文章目錄
- 小文件產生的原因
- 1.查詢建表或者插入
- 2.裝載數據
- 3.動態分區
- 小文件影響
- 解決方法
- 針對已經存在的小文件進行優化
- 1.小文件歸檔
- 2.getmerge
- 3.concatenate
- 4.重寫
- 針對寫入數據時的優化
- 1.調參優化
- 2.動態分區優化
- 3.使用 Spark 算子控制小文件數量
查看 HDFS 上的文件時,無意間點進了 Hive 表的存儲目錄下,打開發現其中有許多的小文件,如下所示:
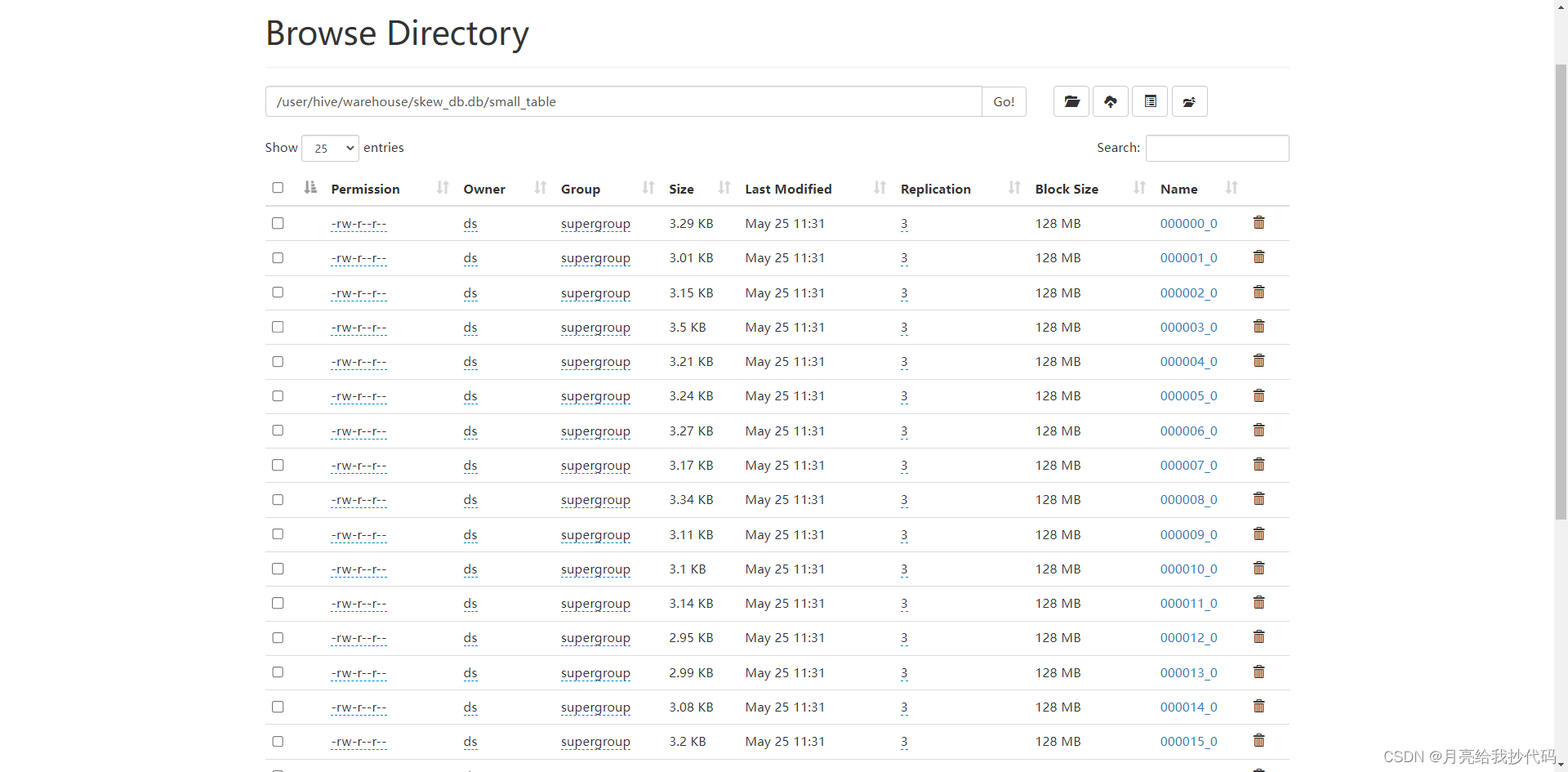
每個文件都是幾個 KB,都占用了一個塊,這種就是典型的小文件。那么通過這篇博客,一起來學習如何解決 Hive 中出現的小文件問題。
注意,博主使用的 Hive 版本為 3.1.3,不同版本之間可能存在微差,但整體影響不大。
小文件產生的原因
產生小文件絕大多數都是和 Reduce 相關的,因為它決定了我們最終的輸出文件數量,主要有以下幾個場景:
1.查詢建表或者插入
當我們通過查詢建表或者通過查詢的方式將數據插入的時候,就有可能會產生小文件,如下所示:
create table test_a select * from tmp;insert into test_a select * from tmp;
2.裝載數據
使用 load 語句裝載或者 insert 語句直接將數據裝載到表中,也可能會產生小文件。
當使用 load 時,導入多少個文件,在 Hive 表中就會生成多少個文件:
load data local inpath 'xxx' overwrite into table test_a;
當使用 insert 直接插入數據時,它會啟動 MR 任務,有多少個 Reduce,就會輸出多少個文件:
insert into test_a values (1,'a'),(2,'b'),(3,'c');
3.動態分區
在 Hive 中使用動態分區時,容易產生大量的小文件。
這主要是由于動態分區插入數據的方式導致的,在每次插入數據時,Hive 可能會為每個分區創建一個新的文件。如果插入的數據量較小或者插入操作頻繁,就會導致產生大量的小文件。
小文件過多會對Hive和底層存儲HDFS產生負面影響。此外,小文件過多也會使得NameNode的元數據變得龐大,占用過多內存,1。
小文件影響
我們都知道在 HDFS 中,所有文件的元數據信息都存儲在 NameNode,也就是命名空間中,它運行在有限的內存里。
HDFS 上每個文件的元數據信息占用 150B 左右的空間,一旦小文件過多,就會影響 HDFS 的性能,還可能撐爆 NameNode 的內存,造成集群宕機,無法提供服務,這就是為什么要處理小文件的根本原因。
同時,對于 Hive 來說,每個小文件在查詢時都會被當作一個塊,并啟動一個 Map 任務來完成,但這種情況下 Map 任務的啟動和初始化時間通常遠大于邏輯處理時間,這樣就會導致大量的資源浪費,降低程序性能。
解決方法
針對已經存在的小文件進行優化
1.小文件歸檔
在 Hadoop 中,提供了一種小文件歸檔技術,它可以將一個目錄下的所有小文件都打包成一個 HAR 文件,也就是說,它只對分區表有效。
-- 是否開啟歸檔操作,默認 false
set hive.archive.enabled=true;
-- 是否允許Hive在創建歸檔時可以設置父目錄(該參數有些Hive版本中已經棄用,無需設置)
set hive.archive.har.parentdir.settable=true;
-- 控制需要歸檔文件的大小
set har.partfile.size=1099511627776;-- 使用語法
ALTER TABLE table_name ARCHIVE PARTITION (partition
)







![[國產大模型簡單使用介紹] 開源與免費API](http://pic.xiahunao.cn/[國產大模型簡單使用介紹] 開源與免費API)
)






)

