github地址
網頁btc預測demo使用的Kronos-mini模型
huggingface的倉庫
文章目錄
- 配置環境
- 安裝python環境
- 獲取市場數據的庫
- 通過webui使用
- example中的例子
- prediction_example.py
- 補充說明
- 根據原例優化的代碼
- CryptoDataFetcher
- 單幣對多周期預測
配置環境
使用conda的環境.
首先進行換源(太久沒用發現原來的源掛了)
conda config --show-sources當前源
==> C:\Users\maten\.condarc <==
channel_priority: strict
channels:- https://mirrors.aliyun.com/anaconda/cloud/bioconda/- https://mirrors.aliyun.com/anaconda/cloud/msys2/- https://mirrors.aliyun.com/anaconda/cloud/conda-forge/- https://mirrors.aliyun.com/anaconda/pkgs/free/- https://mirrors.aliyun.com/anaconda/pkgs/main/- defaults
show_channel_urls: True
打開Windows: C:\Users<你的用戶名>.condarc
修改為下面的源
channels:- defaults
show_channel_urls: truedefault_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
安裝python環境
文章推薦3.10+的版本
conda create -n kronos python=3.10
激活對應環境。
(base) C:\Users\maten> conda activate kronos(kronos) C:\Users\maten>
requirement.txt如下,torch沒有設置版本,默認下載可能是cpu版本,默認調用模型,應該無所謂。
numpy
pandas
torcheinops==0.8.1
huggingface_hub==0.33.1
matplotlib==3.9.3
pandas==2.2.2
tqdm==4.67.1
safetensors==0.6.2在這個地方下載倉庫的代碼。
https://github.com/shiyu-coder/Kronos/tree/master
在此處配置需要的pytorchgpu的版本。
pytorch的官網
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu128
cd G:\Kronos-master\Kronos-master
g:
pip install -r requirement.txt
使用vscode或者trae,用python environments插件


獲取市場數據的庫
#以加密貨幣為例
pip install ccxt #多交易所
pip install python-binance #僅支持幣安
通過webui使用
在命令行中打開的
通過python腳本來啟動。
conda activate kronos
cd webui
python run.py
會要求下載網頁端需要使用的flask。
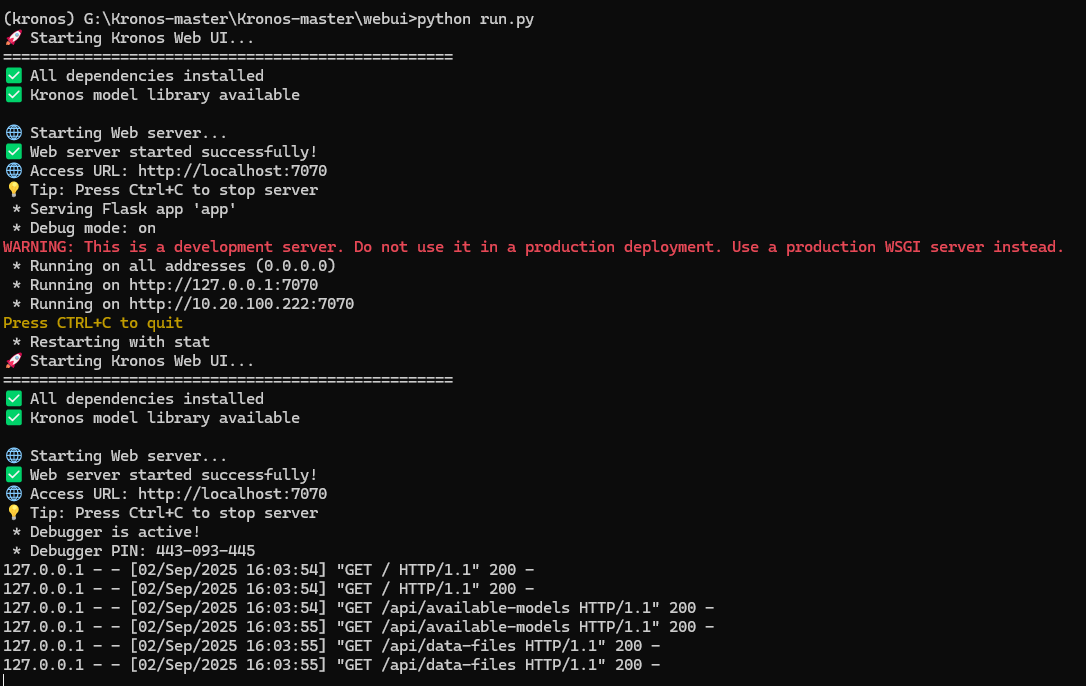
執行會打開這個頁面。
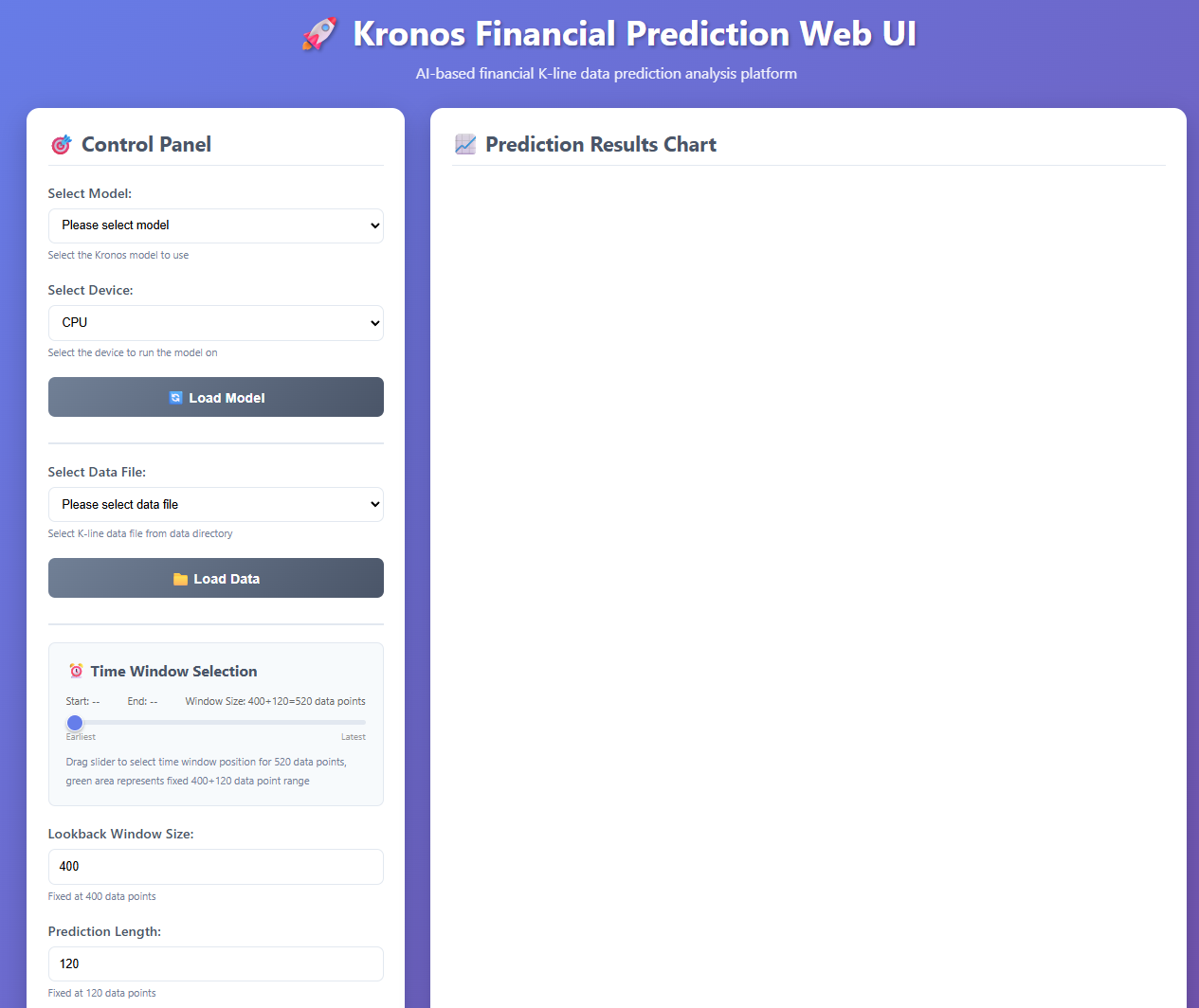
可以選擇模型,在加載數據的時候,需要在項目的根目錄下創建一個data文件夾,并將所使用的數據(csv格式的)放在這個里面,才能訪問到。
這都是固定值,網頁設置了無法修改,代碼中應該可以修改。
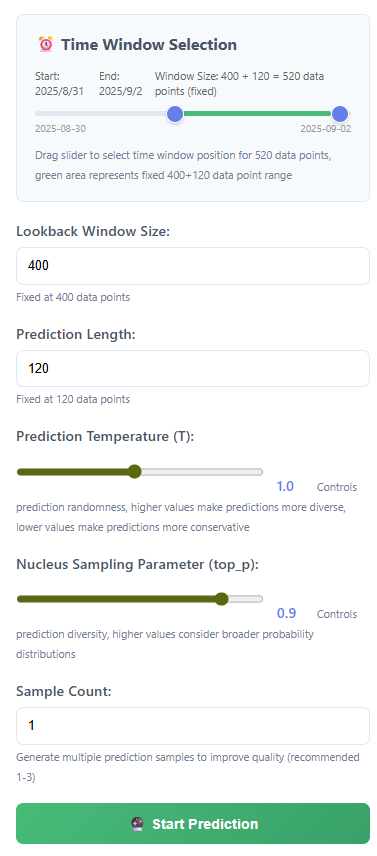
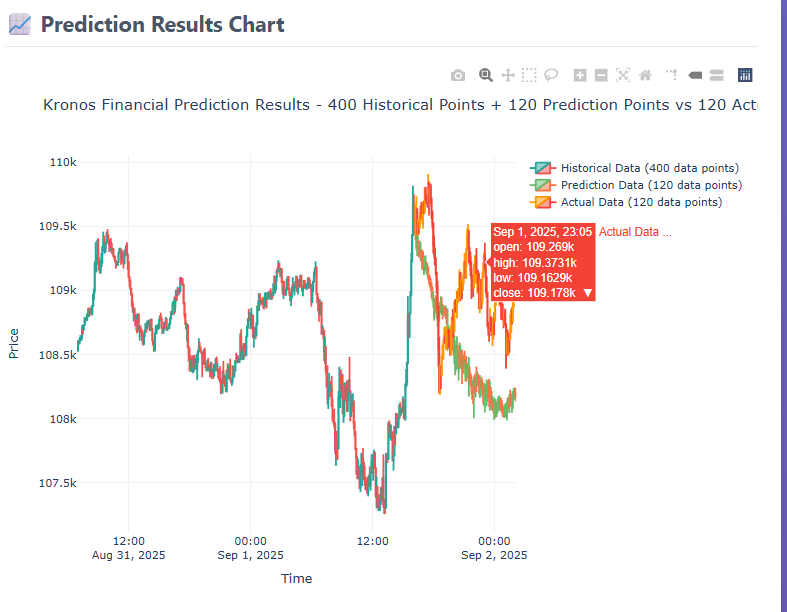
sample設置的多,應該會增強這個細節,但是耗時也會增加很多。
真實的準確性,有待進一步探索。
example中的例子
此函數進行預測
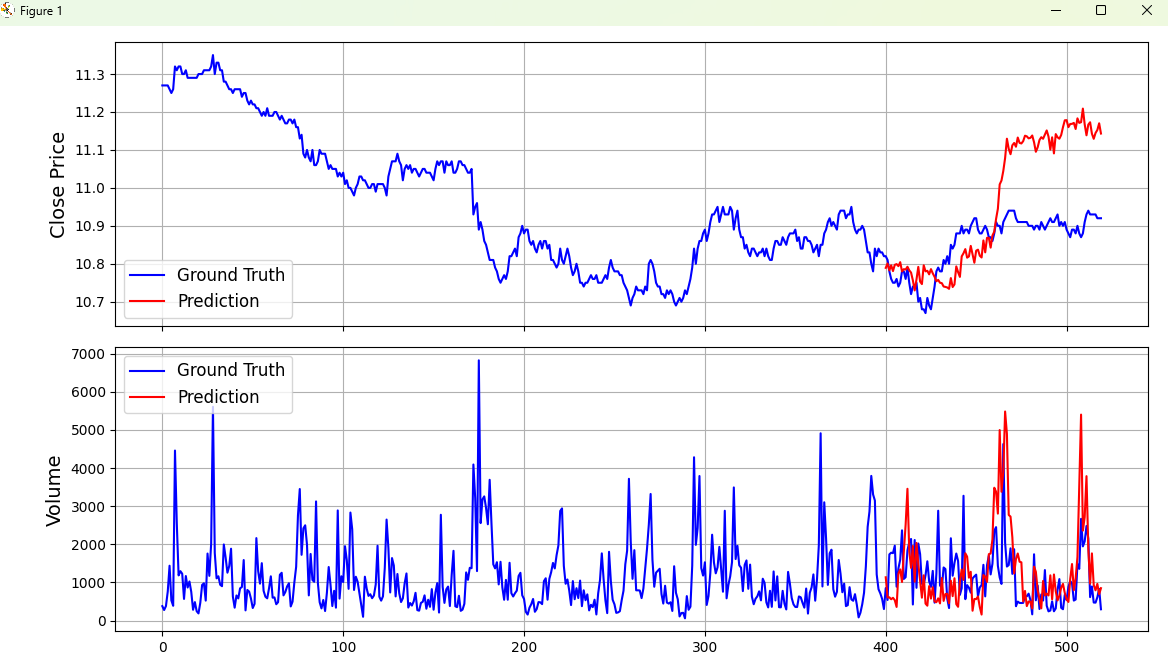
prediction_example.py
# 導入必要的庫
import pandas as pd # 用于數據處理和分析
import matplotlib.pyplot as plt # 用于數據可視化
import os
print(os.getcwd())
# 添加這個,可以確定當前執行文件夾是那個,如果為項目文件夾,可自行修改下面添加的目錄。"./"
import sys
# 添加上級目錄到Python路徑,以便導入model模塊
sys.path.append("../")
from model import Kronos, KronosTokenizer, KronosPredictordef plot_prediction(kline_df, pred_df):"""繪制預測結果對比圖參數:kline_df: 包含歷史數據的DataFramepred_df: 包含預測數據的DataFrame"""# 將預測數據的索引設置為與歷史數據的最后部分對齊pred_df.index = kline_df.index[-pred_df.shape[0]:]# 提取收盤價數據sr_close = kline_df['close'] # 歷史收盤價sr_pred_close = pred_df['close'] # 預測收盤價sr_close.name = 'Ground Truth' # 真實值標簽sr_pred_close.name = "Prediction" # 預測值標簽# 提取成交量數據sr_volume = kline_df['volume'] # 歷史成交量sr_pred_volume = pred_df['volume'] # 預測成交量sr_volume.name = 'Ground Truth' # 真實值標簽sr_pred_volume.name = "Prediction" # 預測值標簽# 合并數據用于繪圖close_df = pd.concat([sr_close, sr_pred_close], axis=1) # 合并收盤價數據volume_df = pd.concat([sr_volume, sr_pred_volume], axis=1) # 合并成交量數據# 創建包含兩個子圖的圖形:上圖顯示價格,下圖顯示成交量fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 6), sharex=True)# 繪制收盤價對比圖(上圖)ax1.plot(close_df['Ground Truth'], label='Ground Truth', color='blue', linewidth=1.5)ax1.plot(close_df['Prediction'], label='Prediction', color='red', linewidth=1.5)ax1.set_ylabel('Close Price', fontsize=14) # 設置Y軸標簽ax1.legend(loc='lower left', fontsize=12) # 添加圖例ax1.grid(True) # 顯示網格# 繪制成交量對比圖(下圖)ax2.plot(volume_df['Ground Truth'], label='Ground Truth', color='blue', linewidth=1.5)ax2.plot(volume_df['Prediction'], label='Prediction', color='red', linewidth=1.5)ax2.set_ylabel('Volume', fontsize=14) # 設置Y軸標簽ax2.legend(loc='upper left', fontsize=12) # 添加圖例ax2.grid(True) # 顯示網格plt.tight_layout() # 自動調整子圖間距plt.show() # 顯示圖形# ==================== Kronos金融時間序列預測示例 ====================# 1. 加載模型和分詞器
print("正在加載Kronos模型和分詞器...")
# 從預訓練模型加載分詞器,用于將數據轉換為模型可理解的格式
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
# 從預訓練模型加載Kronos小型模型,結構已經在Kronos中定義好了
model = Kronos.from_pretrained("NeoQuasar/Kronos-base")
print("模型和分詞器加載完成!")# 2. 實例化預測器
print("正在初始化預測器...")
# 創建預測器實例,指定使用GPU設備和最大上下文長度
predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512)
print("預測器初始化完成!")# 3. 準備數據
print("正在加載和處理數據...")
# 讀取CSV格式的金融數據文件
df = pd.read_csv("./data/XSHG_5min_600977.csv")
# 將時間戳列轉換為pandas的datetime格式
df['timestamps'] = pd.to_datetime(df['timestamps'])
print(f"數據加載完成,共{len(df)}行數據")# 設置預測參數
lookback = 400 # 用于預測的歷史數據長度(400個時間點)
pred_len = 120 # 預測未來的數據長度(120個時間點)print(f"使用前{lookback}個數據點進行訓練,預測未來{pred_len}個數據點")# 準備輸入數據:選擇前lookback行的OHLCVA數據
# 構造預測數據
x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']]
# 準備輸入時間戳:對應的時間序列
x_timestamp = df.loc[:lookback-1, 'timestamps']
# 準備預測時間戳:需要預測的時間點
y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps']print(f"輸入數據形狀: {x_df.shape}")
print(f"預測時間范圍: {y_timestamp.iloc[0]} 到 {y_timestamp.iloc[-1]}")# 4. 執行預測
print("\n開始執行預測...")
pred_df = predictor.predict(df=x_df, # 輸入的歷史數據x_timestamp=x_timestamp, # 輸入數據的時間戳y_timestamp=y_timestamp, # 預測數據的時間戳pred_len=pred_len, # 預測長度T=1.0, # 溫度參數,控制預測的隨機性top_p=0.9, # Top-p采樣參數,控制預測的多樣性sample_count=1, # 采樣次數verbose=True # 顯示詳細信息
)
print("預測完成!")# 5. 可視化結果
print("\n預測結果前5行:")
print(pred_df.head())# 合并歷史數據和預測數據用于繪圖
# 選擇包含歷史數據和對應預測時間段的真實數據
kline_df = df.loc[:lookback+pred_len-1]print(f"\n繪圖數據范圍: {len(kline_df)}行")
print("正在生成預測結果對比圖...")# 調用可視化函數
plot_prediction(kline_df, pred_df)
補充說明
實例化預測器的參數說明
def init (self, model, tokenizer, device="cuda:0", max_context=512, clip=5)
#- model:已經構建好的時間序列生成模型(Kronos 實例),用于解碼預測。
#- tokenizer:與模型配套的量化分詞器(KronosTokenizer 實例),負責把連續值序列編碼為離散 token,并將 token 解碼回連續值。
#- device:推理設備,默認 "cuda:0"。可改為 "cpu" 或 "cuda:1" 等。
#- max_context:最大上下文窗口長度。超過此長度會在自回歸推理時自動只保留最近 max_context 個 token 作為輸入。
#- clip:標準化后輸入的截斷閾值,表示把輸入特征按元素裁剪到 [-clip, clip] 區間,用于抑制異常值對生成過程的破壞。
在進行數據預測的時候,會先對數據進行標準化,此時,如果數據超過一定范圍,就會導致預測的連續性變差,clip是確定方差的大小,默認 5 意味著保留絕大多數正態范圍內的數值(約 ±5σ)。如果你的數據異常值很多、想更穩健,可適當減小;如果擔心信號被過度截斷,可適當增大。過小會丟信息,過大則抑制效果減弱。
根據原例優化的代碼
import pandas as pd
import matplotlib.pyplot as plt
import os
print(os.getcwd())
# 確定當前路徑的位置,修改下面系統路徑的添加
import sys
sys.path.append("../")
sys.path.append("./")from model import Kronos, KronosTokenizer, KronosPredictor
try:from multi_timeframe_prediction.data_fetcher import CryptoDataFetcher
except Exception as e:print("導入數據獲取器失敗,請確保已安裝 python-binance 并在項目根目錄運行。錯誤:", e)raise##############################
# 代碼思路
# 1. 加載模型
# 2. 加載數據
# 3. 預測
# 4. 可視化
##############################
# 1. 加載模型和分詞器
print("正在加載Kronos模型和分詞器...")# 模型配置
model_name = "NeoQuasar/Kronos-base"
tokenizer_name = "NeoQuasar/Kronos-Tokenizer-base"# 從預訓練模型加載
tokenizer = KronosTokenizer.from_pretrained(tokenizer_name)
model = Kronos.from_pretrained(model_name)
print("模型和分詞器加載完成!")# 2. Instantiate Predictor
predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512)# 3. 準備數據
print("正在加載和處理數據...")
# 使用多周期數據獲取器,僅拉取 BTC 與 ETH 的 30m 數據
timeframe = '30m'# 初始化兩個交易對的數據獲取器
btc_fetcher = CryptoDataFetcher(symbol='BTCUSDT', validate_symbol=True)
eth_fetcher = CryptoDataFetcher(symbol='ETHUSDT', validate_symbol=True)# 獲取數據(默認 limit=1000,可按需調整)
btc_df, btc_path = btc_fetcher.get_data(timeframe, limit=1500)
eth_df, eth_path = eth_fetcher.get_data(timeframe, limit=1500)print(f"BTCUSDT {timeframe} 數據已加載,文件: {btc_path},行數: {len(btc_df)}")
print(f"ETHUSDT {timeframe} 數據已加載,文件: {eth_path},行數: {len(eth_df)}")# 雙重預測策略實現
lookback = 512
pred_len = 60# 判斷數據是否為最新區間(檢查是否有足夠的未來數據用于驗證)
data_length = len(eth_df)
has_future_data = data_length >= (lookback + pred_len)print(f"數據總長度: {data_length}")
print(f"需要的最小長度: {lookback + pred_len}")
print(f"是否有足夠的未來數據進行驗證: {has_future_data}")# 第一輪預測:歷史數據預測(如果數據不在最新區間)
if has_future_data:print("\n=== 第一輪預測:歷史數據驗證預測 ===")print(f"使用前{lookback}個數據點進行訓練,預測未來{pred_len}個數據點(用于驗證)")# 準備歷史驗證預測的輸入數據x_df_hist = eth_df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']]x_timestamp_hist = eth_df.loc[:lookback-1, 'timestamps']y_timestamp_hist = eth_df.loc[lookback:lookback+pred_len-1, 'timestamps']pred_df_list_hist = []
else:print("\n數據長度不足,跳過歷史驗證預測")pred_df_list_hist = []# 定義三組不同的預測參數
predict_configs = [{"T": 0.8, "top_p": 0.85, "sample_count": 3, "name": "保守預測"},{"T": 1.0, "top_p": 0.9, "sample_count": 5, "name": "標準預測"},{"T": 1.2, "top_p": 0.95, "sample_count": 8, "name": "激進預測"}
]# 執行第一輪歷史驗證預測
if has_future_data:print(f"開始進行{len(predict_configs)}次歷史驗證預測...")for i, config in enumerate(predict_configs, 1):print(f"\n正在執行第{i}次歷史驗證預測 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")pred_df = predictor.predict(df=x_df_hist, # 輸入的歷史數據x_timestamp=x_timestamp_hist, # 輸入數據的時間戳y_timestamp=y_timestamp_hist, # 預測數據的時間戳pred_len=pred_len, # 預測長度T=config['T'], # 溫度參數,控制預測的隨機性top_p=config['top_p'], # Top-p采樣參數,控制預測的多樣性sample_count=config['sample_count'], # 采樣次數verbose=False # 關閉詳細信息以減少輸出)# 為預測結果添加標識pred_df.name = config['name'] + "(歷史驗證)"pred_df_list_hist.append(pred_df)print(f"第{i}次歷史驗證預測完成!")print(f"\n所有{len(pred_df_list_hist)}次歷史驗證預測完成!")# 第二輪預測:最新數據的未來預測
print("\n=== 第二輪預測:最新數據未來預測 ===")
print(f"使用最新{lookback}個數據點進行訓練,預測真正的未來{pred_len}個數據點")# 準備最新數據的未來預測輸入
latest_start_idx = max(0, data_length - lookback - pred_len)
if has_future_data:# 如果有足夠數據,使用最新的lookback個點x_df_latest = eth_df.iloc[-lookback:][['open', 'high', 'low', 'close', 'volume', 'amount']]x_timestamp_latest = eth_df.iloc[-lookback:]['timestamps']
else:# 如果數據不足,使用所有可用數據available_data = min(lookback, data_length)x_df_latest = eth_df.iloc[-available_data:][['open', 'high', 'low', 'close', 'volume', 'amount']]x_timestamp_latest = eth_df.iloc[-available_data:]['timestamps']# 生成未來時間戳(基于最后一個時間戳推算)
import pandas as pd
from datetime import timedeltalast_timestamp = eth_df['timestamps'].iloc[-1]
if timeframe == '30m':time_delta = timedelta(minutes=30)
elif timeframe == '1h':time_delta = timedelta(hours=1)
elif timeframe == '1d':time_delta = timedelta(days=1)
else:time_delta = timedelta(minutes=30) # 默認30分鐘# 生成未來時間戳序列
future_timestamps = []
for i in range(1, pred_len + 1):future_timestamps.append(last_timestamp + i * time_delta)
y_timestamp_future = pd.Series(future_timestamps)print(f"最新數據起始時間: {x_timestamp_latest.iloc[0]}")
print(f"最新數據結束時間: {x_timestamp_latest.iloc[-1]}")
print(f"未來預測起始時間: {y_timestamp_future.iloc[0]}")
print(f"未來預測結束時間: {y_timestamp_future.iloc[-1]}")pred_df_list_future = []print(f"開始進行{len(predict_configs)}次未來預測...")# 執行未來預測
for i, config in enumerate(predict_configs, 1):print(f"\n正在執行第{i}次未來預測 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")pred_df = predictor.predict(df=x_df_latest, # 輸入的最新歷史數據x_timestamp=x_timestamp_latest, # 輸入數據的時間戳y_timestamp=y_timestamp_future, # 未來預測的時間戳pred_len=pred_len, # 預測長度T=config['T'], # 溫度參數,控制預測的隨機性top_p=config['top_p'], # Top-p采樣參數,控制預測的多樣性sample_count=config['sample_count'], # 采樣次數verbose=False # 關閉詳細信息以減少輸出)# 為預測結果添加標識pred_df.name = config['name'] + "(未來預測)"pred_df_list_future.append(pred_df)print(f"第{i}次未來預測完成!")print(f"\n所有{len(pred_df_list_future)}次未來預測完成!")# 4. 可視化多次預測結果
print("\n開始繪制預測結果對比圖...")# 創建圖形 - 根據是否有歷史驗證預測決定子圖數量
if has_future_data:fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(20, 12))# 第一組圖:歷史驗證預測print("繪制歷史驗證預測結果...")historical_df = eth_df.loc[:lookback+pred_len-1]historical_close = historical_df['close']historical_volume = historical_df['volume']# 繪制歷史收盤價ax1.plot(historical_close.index[:lookback], historical_close.iloc[:lookback], label='歷史數據', color='black', linewidth=2, alpha=0.8)# 繪制真實的未來數據(用于驗證對比)true_future = historical_close.iloc[lookback:]ax1.plot(true_future.index, true_future.values, label='真實數據', color='green', linewidth=2, alpha=0.7)# 繪制歷史驗證預測結果colors = ['red', 'blue', 'orange']for i, pred_df in enumerate(pred_df_list_hist):pred_index = historical_df.index[lookback:lookback+len(pred_df)]ax1.plot(pred_index, pred_df['close'].values, label=f'{pred_df.name}', color=colors[i], linewidth=1.5, linestyle='--', alpha=0.8)ax1.set_title(f'ETH/USDT {timeframe} 歷史驗證預測對比', fontsize=14, fontweight='bold')ax1.set_ylabel('價格 (USDT)', fontsize=12)ax1.legend(loc='upper left')ax1.grid(True, alpha=0.3)# 繪制歷史驗證的成交量對比ax2.bar(range(len(historical_volume[:lookback])), historical_volume.iloc[:lookback], label='歷史成交量', color='gray', alpha=0.6, width=0.8)for i, pred_df in enumerate(pred_df_list_hist):start_idx = lookbackend_idx = lookback + len(pred_df)ax2.bar(range(start_idx, end_idx), pred_df['volume'].values, label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)ax2.set_title('歷史驗證成交量對比', fontsize=12)ax2.set_xlabel('時間點', fontsize=12)ax2.set_ylabel('成交量', fontsize=12)ax2.legend(loc='upper right')ax2.grid(True, alpha=0.3)# 第二組圖:未來預測print("繪制未來預測結果...")latest_close = x_df_latest['close']latest_volume = x_df_latest['volume']# 繪制最新歷史數據ax3.plot(range(len(latest_close)), latest_close.values, label='最新歷史數據', color='black', linewidth=2, alpha=0.8)# 繪制未來預測結果for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_close)pred_end_idx = pred_start_idx + len(pred_df)ax3.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values, label=f'{pred_df.name}', color=colors[i], linewidth=1.5, linestyle='--', alpha=0.8)ax3.set_title(f'ETH/USDT {timeframe} 未來預測', fontsize=14, fontweight='bold')ax3.set_ylabel('價格 (USDT)', fontsize=12)ax3.legend(loc='upper left')ax3.grid(True, alpha=0.3)# 繪制未來預測的成交量ax4.bar(range(len(latest_volume)), latest_volume.values, label='最新歷史成交量', color='gray', alpha=0.6, width=0.8)for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_volume)pred_end_idx = pred_start_idx + len(pred_df)ax4.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values, label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)ax4.set_title('未來預測成交量', fontsize=12)ax4.set_xlabel('時間點', fontsize=12)ax4.set_ylabel('成交量', fontsize=12)ax4.legend(loc='upper right')ax4.grid(True, alpha=0.3)else:# 只有未來預測的情況fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 10), sharex=True)print("繪制未來預測結果...")latest_close = x_df_latest['close']latest_volume = x_df_latest['volume']# 繪制最新歷史數據ax1.plot(range(len(latest_close)), latest_close.values, label='最新歷史數據', color='black', linewidth=2, alpha=0.8)# 繪制未來預測結果colors = ['red', 'blue', 'orange']for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_close)pred_end_idx = pred_start_idx + len(pred_df)ax1.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values, label=f'{pred_df.name}', color=colors[i], linewidth=1.5, linestyle='--', alpha=0.8)ax1.set_title(f'ETH/USDT {timeframe} 未來預測', fontsize=14, fontweight='bold')ax1.set_ylabel('價格 (USDT)', fontsize=12)ax1.legend(loc='upper left')ax1.grid(True, alpha=0.3)# 繪制未來預測的成交量ax2.bar(range(len(latest_volume)), latest_volume.values, label='最新歷史成交量', color='gray', alpha=0.6, width=0.8)for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_volume)pred_end_idx = pred_start_idx + len(pred_df)ax2.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values, label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)ax2.set_title('未來預測成交量', fontsize=12)ax2.set_xlabel('時間點', fontsize=12)ax2.set_ylabel('成交量', fontsize=12)ax2.legend(loc='upper right')ax2.grid(True, alpha=0.3)plt.tight_layout()
plt.show()# 打印預測結果統計信息
print("\n=== 預測結果統計分析 ===")# 歷史驗證預測統計
if has_future_data:print("\n--- 歷史驗證預測統計 ---")for i, pred_df in enumerate(pred_df_list_hist):close_prices = pred_df['close']print(f"\n{pred_df.name}:")print(f" 收盤價范圍: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")print(f" 平均收盤價: {close_prices.mean():.2f} USDT")print(f" 價格標準差: {close_prices.std():.2f} USDT")# 計算價格變化price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100print(f" 預測期間價格變化: {price_change:+.2f}%")# 與真實數據對比(如果有的話)if len(eth_df) > lookback + pred_len - 1:true_data = eth_df.iloc[lookback:lookback+len(pred_df)]['close']mae = abs(pred_df['close'] - true_data.values).mean()mape = (abs(pred_df['close'] - true_data.values) / true_data.values * 100).mean()print(f" 平均絕對誤差 (MAE): {mae:.2f} USDT")print(f" 平均絕對百分比誤差 (MAPE): {mape:.2f}%")# 未來預測統計
print("\n--- 未來預測統計 ---")
for i, pred_df in enumerate(pred_df_list_future):close_prices = pred_df['close']print(f"\n{pred_df.name}:")print(f" 收盤價范圍: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")print(f" 平均收盤價: {close_prices.mean():.2f} USDT")print(f" 價格標準差: {close_prices.std():.2f} USDT")# 計算價格變化price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100print(f" 預測期間價格變化: {price_change:+.2f}%")# 與當前價格對比current_price = x_df_latest['close'].iloc[-1]initial_change = ((close_prices.iloc[0] - current_price) / current_price) * 100final_change = ((close_prices.iloc[-1] - current_price) / current_price) * 100print(f" 相對當前價格初始變化: {initial_change:+.2f}%")print(f" 相對當前價格最終變化: {final_change:+.2f}%")print("\n=== 雙重預測分析完成 ===")
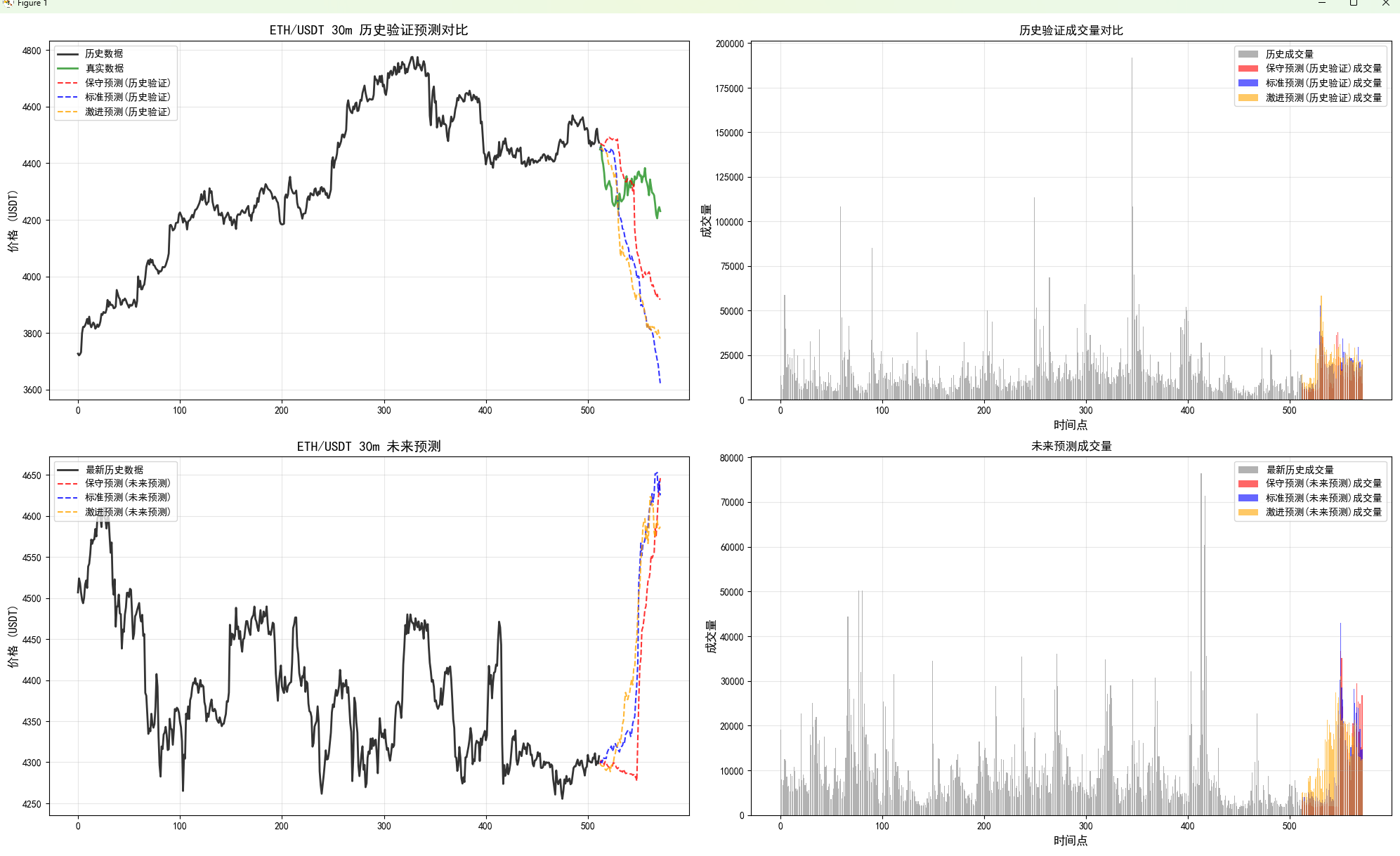
CryptoDataFetcher
#CryptoDataFetcher
# 加密貨幣多周期數據獲取模塊
# Multi-timeframe cryptocurrency data fetcher using Binance APIimport os
import pandas as pd
import time
from datetime import datetime
from binance.client import Client
from typing import Dict, Tuple, Optional, Listclass CryptoDataFetcher:"""加密貨幣多周期數據獲取器支持多種交易對和時間周期的K線數據獲取"""# 默認交易對 - 在這里修改可以統一更改整個系統的交易對# DEFAULT_SYMBOL = 'BTCUSDT' # 可修改為 'ETHUSDT', 'ADAUSDT' 等其他交易對DEFAULT_SYMBOL = 'ETHUSDT' # 可修改為 'ETHUSDT', 'ADAUSDT' 等其他交易對# 支持的時間周期映射TIMEFRAME_MAP = {# 分鐘級別'1m': Client.KLINE_INTERVAL_1MINUTE,'3m': Client.KLINE_INTERVAL_3MINUTE,'5m': Client.KLINE_INTERVAL_5MINUTE,'15m': Client.KLINE_INTERVAL_15MINUTE,'30m': Client.KLINE_INTERVAL_30MINUTE,# 小時級別'1h': Client.KLINE_INTERVAL_1HOUR,'2h': Client.KLINE_INTERVAL_2HOUR,'4h': Client.KLINE_INTERVAL_4HOUR,'6h': Client.KLINE_INTERVAL_6HOUR,'8h': Client.KLINE_INTERVAL_8HOUR,'12h': Client.KLINE_INTERVAL_12HOUR,# 日級別'1d': Client.KLINE_INTERVAL_1DAY,'3d': Client.KLINE_INTERVAL_3DAY,# 周月級別'1w': Client.KLINE_INTERVAL_1WEEK,'1M': Client.KLINE_INTERVAL_1MONTH}# 時間周期描述TIMEFRAME_DESC = {# 分鐘級別'1m': '1分鐘','3m': '3分鐘','5m': '5分鐘', '15m': '15分鐘','30m': '30分鐘',# 小時級別'1h': '1小時','2h': '2小時','4h': '4小時','6h': '6小時','8h': '8小時','12h': '12小時',# 日級別'1d': '1天','3d': '3天',# 周月級別'1w': '1周','1M': '1月'}# 推薦的時間周期組合TIMEFRAME_COMBINATIONS = {'scalping': ['1m', '5m', '15m'], # 超短線'day_trading': ['5m', '15m', '1h', '4h'], # 日內交易'swing_trading': ['1h', '4h', '1d'], # 波段交易'position_trading': ['4h', '1d', '1w'], # 趨勢交易'comprehensive': ['5m', '15m', '1h', '4h', '1d'] # 綜合分析}# 常用交易對列表 (主流貨幣)POPULAR_SYMBOLS = {'BTCUSDT': 'Bitcoin','ETHUSDT': 'Ethereum','DOGEUSDT': 'Dogecoin','SOLUSDT': 'Solana'}def __init__(self, symbol: str = None, validate_symbol: bool = True):"""初始化數據獲取器參數:symbol: 交易對符號,默認使用 DEFAULT_SYMBOLvalidate_symbol: 是否驗證交易對有效性,默認True"""self.symbol = (symbol or self.DEFAULT_SYMBOL).upper()self.client = Client() # 無需API Key的公共客戶端# 驗證交易對if validate_symbol:self._validate_symbol()print(f"初始化數據獲取器 - 交易對: {self.symbol}")if self.symbol in self.POPULAR_SYMBOLS:print(f"幣種名稱: {self.POPULAR_SYMBOLS[self.symbol]}")def get_data(self, timeframe: str, limit: int = 1000, start_time: Optional[datetime] = None, end_time: Optional[datetime] = None, sleep_sec: float = 0.2, strict_limit: bool = True) -> Tuple[pd.DataFrame, str]:"""獲取指定時間周期的K線數據(支持自動分頁)參數:timeframe: 時間周期 ('1m', '5m', '15m', '30m', '1h', '4h', '1d')limit: 目標獲取的數據條數,默認1000條;超過1000將自動分頁抓取start_time: 可選,起始時間(datetime),如提供將從此時間開始向后拉取end_time: 可選,結束時間(datetime),如提供將不超過該時間sleep_sec: 分頁請求之間的休眠秒數,默認0.2,避免觸發頻率限制strict_limit: 若為True,最終返回不超過limit條;若為False,若最后一頁跨越end_time邊界可能略多返回:tuple: (DataFrame, 文件路徑)"""if timeframe not in self.TIMEFRAME_MAP:raise ValueError(f"不支持的時間周期: {timeframe}. 支持的周期: {list(self.TIMEFRAME_MAP.keys())}")print(f"正在獲取{self.symbol} {self.TIMEFRAME_DESC[timeframe]}K線數據...")try:max_per_req = 1000interval = self.TIMEFRAME_MAP[timeframe]collected: List[list] = []# 情況1:未提供時間范圍 -> 從最新開始向過去分頁if start_time is None and end_time is None:fetched = 0end_ms = None # 第一頁不指定endTime,拿最近的數據while True:batch_limit = min(max_per_req, limit - fetched) if strict_limit else max_per_reqif batch_limit <= 0:breakparams = {'symbol': self.symbol,'interval': interval,'limit': batch_limit}if end_ms is not None:params['endTime'] = end_msbatch = self.client.get_klines(**params)if not batch:print(" 未返回更多數據,提前結束。")break# 將更老的一批放在前面,保持時間正序collected = batch + collectedfetched += len(batch)# 下一頁向過去推進:使用本批次最早一根的open time - 1first_open_time = batch[0][0]next_end_ms = first_open_time - 1if end_ms is not None and next_end_ms >= end_ms:print(" 未能向更早時間推進,停止。")breakend_ms = next_end_msprint(f" 已獲取: {fetched} 條...")if strict_limit and fetched >= limit:breakif sleep_sec and sleep_sec > 0:time.sleep(sleep_sec)# 情況2:提供start_time(可選end_time) -> 從start_time向未來分頁elif start_time is not None:fetched = 0start_ms = int(start_time.timestamp() * 1000)end_ms = int(end_time.timestamp() * 1000) if end_time else Nonewhile True:batch_limit = min(max_per_req, limit - fetched) if strict_limit else max_per_reqif batch_limit <= 0:breakparams = {'symbol': self.symbol,'interval': interval,'limit': batch_limit,'startTime': start_ms}if end_ms is not None:params['endTime'] = end_msbatch = self.client.get_klines(**params)if not batch:print(" 未返回更多數據,提前結束。")breakcollected.extend(batch)fetched += len(batch)last_open_time = batch[-1][0]# 如達到end_time或已無前進空間,則停止if end_ms is not None and last_open_time >= end_ms:breaknext_start = last_open_time + 1if next_start <= start_ms:print(" 未能向更晚時間推進,停止。")breakstart_ms = next_startprint(f" 已獲取: {fetched} 條...")if strict_limit and fetched >= limit:breakif sleep_sec and sleep_sec > 0:time.sleep(sleep_sec)# 情況3:僅提供end_time -> 從end_time開始向過去分頁else:fetched = 0end_ms = int(end_time.timestamp() * 1000)while True:batch_limit = min(max_per_req, limit - fetched) if strict_limit else max_per_reqif batch_limit <= 0:breakparams = {'symbol': self.symbol,'interval': interval,'limit': batch_limit,'endTime': end_ms}batch = self.client.get_klines(**params)if not batch:print(" 未返回更多數據,提前結束。")breakcollected = batch + collectedfetched += len(batch)first_open_time = batch[0][0]next_end = first_open_time - 1if next_end >= end_ms:print(" 未能向更早時間推進,停止。")breakend_ms = next_endprint(f" 已獲取: {fetched} 條...")if strict_limit and fetched >= limit:breakif sleep_sec and sleep_sec > 0:time.sleep(sleep_sec)klines = collected# 轉換數據格式data = []for kline in klines:timestamp = datetime.fromtimestamp(kline[0] / 1000)data.append({'timestamps': timestamp,'open': float(kline[1]),'high': float(kline[2]),'low': float(kline[3]),'close': float(kline[4]),'volume': float(kline[5]),'amount': float(kline[7]) # quote asset volume})df = pd.DataFrame(data)# 規范化順序與去重if not df.empty:df = df.sort_values('timestamps').drop_duplicates(subset=['timestamps'], keep='last').reset_index(drop=True)# 若嚴格限制且實際超過limit,根據方向裁剪if strict_limit and len(df) > limit:if start_time is not None:df = df.iloc[:limit].reset_index(drop=True) # 從start_time開始的前limit條else:df = df.iloc[-limit:].reset_index(drop=True) # 最近的limit條# 保存數據到文件(使用實際行數命名)filepath = self._save_data(df, timeframe, len(df))# 打印數據信息self._print_data_info(df, timeframe)return df, filepathexcept Exception as e:print(f"獲取{self.TIMEFRAME_DESC[timeframe]}數據失敗: {e}")raisedef get_multiple_timeframes(self, timeframes: list, limit: int = 1000) -> Dict[str, Tuple[pd.DataFrame, str]]:"""獲取多個時間周期的數據參數:timeframes: 時間周期列表limit: 每個周期獲取的數據條數返回:dict: {timeframe: (DataFrame, filepath)}"""results = {}print(f"\n開始獲取{len(timeframes)}個時間周期的數據...")print("="*60)for i, timeframe in enumerate(timeframes, 1):print(f"\n[{i}/{len(timeframes)}] 獲取{self.TIMEFRAME_DESC[timeframe]}數據")try:df, filepath = self.get_data(timeframe, limit)results[timeframe] = (df, filepath)print(f"? {self.TIMEFRAME_DESC[timeframe]}數據獲取成功")except Exception as e:print(f"? {self.TIMEFRAME_DESC[timeframe]}數據獲取失敗: {e}")results[timeframe] = (None, None)print("\n" + "="*60)print(f"數據獲取完成!成功獲取 {sum(1 for v in results.values() if v[0] is not None)}/{len(timeframes)} 個時間周期")return resultsdef _save_data(self, df: pd.DataFrame, timeframe: str, limit: int) -> str:"""保存數據到文件參數:df: 數據DataFrametimeframe: 時間周期limit: 數據條數返回:str: 文件路徑"""# 創建數據目錄data_dir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'multi_timeframe_data')os.makedirs(data_dir, exist_ok=True)# 生成文件名timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')filename = f"{self.symbol}_{timeframe}_{limit}_{timestamp}.csv"filepath = os.path.join(data_dir, filename)# 保存文件df.to_csv(filepath, index=False)return filepathdef _print_data_info(self, df: pd.DataFrame, timeframe: str):"""打印數據信息參數:df: 數據DataFrametimeframe: 時間周期"""print(f" 數據行數: {len(df)}")print(f" 時間范圍: {df['timestamps'].min()} 到 {df['timestamps'].max()}")# 提取交易對的基礎貨幣名稱(如BTCUSDT -> BTC)base_currency = self.symbol.replace('USDT', '').replace('BUSD', '').replace('USD', '')print(f" 當前{base_currency}價格: ${df['close'].iloc[-1]:.2f}")# 計算時間跨度time_span = df['timestamps'].max() - df['timestamps'].min()print(f" 數據時間跨度: {time_span}")@classmethoddef get_supported_timeframes(cls) -> Dict[str, str]:"""獲取支持的時間周期列表返回:dict: {timeframe: description}"""return cls.TIMEFRAME_DESC.copy()@classmethoddef get_default_timeframes(cls) -> list:"""獲取默認的時間周期列表返回:list: 默認時間周期列表"""return ['1m', '5m', '15m', '1h', '4h', '1d']@classmethoddef get_timeframe_combinations(cls) -> Dict[str, List[str]]:"""獲取推薦的時間周期組合返回:dict: {策略名稱: [時間周期列表]}"""return cls.TIMEFRAME_COMBINATIONS.copy()@classmethoddef get_popular_symbols(cls) -> Dict[str, str]:"""獲取常用交易對列表返回:dict: {交易對: 幣種名稱}"""return cls.POPULAR_SYMBOLS.copy()def _validate_symbol(self):"""驗證交易對是否有效拋出:ValueError: 如果交易對無效"""try:# 嘗試獲取交易對信息ticker = self.client.get_symbol_ticker(symbol=self.symbol)print(f"? 交易對 {self.symbol} 驗證成功,當前價格: ${float(ticker['price']):.4f}")except Exception as e:available_symbols = ', '.join(list(self.POPULAR_SYMBOLS.keys())[:10])raise ValueError(f"交易對 {self.symbol} 無效或不存在。\n"f"常用交易對示例: {available_symbols}...\n"f"錯誤詳情: {str(e)}")def get_symbol_info(self) -> Dict:"""獲取當前交易對的詳細信息返回:dict: 交易對信息"""try:# 獲取交易對信息symbol_info = self.client.get_symbol_info(self.symbol)ticker = self.client.get_symbol_ticker(symbol=self.symbol)info = {'symbol': self.symbol,'name': self.POPULAR_SYMBOLS.get(self.symbol, 'Unknown'),'status': symbol_info['status'],'current_price': float(ticker['price']),'base_asset': symbol_info['baseAsset'],'quote_asset': symbol_info['quoteAsset'],'price_precision': symbol_info['quotePrecision'],'quantity_precision': symbol_info['baseAssetPrecision']}return infoexcept Exception as e:print(f"獲取交易對信息失敗: {e}")return {}@classmethoddef search_symbols(cls, keyword: str) -> List[str]:"""搜索包含關鍵詞的交易對參數:keyword: 搜索關鍵詞返回:list: 匹配的交易對列表"""keyword = keyword.upper()matches = []for symbol, name in cls.POPULAR_SYMBOLS.items():if keyword in symbol or keyword in name.upper():matches.append(symbol)return matchesdef change_symbol(self, new_symbol: str, validate: bool = True):"""更改當前交易對參數:new_symbol: 新的交易對符號validate: 是否驗證新交易對"""old_symbol = self.symbolself.symbol = new_symbol.upper()if validate:try:self._validate_symbol()print(f"交易對已從 {old_symbol} 更改為 {self.symbol}")except ValueError as e:self.symbol = old_symbol # 恢復原交易對raise eelse:print(f"交易對已從 {old_symbol} 更改為 {self.symbol} (未驗證)")# 為了向后兼容,保留原類名作為別名
BTCDataFetcher = CryptoDataFetcher單幣對多周期預測
結果保存在文件夾里。
有歷史回測,默認使用最新的一些時間點。在TIMEFRAMES 這些配置參數的地方修改。
# 雙重預測策略實現
lookback = 512
pred_len = 60
lookback是模型支持的預測的長度,最大就是512.
還有未來值預測,使用三種參數的預測策略,進行對比。
import pandas as pd
import matplotlib.pyplot as plt
import os
print(os.getcwd())
# 確定當前路徑的位置,修改下面系統路徑的添加
import sys
sys.path.append("../")
sys.path.append("./")from model import Kronos, KronosTokenizer, KronosPredictor
try:from multi_timeframe_prediction.data_fetcher import CryptoDataFetcher
except Exception as e:print("導入數據獲取器失敗,請確保已安裝 python-binance 并在項目根目錄運行。錯誤:", e)raise##############################
# 代碼思路
# 1. 加載模型
# 2. 加載數據
# 3. 預測
# 4. 可視化
##############################
# 1. 加載模型和分詞器
print("正在加載Kronos模型和分詞器...")# 模型配置
model_name = "NeoQuasar/Kronos-base"
tokenizer_name = "NeoQuasar/Kronos-Tokenizer-base"# 從預訓練模型加載
tokenizer = KronosTokenizer.from_pretrained(tokenizer_name)
model = Kronos.from_pretrained(model_name)
print("模型和分詞器加載完成!")# 2. Instantiate Predictor
predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512)# 3. 準備數據
print("正在加載和處理數據...")
# 配置參數
SYMBOL = 'ETHUSDT' # 可選擇的幣種: BTCUSDT, ETHUSDT, ADAUSDT, DOTUSDT 等
TIMEFRAMES = ['5m', '15m', '1h'] # 多個時間周期
DATA_LIMIT = 1500 # 數據獲取數量
SAVE_RESULTS = True # 是否保存結果到文件
RESULTS_DIR = '../prediction_results' # 結果保存目錄# 創建結果保存目錄
import os
from datetime import datetime
if SAVE_RESULTS and not os.path.exists(RESULTS_DIR):os.makedirs(RESULTS_DIR)# 初始化數據獲取器
fetcher = CryptoDataFetcher(symbol=SYMBOL, validate_symbol=True)# 存儲所有時間周期的數據和預測結果
all_results = {}print(f"開始處理 {SYMBOL} 的多時間周期預測...")
print(f"時間周期: {TIMEFRAMES}")
print(f"數據獲取數量: {DATA_LIMIT}")
if SAVE_RESULTS:print(f"結果將保存到: {RESULTS_DIR}")for timeframe in TIMEFRAMES:print(f"\n=== 處理 {SYMBOL} {timeframe} 時間周期 ===")# 獲取當前時間周期的數據df, data_path = fetcher.get_data(timeframe, limit=DATA_LIMIT)print(f"{SYMBOL} {timeframe} 數據已加載,文件: {data_path},行數: {len(df)}")# 將數據存儲到結果字典中all_results[timeframe] = {'data': df,'data_path': data_path,'predictions': {'historical': [], 'future': []}}# 使用當前時間周期的數據進行預測current_df = df# 雙重預測策略實現lookback = 512pred_len = 60# 判斷數據是否為最新區間(檢查是否有足夠的未來數據用于驗證)data_length = len(current_df)has_future_data = data_length >= (lookback + pred_len)print(f"數據總長度: {data_length}")print(f"需要的最小長度: {lookback + pred_len}")print(f"是否有足夠的未來數據進行驗證: {has_future_data}")# 第一輪預測:歷史數據預測(如果數據不在最新區間)if has_future_data:print("\n=== 第一輪預測:歷史數據驗證預測 ===")print(f"使用最新數據的倒數第{pred_len+1}到倒數第{pred_len+lookback}個數據點進行訓練")print(f"預測最新的{pred_len}個數據點(用于驗證)")# 準備歷史驗證預測的輸入數據 - 使用最新數據但預留最后pred_len個點用于驗證# 輸入數據:倒數第(pred_len+lookback)到倒數第(pred_len+1)個數據點start_idx = data_length - pred_len - lookbackend_idx = data_length - pred_lenx_df_hist = current_df.iloc[start_idx:end_idx][['open', 'high', 'low', 'close', 'volume', 'amount']]x_timestamp_hist = current_df.iloc[start_idx:end_idx]['timestamps']# 預測目標:最新的pred_len個數據點(用于驗證)y_timestamp_hist = current_df.iloc[-pred_len:]['timestamps']print(f"訓練數據范圍:第{start_idx+1}到第{end_idx}個數據點")print(f"驗證數據范圍:第{data_length-pred_len+1}到第{data_length}個數據點(最新{pred_len}個點)")pred_df_list_hist = []else:print("\n數據長度不足,跳過歷史驗證預測")pred_df_list_hist = []# 定義三組不同的預測參數predict_configs = [{"T": 0.8, "top_p": 0.85, "sample_count": 3, "name": "保守預測"},{"T": 1.0, "top_p": 0.9, "sample_count": 5, "name": "標準預測"},{"T": 1.2, "top_p": 0.95, "sample_count": 8, "name": "激進預測"}]# 執行第一輪歷史驗證預測if has_future_data:print(f"開始進行{len(predict_configs)}次歷史驗證預測...")for i, config in enumerate(predict_configs, 1):print(f"\n正在執行第{i}次歷史驗證預測 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")pred_df = predictor.predict(df=x_df_hist, # 輸入的歷史數據x_timestamp=x_timestamp_hist, # 輸入數據的時間戳y_timestamp=y_timestamp_hist, # 預測數據的時間戳pred_len=pred_len, # 預測長度T=config['T'], # 溫度參數,控制預測的隨機性top_p=config['top_p'], # Top-p采樣參數,控制預測的多樣性sample_count=config['sample_count'], # 采樣次數verbose=False # 關閉詳細信息以減少輸出)# 為預測結果添加標識pred_df.name = config['name'] + "(歷史驗證)"pred_df_list_hist.append(pred_df)print(f"第{i}次歷史驗證預測完成!")print(f"\n所有{len(pred_df_list_hist)}次歷史驗證預測完成!")# 保存歷史驗證預測結果all_results[timeframe]['predictions']['historical'] = pred_df_list_hist# 第二輪預測:最新數據的未來預測print("\n=== 第二輪預測:最新數據未來預測 ===")print(f"使用最新{lookback}個數據點進行訓練,預測真正的未來{pred_len}個數據點")# 準備最新數據的未來預測輸入latest_start_idx = max(0, data_length - lookback - pred_len)if has_future_data:# 如果有足夠數據,使用最新的lookback個點x_df_latest = current_df.iloc[-lookback:][['open', 'high', 'low', 'close', 'volume', 'amount']]x_timestamp_latest = current_df.iloc[-lookback:]['timestamps']else:# 如果數據不足,使用所有可用數據available_data = min(lookback, data_length)x_df_latest = current_df.iloc[-available_data:][['open', 'high', 'low', 'close', 'volume', 'amount']]x_timestamp_latest = current_df.iloc[-available_data:]['timestamps']# 生成未來時間戳(基于最后一個時間戳推算)from datetime import timedeltalast_timestamp = current_df['timestamps'].iloc[-1]if timeframe == '5m':time_delta = timedelta(minutes=5)elif timeframe == '15m':time_delta = timedelta(minutes=15)elif timeframe == '30m':time_delta = timedelta(minutes=30)elif timeframe == '1h':time_delta = timedelta(hours=1)elif timeframe == '1d':time_delta = timedelta(days=1)else:time_delta = timedelta(minutes=30) # 默認30分鐘# 生成未來時間戳序列future_timestamps = []for i in range(1, pred_len + 1):future_timestamps.append(last_timestamp + i * time_delta)y_timestamp_future = pd.Series(future_timestamps)print(f"最新數據起始時間: {x_timestamp_latest.iloc[0]}")print(f"最新數據結束時間: {x_timestamp_latest.iloc[-1]}")print(f"未來預測起始時間: {y_timestamp_future.iloc[0]}")print(f"未來預測結束時間: {y_timestamp_future.iloc[-1]}")pred_df_list_future = []print(f"開始進行{len(predict_configs)}次未來預測...")# 執行未來預測for i, config in enumerate(predict_configs, 1):print(f"\n正在執行第{i}次未來預測 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")pred_df = predictor.predict(df=x_df_latest, # 輸入的最新歷史數據x_timestamp=x_timestamp_latest, # 輸入數據的時間戳y_timestamp=y_timestamp_future, # 未來預測的時間戳pred_len=pred_len, # 預測長度T=config['T'], # 溫度參數,控制預測的隨機性top_p=config['top_p'], # Top-p采樣參數,控制預測的多樣性sample_count=config['sample_count'], # 采樣次數verbose=False # 關閉詳細信息以減少輸出)# 為預測結果添加標識pred_df.name = config['name'] + "(未來預測)"pred_df_list_future.append(pred_df)print(f"第{i}次未來預測完成!")print(f"\n所有{len(pred_df_list_future)}次未來預測完成!")# 保存未來預測結果all_results[timeframe]['predictions']['future'] = pred_df_list_future# 4. 可視化多次預測結果print(f"\n開始繪制 {timeframe} 預測結果對比圖...")# 創建圖形 - 根據是否有歷史驗證預測決定子圖數量if has_future_data:fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(20, 12))# 第一組圖:歷史驗證預測print("繪制歷史驗證預測結果...")# 使用最新數據進行歷史驗證預測的可視化# 訓練數據:倒數第(pred_len+lookback)到倒數第(pred_len+1)個數據點start_idx = data_length - pred_len - lookbackend_idx = data_length - pred_len# 訓練數據部分train_data = current_df.iloc[start_idx:end_idx]train_close = train_data['close']train_volume = train_data['volume']# 真實的最新數據(用于驗證對比)true_latest = current_df.iloc[-pred_len:]true_latest_close = true_latest['close']true_latest_volume = true_latest['volume']# 繪制訓練數據train_x = range(len(train_close))ax1.plot(train_x, train_close.values, label='訓練數據', color='black', linewidth=2, alpha=0.8)# 繪制真實的最新數據(用于驗證對比)true_x = range(len(train_close), len(train_close) + len(true_latest_close))ax1.plot(true_x, true_latest_close.values, label='真實最新數據', color='green', linewidth=2, alpha=0.7)# 繪制歷史驗證預測結果colors = ['red', 'blue', 'orange']for i, pred_df in enumerate(pred_df_list_hist):pred_x = range(len(train_close), len(train_close) + len(pred_df))ax1.plot(pred_x, pred_df['close'].values, label=f'{pred_df.name}', color=colors[i], linewidth=1.5, linestyle='--', alpha=0.8)ax1.set_title(f'{SYMBOL} {timeframe} 歷史驗證預測對比(最新數據驗證)', fontsize=14, fontweight='bold')ax1.set_ylabel('價格 (USDT)', fontsize=12)ax1.legend(loc='upper left')ax1.grid(True, alpha=0.3)# 繪制歷史驗證的成交量對比ax2.bar(train_x, train_volume.values, label='訓練數據成交量', color='gray', alpha=0.6, width=0.8)ax2.bar(true_x, true_latest_volume.values, label='真實最新成交量', color='green', alpha=0.6, width=0.8)for i, pred_df in enumerate(pred_df_list_hist):pred_x = range(len(train_close), len(train_close) + len(pred_df))ax2.bar(pred_x, pred_df['volume'].values, label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)ax2.set_title('歷史驗證成交量對比(最新數據驗證)', fontsize=12)ax2.set_xlabel('時間點', fontsize=12)ax2.set_ylabel('成交量', fontsize=12)ax2.legend(loc='upper right')ax2.grid(True, alpha=0.3)# 第二組圖:未來預測print("繪制未來預測結果...")latest_close = x_df_latest['close']latest_volume = x_df_latest['volume']# 繪制最新歷史數據ax3.plot(range(len(latest_close)), latest_close.values, label='最新歷史數據', color='black', linewidth=2, alpha=0.8)# 繪制未來預測結果for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_close)pred_end_idx = pred_start_idx + len(pred_df)ax3.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values, label=f'{pred_df.name}', color=colors[i], linewidth=1.5, linestyle='--', alpha=0.8)ax3.set_title(f'{SYMBOL} {timeframe} 未來預測', fontsize=14, fontweight='bold')ax3.set_ylabel('價格 (USDT)', fontsize=12)ax3.legend(loc='upper left')ax3.grid(True, alpha=0.3)# 繪制未來預測的成交量ax4.bar(range(len(latest_volume)), latest_volume.values, label='最新歷史成交量', color='gray', alpha=0.6, width=0.8)for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_volume)pred_end_idx = pred_start_idx + len(pred_df)ax4.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values, label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)ax4.set_title('未來預測成交量', fontsize=12)ax4.set_xlabel('時間點', fontsize=12)ax4.set_ylabel('成交量', fontsize=12)ax4.legend(loc='upper right')ax4.grid(True, alpha=0.3)else:# 只有未來預測的情況fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 10), sharex=True)print("繪制未來預測結果...")latest_close = x_df_latest['close']latest_volume = x_df_latest['volume']# 繪制最新歷史數據ax1.plot(range(len(latest_close)), latest_close.values, label='最新歷史數據', color='black', linewidth=2, alpha=0.8)# 繪制未來預測結果colors = ['red', 'blue', 'orange']for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_close)pred_end_idx = pred_start_idx + len(pred_df)ax1.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values, label=f'{pred_df.name}', color=colors[i], linewidth=1.5, linestyle='--', alpha=0.8)ax1.set_title(f'{SYMBOL} {timeframe} 未來預測', fontsize=14, fontweight='bold')ax1.set_ylabel('價格 (USDT)', fontsize=12)ax1.legend(loc='upper left')ax1.grid(True, alpha=0.3)# 繪制未來預測的成交量ax2.bar(range(len(latest_volume)), latest_volume.values, label='最新歷史成交量', color='gray', alpha=0.6, width=0.8)for i, pred_df in enumerate(pred_df_list_future):pred_start_idx = len(latest_volume)pred_end_idx = pred_start_idx + len(pred_df)ax2.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values, label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)ax2.set_title('未來預測成交量', fontsize=12)ax2.set_xlabel('時間點', fontsize=12)ax2.set_ylabel('成交量', fontsize=12)ax2.legend(loc='upper right')ax2.grid(True, alpha=0.3)plt.tight_layout()# 保存圖表到文件chart_filename = f"{SYMBOL}_{timeframe}_prediction_results.png"chart_path = os.path.join(RESULTS_DIR, chart_filename)plt.savefig(chart_path, dpi=300, bbox_inches='tight')plt.close() # 關閉圖表以釋放內存print(f"圖表已保存到: {chart_path}")# 保存圖表路徑到結果字典all_results[timeframe]['chart_path'] = chart_path# 保存預測數據到CSV文件print(f"正在保存 {timeframe} 預測數據到文件...")# 保存歷史驗證預測數據if has_future_data and pred_df_list_hist:for i, pred_df in enumerate(pred_df_list_hist):hist_filename = f"{SYMBOL}_{timeframe}_historical_prediction_{i+1}_{pred_df.name.replace(' ', '_').replace('(', '').replace(')', '')}.csv"hist_path = os.path.join(RESULTS_DIR, hist_filename)pred_df.to_csv(hist_path, index=False)print(f" 歷史驗證預測 {i+1} 已保存: {hist_filename}")# 保存未來預測數據for i, pred_df in enumerate(pred_df_list_future):future_filename = f"{SYMBOL}_{timeframe}_future_prediction_{i+1}_{pred_df.name.replace(' ', '_').replace('(', '').replace(')', '')}.csv"future_path = os.path.join(RESULTS_DIR, future_filename)pred_df.to_csv(future_path, index=False)print(f" 未來預測 {i+1} 已保存: {future_filename}")# 保存原始數據(用于參考)data_filename = f"{SYMBOL}_{timeframe}_original_data.csv"data_path = os.path.join(RESULTS_DIR, data_filename)current_df.to_csv(data_path, index=False)print(f" 原始數據已保存: {data_filename}")# 打印預測結果統計信息
print(f"\n=== {timeframe} 預測結果統計分析 ===")# 歷史驗證預測統計
if has_future_data:print("\n--- 歷史驗證預測統計 ---")for i, pred_df in enumerate(pred_df_list_hist):close_prices = pred_df['close']print(f"\n{pred_df.name}:")print(f" 收盤價范圍: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")print(f" 平均收盤價: {close_prices.mean():.2f} USDT")print(f" 價格標準差: {close_prices.std():.2f} USDT")# 計算價格變化price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100print(f" 預測期間價格變化: {price_change:+.2f}%")# 與真實最新數據對比true_latest_data = current_df.iloc[-pred_len:]['close']mae = abs(pred_df['close'] - true_latest_data.values).mean()mape = (abs(pred_df['close'] - true_latest_data.values) / true_latest_data.values * 100).mean()# 計算相關系數correlation = pred_df['close'].corr(pd.Series(true_latest_data.values))print(f" 平均絕對誤差 (MAE): {mae:.2f} USDT")print(f" 平均絕對百分比誤差 (MAPE): {mape:.2f}%")print(f" 與真實數據相關系數: {correlation:.4f}")# 計算方向準確性(漲跌方向預測準確率)pred_direction = (pred_df['close'].diff() > 0).iloc[1:]true_direction = (pd.Series(true_latest_data.values).diff() > 0).iloc[1:]# 重置索引以確保兩個Series可以正確比較pred_direction = pred_direction.reset_index(drop=True)true_direction = true_direction.reset_index(drop=True)direction_accuracy = (pred_direction == true_direction).mean() * 100print(f" 方向預測準確率: {direction_accuracy:.1f}%")# 未來預測統計
print("\n--- 未來預測統計 ---")
for i, pred_df in enumerate(pred_df_list_future):close_prices = pred_df['close']print(f"\n{pred_df.name}:")print(f" 收盤價范圍: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")print(f" 平均收盤價: {close_prices.mean():.2f} USDT")print(f" 價格標準差: {close_prices.std():.2f} USDT")# 計算價格變化price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100print(f" 預測期間價格變化: {price_change:+.2f}%")# 與當前價格對比current_price = x_df_latest['close'].iloc[-1]initial_change = ((close_prices.iloc[0] - current_price) / current_price) * 100final_change = ((close_prices.iloc[-1] - current_price) / current_price) * 100print(f" 相對當前價格初始變化: {initial_change:+.2f}%")print(f" 相對當前價格最終變化: {final_change:+.2f}%")print(f"\n=== {timeframe} 預測分析完成 ===")# 所有時間周期處理完成后的總結
print("\n=== 所有時間周期預測完成 ===")
for tf in TIMEFRAMES:hist_count = len(all_results[tf]['predictions']['historical'])future_count = len(all_results[tf]['predictions']['future'])print(f"{tf}: 歷史驗證預測{hist_count}次, 未來預測{future_count}次")# 保存完整結果摘要到JSON文件
print("\n正在保存完整結果摘要...")
summary_data = {'symbol': SYMBOL,'timeframes': TIMEFRAMES,'prediction_configs': predict_configs,'results_directory': RESULTS_DIR,'timestamp': pd.Timestamp.now().isoformat(),'summary': {}
}for tf in TIMEFRAMES:summary_data['summary'][tf] = {'historical_predictions_count': len(all_results[tf]['predictions']['historical']),'future_predictions_count': len(all_results[tf]['predictions']['future']),'chart_path': all_results[tf]['chart_path'],'data_length': len(all_results[tf]['data']),'has_future_data': len(all_results[tf]['data']) > lookback + pred_len}summary_filename = f"{SYMBOL}_prediction_summary_{pd.Timestamp.now().strftime('%Y%m%d_%H%M%S')}.json"
summary_path = os.path.join(RESULTS_DIR, summary_filename)import json
with open(summary_path, 'w', encoding='utf-8') as f:json.dump(summary_data, f, indent=2, ensure_ascii=False)print(f"結果摘要已保存: {summary_filename}")print(f"\n=== 所有預測任務完成 ===")
print(f"幣種: {SYMBOL}")
print(f"時間周期: {', '.join(TIMEFRAMES)}")
print(f"結果保存目錄: {RESULTS_DIR}")
print("\n保存的文件包含:")
print("- 各時間周期的預測數據 (CSV格式)")
print("- 對應的可視化圖表 (PNG格式)")
print("- 原始K線數據 (CSV格式)")
print("- 完整結果摘要 (JSON格式)")
print("- 預測結果字典變量 all_results (內存中)")print("\n可以通過以下方式查看結果:")
print(f"1. 打開目錄: {RESULTS_DIR}")
print("2. 查看圖表文件了解預測趨勢")
print("3. 分析CSV數據文件進行詳細研究")
print("4. 使用 all_results 變量進行進一步的程序化分析")
=== 所有預測任務完成 ===
幣種: ETHUSDT
時間周期: 5m, 15m, 30m, 1h, 4h
結果保存目錄: …/prediction_results
保存的文件包含:
- 各時間周期的預測數據 (CSV格式)
- 對應的可視化圖表 (PNG格式)
- 原始K線數據 (CSV格式)
- 完整結果摘要 (JSON格式)
- 預測結果字典變量 all_results (內存中)
可以通過以下方式查看結果:
- 打開目錄: …/prediction_results
- 查看圖表文件了解預測趨勢
- 分析CSV數據文件進行詳細研究
- 使用 all_results 變量進行進一步的程序化分析
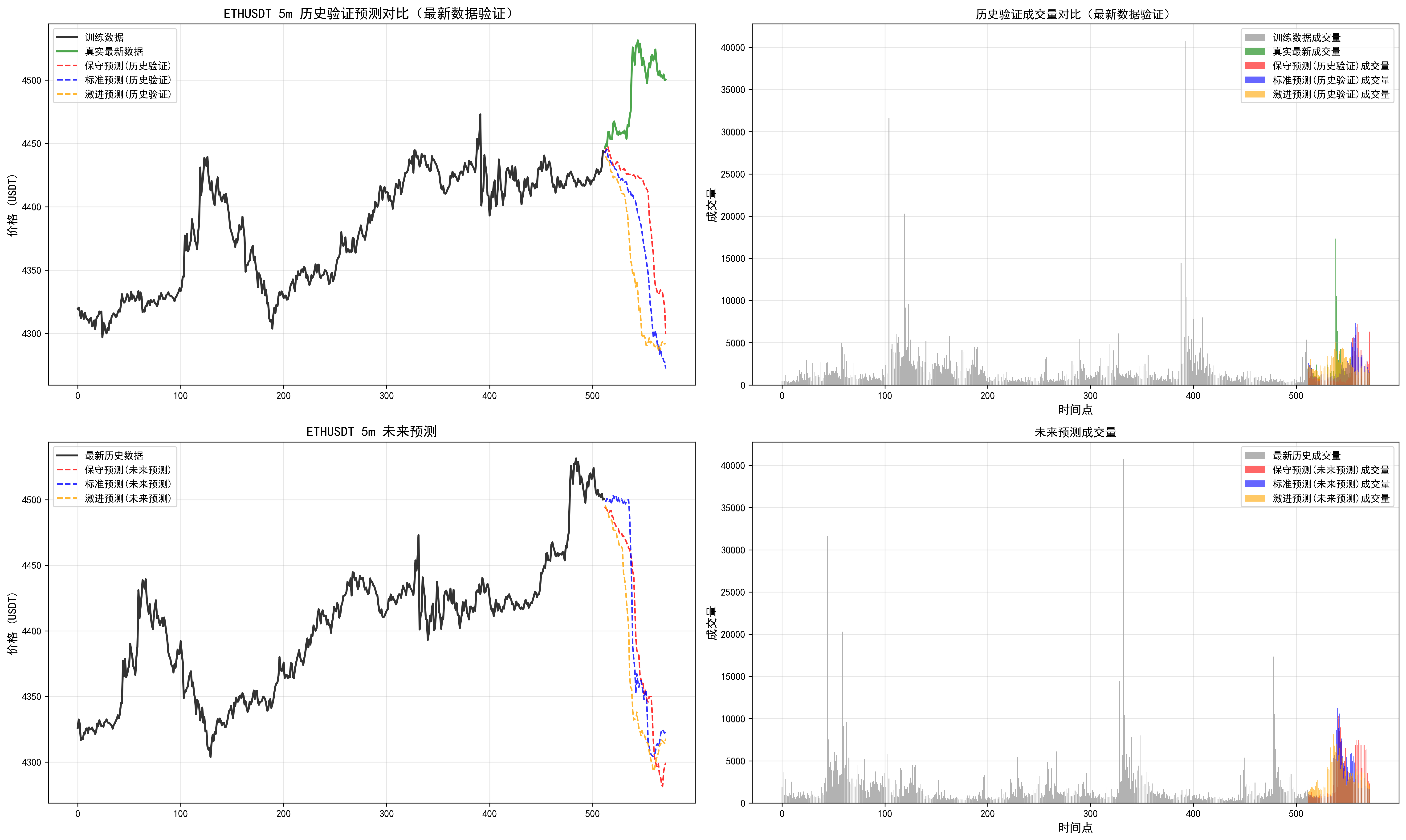
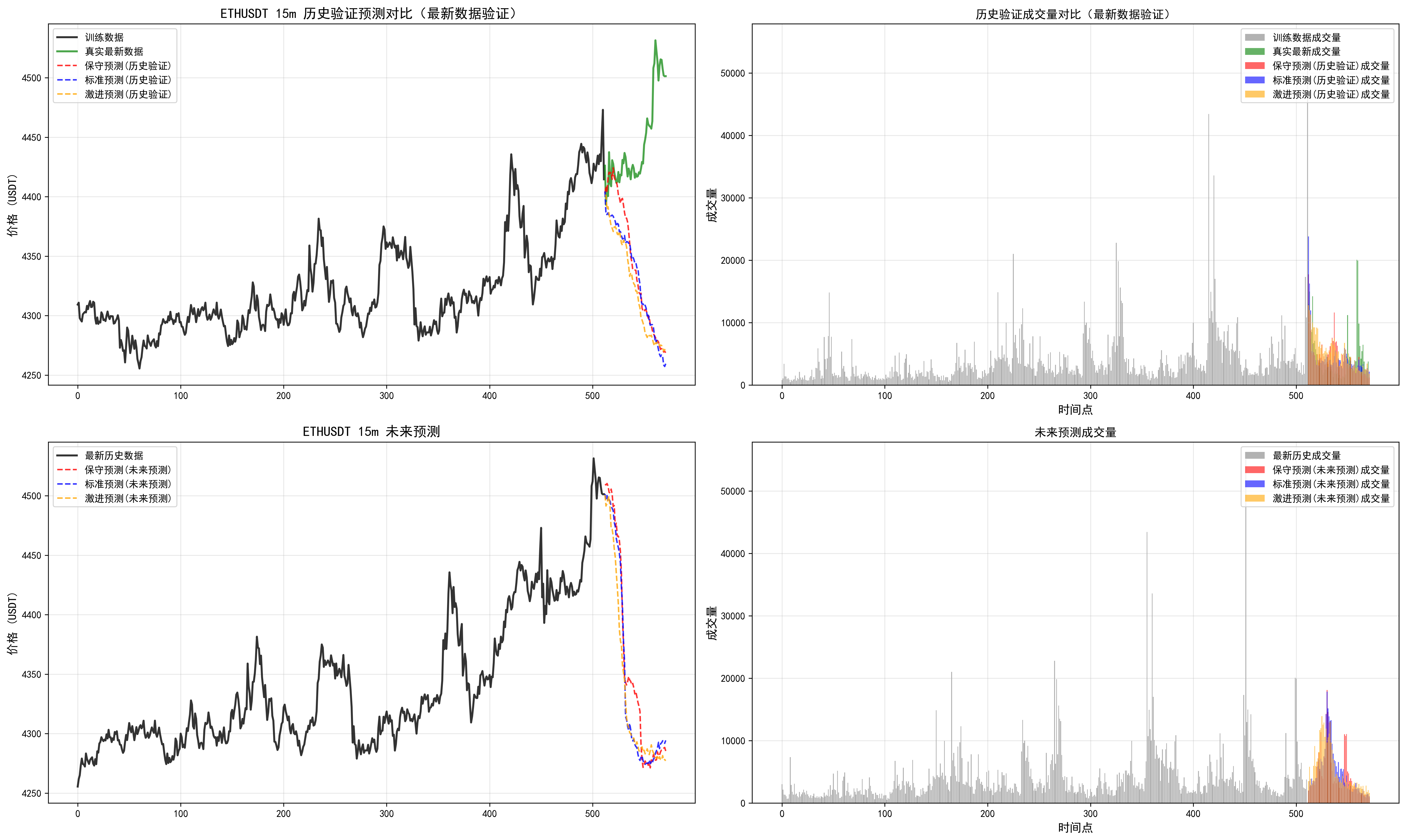
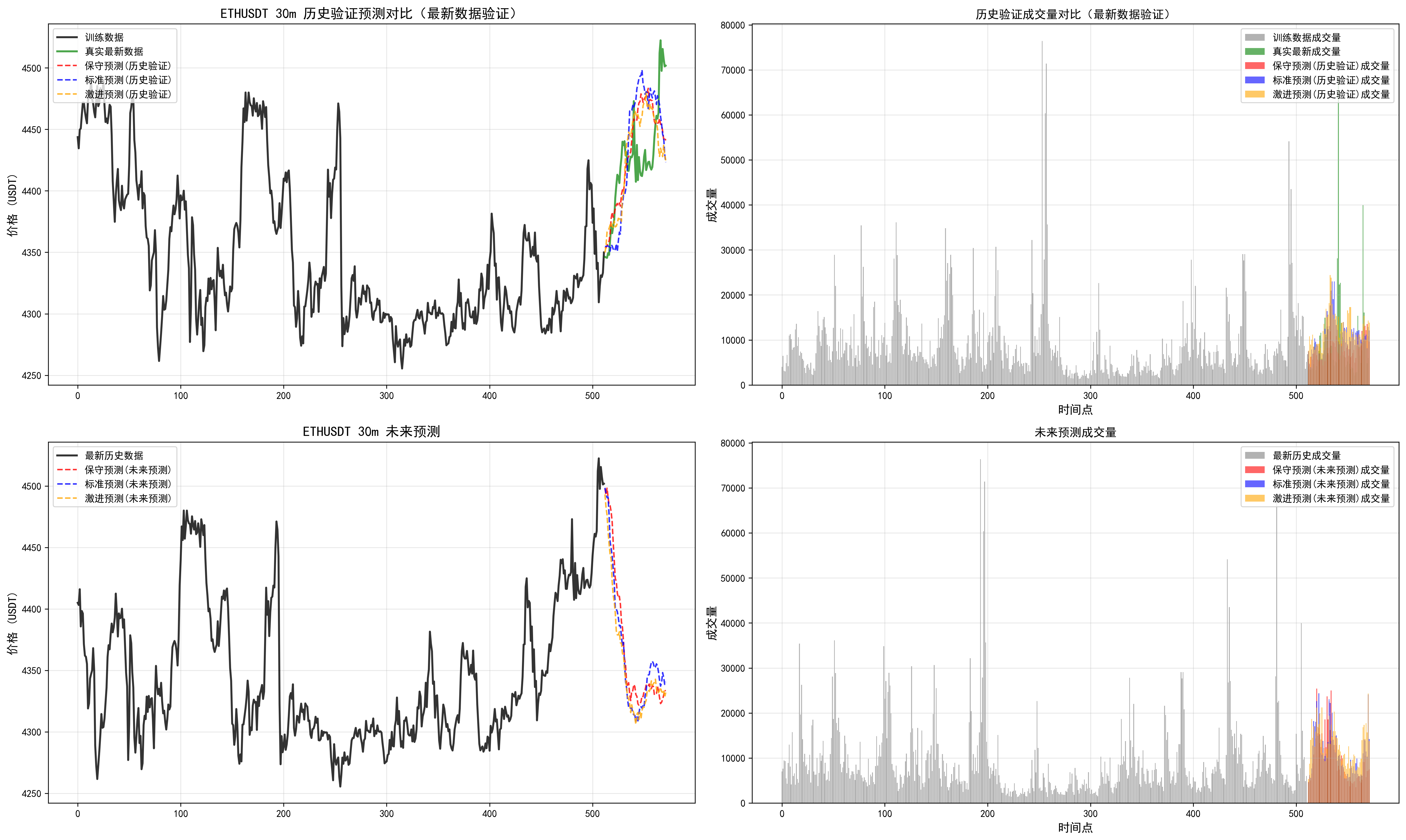
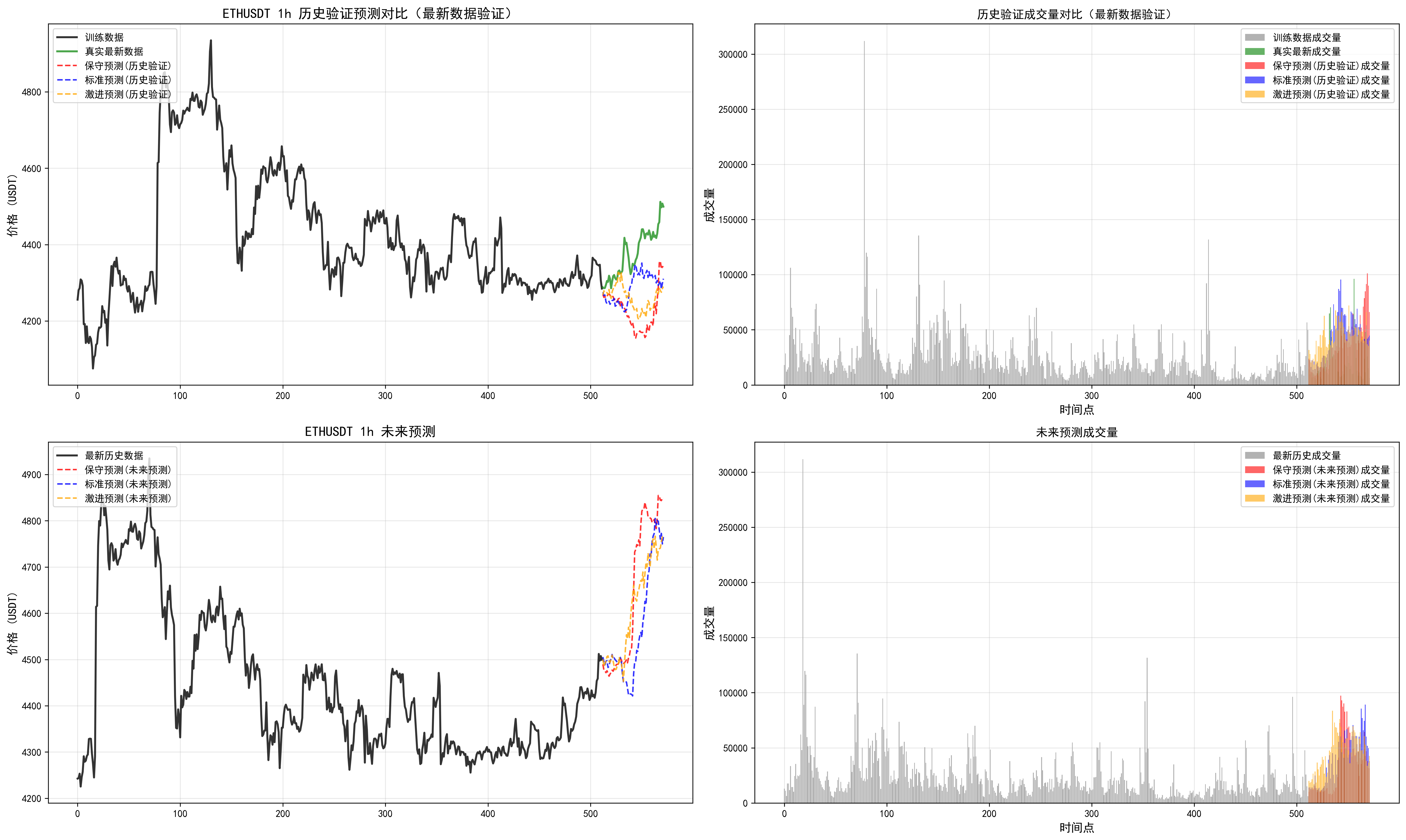
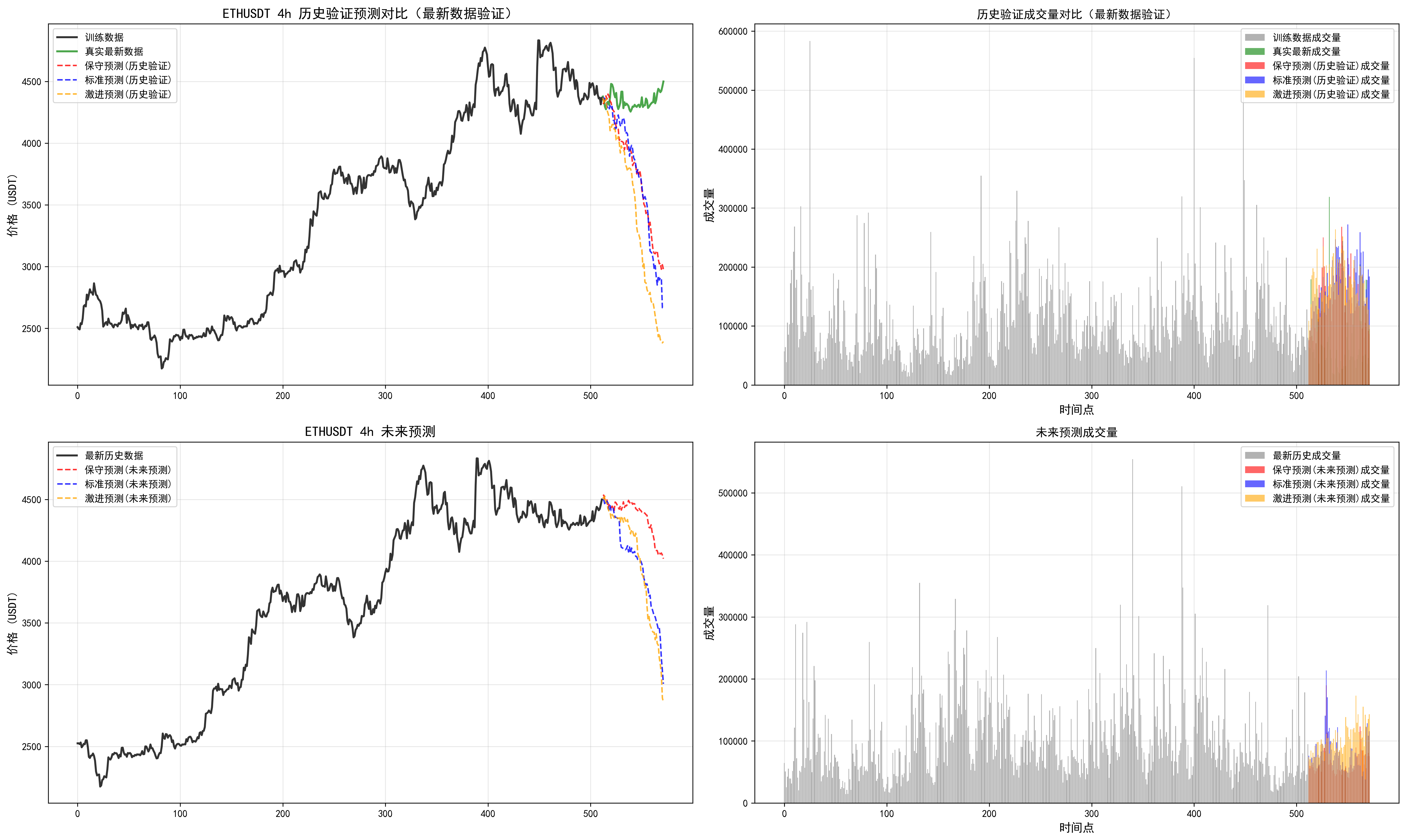
我們可以發現多周期是有分歧的,可以根據最近回測偏離不大的時間周期,追隨未來的結果。但是實踐看來,并不是總是很準,(因為讀取的長度是有限的,最大只能讀取512個k線,最長周期4h,讀取了85天)。需要借助傳統指標,查看當前較長周期和多周期指標支持度。從而綜合下來進行判斷。
因此對于這個預測長度和讀取長度還需要實際進行調整。
對于周期的把握,這個相關信息也需要進一步優化。

解析)




)

:組織、血液、體液制備方法詳解)

)
)



 IDA動態調試Android so文件)



