節前,我們組織了一場算法崗技術&面試討論會,邀請了一些互聯網大廠朋友、今年參加社招和校招面試的同學。
針對大模型技術趨勢、大模型落地項目經驗分享、新手如何入門算法崗、該如何準備面試攻略、面試常考點等熱門話題進行了深入的討論。
總結鏈接如下:《AIGC 面試寶典》(2024版) 正式發布!
本文將從DiT的本質、DiT的原理、DiT的應用三個方面,帶您一文搞懂 Diffusion Transformer|DiT。

一、DiT的本質
DiT的定義:Diffusion Transformer是一種結合了Transformer架構的擴散模型,用于圖像和視頻生成任務,能夠高效地捕獲數據中的依賴關系并生成高質量的結果。

擴散模型的定義:Diffusion Models是一種新型的、先進的生成模型,用于生成與訓練數據相似的數據,可以生成各種高分辨率圖像。

擴散模型的定義
擴散模型的核心思想:Diffusion Models是一種受到非平衡熱力學啟發的生成模型,其核心思想是通過模擬擴散過程來逐步添加噪聲到數據中,并隨后學習反轉這個過程以從噪聲中構建出所需的數據樣本。

擴散過程
DiT的本質:Diffusion Transformer是一種新型的擴散模型,結合了去噪擴散概率模型(DDPM)和Transformer架構。

去噪擴散概率模型(DDPM)
DiT的核心思想:Diffusion Transformer的核心思想是使用Transformer作為擴散模型的骨干網絡,而不是傳統的卷積神經網絡(如U-Net),以處理圖像的潛在表示。
DiT的核心思想
二、DiT的原理
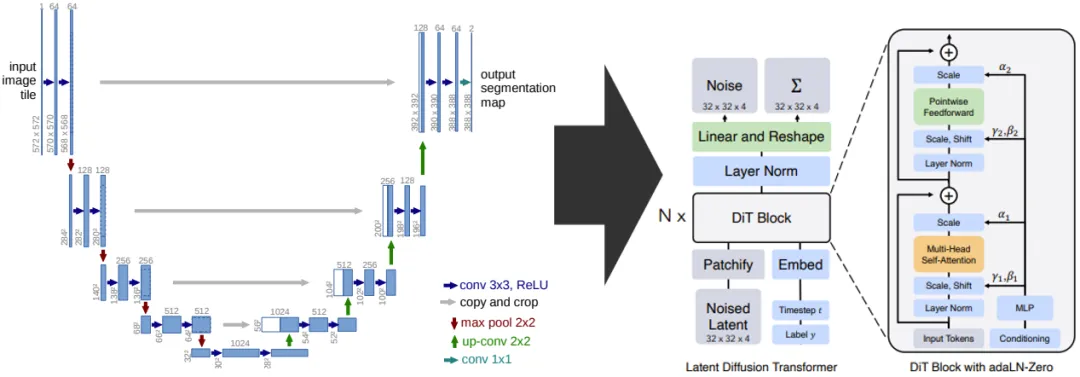
DiT的架構:DiT架構基于Latent Diffusion Model(LDM)框架,采用Vision Transformer(ViT)作為主干網絡,并通過調整ViT的歸一化來構建可擴展的擴散模型。如下圖所示:

DiT的架構
DiT的核心組件:DiT有三種變種形式,分別與In-Context Conditioning、Cross-Attention、adaLN-Zero相組合。

ViT的核心組件
對應Diffusion Transformer模型架構圖中由右到左的順序:
-
上下文條件(In-context conditioning):這是模型處理輸入數據的一種方式,允許模型根據給定的上下文信息生成輸出。
-
交叉注意力塊(Cross-Attention):該模塊允許模型在生成過程中關注輸入數據中的特定部分,從而提高生成的準確性。
-
自適應層歸一化塊(Adaptive Layer Normalization, AdaLN):這是一個歸一化技術,有助于加速模型的訓練并提高性能。

DiT的三種變形形式
DiT的工作流程:通過引入噪聲并訓練神經網絡來逆轉噪聲增加的過程,結合Transformer模型,實現圖像或視頻的生成與變換。這個過程涉及數據預處理、噪聲引入、模型訓練以及最終的圖像或視頻生成。
-
數據預處理:將輸入的圖像或視頻數據轉換為模型可以處理的格式,如將圖像切分成固定大小的patches(小塊),然后將這些patches轉換為特征向量。
-
噪聲引入:在數據預處理后的特征向量上逐步引入噪聲,形成一個噪聲增加的擴散過程。這個過程可以視為從原始數據到噪聲數據的轉換。
-
模型訓練:使用引入了噪聲的特征向量作為輸入,訓練Diffusion Transformer模型。模型的目標是學習如何逆轉噪聲增加的過程,即從噪聲數據恢復出原始數據。
-
圖像或視頻生成:在模型訓練完成后,可以通過輸入噪聲數據(或隨機生成的噪聲)到模型中,經過模型的處理后生成新的圖像或視頻。這個生成過程利用了模型學習到的從噪聲到原始數據的映射關系。

DiT的工作流程
三、DiT的應用
Sora的定義:Sora模型是一種先進的視覺技術模型,以其獨特的方式生成視頻,通過逐步去除噪聲來形成最終畫面,使得生成的場景更加細致,并具備學習復雜動態的能力。
視頻生成模型作為世界模擬器(Video generation models as world simulators)。
Sora
Sora的核心組件:Sora模型的核心組成包括Diffusion Transformer(DiT)、Variational Autoencoder(VAE)和Vision Transformer(ViT)。
DiT負責從噪聲數據中恢復出原始的視頻數據,VAE用于將視頻數據壓縮為潛在表示,而ViT則用于將視頻幀轉換為特征向量以供DiT處理。
-
Diffusion Transformer(DiT):DiT結合了擴散模型和Transformer架構的優勢,通過模擬從噪聲到數據的擴散過程,DiT能夠生成高質量、逼真的視頻內容。在Sora模型中,DiT負責從噪聲數據中恢復出原始的視頻數據。
-
Variational Autoencoder(VAE):VAE是一個生成模型,它能夠將輸入的圖像或視頻數據壓縮為低維度的潛在表示(latent representation),并通過解碼器將這些潛在表示還原為原始數據。在Sora模型中,VAE被用作編碼器,將輸入的視頻數據壓縮為DiT的輸入,從而指導DiT生成與輸入視頻相似的視頻內容。
-
Vision Transformer(ViT):ViT是一種基于Transformer的圖像處理模型,它將圖像視為一系列的patches(小塊),并將這些patches轉換為特征向量作為Transformer的輸入。在Sora模型中,ViT可能被用作預處理步驟或作為模型的一個組件。

技術交流群
前沿技術資訊、算法交流、求職內推、算法競賽、面試交流(校招、社招、實習)等、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企開發者互動交流~
我們建了算法崗技術與面試交流群, 想要大模型技術交流、了解最新面試動態的、需要源碼&資料、提升技術的同學,可以直接加微信號:mlc2040。加的時候備注一下:研究方向 +學校/公司+CSDN,即可。然后就可以拉你進群了。
想加入星球也可以如下方式:
方式①、微信搜索公眾號:機器學習社區,后臺回復:星球
方式②、添加微信號:mlc2040,備注:星球
面試精選
-
一文搞懂 Transformer
-
一文搞懂 Attention(注意力)機制
-
一文搞懂 Self-Attention 和 Multi-Head Attention
-
一文搞懂 BERT(基于Transformer的雙向編碼器)
-
一文搞懂 GPT(Generative Pre-trained Transformer)
-
一文搞懂 Embedding(嵌入)
-
一文搞懂 Encoder-Decoder(編碼器-解碼器)
-
一文搞懂大模型的 Prompt Engineering(提示工程)
-
一文搞懂 Fine-tuning(大模型微調)
-
一文搞懂 LangChain
-
一文搞懂 LangChain 的 Retrieval 模塊
-
一文搞懂 LangChain 的智能體 Agents 模塊
-
一文搞懂 LangChain 的鏈 Chains 模塊
相關論文
- 《Scalable Diffusion Models with Transformers》

![[書生·浦語大模型實戰營]——第二節:輕松玩轉書生·浦語大模型趣味 Demo](http://pic.xiahunao.cn/[書生·浦語大模型實戰營]——第二節:輕松玩轉書生·浦語大模型趣味 Demo)

哪些步驟該丟給GPU)
)

)



)








