個人博客:Sekyoro的博客小屋
個人網站:Proanimer的個人網站
隨著大模型技術蓬勃發展和開源社區越來越活躍,國內的大模型也如雨后春筍一般.這時,一些就會問了,有了llama3,Mistral還有Gemma等等,國外大廠接連發力,一些開源社區也會有一些不錯的模型,國內怎么比?對一個人使用,ollama或者gpt4all直接本地使用,對于一個組,使用1panel+ollama+maxKBHome · 1Panel-dev/MaxKB Wiki (github.com)部署在內網 也成了最佳搭配. 國內大模型怎么比?
我想說的是,確實. 國內廠商也紛紛意識到了這些問題,這些大模型彷佛一夜之間成了garbage,因為一個人根本沒有必要同時使用多個功能類似的大模型,除非搞多Agent工作流,也就是給一個任務,任務分步驟的讓多個大模型解決,這些大模型之間還能互相協作. 當然,這方面還需要繼續發展.
但不可否認的是,國內大模型能力貌似并沒有超過國外大廠,此外審查力度不能說更寬松, 國內大模型根據一些報告已經達到了200多個,有高校研究所的,也就大廠的. 這些大模型比來比去, 現在看來已經意義不大的,對于它們來說,目前能否找到好的場景和建立良好的社區,才是能實現盈利的第一步,沒有大廠背書的模型,等著開源然后期待在社區中煥發第二春吧.
國內商用目前最出名效果也最好的應該是GLM4了,可惜不開源,我目前對于不開源的模型不太感興趣,一個是目前API價格還沒有完全打下來,沒有必要支付這些,如果真要付錢為啥不用GPT4呢? 說到付錢,可以考慮OpenRouter,Azure等平臺使用GPT4.
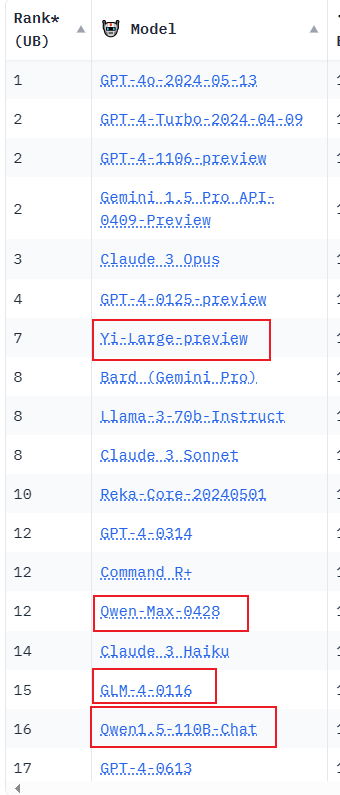
所以對于國內大模型來說,我會首選開源,其次免費API的模型.
后者作為開發者來說非常方便,直接調用就是(但是可能限制比較大),不需要自己搞個VPS部署,即使硬件要求不高.
OpenSource
下面介紹幾個國內開源大模型,主要用途就是跟ollama搭配進行部署本地,不過我猜測這些模型應該進行過國內特色微調,所以不要過于期待比較diverse的結果.
通義千問
QwenLM/Qwen: The official repo of Qwen (通義千問) chat & pretrained large language model proposed by Alibaba Cloud. (github.com)
阿里旗下的,目前開源的最大110B,非常不錯.
ChatGLM3
清華的THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 開源雙語對話語言模型 (github.com),目前有商用的GLM4,但是ollama截止目前貌似沒有支持.
零一萬物
yi (ollama.com)
開源最大的34B,勉強能用.
DeepSeek-V2
DeepSeek | 深度求索
| 模型 | 開源/閉源 | 總分 | 中文推理 | 中文語言 |
|---|---|---|---|---|
| gpt-4-1106-preview | 閉源 | 8.01 | 7.73 | 8.29 |
| DeepSeek-V2 Chat (RL) | 開源 | 7.91 | 7.45 | 8.36 |
| erniebot-4.0-202404 (文心一言) | 閉源 | 7.89 | 7.61 | 8.17 |
| DeepSeek-V2 Chat (SFT) | 開源 | 7.74 | 7.30 | 8.17 |
| gpt-4-0613 | 閉源 | 7.53 | 7.47 | 7.59 |
| erniebot-4.0-202312 (文心一言) | 閉源 | 7.36 | 6.84 | 7.88 |
| moonshot-v1-32k-202404 (月之暗面) | 閉源 | 7.22 | 6.42 | 8.02 |
| Qwen1.5-72B-Chat (通義千問) | 開源 | 7.19 | 6.45 | 7.93 |
| DeepSeek-67B-Chat | 開源 | 6.43 | 5.75 | 7.11 |
| Yi-34B-Chat (零一萬物) | 開源 | 6.12 | 4.86 | 7.38 |
| gpt-3.5-turbo-0613 | 閉源 | 6.08 | 5.35 | 6.71 |
| DeepSeek-V2-Lite 16B Chat | 開源 | 6.01 | 4.71 | 7.32 |
這是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由 236B 個參數組成,其中 21B 個參數用于激活每個標記。與 DeepSeek 67B 相比,DeepSeek-V2 性能更強,同時節省了 42.5% 的訓練成本,減少了 93.3% 的 KV 緩存,最大生成吞吐量提高到 5.76 倍。
訊飛星火
訊飛星火開源-13B
在iFlytekSpark-13B中,使用Rotary Embedding作為位置編碼方法,GELU作為激活函數,其中layer_num為40,head_num為40,hidden_size為5120,ffn_hidden_size為28672
說真的,上面這些大模型吹來吹去,一般來說參數量一樣的情況下真的有差別嗎? 使用的時候不必太糾結.
免費API
主要得益于大模型如過街老鼠,哦不對,雨后春筍,實在太多,對于大廠來說又無法完全盈利. 一般主打AI大模型的公司可能并不會開源或者非常低的價格提供API服務,但是一些大廠可能就不一樣了.
百度有ERNIE和千帆兩款大模型,文心大模型ERNIEKit旗艦版 - ERNIE 3.0介紹 | 百度AI開放平臺 (baidu.com)
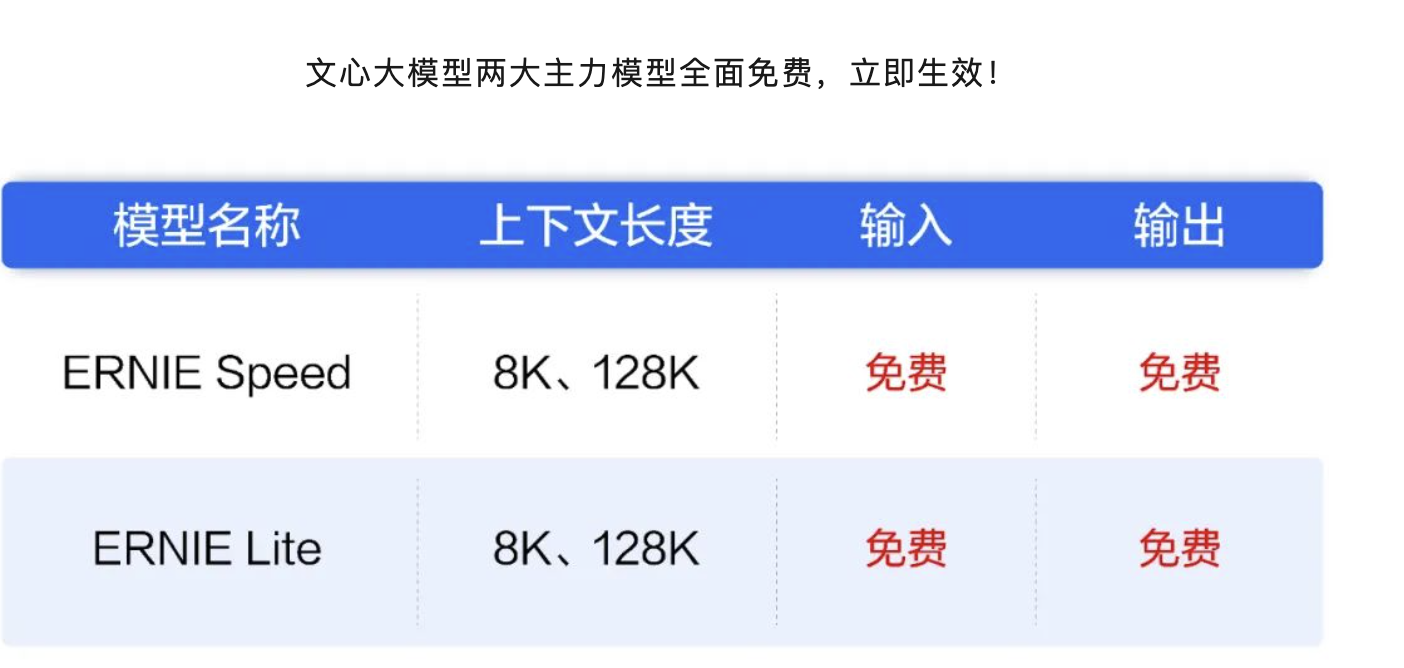
目前ERNIE可以免費了,而阿里的Qwen也降價至0.0005/1K tokens. 對于開發者還是很友好的. 比如你如果害怕瘋狂調用、IP頻繁改變被OpenAI ban掉,那也可以考慮使用國產的大模型API.
在線服務
如果自己部署缺硬件性能也嫌麻煩,除了Poe之外,國內的大模型很多也都支持在線問答了,比如Kimi,GLM等.
參考資料
- Chat with Open Large Language Models (lmsys.org)
- 大概是最全的開源大模型LLM盤點了吧! - 知乎 (zhihu.com)
- CLiB中文大模型能力評測榜單(持續更新) - 知乎 (zhihu.com)
如有疑問,歡迎各位交流!
服務器配置
寶塔:寶塔服務器面板,一鍵全能部署及管理
云服務器:阿里云服務器
Vultr服務器
GPU服務器:Vast.ai
)






)








)
)
![[python]當你認為python字符串的strip()或replace()不能刪除空格或者換行符的時候,看這里](http://pic.xiahunao.cn/[python]當你認為python字符串的strip()或replace()不能刪除空格或者換行符的時候,看這里)
