大模型技術論文不斷,每個月總會新增上千篇。本專欄精選論文重點解讀,主題還是圍繞著行業實踐和工程量產。若在某個環節出現卡點,可以回到大模型必備腔調或者LLM背后的基礎模型新閱讀。而最新科技(Mamba,xLSTM,KAN)則提供了大模型領域最新技術跟蹤。若對于具身智能感興趣的請移步具身智能專欄。技術宅麻煩死磕AI架構設計。當然最重要的是訂閱“魯班模錘”。

Embedding模型概覽
Embeddings是自然語言處理技術中很重要的基石。它有很多種模型,從GloVe、word2vec、FastText、Bert、RoBERTa、XLNet、OpenAI ada、Google VertexAI Text Embeddings、Amazon SageMaker Text Embeddings和Cohere。每種模型都有優劣,如何去分析這些Embeddings技術,重點可以關注如下的參數信息:能否在編碼中捕獲上下文信息、能夠處理非詞表之外的單詞、泛化的能力、預訓練的效率、是否免費、最終效果質量。
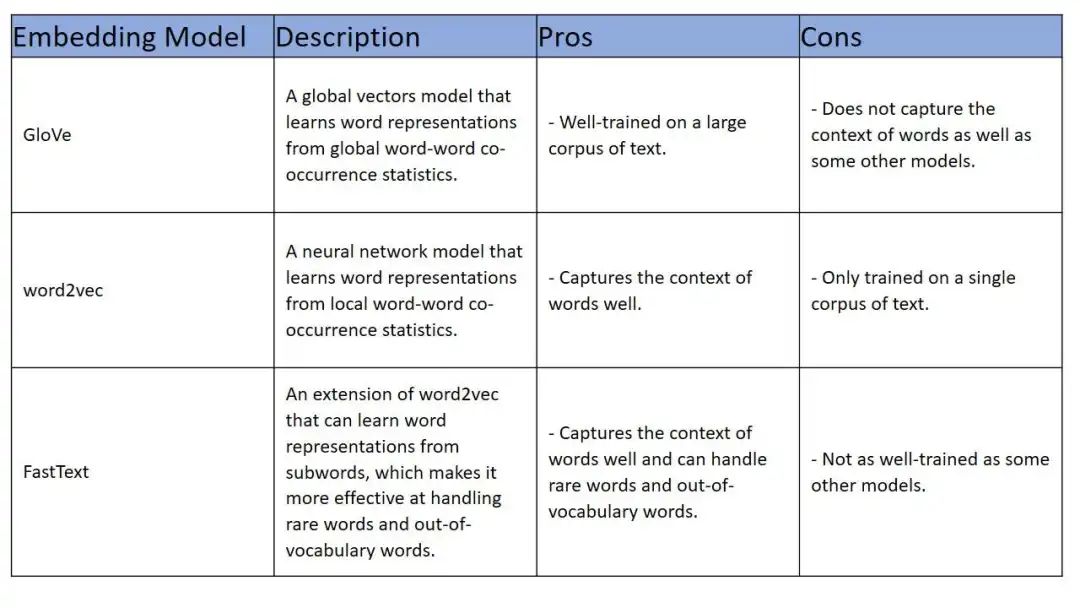
一般而言在大型文本語料庫上經過良好訓練并且能夠很好地捕獲單詞上下文的模型,那么GloVe、word2vec 或 FastText都是不錯的選擇。
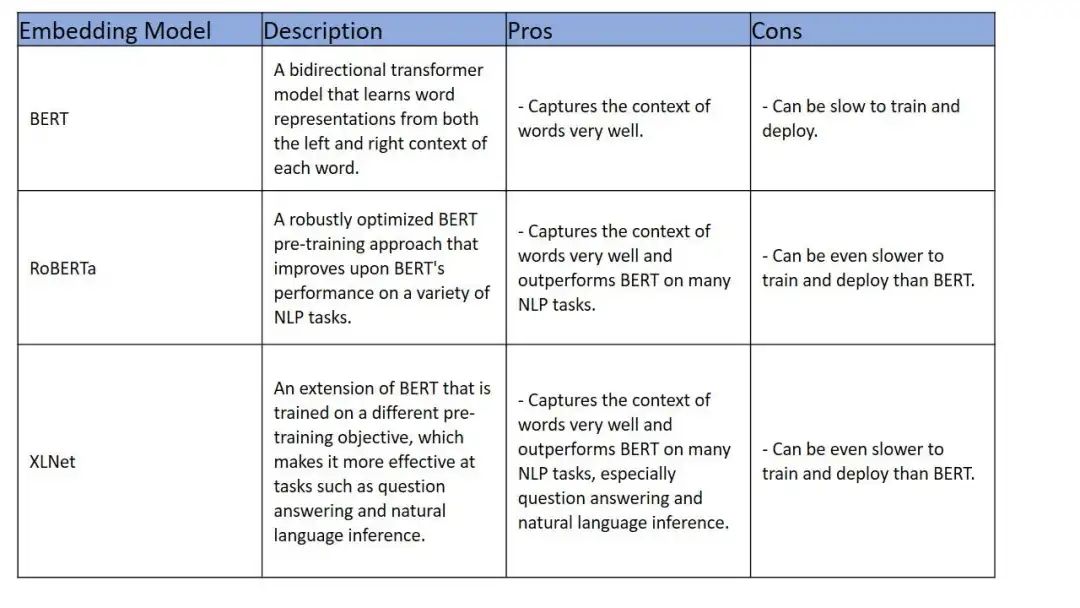
若某個業務場景急需更好的捕獲單詞上下文,而且變現需要優于Bert,那么RoBERTa或XLNet是不錯的選擇。
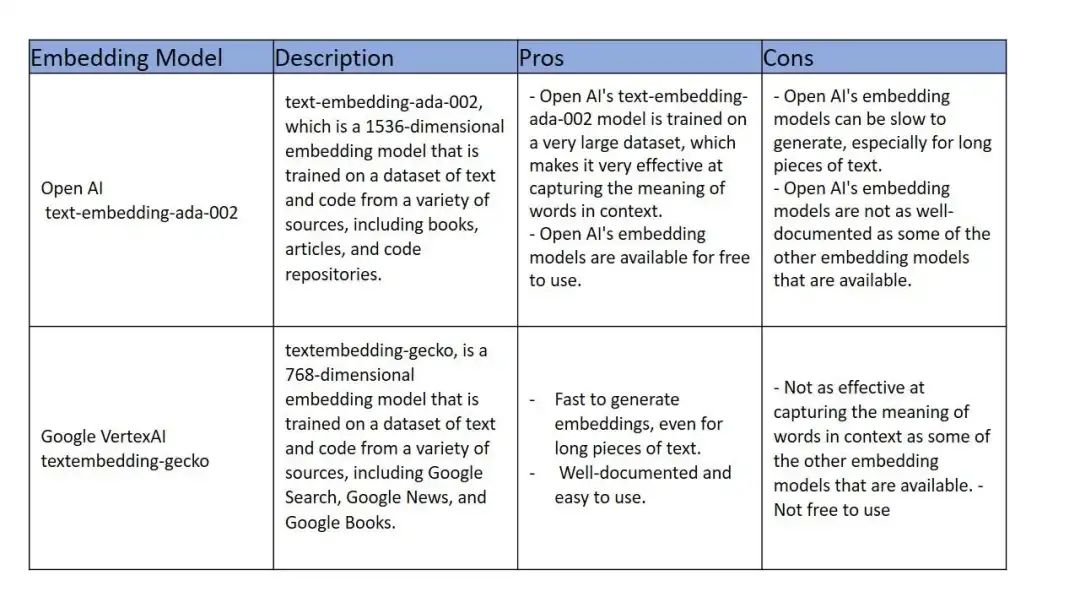
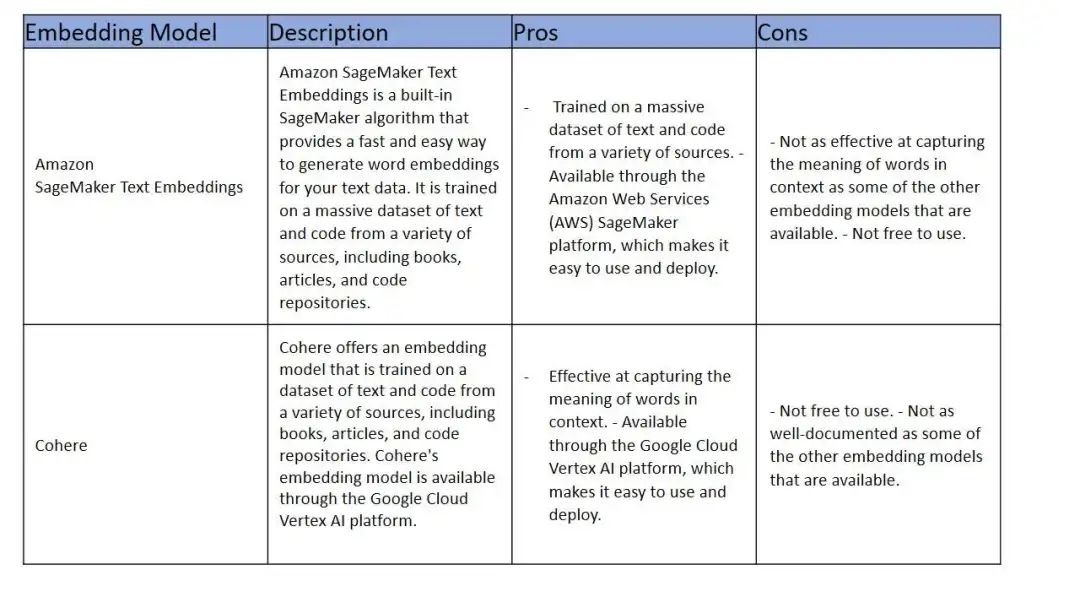
其他大公司的Embeddings模型,有免費也有收費的。OpenAI、Google、Amazon都可以按需選擇。
Embedding模型和訓練數據有關,用于訓練模型的訓練數據的大小和質量更大更高,則會產生更好的模型。還有一些選擇的限制,例如XLNet是問答和自然語言推理的最佳選擇,而RoBERTa是文本摘要和機器翻譯的最佳選擇。

Word2Vec
Word2Vec有兩種,CBOW和Skip-Gram,很多資料都沒有劃對重點。那么接下跟隨小魯來正確打開。
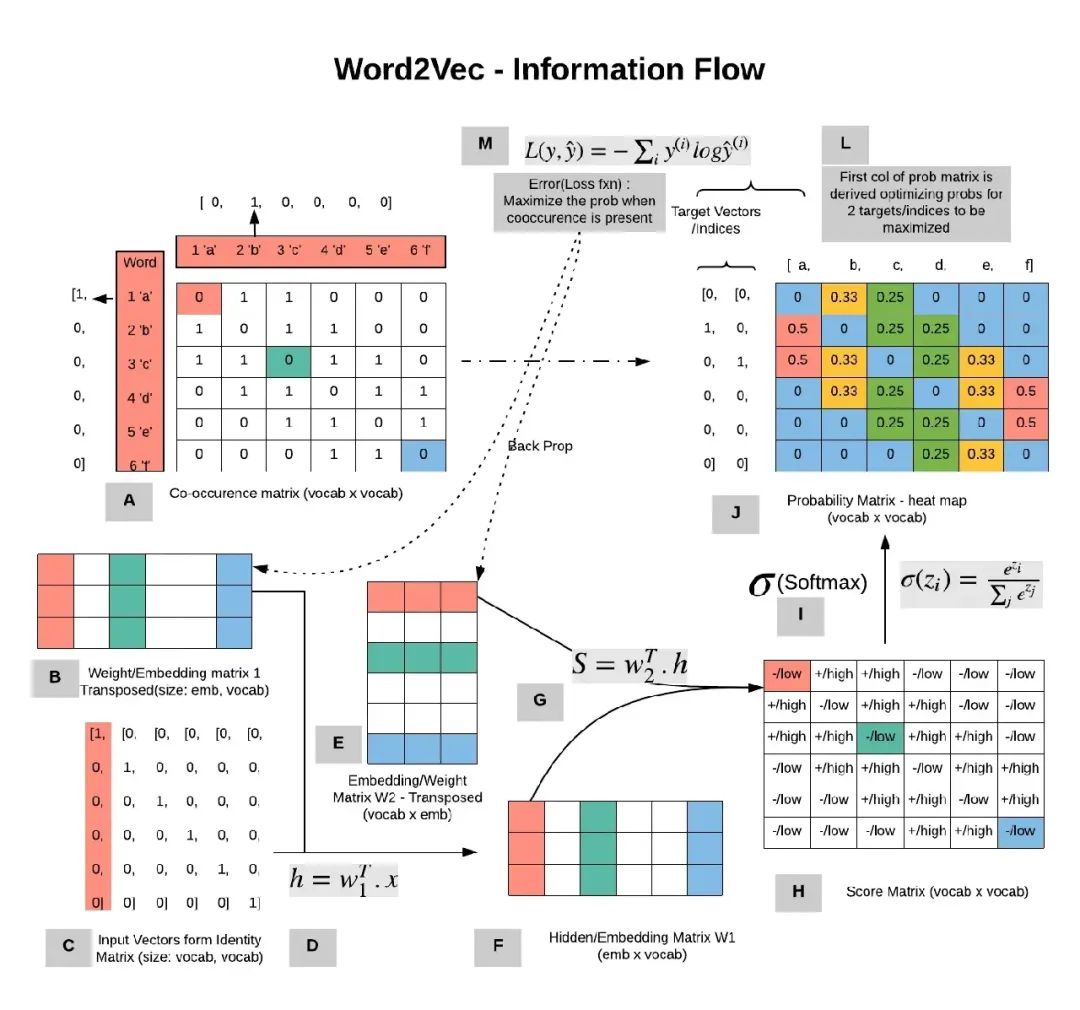
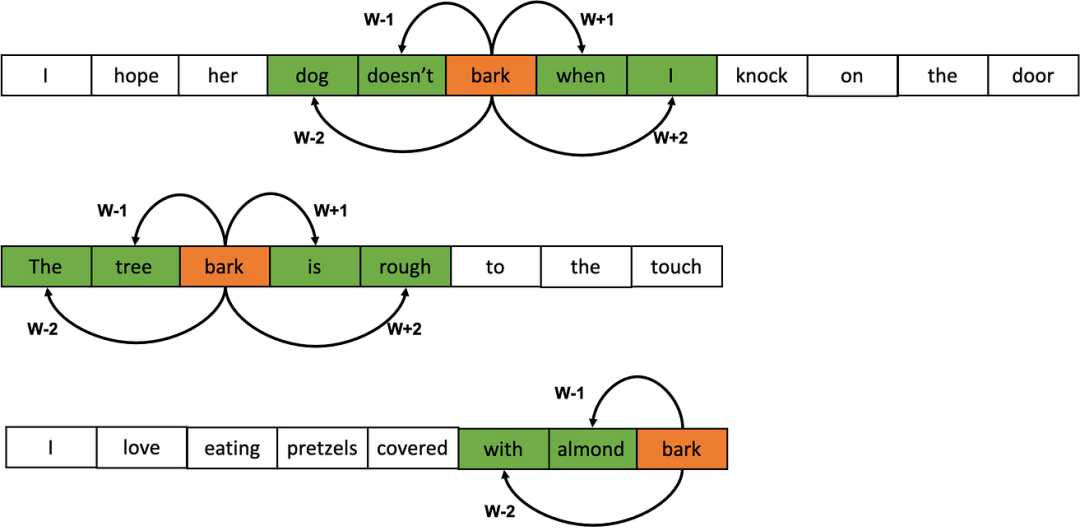
先鋪墊下背景,假如已經擁有某個語料庫,需要對語料庫的詞匯進行Embedding(下文統一稱為編碼)。那么可以將語料庫的所有文本串起來。然后預設窗口的大小(下圖的示例為5),每個窗口正中的橙色部分即為目標單詞,而綠色部則為上下文單詞。隨著窗口的滑動,就可以獲取很多的樣本(目標單詞,上下文單詞)。然后利用這些樣本進行編碼器的訓練。
那么CBOW和Skip-gram的區別就在于CBOW是用上下文的字符去預測目標單詞,而Skip-gram則是用目標單詞去預測上下文單詞。
|
|
|
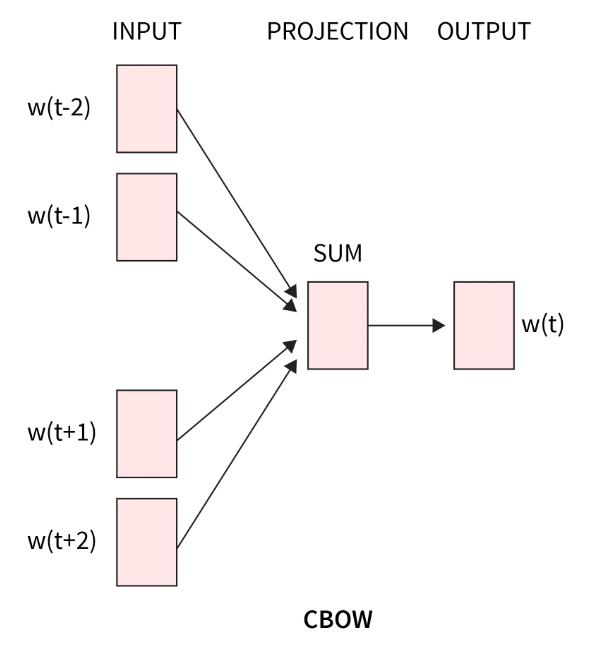
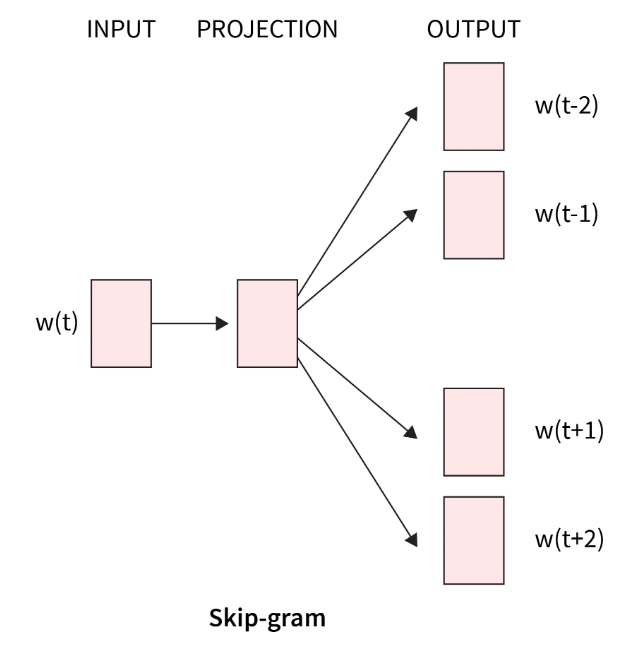
是不是到這里開始有點凌亂了,不是embedding model么,不是學習編碼么,怎么變成預測了?其實就是通過剛才獲取的樣本進行訓練編碼,以CBOW為例,將這個過程放大如下圖。
四個上下文單詞輸入經過一層的矩陣運算之后,得到了中間變量,然后在通過另外一個矩陣運算算出目標單詞,然后將目標單詞和預測的結果對比,反過來調整兩個矩陣的權重。如此反復直到損失收斂。
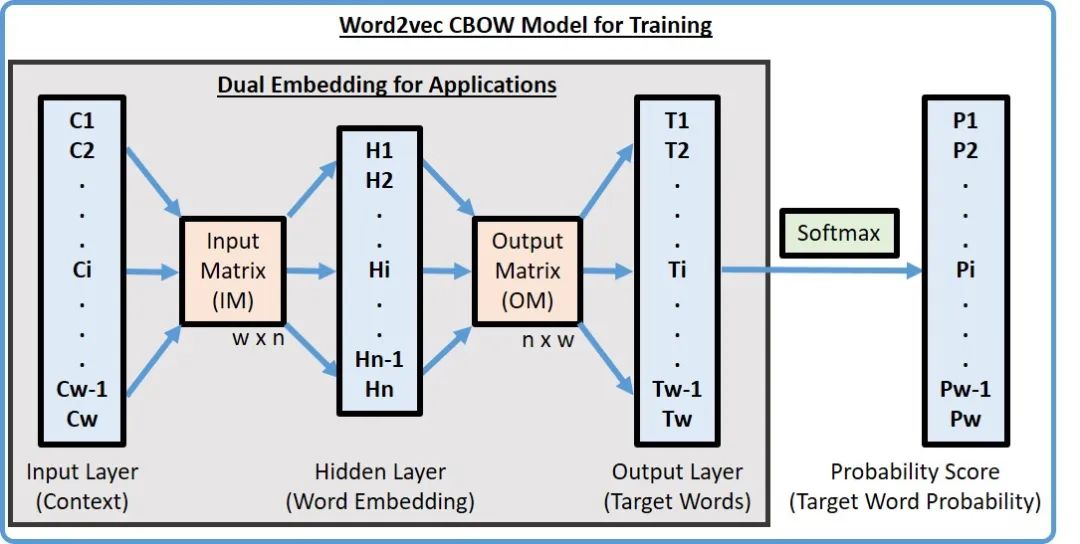
這個過程其實就是為了通過訓練得到橙色的兩個矩陣,前面的矩陣學名為查詢矩陣,后面矩陣學名為上下文矩陣。任何的輸入通過這兩個矩陣就可以編碼。回到剛才的兩種算法,無論誰預測誰,目標都是為了校正這兩個矩陣。
下面是數學版本的推理過程,數學小白可以跳過。輸入V維(也就是詞匯表為V),每個詞匯用N維的向量表示,那么需要學習的矩陣就是一個V*N維,一個N*V維。


Co-occurrence?Vector
上一篇文章發布之后,有好學的同學咨詢若滑動窗口,按照統計學的方法其實也可以得到一個矩陣,那么是如何計算每個單詞的編碼。
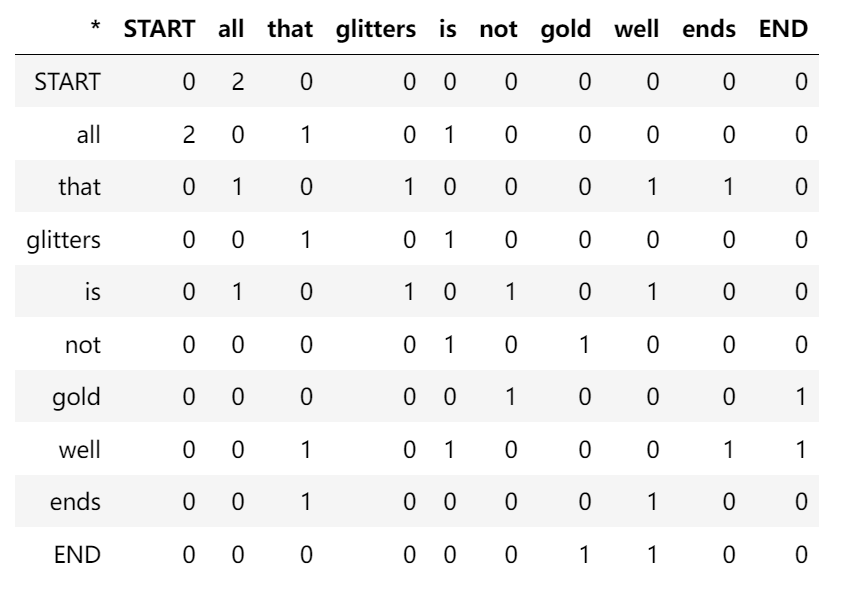
假如,所擁有的語料就兩個文檔:
文檔1: "all that glitters is not gold"
文檔2: "all is well that ends well"
|
| 所有的詞匯一共10個,假定滑動窗口大小為1,那么就可以構造右側的矩陣。 |
|
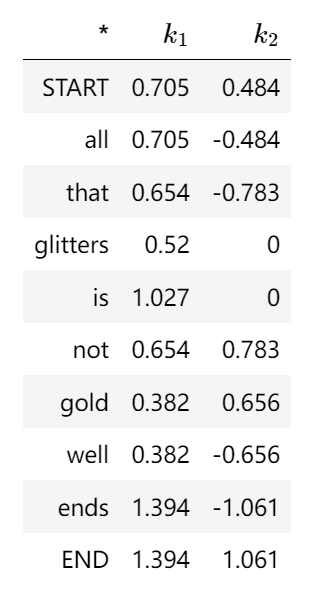
| 然后針對這個10*10(N*N,N為總詞匯數)的矩陣進行PCA或者SVD算法進行降維分解,形成k-維的向量,進而最終完成編碼。例如start的編碼就是[0.705,0.484] |

本章小結
經過編碼之后,所有單詞對應的編碼向量能夠反應單詞之間的關系。理解和搞清楚Embedding的原理是必須的,它是一切的基石,某種意義也是深度神經網絡的靈魂,其實它就是人類所謂的抽象思維。大模型模擬人類解決了將海量的信息進行高效的壓縮編碼。
Embedding是一種很好的技術與思想,微軟和Airbnb已經將它應用到推薦系統。主要參照了把Word Embedding應用到推薦場景的相似度計算中的方法,把每個商品項視為word,把用戶行為序列視為一個集合。通過獲取商品相似性作為自然語言中的上下文關系,構建神經網描繪商品在隱空間的向量表示。
Airbnb通過Embedding捕獲用戶的短期興趣和長期興趣,即利用用戶點擊會話和預定會話序列。這里默認瀏覽點擊的房源之間存在強時序關系,即前面查看房源會對影響后面查看房源的印象。通過客戶點擊或預定方式生成租客類型、房租類型等的Embedding,來獲取用戶對短期租賃和長期租賃興趣。
總而言之,Embedding對于時序的場景有著靈活的運用方式,本質上提取時序中前后的關系,進而在N-維的空間中獲取內在的聯系和邏輯。當然目前為止最出色的還是人腦,對于外界事件的分析、檢索和反應幾乎在一瞬間完成,而且處于低功耗。


![Siemens-NXUG二次開發-創建倒斜角特征、邊倒圓角特征、設置對象顏色、獲取面信息[Python UF][20240605]](http://pic.xiahunao.cn/Siemens-NXUG二次開發-創建倒斜角特征、邊倒圓角特征、設置對象顏色、獲取面信息[Python UF][20240605])











聚類算法)




 與矩陣乘法)