這里寫自定義目錄標題
- 線性表
- 鏈表(鏈式存儲)
- 單鏈表的定義
- 單鏈表初始化
- 不帶頭結點的單鏈表初始化
- 帶頭結點的單鏈表初始化
- 單鏈表的插入
- 按位序插入
- 帶頭結點
- 不帶頭結點
- 指定結點的后插操作
- 指定結點的前插操作
- 單鏈表的刪除
- 按位序刪除(帶頭結點)
- 指定結點的刪除
線性表
鏈表(鏈式存儲)
單鏈表的定義
單鏈表是一種線性表的鏈式存儲結構,由**結點(Node)**組成,每個結點通常包含兩部分:
- 數據域(data):存儲實際的數據。
- 指針域(next):存儲指向下一個結點的地址。
特點:
- 不像順序表那樣需要一塊連續的內存空間,鏈表的每個結點可以分布在內存的任意位置。
- 插入、刪除操作較為靈活(只需修改指針),但按位查找需要從頭開始遍歷。
示意圖:
頭結點(head) → [data | next] → [data | next] → [data | next] → NULL
單鏈表的定義如下:
// 定義鏈表結點結構體
typedef struct Node {int data; // 數據域struct Node *next; // 指針域,指向下一個結點
} Node, *LinkList;
- 結構體
struct Node的核心作用
定義了鏈表的基本單元(節點),包含兩個關鍵部分:int data:數據域,存儲節點的具體數據(此處為整數);struct Node* next:指針域,是指向struct Node類型的指針,用于鏈接下一個節點,使多個節點形成 “鏈式” 結構(這是鏈表能 “鏈” 起來的核心)。
typedef的雙重別名:簡化代碼的關鍵
typedef的功能是給 “類型” 起別名,讓代碼更簡潔易讀。在typedef struct Node { ... } Node, *LinkList;中,同時完成了兩個別名的定義:Node:是struct Node(結構體類型)的別名。之后可用Node代替struct Node聲明節點,例如Node node;等價于struct Node node;;*LinkList:是struct Node*(結構體指針類型)的別名。之后可用LinkList代替struct Node*聲明鏈表頭指針,例如LinkList list;等價于struct Node* list;(LinkList更直觀地表示 “鏈表”)。
- 關于
\*LinkList中\*的本質
*不是 “額外添加” 的符號,而是原類型struct Node*(指針類型)的一部分。因為LinkList是struct Node*的別名,所以在typedef聲明時必須包含*,才能讓LinkList正確代表 “指向結構體的指針類型”。 - 簡寫語法的邏輯
代碼typedef struct Node { ... } Node, *LinkList;是一種 “合并寫法”:- 先通過
struct Node { ... }定義結構體類型; - 緊接著用
Node和*LinkList聲明別名(基于剛定義的struct Node類型)。
這種寫法省略了重復的struct Node,本質和分開寫typedef struct Node Node;與typedef struct Node* LinkList;完全一致。
- 先通過
- 類型與別名的關系
- 結構體類型
struct Node定義后,其指針類型struct Node*會自動成為合法類型(可直接用struct Node* p;聲明指針); - 但
Node(結構體別名)和LinkList(指針別名)不會自動生成,必須通過typedef顯式定義。
- 結構體類型
單鏈表初始化
不帶頭結點的單鏈表初始化
#include <stdio.h>
#include <stdbool.h>typedef struct Node {int data; // 數據域struct Node *next; // 指針域
} Node, *LinkList;// 將鏈表初始化為 “空鏈表”
bool InitList(LinkList *L) {/*參數 LinkList *L 是一個 “指向鏈表頭指針的指針”(二級指針)。因為我們需要修改外部聲明的頭指針 L 的值(讓它指向 NULL),所以必須傳遞它的地址(否則修改的只是函數內部的臨時變量)*/*L = NULL;return true; // 表示讓頭指針指向空地址,此時鏈表中沒有任何節點,稱為 “空鏈表”
}// 判斷鏈表是否為空
bool Empty(LinkList L){return (L==NULL);
}int main() {LinkList L;InitList(&L); // 通過傳參修改外部變量bool result = Empty(L);printf("鏈表是否為空:%d", result);
}
用 printf 輸出結果,最終會打印“鏈表是否為空:1”
帶頭結點的單鏈表初始化
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>typedef struct Node {int data; // 數據域struct Node *next; // 指針域
} Node, *LinkList;// 初始化帶頭結點的單鏈表(傳參版)
bool initList(LinkList *L) {*L = (LinkList)malloc(sizeof(Node)); // 申請頭結點if (!*L) {printf("內存分配失敗\n");return false;}(*L)->next = NULL; // 頭結點的 next 置空return true;
}int main() {LinkList L; if (initList(&L)) { // 傳入指針的地址printf("鏈表初始化成功,頭結點地址 = %p\n", L);}return 0;
}
- 什么是 “頭結點”?
頭結點是一個不存儲實際數據的特殊節點,作為鏈表的 “起始標記” 存在。它的作用是統一鏈表的操作(比如插入、刪除時無需額外判斷鏈表是否為空)。 - 函數細節:
*L = (LinkList)malloc(sizeof(Node)):
用malloc動態分配一塊Node大小的內存(用于存儲頭結點),并將這塊內存的地址賦值給*L(即外部聲明的頭指針L)。(LinkList)是強制類型轉換,將malloc返回的void*轉為struct Node*類型。if (!*L):
檢查內存分配是否成功。如果malloc失敗(返回NULL),則*L為NULL,此時打印錯誤信息并返回false。(*L)->next = NULL:
頭結點的next指針置空,表示 “頭結點后面暫時沒有其他節點”(即鏈表初始化后為空,只有一個頭結點)。- 返回
true表示初始化成功。
單鏈表的插入
按位序插入
帶頭結點
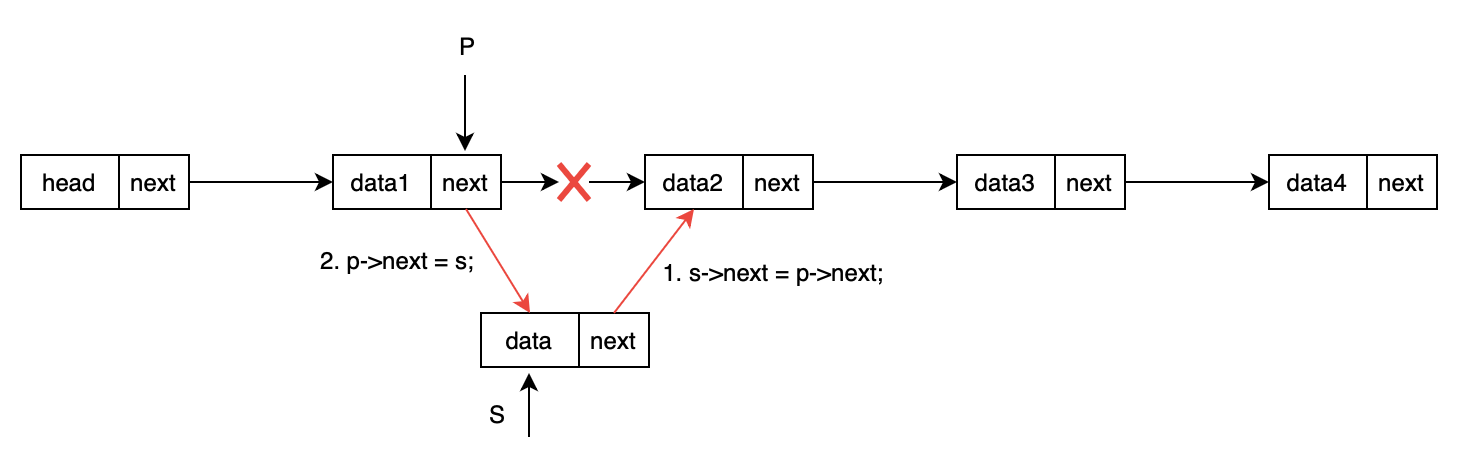
插入過程示意圖如下:
代碼實現如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>typedef struct Node {int data;struct Node *next;
} Node, *LinkList;// 初始化鏈表(帶頭結點)
bool initList(LinkList *L) {*L = (LinkList)malloc(sizeof(Node));if (!*L) return false;(*L)->next = NULL;return true;
}// 按位序插入:在第 i 個位置插入值 e
bool listInsert(LinkList L, int i, int e) {Node *p = L; // p 指向頭結點int j = 0;// 找到第 i-1 個結點while (p != NULL && j < i - 1) {p = p->next;j++;}// i 不合法if (p == NULL) return false;// 創建新結點Node *s = (Node *)malloc(sizeof(Node));if (!s) return false;s->data = e;// 插入操作s->next = p->next;p->next = s;return true;
}// 打印鏈表
void printList(LinkList L) {Node *p = L->next; // 跳過頭結點while (p != NULL) {printf("%d ", p->data);p = p->next;}printf("\n");
}int main() {LinkList L;initList(&L);// 插入一些數據listInsert(L, 1, 10); // 在第1個位置插入10listInsert(L, 2, 20); // 在第2個位置插入20listInsert(L, 2, 15); // 在第2個位置插入15(原20往后移)printList(L); // 輸出:10 15 20return 0;
}
“按位序插入” 指在鏈表的第 i 個位置(從 1 開始計數)插入新數據 e。核心邏輯是 “找到第 i-1 個節點 → 創建新節點 → 插入新節點”,以下是 3 次插入的具體過程:
- 第 1 次插入:
listInsert(L, 1, 10)(在第 1 個位置插入 10)- 目標:在鏈表第 1 個位置插入數據 10(此時鏈表為空,插入后 10 成為第一個數據節點)。
- 步驟:
- 定位第
i-1個節點:i=1,需找到第0個節點(頭結點,因為頭結點是 “第 0 個”,數據節點從 “第 1 個” 開始)。- 函數中
p初始指向頭結點,j=0。循環條件j < i-1即j < 0,不成立,循環不執行,p保持指向頭結點。
- 檢查合法性:
p不為NULL(頭結點存在),插入合法。 - 創建新節點
s:- 分配內存,
s->data = 10(存儲數據 10)。
- 分配內存,
- 插入操作:
s->next = p->next:新節點s的next指向頭結點原本的next(此時為NULL)。p->next = s:頭結點的next指向s,將s鏈接到鏈表中。
- 定位第
- 插入后鏈表結構:
頭結點 -> 10 -> NULL。
- 第 2 次插入:
listInsert(L, 2, 20)(在第 2 個位置插入 20)- 目標:在現有鏈表(10)的第 2 個位置插入 20(插入后 10→20)。
- 步驟:
- 定位第
i-1個節點:i=2,需找到第1個節點(數據節點 10)。p初始指向頭結點,j=0。循環j < 1:- 第一次循環:
p移動到p->next(指向 10),j=1,循環結束。
- 第一次循環:
- 此時
p指向第 1 個節點(10)。
- 檢查合法性:
p不為NULL,插入合法。 - 創建新節點
s:s->data = 20。 - 插入操作:
s->next = p->next:s的next指向 10 原本的next(NULL)。p->next = s:10 的next指向s,將 20 鏈接到 10 后面。
- 定位第
- 插入后鏈表結構:
頭結點 -> 10 -> 20 -> NULL。
- 第 3 次插入:
listInsert(L, 2, 15)(在第 2 個位置插入 15)- 目標:在現有鏈表(10→20)的第 2 個位置插入 15(插入后 10→15→20)。
- 步驟:
- 定位第
i-1個節點:i=2,需找到第1個節點(數據節點 10)。p初始指向頭結點,j=0。循環j < 1:- 第一次循環:
p移動到p->next(指向 10),j=1,循環結束。
- 第一次循環:
- 此時
p指向第 1 個節點(10)。
- 檢查合法性:
p不為NULL,插入合法。 - 創建新節點
s:s->data = 15。 - 插入操作:
s->next = p->next:s的next指向 10 原本的next(即 20)。p->next = s:10 的next指向s,將 15 插入到 10 和 20 之間。
- 定位第
- 插入后鏈表結構:
頭結點 -> 10 -> 15 -> 20 -> NULL。
不帶頭結點
基本思路跟帶頭結點差不多,只不過由于沒有頭結點,在 第 1 個位置插入結點 要單獨處理
代碼實現如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>typedef struct Node {int data;struct Node *next;
} Node, *LinkList;// 按位序插入:在第 i 個位置插入值 e
bool listInsert(LinkList *L, int i, int e) {if (i < 1) return false; // 位序非法Node *s = (Node *)malloc(sizeof(Node));if (!s) return false;s->data = e;// 情況1:在第1個位置插入(新結點成為頭結點)if (i == 1) {s->next = *L;*L = s; // 更新頭指針return true;}// 情況2:插入在第i個位置(i > 1)Node *p = *L;int j = 1;while (p != NULL && j < i - 1) { // 找到第 i-1 個結點p = p->next;j++;}if (p == NULL) { // 位置不合法free(s);return false;}s->next = p->next;p->next = s;return true;
}// 打印鏈表
void printList(LinkList L) {Node *p = L;while (p != NULL) {printf("%d ", p->data);p = p->next;}printf("\n");
}int main() {LinkList L = NULL; // 初始化為空鏈表listInsert(&L, 1, 10); // 插入第1個位置:10listInsert(&L, 2, 20); // 插入第2個位置:10 20listInsert(&L, 2, 15); // 插入第2個位置:10 15 20listInsert(&L, 4, 25); // 插入第4個位置:10 15 20 25printList(L); // 輸出:10 15 20 25return 0;
}
“按位序插入” 指在鏈表的第 i 個位置(從 1 開始計數)插入數據 e。由于鏈表不帶頭結點,插入第 1 個位置時需要特殊處理(直接修改頭指針),其他位置則與帶頭結點邏輯類似。以下是 4 次插入的具體過程:
- 第 1 次插入:
listInsert(&L, 1, 10)(在第 1 個位置插入 10)- 目標:在空鏈表的第 1 個位置插入 10(插入后 10 成為鏈表的第一個數據節點)。
- 步驟:
- 檢查位序合法性:
i=1 ≥ 1,合法。 - 創建新節點
s:通過malloc分配內存,s->data = 10(存儲數據 10)。 - 處理 “第 1 個位置插入” 的特殊性:
- 此時鏈表為空(
*L = NULL),新節點s需成為第一個節點。 s->next = *L:新節點的next指向原頭指針指向的位置(NULL)。*L = s:更新頭指針L,使其指向新節點s(現在s是第一個節點)。
- 此時鏈表為空(
- 檢查位序合法性:
- 插入后鏈表結構:
L → 10 → NULL(頭指針直接指向 10)。
- 第 2 次插入:
listInsert(&L, 2, 20)(在第 2 個位置插入 20)- 目標:在現有鏈表(10)的第 2 個位置插入 20(插入后 10→20)。
- 步驟:
- 檢查位序合法性:
i=2 ≥ 1,合法。 - 創建新節點
s:s->data = 20。 - 定位第
i-1個節點(i=2,即找第 1 個節點):p初始指向*L(即 10,第一個節點),j=1(記錄當前指向的是第幾個節點)。- 循環條件
j < i-1即j < 1,不成立,循環不執行,p保持指向 10(第 1 個節點)。
- 檢查位置合法性:
p ≠ NULL(找到第 1 個節點),合法。 - 插入操作:
s->next = p->next:新節點s的next指向 10 原本的next(NULL)。p->next = s:10 的next指向s,將 20 鏈接到 10 后面。
- 檢查位序合法性:
- 插入后鏈表結構:
L → 10 → 20 → NULL。
- 第 3 次插入:
listInsert(&L, 2, 15)(在第 2 個位置插入 15)- 目標:在現有鏈表(10→20)的第 2 個位置插入 15(插入后 10→15→20)。
- 步驟:
- 檢查位序合法性:
i=2 ≥ 1,合法。 - 創建新節點
s:s->data = 15。 - 定位第
i-1個節點(i=2,即找第 1 個節點):p初始指向*L(10),j=1。- 循環條件
j < 1不成立,p保持指向 10(第 1 個節點)。
- 插入操作:
s->next = p->next:s的next指向 10 原本的next(即 20)。p->next = s:10 的next指向s,將 15 插入到 10 和 20 之間。
- 檢查位序合法性:
- 插入后鏈表結構:
L → 10 → 15 → 20 → NULL。
- 第 4 次插入:
listInsert(&L, 4, 25)(在第 4 個位置插入 25)- 目標:在現有鏈表(10→15→20)的第 4 個位置插入 25(插入后 10→15→20→25)。
- 步驟:
- 檢查位序合法性:
i=4 ≥ 1,合法。 - 創建新節點
s:s->data = 25。 - 定位第
i-1個節點(i=4,即找第 3 個節點):p初始指向*L(10),j=1。- 循環條件
j < 3(需找到第 3 個節點):- 第一次循環:
p = p->next(指向 15),j=2; - 第二次循環:
p = p->next(指向 20),j=3;循環結束(j=3不小于3)。
- 第一次循環:
- 此時
p指向 20(第 3 個節點)。
- 插入操作:
s->next = p->next:s的next指向 20 原本的next(NULL)。p->next = s:20 的next指向s,將 25 鏈接到 20 后面。
- 檢查位序合法性:
- 插入后鏈表結構:
L → 10 → 15 → 20 → 25 → NULL。
帶頭結點和不帶頭結點按位序插入的注意事項:
- 頭結點的作用
- 帶頭結點:頭結點不存放有效數據,只作為鏈表的“哨兵”或“標記”。
- 不帶頭結點:第一個結點就是第一個有效數據結點。
- 插入位置 i 的含義
- 對于帶頭結點的鏈表:
i=1→ 插入到第一個數據結點位置(即頭結點之后)。- 插入邏輯統一,不需要單獨處理第一個結點。
- 對于不帶頭結點的鏈表:
i=1→ 插入到鏈表頭部,此時新結點本身就變成了新的頭結點。- 需要單獨處理 i=1 的情況,否則會丟失鏈表頭指針。
- 對于帶頭結點的鏈表:
- 尋找插入位置
- 帶頭結點:
- 從頭結點開始計數,找到第
i-1個結點后插入。 - 因為有頭結點,
i-1總是合法的,即使是i=1。
- 從頭結點開始計數,找到第
- 不帶頭結點:
- 從第一個結點開始計數,找到第
i-1個結點。 - 但當
i=1時,i-1=0,這時沒有前驅,所以必須單獨處理。
- 從第一個結點開始計數,找到第
- 帶頭結點:
- 代碼處理區別
帶頭結點
不帶頭結點Node *p = L; // L 是頭結點 int j = 0; while (p != NULL && j < i-1) {p = p->next;j++; } // p 就是第 i-1 個結點,統一插入if (i == 1) {// 插在第1個位置,要修改頭指針s->next = *L;*L = s; } else {// 其他情況:找第 i-1 個結點Node *p = *L;int j = 1;while (p != NULL && j < i-1) {p = p->next;j++;}// 插入 } - 優缺點對比
- 帶頭結點
- 插入/刪除邏輯更統一,不需要單獨處理第 1 個位置
- 會多占用一點內存
- 不帶頭結點
- 更省內存,邏輯上更直觀
- 需要單獨處理頭結點的操作(插入/刪除第一個元素比較麻煩)
- 帶頭結點
指定結點的后插操作
指定結點的后插操作 —— 也就是 在鏈表中的某個結點 p 后面插入一個新結點。
這個操作和“按位序插入”不同,不需要從頭開始遍歷找位置,只要知道結點指針 p,就能直接完成插入。
代碼實現如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>typedef struct Node {int data;struct Node *next;
} Node, *LinkList;// 指定結點的后插操作
bool insertAfter(Node *p, int e) {if (p == NULL) return false; // p不能為空Node *s = (Node *)malloc(sizeof(Node));// 檢查內存分配是否成功if (!s) return false;s->data = e;s->next = p->next;p->next = s;return true;
}// 打印鏈表
void printList(LinkList L) {Node *p = L;while (p != NULL) {printf("%d ", p->data);p = p->next;}printf("\n");
}int main() {// 手動構造一個鏈表 10 -> 20 -> 30Node *n1 = (Node *)malloc(sizeof(Node));Node *n2 = (Node *)malloc(sizeof(Node));Node *n3 = (Node *)malloc(sizeof(Node));n1->data = 10; n1->next = n2;n2->data = 20; n2->next = n3;n3->data = 30; n3->next = NULL;LinkList L = n1;printf("原鏈表: ");printList(L);// 在結點 n2 (值20) 后插入新結點25insertAfter(n2, 25);printf("后插后: ");printList(L);return 0;
}
- 后插操作的關鍵:通過兩步指針調整完成插入,先讓新節點
s“接住” 原節點p的后續節點(s->next = p->next),再讓p指向s(p->next = s),避免鏈表斷裂。 - 優勢:相比 “按位序插入”,后插操作無需從頭遍歷找位置(前提是已知
p),時間效率更高(O (1))。 - 注意事項:
- 必須保證
p不為 NULL(否則插入無意義,函數返回 false)。 - 需檢查
malloc是否成功(內存分配失敗時返回 false)。
- 必須保證
指定結點的前插操作
在單鏈表中,所謂指定結點的前插操作,就是在某個結點 p 的前面插入一個新結點。
但是需要注意:
- 單鏈表是單向的,結點只保存了后繼指針
next,并沒有保存前驅指針。 - 所以我們不能直接找到 p 的前驅結點,這使得前插操作比后插操作要麻煩一些。
實現思路:
- 常規方法(遍歷法)
- 從頭開始遍歷鏈表,找到結點
p的前驅結點pre。 - 新建結點
s,讓s->next = p。 - 再讓
pre->next = s,完成插入。 - 時間復雜度為 O(n)O(n)O(n)
- 缺點:必須遍歷,效率較低。
// 在結點 p 前插入結點 s bool InsertPriorNode_traverse(LinkList L, LNode *p, LNode *s) {if (L == NULL || p == NULL || s == NULL)return false;LNode *pre = L; // 從頭結點開始while (pre->next != NULL && pre->next != p) {pre = pre->next;}if (pre->next == NULL) // 沒找到 preturn false;// 插入操作s->next = p;pre->next = s;return true; } - 從頭開始遍歷鏈表,找到結點
- 巧妙方法(復制法,不用找前驅)
- 新建結點
s,把s插入到p的后面。 - 然后把
p的數據復制到s中,再把新數據放到p中。 - 等價于在
p前插入了新結點。 - 時間復雜度為 O(1)O(1)O(1)
- 缺點:數據會發生移動,不適合存儲較復雜數據的場景。
// 在結點 p 之前插入結點 s bool InsertPriorNode(LNode *p, LNode *s) {if (p == NULL || s == NULL) // 防止野指針return false;// 先把 s 接到 p 的后面s->next = p->next;p->next = s;// 用中間變量交換數據ElemType temp = p->data; // 保存 p 的數據p->data = s->data; // p 存 s 的數據s->data = temp; // s 存 p 的舊數據return true; } - 新建結點
完整代碼實現:
- 遍歷法:
#include <stdio.h> #include <stdlib.h> #include <stdbool.h>typedef struct LNode {int data;struct LNode *next; } LNode, *LinkList;// 在結點 p 前插入結點 s(遍歷法) bool InsertPriorNode_traverse(LinkList L, LNode *p, LNode *s) {if (L == NULL || p == NULL || s == NULL)return false;LNode *pre = L; // 從頭結點開始while (pre->next != NULL && pre->next != p) {pre = pre->next;}if (pre->next == NULL) // 沒找到 preturn false;// 插入操作s->next = p;pre->next = s;return true; }// 創建結點 LNode* createNode(int e) {LNode *node = (LNode*)malloc(sizeof(LNode));node->data = e;node->next = NULL;return node; }int main() {// 構建鏈表: 頭結點 -> 1 -> 2 -> 3LinkList L = createNode(0); // 頭結點LNode *n1 = createNode(1);LNode *n2 = createNode(2);LNode *n3 = createNode(3);L->next = n1; n1->next = n2; n2->next = n3;// 新結點LNode *s = createNode(99);// 遍歷法: 在 n2 前插入 sInsertPriorNode_traverse(L, n2, s);// 打印鏈表LNode *p = L->next;while (p) {printf("%d ", p->data);p = p->next;}printf("\n"); } - 復制法
#include <stdio.h> #include <stdlib.h> #include <stdbool.h>typedef struct LNode {int data;struct LNode *next; } LNode, *LinkList;// 在結點 p 前插入結點 s(復制法/交換法) bool InsertPriorNode_copy(LNode *p, LNode *s) {if (p == NULL || s == NULL)return false;// 插到 p 的后面s->next = p->next;p->next = s;// 交換數據ElemType temp = p->data;p->data = s->data;s->data = temp;return true; }// 創建結點 LNode* createNode(int e) {LNode *node = (LNode*)malloc(sizeof(LNode));node->data = e;node->next = NULL;return node; }int main() {// 構建鏈表: 頭結點 -> 1 -> 2 -> 3LinkList L = createNode(0); // 頭結點LNode *n1 = createNode(1);LNode *n2 = createNode(2);LNode *n3 = createNode(3);L->next = n1; n1->next = n2; n2->next = n3;// 新結點LNode *s = createNode(99);// 復制法: 在 n3 前插入一個新結點LNode *s2 = createNode(88);InsertPriorNode_copy(n3, s2);// 再打印鏈表p = L->next;while (p) {printf("%d ", p->data);p = p->next;}printf("\n");return 0; }
單鏈表的刪除
按位序刪除(帶頭結點)
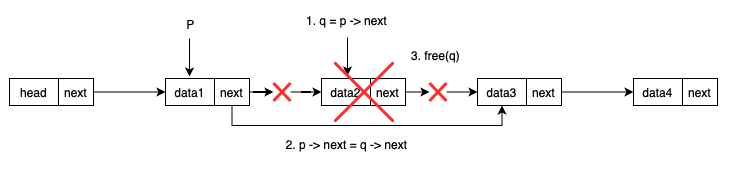
刪除過程示意圖如下:
思路:
- 按位序刪除:就是刪除第
i個結點(不含頭結點,頭結點算第 0 個)。 - 我們需要找到 第
i-1個結點pre,然后讓pre->next指向pre->next->next,并釋放要刪除的結點。 - 注意邊界:
- 如果
i < 1,非法; - 如果鏈表過短,沒有第
i個結點,也要處理。
- 如果
完整代碼實現如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>typedef int ElemType;typedef struct LNode {ElemType data;struct LNode *next;
} LNode, *LinkList;// 按位序刪除(帶頭結點單鏈表)
// 刪除第 i 個結點,并將其數據返回到 e
bool ListDelete(LinkList L, int i, ElemType *e) {if (i < 1) return false; // 位序非法LNode *pre = L; // 指向頭結點int j = 0;// 找到第 i-1 個結點while (pre != NULL && j < i - 1) {pre = pre->next;j++;}if (pre == NULL || pre->next == NULL) // 第 i-1 或第 i 個不存在return false;// 刪除結點 qLNode *q = pre->next;*e = q->data; // 保存數據pre->next = q->next; // 斷鏈free(q); // 釋放內存return true;
}// 工具函數:創建新結點
LNode* createNode(ElemType e) {LNode *node = (LNode*)malloc(sizeof(LNode));node->data = e;node->next = NULL;return node;
}// 測試
int main() {// 構建帶頭結點的鏈表: 0(頭) -> 1 -> 2 -> 3 -> 4LinkList L = createNode(0); // 頭結點LNode *n1 = createNode(1);LNode *n2 = createNode(2);LNode *n3 = createNode(3);LNode *n4 = createNode(4);L->next = n1; n1->next = n2; n2->next = n3; n3->next = n4;// 刪除第 3 個結點(也就是元素 3)ElemType e;if (ListDelete(L, 3, &e)) {printf("刪除成功,刪除的元素是 %d\n", e);} else {printf("刪除失敗\n");}// 打印剩余鏈表LNode *p = L->next;while (p) {printf("%d ", p->data);p = p->next;}printf("\n");return 0;
}
指定結點的刪除
在單鏈表中刪除一個指定結點 p,主要有兩種方法:
- 遍歷法(找到前驅結點再刪除)
- 由于單鏈表是單向的,我們無法直接找到結點
p的前驅。 - 所以需要從頭開始遍歷,找到
p的前驅結點pre,再執行:pre->next = p->next; free(p); - 代碼如下所示:
// 刪除指定結點 p int DeleteNode(LinkList L, Node* p) {if (p == NULL || L == NULL) return 0;Node* pre = L;// 找到 p 的前驅while (pre->next != NULL && pre->next != p) {pre = pre->next;}if (pre->next == NULL) return 0; // 沒找到 ppre->next = p->next;free(p);return 1; }
- 由于單鏈表是單向的,我們無法直接找到結點
- 復制法(用后繼覆蓋當前結點)
- 如果
p不是尾結點,可以將p->next的數據復制到p,然后刪除p->next,這樣就相當于刪除了p。 - 但是,如果
p是尾結點,就不能用此方法(因為沒有后繼)。 - 代碼如下所示:
int DeleteNodeCopy(Node* p) {if (p == NULL || p->next == NULL) return 0; // p 是尾結點,不能用此法Node* q = p->next;p->data = q->data; // 用后繼數據覆蓋當前結點p->next = q->next;free(q);return 1; }
- 如果
:信任、約定與“安全基線”鏡像庫)

)












)



)