目錄
一、關于文件的打開和關閉
1. 文件的打開
2.文件的關閉
二、文件的讀取
1. 文件的讀_r
2. 使用readline
3.使用readlines
三、文件的寫入
1. 文本的新建寫入
2.文本的追加寫入
四、文件的刪除和重命名
1.文件的重命名
2.文件的刪除
五、文件的定位讀寫
1.tell(?)函數
2.seek(?)函數
附錄 P.S.
一、關于文件的打開和關閉
1. 文件的打開
在Python中,open函數用來打開文件,語法格式如下:?

常見的文件打開模式:

又通過互相組合可以得到幾個新的常見模式:

栗子:
當我們只打開某個文件時,要先確保這個文件是存在的。
所以,先創建一個文本文件(與創建python文件類似):
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 在項目欄中 鼠標右擊-->新建-->文件
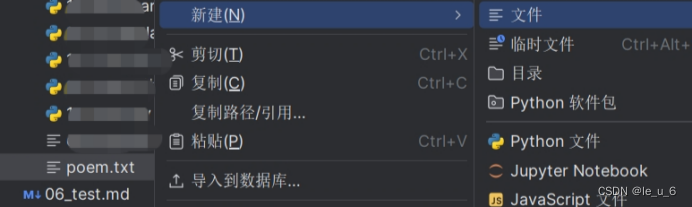
輸入想命名的名字,寫上后綴 .txt ?

然后輸入內容...?
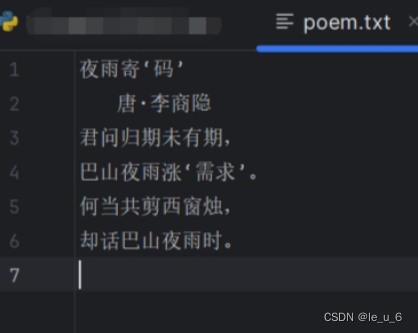
最后、回到python文件,打開一個文本文件

根據填寫要求,文件名是一定要有的,模式可以選填,如果不填,則要保證文本是存在的,否則報錯。

控制臺結果顯示:這個字符串表示的是一個已經打開的文本文件 poem.txt,它被設置為只讀模式,并且使用 GBK 編碼進行文本的編碼和解碼。
2.文件的關閉
文件的關閉強調打開了的文件,要使用close語句關閉。因為即便文件會在程序退出后自動關閉,但考慮到數據的安全性,在每次使用完文件后,都要使用close語句關閉文件,否則一旦程序奔潰就可能導致文件中的數據沒有保存。

二、文件的讀取
1. 文件的讀_r
f = open("poem.txt", "r", encoding="utf-8")
'''打開事先備好的文本文件,填“r”讀的模式,后面是編碼方式
如果你測試的文本文件txt內容含有中文,最好寫上encoding編碼方式,否則報錯'''
content = f.read() # 對f變量進行讀取操作再賦給content
print(content)
f.close()打印結果:

2. 使用readline
readline方法是逐行讀取,比較繁瑣...
f = open('poem.txt', "r", encoding='utf-8')
c1 = f.readline()
c2 = f.readline()
c3 = f.readline()
c4 = f.readline()
c5 = f.readline()
c6 = f.readline()
print(c1)
print(c2)
print(c3)
print(c4)
print(c5)
print(c6)
f.close()考慮文本中存在換行以及print自帶換行,最后結果是每行之間 空的比較大
3.使用readlines
readlins的用法是把整個文本內容一次性都讀取了。
栗子:

這里我們用with...as:語句。因為Python中 ,with...as:語句是一種很好的上下文管理器, 可以確保無論代碼塊中發生什么情況,文本資源最終都會被正確地釋放和關閉。可以防止忘記寫close( )。

這里事先換了首詩,可看到系統自動加\n換行,所以為了好看點,readlines一般可以和for語句一起用:?
with open("poem.txt", "r", encoding="utf-8") as f:c = f.readlines()for p in c: # 使用for循環,可以逐行顯示序列print(p)打印結果:
三、文件的寫入
1. 文本的新建寫入
向文件寫入數據時,如果文件不存在,那么系統會自動創建一個文件并寫入數據。如果文件存在,那么會清空文件原有的數據,重新寫入新數據。
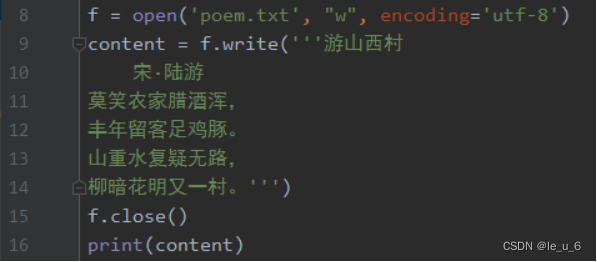
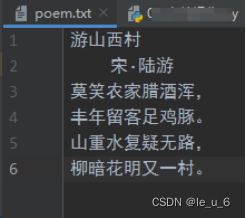
最后控制臺顯示的是 字符數:49

2.文本的追加寫入
文本的追加寫入,我們用模式“ a ”
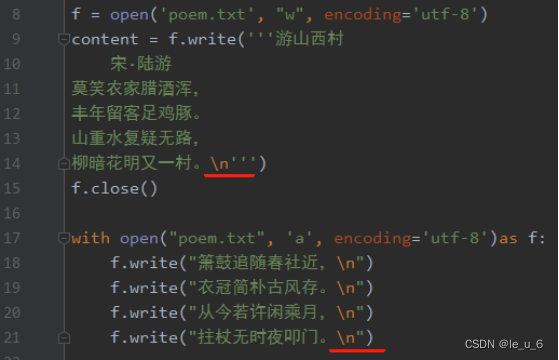
在文末添加內容根據注意換行啊
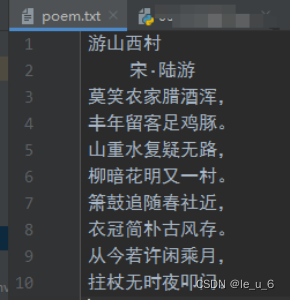
四、文件的刪除和重命名
在Python中,我們要對文本文件進行刪除和重命名的話,可以使用標準庫中的os模塊。與讀取類似,對文件刪除或重命名之前,最好先檢查文件是否存在,以避免拋出異常。
1.文件的重命名
os模塊通過rename函數對文件重命名,rename函數接收兩個參數,分別是舊的文件名和新的文件名。
栗子:
# 引入os模塊
import os
# 將 poem 改成 love_poem
os.rename('poem.txt', "love_poem.txt")運行后,會發現原來目錄下面文本文件的名字已改?
2.文件的刪除
文件的刪除用到os模塊中的remove函數,remove函數接受一個參數,即要刪除的文件的路徑。如果文件被成功刪除,該函數不會有任何返回值。如果文件不存在,os.remove()會拋出一個 FileNotFoundError 異常。
例如:
# 引入os模塊
import os
# 刪除love_poem的文本文件
os.remove('love_poem.txt')五、文件的定位讀寫
在Python中,文件的讀寫定位是指 “控制文件讀寫操作的位置”,以便于能夠從文件的特定位置開始讀取或寫入數據。?通常通過文件的指針來實現,該指針指示下一次讀寫操作將在文本的哪個位置進行。以下兩個函數是常見的獲取和設置文件指針的位置。
1.tell(?)函數
tell()函數會返回文件指針的當前位置,注意中英文字符對位置的影響。
# 打開一個存在的文本文件
f = open("poem.txt", "r", encoding="utf-8")
# 這里偏移量為4,
words = f.read(4)
print("第一次讀取的數據:"words)
# 查找當前位置
position =f.tell()
print("第一次的位置是:",position)words = f.read(16)
print("第二次讀的數據:",words)
position =f.tell()
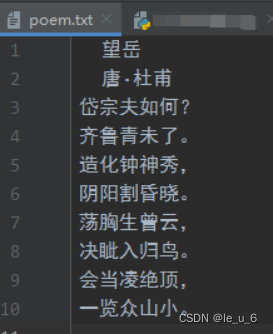
print("第二次位置是:,position)測試的文本:?
?
打印結果:
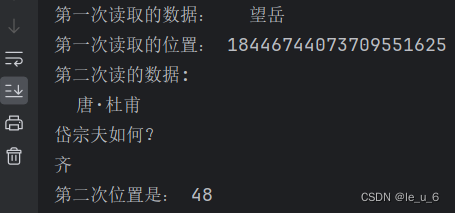
這里第一次位置1844.....我也不懂咋來的,希望有懂的大佬,不吝賜教,留言相告哈。
然后,轉成字母,顯示位置就正常^-^。


2.seek(?)函數
如果希望 重置(重新定位) 指針的位置,可以考慮seek函數
seek函數語法格式:
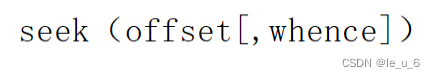
(1)offset :?表示偏移量,也就是需要移動的字節數。
(2)whence:?表示方向,該參數的值有以下三個:
0?:?是whence參數的默認值,表示從文件的起始位置開始偏移,所以也可以不寫。
1?:?表示從文件當前的位置開始偏移。
2 :?表示從文件末尾開始偏移。
f = open("poem.txt", "r", encoding="utf-8")
words = f.read(4)
print("第一次讀取的數據:", words)
position = f.tell()
print("第一次讀取的位置:", position)f.seek(10) # 從初始開始偏移10個
position = f.tell()
print("第二次位置是:", position)
words = f.read(20)
print("第二次讀取的數據:", words)
f.close()后半段seek函數重新偏移從開頭到位置10時,接著開始第二次讀取20個字符,這20個字符是在第10個字符位置的基礎上再往后讀20個。
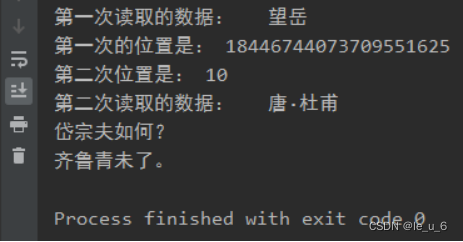
這里10大概是:一行5字+1符號+1換行,然后’唐’前我是2個空格
附錄 P.S.
關于“字符、字節..”的一些百度:
1.空格:?在UTF-8編碼中,一個空格字符(在 ASCII表中)占用一個字節。
2.中文字符:?UTF-8 是一種可變長度的編碼系統,中文字符可能占用3個字節或者更多,具體取決于字符的Unicode碼點。
3.英文字符:?大多數英文字符(包括英文字母和一些基本標點符號)在 UTF-8 編碼中通常占用一個字節。
4.中文標點:?中文標點符號的字節數也可能不同,一些常見的中文標點符號可能占2個或3個字節。
5.英文標點:?大多數英文標點符號,如句號(.)、逗號(,)、分號(;)等,在 UTF-8 編碼中通常占用一個字節。
6.特殊字符:?一些特殊字符,如 emoji (表情)或其他非ASCII字符,可能占用更多的字節,。
總之,在處理文本時,字符計數通常是指邏輯字符的數量,而不是字節數。在UTF-8編碼中,一個中文字符可能占用多個字節,但仍然被視為一個邏輯字符。同樣,空格和標點符號,無論它們占用多少字節,通常每個都被視為一個邏輯字符。(如:len() 函數)來獲取字符串的長度時,它返回的是邏輯字符的數量,而不是字節數。



















