1. 為什么需要Batch Normalization
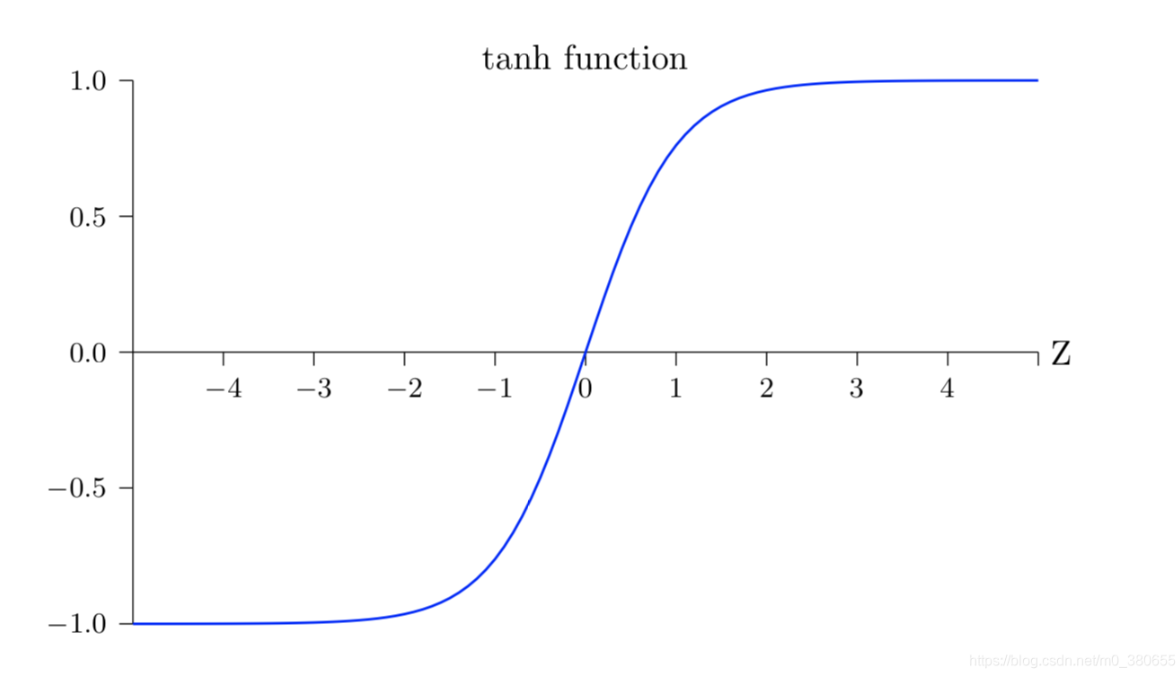
通常我們會在輸入層進行數據的標準化處理,這是為了讓模型學習到更好的特征。同樣,在模型的中間層我們也可以進行normalize。在神經網絡中, 數據分布對訓練會產生影響。?比如我們使用tanh作為激活函數,當輸入激活函數的值很大時,tanh輸出值接近飽和如下所示,這樣我們再增大x,輸出幾乎沒任何變化,可以理解為模型對數據不再敏感了。這種情況在隱藏層時有發生,因此需要Batch Normalization解決。
?2.?Batch Normalization層位置
?Batch Normalization (BN) 層被添加在每一個全連接和激活函數之間,如下:
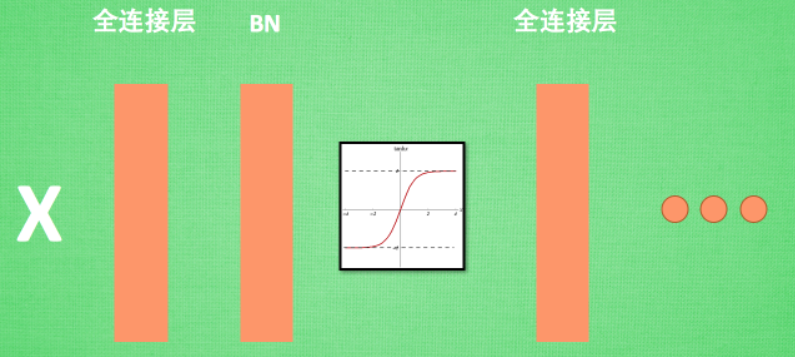
3.?Batch Normalization作用的形象理解
計算結果值的分布對于激活函數很重要。比如還是tanh函數,對于數據值大多分布在中間這個區間的數據, 才能進行更有效的傳遞。?對比下圖這兩個在激活之前的值的分布。上者沒有進行 normalization, 下者進行了 normalization, 我們通過normalization將數據分布在tanh效果最好的區間內,這樣能夠更有效地利用 tanh 進行非線性化的過程:
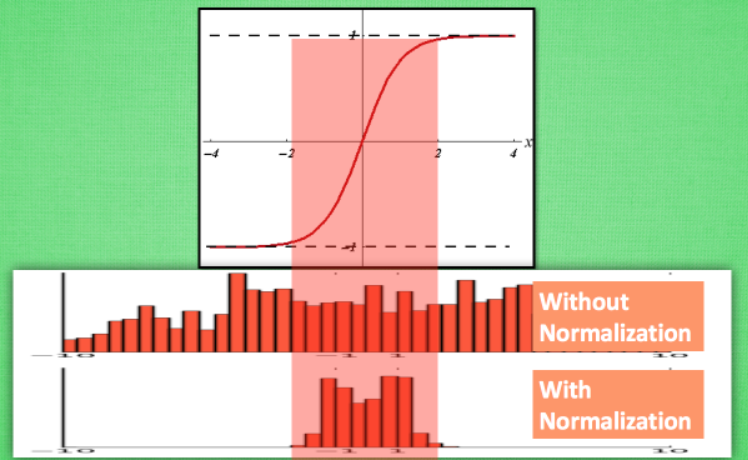
?接著,將這兩個分布的數據分別通過激活函數,觀察輸出分布如下圖所示。沒有 normalize 的數據使用 tanh 激活以后, 激活值大部分都分布到了飽和階段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每個分布區間都還有存在。再將這個激活后的分布傳遞到下一層神經網絡進行后續計算, 每個區間都有分布的這一種對于神經網絡就會更加有價值:

4. BN算法
我們引入batch normalization的公式。標準化工序就是我們在剛剛一直說的normalization, 但是公式的后面還有一個反向操作, 將 normalize 后的數據再擴展和平移。原來這是為了讓神經網絡自己去學著使用和修改這個擴展參數 gamma, 和 平移參數 β, 這樣神經網絡就能自己慢慢琢磨出前面的 normalization 操作到底有沒有起到優化的作用, 如果沒有起到作用, 我就使用 gamma 和 belt 來抵消一些 normalization 的操作。

?注:參考https://zhuanlan.zhihu.com/p/24810318






——二叉樹和堆(下))
)





)



)

