作為一名長期奮戰在一線的AI應用工程師,我在技術選型中最頭疼的問題就是:“這個模型服務的真實性能到底如何?” 官方的基準測試總是在理想環境下進行,而一旦投入使用,延遲波動、吞吐下降、高峰期服務不可用等問題就接踵而至。
直到我發現了由清華系團隊打造的AI Ping,這個平臺號稱能提供真實、客觀的大模型服務性能評測。經過一段時間的深度體驗,我來分享下自己的使用感受和發現。
一、為什么我們需要大模型服務性能評測?
隨著大模型應用開發的爆發式增長,MaaS(Model-as-a-Service)已成為開發者調用模型能力的首選方式。然而,面對眾多服務商和模型版本,開發者在選型時往往陷入“性能不透明、數據不統一、評測不客觀”的困境。正是在這樣的背景下,AI Ping?應運而生。
二、AI Ping 是什么?
AI Ping?是由清華系AI Infra創新企業清程極智推出的大模型服務性能評測與信息聚合平臺。它通過延遲、吞吐、可靠性等核心性能指標,對國內外主流MaaS服務進行持續監測與排名,為開發者提供客觀、實時、可操作的選型參考。
官網直達:https://aiping.cn/?utm_source=cs&utm_content=k
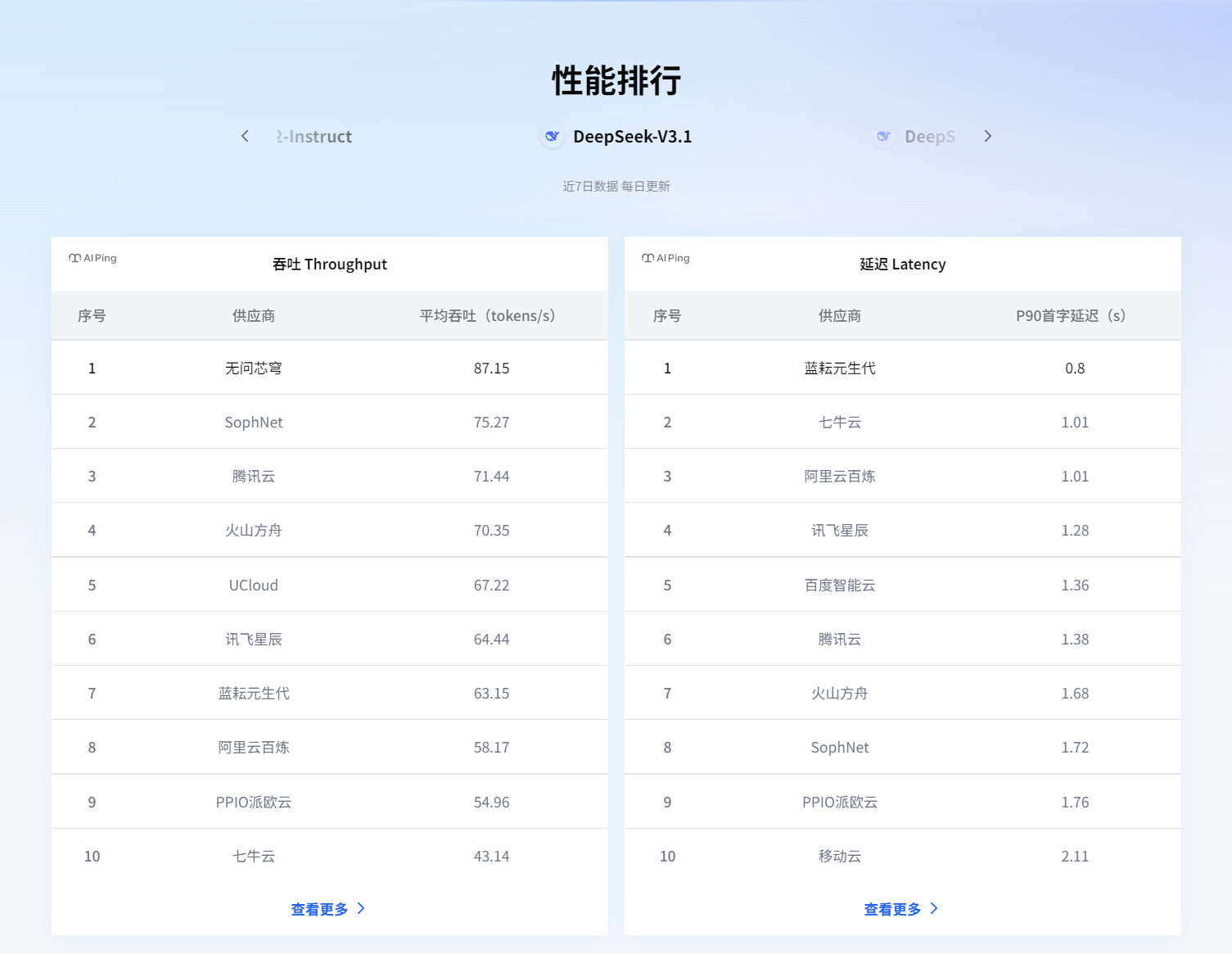
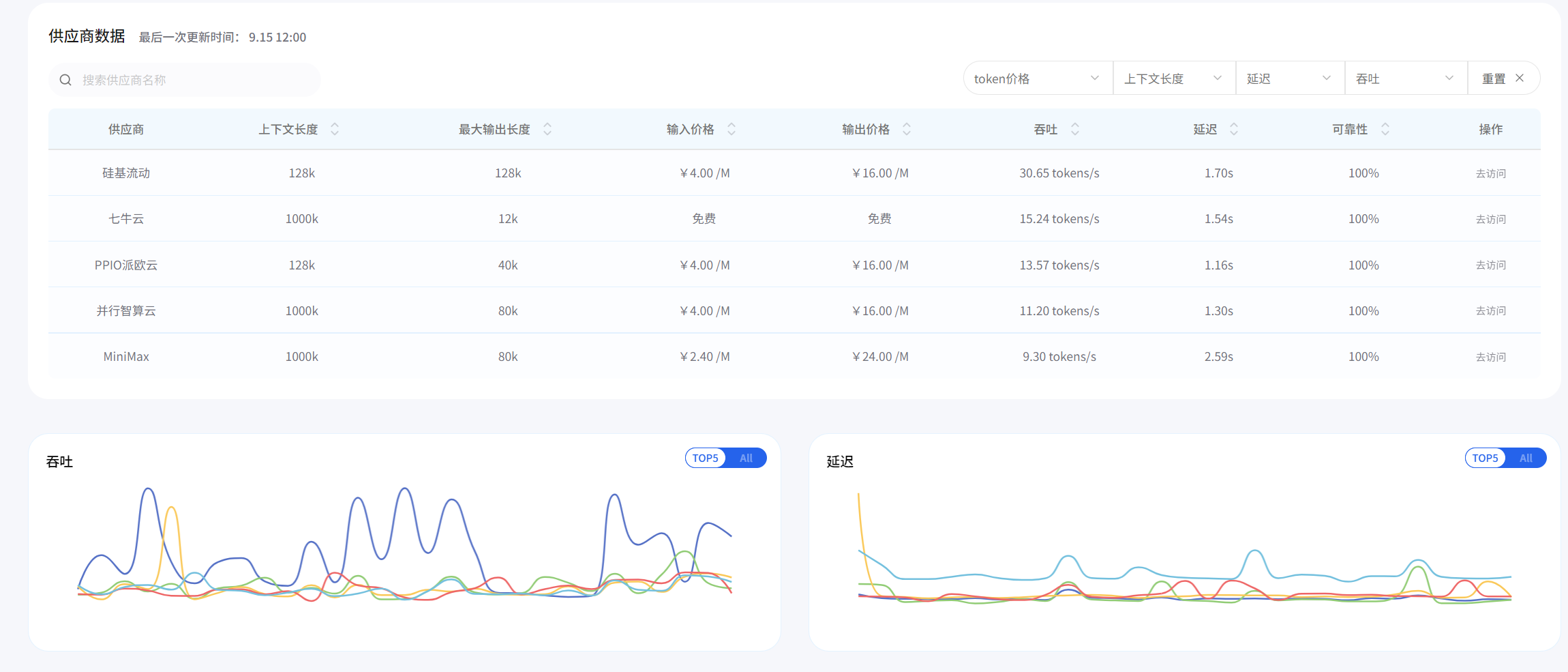
打開AI Ping官網,第一印象是簡潔、直接、信息密度高?- 典型的工程師風格設計。首頁核心位置就是那個備受關注的「大模型服務性能排行榜」,默認展示的是基于多個指標的綜合排名。
首頁性能排行榜,第一眼看到這個深深的吸引了我,因為之前有很多專業記者問我怎么檢查大模型,我一直回答不上,因為網上太多文章寫排行榜,但真正有合理、客觀、真實的評價很少很少,體驗了AI Ping之后,我可以聯系他們,正面答復了!
?左上角這里有模型和供應商搜索,可以快速定位到自己想要找的大模型,如下圖所示:
?右上角有產品文檔https://aiping.cn/docs/product入口,可以幫助快速上手和查看相關資料:

說來慚愧,作為一家創業公司的技術負責人,我去年在選大模型API時栽過大跟頭。當時輕信了某廠商的 benchmark 數據,結果上線后才發現,他們的服務每晚凌晨準時"抽風",延遲從300ms直接飆到2000ms+,我們的夜間客服機器人差點成了"智障機器人"。
直到朋友介紹和聽了清華翟季冬教授的分享,才知道他們聯合中國軟件評測中心推出了《2025大模型服務性能排行榜》,背后的數據支持來自一個叫AI Ping的平臺。
會后我第一時間注冊體驗,沒想到這一用就后續選大模型就先打開這個軟件來參考。今天就跟大家聊聊這個讓我眼前一亮的神器。
三、終于有個說人話的評測平臺
我最喜歡的是那個性能坐標圖——可以看近7日數據、每日更新、平均吞吐量。這個設計太實用了!還記得上次我們的項目就是在晚上8點流量高峰時段崩的,現在我能專門盯著這個時間點看哪個服務最穩。
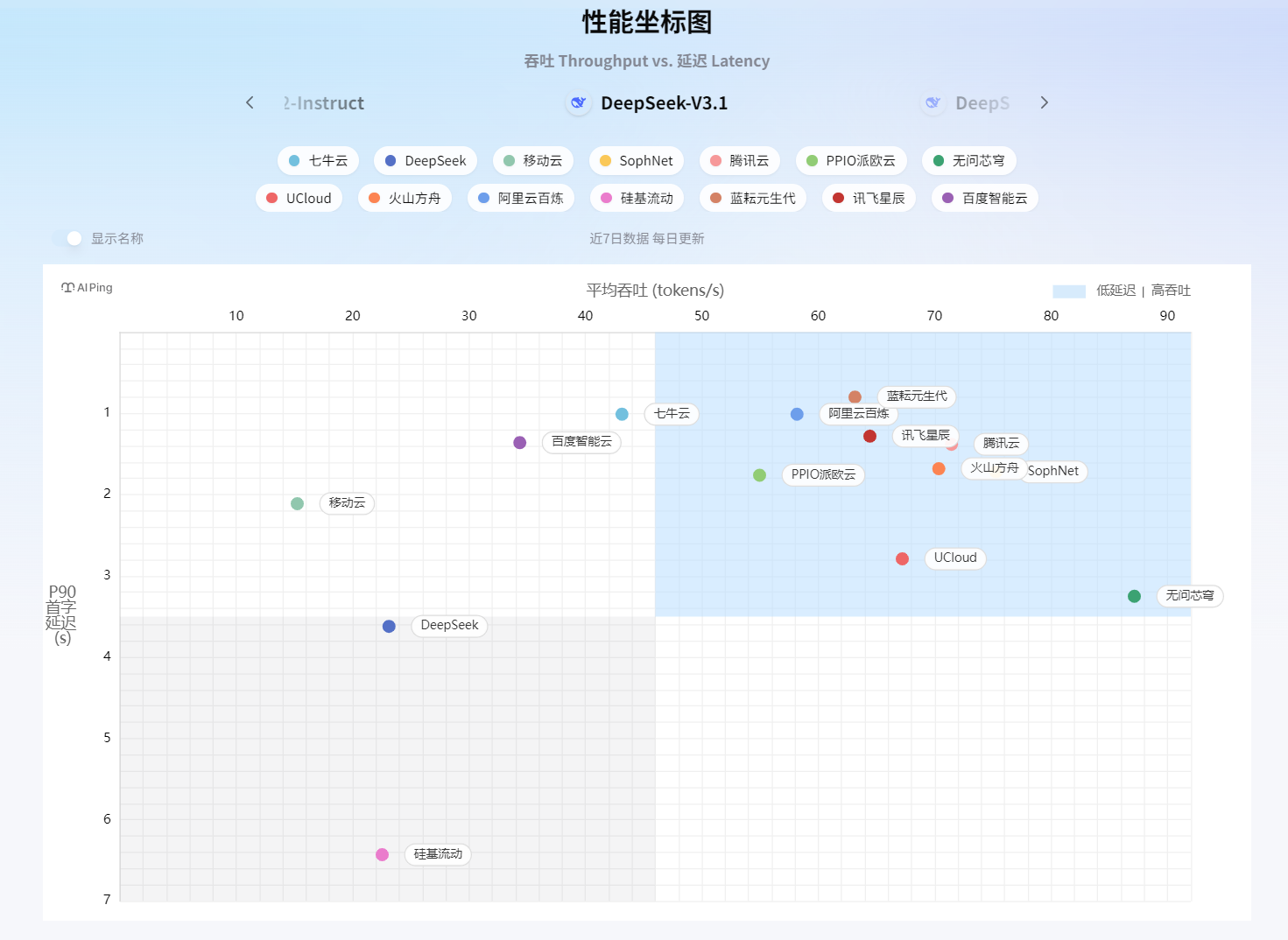
隨手翻了幾個模型的詳情頁,差點笑出聲。某個經常打廣告的廠商,頁面顯示其服務在每天凌晨2點到4點延遲飆升,這不就是我們當時踩的坑么!要是早點有這個工具,我也不用背那個"選型失誤"的鍋了。
?四、深度使用:發現了更多寶藏功能
1. 性能曲線會說話
平臺里的歷史性能曲線簡直是個寶藏。以DeepSeek-V3為例,它的7天延遲曲線平穩得讓人懷疑是不是假數據。相比之下,某些友商的曲線就跟心電圖似的,忽高忽低。
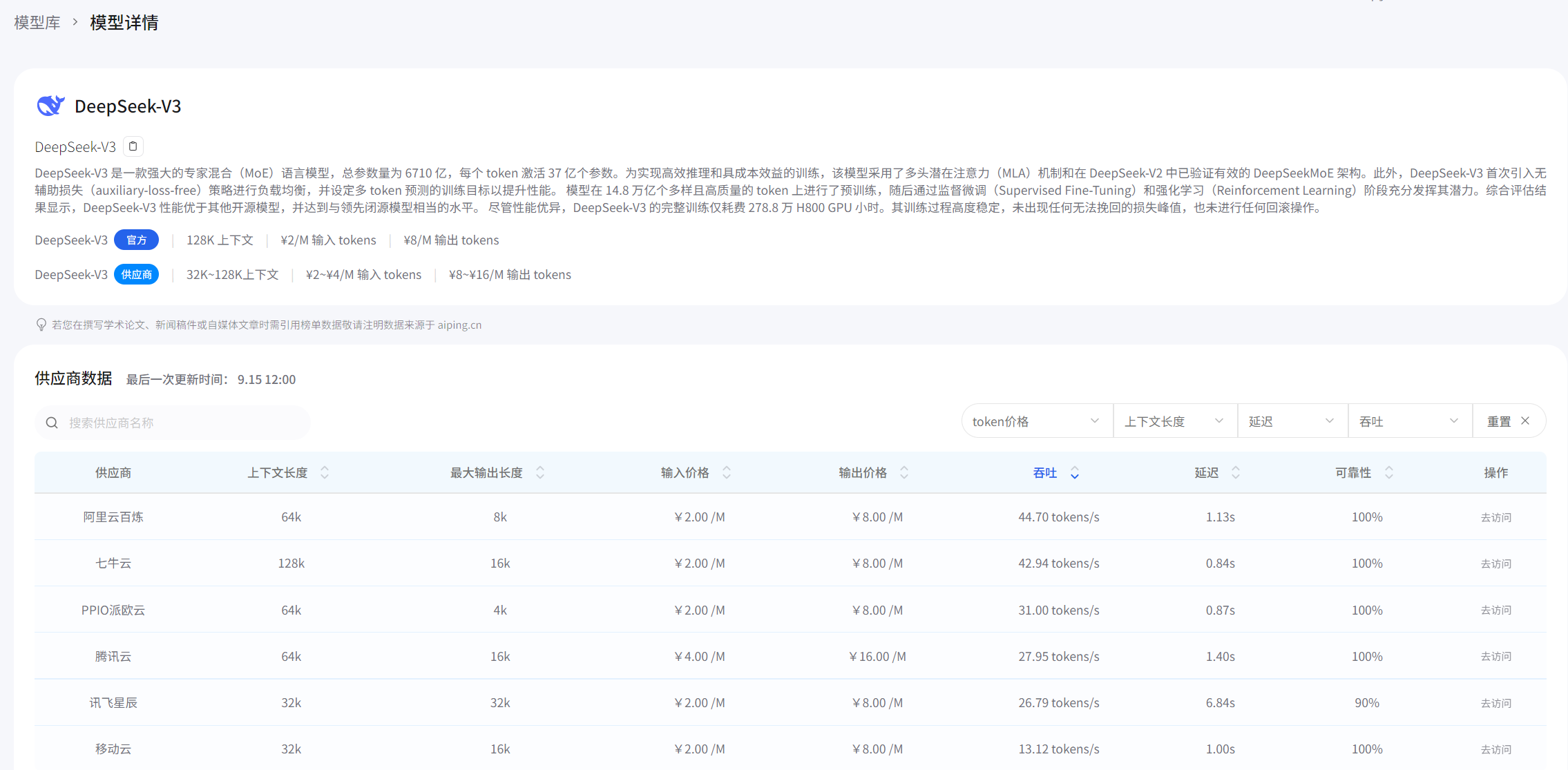
最絕的是,我發現有家廠商的曲線每天下午3點準時出現一個小高峰,后來才知道那是他們每天定時做模型熱更新的時間。這種細節,不去長期監測根本發現不了。
2. 價格對比透明得驚人
之前要對比不同模型的價格,我每次接入幾個新的大模型,老板總是問我,這個模型怎么樣?價格多少錢?性能怎樣?我明白他作為一名老板,最關心的還是價格,這樣我得一個個去翻各家官網,還要自己換算單位,頭疼得要命。AI Ping直接把所有模型的單價列得明明白白,還能按"每元token吞吐量"排序。
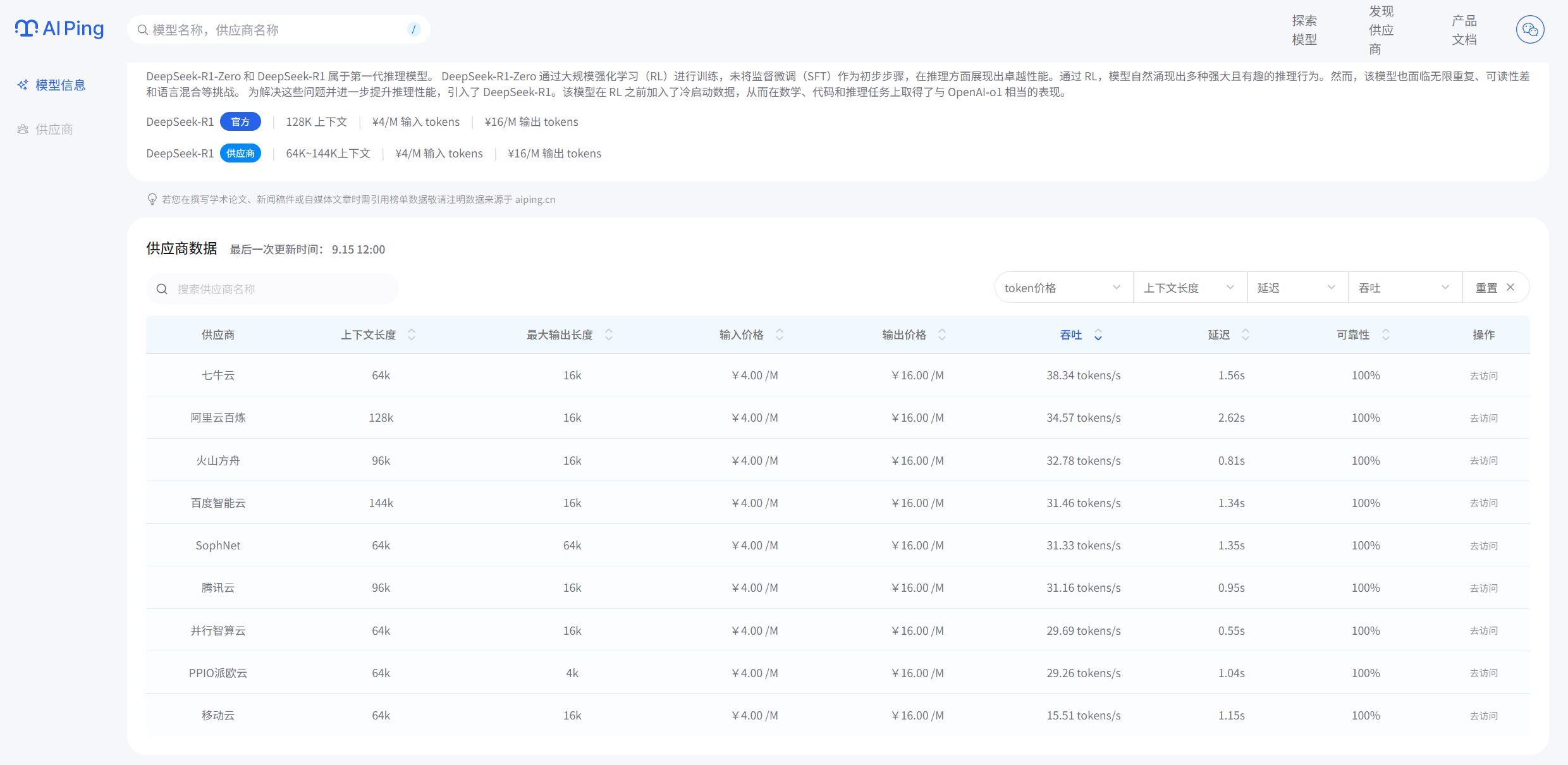
對比一下DeepSeek官網,看得出數據是準確的,值得信賴!
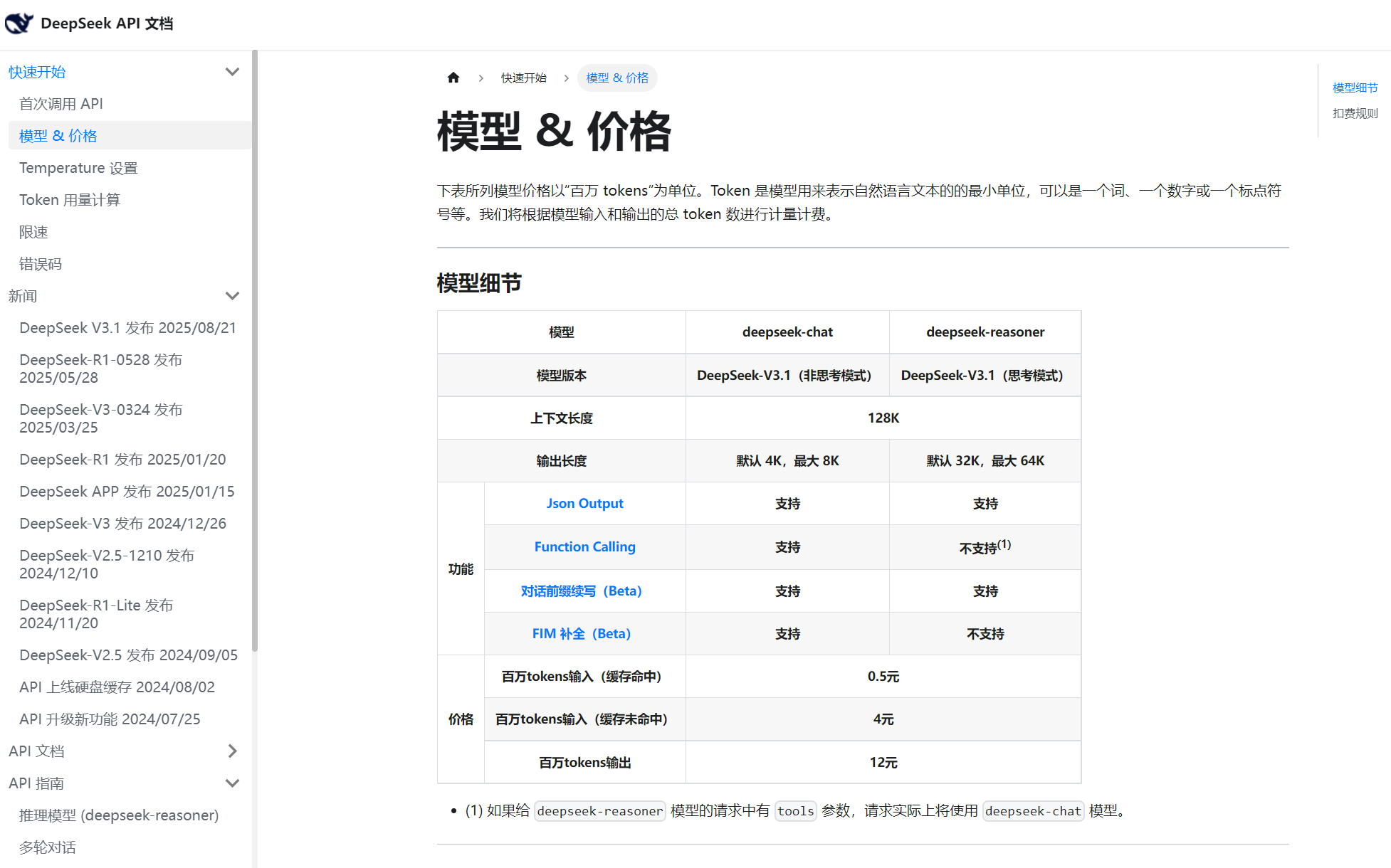
我就這樣發現了一個寶藏廠商:雖然名氣不大,但吞吐量的性價比居然排進前三。試著接了一下,效果確實不錯,每個月能省下小一萬的API調用費。
3. 可靠性數據防踩雷
有個細節讓我印象深刻:某知名廠商的詳情頁里,可靠性曲線顯示每周二上午都會有個明顯的 dips(下降)。一問才知道,他們每周二上午做例行維護。
要是早知道這個,我們就能避開這個時間段安排重要任務了。現在我都養成習慣了,每周二上午絕對不安排批量處理任務。
?五、實戰案例:如何用AI Ping做選型
最近接了個新項目,需要選一個處理長文檔的模型。我的篩選過程是這樣的:
首先,用大于128k上下文長度作為過濾條件,一下子篩掉了一半選項。
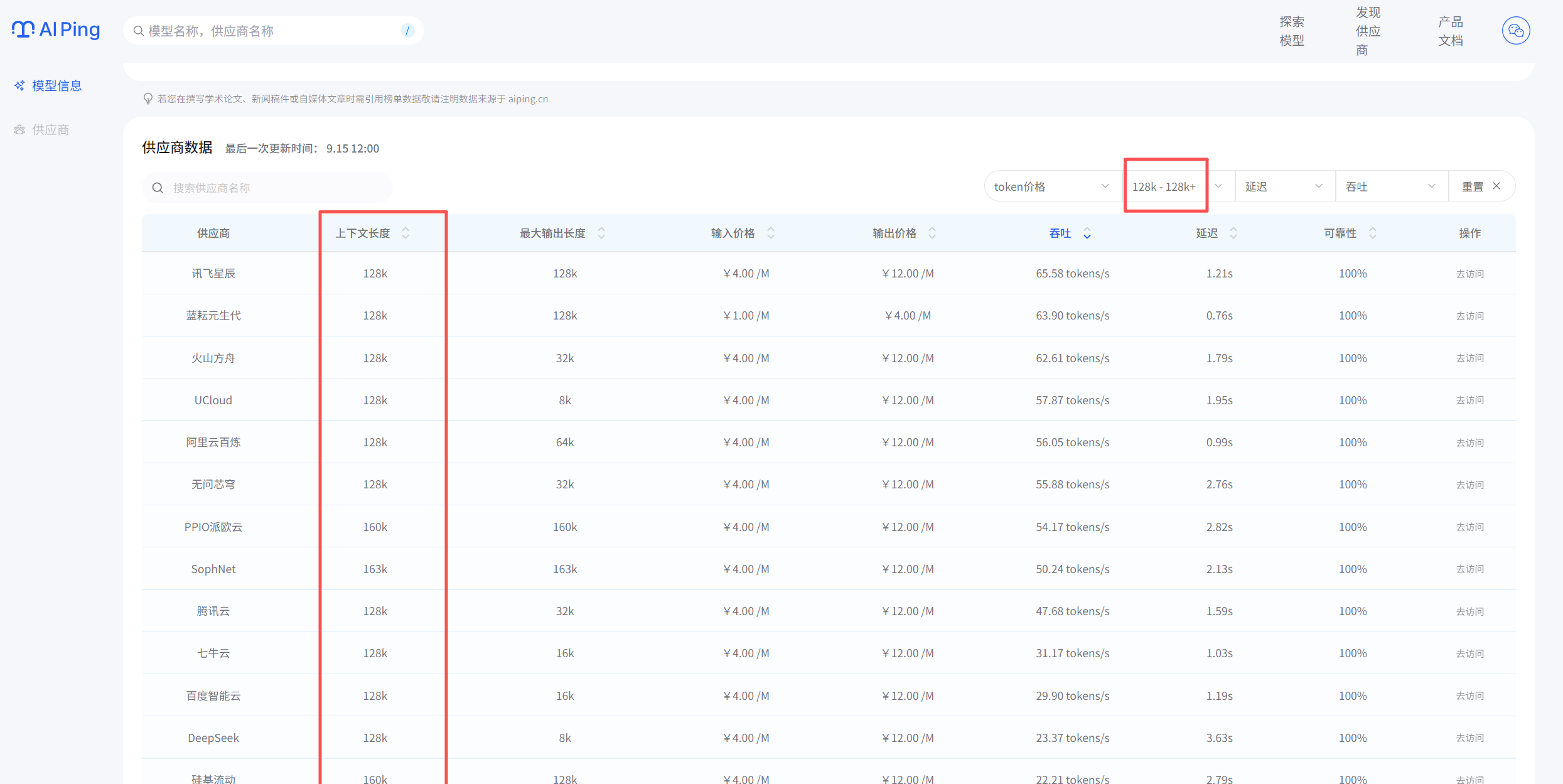
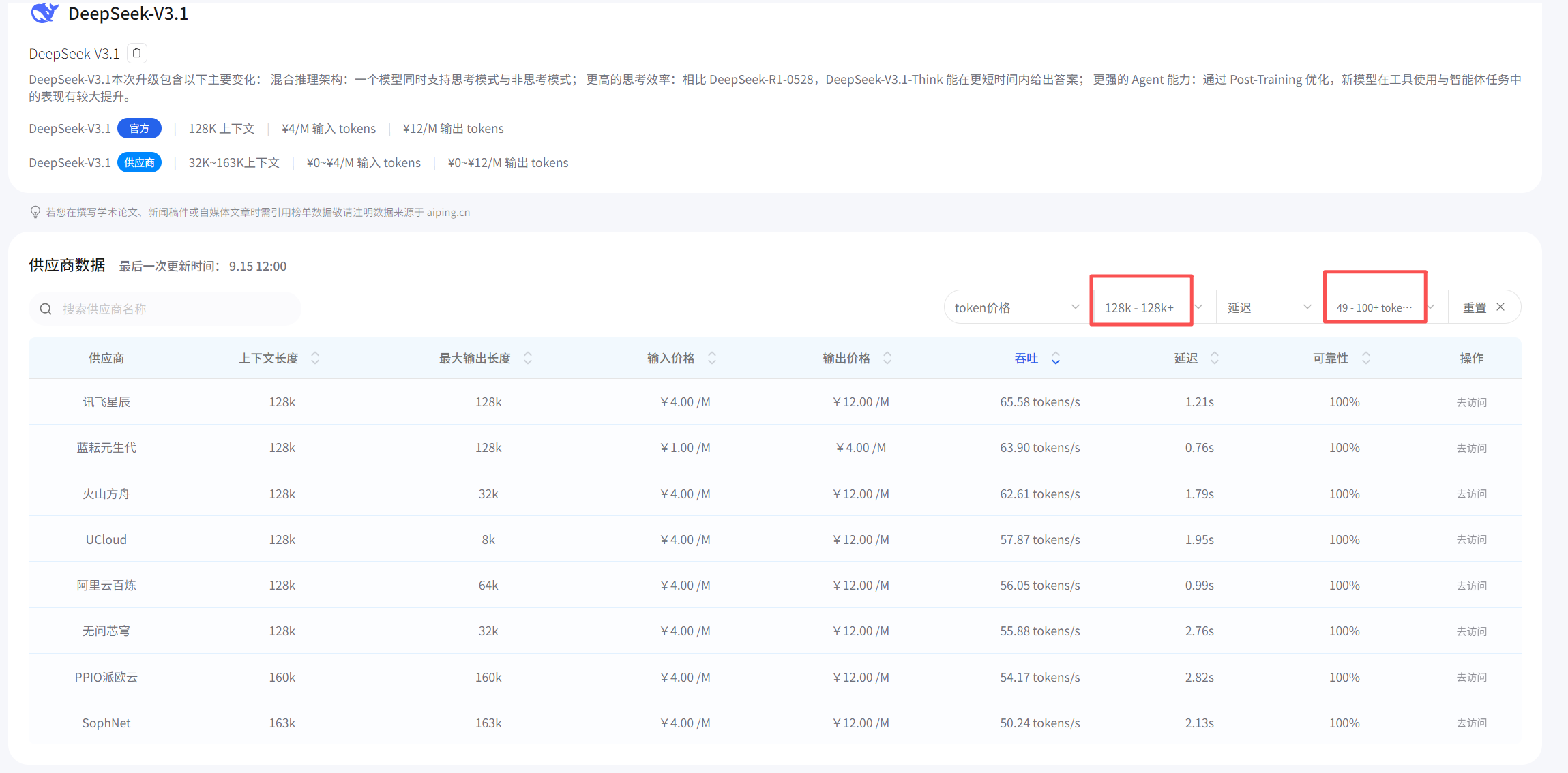
然后,按吞吐量排序,選前5名進入決賽圈。
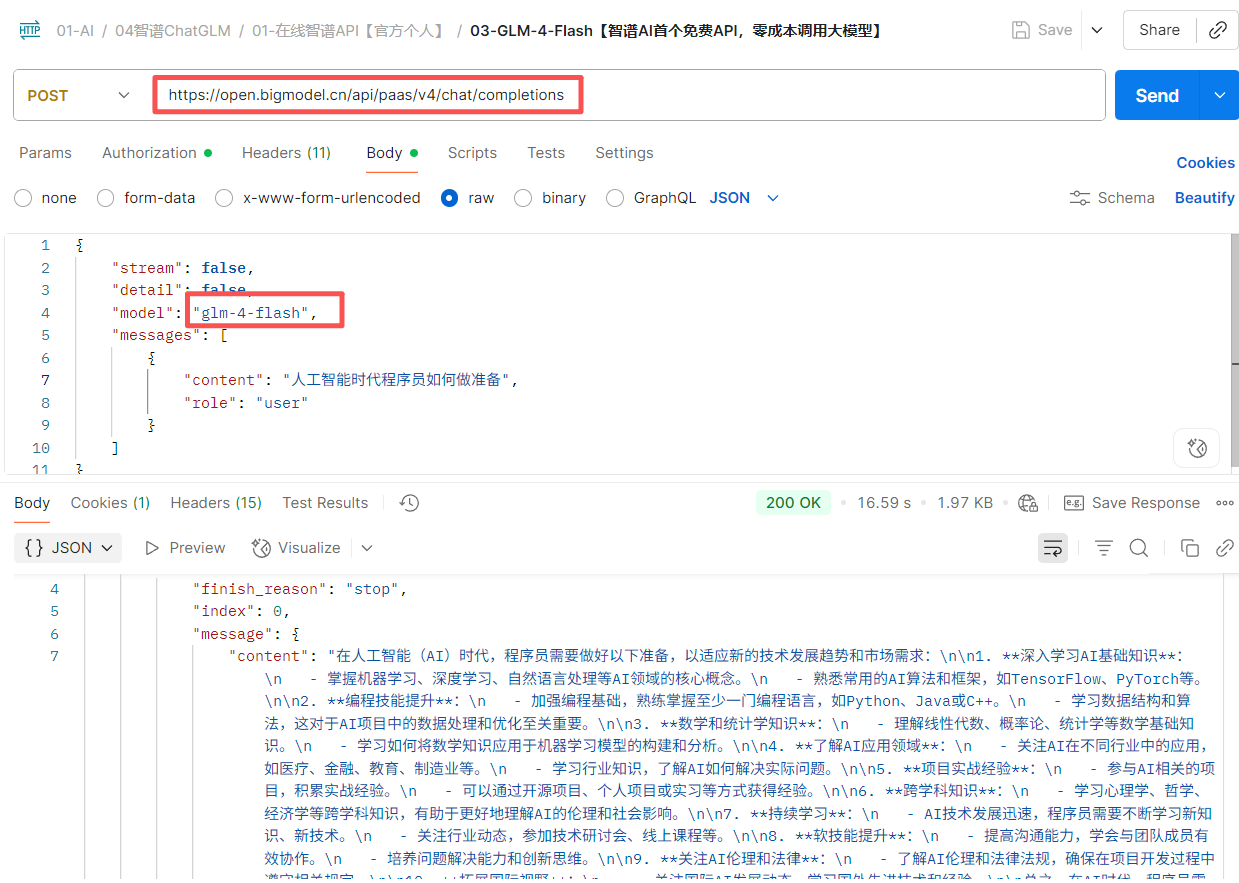
為了驗證這些數據是否準確,我用postman對接了9個廠商分別測試監督,答案令人出乎所料,跟平臺描述的一致,體驗過程如下:
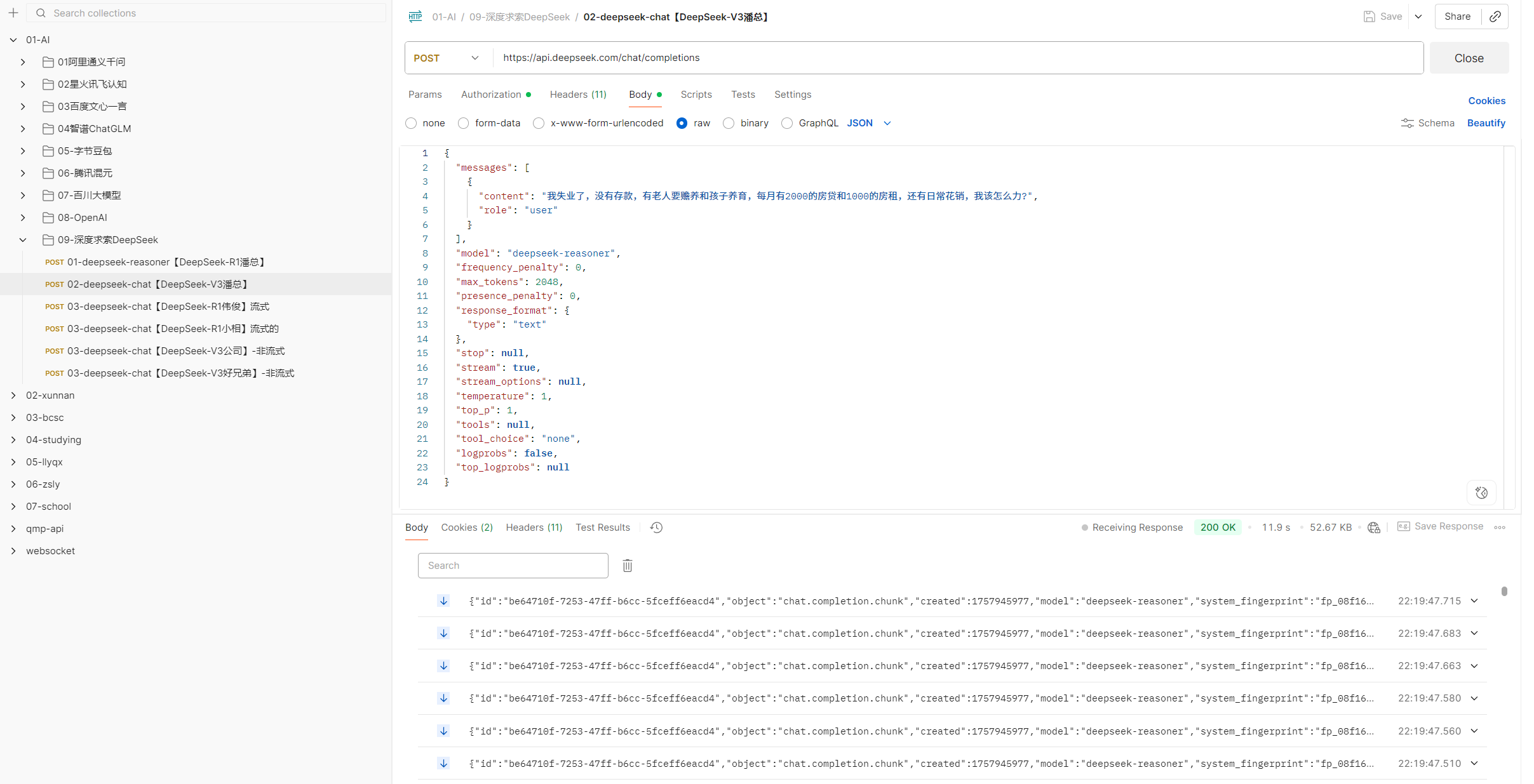
例如智譜官方請求:
還有其他大模型測試記錄,這里我就不一一列舉了,如下圖所示:
接著,逐個點開詳情頁,特別關注它們處理長文本時的性能衰減情況——有些模型處理短文本很快,但一到長文本就崩。
最后,對比價格和高峰時段表現,選了性價比最高的那個。
整個過程只用了20分鐘。放在以前,光測試每個模型的性能就要花上一周時間。
六、期待未來更強大的功能
在使用過程中,我也注意到了一些可以進一步提升的方面,相信隨著平臺的迭代,這些功能都會逐步完善:
首先是在測試場景方面,目前平臺提供了標準化的測試框架,如果未來能夠支持用戶上傳自己的測試用例和業務場景,想必能更好地滿足不同團隊的個性化需求。想象一下,如果能用我們實際業務中的對話場景和文本數據來測試模型表現,那選型精準度肯定能再上一個臺階。
其次是數據接入方面,現在是通過網頁端查看數據,如果未來能提供API接口,就可以把性能數據對接到我們自己的監控系統中,實現自動化報警和性能趨勢分析。這樣一來,我們的運維團隊就能更及時地發現潛在問題。
雖然這些功能暫時還沒有上線,但我注意到平臺一直在快速迭代。相信以清華團隊的技術實力,這些功能應該已經在開發路線圖上了。畢竟,一個好的工具就是這樣,越用越順手,越用越貼心。
七、總結一下
用了一段時間AI Ping,最大的感受是:大模型選型終于從"玄學"變成了"科學"。
以前選型靠的是廠商PPT、技術博客、朋友推薦,現在終于有了客觀的數據支持。特別是那個長時段性能監測功能,簡直就是防坑神器。
如果你也在為選型發愁,不妨去試試這個平臺。反正我們是已經把它列入技術選型標準流程了。
PS:最近看到消息,清華大學和中國軟件評測中心要在GOSIM大會上發布《2025大模型服務性能排行榜》,用的就是AI Ping的數據。能獲得這么權威的認可,說明這個平臺確實有點東西。

實現高可用負載均衡)

:)







)







