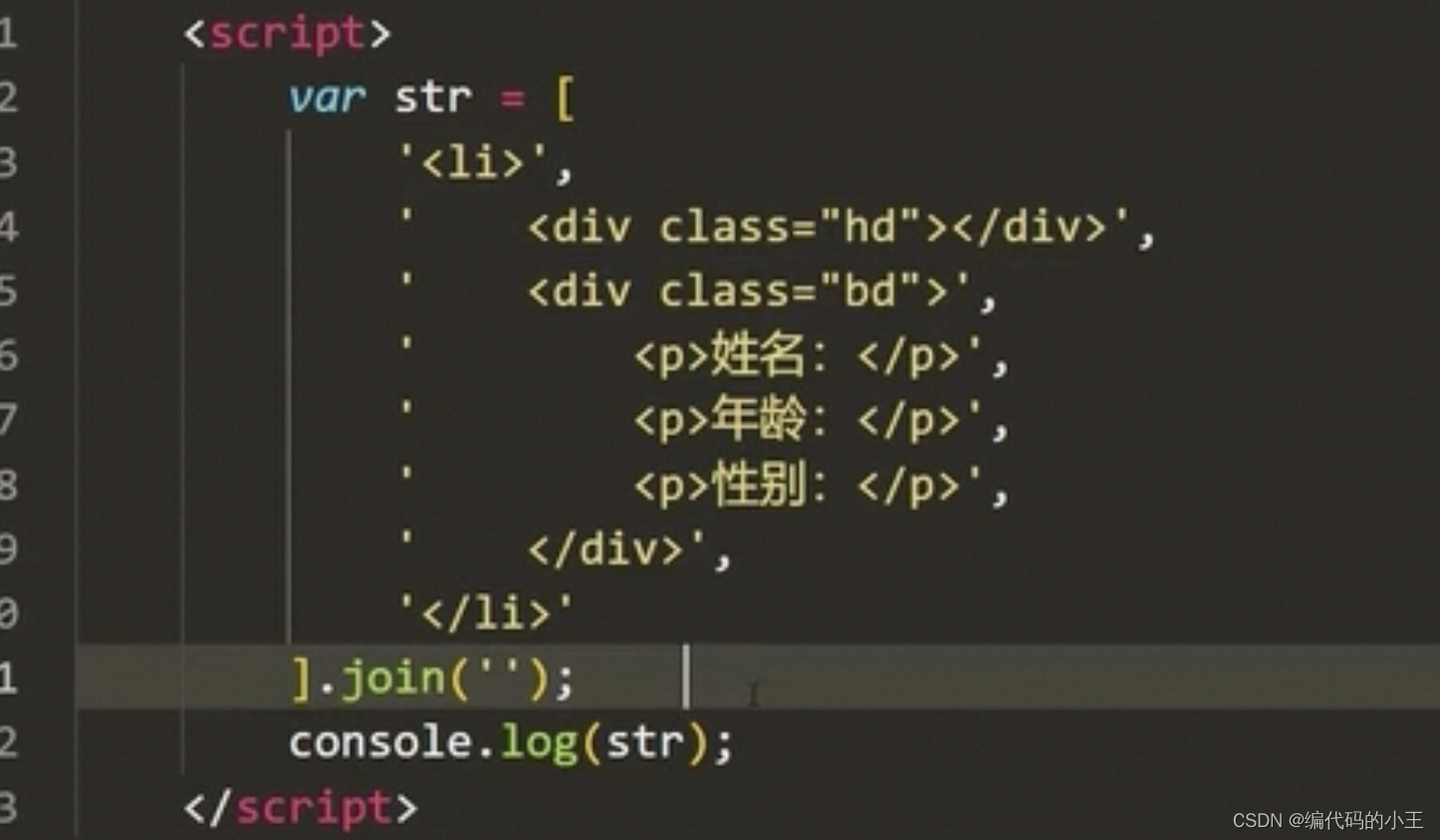
es6反引號法(模版字符串換行)
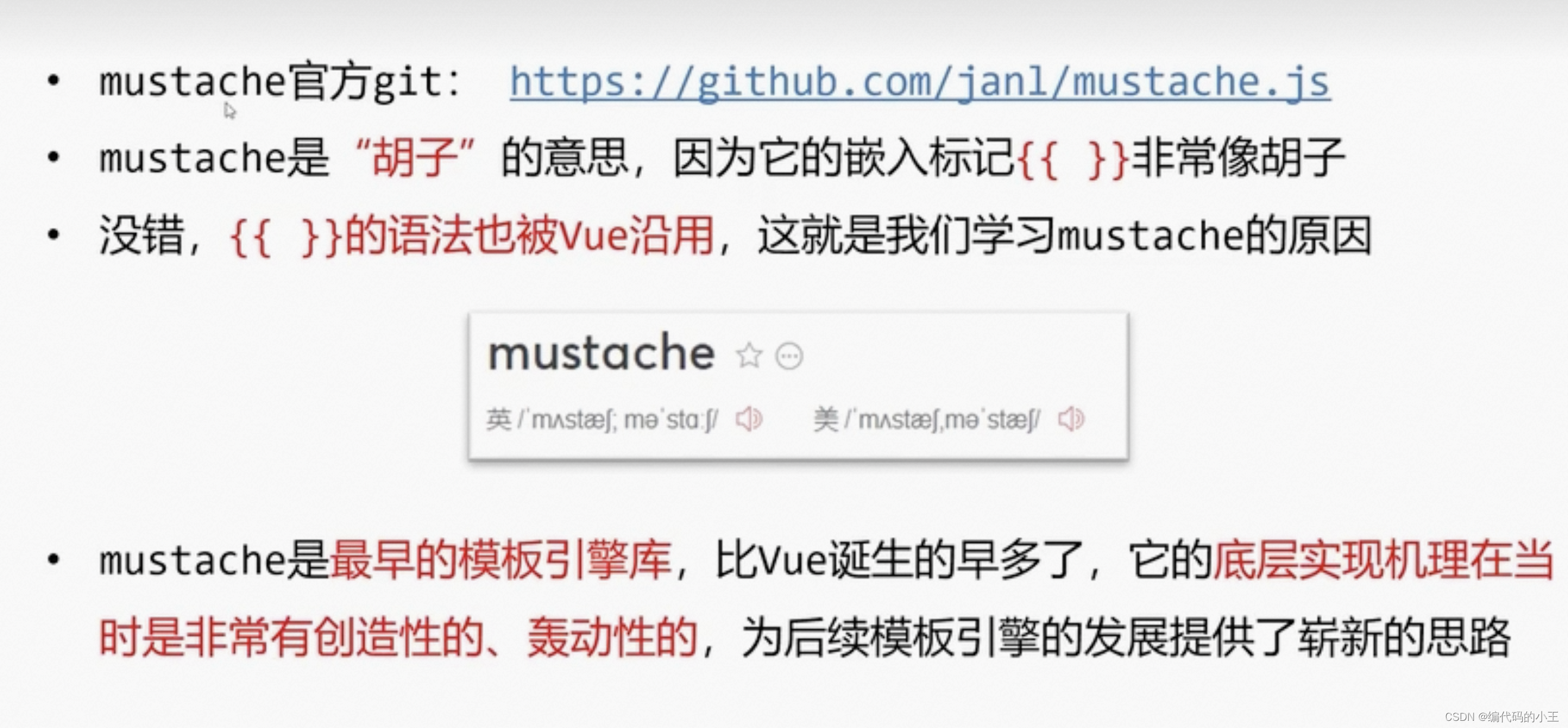
mustache (小胡子)
引入mustache

模版引擎的使用
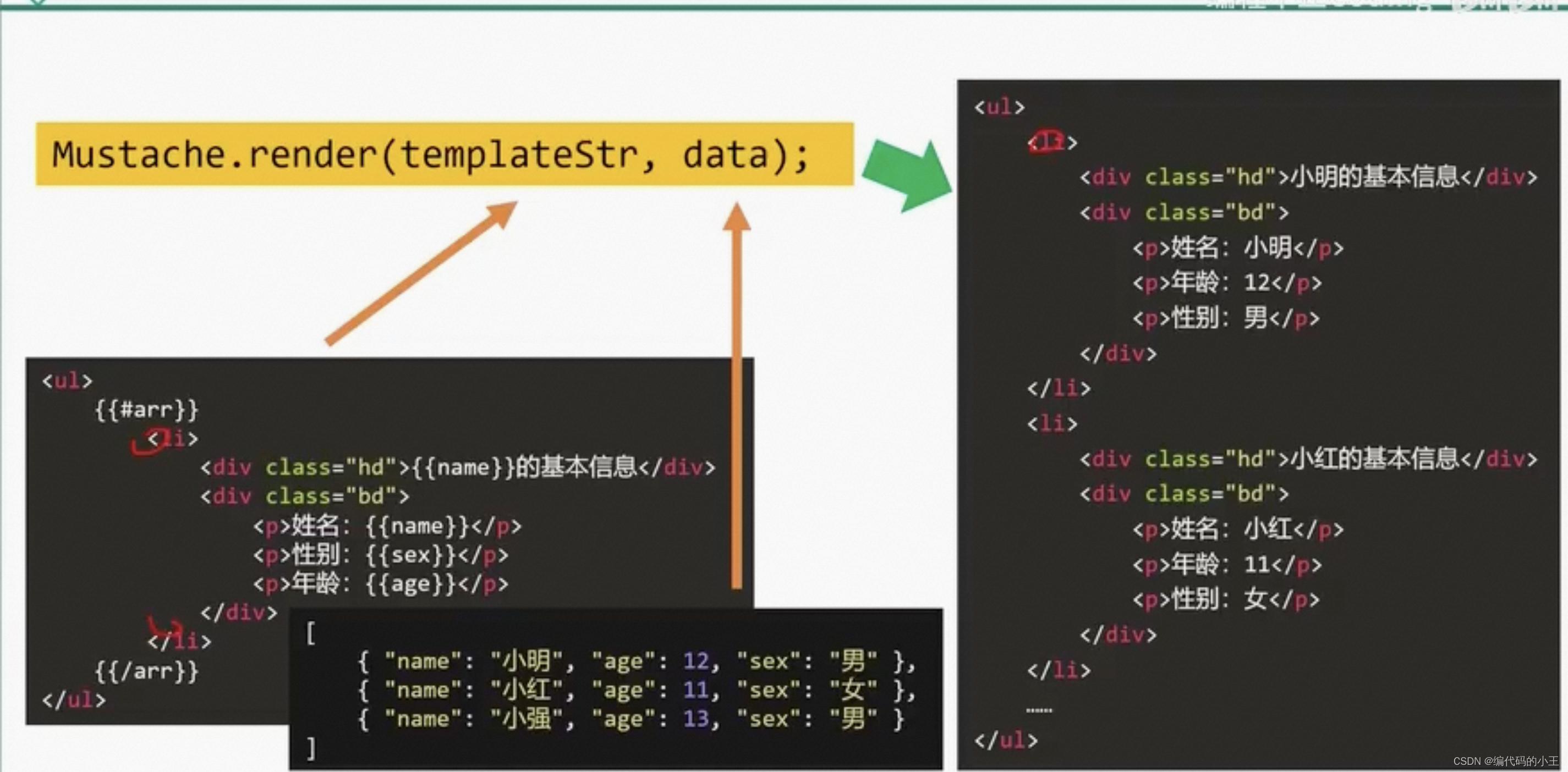
mustache.render(templatestr,data)
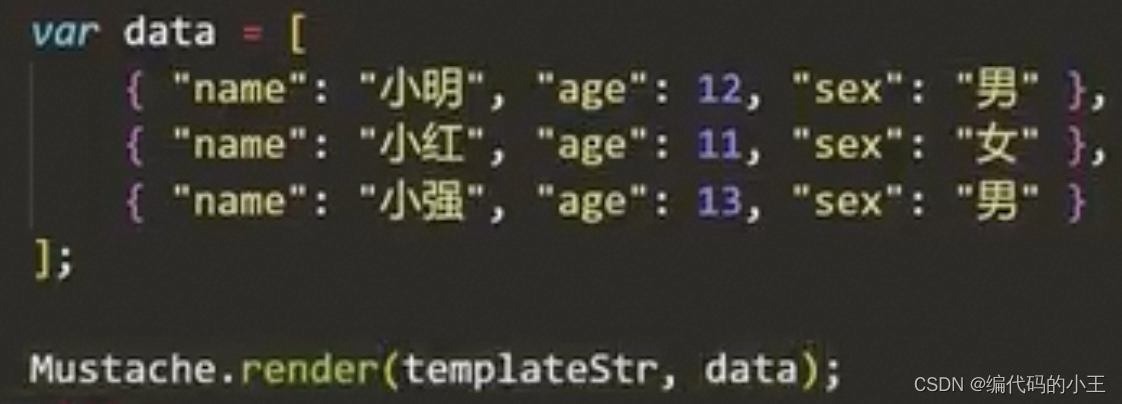
mustache.render
循環簡單數組??
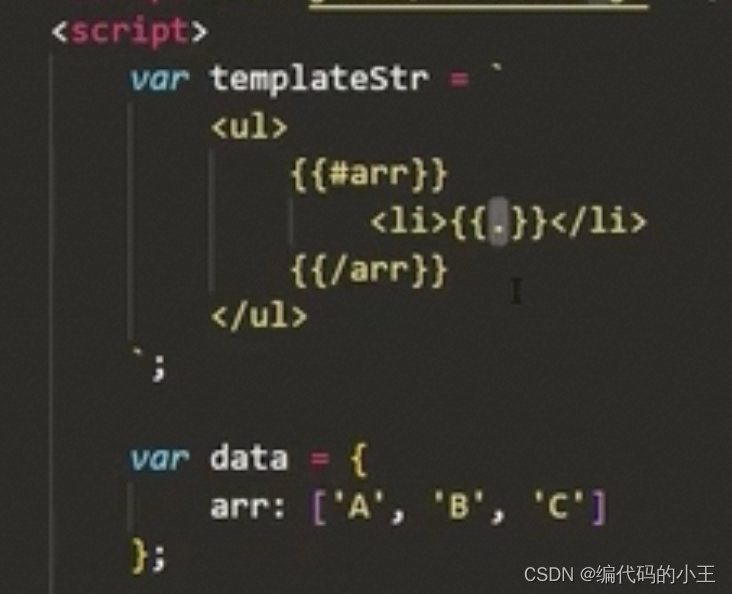
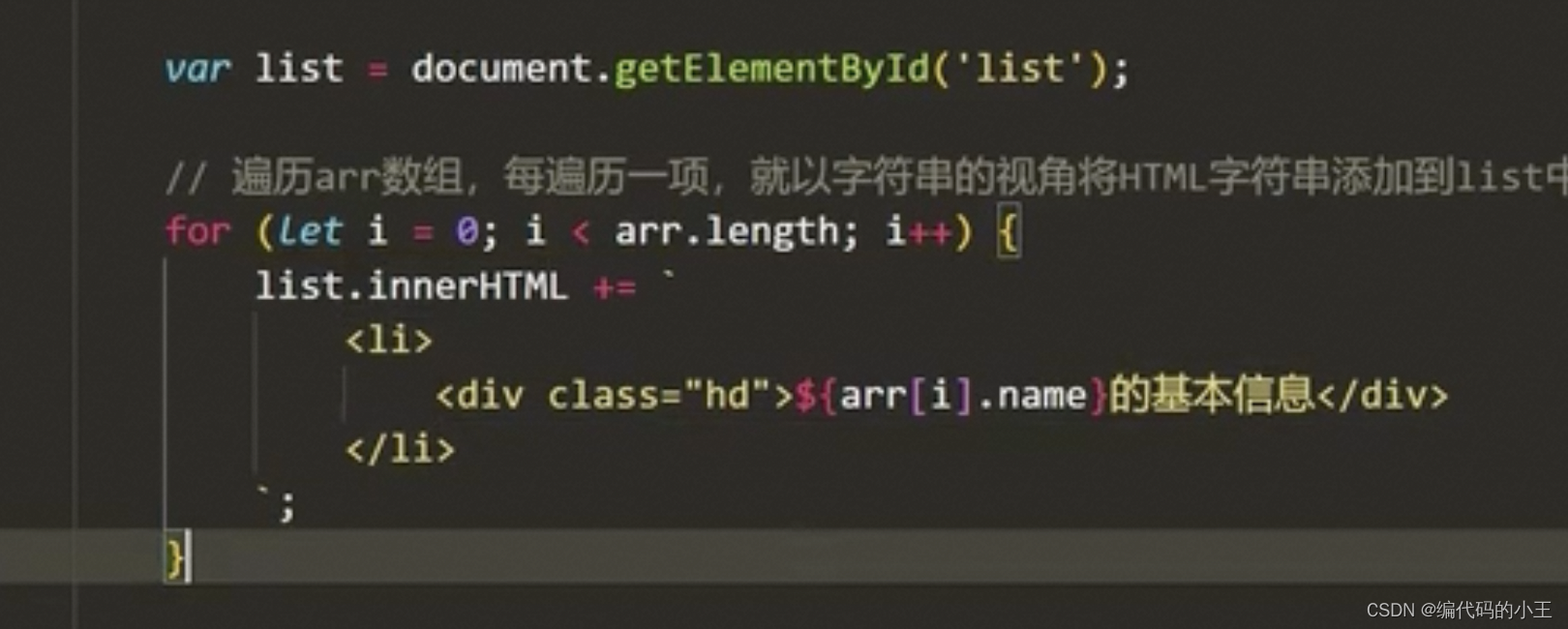
循環復雜數組
循環單項數組
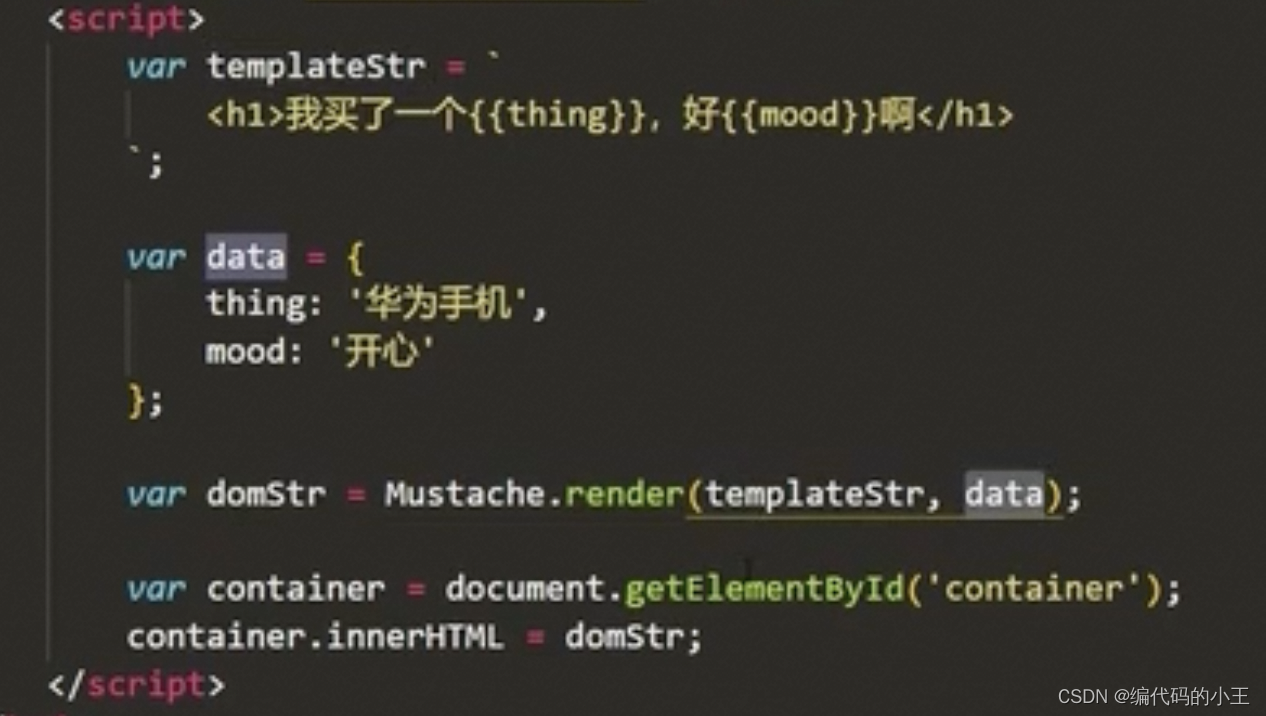
數組的嵌套

mustache底層核心機制
使用正則實現簡單的替換機制(注意點replace替換的時候第二個參數可以為一個函數函數的形參,第一個參數代表查詢的第一個正則機制,第二個為找到data中的第二個參數)

但是mustache不能簡單使用正則來表示,他中間的話牽扯到的數據類型比較復雜
mustache的原理
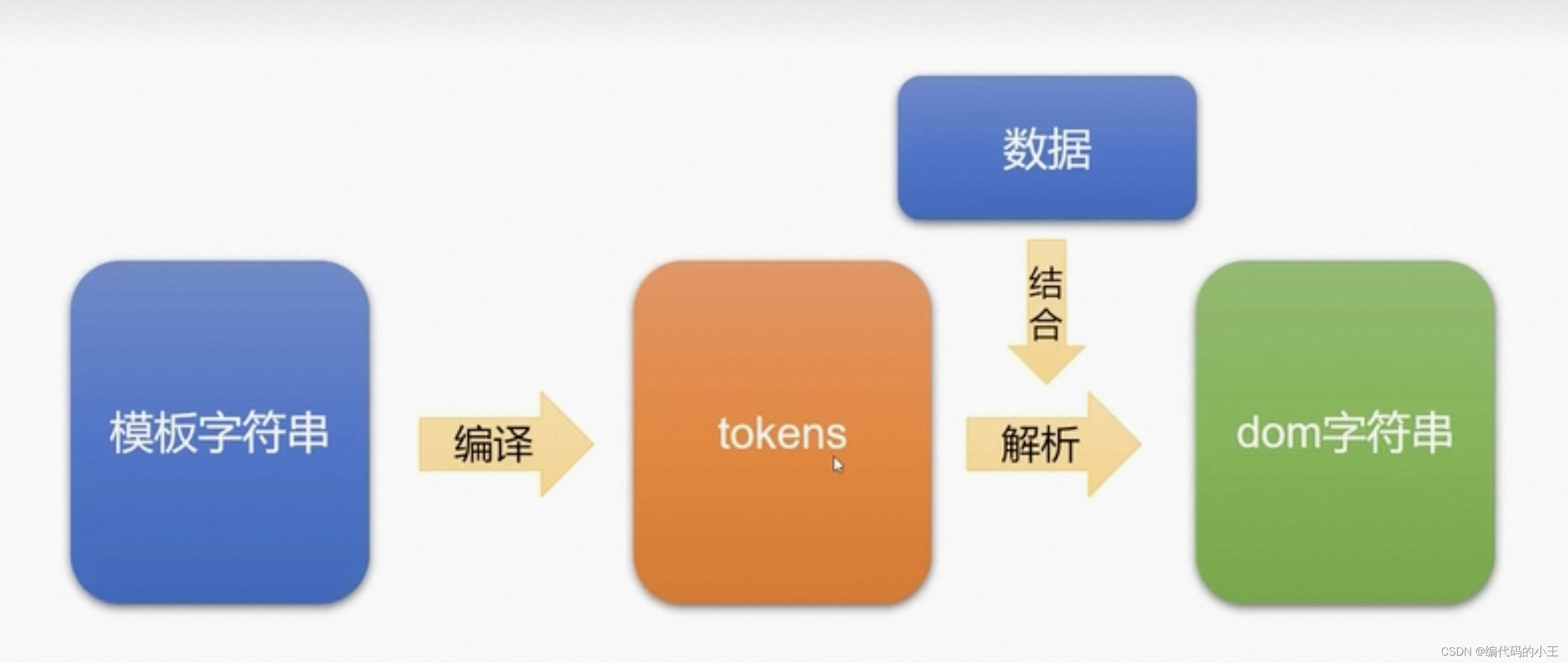 什么是tokens
什么是tokens

循環狀態下的tokens

手寫mustache庫?

安裝依賴運行node解析js文件
npm init
npm i -D webpack@4 webpack-dev-server@3 --legacy-peer-deps 新建webpack.congfig.js文件
const path = require('path') // 引用path模塊module.exports = { // 這里是commrnt.js語法// 使用開發模式打包mode:"development",// 入口文件entry:"./src/index.js",// 打包后的出口文件output:{filename:'build.js',},devServer:{contentBase:path.join(__dirname,"www"),compress:false,port:8000,publicPath:'xuni'}
}
建立這樣的文件格式
 ? ? ??
? ? ??
index.html文件代碼如下
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title></title>
</head>
<body><script src="/xuni/build.js"></script><script>let temple= `我買了一個{{thing}},好{{good}}`let data={}console.log(window. window.vueMustache);window.vueMustache.render(temple,data)</script>
</body>
</html>我們需要手寫算法了!!!!
這個文件是掃描器函數
這個文件是我們需要獲取到當前的文件格式
掃描器函數的目的就是為了獲取模版,并把它進行拆分
具體的拆分如下
我們把這個模版分為scanUntil和scan2個過程,scanUntil是模擬的是"{{"之前的把它拆分出去,scan這個函數是相當于跳過”{{“,利用scasnUntil這個函數對他進行運用
判斷代碼邏輯如下
// 掃描器函數
export default class Scanaer{constructor(temple){console.log("我是",temple);//將子列寫在自己身上this.temple=temple//設計一個指針this.pio=0;//尾巴,最開始尾巴是全文this.tail=temple}//相當于是跳過“{{”這個字符沒有返回值scan(tag){if(this.tail.indexOf(tag)==0){this.pio+=tag.length;//尾巴也要進行變化為從當前指針開始到最后的所有字符this.tail=this.temple.substring(this.pio)}}// 讓指針掃描,遇見指定內容返回,并返回結束前的返回值scanUtil(stopTop){//記錄當前位置指針的當前位置let pio_backup=this.pio// 當尾巴不等于0的時候,或者當我的指針小于當前字符串的長度的時候,如果不小于當前的長度的話就會一直往后走,導致死循環while(this.eos()&&this.tail.indexOf(stopTop)!==0){this.pio++//讓尾巴也跟著變化,獲取到指針位置變化后的尾巴this.tail=this.temple.substring(this.pio)}//返回指針開始的值到現在的值的所有文字return this.temple.substring(pio_backup,this.pio)}//判斷我的指針小于當前字符串的長度的時候,如果不小于當前的長度的話就會一直往后走,導致死循環 end 0f stringeos(){return this.pio<this.temple.length}
}在index。js文件中的代碼
import Scanaer from "./Scanner";
window.vueMustache={render(temple,data){//實例化一個掃描器,構造時提供參數,這個參數就是模版字符串//這個參數就是給模版字符串工作的let Scanaerl=new Scanaer(temple)// let a= Scanaerl.scanUtil("{{")// console.log(a,);// console.log(Scanaerl.pio,"測試掃描器函數是否能到指定內容返回");// Scanaerl.scan("{{")// console.log(Scanaerl.pio,"測試掃描器函數是否可以跳過指定內容");while(Scanaerl.pio!=temple.length){let a= Scanaerl.scanUtil("{{")console.log(a,"獲取到的");Scanaerl.scan("{{")let b= Scanaerl.scanUtil("}}")console.log(b,"獲取到的");Scanaerl.scan("}}")}}
}生成tokens數組

創建這樣的目錄文件
import Scanaer from "./Scanner";
export default function createTokens(temple) {let tokens = [];let scanaer = new Scanaer(temple);let word;//讓掃描器工作while (scanaer.eos()) {console.log("111");word = scanaer.scanUtil("{{")//運行到word到最后的時候會出現字符串的情況if (word !== '') {tokens.push(["text", word])}scanaer.scan("{{")word = scanaer.scanUtil("}}")//判斷是否是#或者/的判斷if (word !== "") {if (word[0] == "#") {tokens.push(["#", word.substring[1]])} else if (word[0] == "/") {tokens.push(["/", word.substring[1]])} else {tokens.push(["text", word])}}scanaer.scan("}}")}return tokens
}index,js文件
import Scanaer from "./Scanner";
import createTokens from "./createTokens.js"
window.vueMustache={render(temple,data){let tokens=createTokens(temple)console.log(tokens);}}但是以上的方法不能滿足于二維數組的使用

,IP6557+IP6538)















【未完】)

