一、樹模型與決策樹基礎
決策樹概念:從根節點開始一步步走到葉子節點得出決策,所有數據最終都會落到葉子節點,既可用于分類,也可用于回歸。
樹的組成
????根節點:第一個選擇點。
????非葉子節點與分支:中間決策過程。
????葉子節點:最終的決策結果。
二、決策樹的訓練與測試
訓練階段:從給定的訓練集構造樹,核心是從根節點開始選擇特征并進行特征切分。
測試階段:根據構造好的樹模型從上到下走一遍即可完成分類或回歸任務。
難點:如何構造出一棵樹,涉及特征選擇與切分等問題。
三、特征切分相關衡量標準
核心問題:如何選擇根節點及后續節點的特征,如何進行切分。目標是通過衡量標準找到能更好切分數據(分類效果更好)的特征作為節點。
熵
????定義:表示隨機變量不確定性的度量,公式為H(X)=- ∑ pi * logpi, i=1,2, ... , n。
????特點:不確定性越大,熵值越大;
信息增益:表示特征X使得類Y的不確定性減少的程度,分類后希望同類數據在一起,即提高分類的專一性。
四、決策樹構造實例
數據與目標:基于14天打球情況的數據,包含4種環境變化特征,目標是構造決策樹。
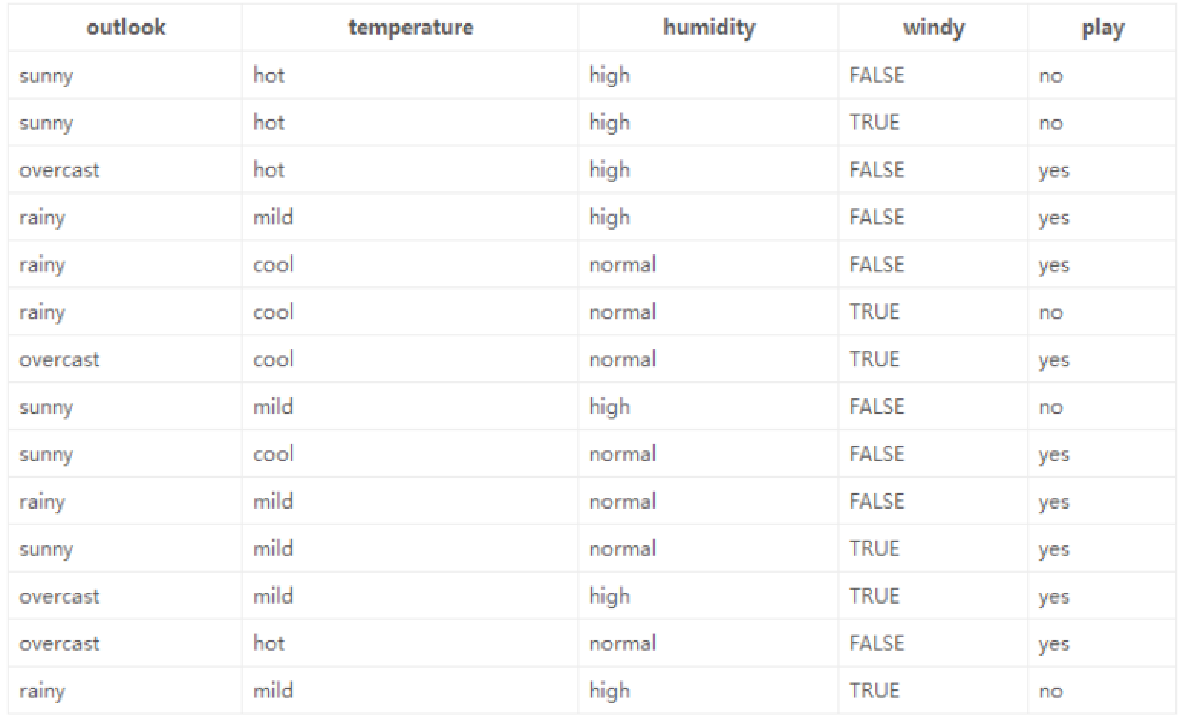
計算過程
????原始數據中9天打球,5天不打球,先計算此時的熵。
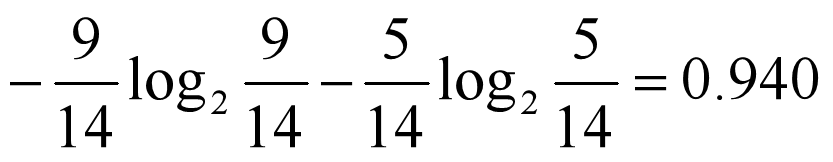
????對4個特征逐一分析,以outlook特征為例,計算其不同取值時的熵值,再結合各取值的概率計算該特征下的總熵值,進而得出信息增益。


????選擇信息增益最大的特征作為根節點,再在剩余特征中按同樣方式選擇后續節點。
?五、課堂練習



![第十六屆藍橋杯青少組C++省賽[2025.8.10]第二部分編程題(6、魔術撲克牌排列)](http://pic.xiahunao.cn/第十六屆藍橋杯青少組C++省賽[2025.8.10]第二部分編程題(6、魔術撲克牌排列))



)
)
Hbase替代方案)


,實現交互式 3D blob)
)
)



:脫圍機制二)
)
