目錄
一、前言
思維導圖概括
二、配置文件解析過程分析
2.1 配置文件解析入口
2.2 初始化XMLConfigBuilder
2.3 XMLConfigBuilder#parse()方法:解析全局配置文件
2.3.1 解析properties配置
2.3.2 解析settings配置
2.3.2.1 元信息對象(MetaClass)創建過程源碼解析
2.3.2.1.1 DefaultReflectorFactory 源碼分析
?
2.3.2.1.2 Reflector 源碼分析
● Reflector 構造方法及成員變量分析
● getter 方法解析過程
● setter 方法解析過程
2.3.2.1.3 PropertyTokenizer 源碼分析
2.3.2.2 小結
2.3.3 設置 settings 配置到 Configuration 中
2.3.4 解析 typeAliases 配置
2.3.4.1 從 typeAlias 節點中解析并注冊別名
2.3.4.2 從指定的包中解析并注冊別名
2.3.4.3 注冊 MyBatis 內部類及常見類型的別名
2.3.5 解析 plugins 配置
2.3.6 解析 environments 配置
2.3.7 解析 typeHandlers 配置
2.3.7.1 register(Class, JdbcType, Class) 方法分析
2.3.7.2 register(Class, Class) 方法分析
2.3.7.3 register(Class) 方法分析
2.3.7.4 register(String) 方法分析
2.3.7.5 小結
2.3.8 解析 mappers 配置
2.4 創建SqlSessionFactory對象
三、總結
解析全局配置文件的時序圖:
一、前言
前面我們介紹了MyBatis的一些基本特性和使用方法,對MyBatis有了個初步了解。接下來,我們將著手來分析一下MyBatis的源碼,從源碼層面復盤MyBatis的執行流程。首先我們先來看MyBatis是如何解析全局配置文件(mybatis-config.xml)的。
思維導圖概括
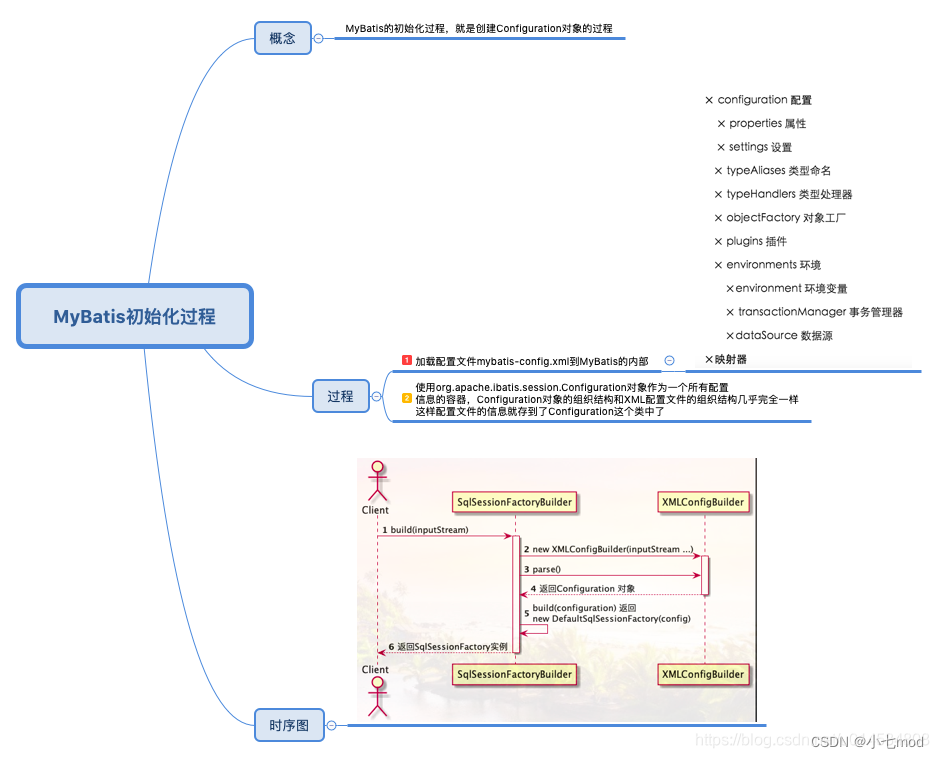
二、配置文件解析過程分析
有了上述思維導圖,我們對配置文件文件的解析過程就有了一個大概的認識,下面我們就來具體分析下解析過程。
2.1 配置文件解析入口
// 全局配置文件的路徑
String resource = "chapter1/mybatis-cfg.xml";// 使用Resources將全局配置文件轉化為文件流
InputStream inputStream = Resources.getResourceAsStream(resource);// 通過加載配置文件流,將XML配置文件構建為Configuration配置類,構建一個SqlSessionFactory,默認是DefaultSqlSessionFactory
SqlSessionFactory ?sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);從上述示例代碼中我們可以很清晰的看出,初始化過程是:
- 首先通過MyBatis 提供的工具類Resources 解析配置文件得到文件流;
- 然后將文件流傳給SqlSessionFactoryBuilder的build方法,并最終得到sqlSessionFactory。
那么我們MyBatis的初始化入口就是SqlSessionFactoryBuilder類的build()方法。build()方法有很多個重載方法,區別就是傳入的參數不同,這里我們就以傳入InputStream類型為例來分析源碼:
//* SqlSessionFactoryBuilder類
public SqlSessionFactory build(InputStream inputStream) {return build(inputStream, null, null);
}public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {try {// 根據全局配置文件的文件流實例化出一個XMLConfigBuilder對象XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);// 使用XMLConfigBuilder的parse()方法構造出Configuration對象return build(parser.parse());} catch (Exception e) {throw ExceptionFactory.wrapException("Error building SqlSession.", e);} finally {ErrorContext.instance().reset();try {// 關閉流inputStream.close();} catch (IOException e) {// Intentionally ignore. Prefer previous error.}}
}// 調用鏈中最后一個build方法使用了一個Configuration對象作為參數,并返回DefaultSqlSessionFactory
public SqlSessionFactory build(Configuration config) {return new DefaultSqlSessionFactory(config);
}
從上述源碼,我們可以知道build 構建SqlSessionFactory 分三步:
- 首先實例化一個XMLConfigBuilder;
- 然后調用XMLConfigBuilder的parse方法得到Configuration對象;
- 最后將Configuration對象作為參數實例化一個DefaultSqlSessionFactory 即SqlSessionFactory對象。
從上面的代碼中,我們大致可以猜出 MyBatis 配置文件是通過XMLConfigBuilder進行解析的。不過目前這里還沒有非常明確的解析邏輯,所以我們繼續往下看。
2.2 初始化XMLConfigBuilder
接著往下看,下面我們來看看XMLConfigBuilder類。首先是實例化XMLConfigBuilder的過程:
//* XMLConfigBuilder類
public XMLConfigBuilder(InputStream inputStream, String environment, Properties props) {// 這里調用XPathParser構造方法來實例化XPathParser對象this(new XPathParser(inputStream, true, props, new XMLMapperEntityResolver()), environment, props);
}// XMLConfigBuilder類有6個構造函數,最終其實都是調用的這個函數,傳入XPathParser
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {// 首先調用父類初始化Configuration,這樣XMLConfigBuilder就持有了Configuration對象super(new Configuration());// 錯誤上下文設置成SQL Mapper Configuration(XML文件配置),以便后面出錯了報錯用吧ErrorContext.instance().resource("SQL Mapper Configuration");// 將Properties全部設置到Configuration里面去this.configuration.setVariables(props);this.parsed = false;this.environment = environment;// 將XPathParser實例對象設置到XMLConfigBuilder中this.parser = parser;
}//* XPathParser類
public XPathParser(Reader reader, boolean validation, Properties variables, EntityResolver entityResolver) {commonConstructor(validation, variables, entityResolver);this.document = createDocument(new InputSource(reader));
}private Document createDocument(InputSource inputSource) {// important: this must only be called AFTER common constructortry {// 這個是DOM解析方式// 得到DocumentBuilderFactory對象,工廠設計模式,用來創建DocumentBuilder對象DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();factory.setValidating(validation);// 命名空間factory.setNamespaceAware(false);// 忽略注釋factory.setIgnoringComments(true);// 忽略空白factory.setIgnoringElementContentWhitespace(false);// 把 CDATA 節點轉換為 Text 節點factory.setCoalescing(false);// 擴展實體引用factory.setExpandEntityReferences(true);// 通過DocumentBuilderFactory創建DocumentBuilder對象DocumentBuilder builder = factory.newDocumentBuilder();// 需要注意的就是定義了EntityResolver(XMLMapperEntityResolver),這樣不用聯網去獲取DTD,// 將DTD放在org\apache\ibatis\builder\xml\mybatis-3-config.dtd,來達到驗證xml合法性的目的builder.setEntityResolver(entityResolver);builder.setErrorHandler(new ErrorHandler() {@Overridepublic void error(SAXParseException exception) throws SAXException {throw exception;}@Overridepublic void fatalError(SAXParseException exception) throws SAXException {throw exception;}@Overridepublic void warning(SAXParseException exception) throws SAXException {}});// DocumentBuilder的parse方法用于解析輸入流,將xml解析到Document對象中return builder.parse(inputSource);} catch (Exception e) {throw new BuilderException("Error creating document instance. Cause: " + e, e);}
}
從上述源碼中,我們可以看出在XMLConfigBuilder的實例化過程包括兩個過程:
- 創建XPathParser的實例并初始化;
- 創建Configuration的實例對象,然后將XPathParser的實例設置到XMLConfigBuilder中。
XPathParser 初始化主要做了兩件事:
- 初始化DocumentBuilder對象;
- 并通過調用DocumentBuilder對象的parse方法得到Document對象,我們配置文件的配置就全部都轉移到了Document對象中。
最終,XMLConfigBuilder對象中就持有了XPathParser對象和Configuration對象,XPathParser對象中就持有了解析XML得到的Document對象。
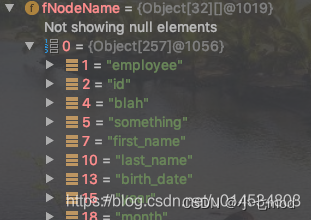
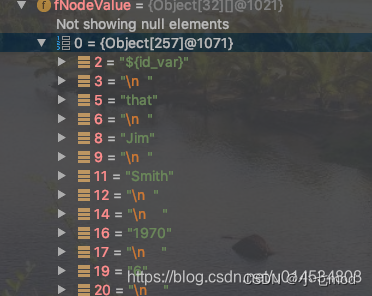
我們下面通過調試看看Document 對象中的內容,測試用例是MyBatis 自身的單元測試XPathParserTest
測試的xml:
<!--nodelet_test.xml
-->
<employee id="${id_var}"><blah something="that"/><first_name>Jim</first_name><last_name>Smith</last_name><birth_date><year>1970</year><month>6</month><day>15</day></birth_date><height units="ft">5.8</height><weight units="lbs">200</weight><active>true</active>
</employee>
測試用例:
//* XPathParserTest類
@Test
public void shouldTestXPathParserMethods() throws Exception {String resource = "resources/nodelet_test.xml";InputStream inputStream = Resources.getResourceAsStream(resource);XPathParser parser = new XPathParser(inputStream, false, null, null);assertEquals((Long)1970l, parser.evalLong("/employee/birth_date/year"));assertEquals((short) 6, (short) parser.evalShort("/employee/birth_date/month"));assertEquals((Integer) 15, parser.evalInteger("/employee/birth_date/day"));assertEquals((Float) 5.8f, parser.evalFloat("/employee/height"));assertEquals((Double) 5.8d, parser.evalDouble("/employee/height"));assertEquals("${id_var}", parser.evalString("/employee/@id"));assertEquals(Boolean.TRUE, parser.evalBoolean("/employee/active"));assertEquals("<id>${id_var}</id>", parser.evalNode("/employee/@id").toString().trim());assertEquals(7, parser.evalNodes("/employee/*").size());XNode node = parser.evalNode("/employee/height");assertEquals("employee/height", node.getPath());assertEquals("employee[${id_var}]_height", node.getValueBasedIdentifier());
}
調試結果:
2.3 XMLConfigBuilder#parse()方法:解析全局配置文件
介紹完XMLConfigBuilder的初始化過程之后,接著我們來看看XMLConfigBuilder中的parse()方法,由前面其初始化過程我們可以得知我們的MyBatis全局配置信息(mybatis-config.xml)已經保存到了XMLConfigBuilder的XPathParser對象的Document中了。XMLConfigBuilder中的parse()方法就是去解析MyBatis的全局配置文件,其實就是將XPathParser中已經解析到Document對象的全局配置信息轉移到XMLConfigBuilder對象持有的Configuration對象中,不多說了,看源碼。
//* XMLConfigBuilder類
// 解析全局配置信息
public Configuration parse() {// 如果已經解析過了,報錯if (parsed) {throw new BuilderException("Each XMLConfigBuilder can only be used once.");}// 將是否解析過設置為true,表示我們要解析全局配置文件了parsed = true; // parser就是XMLConfigBuilder持有的XPathParser對象// 開始解析全局配置文件,將XPathParser對象持有的Document對象中的全局配置信息,解析轉移到configuration對象中// 全局配置文件的根節點是configuration(就是xml中的<configuration>標簽),parseConfiguration方法要傳入根節點對象parseConfiguration(parser.evalNode("/configuration"));// 返回解析完成的configuration對象,此時全局配置信息已經解析到了configuration對象中了return configuration;
}
到這里大家可以看到一些端倪了,注意一個 xpath 表達式 -?/configuration。這個表達式代表的是 MyBatis 的<configuration/>標簽,這里選中這個標簽,并傳遞給parseConfiguration方法。我們繼續跟下去。
//* XMLConfigBuilder類
// 解析全局配置信息到configuration對象中
private void parseConfiguration(XNode root) {try {// 分步驟解析/*** 1.解析 properties節點* 對應mybatis-config.xml標簽:<properties resource="mybatis/db.properties" />* 解析到org.apache.ibatis.parsing.XPathParser#variables成員屬性 和* org.apache.ibatis.session.Configuration#variables成員屬性*/propertiesElement(root.evalNode("properties"));/*** 2.解析settings節點* 具體可以配置哪些屬性:http://www.mybatis.org/mybatis-3/zh/configuration.html#settings* * 對應mybatis-config.xml中的<settings>標簽* <settings><setting name="cacheEnabled" value="true"/><setting name="lazyLoadingEnabled" value="true"/><setting name="mapUnderscoreToCamelCase" value="false"/><setting name="localCacheScope" value="SESSION"/><setting name="jdbcTypeForNull" value="OTHER"/>..............</settings>解析到XMLConfigBuilder的settings成員屬性中**/Properties settings = settingsAsProperties(root.evalNode("settings"));/*** 基本沒有用過該屬性* VFS含義是虛擬文件系統;主要是通過程序能夠方便讀取本地文件系統、FTP文件系統等系統中的文件資源。Mybatis中提供了VFS這個配置,主要是通過該配置可以加載自定義的虛擬文件系統應用程序解析到:org.apache.ibatis.session.Configuration#vfsImpl屬性*/loadCustomVfs(settings);/*** 指定 MyBatis 所用日志的具體實現,未指定時將自動查找。* SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING* * 解析到org.apache.ibatis.session.Configuration#logImpl屬性*/loadCustomLogImpl(settings);/*** 3.解析類型別名* 對應mybatis-config.xml中的<typeAliases>標簽<typeAliases><typeAlias alias="Author" type="cn.tulingxueyuan.pojo.Author"/></typeAliases><typeAliases><package name="cn.tulingxueyuan.pojo"/></typeAliases>解析到org.apache.ibatis.session.Configuration#typeAliasRegistry.typeAliases成員屬性*/typeAliasesElement(root.evalNode("typeAliases"));/*** 4.解析插件(比如分頁插件)* mybatis自帶的* Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)ParameterHandler (getParameterObject, setParameters)ResultSetHandler (handleResultSets, handleOutputParameters)StatementHandler (prepare, parameterize, batch, update, query)解析到:org.apache.ibatis.session.Configuration#interceptorChain.interceptors成員屬性*/pluginElement(root.evalNode("plugins"));// 5.對象工廠objectFactoryElement(root.evalNode("objectFactory"));// 6.對象包裝工廠objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));// 7.將前面解析出來的settings配置設置到Configuration對象中settingsElement(root.evalNode("settings"));/*** 8.解析mybatis環境* 對應mybatis-config.xml中的<environments>標簽<environments default="dev"><environment id="dev"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="root"/><property name="password" value="Zw726515"/></dataSource></environment><environment id="test"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="root"/><property name="password" value="123456"/></dataSource></environment></environments>* 解析到:org.apache.ibatis.session.Configuration#environment成員屬性* 在集成spring情況下由 spring-mybatis提供數據源和事務工廠*/environmentsElement(root.evalNode("environments"));/*** 9.解析數據庫廠商databaseIdProvider* * 對應mybatis-config.xml中的<databaseIdProvider>標簽* <databaseIdProvider type="DB_VENDOR"><property name="SQL Server" value="sqlserver"/><property name="DB2" value="db2"/><property name="Oracle" value="oracle" /><property name="MySql" value="mysql" /></databaseIdProvider>* 解析到:org.apache.ibatis.session.Configuration#databaseId成員屬性*/databaseIdProviderElement(root.evalNode("databaseIdProvider"));/*** 10.解析類型處理器節點* 對應mybatis-config.xml中的<typeHandlers>標簽* <typeHandlers><typeHandler handler="org.mybatis.example.ExampleTypeHandler"/></typeHandlers>解析到:org.apache.ibatis.session.Configuration#typeHandlerRegistry.typeHandlerMap成員屬性*/typeHandlerElement(root.evalNode("typeHandlers"));/*** 11.解析mapper映射器(最最最最最重要的就是解析我們的mapper)** 對應mybatis-config.xml中的<mappers>標簽* <mappers><mapper resource="mybatis/mapper/EmployeeMapper.xml"/> // 指定xml<mapper class="com.tuling.mapper.DeptMapper"></mapper> // 指定Mapper類<package name="com.tuling.mapper"></package> // 也可以批量指定Mapper類所在的包名</mappers>resource:來注冊我們的class類路徑下的url:來指定我們磁盤下的或者網絡資源的class:1.若注冊Mapper不帶xml文件的,這里可以直接注冊2.若注冊的Mapper帶xml文件的,需要把xml文件和mapper文件同名,同路徑解析到:org.apache.ibatis.session.Configuration#mapperRegistry.knownMappers成員屬性*/mapperElement(root.evalNode("mappers"));} catch (Exception e) {throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);}
}
至此,一個MyBatis的解析過程就出來了,每個配置的解析邏輯封裝在相應的方法中,接下來將重點介紹一些常用的配置,例如properties、settings、environments、typeAliases、typeHandler、mappers。閑話少敘,接下來我們首先來分析下properties的解析過程。
2.3.1 解析properties配置
解析properties節點是由propertiesElement這個方法完成的,該方法的邏輯比較簡單。在分析方法源碼前,首先我們來看看一個普通的properties配置。
<properties resource="jdbc.properties"><property name="jdbc.username" value="coolblog"/><property name="hello" value="world"/>
</properties>在上面的配置中,我為 properties 節點配置了一個 resource 屬性,以及兩個子節點。下面我們參照上面的配置,來分析一下 propertiesElement 的邏輯。相關分析如下。
//* XMLConfigBuilder類
private void propertiesElement(XNode context) throws Exception {if (context != null) {// 如果在這些地方,屬性多于一個的話,MyBatis按照如下的順序加載它們:// 1.在 properties 元素體內指定的屬性首先被讀取。// 2.從類路徑下資源或 properties 元素的 url 屬性中加載的屬性第二被讀取,它會覆蓋已經存在的完全一樣的屬性。// 3.作為方法參數傳遞的屬性最后被讀取, 它也會覆蓋任一已經存在的完全一樣的屬性,這些屬性可能是從 properties 元素體內和資源/url 屬性中加載的。通過方法參數傳遞的傳入方式是調用構造函數時傳入,public XMLConfigBuilder(Reader reader, String environment, Properties props)// 1.XNode.getChildrenAsProperties函數方便得到孩子所有PropertiesProperties defaults = context.getChildrenAsProperties();// 2.然后查找resource或者url,加入前面的PropertiesString resource = context.getStringAttribute("resource");String url = context.getStringAttribute("url");if (resource != null && url != null) {throw new BuilderException("The properties element cannot specify both a URL and a resource based property file reference. Please specify one or the other.");}if (resource != null) {// 從文件系統中加載并解析屬性文件defaults.putAll(Resources.getResourceAsProperties(resource));} else if (url != null) {// 通過url加載并解析屬性文件defaults.putAll(Resources.getUrlAsProperties(url));}// 3.Variables也全部加入PropertiesProperties vars = configuration.getVariables();if (vars != null) {defaults.putAll(vars);}parser.setVariables(defaults);// 4. 將屬性值設置到configuration中configuration.setVariables(defaults);}
}/*** 得到孩子,返回Properties,孩子的格式肯定都有name,value屬性* @return*/
public Properties getChildrenAsProperties() {Properties properties = new Properties();// 獲取并遍歷子節點for (XNode child : getChildren()) {// 獲取 property 節點的 name 和 value 屬性String name = child.getStringAttribute("name");String value = child.getStringAttribute("value");if (name != null && value != null) {// 設置屬性到屬性對象中properties.setProperty(name, value);}}return properties;
}// -☆- XNode
public List<XNode> getChildren() {List<XNode> children = new ArrayList<XNode>();// 獲取子節點列表NodeList nodeList = node.getChildNodes();if (nodeList != null) {for (int i = 0, n = nodeList.getLength(); i < n; i++) {Node node = nodeList.item(i);if (node.getNodeType() == Node.ELEMENT_NODE) {// 將節點對象封裝到 XNode 中,并將 XNode 對象放入 children 列表中children.add(new XNode(xpathParser, node, variables));}}}return children;
}
上面是 properties 節點解析的主要過程,不是很復雜。主要包含三個步驟:
- 一是解析 properties 節點的子節點,并將解析結果設置到 Properties 對象中。
- 二是從文件系統或通過網絡讀取屬性配置,這取決于 properties 節點的 resource 和 url 是否為空。第二步對應的代碼比較簡單,這里就不分析了。有興趣的話,大家可以自己去看看。
- 最后一步則是將解析出的屬性對象設置到 XPathParser 和 Configuration 對象中。
需要注意的是,propertiesElement 方法是先解析 properties 節點的子節點內容,后再從文件系統或者網絡讀取屬性配置,并將所有的屬性及屬性值都放入到 defaults 屬性對象中。這就會存在同名屬性覆蓋的問題,也就是從文件系統,或者網絡上讀取到的屬性及屬性值會覆蓋掉 properties 子節點中同名的屬性和及值。比如上面配置中的jdbc.properties內容如下:
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/myblog?...
jdbc.username=root
jdbc.password=1234與 properties 子節點內容合并后,結果如下:
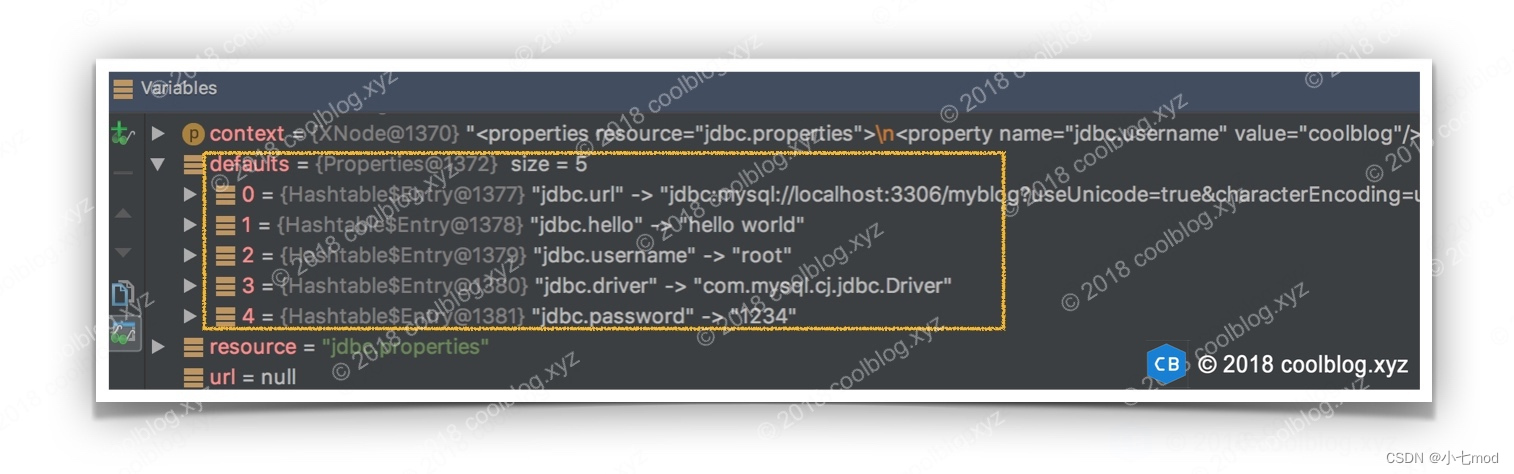
如上,原來在<property>子標簽配置的jdbc.username值為coolblog,現在被引入的jdbc.properties中的同名屬性覆蓋為了root。同名屬性覆蓋的問題需要大家注意一下,總結properties元素的解析順序是:
- 在Properties 元素體內指定的屬性首先被讀取。
- 在類路徑下資源或properties元素的url 屬性中加載的屬性第二個被讀取,它會覆蓋完全一樣的屬性
- 作為方法參數傳遞的屬性最后被讀取,它也會覆蓋任一已存在的完全一樣的屬性,這些屬性可能是從properties 元素體內和資源 /url 屬性中加載的。通過方法參數傳遞的傳入方式是調用構造函數時傳入,public XMLConfigBuilder(Reader reader, String environment, Properties props)
2.3.2 解析settings配置
settings相關配置是MyBatis中非常重要的配置,這些配置用于用戶調整MyBatis運行時的行為。settings配置繁多,在對這些配置不熟悉的情況下,保持默認的配置即可。詳細的配置說明可以參考MyBatis官方文檔setting

我們先看看一個settings 的簡單配置:
<settings><setting name="cacheEnabled" value="true"/><setting name="lazyLoadingEnabled" value="true"/><setting name="multipleResultSetsEnabled" value="true"/>
</settings>接下來我們來看看setting的解析源碼。
//* XMLConfigBuilder
private void settingsElement(XNode context) throws Exception {if (context != null) {// 獲取settings子節點中的內容Properties props = context.getChildrenAsProperties();// 創建Configuration類的"元信息"對象MetaClass metaConfig = MetaClass.forClass(Configuration.class);for (Object key : props.keySet()) {// Check that all settings are known to the configuration class// 通過metaConfig來檢查settings子節是否在Configuration類里都有相應的setter方法(其實就是檢查settings子標簽是否有拼寫錯誤)if (!metaConfig.hasSetter(String.valueOf(key))) {throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive).");}}}// 如果通過了上面的檢查,就將生成好的settings子節點對象返回,會在外部將其賦值給Configuration的settings成員屬性return props;
}
從上述源碼中我們可以總結出setting 的解析主要分為如下幾個步驟:
- 獲取settings 子節點中的內容,這段代碼在之前已經解釋過,再次不在贅述。
- 然后就是創建Configuration類的“元信息”對象,在這一部分中出現了一個陌生的類MetaClass,我們一會再分析。
- 接著檢查是否在Configuration類里都有相應的setter方法,不存在則拋出異常。
- 若通過MetaClass的檢測,則會將Properties對象返回,邏輯結束,會在外部將其中的信息設置到configuration對象中。
上述代碼看似簡單,不過這是一個假象。在上面的代碼中出現了一個陌生的類MetaClass,這個類是用來做什么的呢?它是用來解析目標類的一些元信息,比如類的成員變量,getter/setter 方法等。創建元信息對象的過程還是蠻復雜的。接下來我們就來看看MetaClass類。
2.3.2.1 元信息對象(MetaClass)創建過程源碼解析
元信息類MetaClass的構造方法為私有類型,所以不能直接創建,必須使用其提供的forClass方法進行創建。它的創建邏輯如下:
public class MetaClass {// 反射器工廠類private final ReflectorFactory reflectorFactory;// 反射器// 可以看到方法基本都是再次委派給這個Reflectorprivate final Reflector reflector;private MetaClass(Class<?> type, ReflectorFactory reflectorFactory) {this.reflectorFactory = reflectorFactory;// 根據類型創建 Reflectorthis.reflector = reflectorFactory.findForClass(type);}public static MetaClass forClass(Class<?> type, ReflectorFactory reflectorFactory) {// 調用構造方法return new MetaClass(type, reflectorFactory);}// 省略其他方法
}
上面的代碼看起來很簡單,不過這只是冰山一角。上面代碼出現了兩個新的類ReflectorFactory和Reflector,MetaClass 通過引入這些新類幫助它完成功能。下面我們看一下MetaClass類的hasSetter方法的源碼就知道是怎么回事了。
// -☆- MetaClass
public boolean hasSetter(String name) {// 屬性分詞器,用于解析屬性名PropertyTokenizer prop = new PropertyTokenizer(name);// hasNext 返回 true,則表明 name 是一個復合屬性,后面會進行分析if (prop.hasNext()) {// 調用 reflector 的 hasSetter 方法if (reflector.hasSetter(prop.getName())) {// 為屬性創建創建 MetaClassMetaClass metaProp = metaClassForProperty(prop.getName());// 再次調用 hasSetterreturn metaProp.hasSetter(prop.getChildren());} else {return false;}} else {// 調用 reflector 的 hasSetter 方法return reflector.hasSetter(prop.getName());}
}
從上面的代碼中,我們可以看出 MetaClass 中的 hasSetter 方法最終調用了 Reflector 的 hasSetter 方法。關于 Reflector 的 hasSetter 方法,這里先不分析,Reflector 這個類的邏輯較為復雜,本節會在隨后進行詳細說明。下面來簡單介紹一下上面代碼中出現的幾個類:
- ReflectorFactory -> 顧名思義,Reflector 的工廠類,兼有緩存 Reflector 對象的功能
- Reflector -> 反射器,用于解析和存儲目標類中的元信息
- PropertyTokenizer -> 屬性名分詞器,用于處理較為復雜的屬性名
上面的描述比較簡單,僅從上面的描述中,還不能讓大家有更深入的理解。所以下面單獨分析一下這幾個類的邏輯,首先是ReflectorFactory。ReflectorFactory 是一個接口,MyBatis 中目前只有一個實現類DefaultReflectorFactory,它的分析如下:
2.3.2.1.1 DefaultReflectorFactory 源碼分析
DefaultReflectorFactory 用于創建 Reflector,同時兼有緩存的功能,它的源碼如下。
public class DefaultReflectorFactory implements ReflectorFactory {private boolean classCacheEnabled = true;/** * 目標類和反射器映射緩存 * 用來快速通過類對象去找到對應的反射器*/private final ConcurrentMap<Class<?>, Reflector> reflectorMap = new ConcurrentHashMap<Class<?>, Reflector>();// 省略部分代碼public Reflector findForClass(Class<?> type) {// classCacheEnabled 默認為 trueif (classCacheEnabled) {// 從緩存中獲取 Reflector 對象Reflector cached = reflectorMap.get(type);// 緩存為空,則創建一個新的 Reflector 實例,并放入緩存中if (cached == null) {cached = new Reflector(type);// 將 <type, cached> 映射緩存到 map 中,方便下次取用reflectorMap.put(type, cached);}return cached;} else {// 創建一個新的 Reflector 實例return new Reflector(type);}}
}如上,DefaultReflectorFactory 的findForClass方法邏輯不是很復雜,包含兩個訪問操作,和一個對象創建操作。代碼注釋的比較清楚了,就不多說了。接下來,來分析一下反射器 Reflector。
?
2.3.2.1.2 Reflector 源碼分析
本小節,我們來看一下 Reflector 的源碼。Reflector 這個類的用途主要是是通過反射獲取目標類的 getter 方法及其返回值類型,setter 方法及其參數值類型等元信息。并將獲取到的元信息緩存到相應的集合中,供后續使用。Reflector 本身代碼比較多,這里不能一一分析。本小節,我將會分析三部分邏輯,分別如下:
- Reflector 構造方法及成員變量分析
- getter 方法解析過程
- setter 方法解析過程
下面我們按照這個步驟進行分析,先來分析 Reflector 構造方法。
● Reflector 構造方法及成員變量分析
Reflector 構造方法中包含了很多初始化邏輯,目標類的元信息解析過程也是在構造方法中完成的,這些元信息最終會被保存到 Reflector 的成員變量中。下面我們先來看看 Reflector 的構造方法和相關的成員變量定義,代碼如下:
public class Reflector {private final Class<?> type;private final String[] readablePropertyNames;private final String[] writeablePropertyNames;private final Map<String, Invoker> setMethods = new HashMap<String, Invoker>();private final Map<String, Invoker> getMethods = new HashMap<String, Invoker>();private final Map<String, Class<?>> setTypes = new HashMap<String, Class<?>>();private final Map<String, Class<?>> getTypes = new HashMap<String, Class<?>>();private Constructor<?> defaultConstructor;private Map<String, String> caseInsensitivePropertyMap = new HashMap<String, String>();public Reflector(Class<?> clazz) {type = clazz;// 解析目標類的默認構造方法,并賦值給 defaultConstructor 變量addDefaultConstructor(clazz);// 解析 getter 方法,并將解析結果放入 getMethods 中addGetMethods(clazz);// 解析 setter 方法,并將解析結果放入 setMethods 中addSetMethods(clazz);// 解析屬性字段,并將解析結果添加到 setMethods 或 getMethods 中addFields(clazz);// 從 getMethods 映射中獲取可讀屬性名數組readablePropertyNames = getMethods.keySet().toArray(new String[getMethods.keySet().size()]);// 從 setMethods 映射中獲取可寫屬性名數組writeablePropertyNames = setMethods.keySet().toArray(new String[setMethods.keySet().size()]);// 將所有屬性名的大寫形式作為鍵,屬性名作為值,存入到 caseInsensitivePropertyMap 中for (String propName : readablePropertyNames) {caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);}for (String propName : writeablePropertyNames) {caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);}}// 省略其他方法
}如上,Reflector 的構造方法看起來略為復雜,不過好在一些比較復雜的邏輯都封裝在了相應的方法中,這樣整體的邏輯就比較清晰了。Reflector 構造方法所做的事情均已進行了注釋,大家對照著注釋先看一下。相關方法的細節待會會進行分析。看完構造方法,下面我來通過表格的形式,列舉一下 Reflector 部分成員變量的用途。如下:
| 變量名 | 類型 | 用途 |
| readablePropertyNames | String[] | 可讀屬性名稱數組,用于保存 getter 方法對應的屬性名稱 |
| writeablePropertyNames | String[] | 可寫屬性名稱數組,用于保存 setter 方法對應的屬性名稱 |
| setMethods | Map<String, Invoker> | 用于保存屬性名稱到 Invoke 的映射。setter 方法會被封裝到?MethodInvoker 對象中,Invoke 實現類比較簡單,大家自行分析 |
| getMethods | Map<String, Invoker> | 用于保存屬性名稱到 Invoke 的映射。同上,getter 方法也會被封裝到 MethodInvoker 對象中 |
| setTypes | Map<String, Class<?>> | 用于保存 setter 對應的屬性名與參數類型的映射 |
| getTypes | Map<String, Class<?>> | 用于保存 getter 對應的屬性名與返回值類型的映射 |
| caseInsensitivePropertyMap | Map<String, String> | 用于保存大寫屬性名與屬性名之間的映射,比如 <NAME, name> |
上面列舉了一些集合變量,這些變量用于緩存各種元信息。關于這些變量,這里描述的不太好懂,主要是不太好解釋。要想了解這些變量更多的細節,還是要深入到源碼中。所以我們成熱打鐵,繼續往下分析。
● getter 方法解析過程
getter 方法解析的邏輯被封裝在了addGetMethods方法中,這個方法除了會解析形如getXXX的方法,同時也會解析isXXX方法。該方法的源碼分析如下:
private void addGetMethods(Class<?> cls) {Map<String, List<Method>> conflictingGetters = new HashMap<String, List<Method>>();// 獲取當前類、接口以及父類中的所有方法。該方法邏輯不是很復雜,這里就不展開了Method[] methods = getClassMethods(cls);for (Method method : methods) {// getter 方法不應該有參數,若存在參數,則忽略當前方法if (method.getParameterTypes().length > 0) {continue;}String name = method.getName();// 過濾出方法名以 get 或 is 開頭的方法if ((name.startsWith("get") && name.length() > 3)|| (name.startsWith("is") && name.length() > 2)) {// 將 getXXX 或 isXXX 等方法名轉成相應的屬性,比如 getName -> namename = PropertyNamer.methodToProperty(name);/** 將沖突的方法添加到 conflictingGetters 中。考慮這樣一種情況:* * getTitle 和 isTitle 兩個方法經過 methodToProperty 處理,* 均得到 name = title,這會導致沖突,我們不知道這兩個方法到底要解析哪個方法的信息存儲到getMethods和getTypes中。** 對于沖突的方法,這里先統一起存起來,后續再解決沖突,解決沖突就是在兩個沖突的方法中,選一個方法去解析*/addMethodConflict(conflictingGetters, name, method);}}// 解決 getter 沖突resolveGetterConflicts(conflictingGetters);
}
如上,addGetMethods 方法的執行流程如下:
- 獲取當前類,接口,以及父類中的方法
- 遍歷上一步獲取的方法數組,并過濾出以get和is開頭的方法
- 將方法名轉換成相應的屬性名
- 將屬性名和方法對象添加到沖突集合中
- 解決沖突
在上面的執行流程中,前三步比較簡單,大家自行分析吧。第4步也不復雜,下面我會把源碼貼出來,大家看一下就能懂。在這幾步中,第5步邏輯比較復雜,我們知道getter截取屬性沖突主要是由于 getXXX() 和isXXX() 兩種類型的方法,截取屬性后會沖突,這一步邏輯我們重點關注一下。下面繼續看源碼吧。
/** 添加屬性名和方法對象到沖突集合中 */
private void addMethodConflict(Map<String, List<Method>> conflictingMethods, String name, Method method) {List<Method> list = conflictingMethods.get(name);if (list == null) {list = new ArrayList<Method>();conflictingMethods.put(name, list);}list.add(method);
}/** 解決沖突 */
private void resolveGetterConflicts(Map<String, List<Method>> conflictingGetters) {for (Entry<String, List<Method>> entry : conflictingGetters.entrySet()) {Method winner = null;String propName = entry.getKey();for (Method candidate : entry.getValue()) {if (winner == null) {winner = candidate;continue;}// 獲取返回值類型Class<?> winnerType = winner.getReturnType();Class<?> candidateType = candidate.getReturnType();/* * 兩個方法的返回值類型一致,若兩個方法返回值類型均為 boolean,則選取 isXXX 方法* 為 winner。否則無法決定哪個方法更為合適,只能拋出異常*/if (candidateType.equals(winnerType)) {if (!boolean.class.equals(candidateType)) {throw new ReflectionException("Illegal overloaded getter method with ambiguous type for property "+ propName + " in class " + winner.getDeclaringClass()+ ". This breaks the JavaBeans specification and can cause unpredictable results.");/** 如果方法返回值類型為 boolean,且方法名以 "is" 開頭,* 則認為候選方法 candidate 更為合適*/} else if (candidate.getName().startsWith("is")) {winner = candidate;}/** winnerType 是 candidateType 的子類,類型上更為具體,* 則認為當前的 winner 仍是合適的,無需做什么事情*/} else if (candidateType.isAssignableFrom(winnerType)) {/** candidateType 是 winnerType 的子類,此時認為 candidate 方法更為合適,* 故將 winner 更新為 candidate*/} else if (winnerType.isAssignableFrom(candidateType)) {winner = candidate;} else {throw new ReflectionException("Illegal overloaded getter method with ambiguous type for property "+ propName + " in class " + winner.getDeclaringClass()+ ". This breaks the JavaBeans specification and can cause unpredictable results.");}}// 將篩選出的方法添加到 getMethods 中,并將方法返回值添加到 getTypes 中addGetMethod(propName, winner);}
}private void addGetMethod(String name, Method method) {if (isValidPropertyName(name)) {getMethods.put(name, new MethodInvoker(method));// 解析返回值類型Type returnType = TypeParameterResolver.resolveReturnType(method, type);// 將返回值類型由 Type 轉為 Class,并將轉換后的結果緩存到 setTypes 中getTypes.put(name, typeToClass(returnType));}
}
以上就是解除沖突的過程,代碼有點長,不太容易看懂。這里大家只要記住解決沖突的規則即可理解上面代碼的邏輯。相關規則如下:
- 沖突方法的返回值類型具有繼承關系,子類返回值對應的方法被認為是更合適的選擇
- 沖突方法的返回值類型相同,如果返回值類型為boolean,那么以is開頭的方法則是更合適的方法
- 沖突方法的返回值類型相同,但返回值類型非boolean,此時出現歧義,拋出異常
- 沖突方法的返回值類型不相關,無法確定哪個是更好的選擇,此時直接拋異常
分析完 getter 方法的解析過程,下面繼續分析 setter 方法的解析過程。
● setter 方法解析過程
與 getter 方法解析過程相比,setter 方法的解析過程與此有一定的區別。主要體現在沖突出現的原因,以及沖突的解決方法上。那下面,我們深入源碼來找出兩者之間的區別。
private void addSetMethods(Class<?> cls) {Map<String, List<Method>> conflictingSetters = new HashMap<String, List<Method>>();// 獲取當前類、接口以及父類中的所有方法。該方法邏輯不是很復雜,這里就不展開了Method[] methods = getClassMethods(cls);for (Method method : methods) {String name = method.getName();// 過濾出 setter 方法(方法名以set開頭),且方法僅有一個參數if (name.startsWith("set") && name.length() > 3) {if (method.getParameterTypes().length == 1) {name = PropertyNamer.methodToProperty(name);/** setter 方法發生沖突原因是:可能存在重載情況,比如:* void setSex(int sex);* void setSex(SexEnum sex);*/addMethodConflict(conflictingSetters, name, method);}}}// 解決 setter 沖突resolveSetterConflicts(conflictingSetters);
}
如上,與addGetMethods 方法的執行流程類似,addSetMethods方法的執行流程也分為如下幾個步驟:
- 獲取當前類,接口,以及父類中的方法
- 過濾出setter方法其方法之后一個參數
- 獲取方法對應的屬性名
- 將屬性名和其方法對象放入沖突集合中
- 解決setter沖突
前四步相對而言比較簡單,我在此處就不展開分析了,我們來重點分析下解決setter沖突的邏輯。
從上面的代碼和注釋中,我們可知道 setter 方法之間出現沖突的原因。即方法存在重載,方法重載導致methodToProperty方法解析出的屬性名完全一致。而 getter 方法之間出現沖突的原因是getXXX和isXXX對應的屬性名一致。既然沖突發生了,要進行調停,那接下來繼續來看看調停沖突的邏輯。
private void resolveSetterConflicts(Map<String, List<Method>> conflictingSetters) {for (String propName : conflictingSetters.keySet()) {List<Method> setters = conflictingSetters.get(propName);/** 獲取 getter 方法的返回值類型,由于 getter 方法不存在重載的情況,* 所以可以用它的返回值類型反推哪個 setter 的更為合適*/Class<?> getterType = getTypes.get(propName);Method match = null;ReflectionException exception = null;for (Method setter : setters) {// 獲取參數類型Class<?> paramType = setter.getParameterTypes()[0];if (paramType.equals(getterType)) {// 參數類型和返回類型一致,則認為是最好的選擇,并結束循環match = setter;break;}if (exception == null) {try {// 選擇一個更為合適的方法match = pickBetterSetter(match, setter, propName);} catch (ReflectionException e) {match = null;exception = e;}}}// 若 match 為空,表示沒找到更為合適的方法,此時拋出異常if (match == null) {throw exception;} else {// 將篩選出的方法放入 setMethods 中,并將方法參數值添加到 setTypes 中addSetMethod(propName, match);}}
}/** 從兩個 setter 方法中選擇一個更為合適方法 */
private Method pickBetterSetter(Method setter1, Method setter2, String property) {if (setter1 == null) {return setter2;}Class<?> paramType1 = setter1.getParameterTypes()[0];Class<?> paramType2 = setter2.getParameterTypes()[0];// 如果參數2可賦值給參數1,即參數2是參數1的子類,則認為參數2對應的 setter 方法更為合適if (paramType1.isAssignableFrom(paramType2)) {return setter2;// 這里和上面情況相反} else if (paramType2.isAssignableFrom(paramType1)) {return setter1;}// 兩種參數類型不相關,這里拋出異常throw new ReflectionException("Ambiguous setters defined for property '" + property + "' in class '"+ setter2.getDeclaringClass() + "' with types '" + paramType1.getName() + "' and '"+ paramType2.getName() + "'.");
}private void addSetMethod(String name, Method method) {if (isValidPropertyName(name)) {setMethods.put(name, new MethodInvoker(method));// 解析參數類型列表Type[] paramTypes = TypeParameterResolver.resolveParamTypes(method, type);// 將參數類型由 Type 轉為 Class,并將轉換后的結果緩存到 setTypessetTypes.put(name, typeToClass(paramTypes[0]));}
}關于 setter 方法沖突的解析規則,這里也總結一下吧。如下:
- 沖突方法的參數類型與 getter 的返回類型一致,則認為是最好的選擇
- 沖突方法的參數類型具有繼承關系,子類參數對應的方法被認為是更合適的選擇
- 沖突方法的參數類型不相關,無法確定哪個是更好的選擇,此時直接拋異常
到此關于 setter 方法的解析過程就說完了。我在前面說過 MetaClass 的hasSetter最終調用了 Refactor 的hasSetter方法,那么現在是時候分析 Refactor 的hasSetter方法了。代碼如下如下:
public boolean hasSetter(String propertyName) {return setMethods.keySet().contains(propertyName);
}代碼如上,就兩行,很簡單,就是判斷是否存在propertyName這個成員屬性的setter方法。
2.3.2.1.3 PropertyTokenizer 源碼分析
PropertyTokenizer類的主要作用是對復合屬性進行分解。
對于較為復雜的屬性,需要進行進一步解析才能使用。那什么樣的屬性是復雜屬性呢?來看個測試代碼就知道了。
public class MetaClassTest {private class Author {private Integer id;private String name;private Integer age;/** 一個作者對應多篇文章 */private Article[] articles;// 省略 getter/setter}private class Article {private Integer id;private String title;private String content;/** 一篇文章對應一個作者 */private Author author;// 省略 getter/setter}public void testHasSetter() {// 為 Author 創建元信息對象MetaClass authorMeta = MetaClass.forClass(Author.class, new DefaultReflectorFactory());System.out.println("------------☆ Author ☆------------");System.out.println("id -> " + authorMeta.hasSetter("id"));System.out.println("name -> " + authorMeta.hasSetter("name"));System.out.println("age -> " + authorMeta.hasSetter("age"));// 檢測 Author 中是否包含 Article[] 的 setterSystem.out.println("articles -> " + authorMeta.hasSetter("articles"));System.out.println("articles[] -> " + authorMeta.hasSetter("articles[]"));System.out.println("title -> " + authorMeta.hasSetter("title"));// 為 Article 創建元信息對象MetaClass articleMeta = MetaClass.forClass(Article.class, new DefaultReflectorFactory());System.out.println("\n------------☆ Article ☆------------");System.out.println("id -> " + articleMeta.hasSetter("id"));System.out.println("title -> " + articleMeta.hasSetter("title"));System.out.println("content -> " + articleMeta.hasSetter("content"));// 下面兩個均為復雜屬性,分別檢測 Article 類中的 Author 類是否包含 id 和 name 的 setter 方法System.out.println("author.id -> " + articleMeta.hasSetter("author.id"));System.out.println("author.name -> " + articleMeta.hasSetter("author.name"));}
}
如上,Article類中包含了一個Author引用。然后我們調用 articleMeta 的 hasSetter 檢測author.id和author.name屬性是否存在,我們的期望結果為 true。測試結果如下:
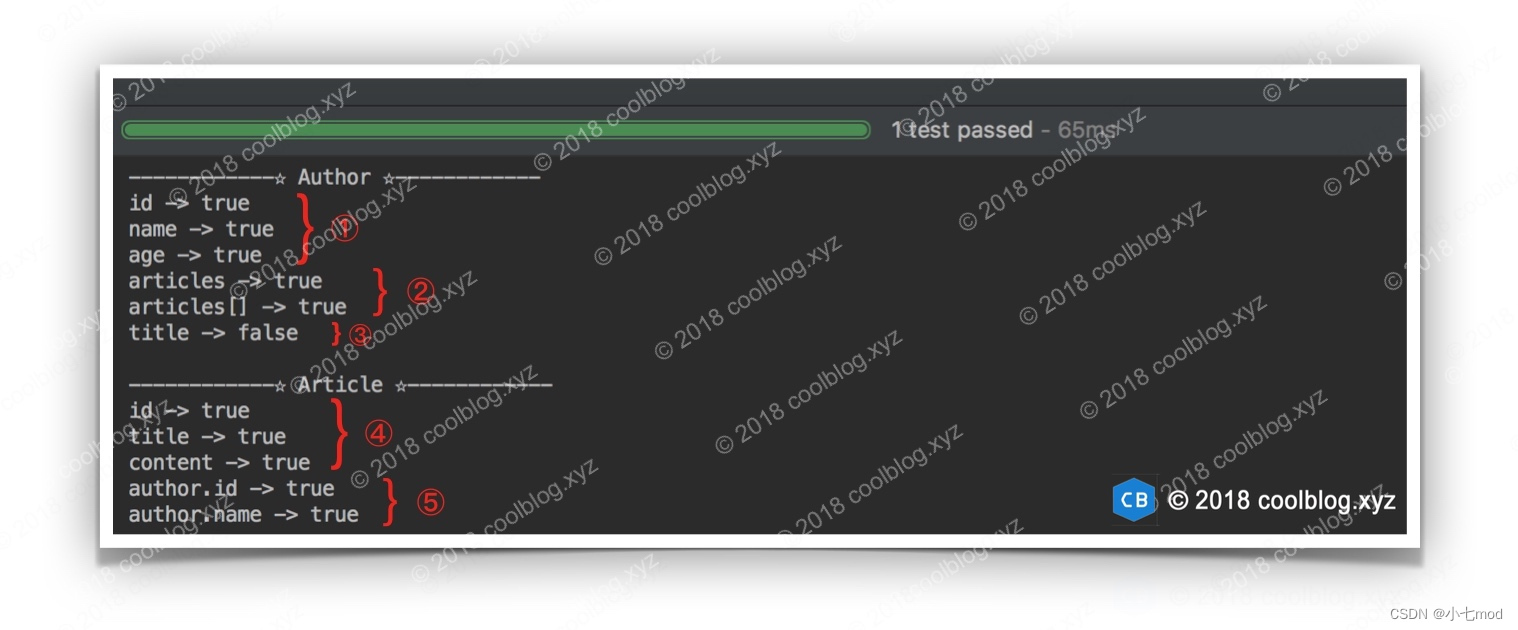
如上,標記⑤處的輸出均為 true,我們的預期達到了。標記②處檢測 Article 數組的是否存在 setter 方法,結果也均為 true。這說明 PropertyTokenizer 對數組和復合屬性均進行了處理。那它是如何處理的呢?答案如下:
public class PropertyTokenizer implements Iterator<PropertyTokenizer> {private String name;private final String indexedName;private String index;private final String children;public PropertyTokenizer(String fullname) {// 檢測傳入的參數中是否包含字符 '.'int delim = fullname.indexOf('.');if (delim > -1) {/** 以點位為界,進行分割。比如:* fullname = www.coolblog.xyz** 以第一個點為分界符:* name = www* children = coolblog.xyz*/ name = fullname.substring(0, delim);children = fullname.substring(delim + 1);} else {// fullname 中不存在字符 '.'name = fullname;children = null;}indexedName = name;// 檢測傳入的參數中是否包含字符 '['delim = name.indexOf('[');if (delim > -1) {/** 獲取中括號里的內容,比如:* 1. 對于數組或List集合:[] 中的內容為數組下標,* 比如 fullname = articles[1],index = 1* 2. 對于Map:[] 中的內容為鍵,* 比如 fullname = xxxMap[keyName],index = keyName** 關于 index 屬性的用法,可以參考 BaseWrapper 的 getCollectionValue 方法*/index = name.substring(delim + 1, name.length() - 1);// 獲取分解符前面的內容,比如 fullname = articles[1],name = articlesname = name.substring(0, delim);}}// 省略 getterpublic boolean hasNext() {return children != null;}public PropertyTokenizer next() {// 對 children 進行再次切分,用于解析多重復合屬性return new PropertyTokenizer(children);}// 省略部分方法
}
以上是 PropertyTokenizer 的源碼分析,注釋的比較多,應該分析清楚了。
PropertyTokenizer類的核心邏輯就在其構造器中,主要包括三部分邏輯:
- 根據 ‘.’,如果不能找到則取全部部分
- 能找到的話則首先截取 ’ .’ 符號之前的部分,把其余部分作為children。 然后通過MetaClass類的getGetterType的方法來循環提取。
2.3.2.2 小結
本節的篇幅比較大,大家看起來應該蠻辛苦的。本節為了分析 MetaClass 的 hasSetter 方法,把這個方法涉及到的源碼均分析了一遍。其實,如果想簡單點分析,我可以直接把 MetaClass 當成一個黑盒,然后用一句話告訴大家 hasSetter 方法有什么用即可。但是這樣做我覺的文章太虛,沒什么深度。關于 MetaClass 及相關源碼大家第一次看可能會有點吃力,看不懂可以先放一放。后面多看幾遍,動手寫點測試代碼調試一下,可以幫助理解。
好了,關于 setting 節點的解析過程就先分析到這里,我們繼續往下分析。
2.3.3 設置 settings 配置到 Configuration 中
上一節講了 settings 配置的解析過程,這些配置解析出來要有一個存放的地方,以使其他代碼可以找到這些配置。這個存放地方就是 Configuration 對象,本節就來看一下這將 settings 配置設置到 Configuration 對象中的過程。如下:
private void settingsElement(Properties props) throws Exception {// 設置 autoMappingBehavior 屬性,默認值為 PARTIALconfiguration.setAutoMappingBehavior(AutoMappingBehavior.valueOf(props.getProperty("autoMappingBehavior", "PARTIAL")));configuration.setAutoMappingUnknownColumnBehavior(AutoMappingUnknownColumnBehavior.valueOf(props.getProperty("autoMappingUnknownColumnBehavior", "NONE")));// 設置 cacheEnabled 屬性,默認值為 trueconfiguration.setCacheEnabled(booleanValueOf(props.getProperty("cacheEnabled"), true));// 省略部分代碼// 解析默認的枚舉處理器Class<? extends TypeHandler> typeHandler = (Class<? extends TypeHandler>)resolveClass(props.getProperty("defaultEnumTypeHandler"));// 設置默認枚舉處理器configuration.setDefaultEnumTypeHandler(typeHandler);configuration.setCallSettersOnNulls(booleanValueOf(props.getProperty("callSettersOnNulls"), false));configuration.setUseActualParamName(booleanValueOf(props.getProperty("useActualParamName"), true));// 省略部分代碼
}
上面代碼處理調用了很多 Configuration 的 setter 方法,就沒太多邏輯了。這里來看一下上面出現的一個調用resolveClass,它的源碼如下:
// -☆- BaseBuilder類
protected Class<?> resolveClass(String alias) {if (alias == null) {return null;}try {// 通過別名解析return resolveAlias(alias);} catch (Exception e) {throw new BuilderException("Error resolving class. Cause: " + e, e);}
}
protected final TypeAliasRegistry typeAliasRegistry;
protected Class<?> resolveAlias(String alias) {// 通過別名注冊器解析別名對于的類型 Classreturn typeAliasRegistry.resolveAlias(alias);
}
這里出現了一個新的類TypeAliasRegistry,大家對于它可能會覺得陌生,但是對于typeAlias應該不會陌生。TypeAliasRegistry 的用途就是將別名和類型進行映射,這樣就可以用別名表示某個類了,方便使用。既然聊到了別名,那下面我們不妨看看別名的配置的解析過程。
2.3.4 解析 typeAliases 配置
在 MyBatis 中,可以為我們自己寫的有些類定義一個別名。這樣在使用的時候,我們只需要輸入別名即可,無需再把全限定的類名寫出來。
該配置主要是減少在映射文件中填寫全限定名的冗余。
在 MyBatis 中,我們有兩種方式進行別名配置。第一種是僅配置包名,讓 MyBatis 去掃描包中的類型,并根據類型得到相應的別名。這種方式可配合 @Alias 注解使用,即通過注解為某個類配置別名,而不是讓 MyBatis 按照默認規則生成別名。這種方式的配置如下:
<typeAliases><package name="xyz.coolblog.model1"/><package name="xyz.coolblog.model2"/>
</typeAliases>第二種方式是通過手動的方式,明確為某個類型配置別名。這種方式的配置如下:
<typeAliases><typeAlias alias="article" type="xyz.coolblog.model.Article" /><typeAlias type="xyz.coolblog.model.Author" />
</typeAliases>對比這兩種方式,第一種自動掃描的方式配置起來比較簡單,缺點也不明顯。唯一能想到缺點可能就是 MyBatis 會將某個包下所有符合要求的類的別名都解析出來,并形成映射關系。如果你不想讓某些類被掃描,這個好像做不到,沒發現 MyBatis 提供了相關的排除機制。不過我覺得這并不是什么大問題,最多是多解析并緩存了一些別名到類型的映射,在時間和空間上產生了一些額外的消耗而已。當然,如果無法忍受這些消耗,可以使用第二種配置方式,通過手工的方式精確配置某些類型的別名。不過這種方式比較繁瑣,特別是配置項比較多時。至于兩種方式怎么選擇,這個看具體的情況了。配置項非常少時,兩種皆可。比較多的話,還是讓 MyBatis 自行掃描吧。
以上介紹了兩種不同的別名配置方式,下面我們來看一下兩種不同的別名配置是怎樣解析的。代碼如下:
// -☆- XMLConfigBuilder類
private void typeAliasesElement(XNode parent) {if (parent != null) {for (XNode child : parent.getChildren()) {// ?? 從指定的包中解析別名和類型的映射if ("package".equals(child.getName())) {String typeAliasPackage = child.getStringAttribute("name");configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage);// ?? 從 typeAlias 節點中解析別名和類型的映射} else {// 獲取 alias 和 type 屬性值,alias 不是必填項,可為空String alias = child.getStringAttribute("alias");String type = child.getStringAttribute("type");try {// 加載 type 對應的類型Class<?> clazz = Resources.classForName(type);// 注冊別名到類型的映射if (alias == null) {typeAliasRegistry.registerAlias(clazz);} else {typeAliasRegistry.registerAlias(alias, clazz);}} catch (ClassNotFoundException e) {throw new BuilderException("Error registering typeAlias for '" + alias + "'. Cause: " + e, e);}}}}
}如上,上面的代碼通過一個if-else條件分支來處理兩種不同的配置,這里我用??標注了出來。該入口程序方法執行流程如下:
- 根據節點名稱判斷是否是package,如果是的話則調用TypeAliasRegistry.registerAliases,去包下找所有類,然后注冊別名(有@Alias注解則用,沒有則取類的simpleName)
- 如果不是的話,則進入另外一個分支,則根據Class名字來注冊類型別名。
下面我們來分別看一下這兩種配置方式的解析過程,首先來看一下手動配置方式的解析過程。
2.3.4.1 從 typeAlias 節點中解析并注冊別名
在別名的配置中,type屬性是必須要配置的,而alias屬性則不是必須的。這個在配置文件的 DTD 中有規定。如果使用者未配置 alias 屬性,則需要 MyBatis 自行為目標類型生成別名。對于別名為空的情況,注冊別名的任務交由void registerAlias(Class<?>)方法處理。若不為空,則由void registerAlias(String, Class<?>)進行別名注冊。這兩個方法的分析如下:
// 別名映射 別名 -> 類對象
private final Map<String, Class<?>> TYPE_ALIASES = new HashMap<String, Class<?>>();// 沒有自己設置別名
public void registerAlias(Class<?> type) {// 獲取全路徑類名的簡稱String alias = type.getSimpleName();Alias aliasAnnotation = type.getAnnotation(Alias.class);// 如果這個類使用了@Alias注解,就用注解上設定的值作為別名if (aliasAnnotation != null) {// 從注解中取出別名alias = aliasAnnotation.value();}// 調用重載方法注冊別名和類型映射registerAlias(alias, type);
}// 自己設置了別名
public void registerAlias(String alias, Class<?> value) {if (alias == null) {throw new TypeException("The parameter alias cannot be null");}// 將別名轉成小寫String key = alias.toLowerCase(Locale.ENGLISH);/** 如果 TYPE_ALIASES 中存在了某個類型映射,這里判斷當前類型與映射中的類型是否一致,* 不一致則拋出異常,不允許一個別名對應兩種類型*/if (TYPE_ALIASES.containsKey(key) && TYPE_ALIASES.get(key) != null && !TYPE_ALIASES.get(key).equals(value)) {throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + TYPE_ALIASES.get(key).getName() + "'.");}// 緩存別名到類型映射TYPE_ALIASES.put(key, value);
}
如上,若用戶為明確配置 alias 屬性,MyBatis 會使用類名的小寫形式作為別名。比如,全限定類名xyz.coolblog.model.Author的別名為author。若類中有@Alias注解,則從注解中取值作為別名。
上面的代碼不是很復雜,注釋的也比較清楚了,就不多說了。繼續往下看。
2.3.4.2 從指定的包中解析并注冊別名
從指定的包中解析并注冊別名過程主要由別名的解析和注冊兩步組成。下面來看一下相關代碼:
public void registerAliases(String packageName) {// 調用重載方法注冊別名registerAliases(packageName, Object.class);
}public void registerAliases(String packageName, Class<?> superType) {ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<Class<?>>();/** 查找某個包下的父類為 superType 的類。從調用棧來看,這里的 * superType = Object.class,所以 ResolverUtil 將查找所有的類。* 查找完成后,查找結果將會被緩存到內部集合中。*/ resolverUtil.find(new ResolverUtil.IsA(superType), packageName);// 獲取查找結果Set<Class<? extends Class<?>>> typeSet = resolverUtil.getClasses();for (Class<?> type : typeSet) {// 忽略匿名類,接口,內部類if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {// 為類型注冊別名 registerAlias(type);}}
}
上面的代碼不多,相關流程也不復雜,可簡單總結為下面兩個步驟:
- 通過ResolverUtil的find方法找到該包下所有的類,傳入的父類是Object
- 循環注冊別名,只有非匿名類及非接口及內部類及非成員類才能注冊。注冊別名最終還是調用registerAlias(alias, type)完成的。
在這兩步流程中,第2步流程對應的代碼上一節已經分析過了,這里不再贅述。第1步的功能理解起來不難,但是背后對應的代碼有點多。限于篇幅原因,這里簡單說一下ResolverUtil查找包下的所有類的源碼:
// 主要的方法,找一個package下滿足條件的所有類,被TypeHanderRegistry,MapperRegistry,TypeAliasRegistry調用
public ResolverUtil<T> find(Test test, String packageName) {String path = getPackagePath(packageName);try {// 通過VFS來深入jar包里面去找一個classList<String> children = VFS.getInstance().list(path);for (String child : children) {if (child.endsWith(".class")) {// 將.class的class對象放入Set集合中,供后面調用addIfMatching(test, child);}}} catch (IOException ioe) {log.error("Could not read package: " + packageName, ioe);}return this;
}
簡單的流程總結。如下:
- 通過 VFS(虛擬文件系統)獲取指定包下的所有文件的路徑名,
比如xyz/coolblog/model/Article.class - 篩選以.class結尾的文件名
- 將路徑名轉成全限定的類名,通過類加載器加載類名
- 對類型進行匹配,若符合匹配規則,則將其放入內部集合中
以上就是類型資源查找的過程,并不是很復雜,大家有興趣自己看看吧。
2.3.4.3 注冊 MyBatis 內部類及常見類型的別名
最后,我們來看一下一些 MyBatis 內部類及一些常見類型的別名注冊過程。如下:
// -☆- Configuration構造方法
public Configuration() {// 注冊事務工廠的別名typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);// 省略部分代碼,下同// 注冊數據源的別名typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class);// 注冊緩存策略的別名typeAliasRegistry.registerAlias("FIFO", FifoCache.class);typeAliasRegistry.registerAlias("LRU", LruCache.class);// 注冊日志類的別名typeAliasRegistry.registerAlias("SLF4J", Slf4jImpl.class);typeAliasRegistry.registerAlias("LOG4J", Log4jImpl.class);// 注冊動態代理工廠的別名typeAliasRegistry.registerAlias("CGLIB", CglibProxyFactory.class);typeAliasRegistry.registerAlias("JAVASSIST", JavassistProxyFactory.class);
}// -☆- TypeAliasRegistry構造方法
public TypeAliasRegistry() {// 注冊 String 的別名registerAlias("string", String.class);// 注冊基本類型包裝類的別名registerAlias("byte", Byte.class);// 省略部分代碼,下同// 注冊基本類型包裝類數組的別名registerAlias("byte[]", Byte[].class);// 注冊基本類型的別名registerAlias("_byte", byte.class);// 注冊基本類型包裝類的別名registerAlias("_byte[]", byte[].class);// 注冊 Date, BigDecimal, Object 等類型的別名registerAlias("date", Date.class);registerAlias("decimal", BigDecimal.class);registerAlias("object", Object.class);// 注冊 Date, BigDecimal, Object 等數組類型的別名registerAlias("date[]", Date[].class);registerAlias("decimal[]", BigDecimal[].class);registerAlias("object[]", Object[].class);// 注冊集合類型的別名registerAlias("map", Map.class);registerAlias("hashmap", HashMap.class);registerAlias("list", List.class);registerAlias("arraylist", ArrayList.class);registerAlias("collection", Collection.class);registerAlias("iterator", Iterator.class);// 注冊 ResultSet 的別名registerAlias("ResultSet", ResultSet.class);
}
以上就是別名解析的全部流程。
2.3.5 解析 plugins 配置
插件是 MyBatis 提供的一個拓展機制,通過插件機制我們可在 SQL 執行過程中的某些點上做一些自定義操作。實現一個插件需要比簡單,首先需要讓插件類實現Interceptor接口。然后在插件類上添加@Intercepts和@Signature注解,用于指定想要攔截的目標方法。MyBatis 允許攔截下面接口中的一些方法:
- Executor: update 方法,query 方法,flushStatements 方法,commit 方法,rollback 方法, getTransaction 方法,close 方法,isClosed 方法
- ParameterHandler: getParameterObject 方法,setParameters 方法
- ResultSetHandler: handleResultSets 方法,handleOutputParameters 方法
- StatementHandler: prepare 方法,parameterize 方法,batch 方法,update 方法,query 方法
比較常見的插件有分頁插件、分表插件等,有興趣的朋友可以去了解下。本節我們來分析一下插件的配置的解析過程,先來了解插件的配置。如下:
<plugins><plugin interceptor="xyz.coolblog.mybatis.ExamplePlugin"><property name="key" value="value"/></plugin>
</plugins>?
解析過程分析如下:
private void pluginElement(XNode parent) throws Exception {if (parent != null) {for (XNode child : parent.getChildren()) {String interceptor = child.getStringAttribute("interceptor");// 獲取配置信息Properties properties = child.getChildrenAsProperties();// 解析攔截器的類型,并創建攔截器Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).newInstance();// 設置屬性interceptorInstance.setProperties(properties);// 添加攔截器到 Configuration 中configuration.addInterceptor(interceptorInstance);}}
}?如上,插件解析的過程還是比較簡單的。首先是獲取配置,然后再解析攔截器類型,并實例化攔截器。最后向攔截器中設置屬性,并將攔截器添加到 Configuration 中。好了,關于插件配置的分析就先到這,繼續往下分析。
2.3.6 解析 environments 配置
在 MyBatis 中,事務管理器和數據源是配置在 environments 中的。它們的配置大致如下:
<!-- 設置一個默認的連接環境信息 -->
<environments default="development"><!--連接環境信息,取一個任意唯一的名字 --><environment id="development"><!-- mybatis使用jdbc事務管理方式 --><transactionManager type="JDBC"><property name="..." value="..."/></transactionManager><!-- mybatis使用連接池方式來獲取數據源連接 --><dataSource type="POOLED"><!-- 配置數據源的4個必要屬性 --><property name="driver" value="${driver}"/><property name="url" value="${url}"/><property name="username" value="${username}"/><property name="password" value="${password}"/></dataSource></environment>
</environments>
如上,配置了連接環境信息,我們心中肯定會有個疑問,${} 這種參數是如何解析的?我一會再分析。
下面我們就來看看這個配置的解析過程。
對照上面的配置進行分析,如下:
private String environment;
private void environmentsElement(XNode context) throws Exception {if (context != null) {if (environment == null) {// 獲取 default 屬性environment = context.getStringAttribute("default");}// 循環比較id是否就是指定的environmentfor (XNode child : context.getChildren()) {// 獲取 id 屬性String id = child.getStringAttribute("id");/** 檢測當前 environment 節點的 id 與其父節點 environments 的屬性 default * 內容是否一致,一致則返回 true,否則返回 false*/if (isSpecifiedEnvironment(id)) {// 1、解析 transactionManager 節點,創建事務工廠TransactionFactory。邏輯和插件的解析邏輯很相似,不在贅述TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));// 2、解析 dataSource 節點,創建數據源。邏輯和插件的解析邏輯很相似,不在贅述DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));// 3、創建 DataSource 對象DataSource dataSource = dsFactory.getDataSource();Environment.Builder environmentBuilder = new Environment.Builder(id).transactionFactory(txFactory).dataSource(dataSource);// 構建 Environment 對象,并設置到 configuration 中configuration.setEnvironment(environmentBuilder.build());}}}
}
如上,解析environments 的流程有三個:
- 創建事務工廠TransactionFactory
- 創建數據源
- 創建Environment對象
我們看看第一步和第二步的代碼。
//* XMLConfigBuilder
private TransactionFactory transactionManagerElement(XNode context) throws Exception {if (context != null) {String type = context.getStringAttribute("type");Properties props = context.getChildrenAsProperties();// 根據type="JDBC"解析返回適當的TransactionFactoryTransactionFactory factory = (TransactionFactory) resolveClass(type).newInstance();factory.setProperties(props);return factory;}throw new BuilderException("Environment declaration requires a TransactionFactory.");
}protected Class<?> resolveClass(String alias) {if (alias == null) {return null;}try {return resolveAlias(alias);} catch (Exception e) {throw new BuilderException("Error resolving class. Cause: " + e, e);}
}
//*Configuration
typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
JDBC 通過別名解析器解析之后會得到JdbcTransactionFactory工廠實例。
數據源的解析與此類似最終得到的是PooledDataSourceFactory工廠實例,這里就不再贅述解析數據源的源碼了。
下面我們來看看之前說過的類似${driver}的解析。其實是通過PropertyParser的parse來處理的。下面我們來看個時序圖。
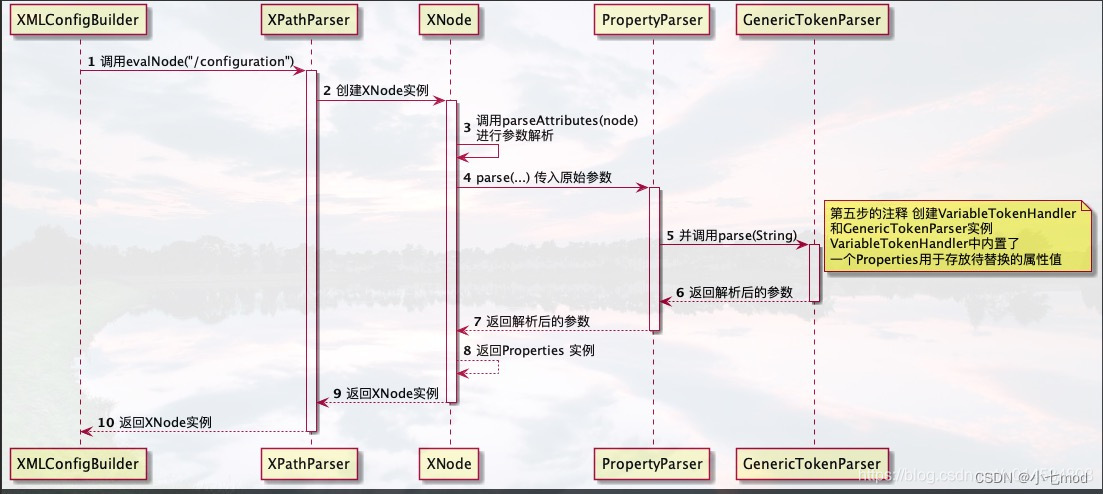
這里最核心的就是第五步,我們來看看源碼
public static String parse(String string, Properties variables) {VariableTokenHandler handler = new VariableTokenHandler(variables);GenericTokenParser parser = new GenericTokenParser("${", "}", handler);return parser.parse(string);
}
// 就是一個map,用相應的value替換key
private static class VariableTokenHandler implements TokenHandler {private Properties variables;public VariableTokenHandler(Properties variables) {this.variables = variables;}@Overridepublic String handleToken(String content) {if (variables != null && variables.containsKey(content)) {return variables.getProperty(content);}return "${" + content + "}";}
}
如上,在VariableTokenHandler 會將${driver} 作為key,其需要被替換的值作為value。傳入GenericTokenParser中。然后通過GenericTokenParser 類的parse進行替換。
至此,我們environments配置就解析完了。
2.3.7 解析 typeHandlers 配置
在向數據庫存儲或讀取數據時,我們需要將數據庫字段類型和 Java 類型進行一個轉換。比如數據庫中有CHAR和VARCHAR等類型,但 Java 中沒有這些類型,不過 Java 有String類型。所以我們在從數據庫中讀取 CHAR 和 VARCHAR 類型的數據時,就可以把它們轉成 String 。在 MyBatis 中,數據庫類型和 Java 類型之間的轉換任務是委托給類型處理器TypeHandler去處理的。MyBatis 提供了一些常見類型的類型處理器,除此之外,我們還可以自定義類型處理器以非常見類型轉換的需求。這里我就不演示自定義類型處理器的編寫方法了,沒用過或者不熟悉的同學可以?MyBatis 官方文檔,或者看這一篇MyBatis自定義通用類型處理器的實現與自動注冊文章中寫的示例。
下面,我們來看一下類型處理器的配置方法:
<!-- 自動掃描 -->
<typeHandlers><package name="xyz.coolblog.handlers"/>
</typeHandlers><!-- 手動配置 -->
<typeHandlers><typeHandler jdbcType="TINYINT"javaType="xyz.coolblog.constant.ArticleTypeEnum"handler="xyz.coolblog.mybatis.ArticleTypeHandler"/>
</typeHandlers>使用自動掃描的方式注冊類型處理器時,應使用@MappedTypes和@MappedJdbcTypes注解配置javaType和jdbcType。關于注解,這里就不演示了,比較簡單,大家自行嘗試。下面開始分析代碼。
private void typeHandlerElement(XNode parent) throws Exception {if (parent != null) {for (XNode child : parent.getChildren()) {// 從指定的包中注冊 TypeHandlerif ("package".equals(child.getName())) {String typeHandlerPackage = child.getStringAttribute("name");// 注冊方法 ①typeHandlerRegistry.register(typeHandlerPackage);// 從 typeHandler 節點中解析別名到類型的映射} else {// 獲取 javaType,jdbcType 和 handler 等屬性值String javaTypeName = child.getStringAttribute("javaType");String jdbcTypeName = child.getStringAttribute("jdbcType");String handlerTypeName = child.getStringAttribute("handler");// 解析上面獲取到的屬性值Class<?> javaTypeClass = resolveClass(javaTypeName);JdbcType jdbcType = resolveJdbcType(jdbcTypeName);Class<?> typeHandlerClass = resolveClass(handlerTypeName);// 根據 javaTypeClass 和 jdbcType 值的情況進行不同的注冊策略if (javaTypeClass != null) {if (jdbcType == null) {// 注冊方法 ②typeHandlerRegistry.register(javaTypeClass, typeHandlerClass);} else {// 注冊方法 ③typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass);}} else {// 注冊方法 ④typeHandlerRegistry.register(typeHandlerClass);}}}}
}
上面代碼中用于解析 XML 部分的代碼比較簡單,沒什么需要特別說明的。除此之外,上面的代碼中調用了4個不同的類型處理器注冊方法。這些注冊方法的邏輯不難理解,但是重載方法很多,上面調用的注冊方法只是重載方法的一部分。由于重載太多且重載方法之間互相調用,導致這一塊的代碼有點凌亂。我一開始在整理這部分代碼時,也很抓狂。后來沒轍了,把重載方法的調用圖畫了出來,才理清了代碼。一圖勝千言,看圖吧。
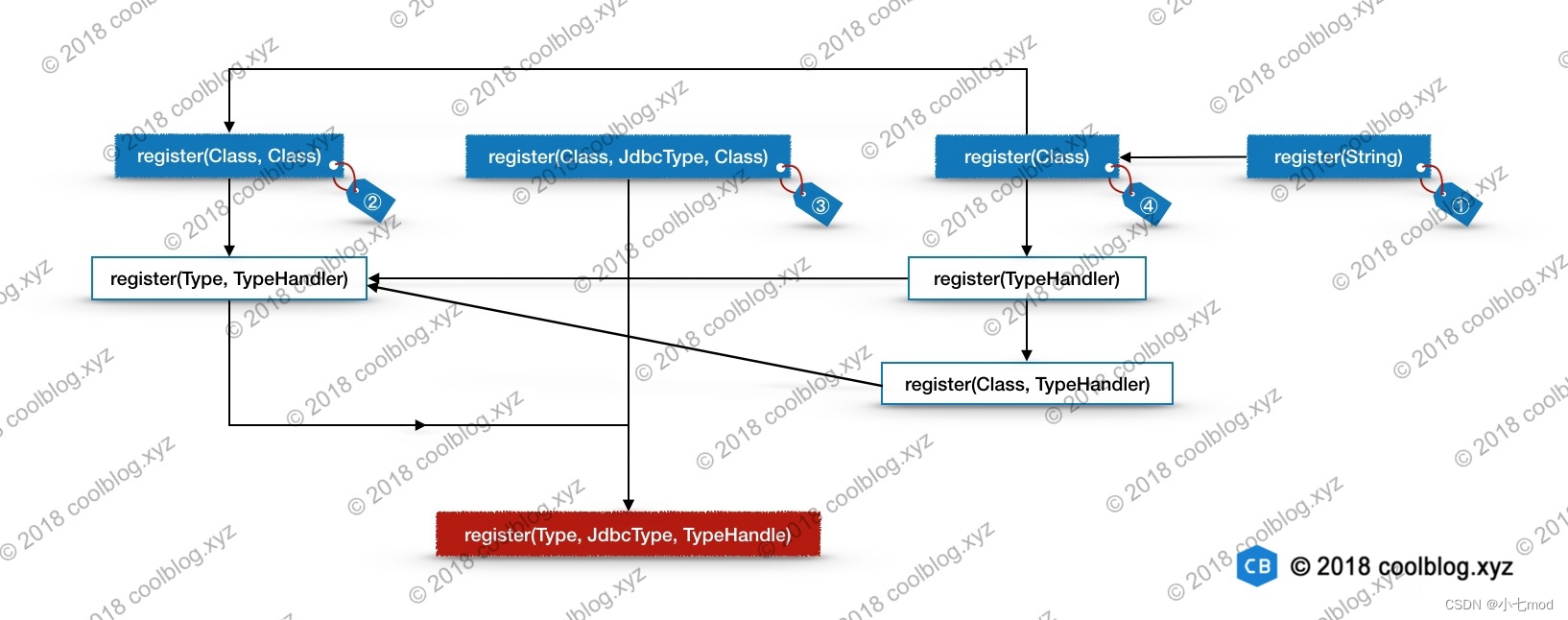
在上面的調用圖中,每個藍色背景框下都有一個標簽。每個標簽上面都已一個編號,這些編號與上面代碼中的標簽是一致的。這里我把藍色背景框內的方法稱為開始方法,紅色背景框內的方法稱為終點方法,白色背景框內的方法稱為中間方法,這些方法都是TypeHandlerRegistry類的方法。下面我會分析從每個開始方法向下分析,為了避免冗余分析,我會按照③ → ② → ④ → ①的順序進行分析。大家在閱讀代碼分析時,可以參照上面的圖片,輔助理解。好了,下面開始進行分析。
2.3.7.1 register(Class, JdbcType, Class) 方法分析
當代碼執行到此方法時,表示javaTypeClass != null && jdbcType != null條件成立,即使用者明確配置了javaType和jdbcType屬性的值。那下面我們來看一下該方法的分析。
public void register(Class<?> javaTypeClass, JdbcType jdbcType, Class<?> typeHandlerClass) {// 調用終點方法register(javaTypeClass, jdbcType, getInstance(javaTypeClass, typeHandlerClass));
}/** 類型處理器注冊過程的終點 */
private void register(Type javaType, JdbcType jdbcType, TypeHandler<?> handler) {if (javaType != null) {// 建立JdbcType 到 TypeHandler 的映射Map<JdbcType, TypeHandler<?>> map = TYPE_HANDLER_MAP.get(javaType);if (map == null || map == NULL_TYPE_HANDLER_MAP) {map = new HashMap<JdbcType, TypeHandler<?>>();// 存儲 javaType 到 Map<JdbcType, TypeHandler> 的映射TYPE_HANDLER_MAP.put(javaType, map);}map.put(jdbcType, handler);}// 存儲所有的 TypeHandlerALL_TYPE_HANDLERS_MAP.put(handler.getClass(), handler);
}
上面的代碼只有兩層調用,比較簡單。同時,所謂的注冊過程也就是把類型和處理器進行映射而已,沒什么特別之處。關于這個方法就先分析到這里,繼續往下分析。下面的方法對應注冊方法②。
2.3.7.2 register(Class, Class) 方法分析
當代碼執行到此方法時,表示javaTypeClass != null && jdbcType == null條件成立,即使用者僅設置了javaType屬性的值。下面我們來看一下該方法的分析。
public void register(Class<?> javaTypeClass, Class<?> typeHandlerClass) {// 調用中間方法 register(Type, TypeHandler)register(javaTypeClass, getInstance(javaTypeClass, typeHandlerClass));
}private <T> void register(Type javaType, TypeHandler<? extends T> typeHandler) {// 獲取 @MappedJdbcTypes 注解MappedJdbcTypes mappedJdbcTypes = typeHandler.getClass().getAnnotation(MappedJdbcTypes.class);if (mappedJdbcTypes != null) {// 遍歷 @MappedJdbcTypes 注解中配置的值for (JdbcType handledJdbcType : mappedJdbcTypes.value()) {// 調用終點方法,參考上一小節的分析register(javaType, handledJdbcType, typeHandler);}if (mappedJdbcTypes.includeNullJdbcType()) {// 調用終點方法,jdbcType = nullregister(javaType, null, typeHandler);}} else {// 調用終點方法,jdbcType = nullregister(javaType, null, typeHandler);}
}上面的代碼包含三層調用,其中終點方法的邏輯上一節已經分析過,這里不再贅述。上面的邏輯也比較簡單,主要做的事情是嘗試從注解中獲取JdbcType的值。這個方法就分析這么多,下面分析注冊方法④。
2.3.7.3 register(Class) 方法分析
當代碼執行到此方法時,表示javaTypeClass == null && jdbcType == null條件成立,即使用者未配置javaType和jdbcType屬性的值。該方法的分析如下。
public void register(Class<?> typeHandlerClass) {boolean mappedTypeFound = false;// 獲取 @MappedTypes 注解MappedTypes mappedTypes = typeHandlerClass.getAnnotation(MappedTypes.class);if (mappedTypes != null) {// 遍歷 @MappedTypes 注解中配置的值for (Class<?> javaTypeClass : mappedTypes.value()) {// 調用注冊方法 ②register(javaTypeClass, typeHandlerClass);mappedTypeFound = true;}}if (!mappedTypeFound) {// 調用中間方法 register(TypeHandler)register(getInstance(null, typeHandlerClass));}
}public <T> void register(TypeHandler<T> typeHandler) {boolean mappedTypeFound = false;// 獲取 @MappedTypes 注解MappedTypes mappedTypes = typeHandler.getClass().getAnnotation(MappedTypes.class);if (mappedTypes != null) {for (Class<?> handledType : mappedTypes.value()) {// 調用中間方法 register(Type, TypeHandler)register(handledType, typeHandler);mappedTypeFound = true;}}// 自動發現映射類型if (!mappedTypeFound && typeHandler instanceof TypeReference) {try {TypeReference<T> typeReference = (TypeReference<T>) typeHandler;// 獲取參數模板中的參數類型,并調用中間方法 register(Type, TypeHandler)register(typeReference.getRawType(), typeHandler);mappedTypeFound = true;} catch (Throwable t) {}}if (!mappedTypeFound) {// 調用中間方法 register(Class, TypeHandler)register((Class<T>) null, typeHandler);}
}public <T> void register(Class<T> javaType, TypeHandler<? extends T> typeHandler) {// 調用中間方法 register(Type, TypeHandler)register((Type) javaType, typeHandler);
}
上面的代碼比較多,不過不用太擔心。不管是通過注解的方式,還是通過反射的方式,它們最終目的是為了解析出javaType的值。解析完成后,這些方法會調用中間方法register(Type, TypeHandler),這個方法負責解析jdbcType,該方法上一節已經分析過。一個負責解析 javaType,另一個負責解析 jdbcType,邏輯比較清晰了。那我們趁熱打鐵,繼續分析下一個注冊方法,編號為①。
2.3.7.4 register(String) 方法分析
本節代碼的主要是用于自動掃描類型處理器,并調用其他方法注冊掃描結果。該方法的分析如下:
public void register(String packageName) {ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<Class<?>>();// 從指定包中查找 TypeHandlerresolverUtil.find(new ResolverUtil.IsA(TypeHandler.class), packageName);Set<Class<? extends Class<?>>> handlerSet = resolverUtil.getClasses();for (Class<?> type : handlerSet) {// 忽略內部類,接口,抽象類等if (!type.isAnonymousClass() && !type.isInterface() && !Modifier.isAbstract(type.getModifiers())) {// 調用注冊方法 ④register(type);}}
}
上面代碼的邏輯比較簡單,其中注冊方法④已經在上一節分析過了,這里就不多說了。
2.3.7.5 小結
類型處理器的解析過程不復雜,但是注冊過程由于重載方法間相互調用,導致調用路線比較復雜。這個時候需要想辦法理清方法的調用路線,理清后,整個邏輯就清晰明了了。好了,關于類型處理器的解析過程就先分析到這。
2.3.8 解析 mappers 配置
前面分析的都是 MyBatis 的一些配置,本節的內容原本是打算分析 mappers 節點的解析過程。但由于本文的篇幅已經很大了,加之 mappers 節點的過程也比較復雜,而且非常重要(可以說是這些解析步驟中最重要的一個)。所以,關于本節的內容,會在后面的文章中單獨講解。
2.4 創建SqlSessionFactory對象
到這里,配置文件mybatis-config.xml和我們定義映射文件XxxMapper.xml就全部解析完成。
再回到SqlSessionFactoryBuilder類,前面講到了XMLConfigBuilder中的parse方法,并返回了一個Configuration對象。
//* SqlSessionFactoryBuilder類
public SqlSessionFactory build(InputStream inputStream) {return build(inputStream, null, null);
}
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {try {// 根據全局配置文件的文件流實例化出一個XMLConfigBuilder對象XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);// 使用XMLConfigBuilder的parse()方法構造出Configuration對象return build(parser.parse());} ....}
返回的Configuration對象此時已經存儲了解析出來的全部全局配置信息,然后再將該對象傳入build()方法,利用Configuration對象創建一個SqlSessionFactory并將其返回。
// 調用鏈中最后一個build方法使用了一個Configuration對象作為參數,并返回DefaultSqlSessionFactory
public SqlSessionFactory build(Configuration config) {return new DefaultSqlSessionFactory(config);
}繼續回到最開始的配置文件解析入口的demo代碼中這一行代碼里:
// 通過加載配置文件流,將XML配置文件構建為Configuration配置類,構建一個SqlSessionFactory,默認是DefaultSqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);這一行代碼就相當于:
SqlSessionFactory sqlSessionFactory = new new DefaultSqlSessionFactory();至此,SqlSessionFactory 對象就創建好了,后面就就可以通過這個工廠類來創建sqlSession連接,進而進行MyBatis的數據庫操作。
三、總結
MyBatis解析全局配置文件的流程總結來看就是,SqlSessionFactoryBuilder利用XMLConfigBuilder去解析全局配置文件,包括屬性配置、別名配置、攔截器配置、環境(數據源和事務管理器)、Mapper配置等;解析完這些配置后會生成一個Configuration對象,這個對象就包含了所有的全局配置信息。然后利用這個Configuration對象創建一個SqlSessionFactory對象,這個對象包含了Configration對象。我們就可以使用這個工廠對象SqlSessionFactory來生成數據庫連接對象sqlSession,進而進行相應的數據庫操作。
解析全局配置文件的時序圖:

相關文章:?【MyBatis】MyBatis的介紹和基本使用
? ? ? ? ? ? ? ? ???【MyBatis】MyBatis的日志實現_mybatis數據庫執行日志-CSDN博客



















