序言
隨著業務發展,我們維護的項目數據庫中的數據可能會越來越大,那么單張表的數據變多后,接口查詢效率可能會變慢,那我們就直接照抄大廠常見的分庫分表嗎?—— 當然不是的,分庫分表不是萬能的。
分庫分表會大大提高系統的復雜度,并且里面可能會踩不少坑:
- 分布式事務:比如進行了數據庫表垂直拆分,那可能會涉及到分布式事務,可能就需要考慮2PC、3PC、Seata TCC、本地事務表等方案;
- 分布式ID:單表可能搞個自增主鍵就完事了,但是如果進行了分庫分表,比如對數據庫表進行了水平拆分,那你后續數據量變更多的時候,你需要再進行擴容,簡單的自增主鍵可能會導致多張數據庫表的主鍵重復且不唯一,那就得用到分布式Id,比如雪花算法(還需要考慮時間回撥、機器號管理問題)或美團的Leaf,相當于你可能需要專門搞個“發號器”服務;
- 分片查詢:假設還是對數據庫表進行了水平拆分,原來執行一句
select * from table where age > 25的SQL,現在需要跑遍所有分片,然后需要考慮把所有結果放在內存拼起來會不會讓內存爆炸; - 數據備份/擴容:水平分庫或者垂直分庫后,數據庫多了,運維時備份策略復雜到要畫思維導圖,擴容就像給高速行駛的汽車換輪胎——稍有不慎全村吃席;
真實案例:電商搞大促,本來分庫分表是為了抗住流量,結果庫存扣減因為跨庫事務超時,30%訂單直接失敗。CTO 當場血壓飆升:“這特么還不如不分!”
解決方案
-
- 索引優化:給數據庫穿雙跑鞋
別上來就搞分庫分表,先看看你的索引是不是像老太太的裹腳布——又臭又長?
殺手锏:用EXPLAIN命令看SQL執行計劃,把那些全表掃描(ALL)、臨時表(Using temporary)的查詢揪出來打;
口訣:聯合索引遵循“最左匹配”,別建一堆單列索引占著茅坑不拉屎;
- 索引優化:給數據庫穿雙跑鞋
-
- 冷熱分離:給數據分個「退休區」
3 年前的訂單還天天查?不如把陳年老數據歸檔到history_orders表;
野路子:直接CREATE TABLE archive_table AS SELECT * FROM orders Where create_time < '2025-01-01'(記得加索引)
好處:主表瘦身成功,查詢速度飛起;
- 冷熱分離:給數據分個「退休區」
-
- 分區表:把大桌子切成抽屜
不用改代碼!MySQL 自帶分區功能,按月分、按 ID 分隨你便;
- 分區表:把大桌子切成抽屜
-
- 讀寫分離:讓小弟們干活
主庫專心寫數據,搞 10 個從庫輪著查,用ShardingSphere這類工具自動分流;
注意:從庫可能有延遲,重要操作(比如支付成功頁)還是得查主庫
- 讀寫分離:讓小弟們干活
-
- 垂直拆分:把胖子表扒層皮
把大字段(比如商品詳情、用戶頭像)單獨存個表,主表只留核心字段
栗子:用戶表拆成 (存 ID、姓名)和 (存地址、簡介),減 少單行數據體積
- 垂直拆分:把胖子表扒層皮
-
- 氪金大法:加錢上 SSD!
別笑!很多公司用機械硬盤跑數據庫,換 SSD 直接性能翻 10 倍
調參秘籍:
innodb_buffer_pool_size調到機器內存的 70%(別讓數據庫餓著)
innodb_flush_log_at_trx_commit=2適當犧牲點安全性換速度
- 氪金大法:加錢上 SSD!
-
- 找外援:NoSQL 來幫忙
搜索交給 ES:商品模糊查詢別折騰數據庫,Elasticsearch 專治各種不服;
緩存懟臉上:用 Redis 存庫存、熱門商品,讀請求直接不碰數據庫
日志存 Mongo:用戶操作日志這種大 JSON,往 MongoDB一扔,省心省力;
- 找外援:NoSQL 來幫忙
什么情況必須分庫分表?
- 數據量打不住:單表超過 5000 萬行,眼瞅著要破億(比如微信的消息表);
- 錢砸不動了:SSD 買頂配、內存加到 512G 還是卡成狗;
- 業務逼到墻角:每秒上萬筆交易,不拆分明天就宕機;
分庫分表兩大流派:
- 垂直拆分:用戶表、訂單表、商品表各占一個庫,適合業務復雜的中臺系統;
- 水平拆分:
- 按用戶 ID 取模:簡單粗暴,但擴容得重新分片;
- 一致性哈希:擴容時只要遷移部分數據,互聯網公司最愛;
- 按時間分片:適合日志類數據,直接按月分庫;
分區表
上面的幾種解決方案大多人多多少少都見過了,然后我們來看看分區表,下面就實戰的看看分區表怎么玩?
由于MySQL天然支持分區操作,我們直接看看官網:mysql_doc_alter-table-partition-operations
先看我們展示的非分區表,表結構如下,
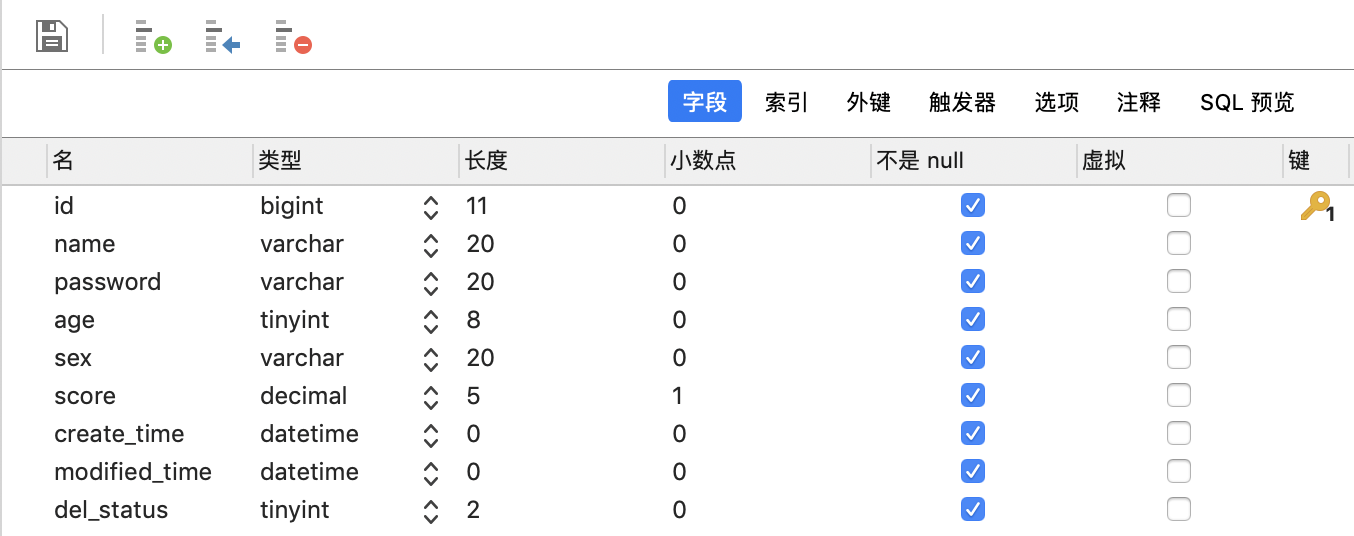
數據如下圖所示,id為主鍵,
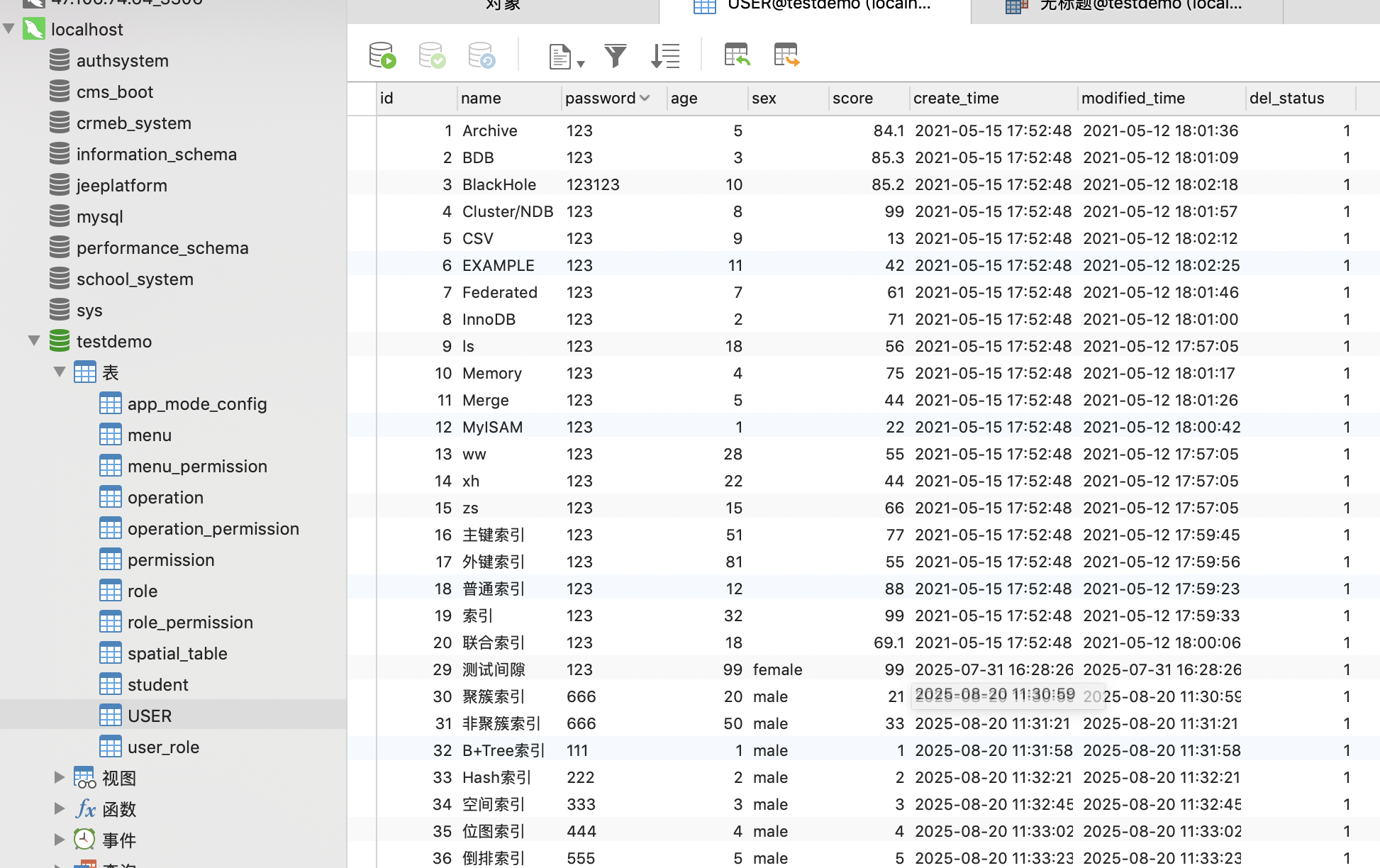
這里只是拿之前測試用的表做展示,表結構可以更加簡化,這張表我們可以通過Hash主鍵id作為分區鍵,假設我們劃分8個分區,執行下面的SQL指令,
ALTER TABLE `USER`PARTITION BY HASH(id)PARTITIONS 8;
執行結果如下圖,可以看到Partitioning Hash算法執行完后數據分布相對均勻,其實是因為在MySQL 8.4版本支持的線性Hash算法
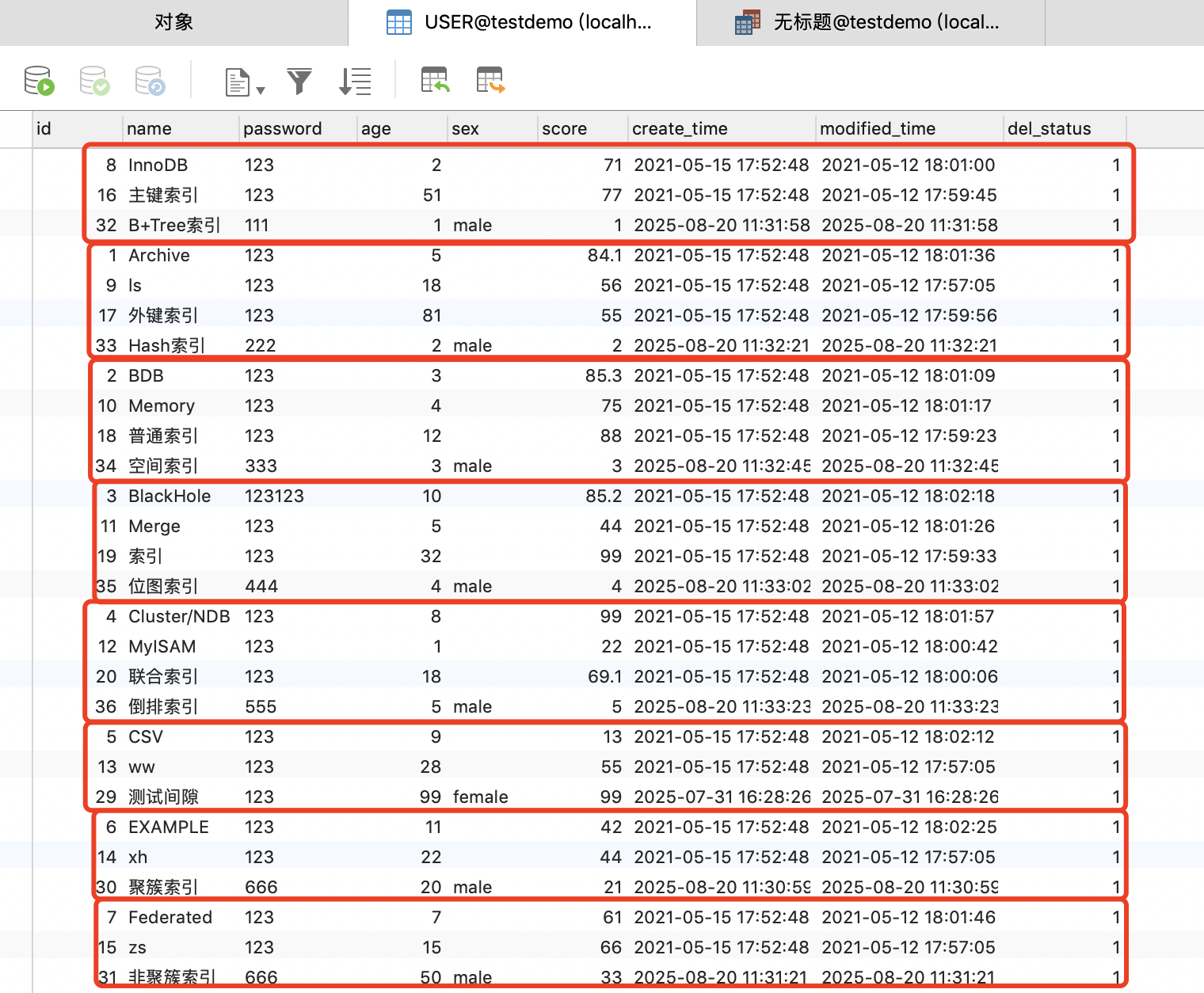
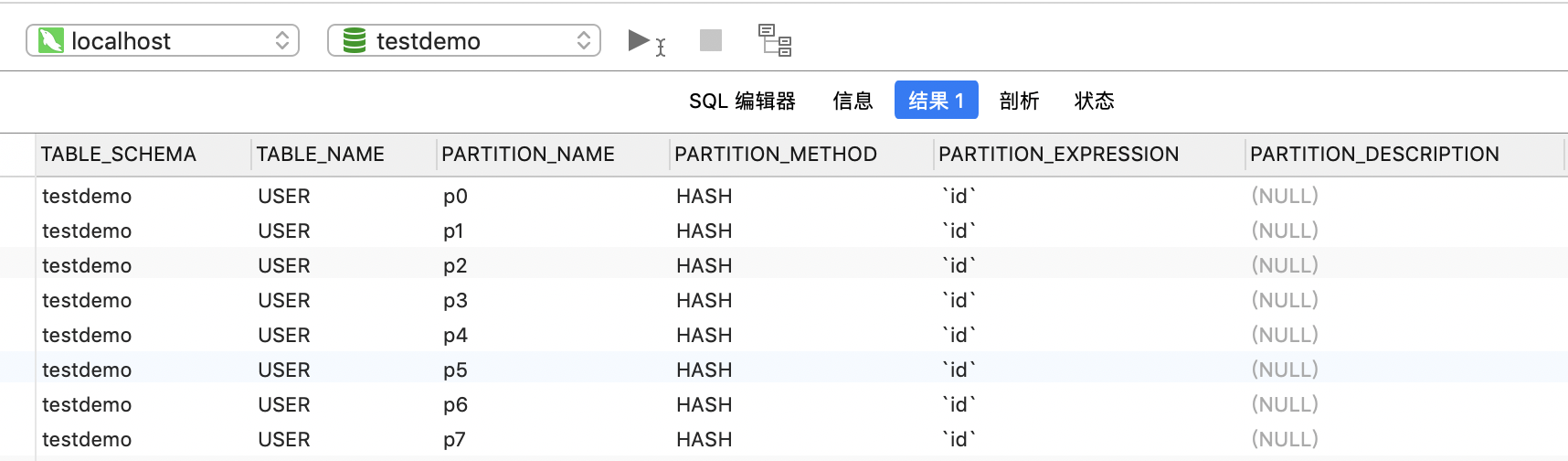
執行下面SQL命令,我們可以查看當前數據庫表的分區情況
SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_METHOD, PARTITION_EXPRESSION, PARTITION_DESCRIPTION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = 'testdemo' AND TABLE_NAME = 'USER';
結果如下圖所示,數據庫、表名、分區名、分區方法等一目了然,
理論上,執行ALTER TABLE USER DROP PARTITION p0,p1,p2,p3,p4,p5,p6,p7;是可以刪除分區的,但是由于DROP PARTITION語句只能用于刪除范圍(RANGE)分區或列表(LIST)分區中的分區。這兩種分區類型允許你基于連續的值范圍或特定的值列表來組織數據。哈希(HASH)分區和鍵(KEY)分區是基于算法而非明確的值范圍或列表進行分區的,因此不支持使用 DROP PARTITION 語句。

針對Hash分區和Key分區,我們可以執行下面命令還原成1個分區,但本質上和初始情況還是有一點差別,初始情況是沒有分區的,而當前進行了一次分區,
ALTER TABLE `USER`PARTITION BY HASH(id)PARTITIONS 1;
ALTER TABLE … PARTITION BY使用規格必須和CREATE TABLE … PARTITION BY的一樣,分區表的分區表達式中使用的所有列都必須是該表可能具有的每個唯一鍵的一部分
ALTER TABLE … PARTITION BY statement must follow the same rules as one created using CREATE TABLE … PARTITION BY
In other words, every unique key on the table must use every column in the table’s partitioning expression. (This also includes the table’s primary key, since it is by definition a unique key. This particular case is discussed later in this section.)
舉個例子,執行下面的分區SQL就是無效的,
ALTER TABLE `USER`PARTITION BY HASH(age)PARTITIONS 5;

執行CREATE TABLE ... PARTITION BY對表t1和t2進行分區時,下面這種也是無效的,
CREATE TABLE t1 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col2)
)
PARTITION BY HASH(col3)
PARTITIONS 4;CREATE TABLE t2 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1),UNIQUE KEY (col3)
)
PARTITION BY HASH(col1 + col3)
PARTITIONS 4;
如果要進行分區,建議表中至少有一個唯一鍵,該鍵不包括分區表達式中使用的所有列,比如下面SQL就是有效的,
CREATE TABLE t1 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col2, col3)
)
PARTITION BY HASH(col3)
PARTITIONS 4;CREATE TABLE t2 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col3)
)
PARTITION BY HASH(col1 + col3)
PARTITIONS 4;
PARTITION BY的規則就不一一細說了,官網上有明確的解釋,接下來我們看看官網PARTITION BY RANGE的規則和用法,如果沒有唯一鍵(包括沒有主鍵),上述規則就不適用了,可以使用任意列進行分區,如下示例,
CREATE TABLE t_no_pk (c1 INT, c2 INT)
PARTITION BY RANGE(c1) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20),
PARTITION p2 VALUES LESS THAN (30),
PARTITION p3 VALUES LESS THAN (40)
);
沒有主鍵的t_no_pk表基本上很少見,這里可以忽略這種規則,如果有需要再來研究,

正常場景,分區使用主鍵,比如下面建了一個訂單表,訂單id和訂單的創建時間作為聯合主鍵,然后再根據創建時間進行按月分區,
CREATE TABLE orders (id BIGINT NOT NULL,user_id BIGINT NOT NULL,order_status VARCHAR(20) NOT NULL,create_time DATETIME NOT NULL,PRIMARY KEY (id, create_time)
)
PARTITION BY RANGE(YEAR(create_time)*100 + MONTH(create_time)) (
PARTITION p202501 VALUES LESS THAN (202501),
PARTITION p202502 VALUES LESS THAN (202502),
PARTITION p202503 VALUES LESS THAN (202503),
PARTITION p202504 VALUES LESS THAN (202504)
)
;
創建完后,可以執行下面SQL命令查看分區信息,
SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_METHOD, PARTITION_EXPRESSION, PARTITION_DESCRIPTION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = 'testdemo' AND TABLE_NAME = 'orders';

Mock數據,可以發現當我們插入了不在分區范圍內的數據時會報錯,
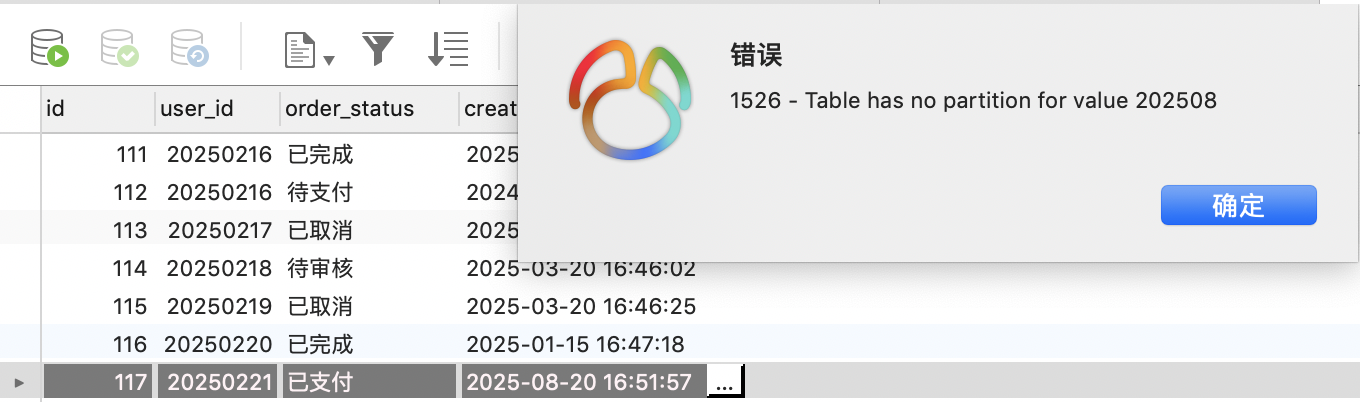
所以需要知行合一,你給數據庫分區了之后超過你分區范圍的數據都插不了數據庫那不是線上大問題?
可以在時間分區后面加一個兜底PARTITION p299912 VALUES LESS THAN (300001),避免出現這種情況,至少你百年去世后這個數據插入也不會有問題。
那么分區之后有什么好處呢?
- 提升查詢效率;
- 簡化表維護;
假設數據如下,
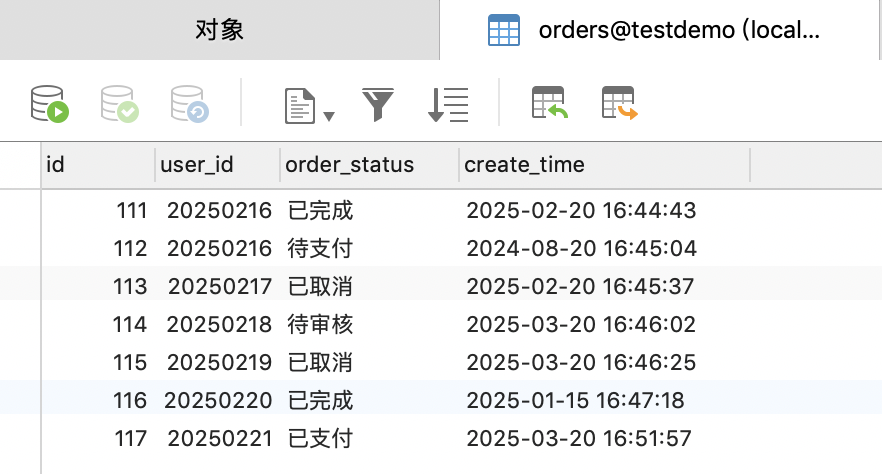
1、查詢特定分區數據;
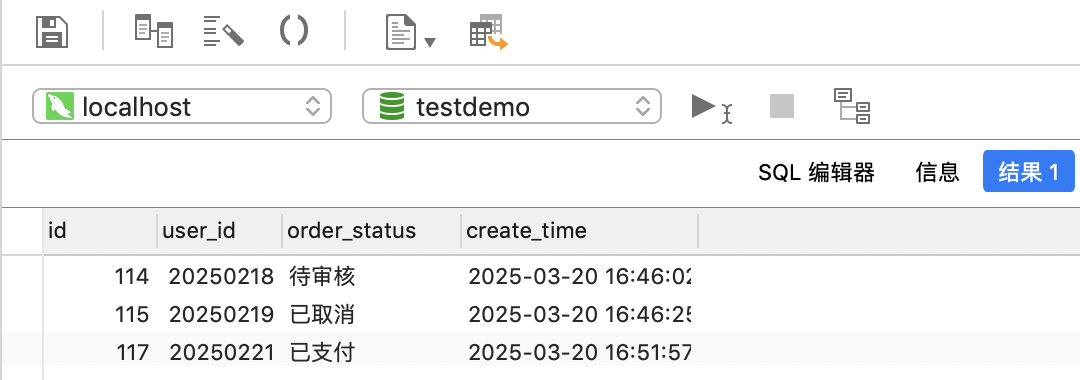
SELECT * FROM orders PARTITION (p202504);
如下圖,我們查到的是大于2025年2月且小于2025年4月,即2025年3月份的數據,
2、使用了分區裁剪(Partition Pruning),當你在WHERE子句中指定了分區鍵的條件時,MySQL會自動利用分區裁剪來優化查詢。例如,
SELECT * FROM orders WHERE create_time = '2025-02-20 16:45:37';
使用EXPLAIN該SQL語句可以看到select_type = SIMPLE(即不需要使用union或子查詢的簡單select查詢),type = ALL即進行了全表掃描,但是走了partitions = p202503的分區,該分區的行數為2條記錄(rows = 2)

3、刪除舊數據比DELETE快10倍;
ALTER TABLE orders TRUNCATE PARTITION p202502;







)



 day58)



與機器翻譯的結合應用)




)