📑前言
在工業物聯網的浪潮中,數據不再是副產品,而是驅動決策的核心資產。"隨著物聯網、工業互聯網和智能監控的迅猛發展,時序數據正以前所未有的速度爆發。據預測,到2025年全球物聯網設備將達750億臺,每秒都在產生海量的時間序列數據。如何高效地存儲、管理與分析這些數據,已成為企業數字化轉型的關鍵挑戰。
作為一名長期深耕數據底層技術的開發者,我深刻體會到:選擇一款合適的時序數據庫,不僅關乎系統性能,更直接影響業務的穩定性與未來擴展性。今天,我想結合行業趨勢與真實案例,和大家聊聊時序數據庫的選型邏輯,并重點分享一款讓我眼前一亮的開源利器——Apache IoTDB。

文章目錄
- 📑前言
- 一、為什么需要時序數據庫?
- 1.1 什么是時序數據?
- 1.2 時序數據的典型特征
- 二、IoTDB 誕生的價值
- 2.1 技術背景與自主研發
- 2.2 核心功能與技術架構
- 2.3 橫向與縱向解決方案
- 三、IoTDB 七大功能特性
- 3.1 管得好:基于業務,便捷建模
- 3.2 接得住:高頻數據、亂序數據高寫入
- 3.3 存得下:首創標準文件格式TsFile
- 3.4 處理強:支持時序特性查詢分析
- 3.5 智能化:AINode擁抱機器學習
- 3.6 實時性:內置實時流處理功能
- 3.7 云邊協同:文件+引擎,全面數據協同
- 四、Apache IoTDB的應用領域
- 五、快速上手:三步體驗IoTDB
- 5.1 下載安裝
- 5.2 啟動服務
- 5.3 寫入第一條數據(Java示例)
- 結語
一、為什么需要時序數據庫?
1.1 什么是時序數據?
時序數據,也稱為時間序列數據,是指按時間順序記錄的同一統計指標的數據集合。這類數據的來源主要是能源、工程、交通等工業物聯網強關聯行業的機器設備和傳感器,如汽車的車速、發動機轉速,發電風車的功率、電壓、電流等[5]。

1.2 時序數據的典型特征
- 測點多:在工業領域,設備數量可達百萬級別,數據測點可達億級,并隨業務增長動態增加。
- 采樣頻率高:在部分振動狀態監控場景下,采樣頻次可達1kHz。
- 存儲成本高:數據的月增量可達10TB以上,并需長期存儲海量歷史數據[5]。

時序數據庫是專門用于管理時序數據的數據庫類型。隨著物聯網設備和數據量的爆炸式增長,時序數據庫通過管理和分析歷史數據以及新產生的時序數據,能夠助力工業企業實現數字化轉型、工業4.0升級,進而達到降低成本、提高效率、提升產品質量等目的[5]。
二、IoTDB 誕生的價值
2.1 技術背景與自主研發
IoTDB是一款國產自研的物聯網原生時序數據庫,其技術發源于清華大學,目前已歷經13年的發展。IoTDB的誕生,主要是為了解決工業物聯網時序數據管理的實時性、壓縮比、分布式部署等多方面痛點[6][7][10]。

開源版IoTDB是Apache基金會時序數據領域第一個Top-Level項目,其核心團隊成立了天謀科技(北京)有限公司(以下簡稱“天謀科技”),專注IoTDB產品的打磨[6][7]。
2.2 核心功能與技術架構
IoTDB提供數據采集工具,可對接多類協議,底層為純自研列式存儲文件系統TsFile,在此基礎上設計存儲、查詢計算、流處理、分析引擎,以及系統管理模塊與多種應用工具,并支持對接大數據生態,與單機版、分布式版、雙活版等多類形態部署[6][7]。
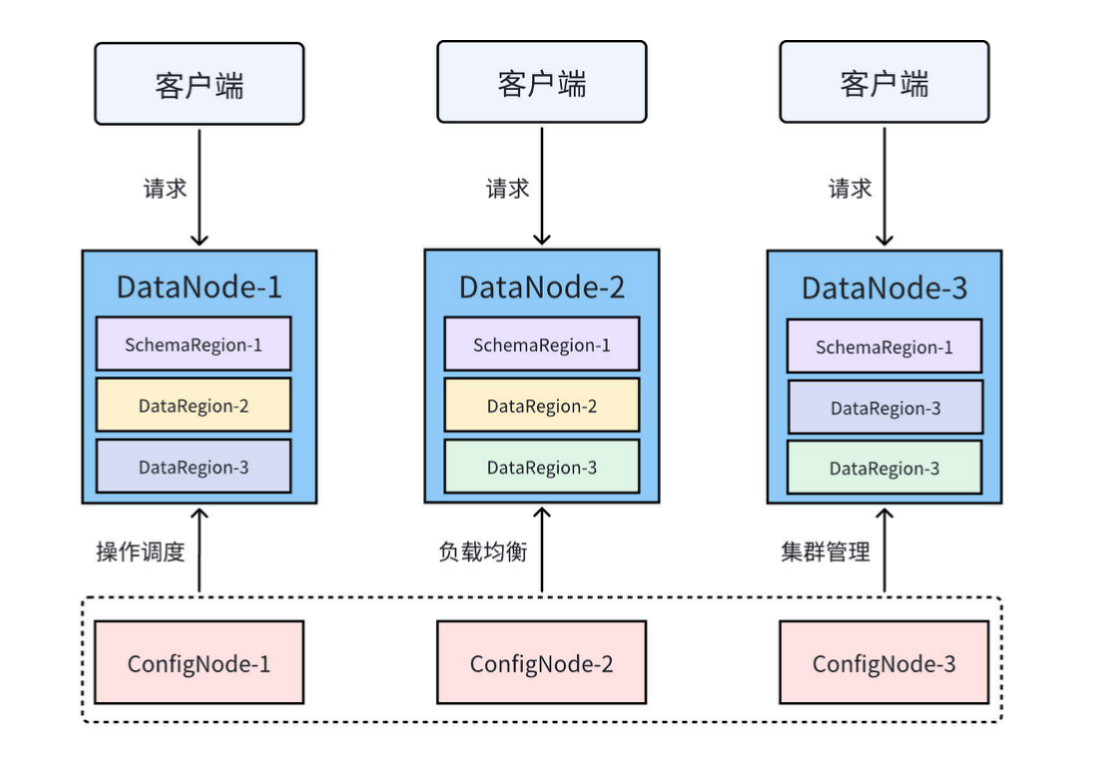
通過多項自研技術創新成果,IoTDB在不依賴第三方系統的情況下,可以實現高吞吐、高壓縮、高可用的性能表現,并建立了物聯網場景時序數據橫向與縱向解決方案[7]。
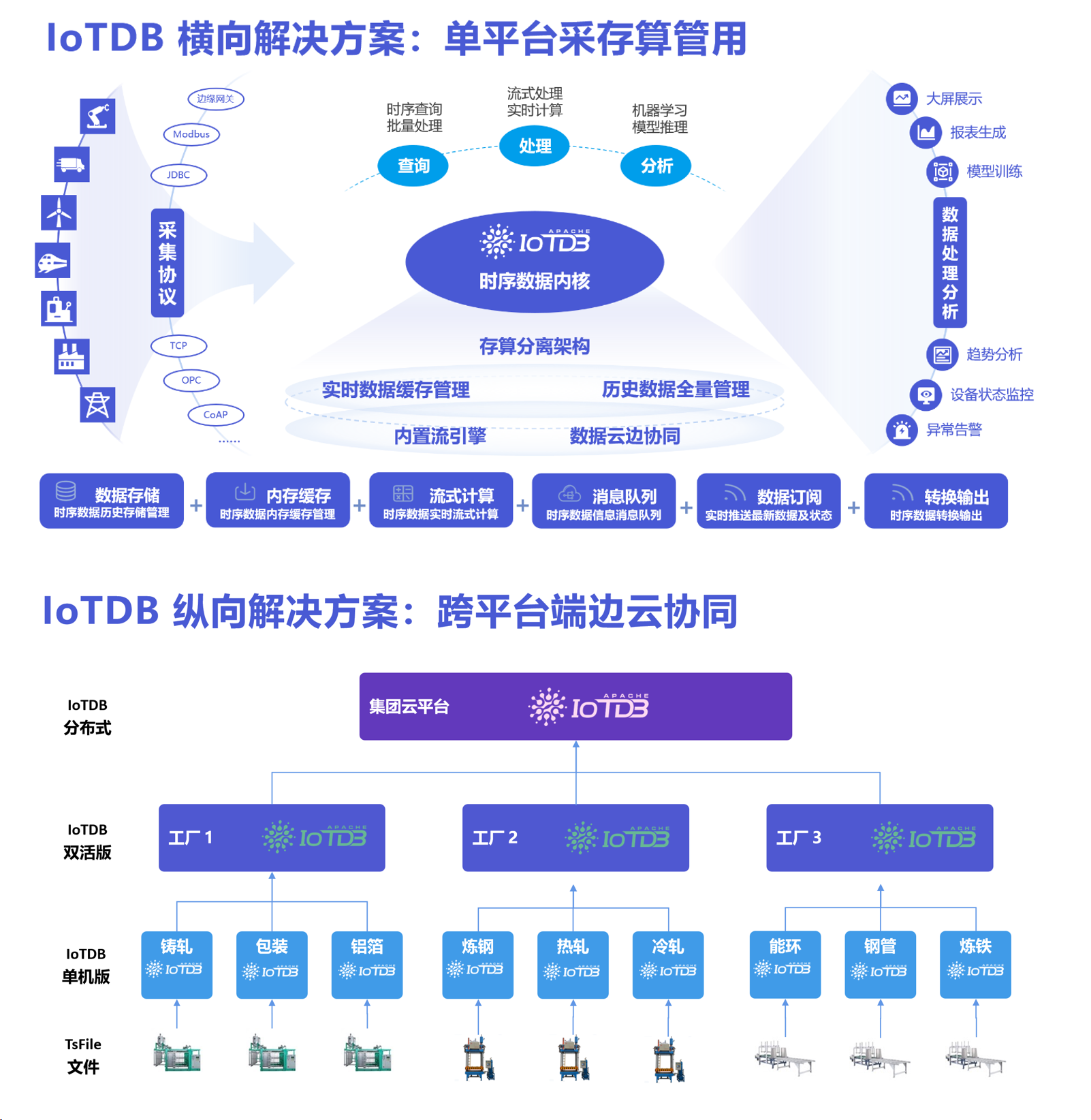
2.3 橫向與縱向解決方案
- 橫向解決方案:以IoTDB為時序數據系統內核,通過其優異的存、讀、寫能力,上游對接多類采集協議,下游對接多類數據分析處理平臺,可支持時序數據單平臺采集、存儲、計算、管理、應用全流程。
- 縱向解決方案:將IoTDB部署于多個平臺,實現跨廠、跨車間應用,IoTDB強大的數據同步能力與簡便的數據同步機制,可支持跨平臺端(設備側/車間側)、邊(廠側)、云(集團側)數據協同[7]。
三、IoTDB 七大功能特性
IoTDB能夠實現穩定、高效、易用的時序數據管理方案,在國際數據庫基準測試性能排行榜benchANT中,IoTDB的讀、寫、壓縮指標均排名第一。其功能特性可簡單歸結為“管得好、接得住、存得下、處理強、實時性、智能性、協同性”七個詞[7]。
3.1 管得好:基于業務,便捷建模
物聯網場景中產線、設備產生的BOM數據是按照層級,彼此關聯起來的。IoTDB實現了樹形時序數據模型,能夠直觀地與BOM數據進行對應。同時對于需要新增或變更的設備,也能夠做到自動化同步,有效降低了時序數據管理與運維的成本[7]。
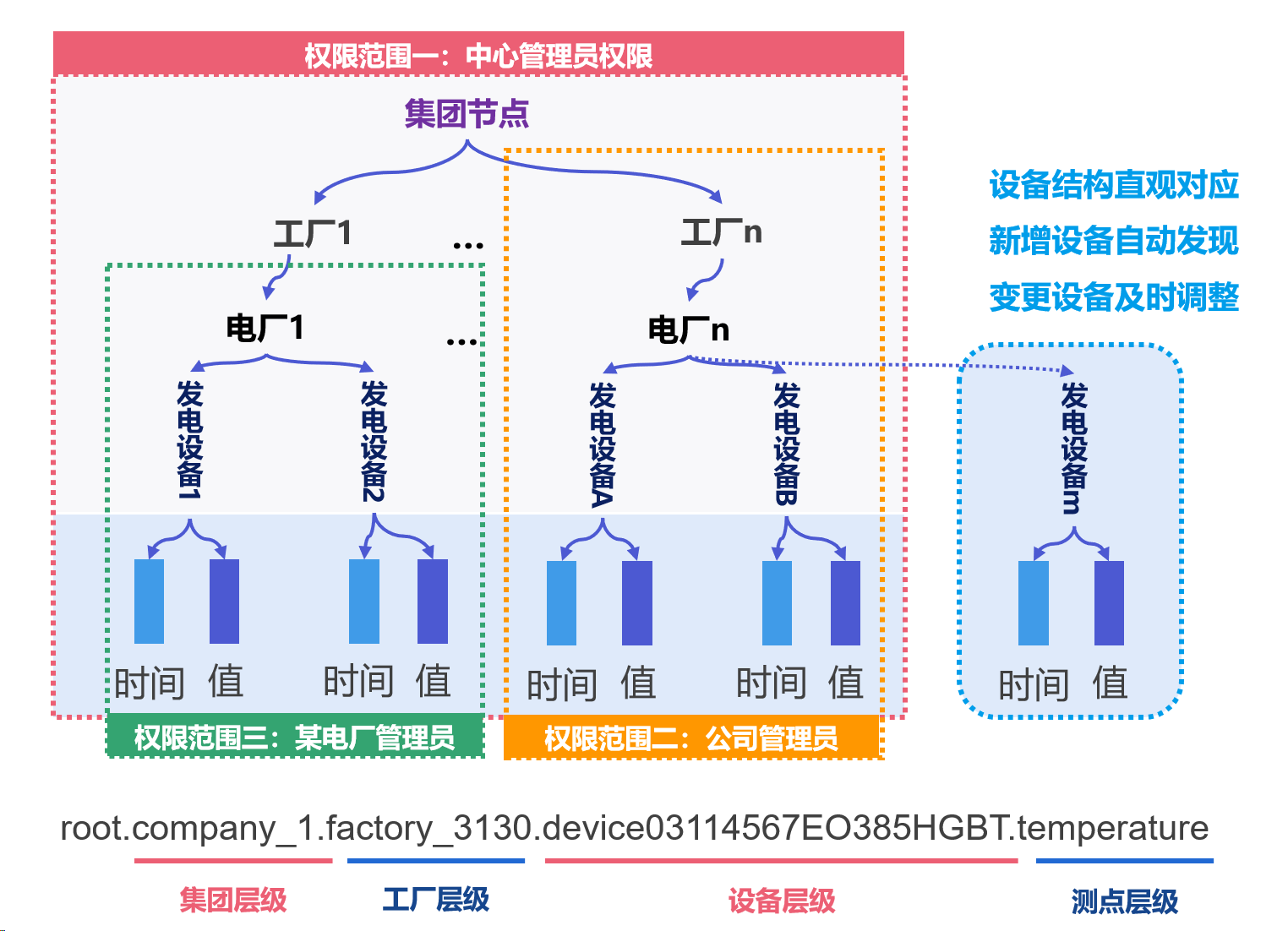
IoTDB自研的基于PBTree的元數據管理模型,可以實現億級的時間序列管理規模,并降低數據冗余,能夠通過高效的元數據存儲提高IoTDB管理的數據質量。在樹形模型基礎上,IoTDB可以對序列級的權限進行更好的控制,比如可以為集團級、工廠級、產線級數據設置不同的權限范圍,進而達到多層級數據高效管理的目的[7]。
3.2 接得住:高頻數據、亂序數據高寫入
- 高頻數據寫入:傳統時序數據庫一般因為采用行式數據寫入,只能支持到秒級數據接入。IoTDB通過底層文件TsFile支持的列式數據寫入,達到毫秒級的數據接入,相比競品有10倍的性能優勢[7]。
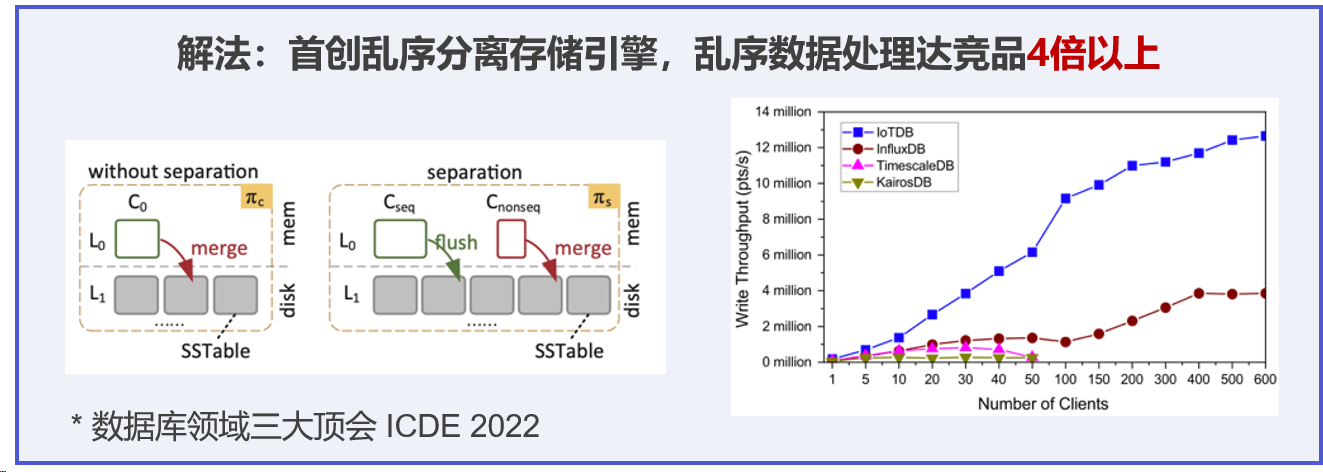
- 亂序數據寫入:亂序數據在實際場景中非常常見,IoTDB首創了亂序分離存儲引擎,用獨有的順亂序判斷機制,將順序數據與亂序數據分開,并通過多種空間合并的方法,消除亂序數據。IoTDB的亂序數據處理效率可以達到競品的4倍以上[7]。
3.3 存得下:首創標準文件格式TsFile
時序數據存儲方面一直面臨海量數據導致存儲成本高昂的問題,而IoTDB通過自研的時序數據標準文件格式TsFile解決了這一難題。TsFile結合列式存儲、編碼算法、分段摘要信息、文件級索引等架構,相比通用的文件格式,對時序數據的壓縮比可以提升20%以上,達到無損壓縮10倍以上、無損壓縮100倍以上的壓縮比[7]。
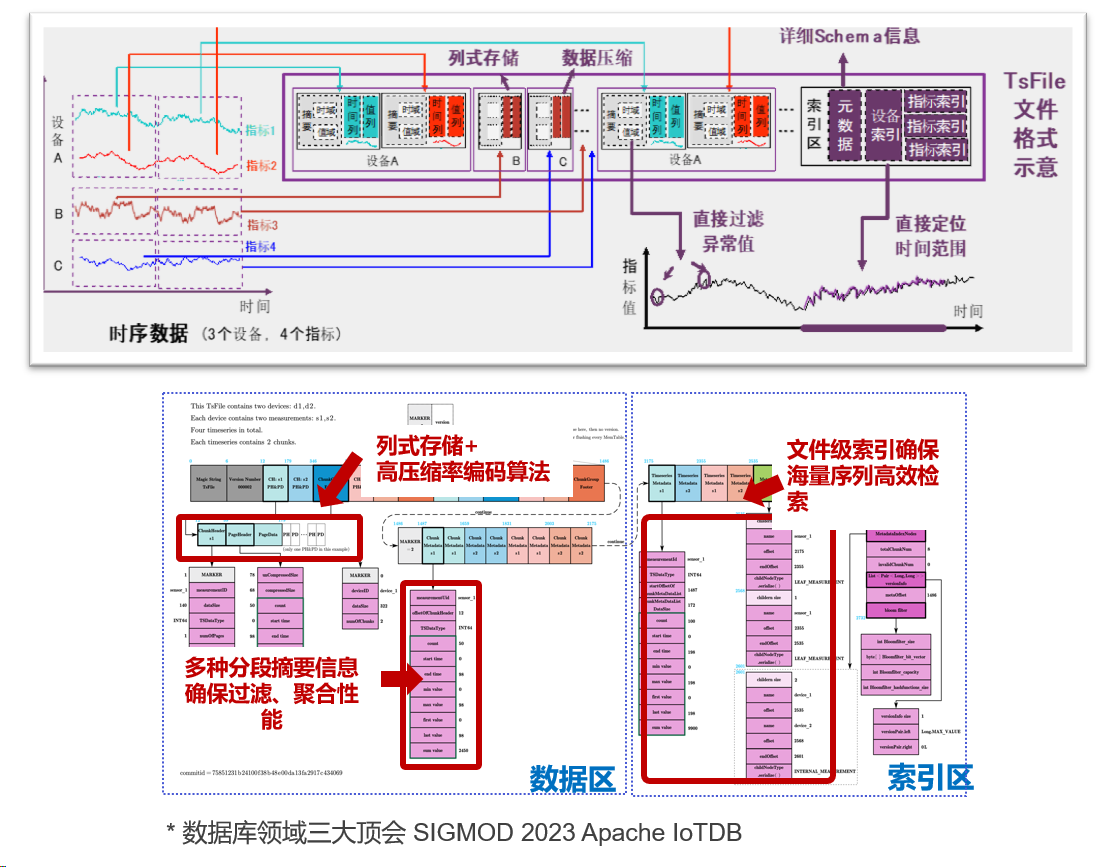
另外,TsFile架構針對時序數據特性的優化,也使得IoTDB有效提升了時序數據的寫入與查詢效率。相比競品,IoTDB的寫入吞吐量提升了2-3倍,查詢吞吐量則提升了2-10倍。值得一提的是,繼IoTDB之后,TsFile已經被Apache基金會通過成為時序數據領域第二個Top-Level項目,這意味著其不但能夠與IoTDB共同使用,還可以作為單獨文件格式進行使用[7]。
3.4 處理強:支持時序特性查詢分析
時序數據因為強時間屬性,在查詢時用戶很可能有一些特殊的、強關聯時間的需求。IoTDB可提供降采樣查詢、最新點查詢和時間分段查詢。降采樣查詢可以去掉原始高頻數據不必要的細節,還原數據的基本趨勢;最新點查詢通過緩存每個設備的最新值,實現毫秒級響應;時序分段查詢可以根據數據的變化閾值、中斷間隔等維度進行多樣的分段查詢[7]。

IoTDB還提供一套UDF(用戶自定義函數)體系,提供超過70種內置函數,可滿足數據修復、數據圖像、異常檢測等時序數據計算需求。如果用戶還有在這套體系之外的計算需求,也可自行在IoTDB中編輯、保存常用的UDF函數[7]。
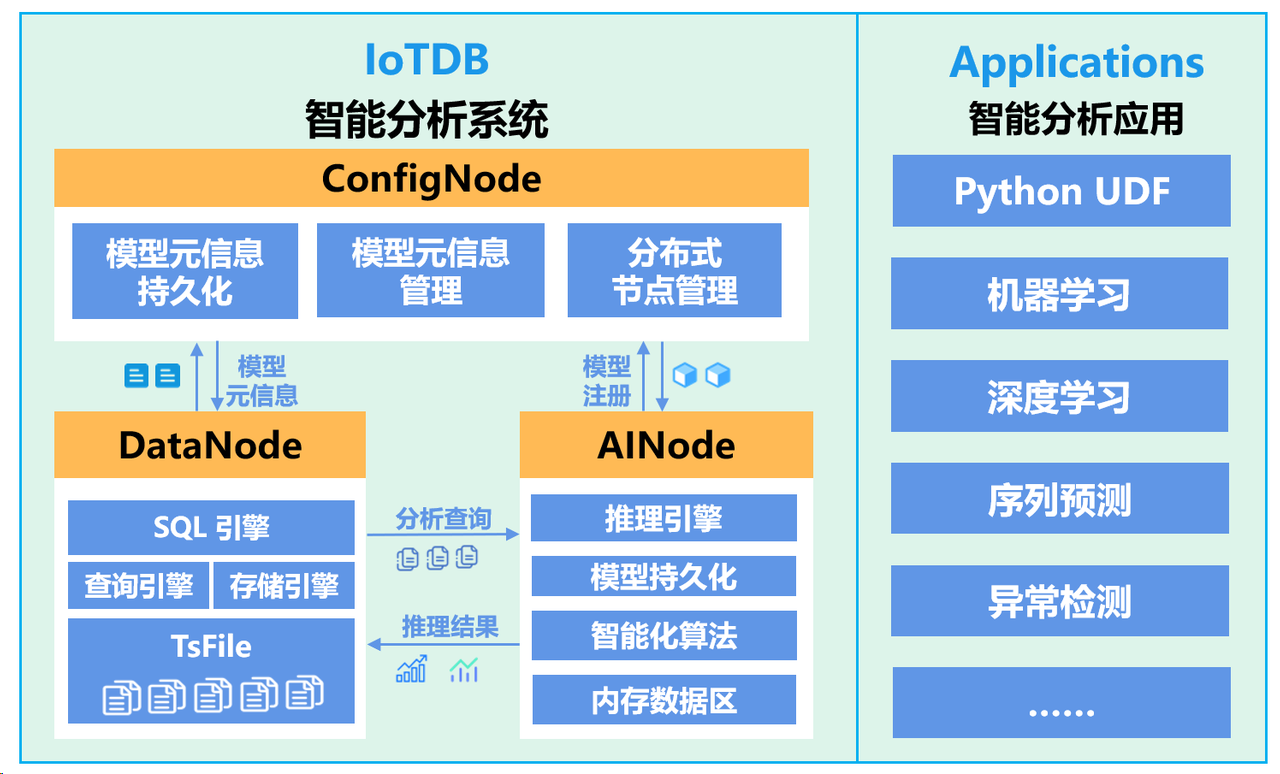
3.5 智能化:AINode擁抱機器學習
為了更好地讓IoTDB實現智能化分析,IoTDB團隊在2023年為IoTDB集群引入了智能分析節點AINode。AINode通過與集群管理節點(ConfigNode)、數據節點(DataNode)的交互,可以為用戶提供模型注冊、管理、推理的能力,結果可直接在IoTDB返回。同時也涵蓋了時序數據適用的多類算法和自研模型,能夠實現序列預測、異常預測等時序分析場景需要的深度學習功能[7][8]。
3.6 實時性:內置實時流處理功能
IoTDB團隊在2023年加入了實時流處理功能,可不間斷地處理數據,并及時發現異常或分析趨勢。IoTDB中,一個流處理任務(Pipe)包含抽取(Extract)、處理(Process)、發送(Connect)三個子任務,三個子任務可由三種獨立插件進行實現,并允許用戶自定義配置三個子任務的處理邏輯和具體屬性,通過組合不同的子任務內核,實現靈活的數據ETL能力[7][8]。
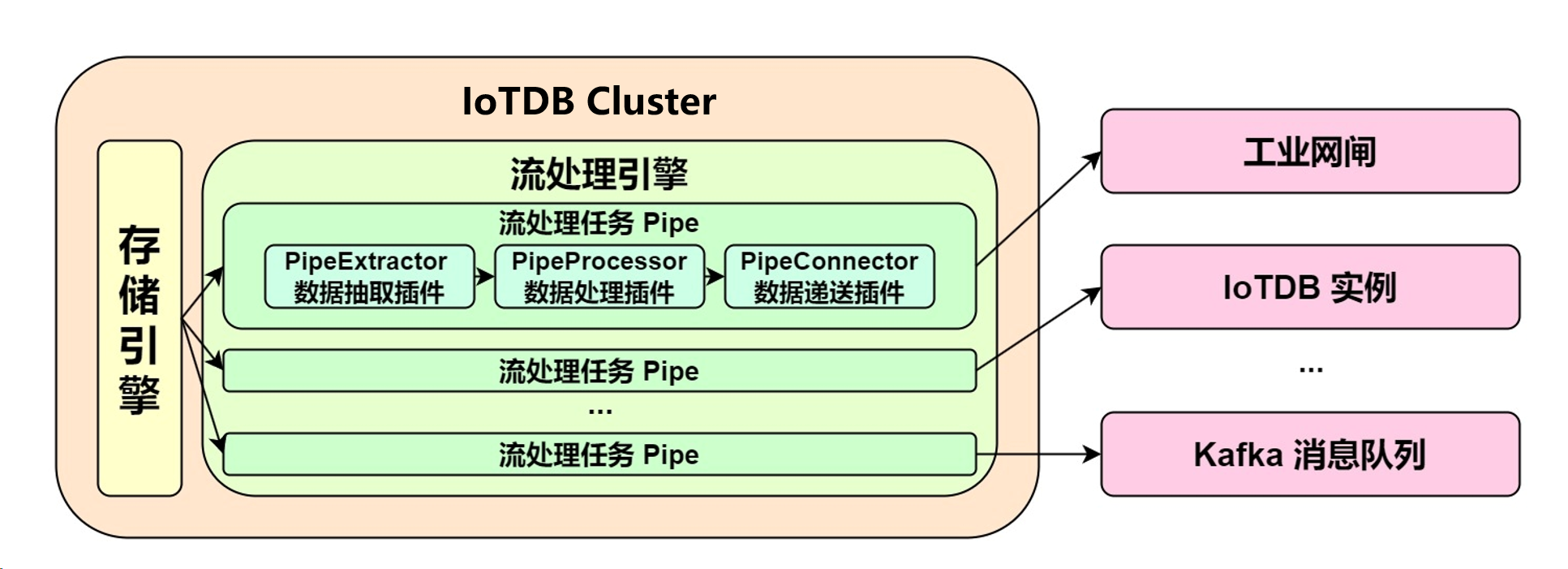
利用流處理框架,可以在IoTDB搭建完整、靈活的數據鏈路,實現毫秒級的低延遲響應,滿足端邊云數據同步、雙活集群部署、網閘穿透、實時告警、數據訂閱、異地災備、讀寫負載分庫等場景需求[7][8]。
3.7 云邊協同:文件+引擎,全面數據協同
工業物聯網應用場景中,產生數據的設備可能來自于多個廠站,數據經常需要匯總至省域或集團進行分析,所以時序數據庫需要多終端、多環境、多平臺部署。IoTDB的數據同步基于可插拔的TsFile文件,并支持操作級、文件級的多種傳輸模式,與跨網閘傳輸、加密傳輸。同一個文件類型可在端、邊、云側進行協同傳輸,同步方案的易用性得以保障;傳輸模式多樣則保障數據傳輸的實時性、吞吐量、安全性[7]。

同時,IoTDB的數據同步支持數據在邊側進行必要的數據清洗與計算操作,再向云側進行同步,能夠最大化地利用邊側的算力資源,同時節省云側算力資源。此外,企業因為業務擴張,往往也經常需要擴展數據庫部署規模。IoTDB的分布式架構具備高擴展性,可以達到秒級擴容、無需遷移數據、靈活調整[7]。
四、Apache IoTDB的應用領域
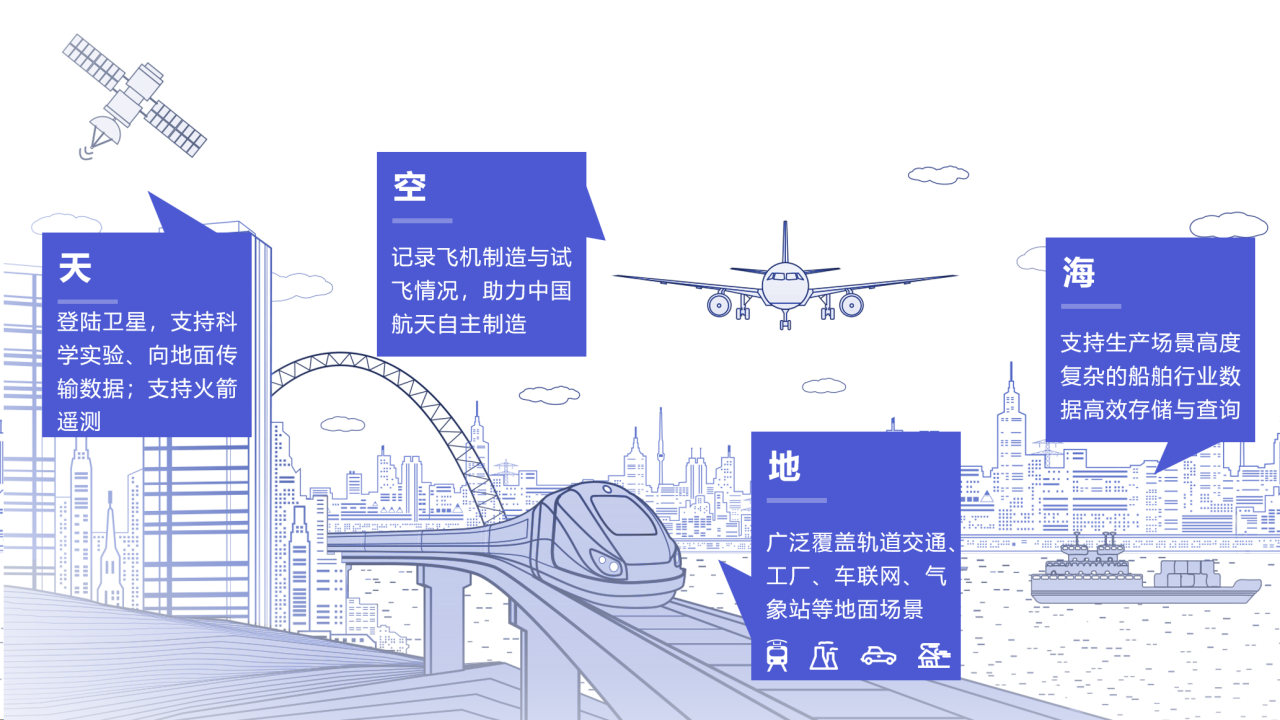
目前,天謀科技構建的IoTDB解決方案在業內得到了廣泛應用,覆蓋“天、空、地、海”各個層面。IoTDB落地的主要行業與應用效果有:
- 電力:已有案例可支持千萬級設備并發,管理百億級累計數據,并支持設備端側、現場邊緣側與中心云側的端邊云數據協同傳輸,與電力行業特性的跨網閘數據傳輸[7][8]。
- 儲能:已有案例可達到毫秒級數據寫入、毫秒級查詢響應、超90倍壓縮比,并實現大字段數據自動掛載、多字段、多路徑、多關鍵詞復雜查詢等功能[7][8]。
- 鋼鐵:已有案例可用少量服務器管理集團全量數據,涉及裝備數百萬,時間序列達千萬,并加速了數據的加工、抽取、備份過程,性能提升1個量級[7][8]。
- 太空:IoTDB于北郵一號衛星邊緣側成功部署,實現低CPU使用率及內存占用,與不定期關機場景下數據的自動保存與恢復,有效支持星-地數據協同[7][8]。
- 飛機制造:已有案例壓縮率可達10倍,空間占用縮減為30%,預計節省百萬存儲成本,并協助實現異地工廠端與云中心側的分布式數據互通和統一管理,與應用層、產線層、設備層多個應用系統的數據存儲與調用[7][8]。
- 軌道交通:已有城軌案例管理列車數能力增加1倍,采樣時間提升60%,需要服務器數降為1/9,月數據增量壓縮后大小下降95%,實現日增4140億數據點管理[7][8]。
- 車聯網:已有案例管理約1.5億時間序列,穩定支持千萬級寫入數據與單車時間范圍查詢、單車全時間序列最新點查詢結果毫秒級返回[7][8]。
- 先進制造:已有案例壓縮比達10倍以上,支持多種查詢方式與多點位同時查詢的需求,針對流程長、工藝復雜、精度高、數據量大的制造場景,支撐對核心指標進行實時分析[7][8]。
目前,應用IoTDB的工業企業已經超過1000家,其中包括國家電網、中核集團、中航成飛、中國中車、中國氣象局等國內企業,和博世力士樂、德國寶馬、西門子、日本小松等海外企業。此外,IoTDB還被集成應用于華為、阿里、海爾、東方國信、用友等多個工業互聯網平臺中[7][8]。
五、快速上手:三步體驗IoTDB
5.1 下載安裝
訪問官方下載頁:https://iotdb.apache.org/zh/Download/,獲取最新版本[1]。
5.2 啟動服務
解壓后執行 sbin/start-server.sh,默認6667端口啟動[3]。
5.3 寫入第一條數據(Java示例)
import org.apache.iotdb.session.Session;public class FirstIoTDB {public static void main(String[] args) {try (Session session = new Session("127.0.0.1", 6667, "root", "root")) {session.open();// 創建時間序列String device = "root.vehicle.d001";session.createTimeseries(device + ".speed", TSDataType.DOUBLE, TSEncoding.PLAIN);// 寫入數據long time = System.currentTimeMillis();double speed = 85.5;session.insertRecord(device, time, new String[]{"speed"}, new Object[]{speed});// 查詢驗證try (SessionDataSet dataset = session.executeQueryStatement("SELECT * FROM root.vehicle.*")) {while (dataset.hasNext()) {System.out.println(dataset.next());}}} catch (Exception e) {e.printStackTrace();}}
}
結語
作為專為物聯網與時序數據打造的高性能數據庫,Apache IoTDB 憑借高效存儲、極速讀寫、靈活擴展三大核心優勢,成為處理大規模 IoT 數據及時序數據的理想之選。其開源、分布式、易集成的特性,更讓它在物聯網、工業監控、智能城市等領域具備廣泛且深入的應用潛力。?
若你正為海量時序數據的存儲、處理難題困擾,不妨給 Apache IoTDB 一次實踐機會 —— 它或許就是幫你搭建高效、穩定、可擴展數據架構的關鍵鑰匙,為你的業務數據管理突破瓶頸。
官網地址:https://iotdb.apache.org
GitHub:https://github.com/apache/iotdb



![P13929 [藍橋杯 2022 省 Java B] 山 題解](http://pic.xiahunao.cn/P13929 [藍橋杯 2022 省 Java B] 山 題解)



- MTK mtk_mipi_tx.c)



)







: 過濾器鏈與自定義過濾器)