文章目錄
- 背景
- 模型實測效果
- 事實性
- 指令跟隨
- 智能體
- 模型技術解讀
- 基準測試
- 文心飛槳攜手共進
- 總結
背景
9月9日,WAVE SUMMIT深度學習開發者大會上,百度首席技術官、深度學習技術及應用國家工程研究中心主任王海峰正式發布了文心大模型X1.1深度思考模型,該模型在事實性、指令遵循、智能體等能力上均有顯著提升。目前,用戶可以在文心一言官網、文小言APP使用文心大模型X1.1。
據王海峰介紹,文心大模型X1是基于文心大模型4.5訓練而來的深度思考模型,相比文心X1,X1.1的事實性提升34.8%,指令遵循提升12.5%,智能體提升9.6%。

模型實測效果
文心大模型X1.1已全面上線!可在文心一言官網、文小言APP或百度智能云千帆平臺,暢享最新模型能力,或直接輕松調用API。

事實性
先來測測事實性!
國慶我想出去玩,在阿聯酋玩3天、阿布扎布玩3天,從南京出發,往返都在?港轉機停留?天,我需要辦哪些簽證和?續嗎
回答過程中帶有思考和網頁參考,同時能夠抽取并分析外部信息源。


再來個博大精深的!
“意思”在“這是什么意思?”、“這點?意思,不成敬意”、”這個景點太沒意思了“中含義是否相同?
能夠結合語境對多義詞語進?解釋,甚至列出了表格進行對比。


指令跟隨
下面測試一下指令跟隨能力。
你是「?紅書運營」,負責的領域是外套,擅?以當代年輕?喜歡的潮流筆撰寫?案,??幽默?趣有吸引?。請撰寫簡短的關于寬松裝翻領中?款?裝外套的種草?案?案關鍵詞:?對?性?戶、材質是聚酯纖維63%、顏?是?尾草綠、1件59元、原價135元?案。
要求1.?句分解、避免重復、輕松幽默且真誠、整體具有可讀性2.?案不能違反?告法,不可出現絕對,?選,最好,最佳等詞語3.整體4?,每?以emoji表情開頭,每?不超過15個字請基于以上要求,盡快撰寫出?段?案。
在復雜指令解析上,它能精準識別?戶需求細節,避免遺漏關鍵要素。

作為‘社恐探店博主’,請以’躲開網紅店人潮’為主題,推薦3家南京小眾咖啡館 要求:
- 寫明適合獨處辦公的細節(插座數量、安靜程度)
- 用’發現秘密基地’的驚喜語氣
- 結尾引導粉絲投稿私藏店鋪 使用emoji風格輸出

智能體
最后測試一下智能體效果。

ps:多模態能力也很強啊



模型技術解讀
文心大模型X1.1的模型訓練主要采用了迭代式混合強化學習訓練框架,一方面通過混合強化學習同時融合提升通用任務和智能體任務的效果,另一方面通過自蒸餾數據的迭代式生產及訓練不斷提升模型整體效果。通過多項技術創新,該模型在智能體、指令遵循和事實性方面的效果表現出色:
1、基于基礎模型和策略模型知識一致性的強化學習訓練
基于基礎模型和策略模型知識一致性的強化學習訓練:在訓練過程中,不斷校驗后訓練模型和預訓練模型知識的一致性,模型的事實性得到了大幅度的提升。
2、基于檢查清單和指令驗證器的強化學習訓練
基于檢查清單和指令驗證器的強化學習訓練:通過自動構建指令檢查清單并驗證,模型在復雜指令遵循方面的效果明顯提升。
3、基于思維和行動鏈的多輪強化學習訓練
基于思維和行動鏈的多輪強化學習訓練:在思考過程中,將思維鏈和行動鏈結合,模型的智能體和工具調用能力明顯提升。
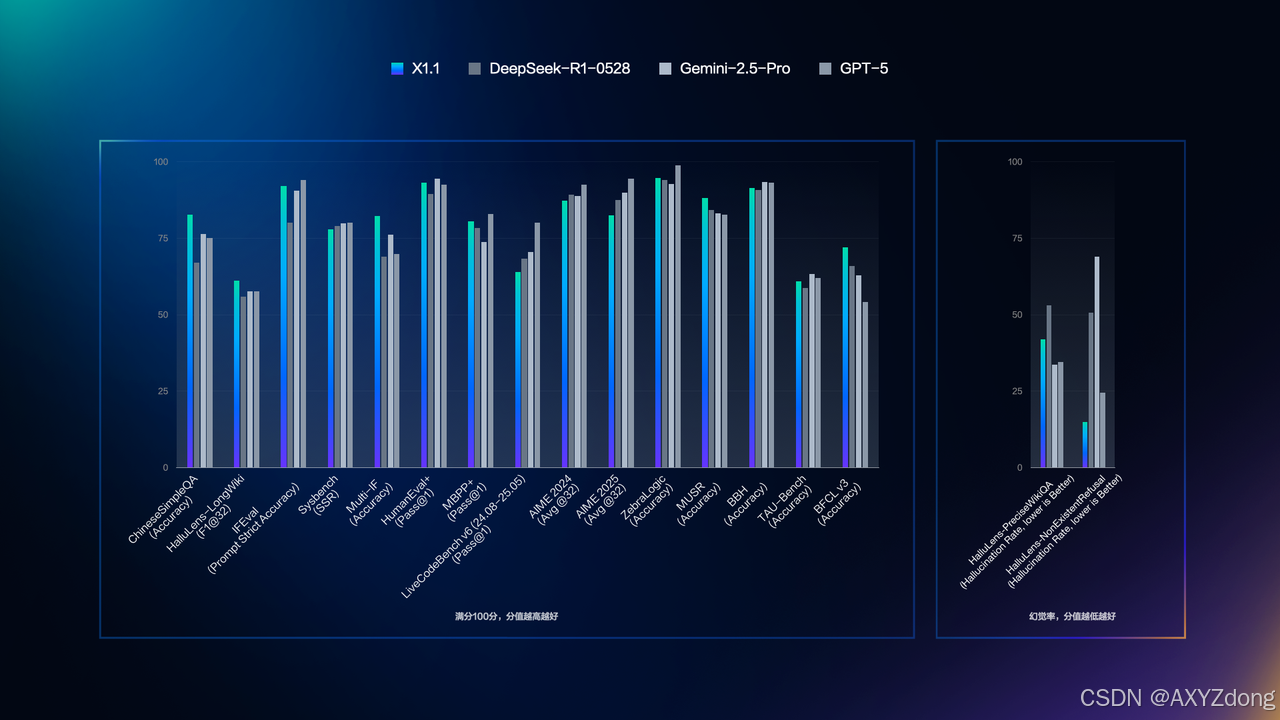
基準測試
在多個權威基準評測中,文心X1.1整體表現超越DeepSeek R1-0528,在部分任務上展現出領先優勢。同時,在與國際頂尖模型GPT-5和Gemini 2.5 Pro相比,效果持平。
文心飛槳攜手共進
-
飛槳框架v3.2
在WAVE SUMMIT深度學習開發者大會現場,百度還發布了全新飛槳框架v3.2,在大模型訓練、硬件適配和生態支持上全面升級,并同步升級大模型開發套件ERNIEKit和高效部署套件FastDeploy。飛槳框架v3.2在?模型訓練、大模型硬件適配、主流?模型及?性能加速庫的?持上進?步提升。
1、突破大模型訓練技術難題,訓練效率更高。包括極致計算優化、高效并行策略和框架原生容錯能力。
2、面向類CUDA芯片,全新升級適配方案。一行代碼完成類CUDA算子注冊,算子內核復用率高達92%,大幅降低適配成本。
3、支持業界主流大模型及高性能加速庫。原生支持Safetensors權重格式,主流高性能加速庫一鍵接入。
4、此外,發布???模型開發套件ERNIEKit和?模型?效部署套件FastDeploy v2.2。 -
文心飛槳開源及生態建設
1、6月30日,百度正式開源文心大模型4.5系列模型,涵蓋47B、3B激活參數的混合專家(MoE)模型,與0.3B參數的稠密型模型等10款模型,并實現預訓練權重和推理代碼的完全開源。目前,文心大模型4.5系列開源模型已經在?業?得到了?泛的應?。
2、百度的文心4.5開源模型系列,新增一款思考模型ERNIE-4.5-21B-A3B-Thinking- ERNIE-4.5-21B-A3B-Thinking是基于ERNIE-4.5-21B-A3B-Base進?步訓練?來的深度思考模型,升級增加了深度思考能?后,該模型在智能體、?具調?、指令遵循、事實性等??表現出?,問答、創作、邏輯推理等??的綜合能?明顯提升。相?于全新發布的文心大模型X1.1,該模型推理速度顯著提升。
- 為了全?位?持基于???模型的創新以及應?開發,百度為開發者們量身打造了配套的功能體系。這套體系不僅涵蓋??4.5系列模型權重,還包括?槳框架、ERNIEKit、PaddleFormers以及FastDeploy開源代碼庫,此外還具備豐富的最佳實踐。所有模型和代碼都遵循Apache 2.0開源協議,開發者可以?由地使?、修改和分發。百度期待與開發者?起,共同探索???模型更?闊的應?前景。
3、據最新數據披露,飛槳文心生態開發者達到2333萬,服務企業達到76萬家。
-
文心飛漿聯合優化
在此次發布會上,文心飛漿聯合優化主要表現在以下三個方面:
1、既包括框架-模型的聯合優化,也包括框架-算力的聯合優化。既有提升訓練性能的創新,也有提升推理吞吐的創新。
2、訓練方面,最新發布的飛槳框架v3.2在計算、并?策略、容錯能?三??進?步升級。極致計算優化方面,提出了存算重疊的稀疏掩碼注意?計算FlashMask V3,同時實現了?效的FP8混合精度效果?損訓練技術。高效并行策略方面,提出了動態?適應的顯存卸載策略,以及創新設計的顯存友好的流?線并?調度,進?步降低顯存開銷。框架原生容錯能力方面,實現了?規模集群訓練容錯系統,在線監測靜默數據損壞等難以察覺的故障,并實現了?可?的檢查點容災?法,降低中斷恢復損失。經過上述優化,??X1.1及4.5系列模型均獲得了優異的性能表現,并在文心最?規模的4.5?本模型ERNIE-4.5-300B-A47B的預訓練上取得了47% MFU。
3、推理方面,通過卷積編2比特極致壓縮,可插拔稀疏化輕量注意力,混合動態自適應多步投機解碼,通信存儲計算深度協同優化的大規模P/D分離部署等技術,提供大模型高效部署及高性能推理全棧能力。在文心4.5激活參數量47B、總參數量300B的模型ERNIE-4.5-300B-A47B上,通過上述系統性優化,在TPOT 50ms時延條件下,實現了輸入吞吐高達57K、輸出吞吐29K的卓越性能表現。
總結
從最新發布內容來看,百度正憑借扎實的技術積累與開放的生態策略,持續優化其全棧AI布局——芯片、框架、模型與應用四層架構緊密圍繞開發者實際需求展開推進。尤其通過飛槳深度學習平臺與文心大模型的深度協同,百度為開發者提供了更加高效、易用的工具鏈和生態支持。








![【python實用小腳本-211】[硬件互聯] 桌面壁紙×Python夢幻聯動|用10行代碼實現“開機盲盒”自動化改造實錄(建議收藏)](http://pic.xiahunao.cn/【python實用小腳本-211】[硬件互聯] 桌面壁紙×Python夢幻聯動|用10行代碼實現“開機盲盒”自動化改造實錄(建議收藏))


)






:融合Self-Attention的CNN架構)
-- Symbol與集合數據結構)