
倒排索引是一種用于全文搜索的數據結構。它的主要功能是將文檔中的單詞作為索引項,映射到包含該單詞的文檔列表。通過倒排索引,可以快速準確地定位到與查詢詞相匹配的文檔列表,從而大幅提高查詢性能。倒排索引在搜索引擎、數據庫和信息檢索系統中被廣泛應用。
倒排索引的基本原理
倒排索引的概念
假設我們有如下的一個數據表:
CREATE TABLE test(id INT, title STRING);
INSERT INTO test VALUES
(1, 'Index helps search words'),
(2, 'Search articles quickly'),
(3, 'Index speeds up searches')為了查找數據表中包含某個單詞或詞組的行,數據庫通常會使用?like?語句來進行查找。例如,查找出標題中包含單詞 "search" 的行,可以使用如下的 SQL 語句進行查詢。
SELECT * FROM test WHERE title like '%search%';
┌────────────────────────────────────────────┐
│ id │ title │
│ Nullable(Int32) │ Nullable(String) │
├─────────────────┼──────────────────────────┤
│ 1 │ Index helps search words │
│ 3 │ Index speeds up searches │
└────────────────────────────────────────────┘這種方式雖然可以滿足一些場景的使用需求,但是也存在幾個問題:
- 需要進行全表數據掃描再進行過濾,當數量較大時通常會比較耗時。
- 只能進行簡單的單詞匹配,無法支持復雜的查詢邏輯,如「查找單詞 "search" OR "quickly" 」等。
- 無法根據數據與查詢詞的相關性進行排序。
倒排索引通過為文檔中的詞語(Term)與文檔標識符(DocId)建立映射關系來實現高效的全文檢索。這里我們可以使用 test 表中的 id 列作為 DocId 。
生成倒排索引主要有如下三個步驟:
-
首先對數據進行分詞,根據語義拆分為一個個的單詞,我們采用了 jieba 對中文進行分詞。
-
對拆分后的單詞進行過濾,將單詞轉為統一的 Term,主要包括如下幾種:
- 字母都轉為小寫字母。
- 去除停用詞 (stop word),如 a、the 等。
- 提取單詞的詞干,例如將 quickly 轉為 quick。
-
將 Term 作為索引詞,與對應的 DocIds 建立一個映射關系。
經過以上處理之后,我們可以得到 Term 與 DocIds 映射的倒排索引。
| Term | DocIds |
|---|---|
| index | 1,3 |
| help | 1 |
| search | 1,2,3 |
| word | 1 |
| article | 2 |
| quick | 2 |
| speed | 3 |
| up | 3 |
有了倒排索引,在查詢的時候我們就能夠根據關鍵詞快速、準確地找到對應的數據。
倒排索引的結構
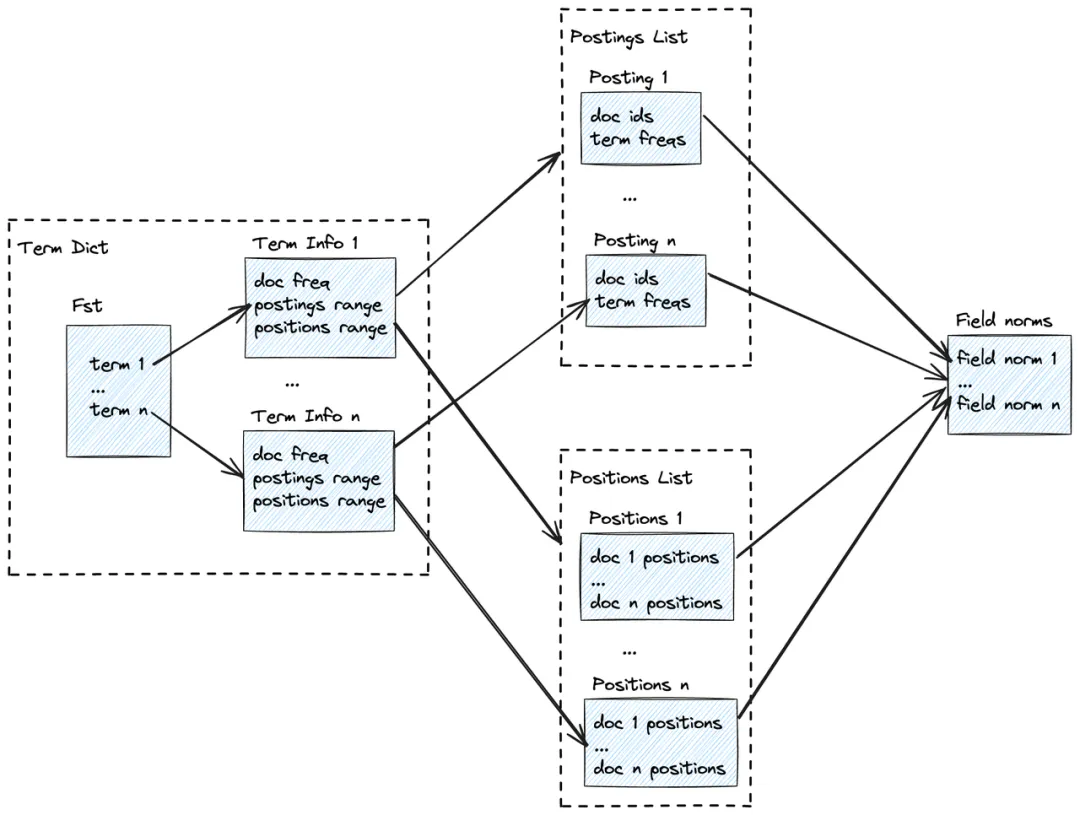
倒排索引的最主要功能是通過一個查詢詞(Term)找到相關的信息(TermInfo),通常使用 FST(Finite-State Transducer) 構建倒排詞典(Term Dict)來實現這個功能。在構建倒排 FST 時,為每個 Term 創建一個狀態,并將 TermInfo 作為輸出符號附加到該狀態。在查詢時,給定一個 Term ,可以在 FST 中找到與之對應的最終狀態,并從該狀態中提取出相應的 TermInfo。關于 FST 更詳細的原理可以參考這篇文章的介紹。
相比其它 key-value 類型的數據結構,例如 HashMap,Trie 等,FST 具有如下的優點:
- 快速查詢:FST 利用其確定性的狀態轉移特性,可以在非常短的時間內完成查詢操作。相比于其它數據結構,FST 的查詢速度更快,特別是對于大規模的索引和復雜的查詢條件。
- 小內存占用:FST 可以對倒排索引進行壓縮,占用的內存空間很少,這對于大規模數據集尤為重要,可以節省存儲成本并提高索引的加載和查詢效率。
- 高效的前綴和模糊匹配:FST 支持前綴匹配和模糊匹配,可以快速找到以給定前綴開頭的關鍵詞,或者根據模糊匹配規則查找相似的關鍵詞。
倒排索引除了根據查詢詞查找匹配的數據行之外,還需要計算查詢詞與數據的相關性,用于根據相關性進行排序。除了存儲倒排詞典(Term Dict)之外,還需要存儲如下的一些數據:
- 文檔標識符(DocId):使用數據表中一行數據的 RowId 來表示,用于過濾后查找原始數據。
- 詞語(Term):數據分詞并過濾處理后的一個詞,用作索引詞進行存儲在 FST 結構中,每個 Term 會映射到一個 TermInfo。
- 詞頻(Term freq):Term 在一行數據中出現的次數。
- 文檔頻率(Doc freq):包含一個 Term 的行數。
- 字段長度(Field norm):每一行數據包含的 Term 數,即文檔的長度。
- 位置(Position):記錄 Term 在每一行中出現的位置,用于詞組搜索。
以上數據中,文檔標識符(DocId)和詞頻(Term freq)存儲在倒排列表(Posting list)中,位置(Position)存儲在位置列表(Position list)中。TermInfo 包含三部分信息:
- 文檔頻率(Doc freq)。
- 倒排列表范圍(Postings Range):用于在倒排列表(Posting list)中找到查詢詞 Term 對應的信息。
- 位置列表范圍(Positions Range):用于在位置列表(Position list)中找到查詢詞 Term 對應的信息。
查詢時,首先通過 FST 找到 Term 對應的 TermInfo,再通過 TermInfo 找到文檔標識符(DocId)列表,確定匹配的數據行。如果需要排序,可以使用詞頻(Term freq)、文檔頻率(Doc freq)、字段長度(Field norm)等計算出每一行的評分( Score)。此外,如果是詞組搜索,還需要使用位置(Position)判斷詞組中的 Term 是否相鄰。
倒排索引數據的整體結構如下圖所示:
Score 算法
相關性評分( Score )的計算采用廣泛使用的 BM25(Best Matching 25)算法。BM25 算法的核心思想是根據查詢詞頻率(Term freq, TF)和逆文檔頻率(Inverse document freq, IDF)來計算文檔的相關性,將文檔和查詢表示為向量,然后計算兩個向量之間的余弦相似度。
BM25 算法的基本公式如下:
$$Score(D,Q)= {\textstyle \sum_{i=1}^{n}} IDF(q_{i})\times \frac{f(q_{i},D)\times(k_{1} + 1)}{f(q_{i},D) + k_{i}\times(1-b+b\times\frac{\left | D \right | }{avg(dl)}))} $$
其中:
- Score(D,Q) 是文檔 D 與查詢 Q 的相關性得分。
- $$q_{i}$$ 是查詢中的第 i 個詞。
- f($$q_{i$$, D)是詞 qi 在文檔 D 中出現的頻率。 詞頻(Term freq)是衡量一個詞在文檔中重要性的基本指標。詞頻越高,這個詞在文檔中的重要性通常越大。
- IDF($$q_i$$) 是詞 $$q_i$$ 的逆文檔頻率。逆文檔頻率是衡量一個詞對于整個文檔集合的獨特性或信息量的指標。它是由整個文檔集合中包含該詞的文檔數量決定的。一個詞在很多文檔中出現,其 IDF 值就會低,反之則高。這意味著罕見的詞通常有更高的IDF值,從而在相關性評分中擁有更大的權重。
- |D| 是文檔 D 的字段長度(Field norm)。用于調整詞頻的影響,因為較長的文檔可能僅因為它們的長度就有更高的詞頻。
- avg(dl)是所有文檔的平均長度。用于標準化不同文檔的長度,以便可以公平比較不同長度的文檔。
- $$k_1$$ 和 b 是可調的參數, $$k_1$$ 用于控制詞頻的飽和度,較高的 $$k_1$$ 值意味著詞頻對評分的影響更大,通常 $$k_1$$ 在 1.2 到 2 之間。 b 用于控制文檔長度對評分的影響的參數,取值在 0 到 1 之間,通常設為 0.75。
IDF 計算公式如下:
$$IDF(q_{i})= \ln_{}{(\frac{N-n(q_{i})+0.5}{n(q_{i})+0.5} + 1)} $$
其中
- N 是文檔集合中的文檔總數。
- n($$q_i$$) 是包含詞 $$q_i$$ 的文檔數量,即文檔頻率(Doc freq)。
查詢時,通過 BM25 算法可以為每一行數據計算出一個相關性的評分(Score),這個評分表示該行數據與用戶查詢的相關程度,可以用于對搜索結果進行排序,將最相關的數據顯示在前面。
倒排索引在 Databend 的實現
Databend 一個表的數據會分為若干個 segments,并在每個 segment 內進一步分為多個 blocks,這樣的設計有利于并行處理和查詢數據,從而提高整體的處理速度和響應性能,使得 Databend 能夠處理大規模數據集,提供高性能的數據處理和查詢能力,并保證數據的可靠性和可用性。在生成索引數據時,我們會為每個 block 生成一個單獨的索引文件,相比于包含多個 block 的大索引文件,單獨索引的設計有如下的優點:
- 空間利用效率:將每個 block 生成一個單獨的索引文件可以提高空間利用效率。由于每個索引文件僅包含一個 block 的數據信息,其大小相對較小。這種細粒度的索引文件設計可以減少索引文件的存儲空間占用,特別適用于大規模數據集的情況。
- 并行處理查詢:通過為每個 block 生成單獨的索引文件,可以實現并行處理查詢。在查詢時,可以同時加載多個 block 的索引文件,并發地進行查詢操作。這樣可以充分利用多核處理器或分布式計算資源,加快查詢的速度,提高系統的查詢并發性能。
- 方便與其它索引結合:每個 block 原本就有 Range 索引和 Bloom 索引,可以快速的進行范圍查詢和點查詢過濾,去掉不符合查詢條件的 block,這樣可以有效地減少需要加載的倒排索引文件數據,提高查詢效率。
- 索引維護和更新效率:單獨的索引文件設計有利于索引的維護和更新。當數據發生變化時,只需更新受影響的 block 的索引文件,而無需對整個表的索引文件進行操作。這樣可以減少索引維護的開銷,并支持實時數據的快速插入、更新和刪除。
對于索引文件的內部數據結構,Databend 使用開源的?tantivy?庫來實現倒排索引功能,主要有以下原因:
- 強大的功能:tantivy 是一個功能強大且成熟的全文搜索引擎庫,具有完善的的功能和高效的查詢速度。同時提供了豐富的查詢語法和搜索選項,能夠滿足各種類型的查詢需求。
- 可擴展性和靈活性:tantivy 的設計具有良好的可擴展性和靈活性。通過 tokenizer-api 可以實現自定義的分詞算法,方便接入不同的分詞庫來實現對多種語言的支持。
- 社區支持和活躍度:tantivy 是一個開源項目,擁有活躍的社區和廣泛的用戶群體。這意味著可以從社區中獲取技術支持、文檔資源,并且能夠與其他使用 tantivy 的開發者進行交流。這對于 databend 來說是一個重要的因素,可以借鑒和共享倒排索引的最佳實踐。
Databend 倒排索引的整體結構如下圖所示:

倒排索引的使用
為了使用倒排索引,我們需要首先創建倒排索引,以文章開頭的測試表為例:
CREATE INVERTED INDEX idx1 ON test(title);REFRESH INVERTED INDEX idx1 ON test;創建索引時可以指定一些配置項,例如是否支持中文分詞,是否開啟 stop words 過濾等。更多的詳細信息可以查看?Databend 相關文檔。REFRESH 命令主要用于刷新已有的數據生成索引,新插入的數據會自動生成倒排索引,不需要額外操作。
在查詢語法方面,我們參考了 elasticsearch 的設計,提供了?match,?query?和?score?函數。例如,可以通過下面的語法查詢數據:
SELECT id, score(), title FROM test WHERE match(title, 'index');
┌─────────────────────────────────────────────────────────┐
│ id │ score() │ title │
│ Nullable(Int32) │ Float32 │ Nullable(String) │
├─────────────────┼────────────┼──────────────────────────┤
│ 1 │ 0.45315093 │ Index helps search words │
│ 3 │ 0.45315093 │ Index speeds up searches │
└─────────────────────────────────────────────────────────┘SELECT id, score(), title FROM test WHERE query('title:"speeds up"');
┌────────────────────────────────────────────────────────┐
│ id │ score() │ title │
│ Nullable(Int32) │ Float32 │ Nullable(String) │
├─────────────────┼───────────┼──────────────────────────┤
│ 3 │ 1.8913201 │ Index speeds up searches │
└────────────────────────────────────────────────────────┘SELECT id, score(), title FROM test WHERE query('title:words OR articles') ORDER BY score() DESC;
┌─────────────────────────────────────────────────────────┐
│ id │ score() │ title │
│ Nullable(Int32) │ Float32 │ Nullable(String) │
├─────────────────┼────────────┼──────────────────────────┤
│ 2 │ 1.0596459 │ Search articles quickly │
│ 1 │ 0.94566005 │ Index helps search words │
└─────────────────────────────────────────────────────────┘query 函數支持了多種查詢語法,可以實現復雜的查詢功能,相關語法可以查看?query 函數文檔。
存在的問題和未來規劃
Databend 的倒排索引在目前存在一些不足之處,主要問題是索引文件中的倒排列表(Posting list)和位置列表(Position list)占用空間過大,導致初次加載時速度較慢,并且占有較大的內存空間。為了解決這個問題,我們會考慮使用一些壓縮算法或更緊湊數據結構來減小索引文件的存儲需求,加快查詢速度。另外,我們會進一步完善索引配置項和查詢語法的支持,來滿足更多的應用場景的使用需求。








)


)
![uni-app項目在微信開發者工具打開時報錯[ app.json 文件內容錯誤] app.json: 在項目根目錄未找到 app.json](http://pic.xiahunao.cn/uni-app項目在微信開發者工具打開時報錯[ app.json 文件內容錯誤] app.json: 在項目根目錄未找到 app.json)



詳解)
(一步步實現+源碼)前端篇(一))

