當前,AI 應用正處于極速發展階段,大語言模型(LLM)與檢索增強生成(RAG)系統已成為構建智能問答、知識管理等高階 AI 應用的核心引擎,被廣泛應用于金融分析、學術研究、企業合規等多個領域。然而,許多團隊在將 LLM 與 RAG 系統落地到實際項目時,卻遭遇了明顯的瓶頸:系統的實際表現與預期存在較大差距,無論是回答用戶問題的準確性、內容相關性,還是整體響應效率,均難以滿足業務需求。
優質的文檔解析并非簡單提取文字,而是對文檔內容進行深度理解與結構化重建—— 既要還原標題層級、段落順序、表格結構等顯性信息,也要捕捉元素間的語義關聯(如圖表與正文的對應關系、跨頁內容的邏輯銜接),為后續 RAG 系統和 LLM 提供 “可理解” 的輸入數據。
傳統 OCR 工具的局限性恰好凸顯了優質文檔解析的重要性:傳統 OCR 僅能機械提取圖像上的文字,如同 “近視的搬運工”,無法識別文檔的內在 “藍圖”—— 標題層級關系混亂、段落被拆分得支離破碎、復雜表格像撕碎的拼圖、跨頁內容徹底斷裂、圖表淪為無注釋的 “孤島”。
當這種缺乏結構、語義斷裂的數據直接輸入 RAG 系統時,會引發一系列連鎖問題:
- 檢索效率低下:系統難以精準定位包含答案的關鍵片段,只能在海量文字碎片中 “大海撈針”,耗時且低效;
- 答案準確性受損:上下文缺失或錯位導致 LLM “理解偏差”,生成跑題甚至錯誤的回答;
- 信息完整性打折:表格數據混亂、跨頁信息斷裂、圖表意義不明,關鍵細節丟失,無法支撐完整的分析與決策。
由此可見,文檔解析的質量直接鎖定了 RAG 系統乃至整個 AI 應用效果的上限,而解決這一痛點,正是提升大模型處理長文檔能力的核心突破口。
案例數據
TextIn xParse 智能文檔解析引擎作為針對性解決方案,已在多個實際場景中驗證了其對大模型處理長文檔能力的提升作用:
| 案例類型 | 核心挑戰 | 解析效果 |
| 密集少線表格識別 | 表格線條稀疏、數據密集,傳統 OCR 易混淆單元格邊界,導致數據錯位 | 精準識別單元格邊界,前端支持選中表格并在原圖上顯示模型預測的單元格,數據提取準確率達 98% 以上 |
| 跨頁表格合并與頁眉頁腳識別 | 表格跨頁斷裂、頁眉頁腳與正文混淆,傳統 OCR 無法關聯跨頁數據,易遺漏關鍵信息 | 自動合并跨頁表格,完整保留數據連續性;精準區分頁眉頁腳與正文內容,避免無關信息干擾 RAG 檢索 |
| 圖表識別 | 圖表數據肉眼讀取困難,傳統 OCR 僅能提取圖表標題,無法獲取圖表內數值信息 | 通過精確測量給出圖表內預估數值,關聯圖表標題與正文注釋,幫助 LLM 挖掘圖表背后的有效數據 |
| 標題層級識別 | 長文檔(如論文、年報)標題層級多,傳統 OCR 無法區分一級標題、二級標題等邏輯關系 | 基于語義提取段落 embedding 值,預測標題層級關系,構造清晰的文檔樹,提升 RAG 檢索時的知識點定位效率 |
| 多欄版式還原 | 多欄布局文檔(如學術論文、業務報告)閱讀順序復雜,傳統 OCR 易按列亂序提取文字 | 理解文檔元素排列邏輯,精準還原正確閱讀順序,確保上下文語義連貫,避免 LLM 因語序混亂產生理解偏差 |
| 彎折圖片識別 | 手機拍攝、掃描的文檔易出現頁面彎折,傳統 OCR 因圖像變形導致文字提取錯誤 | 集成強大的圖像處理能力,一鍵矯正彎折頁面,排除圖像質量干擾,文字提取準確率不受變形影響 |
核心能力
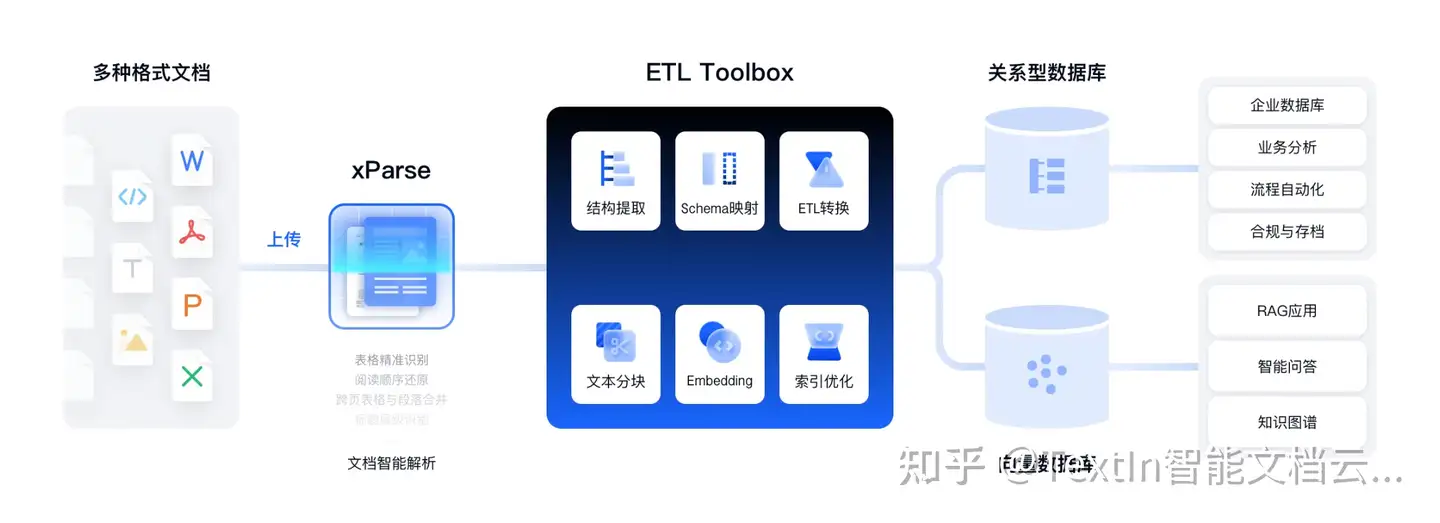
TextIn xParse 作為大模型友好型解析工具,通過多維度核心能力解決傳統文檔解析的痛點,為大模型處理長文檔提供高質量數據輸入:
(1)多格式文件全覆蓋解析
支持 PDF、Word、Excel、PPT、圖片等十余種格式的非結構化文件解析,無論是電子文檔還是掃描件,均能快速轉換為 Markdown 或 JSON 格式輸出,同時保留精確的頁面元素和坐標信息,滿足不同場景下大模型對數據格式的需求。
(2)全類型元素精準識別
可識別文本、圖像、表格、公式、手寫體、表單字段、頁眉頁腳等各類文檔元素,還支持印章、二維碼、條形碼等子類型識別,確保無關鍵元素遺漏,為 LLM 推理、訓練提供完整的輸入數據,助力數據清洗和文檔問答任務。
(3)復雜表格深度處理能力
具備行業領先的表格識別技術,可輕松解決合并單元格、跨頁表格、無線表格、密集表格等傳統解析工具難以應對的難題,完整保留表格結構與數據關聯,避免因表格解析錯誤導致 LLM 生成錯誤結論。
(4)文檔語義結構還原
- 閱讀順序還原:理解多欄布局、圖文混排等復雜版式,還原文檔正確閱讀順序,確保上下文語義連貫;
- 標題層級構建:自研文檔樹引擎,基于語義預測標題層級關系,構造文檔樹結構,提升 RAG 檢索的召回效果和精準度。
(5)掃描內容自適應處理
能良好處理各類圖片與掃描文檔,包括手機照片、截屏、彎折頁面等質量不佳的內容,通過圖像處理技術矯正圖像變形、去除噪聲,確保文字與元素識別的準確性,打破 “優質解析依賴高清文檔” 的限制。
(6)多語言支持
覆蓋簡體中文、繁體中文、英文、數字、西歐主流語言、東歐主流語言等共 50 + 種語言,滿足跨國企業、學術研究等多語言場景下的文檔解析需求,避免因語言限制導致的知識遺漏。
(7)圖像處理能力
針對文檔常見的水印、頁面彎曲、模糊等問題,提供一鍵解決方案:自動去除水印、矯正彎曲頁面、增強模糊圖像,排除圖像質量對解析效果的干擾,確保數據提取的穩定性。
(8)開發者友好的集成體驗
提供清晰的 API 文檔和靈活的集成方式,包括 MCP Server、Coze、Dify 插件,同時支持 FastGPT、CherryStudio、Cursor 等主流平臺,降低開發者集成門檻,可快速適配知識庫、RAG、Agent 或其他自定義 AI 工作流程。
獨特價值
TextIn xParse 的核心價值,在于打破了 “非結構化文檔” 與 “大模型理解” 之間的壁壘,其獨特性體現在三個層面:
(1)從 “文字提取” 到 “語義重建” 的升級
區別于傳統 OCR “只搬文字不懂結構” 的局限,TextIn xParse 以 “機器和 LLM 真正理解” 為目標,通過結構化重建讓文檔數據具備 “語義屬性”—— 不僅提取文字,更還原邏輯關系(如標題與正文的從屬、圖表與注釋的關聯、跨頁內容的銜接),為后續 RAG 分塊策略、高效向量檢索以及 LLM 精準生成提供 “高質量燃料”。
(2)全場景適配的實用性
TextIn xParse 的能力覆蓋金融、學術、企業、教育、醫療、法律等多個領域的核心場景:
- 金融領域:解析年報、研報,支撐財務對比與合規審查;
- 學術領域:重建論文結構,助力知識圖譜構建;
- 醫療領域:結構化病歷數據,輔助臨床決策;
- 法律領域:提取條款層級,賦能合規風險預警。
其適配性不僅體現在格式與元素識別,更在于對不同行業文檔 “業務邏輯” 的理解,確保解析結果貼合實際需求。
(3)為 AI 應用效果提供 “底層保障”
文檔解析是大模型處理長文檔的 “第一步”,也是最關鍵的一步。TextIn xParse 通過提升輸入數據的 “質量”,從源頭解決 RAG 檢索低效、LLM 回答偏差、信息遺漏等問題,幫助 AI 應用突破效果上限 —— 無論是知識庫構建、智能問答,還是 Agent 自動化流程,均能基于結構化數據實現更精準、更高效的輸出,最終降低 AI 應用落地成本,提升業務價值。
立即體驗 Textin文檔解析![]() https://cc.co/16YSWm
https://cc.co/16YSWm


,并在同一窗口顯示)











并測試腳本執行情況)


)

