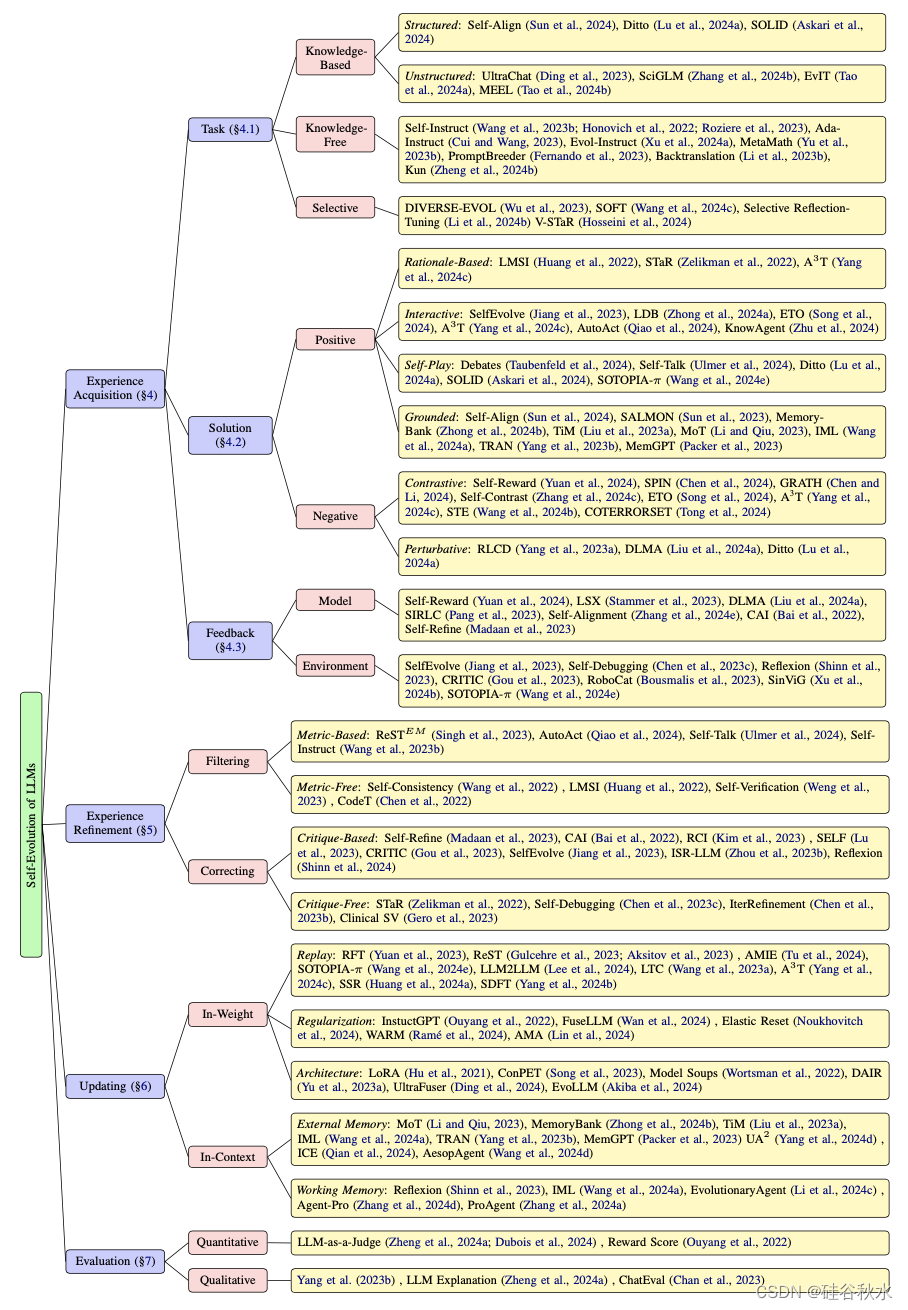
24年4月來自北大的論文“A Survey on Self-Evolution of Large Language Models”。
大語言模型(LLM)在各個領域和智體應用中取得了顯著的進步。 然而,目前從人類或外部模型監督中學習的LLM成本高昂,并且隨著任務復雜性和多樣性的增加可能面臨性能的天花板。 為了解決這個問題,使LLM能夠自主獲取、完善模型本身生成的經驗并從中學習的自我進化方法,正在迅速發展。 這種受人類體驗式學習過程啟發的新訓練范式提供了將LLM擴展到超級智能的潛力。 這項工作對LLM的自我進化方法進行了全面的調查。 首先提出了自我進化的概念框架,并將進化過程概述為由四個階段組成的迭代循環:經驗獲取、經驗細化、更新和評估。 其次,對 LLM 和基于 LLM 智體的演化目標進行了分類; 然后總結文獻并為每個模塊提供分類和見解。 最后,指出現有的挑戰并提出了改進自我進化框架的未來方向。
人工智能的自我進化。 人工智能代表了智體的一種高級形式,具有與人類相似的認知能力和行為。 人工智能開發人員的愿望在于使人工智能能夠利用自我進化能力,與人類發展的體驗式學習過程平行進行。 人工智能中自我進化的概念源于更廣泛的機器學習和進化算法領域(B?ck & Schwefel,1993)。 最初受到自然進化原理(例如選擇、突變和繁殖)的影響,研究人員開發了模擬這些過程的算法,優化復雜問題的解決方案。 Holland(1992)引入了遺傳算法,標志著人工智能自我進化能力歷史上的一個基礎性時刻。 神經網絡和深度學習的后續發展進一步增強了這種能力,允許人工智能系統在無需人工干預的情況下修改自己的架構并提高性能(Liu et al., 2021)。
在自我進化的概念框架中,一個動態的、迭代的過程,反映了人類獲取和完善技能和知識的能力。 該框架如圖所示,強調學習和改進的循環性質。 該過程的每次迭代都專注于特定的演化目標,允許模型參與相關任務、優化其體驗、更新其架構并在進入下一個周期之前評估其進度。

該概念框架概述了LLM的自我進化,類似于人類的獲取、完善和自主學習過程,其類別如圖所示:
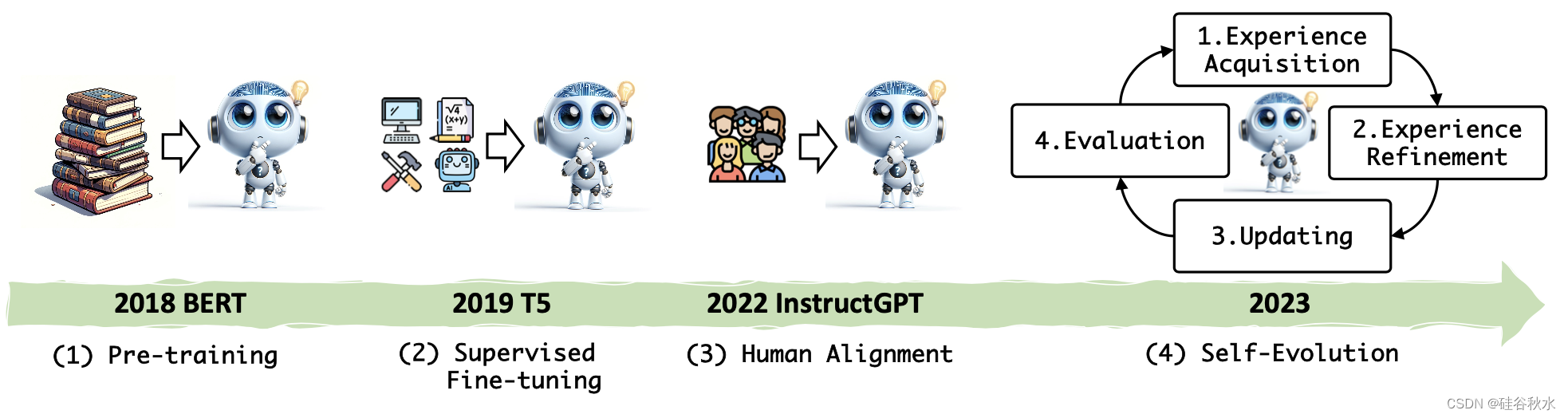
如圖是LLM訓練范式的變化史:
自我進化LLM的進化目標是預定義的目標,可以自主指導其發展和完善。 就像人類根據需求和愿望設定個人目標一樣,這些目標至關重要,因為它們決定了模型如何迭代地自我更新。 它們使LLM能夠自主地從新數據中學習、優化算法并適應不斷變化的環境,通過反饋或自我評估有效地“感受”其需求,并設定自己的目標來增強功能,而無需人工干預。
進化目標定義為進化能力和進化方向的結合。 不斷發展的能力代表著與生俱來的、細致的技能。 進化方向是進化目標旨在改進的方面。
下表是自我進化方法概述,詳細介紹了各個進化階段的方法。 其中:Pos(積極)、Neg(消極)、R(基于基本原理)、I(互動)、S(自我搏擊)、G(落地)、C(對比)、P(擾動)、Env(環境) 、In-W(權重內)、In-C(上下文中)、IF(指令跟隨)。 對于進化目標,“反饋的適配”為綠色,“知識庫擴展”為藍色,“安全、道德和減少偏見”為棕色。 “提高性能”采用默認的黑色。
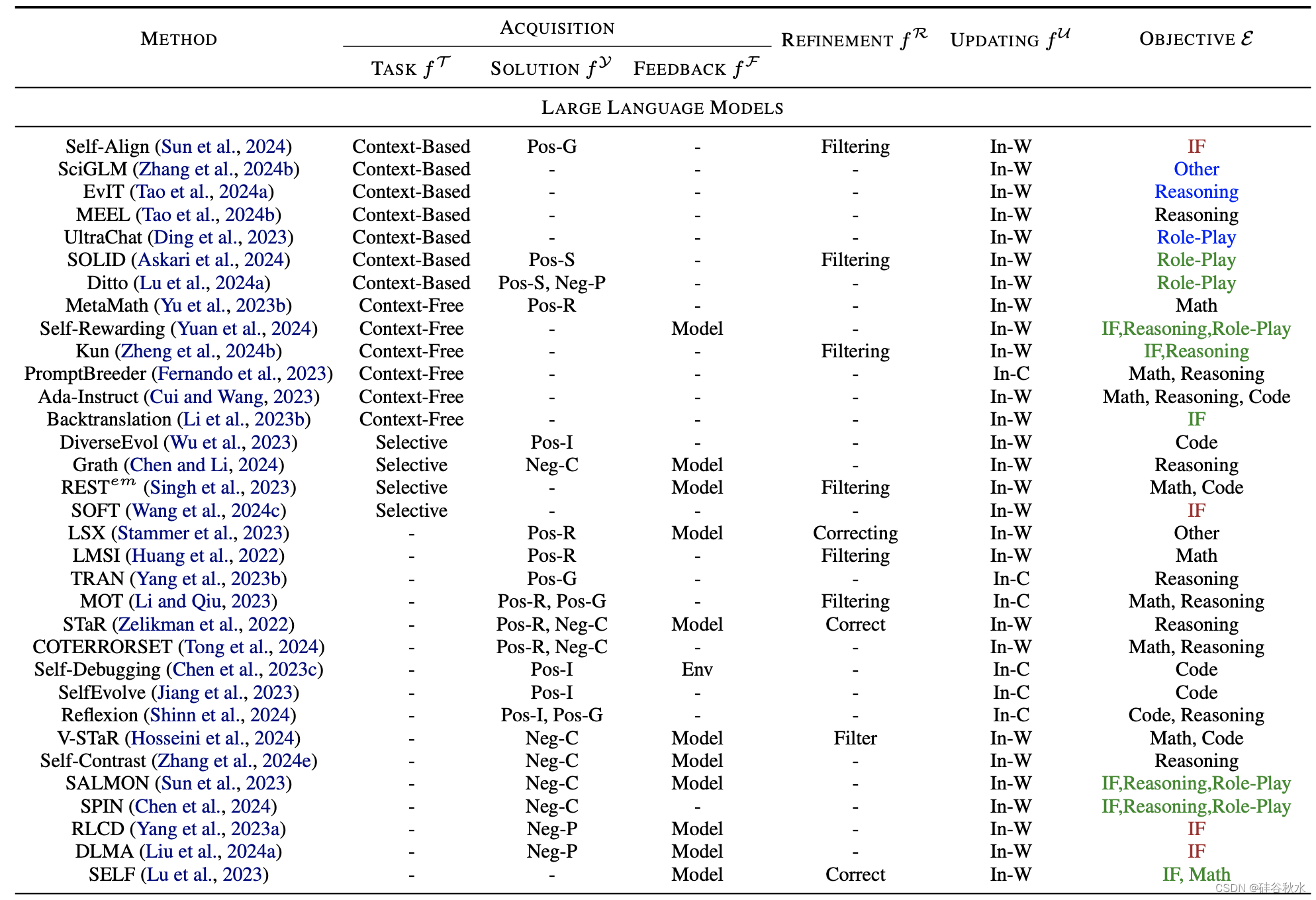
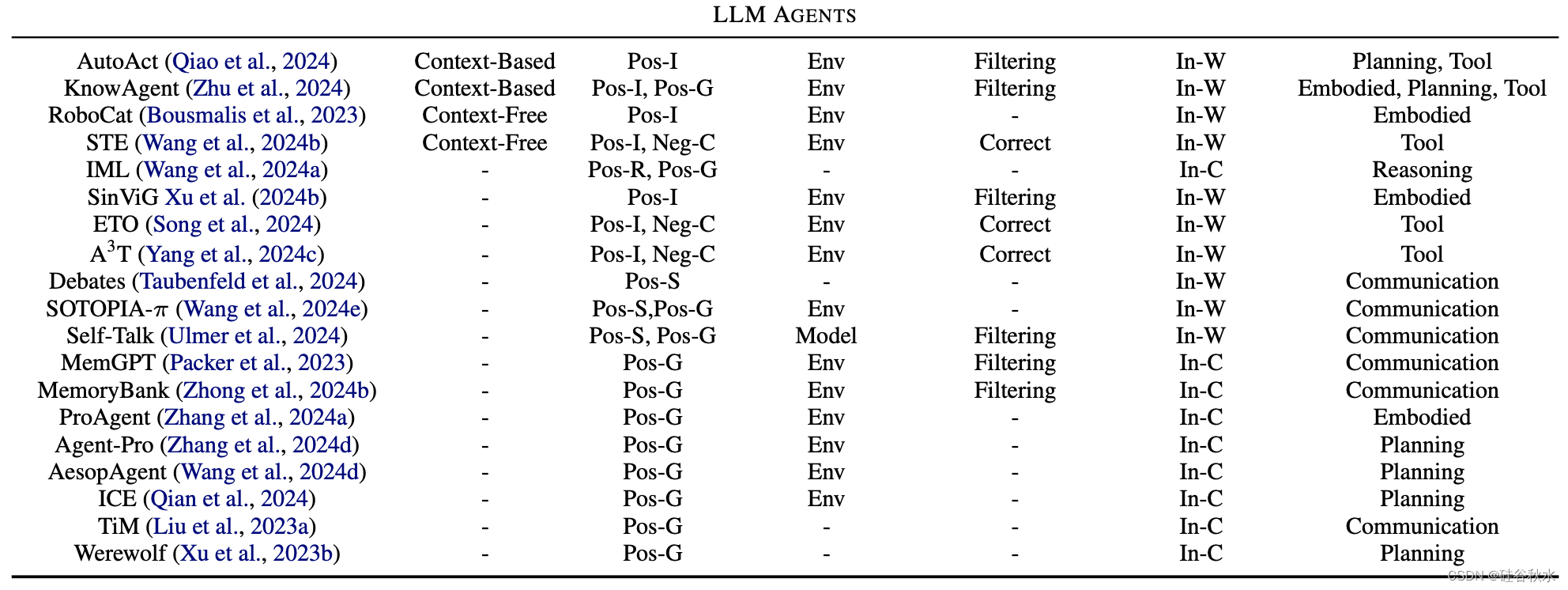
表中目標進化能力分為兩類:LLM和LLM智體。
LLM的基本能力包括:遵循指令(Xu 等人,2023a)、推理(Cui & Wang,2023)、數學(Ahn,2024)、編碼(Singh ,2023;Zelikman,2023)、角色扮演(Lu et al., 2024a)和其他NLP 任務(Stammer et al., 2023; Koa et al., 2024; Gulcehre et al., 2023; Zhang et al. ., 2024b,c)。
基于LLM的智體能力是用于在數字或物理世界中解決任務或模擬的高級人類特征。 這些功能反映了人類的認知功能,使這些智體能夠執行復雜的任務并在動態環境中有效地交互。 包括:規劃(Qiao et al., 2024)、工具使用(Zhu et al., 2024)、具身控制(Bousmalis,2023)和溝通(Ulmer et al., 2024)。
探索和利用(Gupta et al., 2006)是人類和LLM學習的基本策略。 其中,探索涉及尋求新的經驗以實現目標,類似于LLM自我進化的初始階段,即經驗獲取。 這個過程對于自我進化至關重要,使模型能夠自主應對核心挑戰,例如適應新任務、克服知識限制和增強解決方案的有效性。 此外,經驗是一個整體的建構,不僅包括所遇到的任務(Dewey,1938),還包括為解決這些任務而開發的解決方案(Sch?n,2017)以及作為任務執行的結果而收到的反饋(Boud et al.,2013)。
受此啟發,經驗獲取分為三個部分:任務進化、解決方案進化和獲取反饋。 在任務進化中,LLM根據進化目標策劃和進化新的任務。 對于解決方案的進化,LLM制定并實施策略來完成這些任務。 最后,LLM可以選擇收集與環境交互的反饋,以進一步改進。
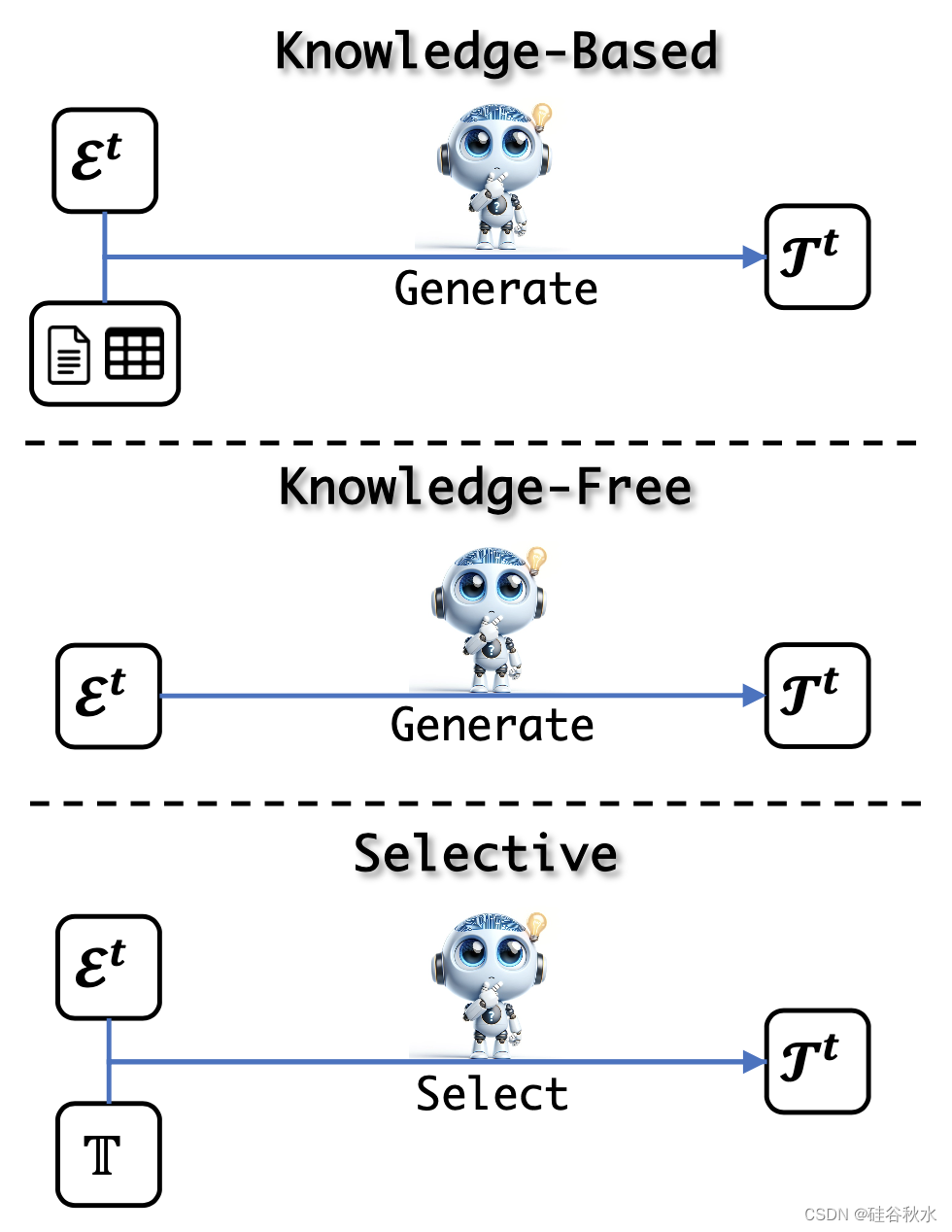
如圖所示任務進化示意圖:基于知識、無知識和選擇方法;前兩種是生成方法,根據各自對知識的使用而有所不同;相比之下,第三種方法采用判別性方法來選擇要學習的內容。
獲得進化任務后,LLM解決任務以獲得相應的解決方案。 最常見的策略是直接根據任務公式生成解決方案(Zelikman et al., 2022; Gulcehre et al., 2023; Singh et al., 2023; Cheng et al., 2024b; Yuan et al., 2024 )。 然而,這種簡單的方法可能會得到與進化目標無關的解決方案,從而導致次優進化(Hare,2019)。 因此,解決方案的進化使用不同的策略來解決任務并通過確保解決方案不僅生成而且具有相關性和信息性來增強LLM能力。 如圖所示:
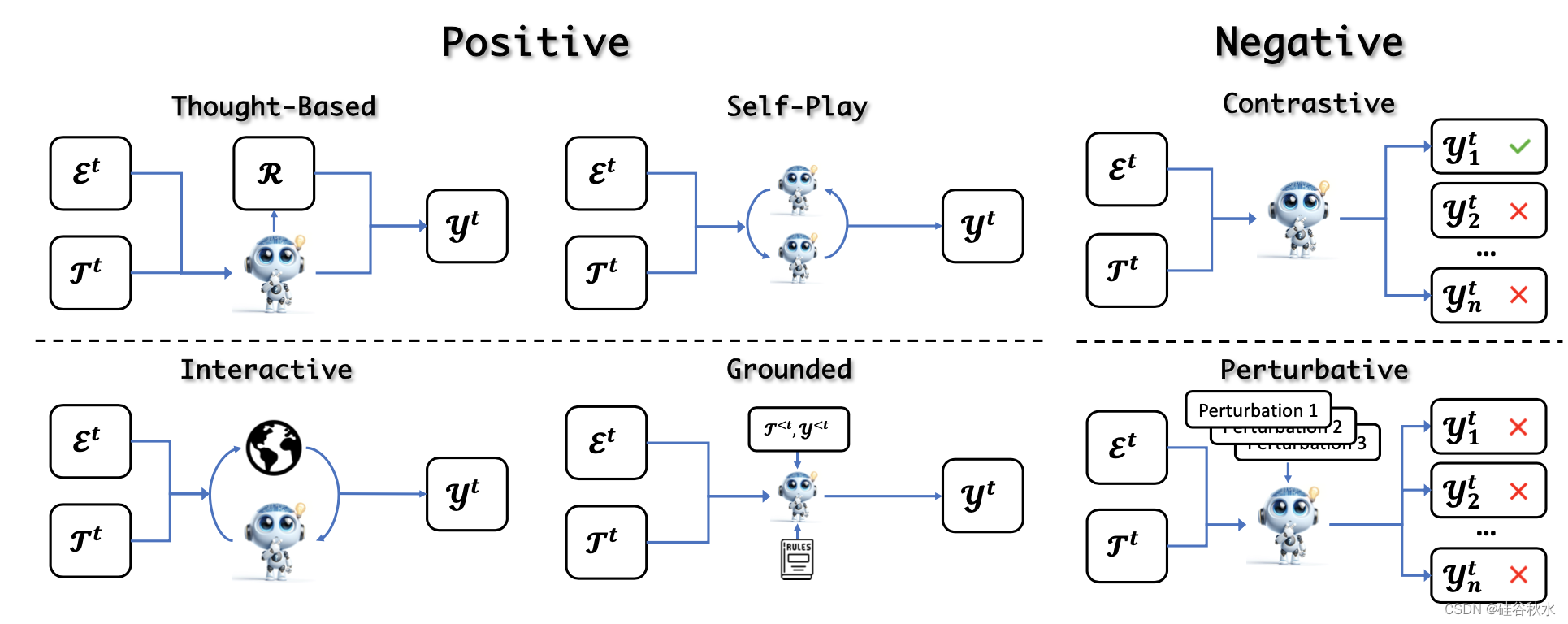
根據解決方案的正確性將這些方法分為積極方法和消極方法。 積極方法引入了各種方法來獲得正確且理想的解決方案。 相反,消極方法會引出并收集不需要的解決方案,包括不忠實或不一致的模型行為,然后將其用于偏好對齊。
當人類學習技能時,反饋在證明解決方案的正確性方面發揮著至關重要的作用。 這些關鍵信息使人類能夠反思并更新他們的技能。 與此過程類似,LLM應該在自我進化周期中的任務解決期間或之后獲得反饋。
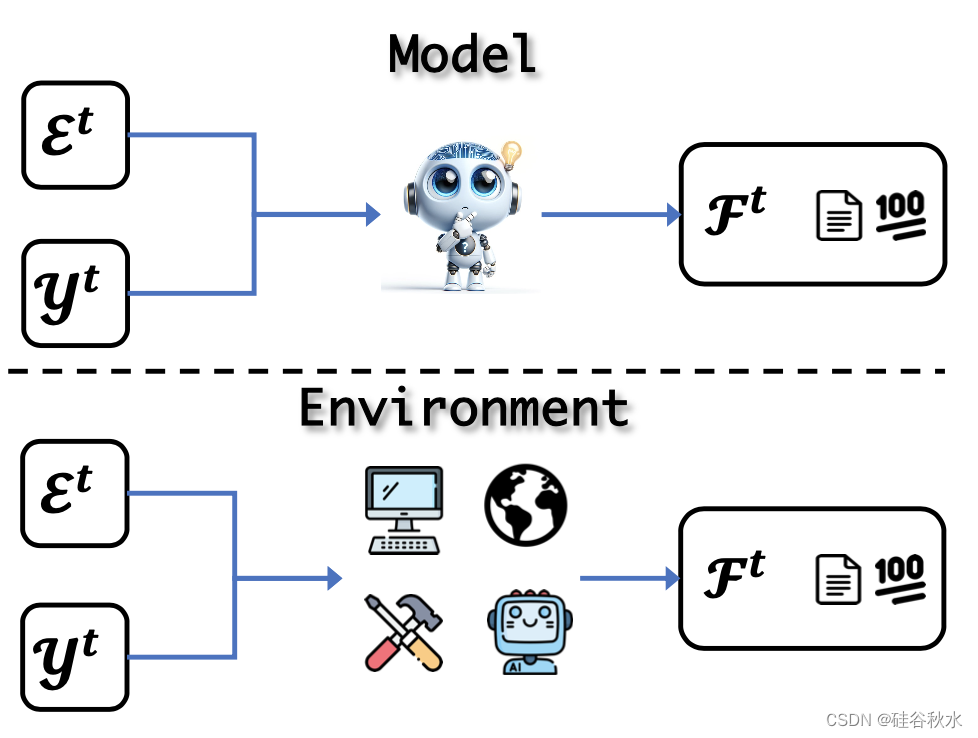
存在兩種類型的反饋:模型反饋是指收集LLM自己評價的批評或評分;此外,環境反饋表示直接從外部環境收到的反饋。 如圖所示這些概念:
在獲得經驗之后和自我進化更新之前,LLM可以通過經驗細化來提高其輸出的質量和可靠性。 它幫助LLM適應新的信息和環境,而無需依賴外部資源,從而在動態環境中獲得更可靠、更有效的幫助。這些方法分為兩類:過濾和修正。如圖所示:
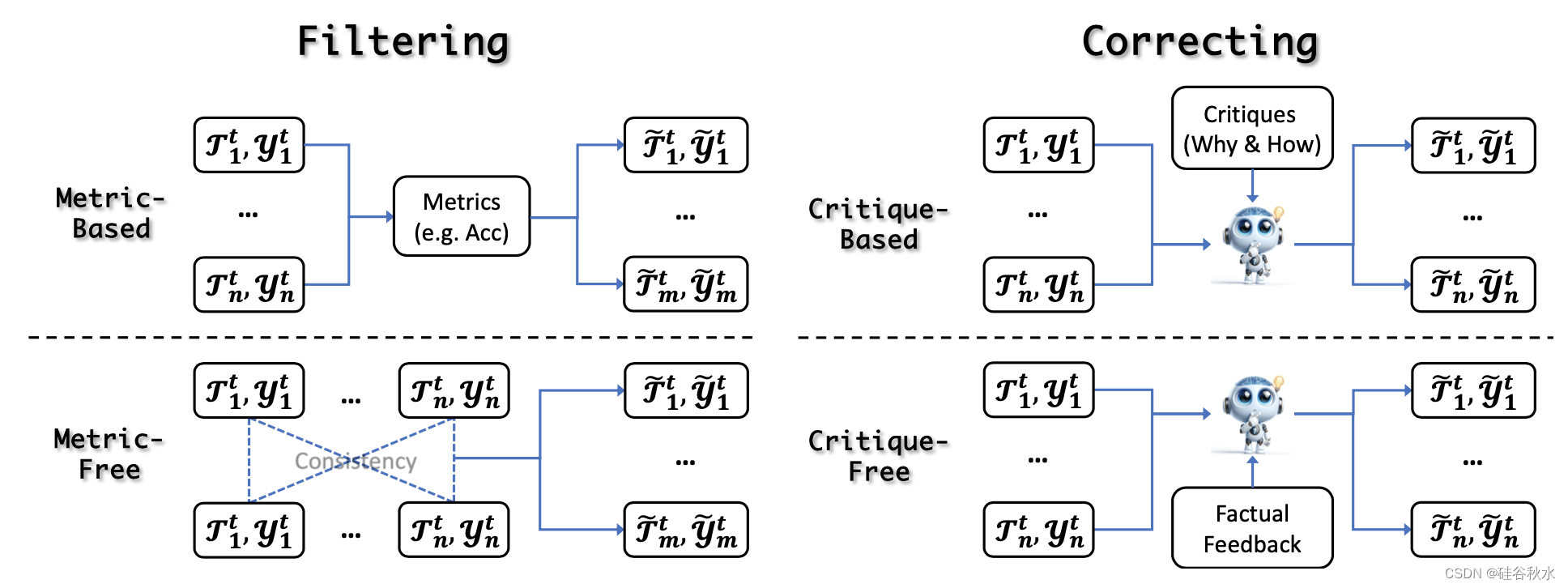
自我進化的經驗細化涉及兩種主要的濾波策略:基于度量和無度量。 前者使用外部指標來評估和過濾輸出,而后者不依賴這些指標。 這確保了只有最可靠和高質量的數據才能用于進一步更新。
自我進化的最新進展凸顯了迭代自我修正的重要性,它使模型能夠完善其經驗。 把方法分為兩類:基于批評的糾正和無批評的糾正。 批評通常作為強烈的暗示,包括感知錯誤或次優輸出背后的基本原理,指導模型改進迭代。
經驗細化后,進入關鍵的更新階段,利用細化的經驗來提高模型性能。這些方法分為權重學習(涉及模型權重的更新)和上下文學習(涉及外部或工作記憶的更新)。如圖所示:
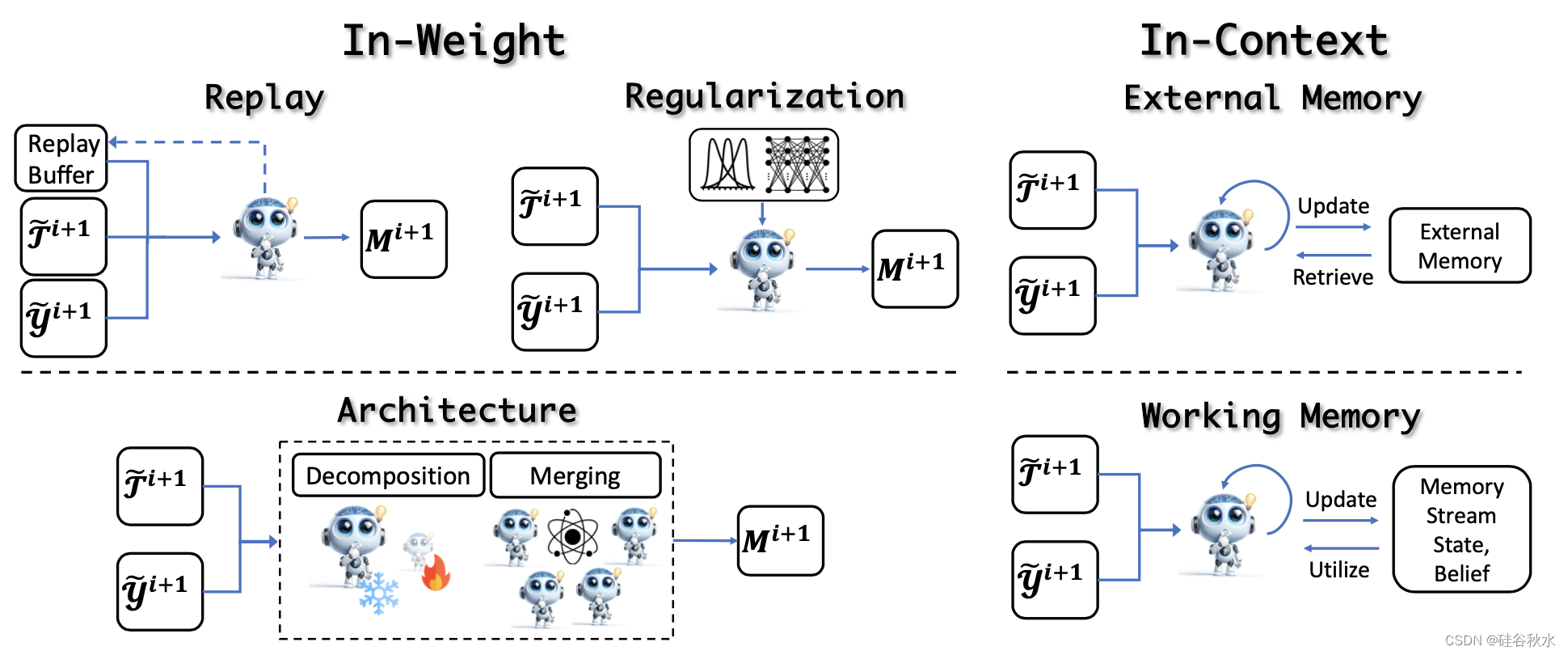
更新LLM權重的經典訓練范式包括連續預訓練(Brown et al., 2020; Roziere et al., 2023)、有監督微調(Longpre et al., 2023)和偏好對齊(Ouyang et al., 2022;Touvron,2023a)。 然而,在自我進化的迭代訓練過程中,核心挑戰在于實現整體改進并防止災難性遺忘,這需要在保留原有技能的同時提煉或獲取新的能力。 這一挑戰的解決方案可以分為三種主要策略:**基于重放、基于正則化和基于合并(架構)**的方法。
除了直接更新模型參數之外,另一種方法是利用LLM的上下文能力從經驗中學習,從而無需昂貴的培訓成本即可實現快速自適應更新。 這些方法可分為更新外部記憶和更新工作記憶。
就像人類的學習過程一樣,必須通過評估來確定當前的能力水平是否足夠,是否滿足應用要求。此外,正是從這些評估中,人們可以確定未來學習的方向。然而,如何準確評估進化模型的性能并為未來的改進提供方向是一個至關重要但尚未充分探索的研究領域。其方法分成定量和定性兩種。
自我進化方法存在的開放問題:
分級和多樣。
自動化級別:低、中、高。
經驗獲取和細化:從經驗到理論。
更新方法:穩定性-可塑性困境。
評估:系統和進化。
安全和超對齊。



)

 | CPU 的好幫手)
和客戶端渲染(CSR)的概念,各自的優點和缺點,并比較如Next.js, Nuxt.js等解決方案)
-- 前后端初始化)






塊存儲簡單對接k8s(上集))




