? ? ? ? 如果你覺得openai的gpt沒有隱私,或者需要離線使用gpt,還是打造專業領域知識,可以借用AnythingLLM+Ollama輕松實現本地GPT.
AnythingLLM+Ollama 實現本地GPT步聚:
1 下載 AnythingLLM軟件
AnythingLLM官網地址:
AnythingLLM | The ultimate AI business intelligence tool
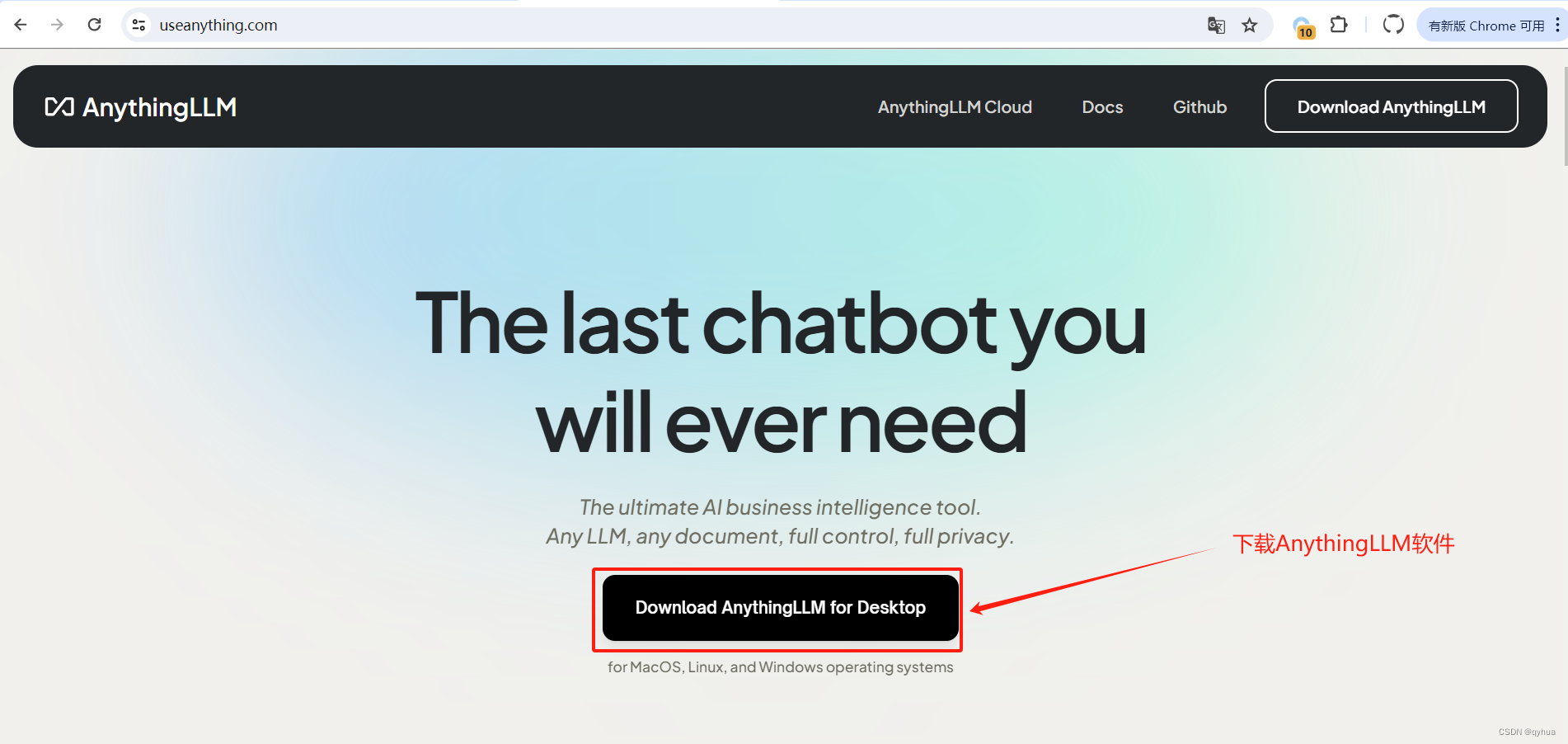
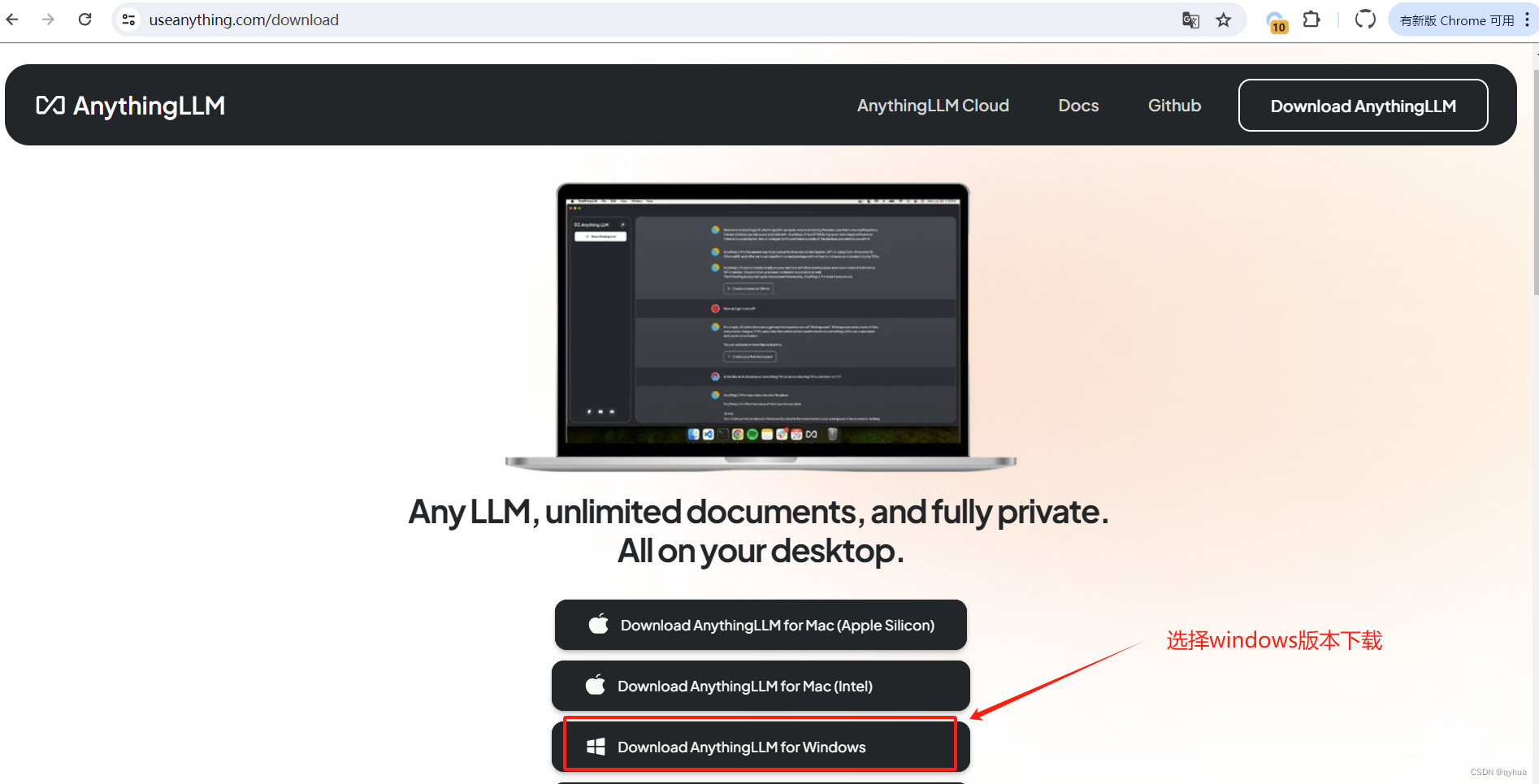
2 下載 Ollama
Ollama官網下載:?
?Ollama
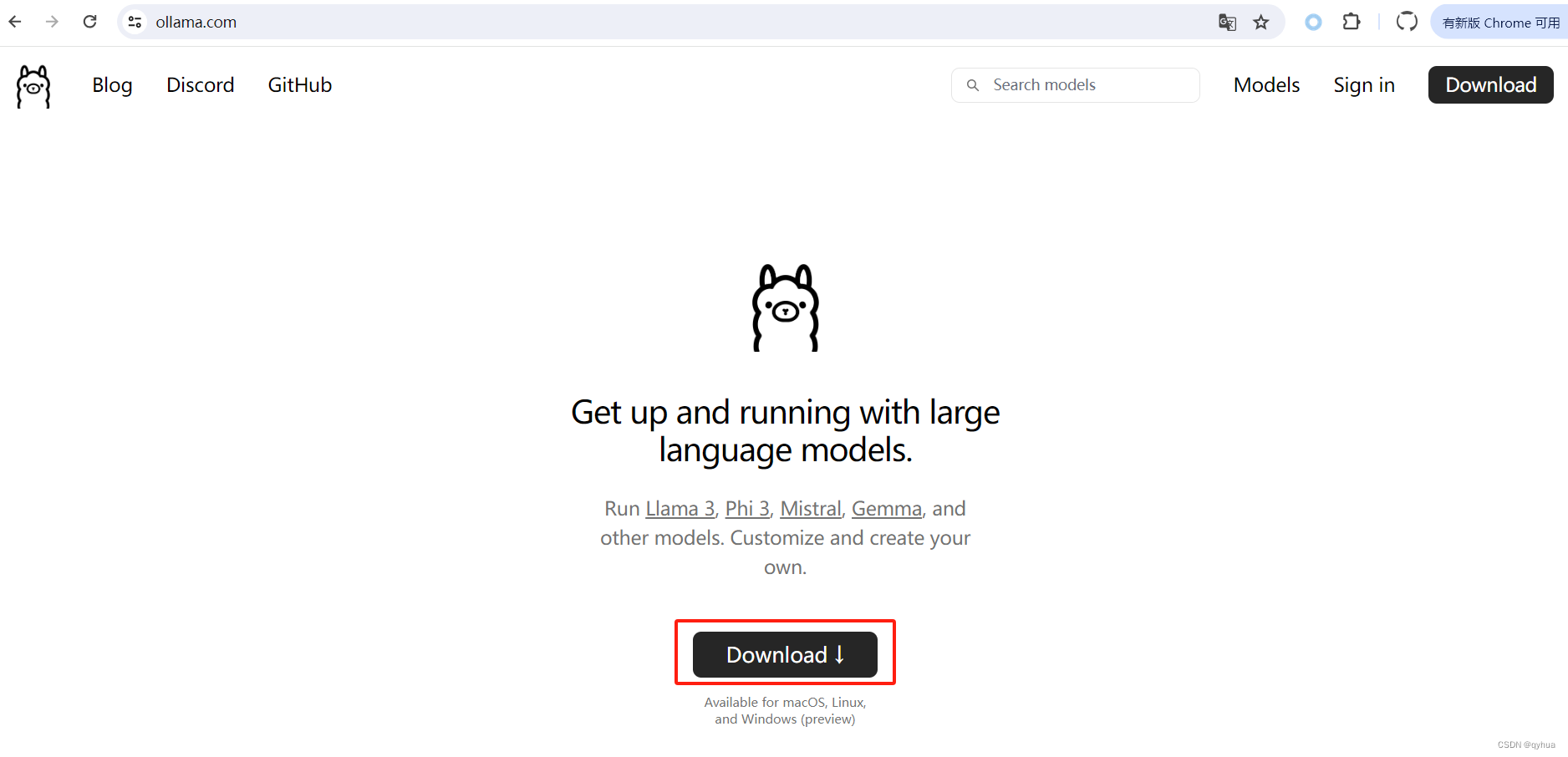
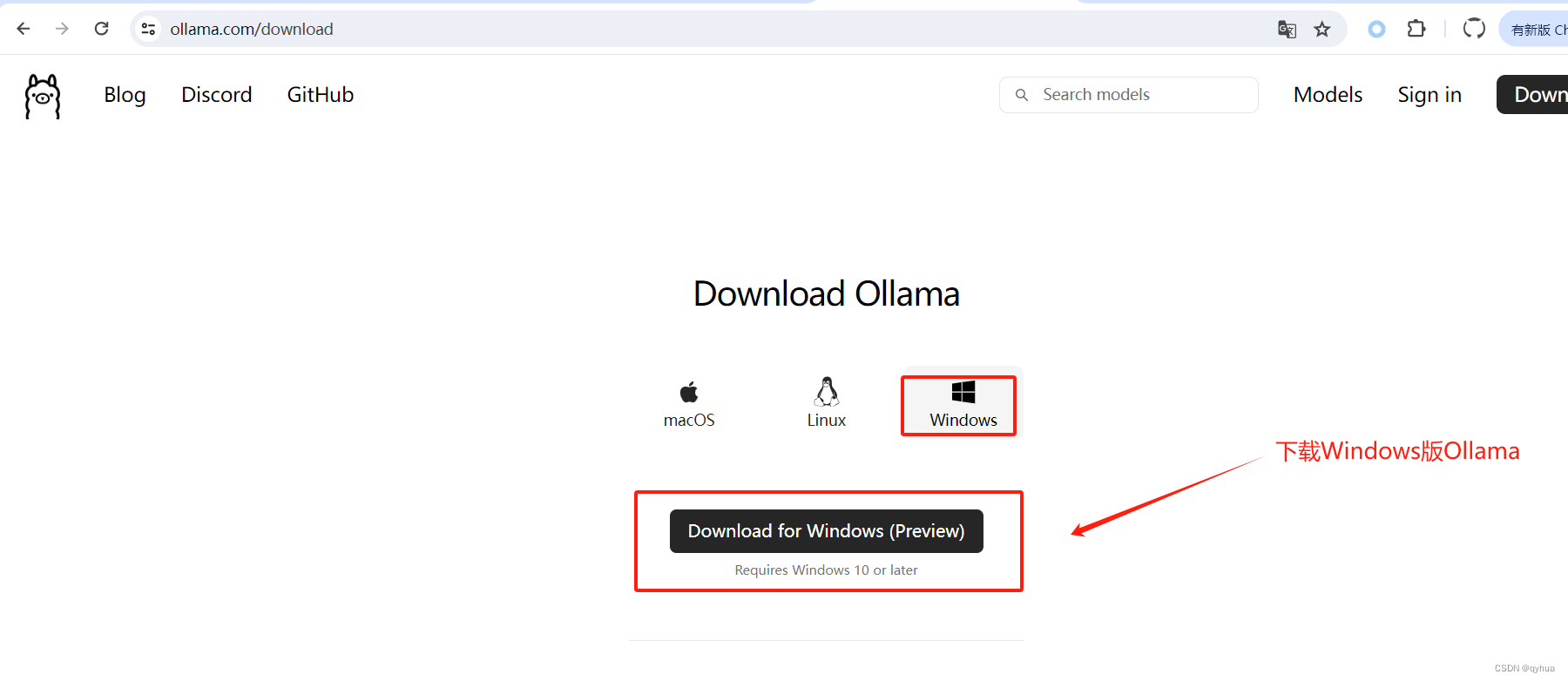
下載好的兩個軟件如下圖:?
3 安裝AnythingLLM
和安裝其它軟件一樣雙擊安裝即可,如下圖:

安裝成功后,我們接著再安裝Ollama。
4 安裝Ollama
和安裝其它軟件一樣雙擊安裝即可,安裝成功后右下角有個運行圖標如下圖:

?配置 Ollama
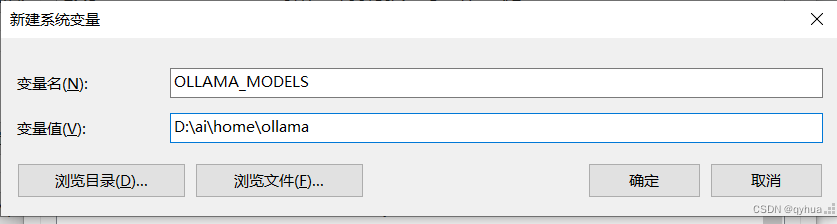
?1 配置Ollama模型數據路徑
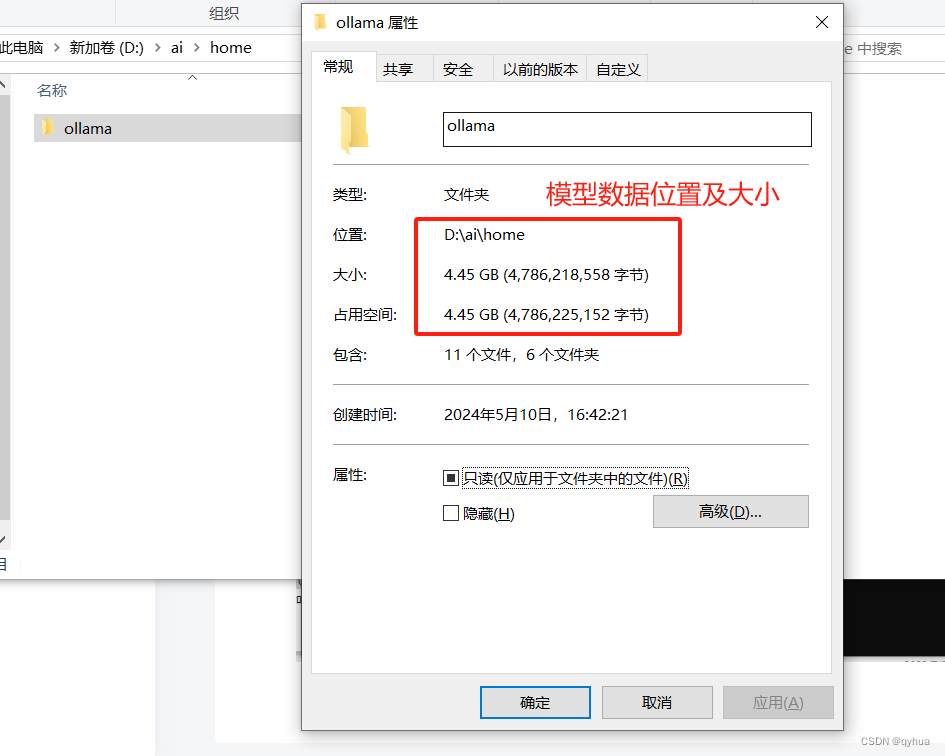
模型數據默認是保存在C盤的,由于模型數據特別大,所以這里一定要記住配置模型數據的路徑,只里設置系統變量OLLAMA_MODELS的值為模型數據保存路徑,如下圖:
?2 選擇配置主模型
? 這里考慮到我們平時主要處理中文相關資料,選擇阿里的千問模型,結合當前環境筆記是16G內存,我們這里選擇千問7b(占用8G內存):
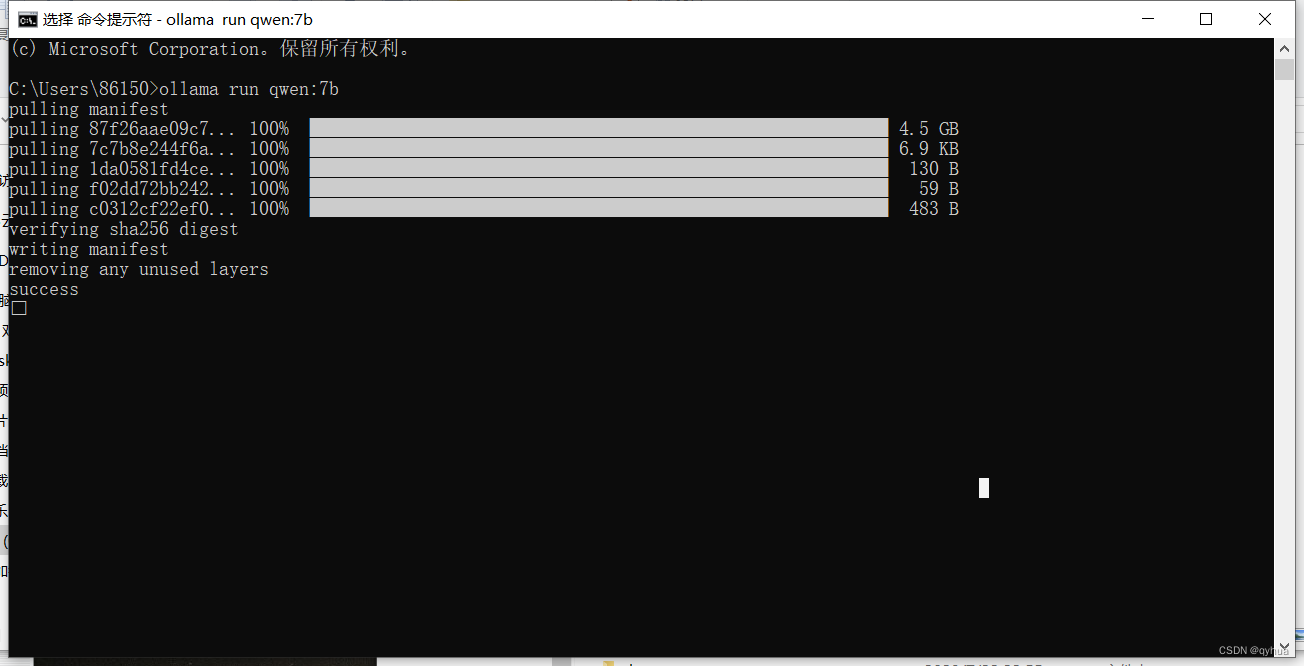
? 運行選擇的模型
ollama run qwen:7b首次運行會下載該模型,如下圖:?

下載完成,如下圖:?
3?選擇配置嵌入模型
?嵌入模型并不直接生產數據,主要用于把本地知識doc.pdf txt等文檔保存在向量數據庫時用到。
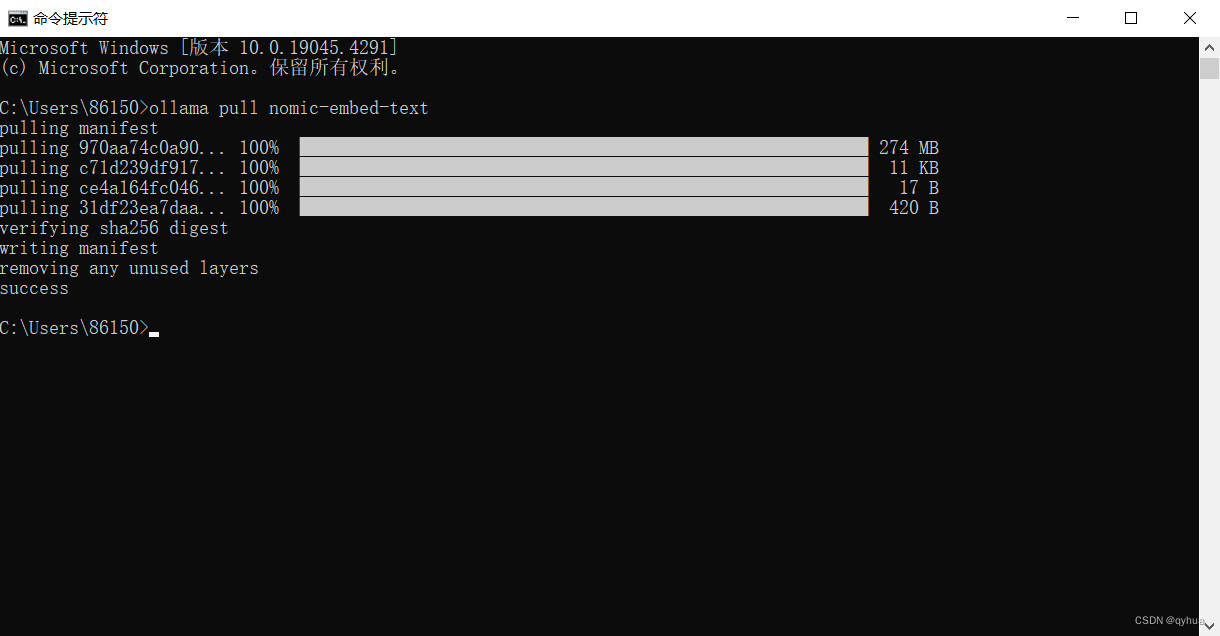
這里我們選擇?nomic-embed-text ,它是具有大型令牌上下文窗口的高性能開放嵌入模型。
ollama pull nomic-embed-text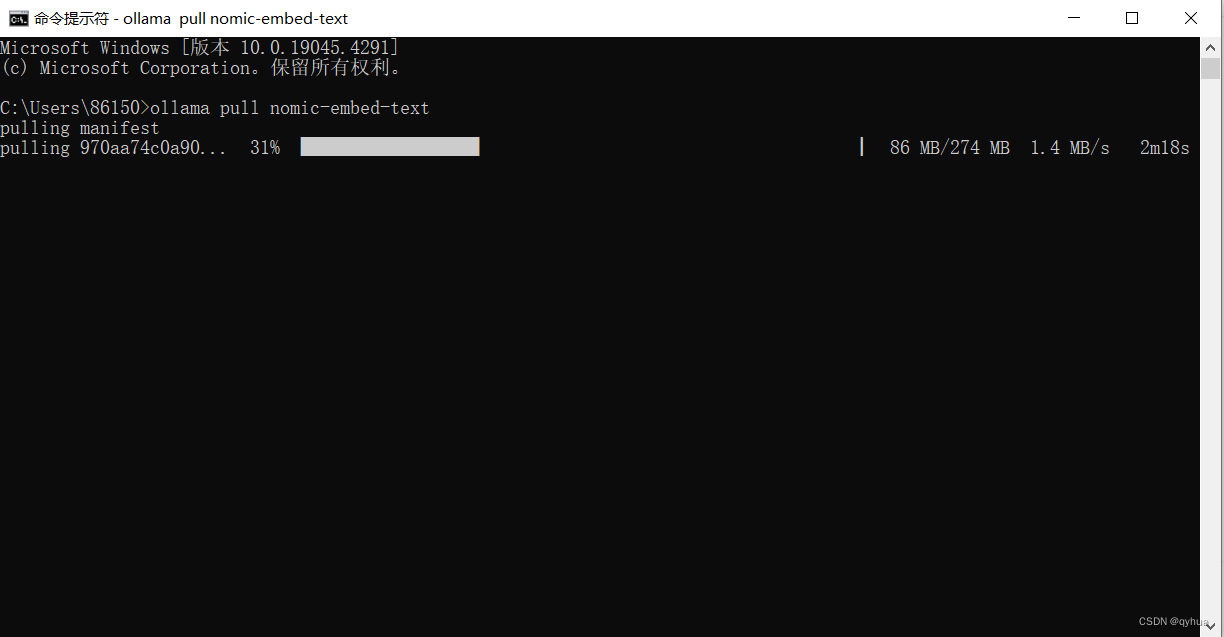
5 配置AnythingLLM
打開AnythingLLM 進行設置項,如下圖:

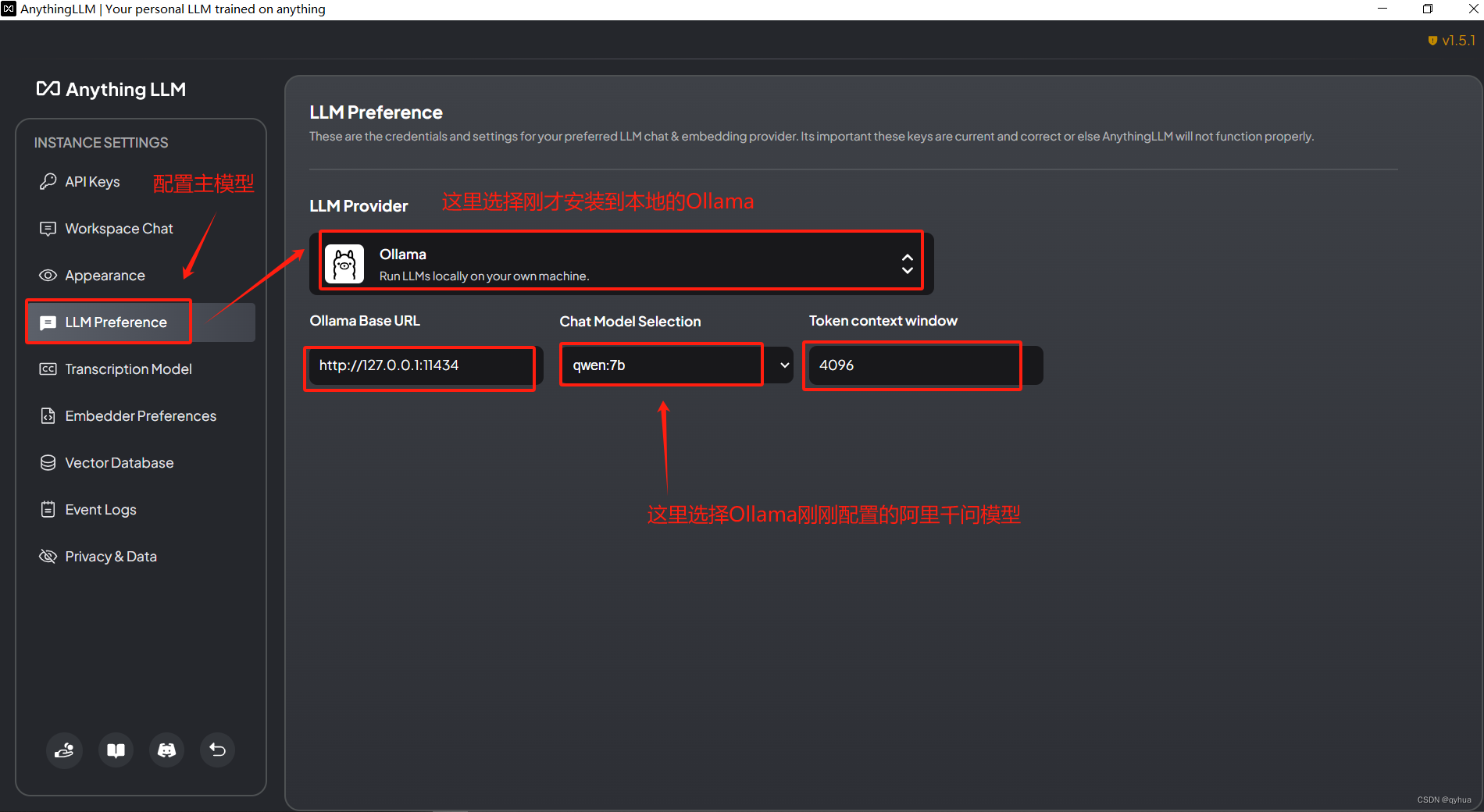
1 配置主模型
這里選擇上面Ollama下載的千問模型
2 配置嵌入模型
這里選擇配置與上面安裝的模型nomic-embed-text一致,如下圖:
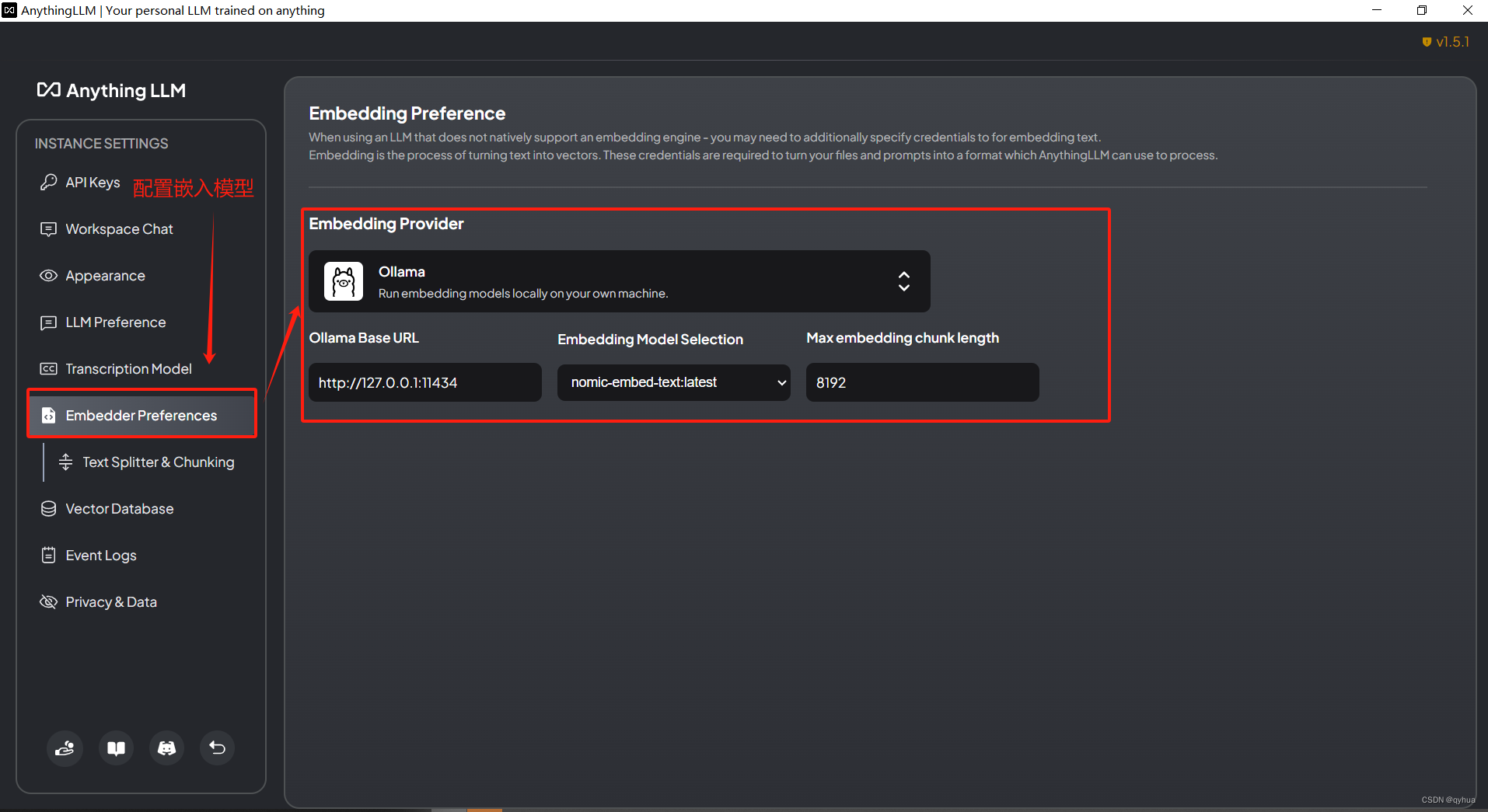
配置嵌入模型在處理上傳知識文件保存到向量數據時兩個關鍵參數:
- ??分塊大小 (這是單個向量中允許存在的最大字符數量。例如,如果設置為8192,意味著每個文本塊或向量最多包含8192個字符。)
- ?文本塊重疊度(這是指在兩個相鄰文本塊切分過程中允許的最大字符重疊量。設置重疊可以幫助保持信息的連續性,避免因嚴格切分導致的語義斷裂,尤其是在信息的關鍵邊界附近。)
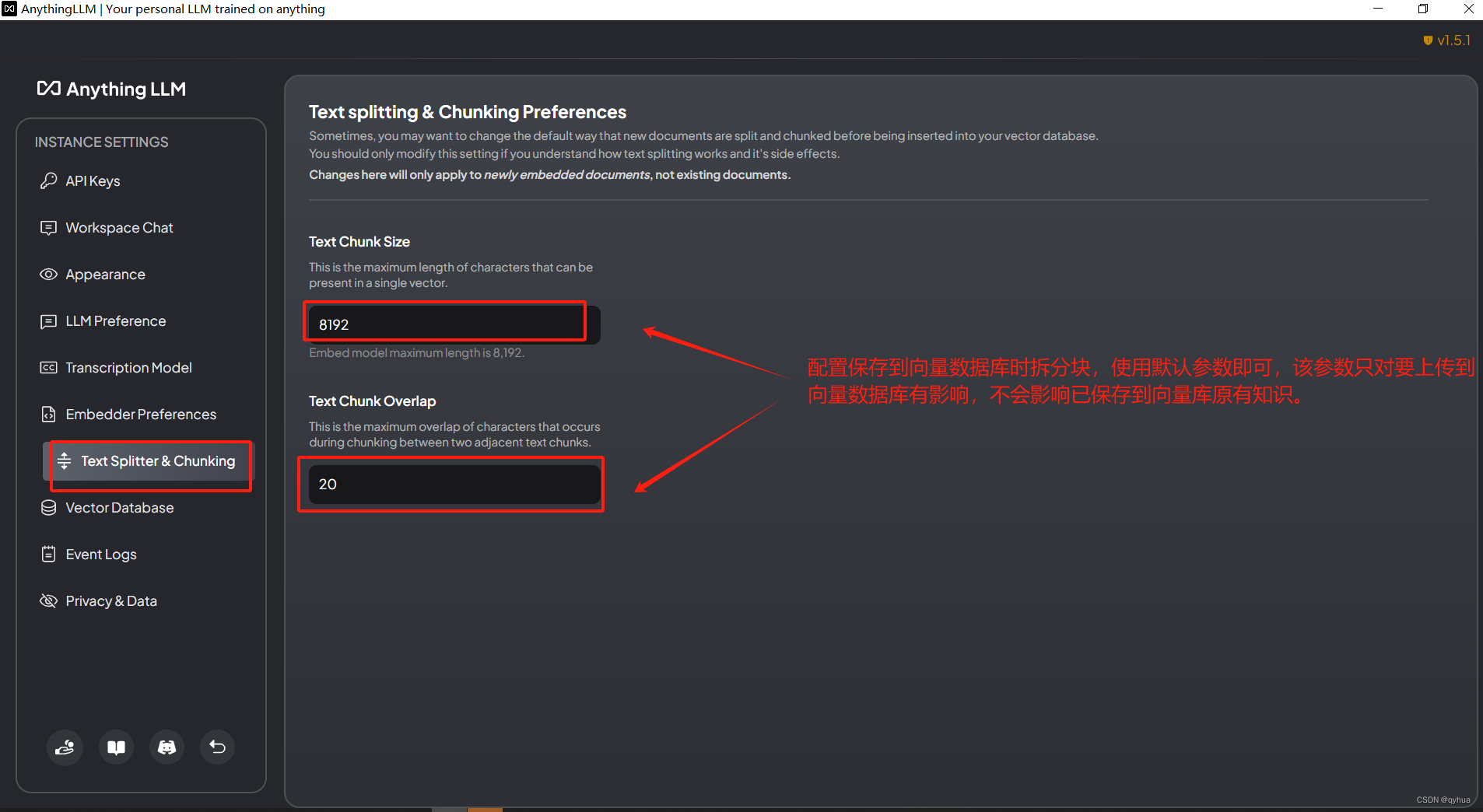
? 注意:這兩個參數僅適用于新嵌入的文檔,對已存在的文檔沒有影響。?
?3 配置使用向量數據庫
設置使用向量數據庫,沒有特別需求使用默認即可,如下圖:
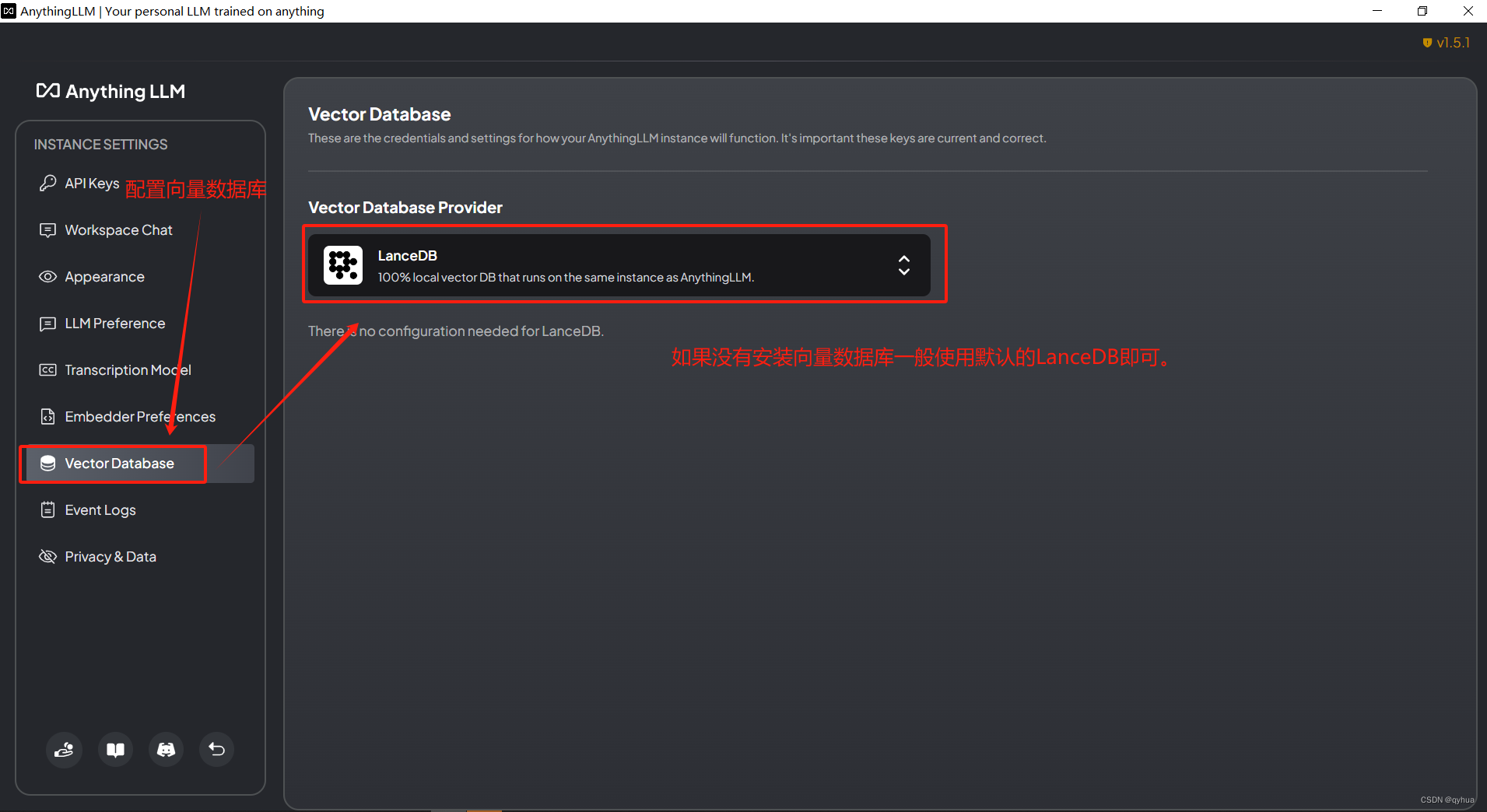
?說明:LanceDB是一個開源的無服務器向量數據庫,專為處理人工智能應用中的大規模多模態數據(如文本、圖像、視頻、點云等)而設計。它簡化了高維向量的檢索、過濾和管理過程,無需用戶管理和維護服務器基礎設施,從而降低了運維成本并提高了開發效率。?
配置完成,如下圖:?
 ?
?
6 開始使用本地GPT(使用AnythingLLM)
現在我們開始使用AnythingLLM:
1 創建空間
? AnythingLLM 有一個很好的概念工作空間,有點像我們平時用eplise創建項目一樣,一個項目一個空間,不同的空間還可以單獨配置,這樣可以很好的劃分不同類類型的專業領域。
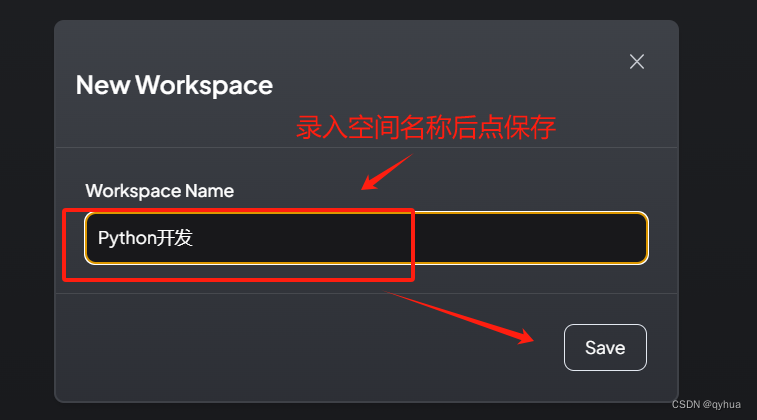 ?保存空間名稱后,即可正常提問
?保存空間名稱后,即可正常提問
開始問答:
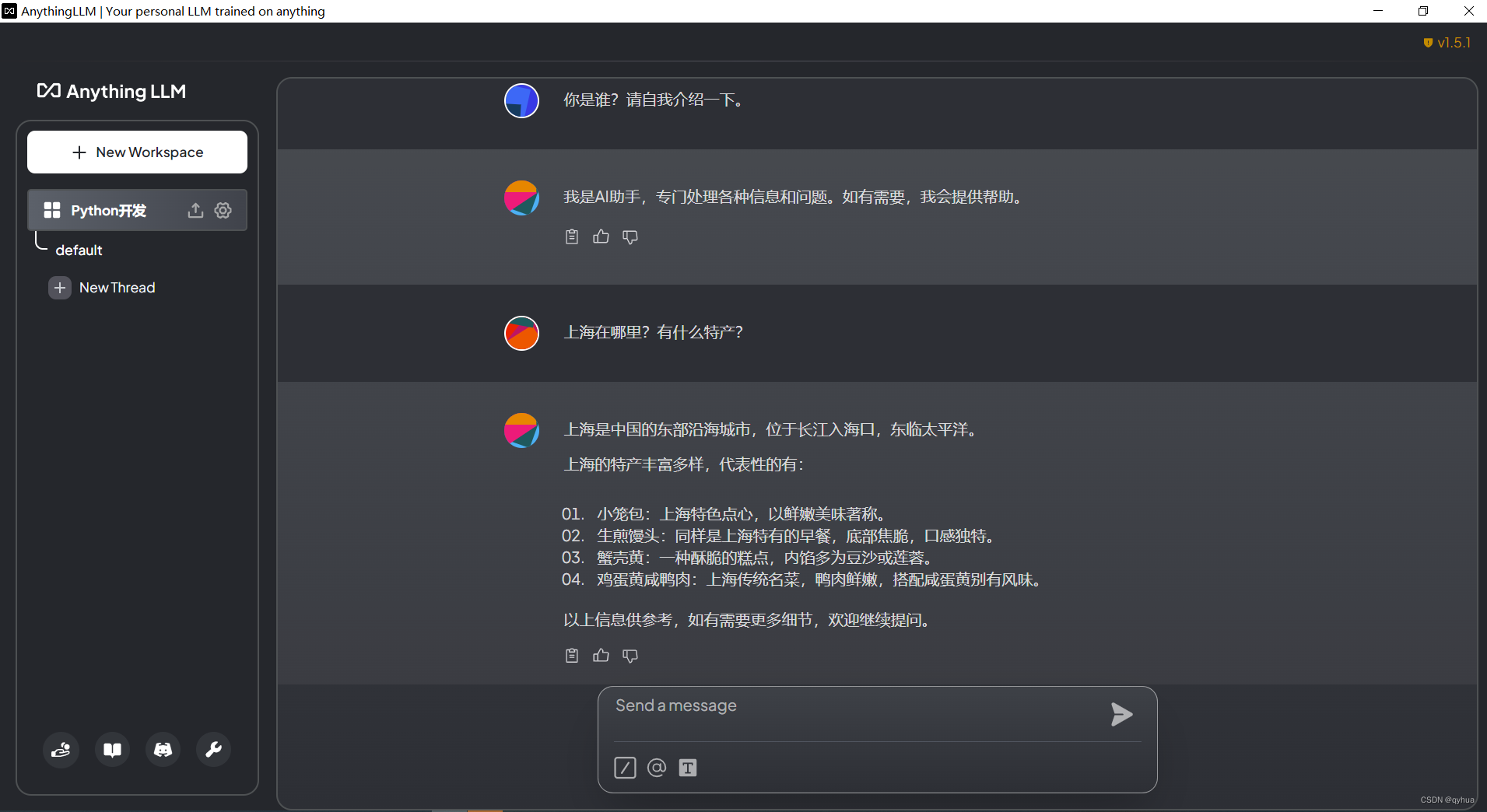 因為是離線,而本地又沒有顯卡,所以回答問題時并不是很快,而且CPU會拉升,如下圖:?
因為是離線,而本地又沒有顯卡,所以回答問題時并不是很快,而且CPU會拉升,如下圖:?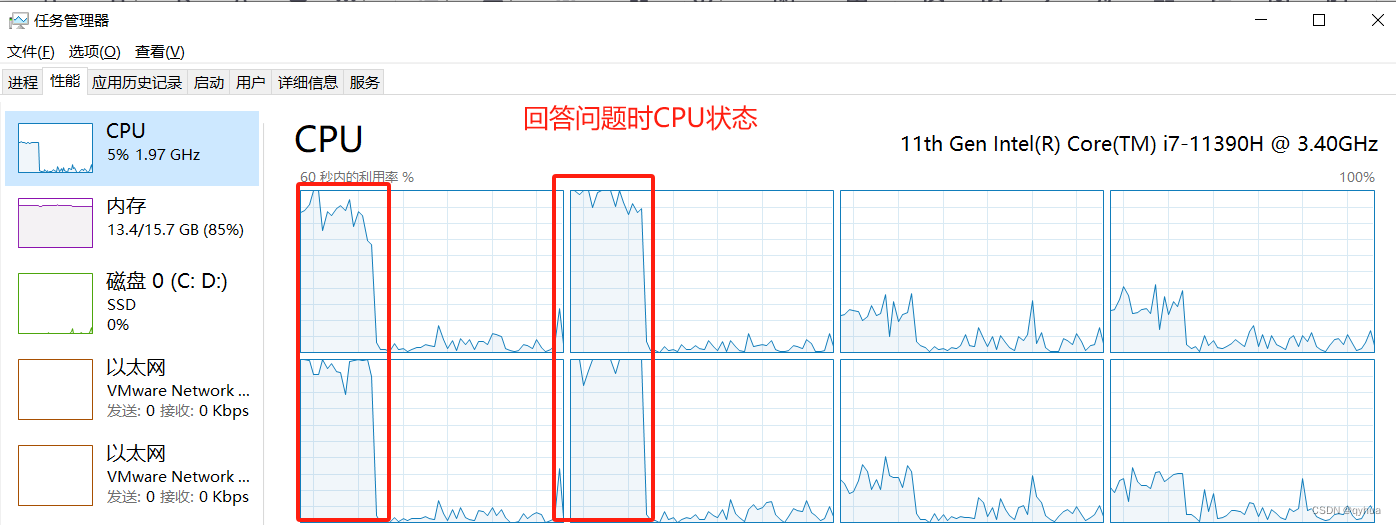
 ?ollama 服務CPU占用50%,內存12G,消耗挺大的。
?ollama 服務CPU占用50%,內存12G,消耗挺大的。
2 可選擇單獨配置參數
? 為當前空間單獨配置參數(默認使用設置中的配置)?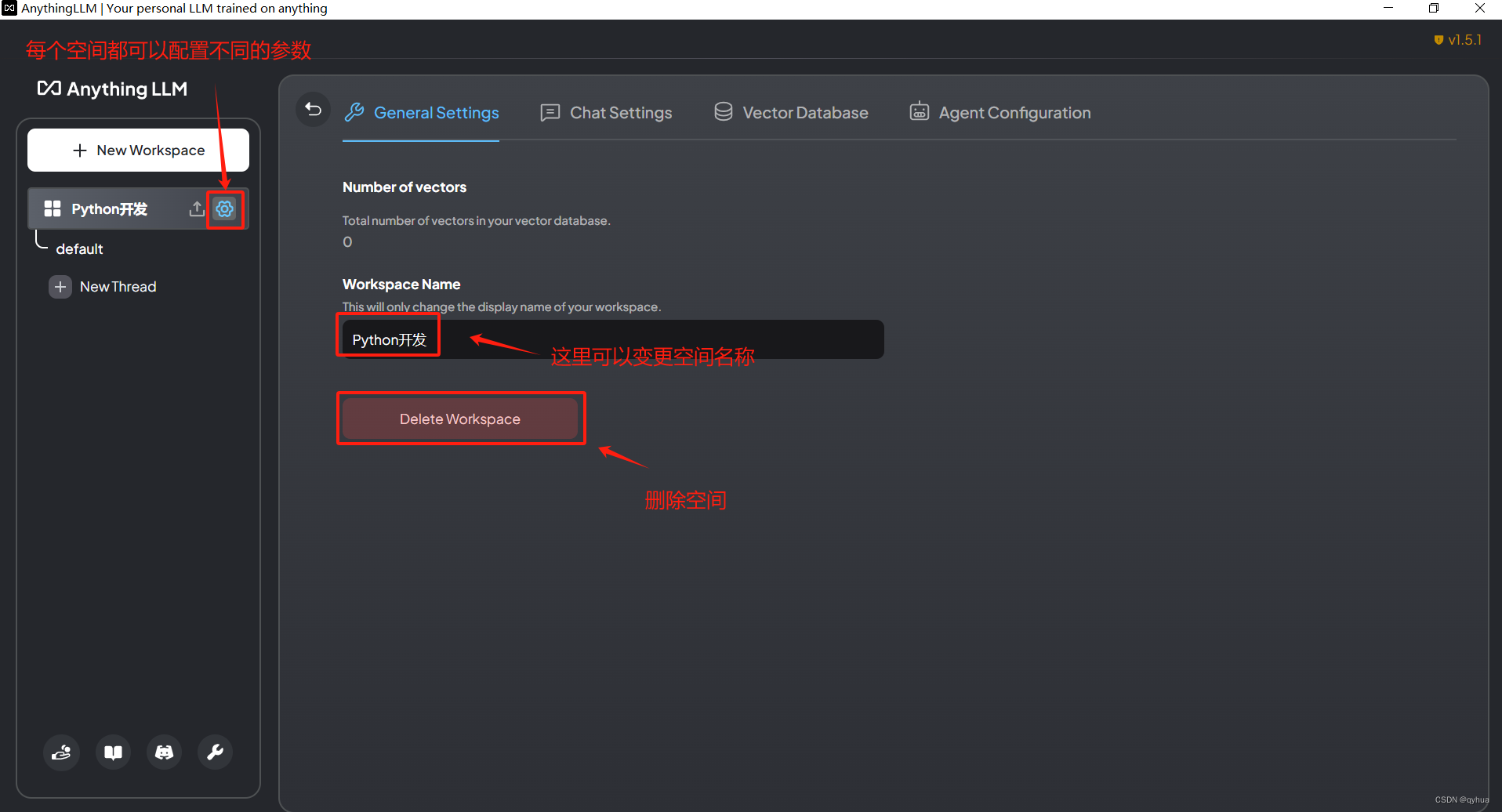
配置聊天模型,這個配置很重要,如果只是針對知識庫直接設置成查詢模型即可,如下圖:?
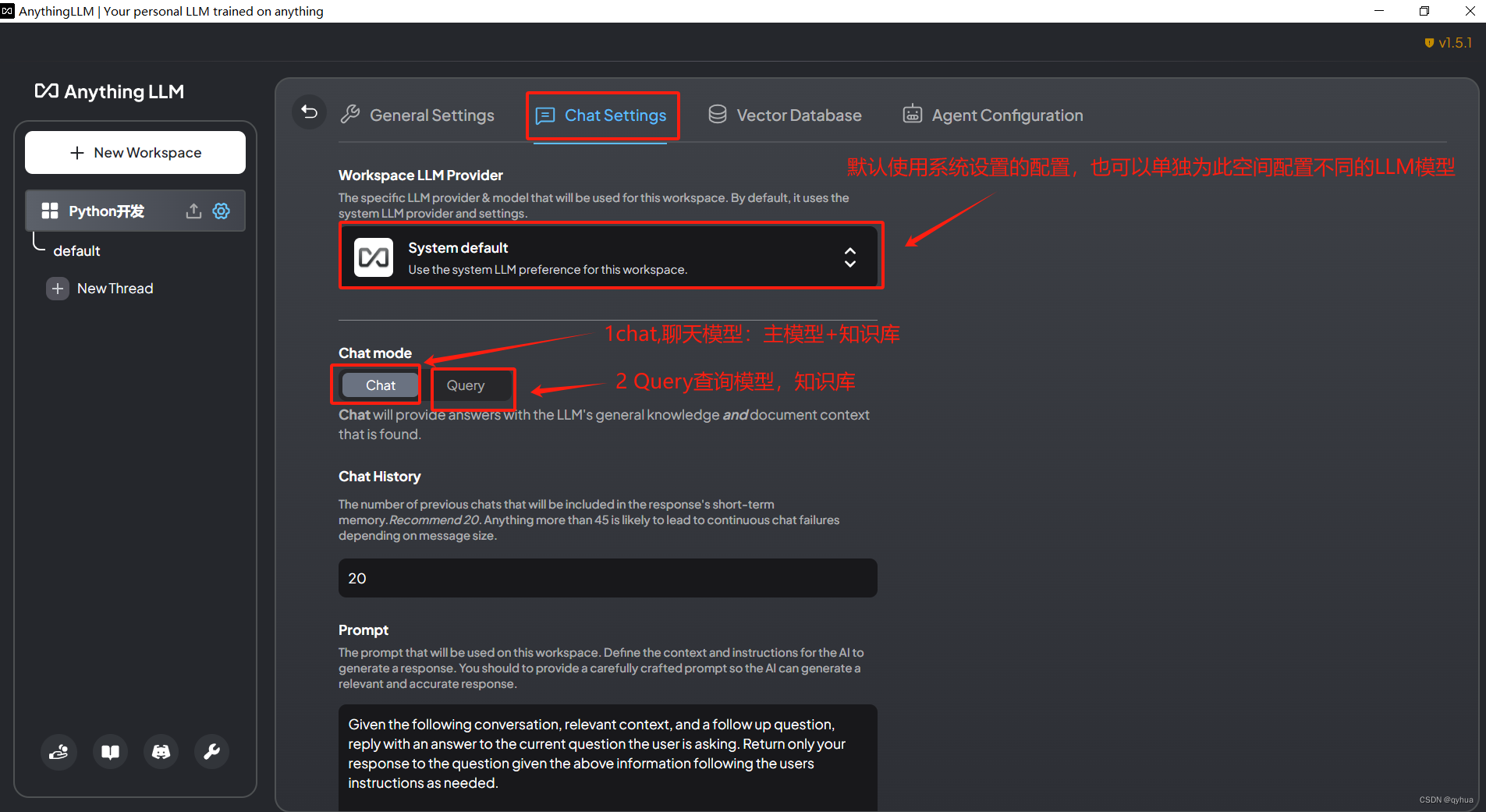 ?
?
3 知識庫使用
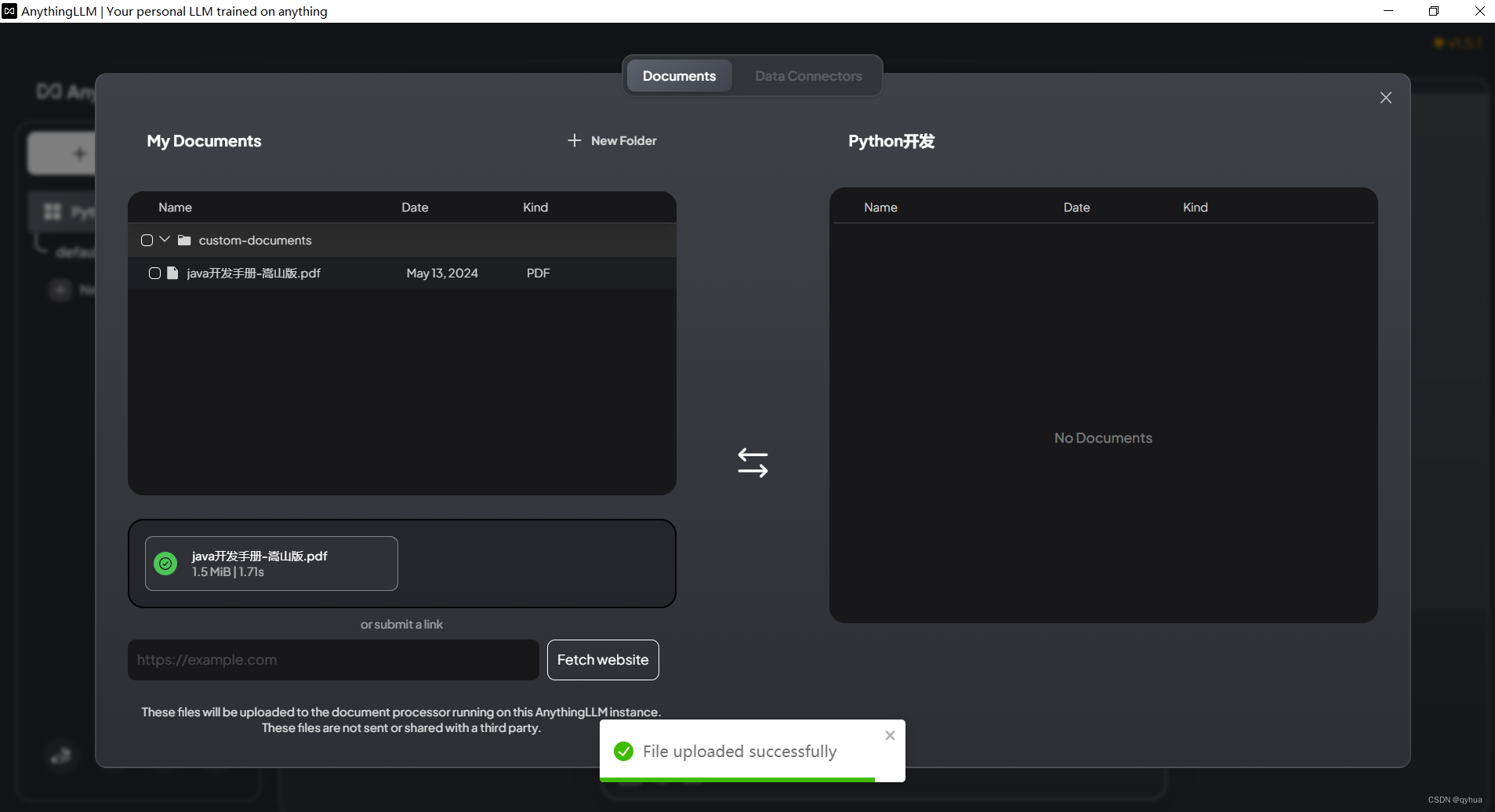
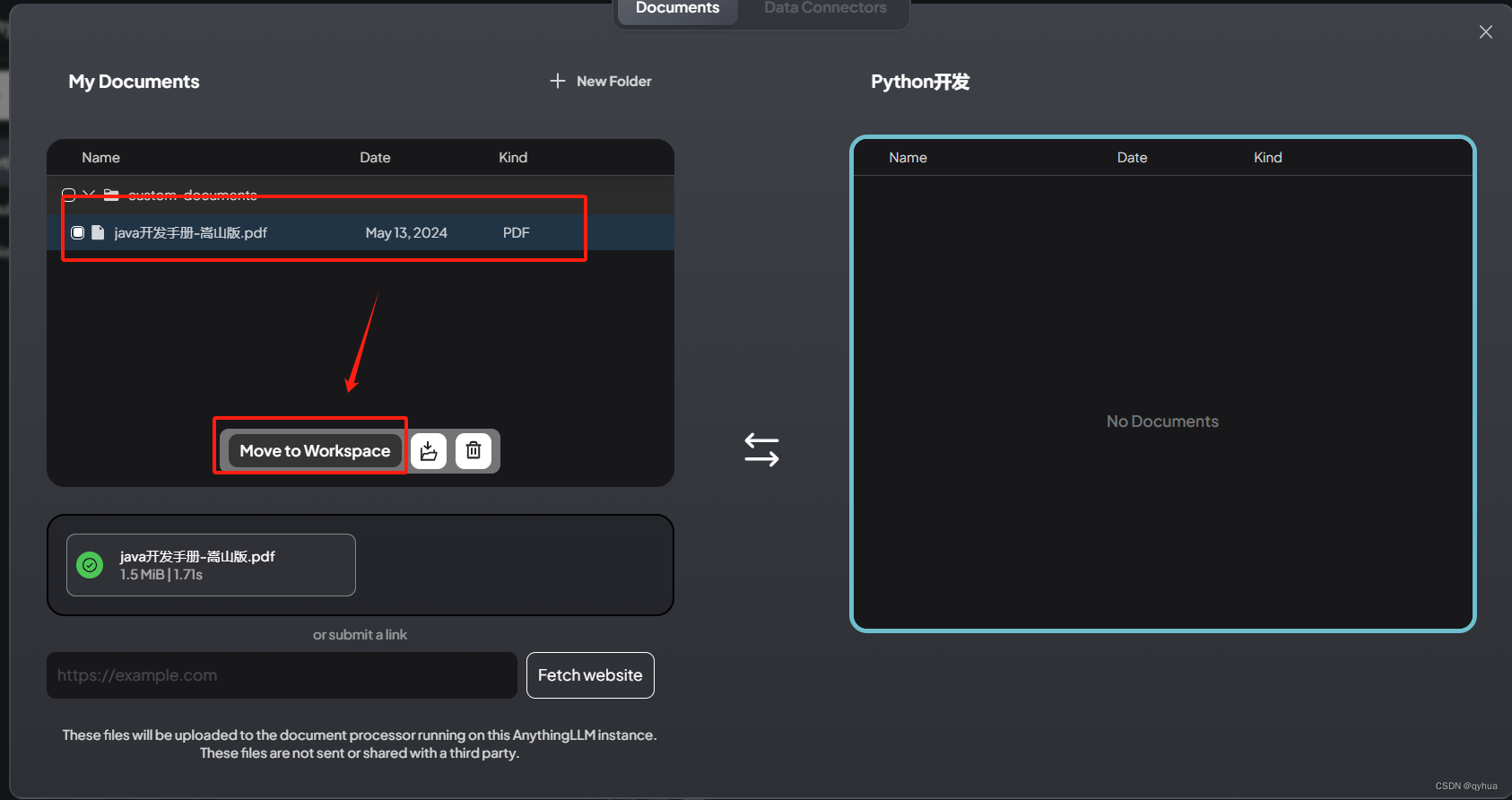
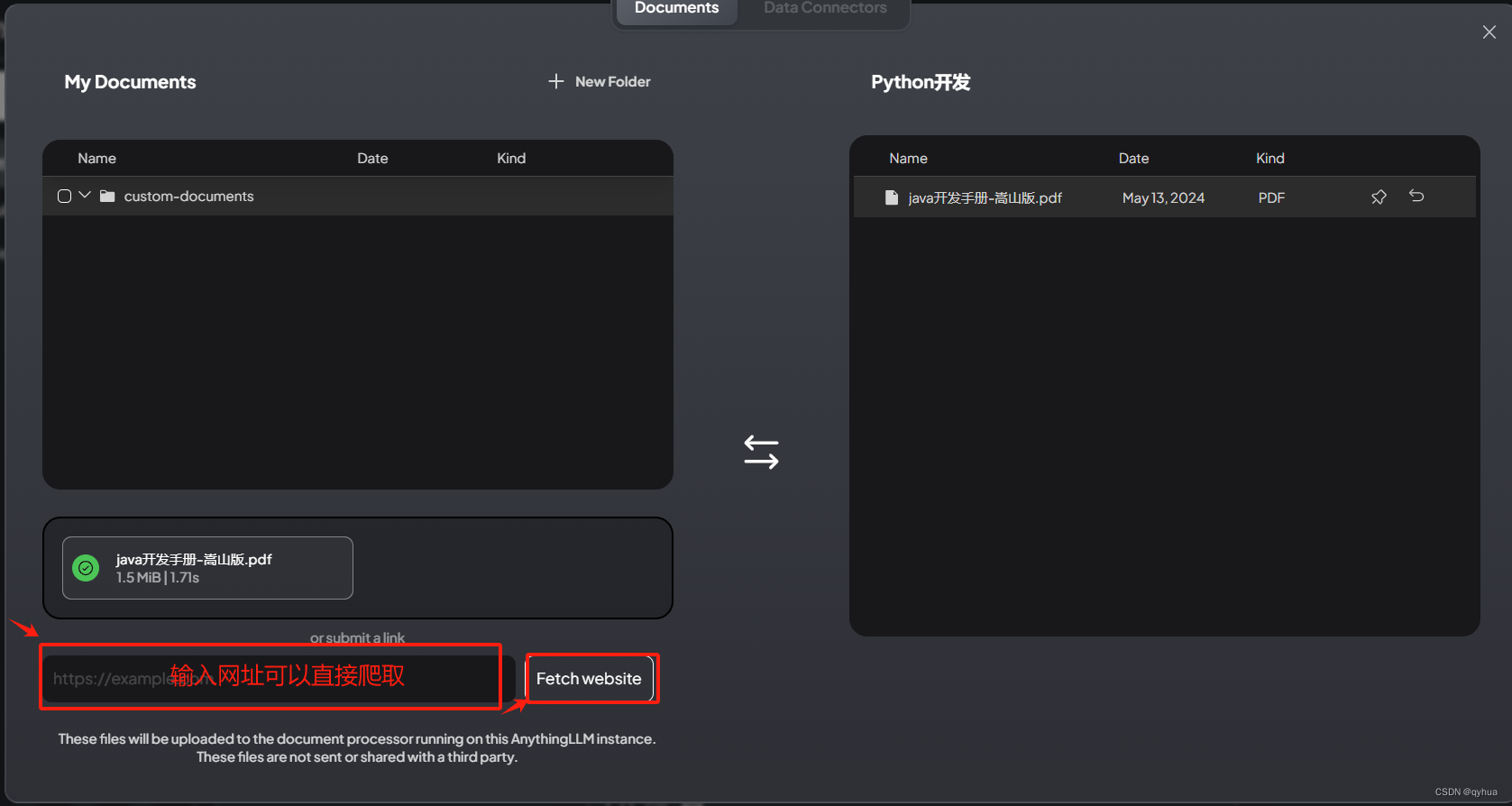
?上傳文檔形成專業知識庫,如下圖:
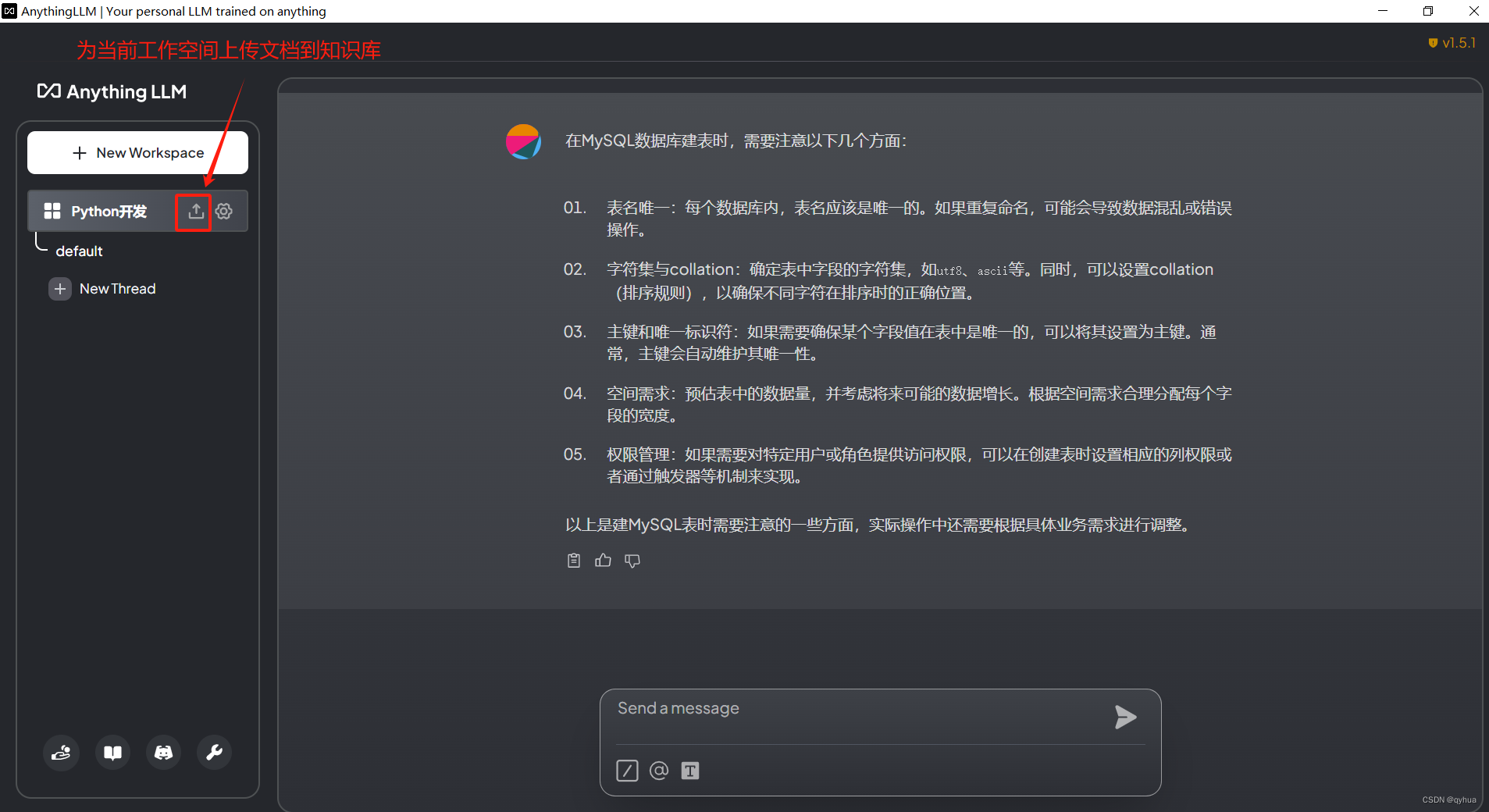
選擇文檔上傳,如下圖:?
 ?
?
 ?
?
或者輸入網址直接獲取內容?
 ?使用查詢模型提問,直接使用知識庫如下圖:
?使用查詢模型提問,直接使用知識庫如下圖: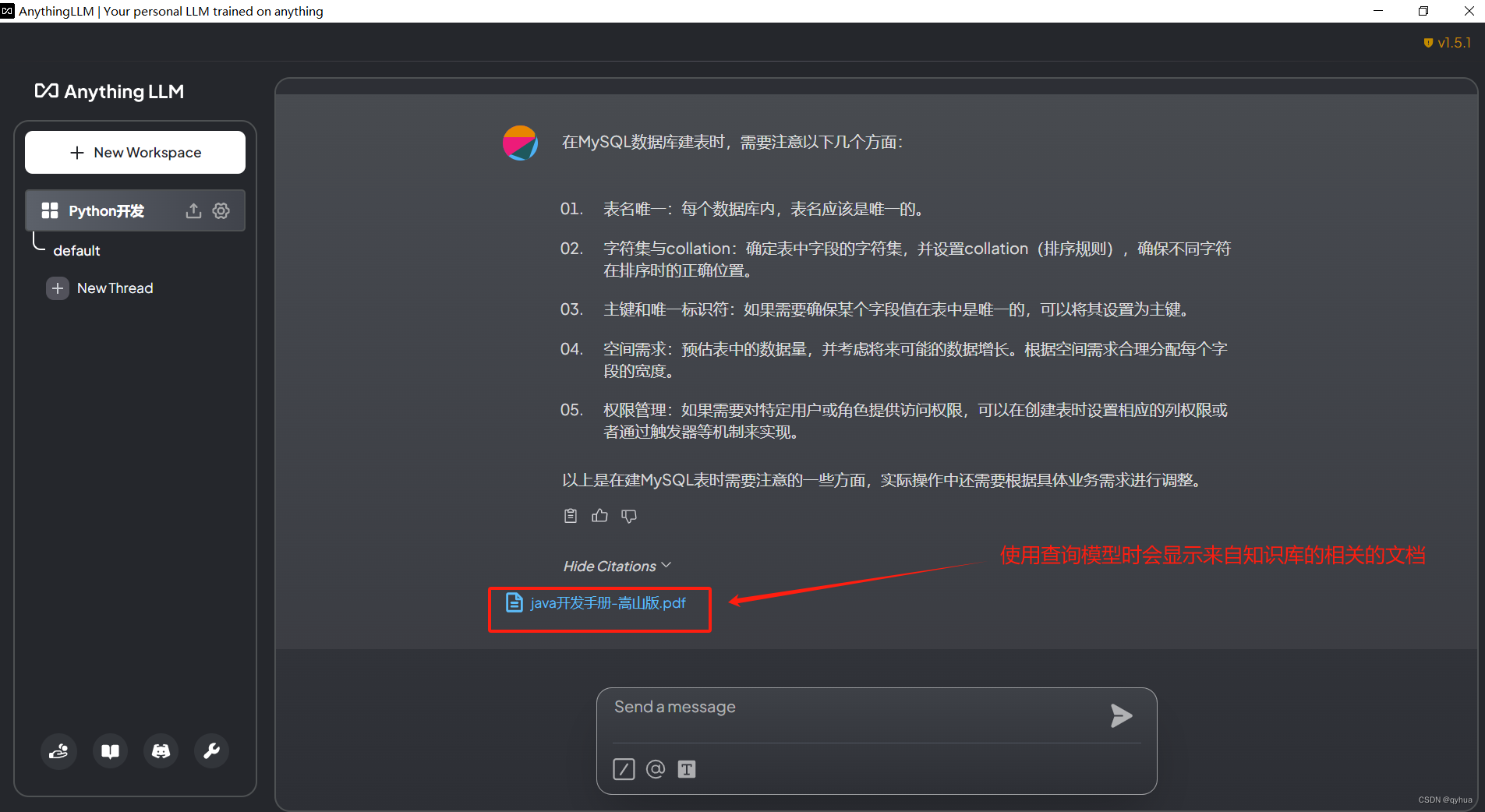
小結,普通的筆記本電腦在使用查詢模式會比聊天模型更快,并且可以節約CPU與內存。?








)

 | CPU 的好幫手)
和客戶端渲染(CSR)的概念,各自的優點和缺點,并比較如Next.js, Nuxt.js等解決方案)
-- 前后端初始化)






塊存儲簡單對接k8s(上集))