目錄
1 棧
2?隊列
3 deque 介紹
4 優先級隊列
5 反向迭代器
棧也是我們在C語言就模擬實現過的一種數據結構,在C++中,棧其實和我們前面模擬實現過的string、vector等容器有一點區別,站起是不是容器,而是一種容器適配器,我們可以打開C++官方文檔找到stack的介紹來看一下
同時我們打開隊列的文檔就會發現,隊列也是一種容器適配器,

那么適配器到底是什么東西呢?適配器其實是一種設計模式,是一套被反復使用、多數人知曉的、經過分類編目的、代碼設計經驗的總結。使用設計模式是為了可重用代碼、讓代碼更容易被他人理解、保證代碼可靠性、程序的重用性。
在前面的容器的模擬實現中,困擾我們頗多的迭代器也是一種設計模式。而適配器是設計模式中結構模式中的一種。 適配器本質上是進行轉換的,使用現有的東西封裝轉換成你想要的東西。
1 棧
我們說棧是一種容器適配器,而適配器的本質是進行轉換。 ?
?
我們發現棧的結構很少,因為他的結構限制了他的接口,而在之前C語言我們實現棧使用一個動態順序表來實現的,因為棧的接口其實就相當于順序表的尾插尾刪,使用數組完成效率很高,這其實就是一種轉換,我們將順序表通過封裝接口轉換出我們想要的棧。而在C++中,我們也能夠使用前面模擬實現過的 vector 和 list 來作為棧的適配容器,具體使用哪個其實都行,在棧的實現上,它們各有千秋,而我們看到的庫里面的棧的默認適配容器則是一個雙端隊列 deque ?
?
這個容器我們還沒學過,在棧和隊列后面會講一下。
目前我們實現棧就使用vector來作默認容器,因為其實 vector 實現棧的效率其實跟deuqe差不多的。棧的基本的結構如下,就是一個vector,然后封裝vector的接口來實現棧的接口
 ?
?
 ?
?
棧的構造函數只有一個,而這個構造函數我們直接理解為無參的構造就行了,這里的缺省值的意思其實就是可以使用我們的適配器容器的對象來初始化,但是我們一般實現棧是不需要這樣初始化的。
既然是一個無參構造,那么我們需要自己寫嗎?不需要,因為編譯器自動生成的就夠用了,棧對象中只有一個我們實現過的vector的對象,而我們實現過的vector是有默認構造的,那么編譯器自動生成構造函數就會去調用vector的默認構造去對st進行初始化。那么析構也是一樣的,我們也不需要自己去實現。
那么剩下的幾個接口 size 、empty 、top 、 push 、pop就很簡單了。
????????
bool empty()const{return st.empty();}size_t size()const{return st.size();}T& top(){assert(!empty());return st.back();}const T& top()const{assert(!empty());return st.back();}void push(const T& val){st.push_back(val);}void pop(){assert(!empty());st.pop_back();}這樣一來,一個簡單的棧就實現了。棧是不需要實現迭代器的,因為不需要,對于棧而言,遍歷整個棧就是需要用戶不斷地取top,然后pop,而不是像容器一樣通過迭代器遍歷。
2?隊列
隊列是先入先出的結構,也就是頭插和頭刪,尾插頭刪vector的效率就不如list了,所以我們實現queue使用list作為默認容器。 ?
?
 ?
?
其他的接口也基本上和stack差不多
bool empty()const{return q.empty();}size_t size()const{return q.size();}const T& front()const{assert(!empty());return q.front();}const T& back()const{assert(!empty());return q.back();}void push(const T& val){q.push_back(val);}void pop(){assert(!empty());q.pop_front();}3 deque 介紹
為什么stack和queue的默認適配容器都是 deque?雙端隊列呢?deque到底是何方神圣?
在介紹 deque之前,我們先回想一下vector和list都有什么缺點。vector的缺點就是擴容的開銷大,因為他的擴容需要挪動數據,同時他的頭插頭刪的開銷也很大,不適合作為隊列的適配容器。 而list的缺點則是不支持隨機訪問,同時由于空間不連續,他的CPU高速緩存命中率低。
那么能不能設計一個容器,能夠完美融合vector和list的優點,同時能夠規避他們的缺點呢?從結果上來說,肯定是沒有的,如果有容器能夠完美替代vector和list,如今我們也不會學習這兩個容器了,早就被湮沒在歷史中。雙端隊列就是一個兼具?vector 和 list 的優點的一個容器 ,比如他的頭插頭刪效率高,cpu命中率高等,但是他的這些性能都比不上單獨拎出來的 list 和vector,相當于不上不下的水平,list 和vector在各自的領域是極致效率的,而deque的效率最多只能用拔尖來描述,比不上list 和vector。
deque是怎么做到既適合頭插頭刪,同時cpu命中率還高的呢?這就要從它的結構說起了。
deque其實是由一個一個的數組來構成的,同時 deque 內部存儲了一個指針數組,來保存些數組的地址。
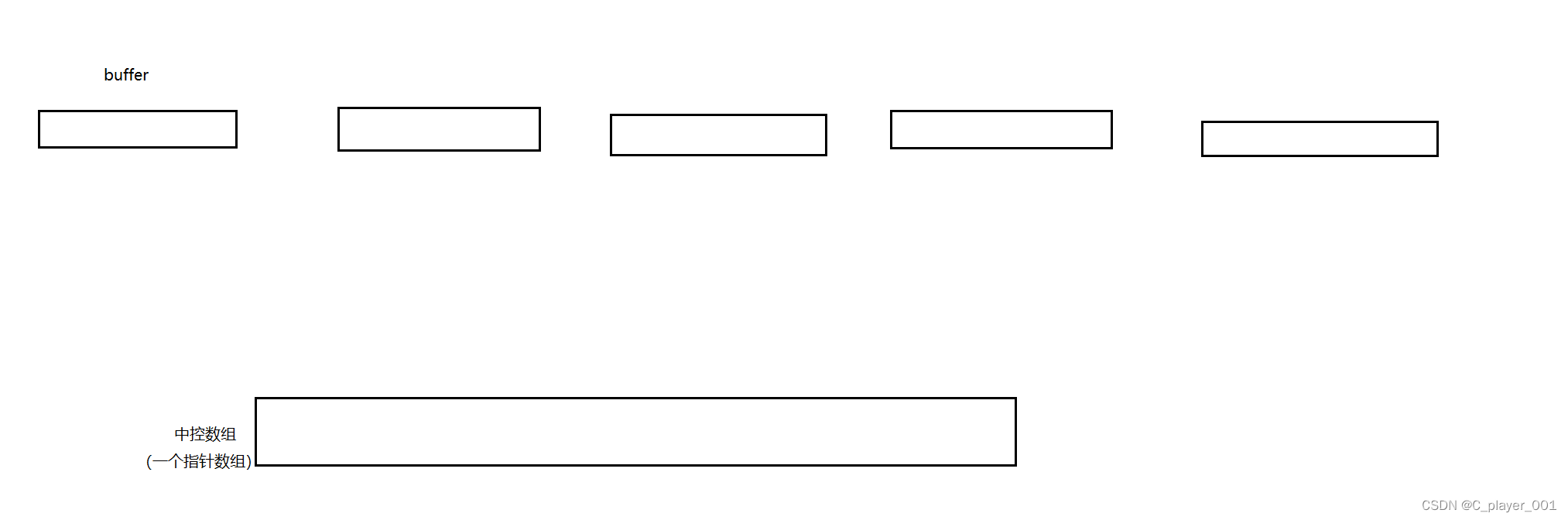 ?
?
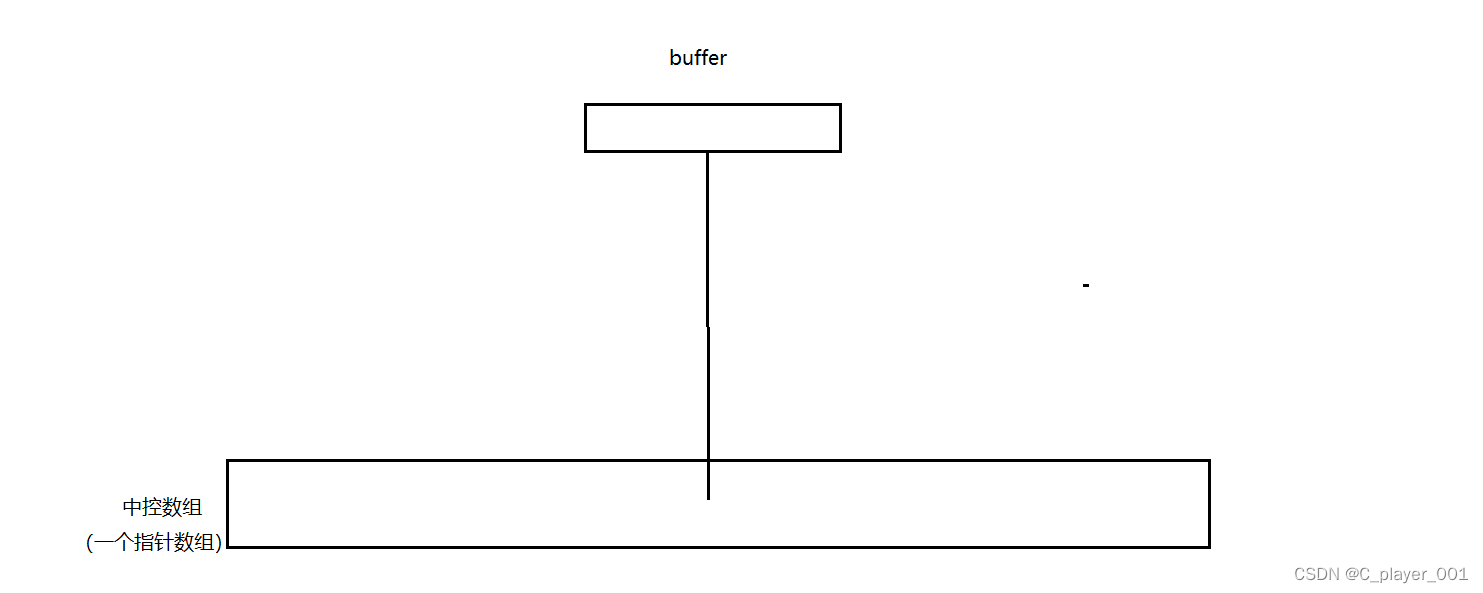
當我們第一次插入數據時,首先申請一個數組buffer,buffer的大小是由我們自己來指定的靜態數組。 第一個申請的數組的指針保存在 中控數組的中間位置上
 ?
?
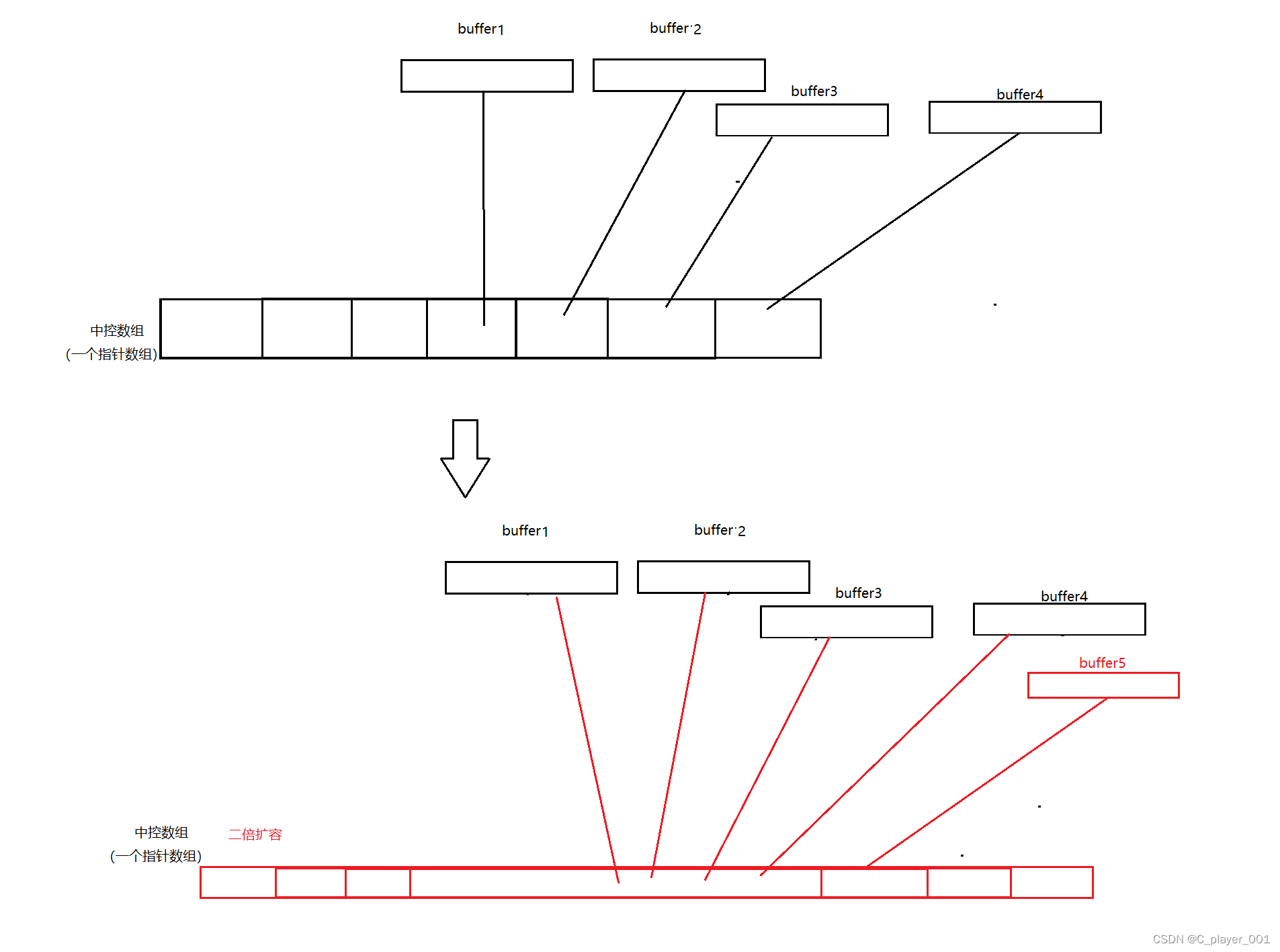
而當我們不斷尾插數據時,數組的尾部進行插入,如果數組滿了,再次尾插,則會再開辟一個同樣大小的數組,將數組的地址保存在中控數組的后一個位置
 ?
?
依次類推,當尾插到一定數量時,中控數組的后半部分都已經被填滿了,這時候就會被中控數組進行二倍擴容
 ?
?
擴容之后會將原中控數組保存的指針全部拷貝到新的數組中,同時不會釋放原來的 buffer ,再創建一個新的buffer來存儲新插入的數據。 所以說,deque其實也是有擴容的消耗的,只是他的消耗相比于vector來說要小得多,它只需要挪動指針數組就行了。
而如果要頭插的話,則需要在中控數組的中間位置的前面填充新創建的buffer的指針,然后將新的數組從專門用于頭插的 buffer 的尾部開始插入,不斷往前插入,過程基本類似于尾插。
而deque支持的隨機訪問則需要在 [ ]重載的時候進行一定的運算轉換來找到對用下標的數據,所以他的隨機訪問的效率其實也是不如vector的。
同時,我們也能發現一個問題,就是deque在進行中間位置的插入刪除的話會很復雜,如果要插入或者刪除的數據個數剛好是 buffer 大小的整數倍還好說,如果不是整數倍,則要比 vector 和list 麻煩的多,所以其實deque的任意位置插入刪除的效率也是比不上 list 的?
但是這其實也是它的優勢所在,他進行除了中間位置插入刪除之外的其他的操作的操作都還不錯,我們知道 queue 和stack是不需要中間位置的插入刪除的,所以由 deque 作為 stack 和 queue 的默認適配容器剛剛好,很通用。?
如果要模擬實現 deque ,最復雜的其實還不是他的下標轉換以及他的中間位置的插入刪除,而是他的迭代器的實現,他的迭代器的實現需要四個指針來實現,具體的實現大家可以在網上查閱相關資料,總之十分的復雜,簡直折磨人 。我們只需要知道她大概的實現就OK了,最重要的就是中控數組也就是一個指針數組就行了。
4 優先級隊列
優先級隊列其實就是把優先級最高的或者優先級最低的數據放在第一個,那么之前我們有沒有學過類似的結構呢? 學過,就是我們的堆。 大堆就是把最大的數放在堆頂,也就是優先級最高的數據放在最前面,而小堆就是把優先級最小的數據放在最前面。而我們以前實現了堆,他的物理結構其實是一個數組,也就是一個vector,而他的邏輯結構我們看成是一棵完全二叉樹。
那么優先級隊列的默認適配容器我們就能夠使用vector來實現。同時,雖然他叫做優先級隊列,但是他的本質上還是一個堆,同時他也只能夠讀取頭部數據以及頭刪,他的插入是需要進行調整來保證堆結構的。
我們可以看一下庫里面的優先級隊列的模板參數,我們發現模板參數除了我們意料之中的數據類型,適配容器,還有一個 less<...> ,這個less< >相信我們在leetcode刷題的時候或者我們使用sort的時候也經常使用。

我們先不管這個less 仿函數,假設我們就用 vector 實現一個大堆,實現完之后我們再將仿函數加上。
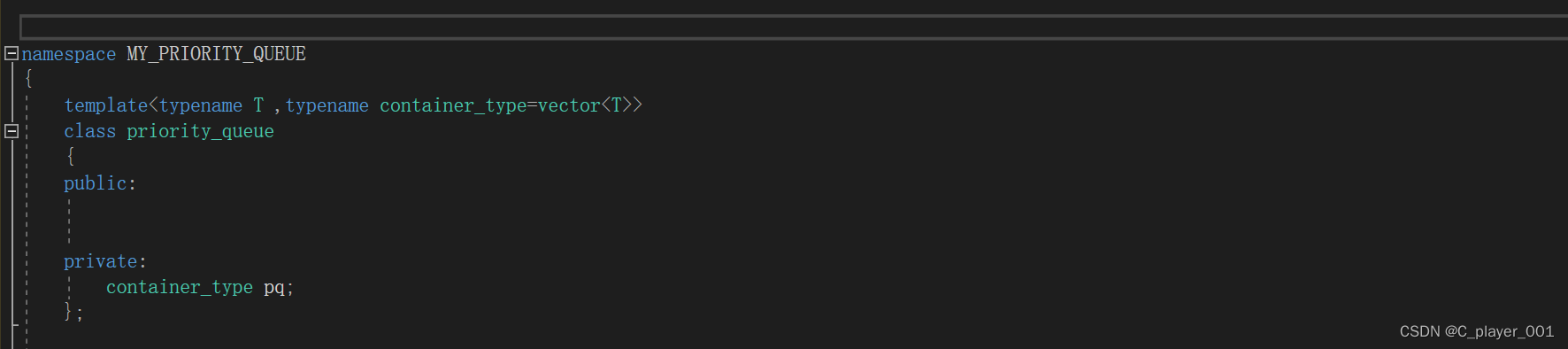

他的接口中,默認的構造和析構編譯器自動生成的就夠用,不需要我們自己寫。而 empty ,size 和top接口實現起來也十分簡單,
public:bool empty()const{return pq.empty();}size_t size()const{return pq.size();}const T& top()const{assert(!empty());return pq[0];}他的重點在插入和刪除上,對于插入數據,以前我們使用堆的時候插入數據首先是插入在數組的最后,也就是尾插,然后通過向上調整來維持堆結構。我們可以寫一下push和adjustup的實現
//push 就是尾插void push(const T& val){pq.push_back(val);//然后向上調整adjust(size()-1); //傳新插入的數據的的下標}void adjust(size_t child){size_t parent = (child - 1) / 2; //父節點的下標while (child) //child 為 0 時退出循環{if (pq[child] >pq[parent]) //假設是建大堆、{swap(pq[child],pq[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}然后實現 pop ,pop 就是刪除 棧頂元素,但是刪除棧頂元素之后我們還需要通過向下調整來保證棧結構。
void pop(){swap(pq.front(),pq.back());pq.pop_back();adjustdown(0); //開始調整下標 }//向下調整void adjustdown(size_t parent){size_t maxchild = parent*2+1;while (maxchild<size()){if (maxchild + 1 < pq.size() && pq[maxchild + 1] > pq[maxchild]) //假設是大堆maxchild++;if (pq[parent] < pq[maxchild]){swap(pq[parent],pq[maxchild]);parent = maxchild;maxchild = parent*2 + 1;}elsebreak;}}
這樣一來就寫好了彈出棧頂元素和向下調整的方法了。
最后再實現一個迭代器區間的構造函數,
這個函數還是要用到仿函數,但是我們在這里其實也可以不使用仿函數,因為我們可以直接復用adjustdown來進行向下調整建大堆,一會講完了仿函數之后我們也只需要修改向下調整和向上調整的邏輯就行了,而不用修改這里的構造函數。
向下調整建大堆我們只需要找到第一個非葉子節點,然后往前遍歷,讓每一棵子樹都是大堆就行了。至于為什么不用向上調整建大堆 可以 看一下我的數據結構專欄的堆的實現,是由于向下調整建堆的效率比向上調整建堆的效率是要高得多的,效率差距主要體現在葉子節點的向上調整中。
//默認構造priority_queue(){}//迭代器區間構造template<class InputIterator>priority_queue(InputIterator first, InputIterator last):pq(first,last){size_t end = (size() - 1 - 1) / 2;while (end!=0){adjustdown(end);end--;}adjustdown(end);}
這里要注意的一點就是,如果我們寫了迭代器區間的構造,那么編譯器就不會自動生成默認構造函數了,我們需要自己實現一個默認構造,而這里的priority_queue的默認構造我們也什么都不用寫,編譯器會再初始化列表自動調用vector的默認構造來進行初始化,析構函數也是一樣的,編譯器自動生成的就能夠完成析構了。
仿函數
實現完一個大堆,我們就要開始該清楚仿函數是什么東西,只有搞清楚了仿函數我們才能夠實現一個完成的優先級隊列。
仿函數其實就是一個類,這個類實例化出來的對象就叫仿函數,類里面重載了( ) 這個函數調用操作符。叫做仿函數的原因是這個類的對象可以像函數調用一樣實現按我們的邏輯。
比如:
template<typename T>
class myless
{
public:bool operator()(const T& x, const T& y)const {return x < y;}
};
這樣一個類能夠干什么呢?
我們使用 sort 的時候是不是有這樣的用法??
sort ( container :: iterator first? , container :: iterator last , less<T> ( ) )
這里面的 less<T>() 就是一個仿函數,為什么這么說呢?參考我們上面實現的仿函數類, <T>表示數據類型是T,編譯器在實例化出這個匿名對象的時候就會使用具體的 T 去實例化,然后用這個匿名對象的 ( ) 也就是 operator() 來傳參,也就是將這個成員函數傳給了 sort 。
vector<int> v;v.push_back(5);v.push_back(7);v.push_back(4);v.push_back(3);v.push_back(9);v.push_back(2);vector<int>v1 = v;sort(v.begin(),v.end(),myless<int>());for (auto e : v){cout << e << " ";}cout << endl;sort(v1.begin(), v1.end(), less<int>());for (auto e : v){cout << e << " ";}cout << endl;我們可以看一下我們自己實現的的 myless 和庫里面的 less 是不是一樣的

其實仿函數的傳參就有點類似于我們以前C語言傳遞函數指針,但是函數指針寫起來很復雜,尤其是對于一些復雜的函數指針,同時函數指針也不支持泛型編程,每一個類型的比較都需要寫一個函數來實現,但是仿函數他就是一個類實例化出來的對象,我們傳參穿的也是這個對象,我們只需要顯式傳遞數據類型,就能夠實例化出我們想要的數據類型的比較函數。
上面的傳參我們也可以使用一個有名對象來傳參
myless<int> mless;sort(v.begin(),v.end(),mless);我們以前的泛型都是類型的泛型,而這里的仿函數的泛型則是邏輯的泛型。
那么我們就可以用仿函數來完善我們的優先級隊列了。
template<typename T ,typename container_type=vector<T>,typename CMP=less<T>>void adjustup(size_t child){CMP cmp;size_t parent = (child - 1) / 2; //父節點的下標while (child) //child 為 0 時退出循環{//if (pq[child] >pq[parent]) //假設是建大堆if(cmp(pq[parent],pq[child])){swap(pq[child],pq[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}} //向下調整void adjustdown(size_t parent){CMP cmp;size_t maxchild = parent*2+1;while (maxchild<size()){//if (maxchild + 1 < pq.size() && pq[maxchild + 1] > pq[maxchild]) //假設是大堆if (maxchild + 1 < pq.size() && cmp(pq[maxchild],pq[maxchild+1])) //假設是大堆maxchild++;//if (pq[parent] < pq[maxchild])if (cmp(pq[parent] , pq[maxchild])){swap(pq[parent],pq[maxchild]);parent = maxchild;maxchild = parent*2 + 1;}elsebreak;}}這還只是仿函數的基礎用法,仿函數還有一些高級用法,比如我們要實現兩個對象的大小的比較
class A
{
public:A(int n = 0):_n(n){}bool operator<(const A& a)const{return _n < a._n;}
private:int _n;
};
我們首先要在該類中重載 < 運算符,然后創建兩個對象進行比較
int main()
{A a1(10);A a2(20);int ret = myless<A>()(a1,a2);cout << ret << endl;return 0;
}
目前來看沒什么問題,但是當我們的對象是使用 new 申請的呢?這時候我們一般使用的就是對象的指針了,如果我們想要直接傳這兩個指針進行兩個指針所指向的對象比較,目前我們實現的仿函數類是做不到的,
A* p1 = new A(20);A* p2 = new A(10);int ret = myless<A*>()(p1,p2);cout << ret << endl;?我們只能這么用,而且這樣比較出來的結果還不一定是對的,因為這樣比較的話,比較的是兩個指針的大小,而不是對象的大小了,但是我們就是想要比較類對象的大小要怎么做呢??
很簡單,我們只需要在仿函數類中再重載一個( )函數就行了.
bool operator<(const A& a)const{return _n < a._n;}這樣一來,如果我們傳的是A類型的指針,我們也可以直接使用 myless<A>的仿函數進行比較
A* p1 = new A(20);A* p2 = new A(10);int ret = myless<A>()(p1,p2);cout << ret << endl;我們這里舉例的例子其實用的不是很合適,更恰當的例子是類似于一個排序算法的場景,既要支持對象本身的比較,還要支持參數是對象指針時對指針所指向的對象的比較。
5 反向迭代器
為什么我們前面沒實現反向迭代器,因為反向迭代器其實就是一種適配器,為什么這么說呢?我們知道,反向迭代器和正向迭代器唯一的區別就是 ++ 和 -- 的方向,正向迭代器 ++? 是從前往后走 ,而反向迭代器的 ++ 是從后往前走,所以要實現反向迭代器我們只需要封裝和復用正向迭代器的代碼,就能夠很輕松的實現。
拿 list 的反向迭代器來舉例,反向迭代器的 rbegin() 和 rend() 的位置是哪呢?
我們可以向正向迭代器一樣,讓?rbegin 指向最后一個節點,也就是在迭代器中維護 phead->prev ,然后rend 指向第一個節點的前一個節點,也就是 phead ,這樣是一個標準的反向迭代器,但是這樣卻沒有最大程度的復用正向迭代器。 讓 rbegin 直接復用 正向迭代器的 end ,讓rend 直接復用 begin ,但是這樣設計有一個要注意的地方就是,解引用的時候 ,要返回的不是當前指針指向的節點的數據,而是當前節點的建一個節點的數據,因為我們相當于 將區間整體往右移了一個節點。 還有就是要實現 反向迭代器的 ++ ,我們就需要正向迭代器中重載了 - - ,要實現 - - ,則需要復用正向迭代器的 ++ 。?
那么反向迭代器的實現就很簡單了,下面是一個針對 list 的反向迭代器的簡單的實現,可能會有一些問題,但是大體的框架就是這樣了。
template<typename T, typename ref, typename ptr>class reverse_list_iterator {public:typedef _list_iterator<T> _list_iterator;//迭代器的構造reverse_list_iterator(_list_iterator it):_it(it){}reverse_list_iterator& operator++(){return --_it;}reverse_list_iterator& operator++(int) //后置++{return _it--;}bool operator!=(reverse_list_iterator& it1)const{return _it!=it1._it;}ref operator*(){list_iterator tmp=_it;--tmp;return *tmp;}const T& operator*()const{list_iterator tmp = _it;--tmp;return *tmp;}ptr operator->(){return _it.operator->();}listnode* pnode;private:_list_iterator _it;};但是,其實反向迭代器不是針對某一個容器來設計的,他的重點在于復用,能夠用不同類型的正向迭代器,來轉換出相應的反向迭代器。
template<typename Iterator>但是這里面需要用到一些牛逼的技術來實現 從 正向迭代器中提取出 ref 和 ptr 用于 * 和 -> 的返回類型。
)


](http://pic.xiahunao.cn/大數據面試題之Presto[Trino](3))
)
)


)





:線性回歸模型第二部分:單變量線性回歸模型)




