一、文章摘要
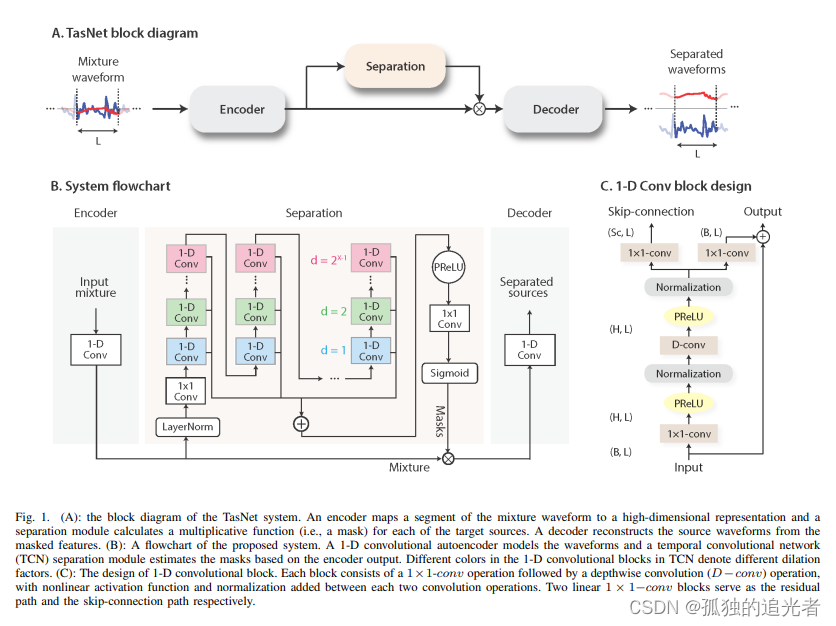
????????本文中,比較了兩種時域結構。首先將最初為語音源分離而開發的卷積tasnet應用于音樂源分離任務。雖然ConvTasnet擊敗了許多現有的頻域方法,但正如人類評估所顯示的那樣,它存在明顯的artifacts。本文提出了一種新的時域模型Demucs,它具有U-Net結構和雙向LSTM。
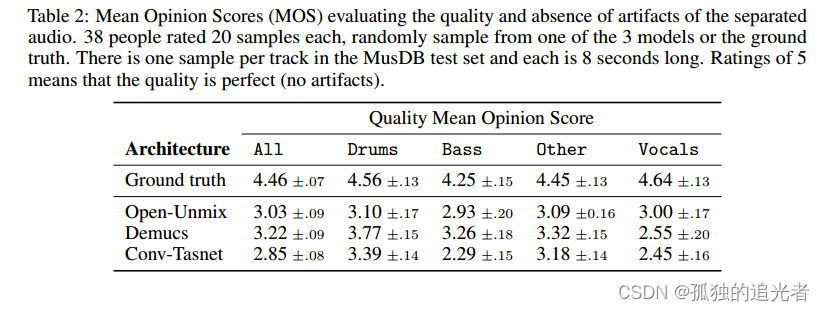
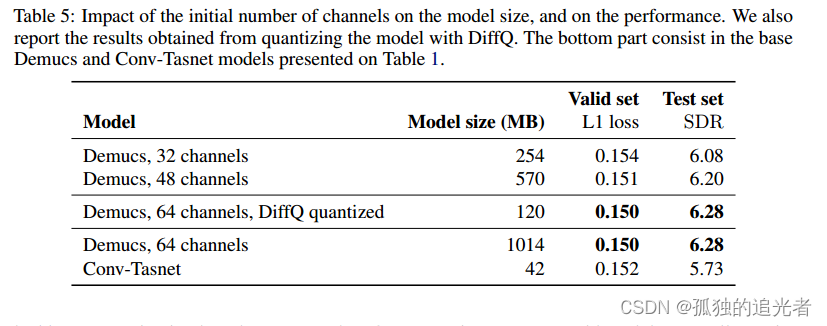
????????在MusDB數據集上的實驗表明,通過適當的數據增強,Demucs擊敗了所有現有的最先進的架構,包括convt - tasnet,平均為6.3 SDR,(在150首額外的訓練歌曲中達到6.8 SDR,甚至超過了bass源的IRM oracle)。使用模型量化的最新發展,Demucs可以壓縮到120MB而不會損失任何精度。我們還提供了人類的評估,表明Demucs在音頻的自然度方面有很大的優勢。然而,它存在一些泄露問題,特別是在人聲和其他源之間。
二、本文方法?
2.1?Conv-Tasnet方法適配到音源分離任務
????????原始的conv?- tasnet架構[Luo和Mesgarani, 2018]由一個學習的前端組成,該前端在以8 kHz采樣的輸入單音混合波形和以1 kHz采樣的128通道過完整表示之間來回轉換,使用卷積作為編碼器和轉置卷積作為解碼器,兩者的核大小為16,步幅為8。通過殘塊堆疊構成的分離網絡對高維表示進行屏蔽。
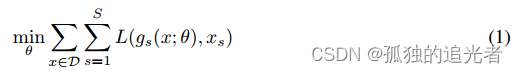
? ? ? ? 整個的分離思路按照公式(1)進行,一句話概括:最小化各個重建源加和的誤差。
? ? ? ? 其中:g表示訓練的模型,x表示各個源,L表示重建誤差,S表示各個源的編號(假設1=bass、2=voval等),D表示訓練用的數據(dataset)。
2.2?Demucs方法

????????Demucs將立體聲混合作為輸入,并輸出每個源的立體聲估計(C = 2)。它是一個編碼器/解碼器架構,由卷積編碼器、雙向LSTM和卷積解碼器組成,編碼器和解碼器通過跳躍連接相連。與圖像[Karras等人,2018,2017]和聲音[dsamfosez等人,2018]生成中的其他工作類似,我們沒有使用批處理歸一化[Ioffe和Szegedy, 2015],因為我們的早期實驗表明它不利于模型性能。
三、實驗結果
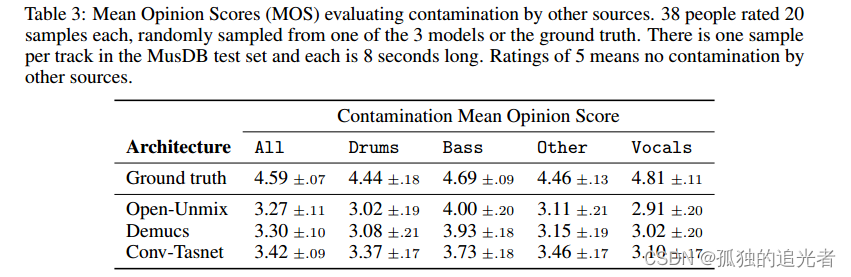
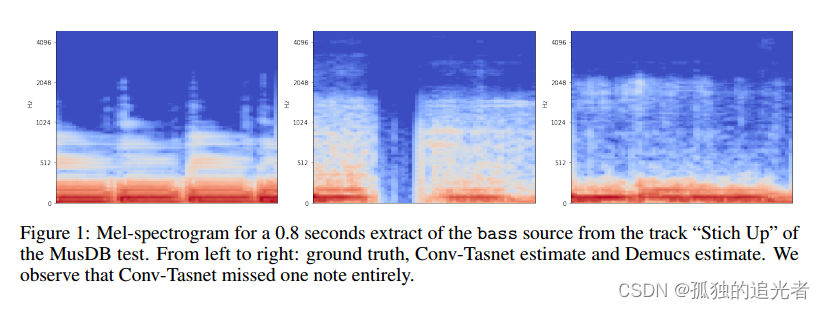
????????我們注意到通過convt - tasnet分離的音頻上有很強的偽像,特別是對于鼓和低音源:1到2 kHz之間的靜態噪聲,中空樂器攻擊或缺失音符,如圖1所示。
????????
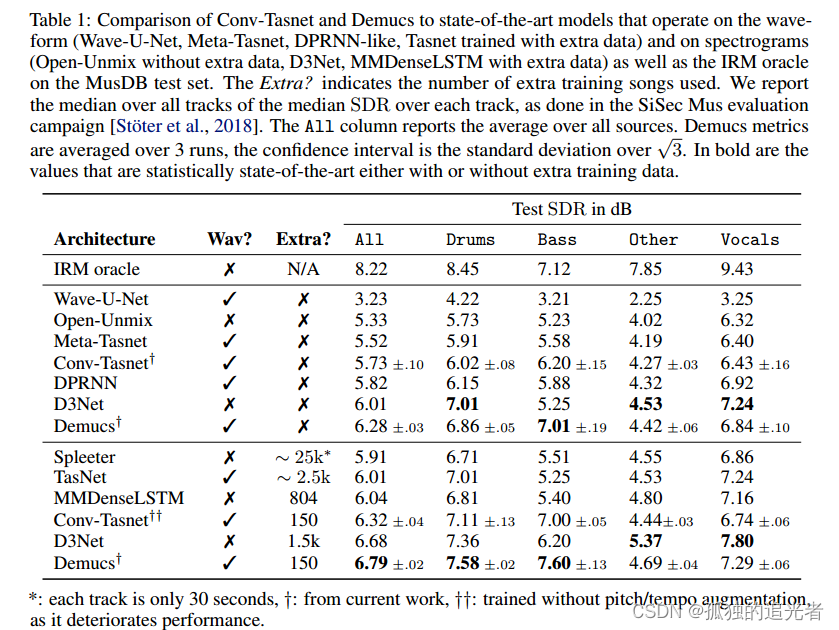
????????我們在波形域中試驗了兩種音樂源分離架構:Demucs和convt - tasnet。我們表明,通過適當的數據增強,Demucs在波形或頻譜域中超過所有最先進的架構至少0.3 dB的SDR。然而,波形和譜圖域模型之間沒有明顯的贏家,因為前者似乎在低音和鼓源中占主導地位,而后者在人聲和其他源上獲得最佳表現,這是通過客觀指標和人類評估來衡量的。我們推測,譜圖域模型在內容主要是諧波和快速變化時具有優勢,而對于沒有諧波的源(鼓)或具有強烈和強調的攻擊機制(低音),波形域將更好地保留音樂源的結構。
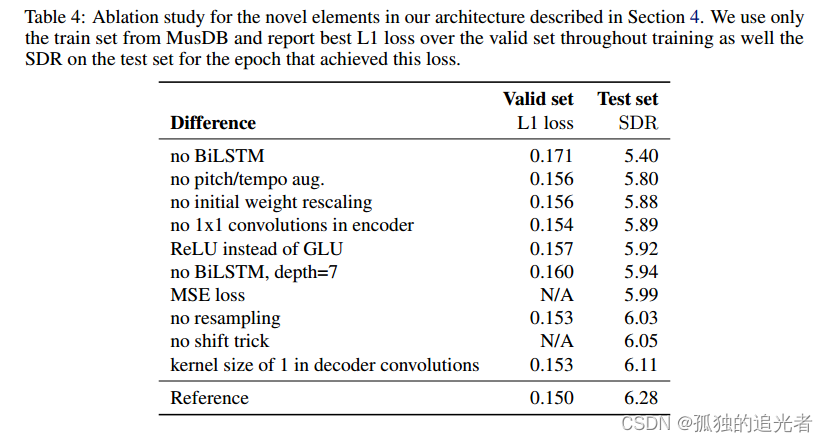
????????在訓練和架構方面,我們確認了使用音高/節奏變換增強的重要性(盡管卷積- tasnet架構似乎并沒有從中受益),以及使用LSTM進行長距離依賴,以及具有1x1卷積和GLU激活的強大編碼和解碼層。
????????當使用額外的數據進行訓練時,Demucs首次超過了用于低音源的IRM oracle。另一方面,Demucs仍然遭受比其他架構更大的泄漏,特別是對于人聲和其他來源,我們將在未來的工作中盡量減少。
【原文鏈接】https://arxiv.org/pdf/1911.13254
 | CPU 的好幫手)
和客戶端渲染(CSR)的概念,各自的優點和缺點,并比較如Next.js, Nuxt.js等解決方案)
-- 前后端初始化)






塊存儲簡單對接k8s(上集))





銷售數據排行榜)

)

