摘要:
隨著城市化進程的加快,垃圾問題日益嚴重。傳統的垃圾分類方法存在效率低下、準確率不高等問題。本文提出了一種基于卷積神經網絡(CNN)的垃圾分類模型,該模型能夠自動識別并分類不同類型的垃圾。實驗表明,該模型在垃圾分類任務中取得了較高的準確率,為垃圾處理提供了有效的技術支持。
關鍵詞:卷積神經網絡;垃圾分類;深度學習;圖像識別
一、引言
(一)背景
隨著人們生活水平的提高,城市垃圾產生量不斷增加,垃圾分類已成為城市管理的重要任務。然而,傳統的垃圾分類方法主要依賴于人工操作,存在勞動強度大、分類效率低、易受主觀因素影響等問題。近年來,深度學習技術的快速發展為垃圾分類提供了新的解決方案。其中,卷積神經網絡(CNN)因其強大的圖像處理能力在圖像識別領域取得了顯著成果[1]。因此,本文提出了一種基于CNN的垃圾分類模型,旨在提高垃圾分類的效率和準確率。
(二)框架選取
本文將采用由百度飛槳研發的PaddlePaddle深度學習框架(下文簡稱Paddle框架)。該框架支持傳統深度學習框架的基本功能,如模型組網、顯卡訓練等。此外,該框架提供了高級API,可以更加方便快捷地完成訓練腳本的編寫。
二、數據集選取
本文選取了飛槳AI Studio的“垃圾分類40種”數據集,如圖2.1、圖2.2所示。該數據集的截取對象更偏向于“垃圾”而非“生活物品”,更符合垃圾分類模型的應用場景:


并且,該數據集基本覆蓋了常見的生活垃圾,其40個類別如表2.1所示。
表2.1 該數據集的分類
| 類別 |
|---|
| 其他垃圾/一次性快餐盒 |
| 其他垃圾/污損塑料 |
| 廚余垃圾/茶葉渣 |
| 廚余垃圾/菜葉菜根 |
| 廚余垃圾/蛋殼 |
| 廚余垃圾/魚骨 |
| 可回收物/充電寶 |
| 可回收物/包 |
| 可回收物/化妝品瓶 |
| 可回收物/塑料玩具 |
| 可回收物/塑料碗盆 |
| 可回收物/塑料衣架 |
| 其他垃圾/煙蒂 |
| 可回收物/快遞紙袋 |
| 可回收物/插頭電線 |
| 可回收物/舊衣服 |
| 可回收物/易拉罐 |
| 可回收物/枕頭 |
| 可回收物/毛絨玩具 |
| 可回收物/洗發水瓶 |
| 可回收物/玻璃杯 |
| 可回收物/皮鞋 |
| 可回收物/砧板 |
| 其他垃圾/牙簽 |
| 可回收物/紙板箱 |
| 可回收物/調料瓶 |
| 可回收物/酒瓶 |
| 可回收物/金屬食品罐 |
| 可回收物/鍋 |
| 可回收物/食用油桶 |
| 可回收物/飲料瓶 |
| 有害垃圾/干電池 |
| 有害垃圾/軟膏 |
| 有害垃圾/過期藥物 |
| 其他垃圾/破碎花盆及碟碗 |
| 其他垃圾/竹筷 |
| 廚余垃圾/剩飯剩菜 |
| 廚余垃圾/大骨頭 |
| 廚余垃圾/水果果皮 |
| 廚余垃圾/水果果肉 |
?其數據總量較多,每個類別分配較平均,其每個類別的數量如表2.2所示。
表2.2 該數據集的分類數量情況
三、數據集處理
本文采用Paddle框架搭建數據集。在數據集初始化時,程序會順序執行以下操作:
- 獲取數據集文件夾下的所有子文件夾
- 對每個子文件夾,遍歷每個圖片,順序進行如下操作:
- 使用PIL打開圖片
- 重設圖片大小為256x256
- 將通道維度置于最前,以適應Paddle框架。即將圖片維度從(256, 256, 3)轉為(3, 256, 256)
- 將圖片和標簽存入對應列表
當外界需要獲取指定索引的數據時,程序會按照對應索引,從列表中讀取并返回數據。
數據集腳本的具體代碼如下:
import paddle
import numpy as np
from PIL import Image
import osdef getAllPath(path):return [os.path.join(path, f) for f in os.listdir(path)]class Dataset(paddle.io.Dataset):def __init__(self, mode='train'):super().__init__()self.data = []self.label = []for type_dir in getAllPath(f'./dataset/{mode}'):print('正在讀取:', os.path.basename(type_dir))for path in getAllPath(type_dir):img = Image.open(path)img = img.resize((256, 256))img = np.array(img, dtype=np.float32).transpose((2, 0, 1))self.data.append(img)self.label.append(int(os.path.basename(type_dir)))self.data = np.array(self.data, dtype=np.float32)def __getitem__(self, idx):return self.data[idx], self.label[idx]def __len__(self):return len(self.data)
四、模型訓練
(一)模型選取
本文采用ResNet(Residual Neural Network)作為分類模型。ResNet是深度學習中一種非常有效的卷積神經網絡(CNN)結構,通過引入殘差塊(Residual Block)解決了深度神經網絡訓練中的梯度消失和模型退化問題。ResNet的提出使得訓練深度達到幾百甚至上千層的神經網絡成為可能,提高了模型的準確性,并在多項計算機視覺任務中取得了顯著的性能提升。[2]
由于垃圾分類的任務相對簡單,不需要過于復雜的模型,因此本文采用ResNet-18(18層的ResNet模型)進行分類任務,達到較號的性能與準確的平衡。
(二)優化器選取
在訓練神經網絡時,優化器的選擇對模型的性能具有重要影響。優化器用于更新和計算影響模型訓練和模型參數的梯度,以最小化損失函數。本文采用Adam(Adaptive Moment Estimation)作為優化器。
Adam優化器將在梯度大時加速訓練,梯度小時減速訓練,而不是以固定的學習率訓練。這將會大大加速訓練過程,并且減少因訓練集梯度問題而產生的訓練問題,增加準確率。[3]
(三)損失函數選取
在機器學習和深度學習中,損失函數用于量化模型預測與真實標簽之間的差異。選擇一個合適的損失函數對于訓練一個高效且準確的模型至關重要。本文采用交叉熵損失函數(Cross-Entropy Loss Function)進行訓練。
在多分類問題中,通常有多個類別(假設為C個),模型的輸出是一個C維的向量,每個元素表示樣本屬于對應類別的概率,其表達式為:
其中,C表示樣本個數,y是標簽(0或1),p是模型的輸出。
交叉熵損失函數常用于分類問題,衡量預測概率分布與真實概率分布之間的差異。而垃圾分類是典型的分類問題,適用于交叉熵損失函數。
使用交叉熵損失函數的好處之一是它能夠有效地處理類別不平衡的問題,因為它關心的是預測概率與真實概率之間的差異,而不是僅僅關注是否預測正確。此外,交叉熵損失函數在梯度下降過程中表現良好,能夠提供穩定的梯度更新,有助于模型的快速收斂。[4]
(四)訓練腳本編寫
Paddle框架提供的高級API極大簡化了訓練腳本的編寫。因此,該腳本只需要設置優化器、損失函數和評價指標(準確率)并調用model.fit方法即可進行訓練。另外,該腳本還通過回調函數,實現損失和準確率的記錄,并寫到一個csv文件中。
該腳本的代碼如下:
import paddle
import csv
from paddle.metric import Accuracy
from paddle.callbacks import ProgBarLogger, Callback
from dataset import Datasettrain_dataset = Dataset()net = paddle.vision.models.resnet18(num_classes=40)
model = paddle.Model(net)# 自定義一個回調函數來記錄loss和acc
class CSVLogger(Callback):def __init__(self, csv_file):super().__init__()self.csv_file = csv_fileself.file = Noneself.csv_writer = Nonedef on_train_begin(self, logs=None):self.file = open(self.csv_file, 'w', newline='')fieldnames = ['epoch', 'loss', 'acc']self.csv_writer = csv.DictWriter(self.file, fieldnames=fieldnames)self.csv_writer.writeheader()def on_epoch_end(self, epoch, logs=None):row_dict = {'epoch': epoch + 1, 'loss': logs.get('loss')[0], 'acc': logs.get('acc')}self.csv_writer.writerow(row_dict)def on_train_end(self, logs=None):self.file.close()# 實例化CSVLogger
csv_logger = CSVLogger('training_history.csv')# 準備模型訓練
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),paddle.nn.CrossEntropyLoss(),Accuracy())# 使用fit方法并傳入自定義的CSVLogger
model.fit(train_dataset, epochs=50, batch_size=64, callbacks=[ProgBarLogger(verbose=1), csv_logger])# 模型保存
model.save('./output/model')
(五)訓練結果
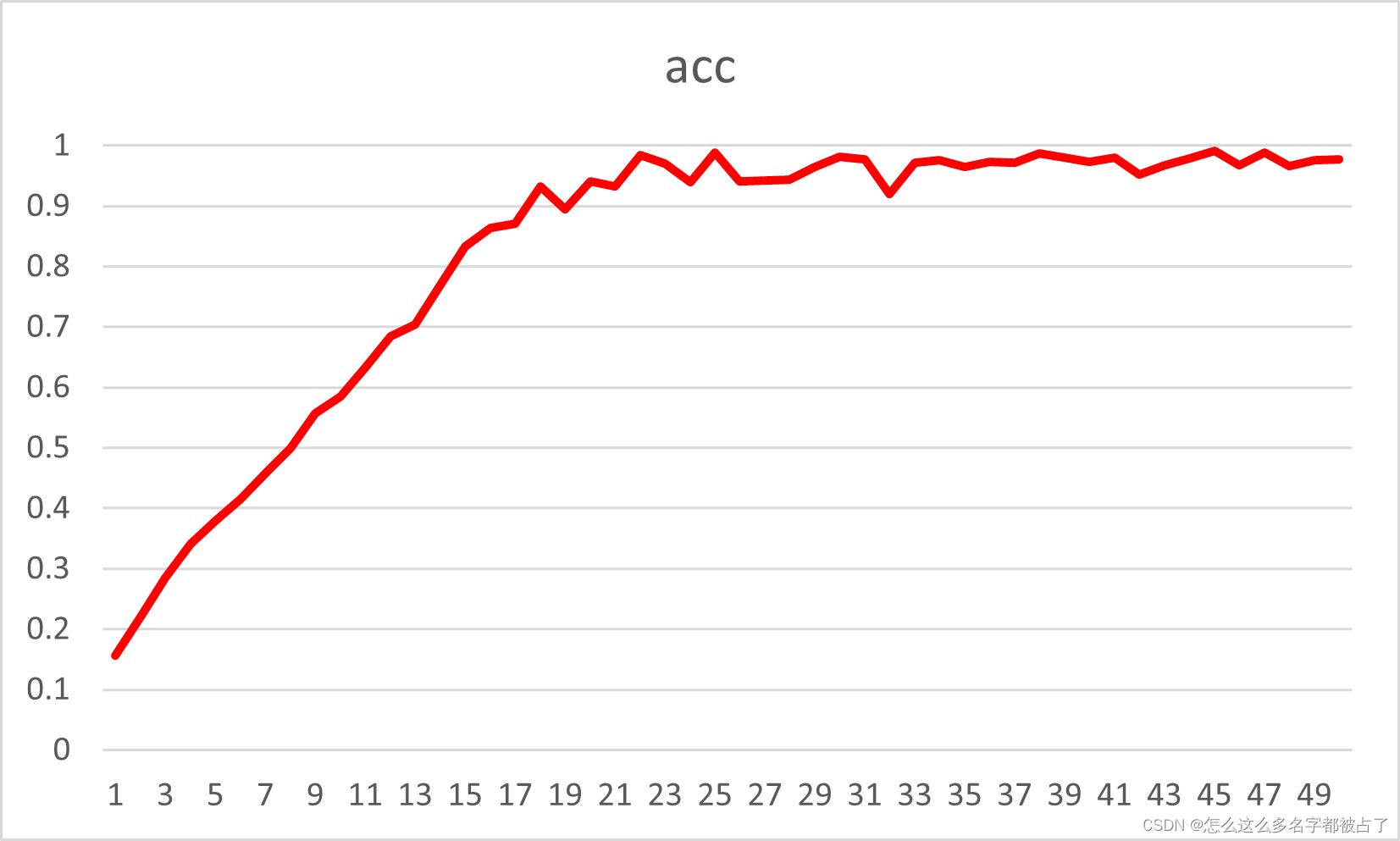
經過50個epoch的訓練后,模型的準確率穩定在97%左右,損失也逐漸趨于平穩,如圖4.1和圖4.2所示。

?(六)模型測試
該模型的測試結果也非常好,其損失達到了9.6559^-6,準確率達到99.25%。可以看到,這個模型的分類是比較準確的,擬合性較高。
五、模型使用
本文提供了簡單的模型使用程序,將會讀取指定文件,并輸出分類結果。其代碼如下所示。
import paddle
from PIL import Image
import numpy as np
import json# 初始化模型
net = paddle.vision.models.resnet18(num_classes=40)
model = paddle.Model(net)# 加載模型
model.load('output/model')# 加載鍵值對
with open('dataset/garbage_dict.json', 'r', encoding='utf-8') as f:mapping = json.load(f)# 加載圖片
path = 't3.jpeg'
img = Image.open(path)
img = img.resize((256, 256))
img = np.array(img, dtype=np.float32).transpose((2, 0, 1))[np.newaxis, :]# 預測
pred = model.predict_batch(img)[0]
label = int(pred.argmax())
print(mapping[str(label)])
本文使用模型給出了三個網絡圖片的分類,如圖5.1、圖5.2、圖5.3所示



可以看到,本模型準確地給出了這些圖片所對應的垃圾分類。?
六、結論與展望
本文提出了一種基于CNN的垃圾分類模型,并通過實驗驗證了其有效性。該模型能夠自動識別并分類不同類型的垃圾,為垃圾處理提供了有效的技術支持。實驗表明,該模型在垃圾分類任務中取得了較高的準確率,為垃圾處理提供了有效的技術支持。在應用方向上,可以將此模型應用于智能分類垃圾桶、垃圾分揀裝置等,實現準確高效的垃圾分類。
參考文獻
[1]黃琳軒.基于卷積神經網絡的垃圾自動分類算法[J].科技與創新,2024,(10):70-72.DOI:10.15913/j.cnki.kjycx.2024.10.016.
[2]孫毅,吳斯曼,方偉,等.基于ResNet的安全監控目標檢測[J/OL].集成技術:1-10[2024-06-06].http://kns.cnki.net/kcms/detail/44.1691.t.20240527.1512.004.html.
[3]張波,肖杰.深度學習模型訓練的優化器實驗設計[J].電子制作,2024,32(02):114-117.DOI:10.16589/j.cnki.cn11-3571/tn.2024.02.023.
[4]黃輝城,李建新.基于深度視覺的智能卸垛機快遞箱邊界檢測系統[J].光學技術,2024,50(02):220-227.DOI:10.13741/j.cnki.11-1879/o4.2024.02.018.




)





)






用與數據整合和批次處理)

