Highlights
-
大模型時代元年感悟
-
Scaling Laws 是大模型時代的摩爾定律,是最值得研究的方向
-
LLM 發展的三個階段: 算法瓶頸 -> 數據瓶頸 -> Infra 瓶頸
-
為什么 GPT 一枝獨秀, BERT、T5 日落西山?
-
大模型時代,是大部分 Infra 人的冬天,少部分 Infra 人的春天(算法研究者 同理)
前言
2023 是我過往人生經歷中最傳奇的一年(雖然只過去了 3/4),年初 ChatGPT 爆火讓所有人看到了 AGI 可能實現的曙光,無數創業公司、大廠立即跟進 LLM 甚至 ALL IN, 緊隨而來的 GPT-4 和 Office Copilot 讓市場沸騰。當時感覺,AI 時代的技術迭代速度以天記,洶涌的 AI 技術革命將迅速影響每個人的生活。從技術發展曲線來看, GPT-4 的發布應該是市場關注度的峰值:
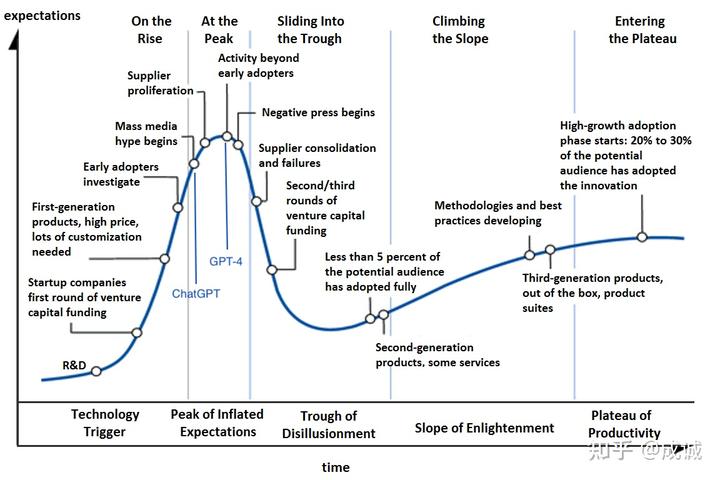
LLM 技術成熟度曲線(大致)
那時某人也有幸跟隨袁老師加入老王創立的光年之外,在低頭開發分布式深度學習框架 OneFlow 六年之后,幸運的站在了時代旋渦的中心(兩個月 AI 獨角獸 體驗卡),也第一次體驗了實操千卡集群做大模型訓練究竟是怎樣的,瓶頸在哪里(其實很多實際經驗和預先設想的相悖)。
最近 DALL·E 3 和 GPT-4V 相繼出爐,OpenAI 的圖片理解和生成能力都有很大的提升。 不過無論是 資本市場 還是 媒體關注度 其實都相對冷靜下來了, AI 時代的技術迭代速度也不是按天革新的, 商業化能力更是遭到投資人的質疑。雖然所有人都認可未來是 AI 的時代,但在中短期內 AI 如何盈利是一個頭大的問題,只有賣 GPU 的 NVIDIA 著實賺了錢。
對于做 AI Infra / MLSys 方向的我來說, 大模型的機會是既激動又悲哀的。 激動的是:終于有機會在之前難以想象的尺度上解決復雜的、最前沿的工程問題,且能產生巨大的經濟成本和時間成本收益。 悲哀的是: 隨著 GPT 一統江湖,以及能真正訓練超大模型的機會稀缺,一個通用的分布式深度學習框架和通用并行優化算法已經失去了其意義(深度學習編譯器同理, 在大模型訓練側,一定是手工優化最優,參考 FlashAttention?
聚類算法)




 與矩陣乘法)



】)









