安裝openjdk21
- 下載
wget https://download.java.net/openjdk/jdk21/ri/openjdk-21+35_linux-x64_bin.tar.gz- 解壓
tar -xvf openjdk-21+35_linux-x64_bin.tar.gzsudo mv jdk-21/ /opt/jdk-21/- 設置環境變量
echo 'export JAVA_HOME=/opt/jdk-21' | sudo tee /etc/profile.d/java21.sh
echo 'export PATH=$JAVA_HOME/bin:$PATH'|sudo tee -a /etc/profile.d/java21.sh
source /etc/profile.d/java21.sh
- 驗證安裝
java --version
安裝spark
- 安裝組件
sudo apt update
sudo apt install default-jdk scala git -y
java -version; javac -version; scala -version; git --versionCopied!
- 下載spark
mkdir /home/yourname/spark
cd spark/
wget https://dlcdn.apache.org/spark/spark-3.5.6/spark-3.5.6-bin-hadoop3.tgz
- 驗證下載的包
cd /home/yourname/spark
wget https://dlcdn.apache.org/spark/spark-3.5.6/spark-3.5.6-bin-hadoop3.tgz.sha512shasum -a 512 -c spark-3.5.6-bin-hadoop3.tgz.sha512
4. 解壓
tar -xvf spark-3.5.6-bin-hadoop3.tgz- 解壓后即可,驗證安裝
/home/yourname/spark/spark-3.5.6-bin-hadoop3/bin/spark-shell --version
- 設置環境變量
vim ~/.profileexport SPARK_HOME=/home/yourname/spark/spark-3.5.6-bin-hadoop3/
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinsource ~/.profile
- 配置遠程連接
cp spark-defaults.conf.template spark-defaults.conf添加以下內容
spark.ui.host 0.0.0.0spark.ui.port 8080
- 設置spark env
cp spark-env.sh.template spark-env.sh添加以下內容
export JAVA_HOME=/opt/jdk-21/
SPARK_MASTER_HOST=192.168.220.132
SPARK_MASTER_PORT=7077
- Start Standalone Spark Master Server
$SPARK_HOME/sbin/start-master.sh訪問本機8080端口即可訪問
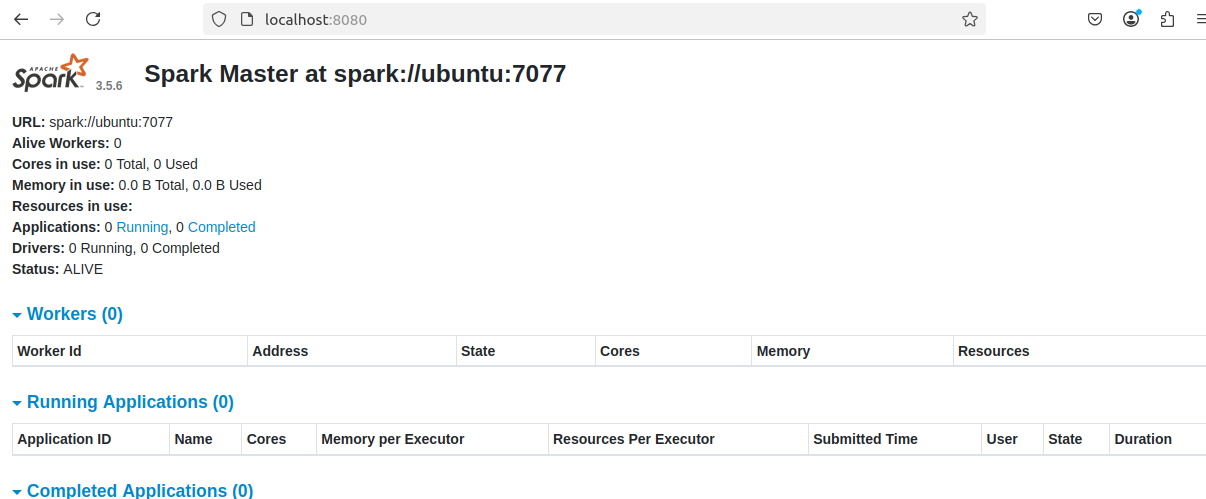
10. 啟動一個worker
$SPARK_HOME/sbin/start-worker.sh spark://192.168.220.132:7077
- Basic Commands to Start and Stop Master Server and Workers
The following table lists the basic commands for starting and stopping the Apache Spark (driver) master server and workers in a single-machine setup.
| Command | Description |
|---|---|
| start-master.sh | Start the driver (master) server instance on the current machine. |
| stop-master.sh | Stop the driver (master) server instance on the current machine. |
| start-worker.sh spark://master_server:port | Start a worker process and connect it to the master server (use the master’s IP or hostname). |
| stop-worker.sh | Stop a running worker process. |
| start-all.sh | Start both the driver (master) and worker instances. |
| stop-all.sh | Stop all the driver (master) and worker instances. |
Pyspark 讀csv
- 安裝與spark相同版本的pyspark
pip install pyspark==3.5.6
如果你之前安裝了別的版本,在你卸載后,最好將package路徑下的pyspark文件夾也刪除
- 本地調試
from pyspark.sql import SparkSession
import os
os.environ["JAVA_HOME"] = r"D:\java21opensdk\jdk-21.0.1"spark = SparkSession.builder \.appName("test") \.getOrCreate()# .master("spark://192.168.220.132:7077") \# .getOrCreate()path = r"C:\Users\test\Desktop\test.csv"df = spark.read.csv(path,header=True, inferSchema=True)
rows = df.collect()for row in rows:print(row.asDict())
- 使用worker運行
from pyspark.sql import SparkSession
import os
os.environ["JAVA_HOME"] = r"D:\java21opensdk\jdk-21.0.1"spark = SparkSession.builder \.appName("test") \.master("spark://192.168.220.132:7077") \.getOrCreate()
# 注意這個csv文件需要傳遞到spark服務器上
path = "file:///opt/data/test.csv"df = spark.read.csv(path,header=True, inferSchema=True)
rows = df.collect()for row in rows:print(row.asDict())
參考




,并在同一窗口顯示)











并測試腳本執行情況)


)