本文使用NST特征蒸餾實現deeplabv3+模型對剪枝后模型的蒸餾過程;
一、NST特征蒸餾簡介
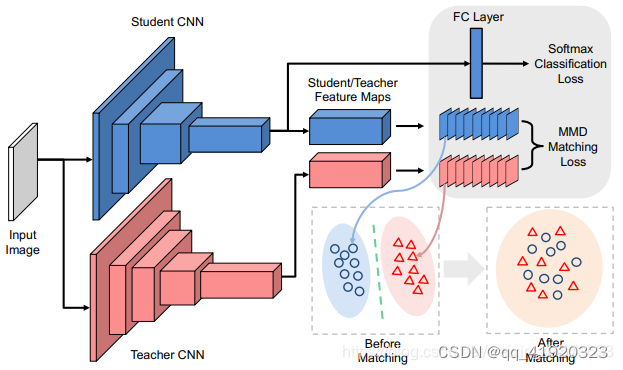
下面是兩張疊加了熱力圖(heat map)的圖片,從圖中很容易看出這兩個神經元具有很強的選擇性:左圖的神經元對猴子的臉部非常敏感,右側的神經元對字符非常敏感。這種激活實際上意味著神經元的選擇性,即什么樣的輸入可以觸發這些神經元。換句話說,一個神經元高激活的區域可能共享一些與任務相關的相似特性,而這種相似特征,即為學生網絡向教師網絡學習的目標。

如下圖所示為神經元選擇性遷移的架構。學生網絡不僅利用真正的標簽訓練,而且還模仿了教師網絡中間層的激活分布。圖中的每個點或三角形表示其對應的濾波器的激活圖。
NST損失函數如下所示:
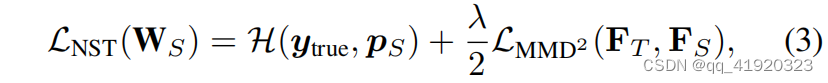
其中,第一項 H(y,p)為交叉熵損失,y是ground truth標簽,p是學生模型的輸出概率;第二項為最大平均差異(MMD)損失,即為NST損失,用來衡量教師和學生特征之間的差異;MMD的想法就是求兩個隨機變量在高維空間中均值的距離,
卷積模型的剪枝、蒸餾---蒸餾篇--NST特征蒸餾(以deeplabv3+為例)
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/web/12891.shtml 繁體地址,請注明出處:http://hk.pswp.cn/web/12891.shtml 英文地址,請注明出處:http://en.pswp.cn/web/12891.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

程序員績效管理-序言
開辟一個新專欄專門討論程序員績效管理。作為軟件開發企業,公司的命脈掌握在程序員手中。程序員的績效管理是個超級難題。小張和老王專欄介紹了兩個典型的人員。但是這是兩個虛擬的極端人員,大部分開發人員沒有那么容易分辨。1個任務,應該1天…

LabVIEW軟件開發工程師需要具備哪些能力與素質?
成為一名優秀的LabVIEW軟件開發工程師,需要具備以下能力與素質:
技術能力 LabVIEW編程技能: 精通LabVIEW編程,能夠熟練使用其圖形化編程界面。熟悉LabVIEW中的各種功能模塊和工具包,如數據采集(DAQ&#x…

如何配置Nacos的健康檢查參數?
在微服務架構中,服務注冊與發現以及健康檢查是至關重要的組件。Nacos,作為阿里巴巴開源的一個更易于構建云原生應用的動態服務發現、配置和服務管理平臺,廣泛應用于微服務架構中。在Nacos中,服務的健康檢查是一個核心功能…

【Python】使用MySQL綜合案例
數據說明:
一月份各省銷售數據:csv格式
二月份各省銷售數據:json格式
實現要求:將兩個文件中的數據存儲到數據庫中,并反向從數據庫中讀取數據存儲為json格式文件
本文提供數據
完成案例所需基礎
【Python】基礎知識(函數與數…
![C++ 日志庫 log4cpp 編譯、壓測及其范例代碼 [全流程手工實踐]](http://pic.xiahunao.cn/C++ 日志庫 log4cpp 編譯、壓測及其范例代碼 [全流程手工實踐])
C++ 日志庫 log4cpp 編譯、壓測及其范例代碼 [全流程手工實踐]
文章目錄 一、 log4cpp官網二、下載三、編譯1.目錄結構如下2.configure 編譯3.cmake 編譯 四、測試五、壓測源碼及結果1.運行環境信息2.壓測源碼3.壓測結果 文章內容:包含了對其linux上的完整使用流程,下載、編譯、安裝、測試用例嘗試、以及一份自己寫好…
)
Qt | QTimer 類(計時器)
01、相關知識回顧 Qt C++ | QTimer經驗總結Qt | QDateTimeEdit、QDateEdit類和QTimeEdit類02、QTimer 類
1、QTimer 類是 QObejct 的直接子類,該類用于實現計時器,QTimer 類未繼承自 QW

IT革新狂潮:引領未來的技術趨勢
方向一:技術革新與行業應用 當前現狀: 量子計算:量子計算的研究正在加速,盡管目前仍處于初級階段,但其在藥物研發、加密技術和材料科學等領域的應用潛力已被廣泛認可。 虛擬現實(VR)與增強現實…
)
湖南大學OS-2018期末考試(不含解析)
前言
不知道哪里翻出來的一張,看著確實像期末考卷,暫且放一下。或許做過,或許沒做過。
總之答案不記得了。做完可以評論區發一下或者找我發出來。
共6道大題。 一、(30%)
1. (6%) 進程間通信的兩種方法分別是什么&…
)
完成所有任務的最少時間 - (LeetCode)
前言
今天也是很無精打采的一天,早上看到這道題,都有點懵逼,開始也不懂如何入手,既然自己搞不定,就順便測試了一下AI吧,測試了通義千問和文心一言,把題目拿去那里問,可以把解題思路…


error Error: certificate has expired
用yarn命令安裝依賴的時候遇到報錯: 原因:可能是開了服務器代理訪問導致ssl安全證書失效
解決方法:
在終端輸入 yarn config set "strict-ssl" false -g
yarn config set "strict-ssl" false -g
然后再安裝依賴就不…

RS2227XN功能和參數介紹及PDF資料
RS2227XN是一款模擬開關/多路復用器 品牌: RUNIC(潤石) 封裝: MSOP-10 描述: USB2.0高速模擬開關 開關電路: 雙刀雙擲(DPDT) 通道數: 2 工作電壓: 1.8V~5.5V 導通電阻(RonVCC): 10Ω 功能:模擬開關/多路復用器 USB2.0高速模擬開關 工作電壓范圍:1.8V ~ 5…

Linux運行級別介紹
unlevel 運行級別 cat /etc/inittab
0 - halt (Do NOT set initdefault to this) --關機 1 - Single user mode --單用戶(進入單用戶不需要帳號與密碼) 2 - Multiuser, without NFS (The same as 3, if you do not have networking) 多用戶(沒有網絡) 3…

Java基礎篇常見面試問題總結
文章目錄 1. 你是怎樣理解 OOP面向對象?2. 重載與重寫區別3. 接口與抽象類的區別4. 深拷貝與淺拷貝的理解5. 什么是自動拆裝箱? int和 Integer有什么區別6. 和 equals()區別7. String類 能被繼承嗎為什么用 final修飾8. final、finally、finalize區別 1. 你是怎樣理…
)
【C語言】6.C語言VS實用調試技巧(1)
文章目錄 1.什么是 bug2.什么是調試(debug)?3.Debug 和 Release4.VS調試快捷鍵4.1 環境準備4.2 調試快捷鍵 5.監視和內存觀察5.1 監視5.2 內存 1.什么是 bug
bug現在一般是指在電腦系統或程序中,隱藏著的一些未被發現的缺陷或問題…
:版本管理)
Git使用(3):版本管理
一、查看歷史 編寫一個java類進行測試 選擇Git -> Show Git Log查看日志。 第一次修改推送到遠程倉庫了,所以有origin(遠程倉庫地址),第二次修改只提交到本地倉庫所以沒有。 二、版本回退
1、本地回退 在要回退的版本上右鍵&a…

XLSX文件刪除了怎么找回?8個恢復方法,太實用了!
U盤作為一種便攜的存儲設備,隨之而來的數據丟失問題也讓人頭疼。尤其是當U盤中的XLSX文件(Excel 2007及以后版本的默認文件格式)被誤刪除或丟失時,如何高效找回這些數據成為了許多人關注的焦點。 本文將從XLSX文件的特性、U盤格式…

C++set關聯式容器
Cset
1. 關聯式容器
vector、list、deque、forward_list(C11)等STL容器,其底層為線性序列的數據結構,里面存儲的是元素本身,這樣的容器被統稱為序列式容器。而map、set是一種關聯式容器,關聯式容器也是用來存儲數據的࿰…

深度盤點在當今經濟形勢下資深項目經理或PMO的或去或從
在當今經濟形勢下,資深項目經理(Project Manager)或項目管理辦公室(PMO)的去向和選擇受到多種因素的影響。以下是對他們可能面臨的或去或從的深度盤點: 1、發展去向
1. 深化專業領域:在經濟形勢…
:Linux基礎入門安裝和實操手冊)
Linux程序開發(一):Linux基礎入門安裝和實操手冊
Tips:"分享是快樂的源泉💧,在我的博客里,不僅有知識的海洋🌊,還有滿滿的正能量加持💪,快來和我一起分享這份快樂吧😊! 喜歡我的博客的話,記得…