此 Python 筆記本提供了有關利用 LlamaParse 從 PDF 文檔中提取信息并隨后將提取的內容存儲到 Neo4j 圖形數據庫中的綜合指南。本教程在設計時考慮到了實用性,適合對文檔處理、信息提取和圖形數據庫技術感興趣的開發人員、數據科學家和技術愛好者。
該筆記本電腦的主要特點:
-
設置環境:逐步說明如何設置 Python 環境,包括安裝必要的庫和工具,例如 LlamaParse 和 Neo4j 數據庫驅動程序。
-
PDF 文檔處理:演示如何使用 LlamaParse 讀取 PDF 文檔,提取相關信息(例如文本、表格和圖像),并將這些信息轉換為適合數據庫插入的結構化格式。
-
文檔圖模型:設計有效圖模型的指南,該模型表示從 PDF 文檔中提取的關系和實體,確保查詢和分析的最佳結構。
-
在 Neo4j 中存儲提取的數據:詳細的代碼示例展示了如何從 Python 連接到 Neo4j 數據庫,根據提取的數據創建節點和關系,以及執行 Cypher 查詢來填充數據庫。
-
生成和存儲文本嵌入:使用過去創建的程序通過 OpenAI API 調用生成文本嵌入,并將嵌入存儲為 Neo4j 中的向量。
-
查詢和??分析數據:用于檢索和分析存儲數據的 Cypher 查詢示例,說明 Neo4j 如何發現隱藏在 PDF 內容中的見解和關系。
-
結論:有關處理 PDF、設計圖形模式和優化 Neo4j 查詢的最佳實踐的提示,以及針對在此過程中遇到的潛在問題的常見故障排除建議。
請注意,對于此示例,版本是必需的llama_index >=0.10.4。如果pip install --upgrade <package_name>不起作用,您可以pip uninstall <package_name>再次使用并安裝所需的軟件包。
1.搭建環境
pip?install?-qU?llama-index?llama-index-core?llama-index-embeddings-mistralai?llama-parse?neo4j
Note: you may need to restart the kernel to use updated packages.
#下載測試文件
!wget?"https://www.dropbox.com/scl/fi/g5ojyzk4m44hl7neut6vc/chinese_pdf.pdf?rlkey=45reu51kjvdvic6zucr8v9sh3&dl=1"?-O?chinese_pdf.pdf
LlamaParse簡介
LlamaParse 是由 LlamaIndex 創建的一項技術,專門用于高效地解析和表示PDF文件,以便通過 LlamaIndex 框架進行高效檢索和上下文增強,特別適用于復雜的PDF文檔。它基于RAG(Rule-based Approach with Grammar)技術,能夠準確地提取文本、圖像、表格等元素,同時保持良好的性能。這項技術的設計初衷是為了處理那些包含嵌入式對象(如表格和圖形)的復雜文檔,這類文檔的處理在以往往往是個挑戰。通過與 LlamaIndex 的直接整合,LlamaParse不僅能夠支持對這些復雜、半結構化文檔的解析,還能夠在檢索時提供支持,從而讓用戶能夠回答之前難以解決的復雜問題。
LlamaParse 的核心優勢在于它的專有解析技術,這使得它能夠理解和處理PDF文件中的復雜結構。此外,由于它與LlamaIndex 的緊密整合,用戶可以非常方便地將解析后的數據用于增強檢索和上下文理解,從而大大提高了信息檢索的效率和準確性。
LlamaParse 默認將 PDF 轉換為 Markdown,文檔的內容可以準確的解析出來。但LlamaCloud 官網因為不能設置解析文檔的語言,默認只能識別英文的文檔,中文的解析識別需要在 Python 代碼中指定。
2.PDF文檔處理
我們需要 OpenAI 和 LlamaParse API 密鑰來運行該項目。
我們將使用 Python 代碼展示 LlamaParse,在開始之前,你將需要一個 API 密鑰。它是免費的。你可以從下圖中看到設置密鑰的鏈接,因此現在單擊該鏈接并設置您的 API 密鑰。由于我使用 OpenAI 進行 LLM 和嵌入,因此我也需要獲取 OpenAI API 密鑰。
#?llama-parse?is?async-first,?running?the?async?code?in?a?notebook?requires?the?use?of?nest_asyncio
import?nest_asyncio
nest_asyncio.apply()
import?os
#?API?access?to?llama-cloud
os.environ["LLAMA_CLOUD_API_KEY"]?=?"llx-Pd9FqzqbITfp7KXpB0YHWngqXK4GWZvB5BSAf9IoiNDBeie4"
#?Using?OpenAI?API?for?embeddings/llms
#os.environ["OPENAI_API_KEY"]?=?"sk-OK5mvOSKVeRokboDB1eHrIuifAcUc6wAqU82ZgRVJMAg4tJ3"
os.environ["MISTRAL_API_KEY"]?=?"q9ebyLLL3KoZTLAeb8I81doRLZK5SXNO"
pip?install?-qU?llama-index-llms-mistralai?llama-index-embeddings-mistralai
Note: you may need to restart the kernel to use updated packages.
from?llama_index.llms.mistralai?import?MistralAI
from?llama_index.embeddings.mistralai?import?MistralAIEmbedding
from?llama_index.core?import??VectorStoreIndex
from?llama_index.core?import?Settings
EMBEDDING_MODEL??=?"mistral-embed"
GENERATION_MODEL?=?"open-mistral-7b"
llm?=?MistralAI(model=GENERATION_MODEL)
Settings.llm?=?llm
使用全新的“LlamaParse”PDF閱讀器進行PDF解析
我們還比較了兩種不同的檢索/查詢引擎策略:
-
使用原始 Markdown 文本作為節點來構建索引,并應用簡單的查詢引擎來生成結果; -
用于MarkdownElementNodeParser解析LlamaParse輸出 Markdown 結果并構建遞歸檢索器查詢引擎以進行生成。
有一些參數值得關注:
-
result_type 選項僅限于 "text" 和 "markdown" 。 這里我們選擇 Markdown 格式輸出,因為它將很好地保留結構化信息。 -
num_workers 設置工作線程的數量。一般來說,我們可以根據需要解析的文件數量來設定工作線程的數量。 (最大值為 10 ) -
配置工作線程的數量:你可以根據需要解析的文件數量來設定工作線程的數量。這樣做可以讓你根據任務的規模來優化資源的使用和提高處理效率。 -
根據文件數量設定:通常,你會希望設置的工作線程數量與你打算解析的文件數量相匹配。例如,如果你有5個文件需要解析,那么設置5個工作線程可能是合理的,這樣可以確保每個文件都有一個專門的線程來處理。 -
最大限制:LlamaParse對于工作線程的數量有一個最大限制,這里是設置為10。這意味著你最多可以同時設置10個工作線程來并行處理解析任務。這個限制可能是為了確保系統的穩定性和防止資源過度消耗。
-
from?llama_parse?import?LlamaParse
from?llama_parse.base?import?ResultType,?Language
pdf_file_name?=?'./chinese_pdf.pdf'
parser=?LlamaParse(
????result_type=ResultType.MD,
????language=Language.SIMPLIFIED_CHINESE,
????verbose=True,
????num_workers=1,
)
documents?=?parser.load_data(pdf_file_name)
Started parsing the file under job_id 2bd5a318-08f2-4b12-b9f3-424b8238bd96
執行以上代碼,會啟動一個PDF解析的異步任務。
解析完我們查看一下解析后的結果,這里分別輸出文檔中的兩部分內容。從結果可以看到,質量還是比較高的。
#?Check?loaded?documents
print(f"Number?of?documents:?{len(documents)}")
for?doc?in?documents:
????print(doc.doc_id)
????print(doc.text[:500]?+?'...')
Number of documents: 1
093b2e8e-03b2-4a07-aeb0-270adcb4f9ba
# CAICT pBEiwrHze BR+E No.20230 8數據要素白皮書 (2023 年)中 國 信 息 通 信 研 究院 2023年9月
---
# 版權聲明本白皮書版權屬于中國信息通信研究院,并受法律保護。轉載、摘編或利用其它方式使用本白皮書文字或者觀點的,應注明“來源:中國信息通信研究院”。違反上述聲明者,本院將追究其相關法律責任。CaICT
---
# 前言2022年12月,中共中央、國務院印發《關于構建數據基礎制度更好發揮數據要素作用的意見》(下稱“數據二十條”),這是我國首部從生產要素高度系統部署數據要素價值釋放的國家級專項政策文件。“數據二十條”確立了數據基礎制度體系的“四梁八柱”,在數據要素發展進程中具有重大意義。...
#?Parse?the?documents?using?MarkdownElementNodeParser
from?llama_index.core.node_parser?import?MarkdownElementNodeParser
node_parser?=?MarkdownElementNodeParser(llm=llm,?num_workers=8)
nodes?=?node_parser.get_nodes_from_documents(documents)
3it [00:00, 3851.52it/s]
100%|█████████████████████████████████████████████| 3/3 [00:11<00:00, 3.74s/it]
#?Convert?nodes?into?objects
base_nodes,?objects?=?node_parser.get_nodes_and_objects(nodes)
import?json
#?Check?parsed?node?objects?
print(f"Number?of?nodes:?{len(base_nodes)}")
Number of nodes: 36
TABLE_REF_SUFFIX?=?'_table_ref'
TABLE_ID_SUFFIX??=?'_table'
#?Check?parsed?objects?
print(f"Number?of?objects:?{len(objects)}")
for?node?in?objects:?
????print(f"id:{node.node_id}")
????print(f"hash:{node.hash}")
????print(f"parent:{node.parent_node}")
????print(f"prev:{node.prev_node}")
????print(f"next:{node.next_node}")
????#?Object?is?a?Table
????if?node.node_id[-1?*?len(TABLE_REF_SUFFIX):]?==?TABLE_REF_SUFFIX:
????????if?node.next_node?is?not?None:
????????????next_node?=?node.next_node
????????
????????????print(f"next_node?metadata:{next_node.metadata}")
????????????print(f"next_next_node:{next_next_nod_id}")
????????????obj_metadata?=?json.loads(str(next_node.json()))
????????????print(str(obj_metadata))
????????????print(f"def:{obj_metadata['metadata']['table_df']}")
????????????print(f"summary:{obj_metadata['metadata']['table_summary']}")
????print(f"next:{node.next_node}")
????print(f"type:{node.get_type()}")
????print(f"class:{node.class_name()}")
????print(f"content:{node.get_content()[:200]}")
????print(f"metadata:{node.metadata}")
????print(f"extra:{node.extra_info}")
????
????node_json?=?json.loads(node.json())
????print(f"start_idx:{node_json.get('start_char_idx')}")
????print(f"end_idx:{node_json['end_char_idx']}")
????if?'table_summary'?in?node_json:?
????????print(f"summary:{node_json['table_summary']}")
????print("=====================================")???
Number of objects: 3
id:1ace071a-4177-4395-ae42-d520095421ff
hash:e593799944034ed3ff7d2361c0f597cd67f0ee6c43234151c7d80f84407d4c5f
parent:None
prev:node_id='9694e60e-6988-493b-89c3-2533ff1adcd2' node_type=<ObjectType.TEXT: '1'> metadata={} hash='898f4b8eb4de2dbfafa9062f479df61668c6a7604f2bea5b9937b70e234ba746'
next:node_id='9c71f897-f510-4b8c-a876-d0d8ab55e004' node_type=<ObjectType.TEXT: '1'> metadata={'table_df': "{'一、數據要素再認識': {0: '(一)國家戰略全方位布局數據要素發展', 1: '(二)人工智能發展對數據供給提出更高要求', 2: '(三)數據要素概念聚焦于數據價值釋放', 3: '二、資源:分類推進數據要素探索已成為共識', 4: '(一)不同類別數據資源面臨不同關鍵問題', 5: '(二)授權運營促進公共數據供給提質增效', 6: '(三)會計入表推動企業數據價值“顯性化”', 7: '(四)權益保護仍是個人數據開發利用主線', 8: '三、主體:企業政府雙向發力推進可持續探索', 9: '(一)企業側:數據管理與應用能力是前提', 10: '(二)政府側:建立公平高效的機制是關鍵', 11: '四、市場:場內外結合推動數據資源最優配置', 12: '(一)數據流通存在多層次多樣化形態', 13: '(二)場外交易活躍,場內交易多點突破', 14: '(三)多措并舉破除數據流通障礙', 15: '五、技術:基于業務需求加速創新與體系重構', 16: '(一)數據技術隨業務要求不斷演進', 17: '(二)數據要素時代新技術不斷涌現', 18: '(三)數據要素技術體系重構加速', 19: '六、趨勢與展望', 20: '參考文獻'}, '1': {0: 1, 1: 3, 2: 5, 3: 7, 4: 7, 5: 11, 6: 15, 7: 18, 8: 21, 9: 21, 10: 26, 11: 29, 12: 30, 13: 33, 14: 35, 15: 37, 16: 37, 17: 38, 18: 42, 19: 42, 20: 46}}", 'table_summary': 'Title: Data Element Development and Utilization in National Strategic Perspective\n\nSummary: This table discusses various aspects of data element development and utilization, including strategic layout, resource classification, subject involvement, market dynamics, technological advancements, and trends. It also highlights key issues in different categories of data resources, the role of authorization and operation in improving public data supply, the importance of data management and application capabilities for enterprises, the need for a fair and efficient mechanism on the government side, and the significance of equity protection in personal data development and utilization. The table concludes with a section on market and technological trends.\n\nTable ID: Not provided in the context.\n\nThe table should be kept as it provides valuable insights into the development and utilization of data elements from a national strategic perspective.,\nwith the following columns:\n'} hash='48055467b0febd41fcce52d02d72730f8ea97c7a7905749afb557b0dcecef7c2'
next:node_id='9c71f897-f510-4b8c-a876-d0d8ab55e004' node_type=<ObjectType.TEXT: '1'> metadata={'table_df': "{'一、數據要素再認識': {0: '(一)國家戰略全方位布局數據要素發展', 1: '(二)人工智能發展對數據供給提出更高要求', 2: '(三)數據要素概念聚焦于數據價值釋放', 3: '二、資源:分類推進數據要素探索已成為共識', 4: '(一)不同類別數據資源面臨不同關鍵問題', 5: '(二)授權運營促進公共數據供給提質增效', 6: '(三)會計入表推動企業數據價值“顯性化”', 7: '(四)權益保護仍是個人數據開發利用主線', 8: '三、主體:企業政府雙向發力推進可持續探索', 9: '(一)企業側:數據管理與應用能力是前提', 10: '(二)政府側:建立公平高效的機制是關鍵', 11: '四、市場:場內外結合推動數據資源最優配置', 12: '(一)數據流通存在多層次多樣化形態', 13: '(二)場外交易活躍,場內交易多點突破', 14: '(三)多措并舉破除數據流通障礙', 15: '五、技術:基于業務需求加速創新與體系重構', 16: '(一)數據技術隨業務要求不斷演進', 17: '(二)數據要素時代新技術不斷涌現', 18: '(三)數據要素技術體系重構加速', 19: '六、趨勢與展望', 20: '參考文獻'}, '1': {0: 1, 1: 3, 2: 5, 3: 7, 4: 7, 5: 11, 6: 15, 7: 18, 8: 21, 9: 21, 10: 26, 11: 29, 12: 30, 13: 33, 14: 35, 15: 37, 16: 37, 17: 38, 18: 42, 19: 42, 20: 46}}", 'table_summary': 'Title: Data Element Development and Utilization in National Strategic Perspective\n\nSummary: This table discusses various aspects of data element development and utilization, including strategic layout, resource classification, subject involvement, market dynamics, technological advancements, and trends. It also highlights key issues in different categories of data resources, the role of authorization and operation in improving public data supply, the importance of data management and application capabilities for enterprises, the need for a fair and efficient mechanism on the government side, and the significance of equity protection in personal data development and utilization. The table concludes with a section on market and technological trends.\n\nTable ID: Not provided in the context.\n\nThe table should be kept as it provides valuable insights into the development and utilization of data elements from a national strategic perspective.,\nwith the following columns:\n'} hash='48055467b0febd41fcce52d02d72730f8ea97c7a7905749afb557b0dcecef7c2'
type:3
class:IndexNode
content:Title: Data Element Development and Utilization in National Strategic PerspectiveSummary: This table discusses various aspects of data element development and utilization, including strategic layout
metadata:{'col_schema': ''}
extra:{'col_schema': ''}
start_idx:816
end_idx:1319
=====================================
3. 解析文檔的圖模型
無論使用哪種PDF解析工具,將結果作為知識圖譜保存到Neo4j中,圖模式實際上是相當一致的。
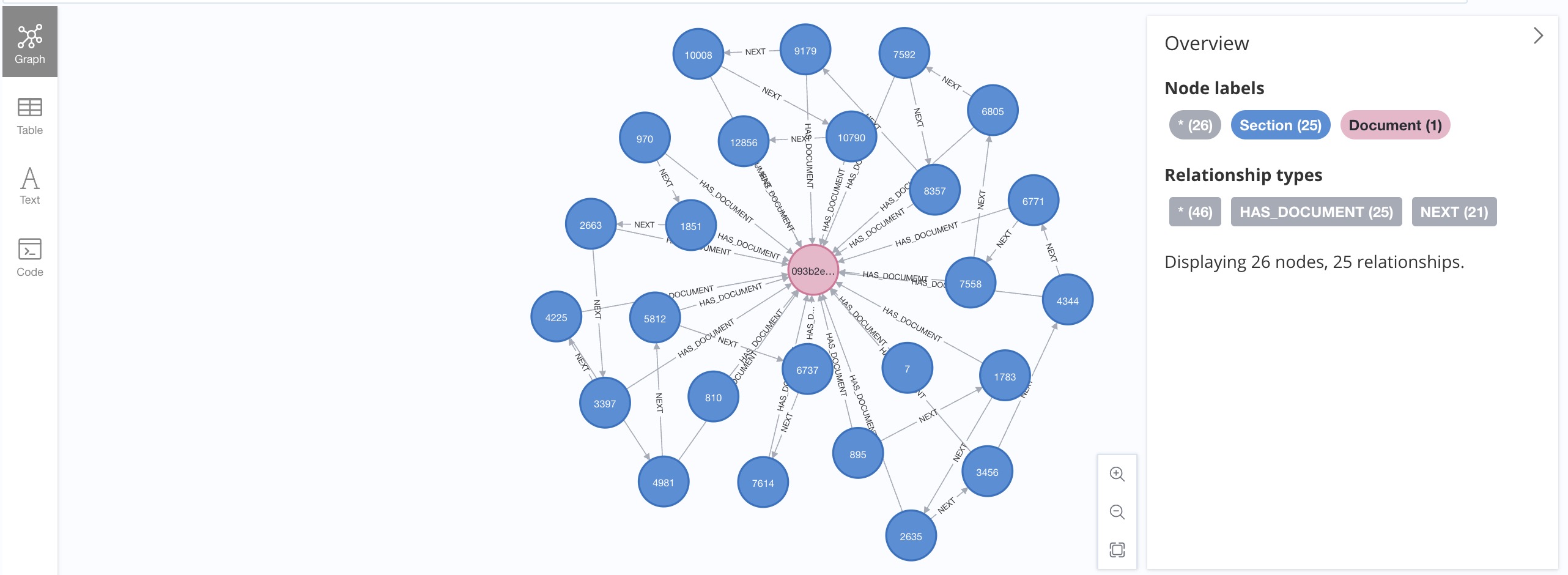
在本項目中,將使用類似的圖模型。讓我們從圖數據庫模式定義開始:
-
關鍵屬性的唯一性約束 -
嵌入向量索引
from?neo4j?import?GraphDatabase
#?Local?Neo4j?instance
NEO4J_URL?=?"bolt://localhost:7687"
#?Remote?Neo4j?instance?on?AuraDB
#NEO4J_URL?=?"http://localhost:7474"
NEO4J_USER?=?"neo4j"
NEO4J_PASSWORD?=?"langchain"
NEO4J_DATABASE?=?"neo4j"
def?initialiseNeo4jSchema():
????cypher_schema?=?[
????????"CREATE?CONSTRAINT?sectionKey?IF?NOT?EXISTS?FOR?(c:Section)?REQUIRE?(c.key)?IS?UNIQUE;",
????????"CREATE?CONSTRAINT?chunkKey?IF?NOT?EXISTS?FOR?(c:Chunk)?REQUIRE?(c.key)?IS?UNIQUE;",
????????"CREATE?CONSTRAINT?documentKey?IF?NOT?EXISTS?FOR?(c:Document)?REQUIRE?(c.url_hash)?IS?UNIQUE;",
????????"CREATE?VECTOR?INDEX?`chunkVectorIndex`?IF?NOT?EXISTS?FOR?(e:Embedding)?ON?(e.value)?OPTIONS?{?indexConfig:?{`vector.dimensions`:?1536,?`vector.similarity_function`:?'cosine'}};"
????]
????driver?=?GraphDatabase.driver(NEO4J_URL,?database=NEO4J_DATABASE,?auth=(NEO4J_USER,?NEO4J_PASSWORD))
????with?driver.session()?as?session:
????????for?cypher?in?cypher_schema:
????????????session.run(cypher)
????driver.close()
#?create?constraints?and?indexes
initialiseNeo4jSchema()
4. 在 Neo4j 中存儲提取的數據
driver?=?GraphDatabase.driver(NEO4J_URL,?database=NEO4J_DATABASE,?auth=(NEO4J_USER,?NEO4J_PASSWORD))
#?================================================
#?1)?Save?documents
print("Start?saving?documents?to?Neo4j...")
i?=?0
with?driver.session()?as?session:
????for?doc?in?documents:
????????cypher?=?"MERGE?(d:Document?{url_hash:?$doc_id})?ON?CREATE?SET?d.url=$url;"
????????session.run(cypher,?doc_id=doc.doc_id,?url=doc.doc_id)
????????i?=?i?+?1
????session.close()
print(f"{i}?documents?saved.")
#?================================================
#?2)?Save?nodes
print("Start?saving?nodes?to?Neo4j...")
i?=?0
with?driver.session()?as?session:
????for?node?in?base_nodes:?
????????#?>>1?Create?Section?node
????????cypher??=?"MERGE?(c:Section?{key:?$node_id})\n"
????????cypher?+=?"?FOREACH?(ignoreMe?IN?CASE?WHEN?c.type?IS?NULL?THEN?[1]?ELSE?[]?END?|\n"
????????cypher?+=?"?????SET?c.hash?=?$hash,?c.text=$content,?c.type=$type,?c.class=$class_name,?c.start_idx=$start_idx,?c.end_idx=$end_idx?)\n"
????????cypher?+=?"?WITH?c\n"
????????cypher?+=?"?MATCH?(d:Document?{url_hash:?$doc_id})\n"
????????cypher?+=?"?MERGE?(d)<-[:HAS_DOCUMENT]-(c);"
????????node_json?=?json.loads(node.json())
????????session.run(cypher,?node_id=node.node_id,?hash=node.hash,?content=node.get_content(),?type='TEXT',?class_name=node.class_name()
??????????????????????????,?start_idx=node_json['start_char_idx'],?end_idx=node_json['end_char_idx'],?doc_id=node.ref_doc_id)
????????#?>>2?Link?node?using?NEXT?relationship
????????if?node.next_node?is?not?None:?#?and?node.next_node.node_id[-1*len(TABLE_REF_SUFFIX):]?!=?TABLE_REF_SUFFIX:
????????????cypher??=?"MATCH?(c:Section?{key:?$node_id})\n"????#?current?node?should?exist
????????????cypher?+=?"MERGE?(p:Section?{key:?$next_id})\n"????#?previous?node?may?not?exist
????????????cypher?+=?"MERGE?(p)<-[:NEXT]-(c);"
????????????session.run(cypher,?node_id=node.node_id,?next_id=node.next_node.node_id)
????????if?node.prev_node?is?not?None:??#?Because?tables?are?in?objects?list,?so?we?need?to?link?from?the?opposite?direction
????????????cypher??=?"MATCH?(c:Section?{key:?$node_id})\n"????#?current?node?should?exist
????????????cypher?+=?"MERGE?(p:Section?{key:?$prev_id})\n"????#?previous?node?may?not?exist
????????????cypher?+=?"MERGE?(p)-[:NEXT]->(c);"
????????????if?node.prev_node.node_id[-1?*?len(TABLE_ID_SUFFIX):]?==?TABLE_ID_SUFFIX:
????????????????prev_id?=?node.prev_node.node_id?+?'_ref'
????????????else:
????????????????prev_id?=?node.prev_node.node_id
????????????session.run(cypher,?node_id=node.node_id,?prev_id=prev_id)
????????i?=?i?+?1
????session.close()
print(f"{i}?nodes?saved.")
#?================================================
#?3)?Save?objects
print("Start?saving?objects?to?Neo4j...")
i?=?0
with?driver.session()?as?session:
????for?node?in?objects:???????????????
????????node_json?=?json.loads(node.json())
????????#?Object?is?a?Table,?then?the?????_ref_table?object?is?created?as?a?Section,?and?the?table?object?is?Chunk
????????if?node.node_id[-1?*?len(TABLE_REF_SUFFIX):]?==?TABLE_REF_SUFFIX:
????????????if?node.next_node?is?not?None:??#?here?is?where?actual?table?object?is?loaded
????????????????next_node?=?node.next_node
????????????????obj_metadata?=?json.loads(str(next_node.json()))
????????????????cypher??=?"MERGE?(s:Section?{key:?$node_id})\n"
????????????????cypher?+=?"WITH?s?MERGE?(c:Chunk?{key:?$table_id})\n"
????????????????cypher?+=?"?FOREACH?(ignoreMe?IN?CASE?WHEN?c.type?IS?NULL?THEN?[1]?ELSE?[]?END?|\n"
????????????????cypher?+=?"?????SET?c.hash?=?$hash,?c.definition=$content,?c.text=$table_summary,?c.type=$type,?c.start_idx=$start_idx,?c.end_idx=$end_idx?)\n"
????????????????cypher?+=?"?WITH?s,?c\n"
????????????????cypher?+=?"?MERGE?(s)?<-[:UNDER_SECTION]-?(c)\n"
????????????????cypher?+=?"?WITH?s?MATCH?(d:Document?{url_hash:?$doc_id})\n"
????????????????cypher?+=?"?MERGE?(d)<-[:HAS_DOCUMENT]-(s);"
????????????????session.run(cypher,?node_id=node.node_id,?hash=next_node.hash,?content=obj_metadata['metadata']['table_df'],?type='TABLE'
??????????????????????????????????,?start_idx=node_json['start_char_idx'],?end_idx=node_json['end_char_idx']
??????????????????????????????????,?doc_id=node.ref_doc_id,?table_summary=obj_metadata['metadata']['table_summary'],?table_id=next_node.node_id)
????????????????
????????????if?node.prev_node?is?not?None:
????????????????cypher??=?"MATCH?(c:Section?{key:?$node_id})\n"????#?current?node?should?exist
????????????????cypher?+=?"MERGE?(p:Section?{key:?$prev_id})\n"????#?previous?node?may?not?exist
????????????????cypher?+=?"MERGE?(p)-[:NEXT]->(c);"
????????????????if?node.prev_node.node_id[-1?*?len(TABLE_ID_SUFFIX):]?==?TABLE_ID_SUFFIX:
????????????????????prev_id?=?node.prev_node.node_id?+?'_ref'
????????????????else:
????????????????????prev_id?=?node.prev_node.node_id
????????????????
????????????????session.run(cypher,?node_id=node.node_id,?prev_id=prev_id)
????????????????
????????i?=?i?+?1
????session.close()
#?================================================
#?4)?Create?Chunks?for?each?Section?object?of?type?TEXT
#?If?there?are?changes?to?the?content?of?TEXT?section,?the?Section?node?needs?to?be?recreated
print("Start?creating?chunks?for?each?TEXT?Section...")
with?driver.session()?as?session:
????cypher??=?"MATCH?(s:Section)?WHERE?s.type='TEXT'?\n"
????cypher?+=?"WITH?s?CALL?{\n"
????cypher?+=?"WITH?s?WITH?s,?split(s.text,?'\n')?AS?para\n"
????cypher?+=?"WITH?s,?para,?range(0,?size(para)-1)?AS?iterator\n"
????cypher?+=?"UNWIND?iterator?AS?i?WITH?s,?trim(para[i])?AS?chunk,?i?WHERE?size(chunk)?>?0\n"
????cypher?+=?"CREATE?(c:Chunk?{key:?s.key?+?'_'?+?i})?SET?c.type='TEXT',?c.text?=?chunk,?c.seq?=?i?\n"
????cypher?+=?"CREATE?(s)?<-[:UNDER_SECTION]-(c)?}?IN?TRANSACTIONS?OF?500?ROWS?;"
????
????session.run(cypher)
????
????session.close()
print(f"{i}?objects?saved.")
print("=================DONE====================")
driver.close()
Start saving documents to Neo4j...
1 documents saved.
Start saving nodes to Neo4j...
36 nodes saved.
Start saving objects to Neo4j...
Start creating chunks for each TEXT Section...
3 objects saved.
=================DONE====================
5. 生成和存儲文本嵌入
from?mistralai.client?import?MistralClient
def?get_embedding(client,?text,?model):
????response?=?client.embeddings.create(
????????????????????input=text,
????????????????????model=model,
????????????????)
????return?response.data[0].embedding
def?LoadEmbedding(label,?property):
????driver?=?GraphDatabase.driver(NEO4J_URL,?auth=(NEO4J_USER,?NEO4J_PASSWORD),?database=NEO4J_DATABASE)
????mistralai_client?=?MistralClient?(api_key?=?os.environ["MISTRAL_API_KEY"])
????with?driver.session()?as?session:
????????#?get?chunks?in?document,?together?with?their?section?titles
????????result?=?session.run(f"MATCH?(ch:{label})?RETURN?id(ch)?AS?id,?ch.{property}?AS?text")
????????#?call?OpenAI?embedding?API?to?generate?embeddings?for?each?proporty?of?node
????????#?for?each?node,?update?the?embedding?property
????????count?=?0
????????for?record?in?result:
????????????id?=?record["id"]
????????????text?=?record["text"]
????????????
????????????#?For?better?performance,?text?can?be?batched
????????????embedding_batch_response?=?mistralai_client.embeddings(model=EMBEDDING_MODEL,input=text,?)
????????????#print(embedding_batch_response.data[0])
????????????#print(embedding_batch_response.data[0].embedding)
????????????#?key?property?of?Embedding?node?differentiates?different?embeddings
????????????cypher?=?"CREATE?(e:Embedding)?SET?e.key=$key,?e.value=$embedding,?e.model=$model"
????????????cypher?=?cypher?+?"?WITH?e?MATCH?(n)?WHERE?id(n)?=?$id?CREATE?(n)?-[:HAS_EMBEDDING]->?(e)"
????????????session.run(cypher,key=property,?embedding=embedding_batch_response.data[0].embedding,?id=id,?model=EMBEDDING_MODEL)?
????????????count?=?count?+?1
????????session.close()
????????
????????print("Processed?"?+?str(count)?+?"?"?+?label?+?"?nodes?for?property?@"?+?property?+?".")
????????return?count
#?For?smaller?amount?(<2000)?of?text?data?to?embed
LoadEmbedding("Chunk",?"text")
Processed 368 Chunk nodes for property @text.368
6. 查詢文檔知識圖譜
讓我們打開 Neo4j 瀏覽器來檢查加載的文檔圖。
在文本框中輸入MATCH (n:Section) RETURN n并運行它,我們將看到文檔的一系列部分。通過點擊并展開一個Section節點,我們可以看到它所連接的Chunk節點。 
如果“Section”節點的類型為“type” TEXT,則它具有一組“Chunk”節點,每個節點在“text”屬性中存儲一個段落。 
如果一個Section節點的類型為TABLE,那么它只有一個Chunk節點,其中text屬性存儲表內容的摘要,definition屬性存儲表的內容。
每個Chunk節點都連接一個Embedding節點,該節點存儲Chunk節點文本內容的嵌入。在這個項目的開始,我們定義了一個向量索引,以便我們能夠更有效地執行相似性搜索。
由于部分節點的文本內容可能超出嵌入模型強制執行的標記長度限制(8k,~ 5k 個單詞),因此通過將內容拆分為段落可以幫助糾正此限制,并且嵌入更相關的文本,因為它們出現在相同的文本中段落。
七、結論
LlamaParse 是一款功能強大的 PDF 文檔解析工具,擅長以卓越的效率處理復雜的結構化和非結構化數據。其先進的算法和直觀的 API 有助于從 PDF 中無縫提取文本、表格、圖像和元數據,將通常具有挑戰性的任務轉變為簡化的流程。
在 Neo4j 中將提取的數據存儲為圖表進一步放大了優勢。通過在圖形數據庫中表示數據實體及其關系,用戶可以發現使用傳統關系數據庫很難(如果不是不可能)檢測到的模式和連接。 Neo4j 的圖形模型提供了一種自然直觀的方式來可視化復雜關系,增強了進行復雜分析和得出可行見解的能力。
一致的文檔知識圖模式使得與下游任務的其他工具集成變得更加容易,例如使用GenAI Stack(LangChain 和 Streamlit)構建檢索增強生成。
LlamaParse 的提取功能與 Neo4j 基于圖形的存儲和分析相結合,為數據驅動決策開辟了新的可能性。它允許更細致地理解數據關系、高效的數據查詢以及隨著數據集規模和復雜性不斷增長而擴展的能力。這種協同作用不僅加速了提取和分析過程,還有助于采用更明智和更具戰略性的數據管理方法。
目前還沒有辦法把文件中的內容作為節點準確識別,這是后續要研究的方向。
本文由 mdnice 多平臺發布










:BR/EDR的連接過程;查詢(發現)=》尋呼(連接)=》安全建立=》認證=》pair成功;類比WiFi連接過程。)




等級考試試卷(三級))
依賴下載)


