PostgreSQL15查詢詳解
- 一、簡單查詢
- 1.1、單表查詢
- 1.2、無表查詢
- 1.3、消除重復結果
- 1.4、使用注釋
- 二、查詢條件
- 2.1、WHERE子句
- 2.2、模式匹配
- 2.3、空值判斷
- 2.4、復雜條件
- 三、排序顯示
- 3.1、單列排序
- 3.2、多列排序
- 3.3、空值排序
- 四、限定結果數量
- 4.1、Top-N查詢
- 4.2、分頁查詢
- 4.3、注意事項
- 五、分組匯總
- 5.1、聚合函數
- 5.2、分組聚合
- 5.3、分組過濾
- 5.4、高級選項
- 5.4.1、GROUPING SETS選項
- 5.4.2、CUBE選項
- 5.4.3、ROLLUP選項
- 5.4.4、GROUPING函數
- 六、多表連接
- 6.1、內連接
- 6.2、左/右外連接
- 6.3、全外連接
- 6.4、交叉連接
- 6.5、自然連接
- 6.6、自連接
一、簡單查詢
1.1、單表查詢
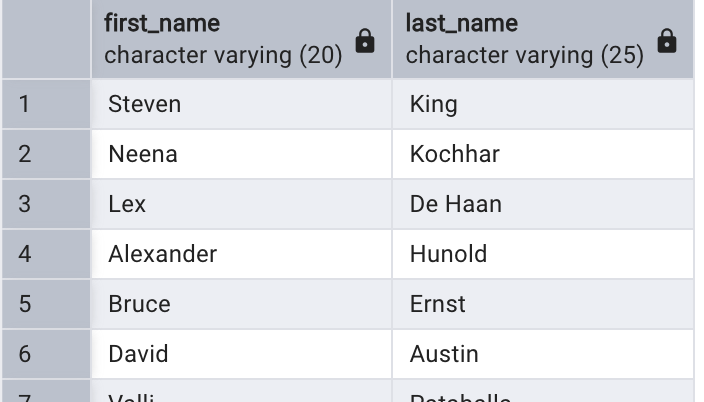
select first_name, last_name
from employees;
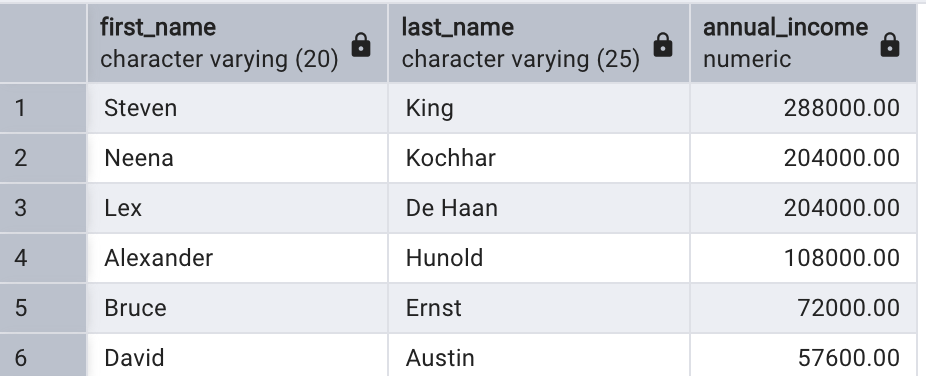
select first_name, last_name, salary * 12 as annual_income
from employees;
1.2、無表查詢
有的時候,我們可能會遇到這樣的查詢語句:

也就是省略了FROM 子句的查詢,這是PostgreSQL 的擴展語法。這種查詢通常用于返回系統信息,或者當作計算器使用。需要注意的是,并非所有的關系數據庫都支持這種寫法,因此它并不具有可移植性。
1.3、消除重復結果
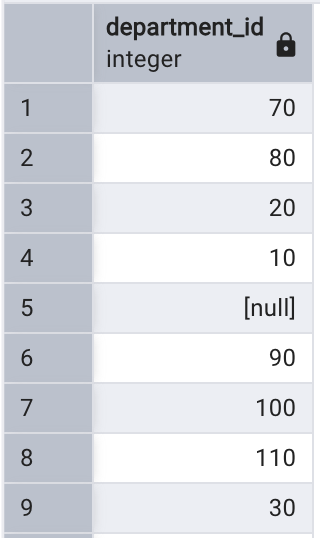
SQL 提供了消除查詢結果重復值的 DISTINCT 關鍵字。
select distinct department_id
from employees;
DISTINCT 也可以針對多個字段進行去重操作,例如:
select distinct first_name, last_name
from employees;
1.4、使用注釋
標準SQL注釋:
-- 這是標準SQL注釋方式
SELECT DISTINCT first_name
FROM employees;
注釋的內容會在語法分析之前替換成空格,因此不會被服務器執行。另外,PostgreSQL 還支持 C 語言風格的注釋方法(/* … */)。例如:
SELECT DISTINCT first_name
/* 這是一個多行注釋,
DISTINCT 表示排除重復值
/* 這是一個嵌套的注釋 */
*/
FROM employees;
二、查詢條件
2.1、WHERE子句
-- 語法
SELECT column1, column2, ...
FROM table
WHERE conditions;
WHERE 子句位于 FROM 之后,用于指定一個或者多個邏輯條件,用于過濾返回的結果。滿足條件的行將會返回,否則將被忽略。PostgreSQL 提供了各種運算符和函數,用于構造邏輯
條件。
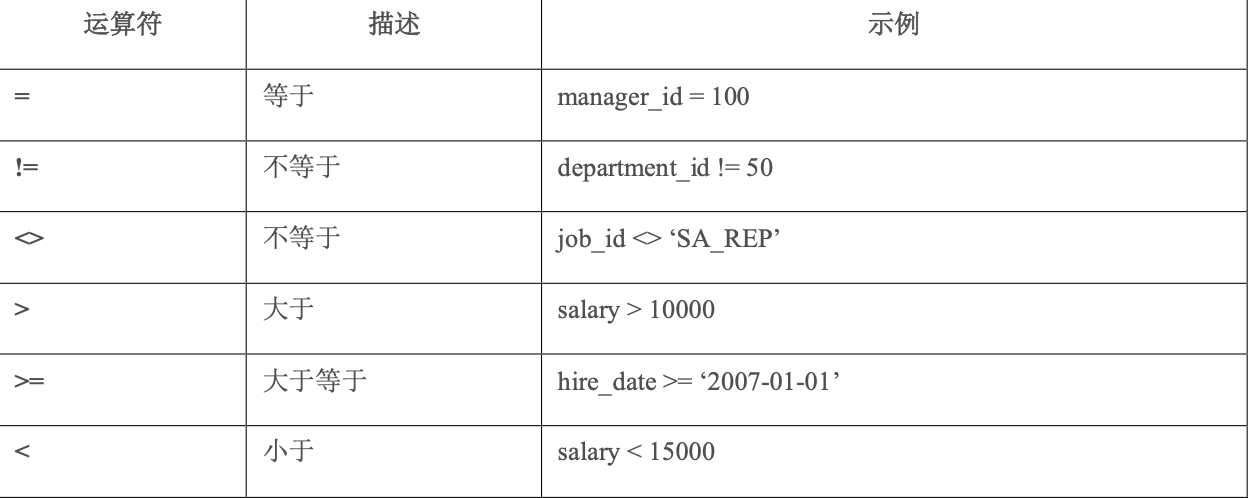

以上這些運算符的作用都比較明顯,不做詳細介紹。需要注意的是 BETWEEN 包含了兩端的值,等價于>=加上<=。
select first_name, last_name, salary
from employees
where salary between 11000 and 12000;

2.2、模式匹配
PostgreSQL 支持各種字符串模式匹配的功能。最簡單的方式就是使用 LIKE 運算符,以下查詢返回了姓氏(last_name)以“Kin”開頭的員工。

其中的百分號(%)可以匹配零個或者多個任意字符;另外,下劃線(_)可以匹配一個任意字符。例如:
- “%en”匹配以“en”結束的字符串;
- “%en%”匹配包含“en”的字符串;
- “B_g”匹配“Big”、“Bug”等。
如果字符串中存在這兩個通配符(%或),可以在它們前面加上一個反斜杠(\)進行轉義。

也可以通過 ESCAPE 子句指定其他的轉義字符。

另外,NOT LIKE 運算符匹配與 LIKE 相反的結果。

LIKE 運算符區分大小寫,PostgreSQL 同時還提供了不區分大小寫的 ILIKE 運算符。

2.3、空值判斷
根據SQL 標準,空值使用 NULL 表示。空值是一個特殊值,代表了未知數據。如果使用常規的比較運算符與 NULL 進行比較,總是返回空值。
NULL = 0; -- 結果為空值
NULL = NULL; -- 結果為空值
NULL != NULL; -- 結果為空值
如果在查詢條件中使用這種方式,將不會返回任何結果。因此,對于 NULL 值的比較,需要使用特殊的運算符:IS NULL。

IS NOT NULL 執行與 IS NULL 相反的操作,返回值不為空的數據。
2.4、復雜條件
WHERE 子句可以包含多個條件,使用邏輯運算符(AND、OR、NOT)將它們進行組合,并根據最終的邏輯值進行過濾。
AND(邏輯與)運算符的邏輯真值表如下:
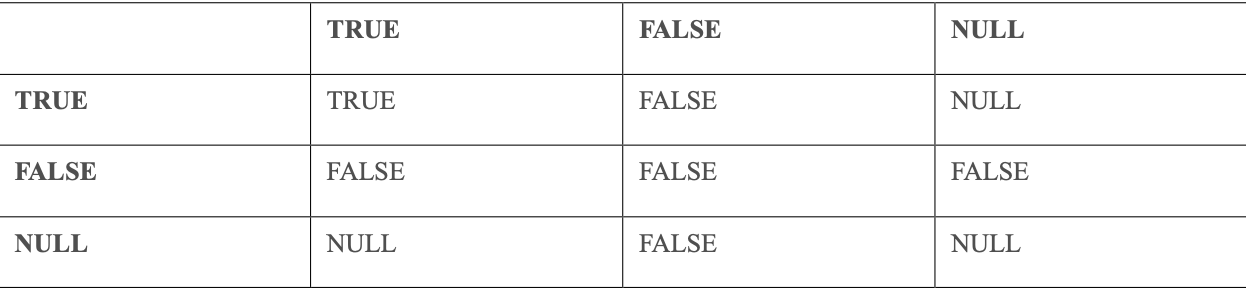
對于 AND 運算符,只有當它兩邊的結果都為真時,最終結果才為真;否則最終結果為假,不返回結果。

OR(邏輯或)運算符的邏輯真值表如下:
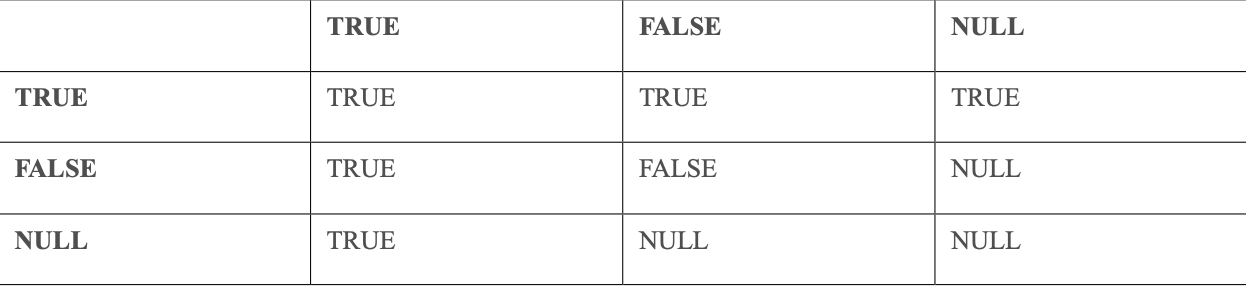
OR 邏輯或運算符只要有一個條件為真,結果就為真。以下查詢返回薪水為 10000,或者姓氏為“King”的員工:

對于邏輯運算符 AND 和 OR,需要注意的是,它們使用短路運算。也就是說,只要前面的表達式能夠決定最終的結果,不進行后面的計算。這樣能夠提高運算效率。因此,以下語句不會產生除零錯誤:
SELECT 1 WHERE 1 = 0 AND 1/0 = 1;
SELECT 1 WHERE 1 = 1 OR 1/0 = 1;
還需要注意的一個問題是,當我們組合 AND 和 OR 運算符時,AND 運算符優先級更高,總是先執行。

由于 AND 優先級高,查詢返回的是薪水為 24000 并且姓氏為“King”的員工,或者薪水為10000 的員工。如果相要返回姓氏為“King”,并且薪水為 10000 或24000 的員工,可以使用括號修改優先級:

NOT(邏輯非)運算符用于取反操作,它的邏輯真值表如下:
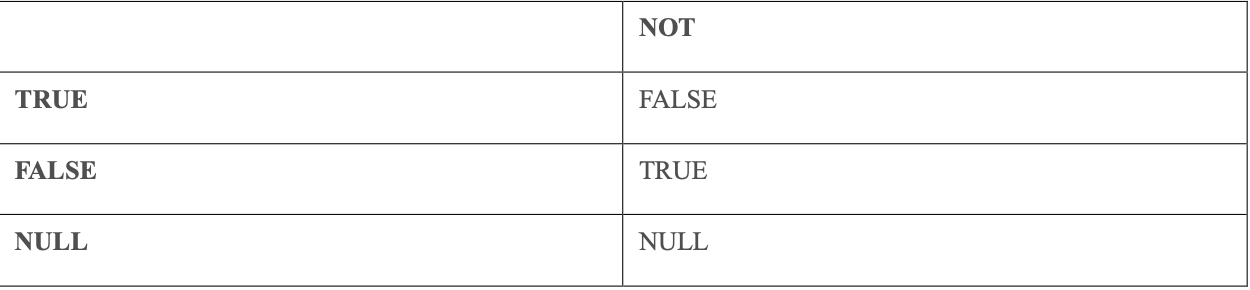
注意,對于未知的 NULL 值,經過 NOT 處理之后仍然是未知值。除此之外,NOT 還可以結合前面介紹的運算符一起使用:
- NOT BETWEEN,位于范圍之外
- NOT IN,不在列表之中
- NOT LIKE,不匹配模式
- NOT IS NULL,不為空,等價于 IS NOT NULL
最后,當查詢條件包含復雜邏輯時,它們的運算優先級從高到低排列如下:

三、排序顯示
3.1、單列排序
單列排序是指按照某個字段或者表達式進行排序,用法如下:
SELECT column1, column2, ...
FROM table
ORDER BY column1 [ASC | DESC];
ORDER BY 表示按照某個字段進行排序,ASC 表示升序排序(Ascending),DESC 表示降序排序(Descending),默認值為 ASC。
以下查詢返回部門編號為 60 的員工,并且按照薪水從高到低進行排序顯示:
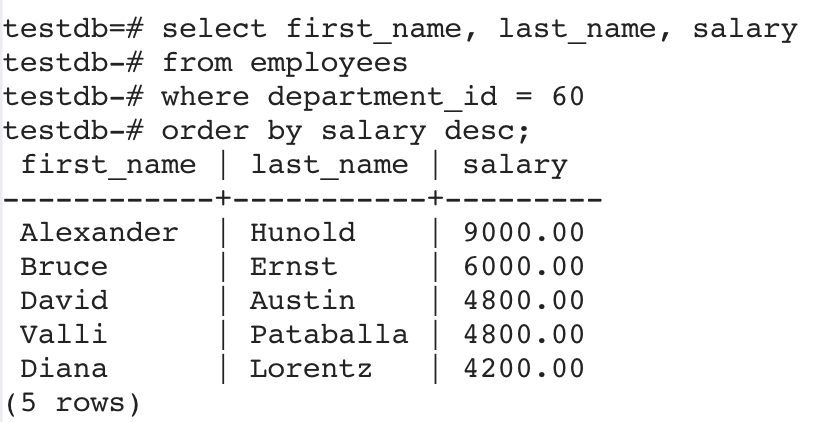
3.2、多列排序
-- 語法
SELECT column1, column2, ...
FROM table
ORDER BY column1 ASC, column2 DESC, ...;
以下查詢返回部門編號為 60 的員工,并且按照薪水從高到低進行排序顯示,如果薪水相同,再按照名字(first_name)降序排列:
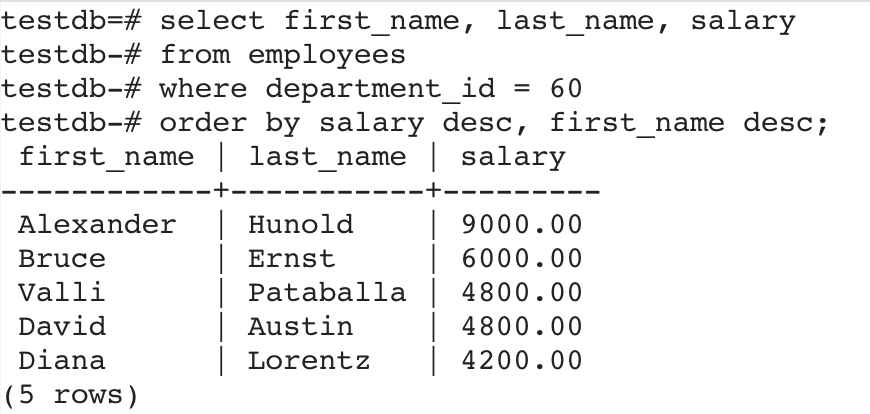
ORDER BY 后的排序字段可以是SELECT 列表中沒有的字段。以下語句返回了員工的姓名和薪水,按照入職先后進行顯示:
SELECT first_name, last_name, salary
FROM employees
ORDER BY hire_date;
除了在 ORDER BY 后指定字段名或者表達式之外,也可以簡單的使用它們在SELECT 列表中出現的順序來表示:
-- 以上語句表示先按照第 1 個字段(first_name)進行排序,再按照第 3 個字段(salary)進行排序。
SELECT first_name,last_name,salary
FROM employees
ORDER BY 1, 3;
PostgreSQL 對于字符類型的數據進行排序時不區分大小寫, “CAT”和“cat”順序相同。
3.3、空值排序
select first_name, last_name, commission_pct
from employees
where first_name = 'Peter'
order by commission_pct;

以上查詢按照傭金百分比(commission_pct)進行升序顯示。對于“Peter Vargas”,由于他沒有傭金提成,相應的值為空,PostgreSQL 默認將他排在了最后。
PostgreSQL 支持使用 NULLS FIRST(空值排在最前)和 NULLS LAST(空值排在最后)指定空值的排序位置;升序排序時默認為 NULLS LAST,降序排序時默認為 NULLS FIRST。
select first_name, last_name, commission_pct
from employees
where first_name = 'Peter'
order by commission_pct nulls first;

四、限定結果數量
查詢語句的結果可能包含成百上千行數據,但是前端顯示時也許只需要其中的小部分,例如TOP-N 排行榜;或者為了便于查看,每次只顯示一定數量的結果,例如分頁功能。為了處理這類應用,SQL 提供了標準的FETCH 和 OFFSET 子句。另外,PostgreSQL 還實現了擴展的 LIMIT語法。
4.1、Top-N查詢
這類查詢通常是為了找出排名中的前N 個記錄,例如以下語句查詢薪水最高的前10 名員工,使用 FETCH 語法:
select first_name, last_name, salary
from employees
order by salary desc
fetch first 10 rows only;-- 其中,FIRST 也可以寫成 NEXT,ROWS 也可以寫成 ROW。結果返回了排序之后的前 10條記錄。
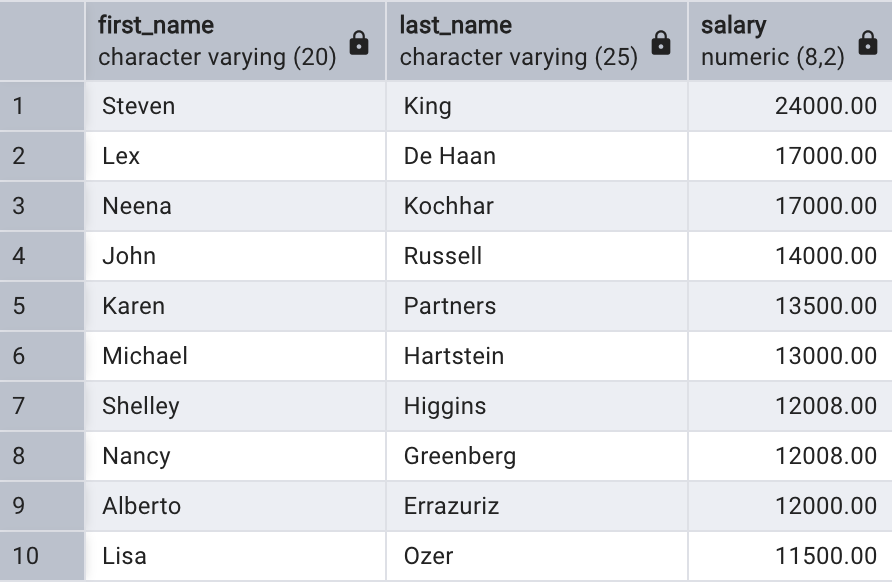
使用LIMIT 語法也可以實現相同的功能:
select first_name, last_name, salary
from employees
order by salary desc
limit 10;
4.2、分頁查詢
許多應用都支持分頁顯示的功能,即每頁顯示一定數量的記錄(例如 10 行、20 行等),同時提供類似上一頁和下一頁的導航。使用SQL 實現這種功能需要引入另一個子句:OFFSET。
假設我們的應用提供了分頁顯示,每頁顯示 10 條記錄。現在用戶點擊了下一頁,需要顯示第 11 到第 20 條記錄。使用標準SQL 語法實現如下:
select first_name, last_name, salary
from employees
order by salary desc
offset 10 rows
fetch first 10 rows only;-- OFFSET 表示先忽略掉多少行數據,然后再返回后面的結果。ROWS 也可以寫成 ROW。對于應用程序而言,只需要傳入不同的OFFSET 偏移量和FETCH 數量,就可以在結果中任意導航。
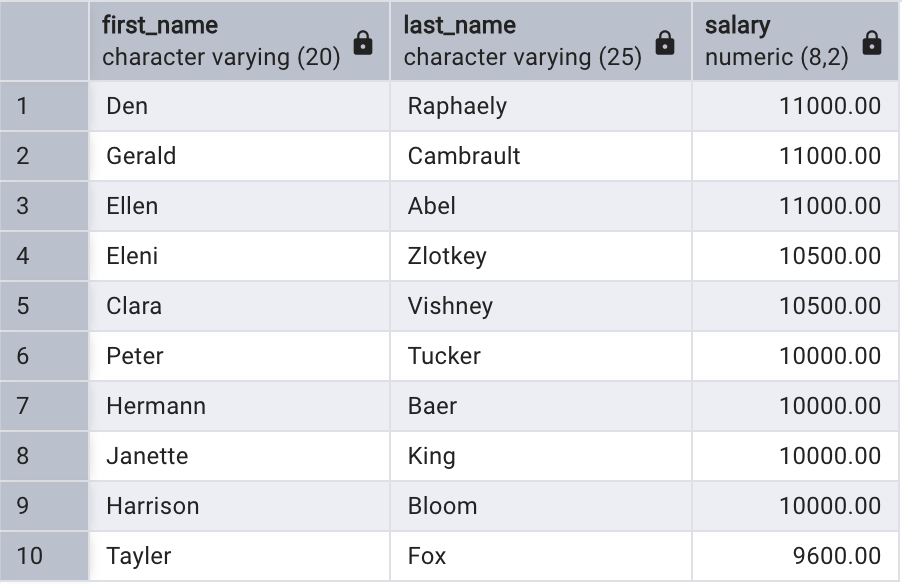
使用LIMIT 加上 OFFSET 同樣可以實現分頁效果:
select first_name, last_name, salary
from employees
order by salary desc
limit 10 offset 10;
4.3、注意事項
先看一下完整的FETCH 和LIMIT 語法:
SELECT column1, column2, ...
FROM table
[WHERE conditions]
[ORDER BY column1 ASC, column2 DESC, ...]
[OFFSET m {ROW | ROWS}]
[FETCH { FIRST | NEXT } [ num_rows] { ROW | ROWS } ONLY];SELECT column1, column2, ...
FROM table
[WHERE conditions]
[ORDER BY column1 ASC, column2 DESC, ...]
[LIMIT { num_rows| ALL } ]
[OFFSET m {ROW | ROWS}];
在使用以上功能時需要注意以下問題:
- FETCH 是標準 SQL 語法,LIMIT 是PostgreSQL 擴展語法。
- 如果沒有指定 ORDER BY,限定數量之前并沒有進行排序,是一個隨意的結果。
- OFFSET 偏移量必須為 0 或者正整數。默認為0,NULL 等價于 0。
- FETCH 限定的數量必須為 0 或者正整數。默認為 1,NULL 等價于不限定數量。
- LIMIT 限定的數量必須為0 或者正整數, 沒有默認值。 ALL 或者NULL 表示不限定數量。
- 隨著 OFFSET 的增加,查詢的性能會越來越差。因為服務器需要計算更多的偏移量,即使這些數據不需要被返回前端。
五、分組匯總
5.1、聚合函數
PostgreSQL支持以下常見的聚合函數:
- AVG - 計算一組值的平均值。
- COUNT - 統計一組值的數量。
- MAX - 計算一組值的最大值。
- MIN - 計算一組值的最小值。
- SUM - 計算一組值的和值。
- STRING_AGG - 連接一組字符串。
以下示例分別返回了 IT 部門所有員工的平均薪水、員工總數、最高薪水、最低薪水、以及薪水總計:
select avg(salary),count(*),max(salary),min(salary),sum(salary)
from employees
where department_id = 60;

關于聚合函數,需要注意兩點:
- 函數參數前添加 DISTINCT 關鍵字,可以在計算時排除重復值。
- 忽略參數中的 NULL 值。
select count(*),count(distinct salary),count(commission_pct)
from employees
where department_id = 60;
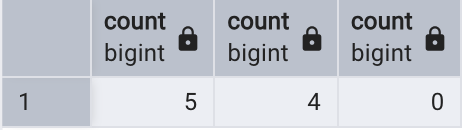
其中,COUNT(*)返回了該部門員工的總數(5),COUNT(DISTINCT salary)返回了薪水不相同的員工數量(4),COUNT(commission_pct)返回了傭金百分比不為空值的數量(0),該部門員工都沒有傭金提成。
另外,PostgreSQL 為聚合函數提供了一個FILTER 擴展選項,可以用于匯總滿足特定條件的數據。例如:
select count(*) filter (where salary >= 10000) high_sal,count(*) filter (where salary < 10000) low_sal
from employees;

其中, FILTER 選項可以指定一個 WHERE 條件,只有滿足條件的數據才會進行匯總。因此,示例中的第一個 COUNT 函數返回了月薪大于等于 10000 的員工數量, 第二個COUNT 函數返回了月薪小于 10000 的員工數量。
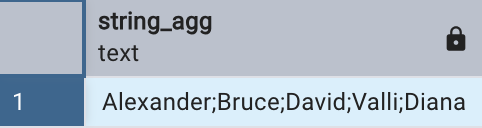
以下示例使用 STRING_AGG 函數將 IT 部門員工的名字使用分號進行分隔,按照薪水從高到低排序后連接成一個字符串:
select string_agg(first_name, ';' order by salary desc)
from employees
where department_id = 60;
5.2、分組聚合
如果我們想要知道每個部門內所有員工的平均薪水、員工總數、最高薪水、最低薪水、以及薪水總計,可以使用以下查詢語句:
select department_id, avg(salary),count(*),max(salary),min(salary),sum(salary)
from employees
group by department_id
order by department_id;
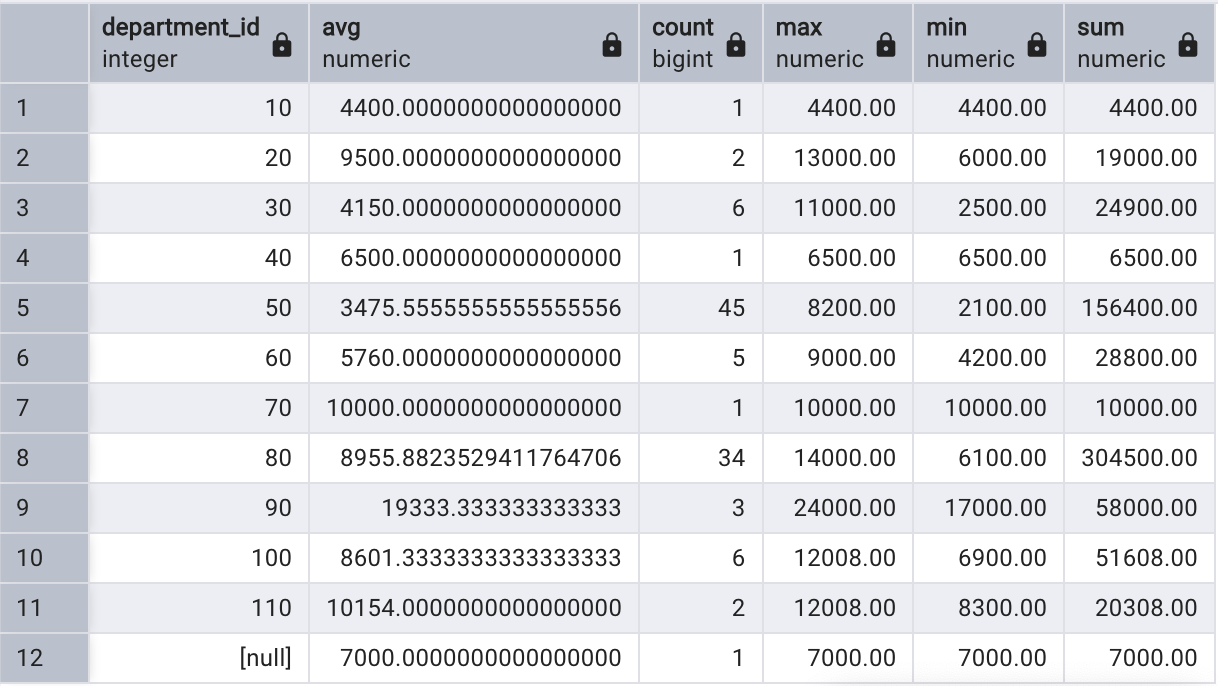
查詢執行時,首先根據 GROUP BY 子句中的列(department_id)進行分組,然后使用聚合函數匯總組內的數據。最后一條數據是針對部門編號字段為空的數據進行的分組匯總,GROUP BY 將所有的 NULL 分為一組。
GROUP BY 并不一定需要與聚合函數一起使用,例如:
select department_id
from employees
group by department_id
order by department_id;
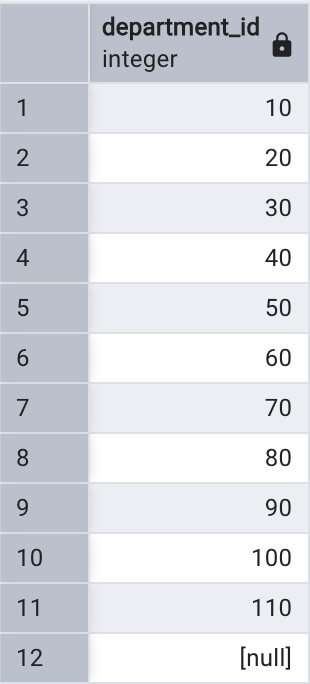
查詢的結果就是不同的部門編號分組,這種查詢的結果與 DISTINCT 效果相同:
select distinct department_id
from employees
order by department_id;
GROUP BY 不僅可以按照一個字段進行分組,也可以使用多個字段將數據分成更多的組。例如,以下查詢將員工按照不同的部門和職位組合進行分組,然后進行匯總:
select department_id, job_id, avg(salary),count(*),max(salary),min(salary),sum(salary)
from employees
group by department_id, job_id
order by department_id, job_id;
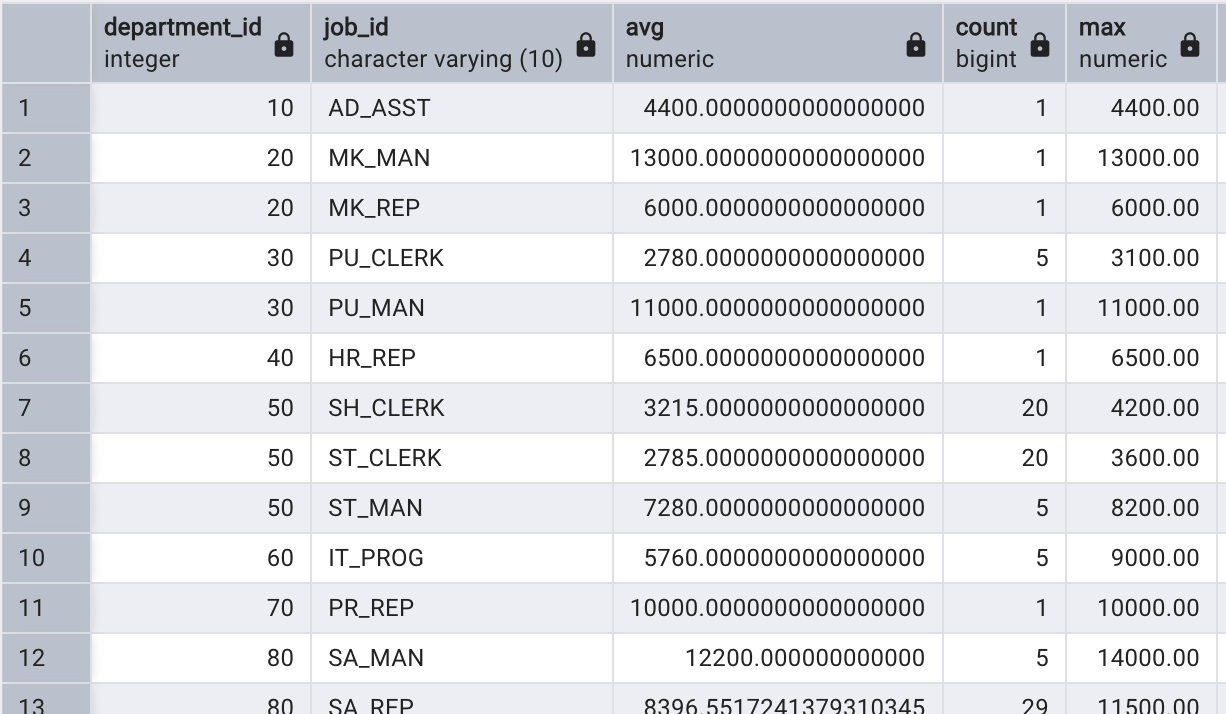
使用了 GROUP BY 子句進行分組操作之后需要注意一點,就是SELECT 列表中只能出現分組字段或者聚合函數,不能再出現表中的其他字段。下面是一個錯誤的示例:
select department_id, job_id, avg(salary),count(*),max(salary),min(salary),sum(salary)
from employees
group by department_id;-- ERROR: column "employees.job_id" must appear in the GROUP BY clause or be used in an aggregate function
-- LINE 1: select department_id, job_id,
5.3、分組過濾
當我們需要針對分組匯總后的數據再次進行過濾時,例如找出平均薪水值大于 10000 的部門:
select department_id,avg(salary),count(*),max(salary),min(salary),sum(salary)
from employees
group by department_id
having avg(salary) > 10000
order by department_id;

HAVING 出現在 GROUP BY 之后,也在它之后執行,因此能夠使用聚合函數進行過濾。我們可以同時使用 WHERE 子句進行數據行的過濾,使用 HAVING 進行分組結果的過濾。
以下示例用于查找哪些部門中薪水大于 10000 的員工的數量多于2 個:
select department_id,count(*) as headcount
from employees
where salary > 10000
group by department_id
having count(*) > 2;
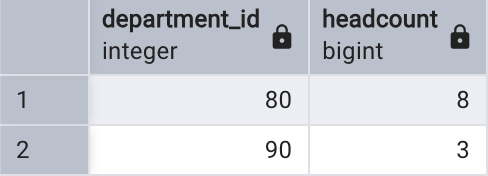
查詢時,首先通過 WHERE 子句找出薪水大于 10000 的所有員工;然后,按照部門編號進行分組,計算每個組內的員工數量;最后使用 HAVING 子句過濾員工數量多于2 個人的部門。
5.4、高級選項
PostgreSQL 除了支持基本的 GROUP BY 分組操作之外,還支持 3 種高級的分組選項:GROUPING SETS、ROLLUP 以及 CUBE。
5.4.1、GROUPING SETS選項
GROUPING SETS 是GROUP BY 的擴展選項,用于指定自定義的分組集。舉例來說,以下是一個銷售數據表:
CREATE TABLE sales (item VARCHAR(10),year VARCHAR(4),quantity INT
);INSERT INTO sales VALUES('apple', '2018', 800);
INSERT INTO sales VALUES('apple', '2018', 1000);
INSERT INTO sales VALUES('banana', '2018', 500);
INSERT INTO sales VALUES('banana', '2018', 600);
INSERT INTO sales VALUES('apple', '2019', 1200);
INSERT INTO sales VALUES('banana', '2019', 1800);
按照產品(item)和年度(year)進行分組匯總時,所有可能的4 種分組集包括:
- 按照產品和年度的組合進行分組;
- 按照產品進行分組;
- 按照年度進行分組;
- 所有數據分為一組。
-- 按照產品和年度的組合進行分組
select item, year, sum(quantity)
from sales
group by item, year;
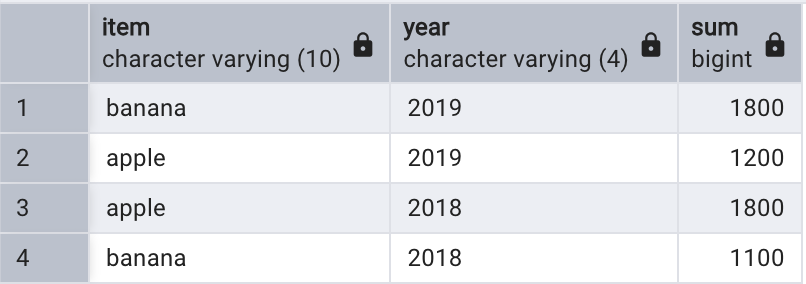
-- 按照產品進行分組
SELECT item, NULL AS year, SUM(quantity)
FROM sales
GROUP BY item;
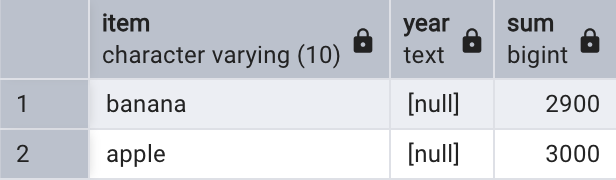
-- 按照年度進行分組
SELECT NULL AS item, year, SUM(quantity)
FROM sales
GROUP BY year;

-- 所有數據分為一組
SELECT NULL AS item, NULL AS year, SUM(quantity)
FROM sales;

GROUPING SETS 是GROUP BY 的擴展選項,能夠為這種查詢需求提供更加簡單有效的解決方法。我們使用分組集改寫上面的示例:
SELECT item, year, SUM(quantity)
FROM sales
GROUP BY GROUPING SETS ((item, year),(item),(year),()
);
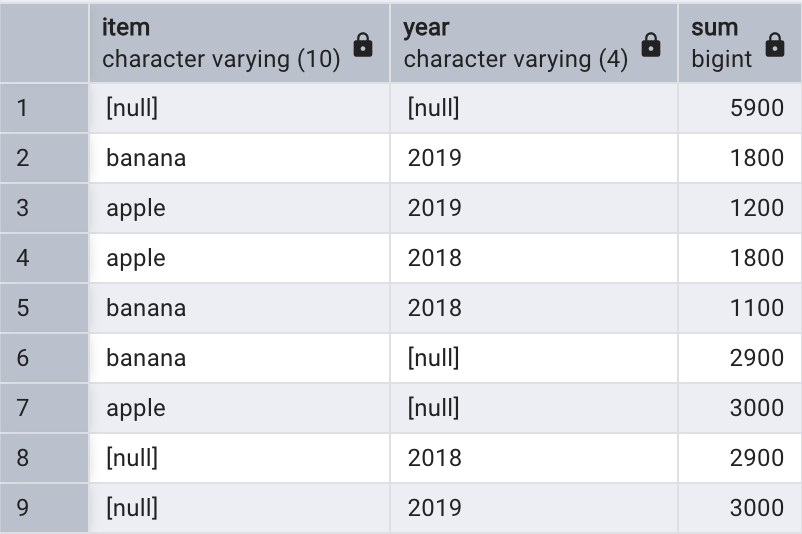
GROUPING SETS 選項用于定義分組集,每個分組集都需要包含在單獨的括號中,空白的括號(())表示將所有數據當作一個組處理。查詢的結果等于前文 4 個查詢的合并結果,但是語句更少,可讀性更強;而且 PostgreSQL 執行時只需要掃描一次銷售表,性能更加優化。
另外,默認的 GROUP BY 使用由所有分組字段構成的一個分組集,本示例中為 ((item, year))。
5.4.2、CUBE選項
隨著分組字段的增加,即使通過 GROUPING SETS 列出所有可能的分組方式也會顯得比較麻煩。設想一下使用 4 個字段進行分組統計的場景,所有可能的分組集共計有 16 個。這種情況下編寫查詢語句仍然很復雜,為此PostgreSQL 提供了簡寫形式的 GROUPING SETS:CUBE 和ROLLUP。
CUBE 表示所有可能的分組集,例如:
CUBE(c1, c2, c3)-- 等價于GROUPING SETS((c1, c2, c3),(c1, c2),(c1, c3),(c2, c3),(c1),(c2),(c3),()
)
因此,我們可以進一步將上面的示例改寫如下:
select item, year, sum(quantity)
from sales
group by cube (item, year);
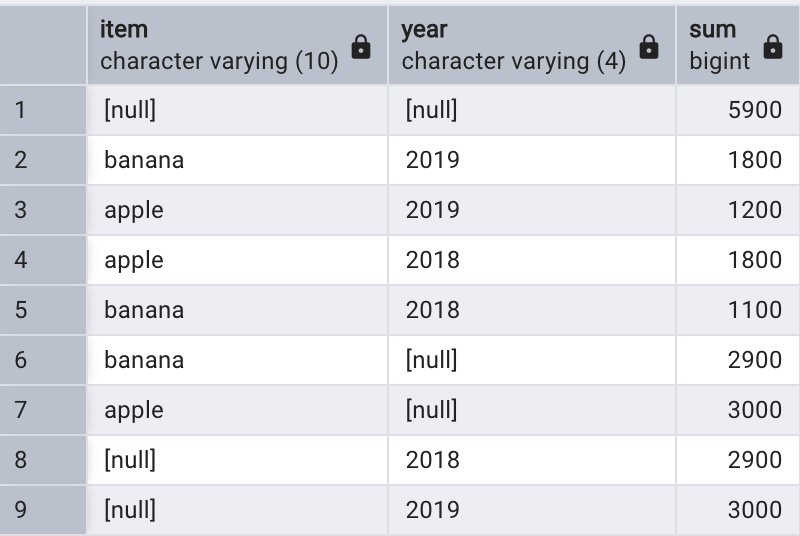
5.4.3、ROLLUP選項
GROUPING SETS 第二種簡寫形式就是 ROLLUP,用于生成按照層級進行匯總的結果,類似于財務報表中的小計、合計和總計。例如:
ROLLUP(c1, c2, c3)-- 等價于GROUPING SETS((c1, c2, c3),(c1, c2),(c1),()
)
以下查詢返回按照產品和年度組合進行統計的銷量小計,加上按照產品進行統計的銷量合計,再加上所有銷量的總計:
select item, year, sum(quantity)
from sales
group by rollup(item, year);
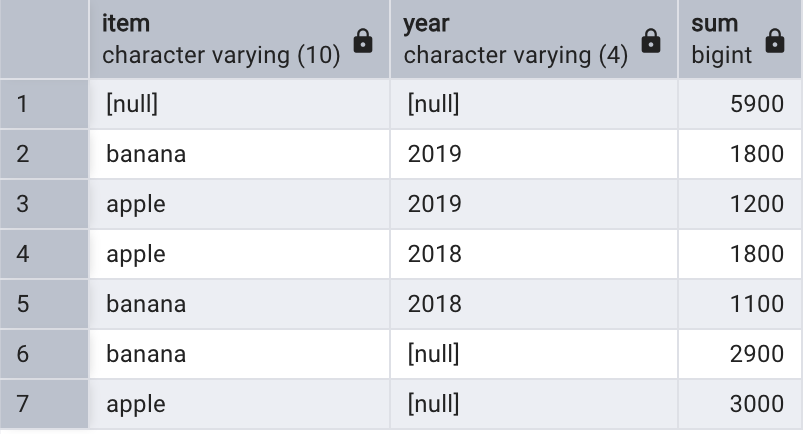
查看結果時,需要根據每個字段上的空值進行判斷。比如第一行的產品和年度都為空,因此它是所有銷量的總計。為了便于查看,可以將空值進行轉換顯示:
select coalesce(item, '所有產品') as "產品",coalesce(year, '所有年度') as "年度",sum(quantity) as "銷量"
from sales
group by rollup(item, year);
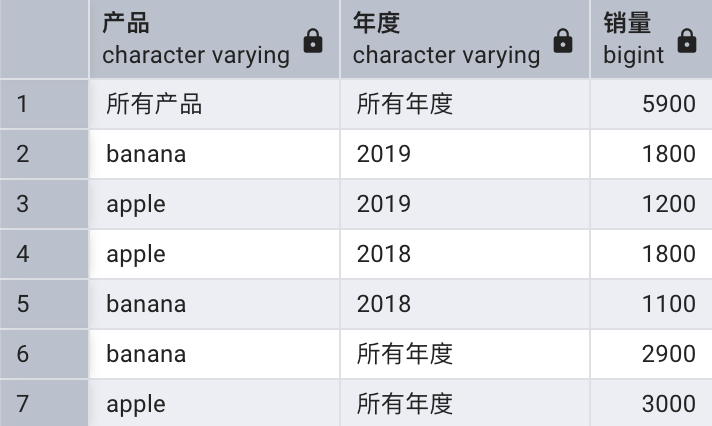
可以根據需要返回按照某些組合進行統計的結果,以下查詢返回按照產品和年度組合進行統計的銷量小計,加上按照產品進行統計的銷量合計:
select coalesce(item, '所有產品') as "產品",coalesce(year, '所有年度') as "年度",sum(quantity) as "銷量"
from sales
group by item, rollup(year);
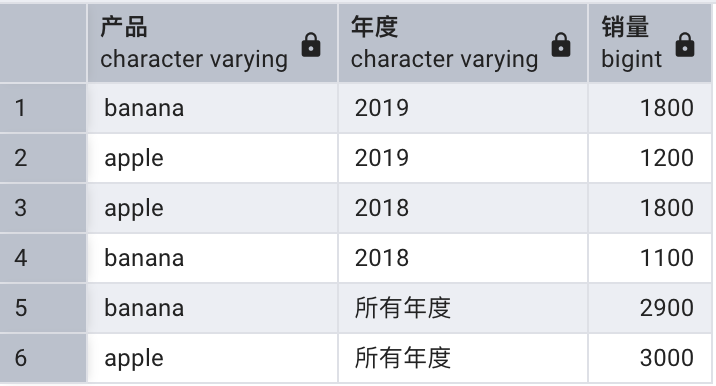
對于CUBE 和ROLLUP 而言,每個元素可以是單獨的字段或表達式,也可以是使用括號包含的列表。如果是括號中的列表,產生分組集時它們必須作為一個整體。例如:
CUBE((c1,c2), (c3,c4))
-- 等價于
GROUPING SETS((c1,c2, c3,c4),(c1,c2),(c3,c4),()
)
-- 因為c1 和 c2 是一個整體,c3 和c4 是一個整體。
同樣:
ROLLUP ( c1, (c2, c3), c4 )
-- 等價于
GROUPING SETS (( c1, c2, c3, c4 ),( c1, c2, c3 ),( c1 ),( )
)
5.4.4、GROUPING函數
雖然有時候可以通過空值來判斷數據是不是某個字段上的匯總,比如說按照年度進行統計的結果在字段 year 上的值為空。但是情況并非總是如此,考慮以下示例:
-- 未知產品在 2018 年的銷量為 5000
INSERT INTO sales VALUES(NULL, '2018', 5000);SELECT coalesce(item, '所有產品') AS "產品",coalesce(year, '所有年度') AS "年度",SUM(quantity) AS "銷量"
FROM sales
GROUP BY ROLLUP (item,year);
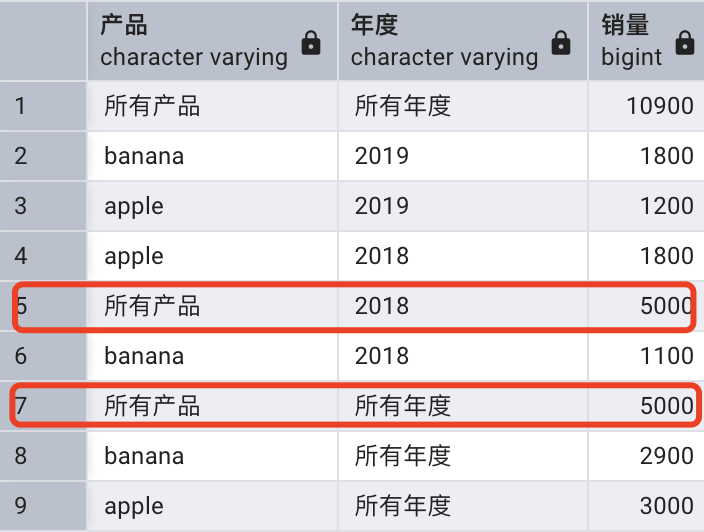
其中第 5 行和第 7 行的顯示存在問題,它們分別應該是未知產品在 2018 年的銷量小計和所有年度的銷量合計。問題的關鍵在于無法區分是分組產生的 NULL 還是源數據中的 NULL。為了解決這個問題,PostgreSQL 提供了一個分組函數:GROUPING。
-- 以下查詢顯示了 GROUPING 函數的結果:
SELECT item AS "產品",year AS "年度",SUM(quantity) AS "銷量",GROUPING(item),GROUPING(year),GROUPING(item, year)
FROM sales
GROUP BY ROLLUP (item,year);
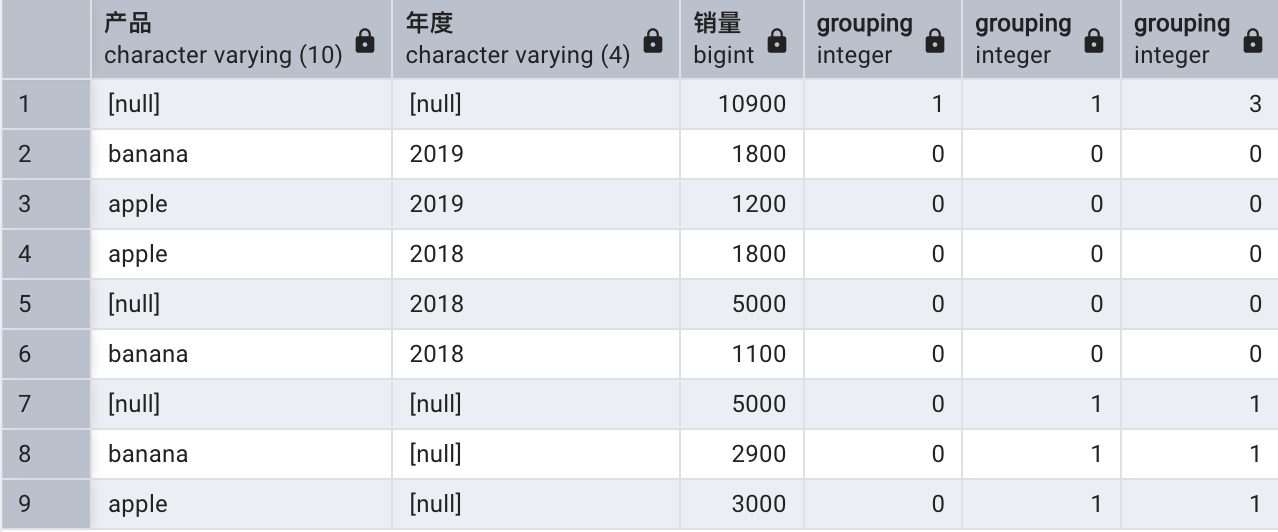
GROUPING 函數如果只有一個參數,返回整數 0 或者 1。如果某個統計結果使用的分組集包含了函數中的參數字段,該函數返回 0,否則返回 1。比如說,第 1 行數據是所有產品所有年度的統計(分組集為空),所以 GROUPING(item)和 GROUPING(year)結果都是 1;第 7 行數據是未知產品所有年度的統計(分組集為(item, )),所以GROUPING(item)結果為0, GROUPING(year)結果為 1。
GROUPING 函數如果包含多個參數,針對每個參數返回整數 0 或者 1,然后將它們按照二進制數值連接到一起。比如說,第1 行數據中的GROUPING(item, year)結果等于GROUPING(item)和 GROUPING(year)結果的二進制數值連接,也就是 3(二進制的 11)。
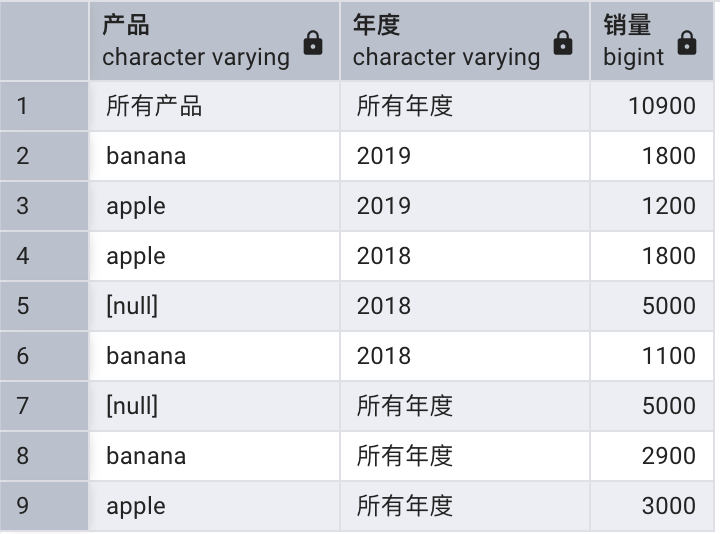
通過使用 GROUPING 函數,我們可以正確顯示分組中的 NULL 值和源數據中的 NULL 值:
SELECT CASE GROUPING(item) WHEN 1 THEN '所有產品' ELSE item END AS "產品",CASE GROUPING(year) WHEN 1 THEN '所有年度' ELSE year END AS "年度",SUM(quantity) AS "銷量"
FROM sales
GROUP BY ROLLUP (item,year);
六、多表連接
PostgreSQL 支持各種類型的 SQL 連接查詢:
- 內連接(INNER JOIN)
- 左外連接(LEFT OUTER JOIN)
- 右外連接(RIGHT OUTER JOIN)
- 全外連接(FULL OUTER JOIN)
- 交叉連接(CROSS JOIN)
- 自然連接(NATURAL JOIN)
- 自連接(Self Join)
其中,左外連接、右外連接以及全外連接統稱為外連接(OUTER JOIN)。
6.1、內連接
內連接用于返回兩個表中匹配的數據行,使用關鍵字INNER JOIN 表示,也可以簡寫成JOIN;以下是內連接的示意圖(基于兩個表的 id 進行連接):

SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
其中,JOIN 表示內連接,ON 表示連接條件。另外,SELECT 列表中的字段名加上了表名限定,例如 d.department_id,這是因為兩個表中都存在部門編號,必須明確指定需要顯示哪個表中的字段。不過,如果某個字段只存在于一個表中,可以省略表名,例如 first_name。
-- 對于內連接而言,也可以使用FROM 和 WHERE 表示:
SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM employees e, departments d
WHERE e.department_id = d.department_id;
在這種語法中,多個表在 FROM 子句中使用逗號進行分割,連接條件使用 WHERE 子句表示。實際上,在 SQL 歷史中定義了兩種多表連接的語法:
- ANSI SQL/86 標準使用FROM 和 WHERE 關鍵字指定表的連接條件。
- ANSI SQL/92 標準使用JOIN 和 ON 關鍵字指定表的連接條件。
6.2、左/右外連接
左外連接返回左表中所有的數據行;對于右表,如果沒有匹配的數據,顯示為空值。左外連接使用關鍵字 LEFT OUTER JOIN 表示,也可以簡寫成 LEFT JOIN。 左外連接參考以下示意圖(基于兩個表的 id 進行連接):

由于某些部門剛剛成立,可能還沒有員工,因此前面的內連接查詢不會顯示這些部門的信息。如果想要在連接查詢中返回這些部門的信息,需要使用左外連接:
SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM departments d LEFT JOIN employees e
ON e.department_id = d.department_id;
右外連接返回右表中所有的數據行;對于左表,如果沒有匹配的數據,顯示為空值。右外連接使用關鍵字RIGHT OUTER JOIN 表示,也可以簡寫成RIGHT JOIN。也就是說:
table1 RIGHT JOIN table2
-- 等價于
table2 LEFT JOIN table1
因此,上面的查詢也可以使用右外連接來表示:
SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM departments d RIGHT JOIN employees e
ON d.department_id = e.department_id;
6.3、全外連接
全外連接等效于左外連接加上右外連接,返回左表和右表中所有的數據行。全外連接使用關鍵字 FULL OUTER JOIN 表示,也可以簡寫成 FULL JOIN。
全外連接的示意圖如下(基于兩個表的 id 進行連接):
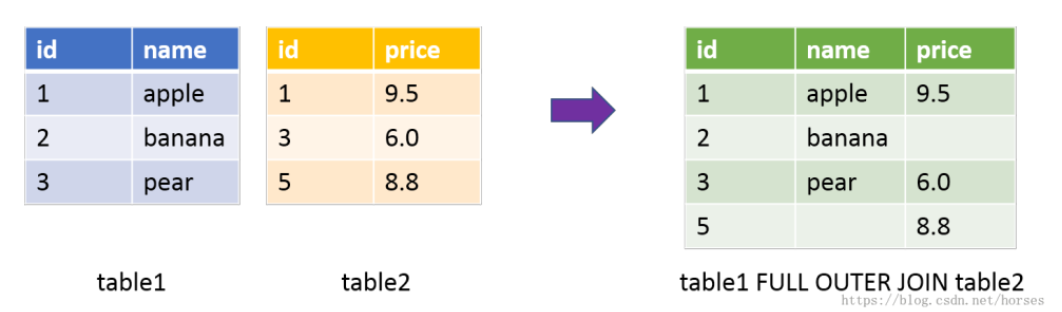
以下查詢將員工表和部門表進行全外連接,連接字段為部門編號:
SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM departments d FULL JOIN employees e
ON d.department_id = e.department_id
WHERE e.employee_id IN (176, 177, 178)
OR d.department_id IN (110, 120, 130);
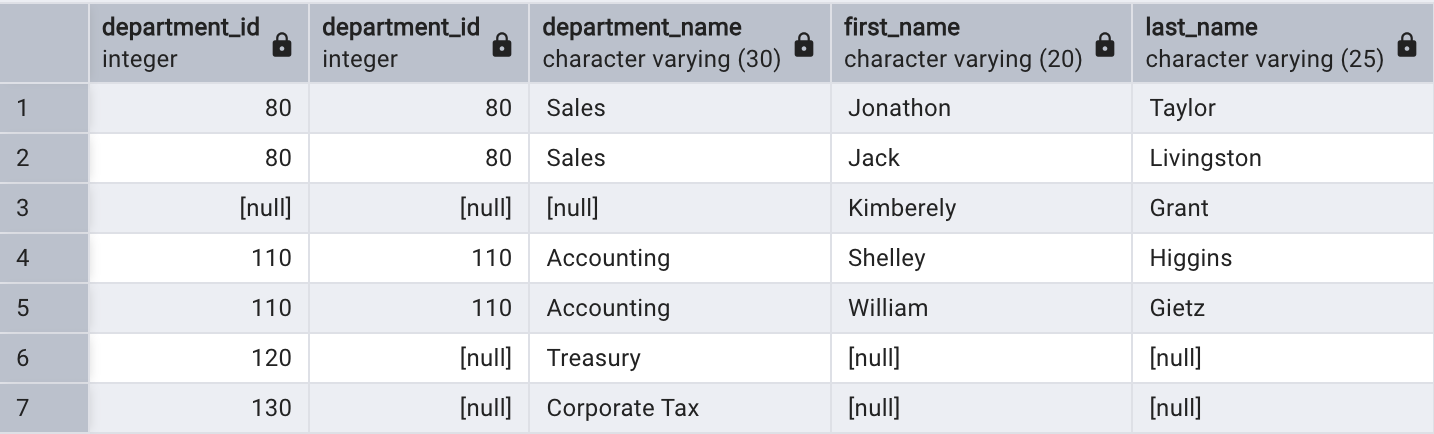
查詢結果不但包含了沒有員工的部門,同時還存在一個沒有部門的員工。
對于外連接,需要注意 WHERE 條件和 ON 條件之間的差異:ON 條件是針對連接之前的數據進行過濾,WHERE 是針對連接之后的數據進行過濾,同一個條件放在不同的子句中可能會導致不同的結果。
以下示例將部門表與員工表進行左外連接查詢,并且在 ON 子句中指定了多個條件:
SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM departments d
LEFT JOIN employees e
ON d.department_id = e.department_id AND e.employee_id = 0;
ON 子句指定了一個不存在的員工(e.employee_id = 0),因此員工表不會返回任何數據。但是由于查詢指定的是左外連接,仍然會返回部門信息。
對于相同的查詢條件,使用 WHERE 子句的示例如下:
SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM departments d LEFT JOIN employees e
ON d.department_id = e.department_id
WHERE e.employee_id = 0;
查詢結果沒有返回任何數據,因為左連接產生的結果經過 WHERE 條件(e.employee_id = 0)過濾之后沒有任何滿足的數據。
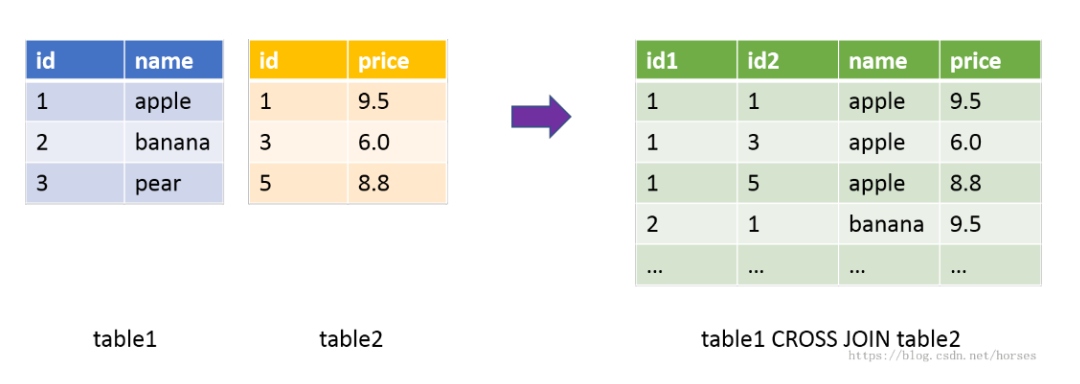
6.4、交叉連接
當連接查詢沒有指定任何連接條件時,就稱為交叉連接。交叉連接使用關鍵字CROSS JOIN表示,也稱為笛卡爾積(Cartesian product)。
兩個表的笛卡爾積相當于一個表的所有行和另一個表的所有行兩兩組合,結果數量為兩個表的行數相乘。假如第一個表有 100 行,第二個表有 200 行,它們的交叉連接將會產生100 × 200 = 20000 行結果。交叉連接的示意圖如下(基于兩個表的id 進行連接):
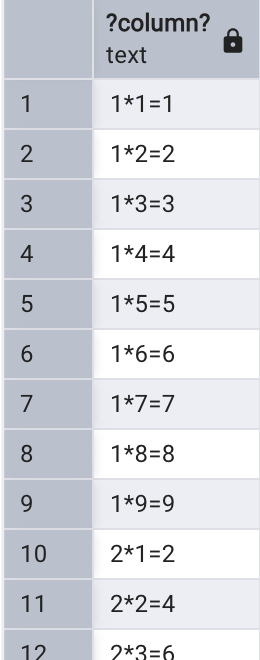
以下查詢通過笛卡兒積返回九九乘法表:
SELECT v || '*' || h || '=' || v*h
FROM generate_series(1,9) v
CROSS JOIN generate_series(1,9) h;
上面的交叉連接也可以使用以下等效寫法:
SELECT v || '*' || h || '=' || v*h
FROM generate_series(1,9) v, generate_series(1,9) h;SELECT v || '*' || h || '=' || v*h
FROM generate_series(1,9) v
JOIN generate_series(1,9) h ON TRUE;
6.5、自然連接
對于連接查詢,如果滿足以下條件,可以使用 USING 替代 ON 子句,簡化連接條件的輸入:
- 連接條件是等值連接,即 t1.col1 = t2.col1;
- 兩個表中的列必須同名同類型,即t1.col1 和t2.col1 的類型相同。
由于 employees 表和 departments 表中的 department_id 字段名稱和類型都相同,可以使用USING 簡寫前文中的連接查詢:
SELECT d.department_id,e.department_id,d.department_name,e.first_name,e.last_name
FROM employees e
JOIN departments d
USING (department_id);
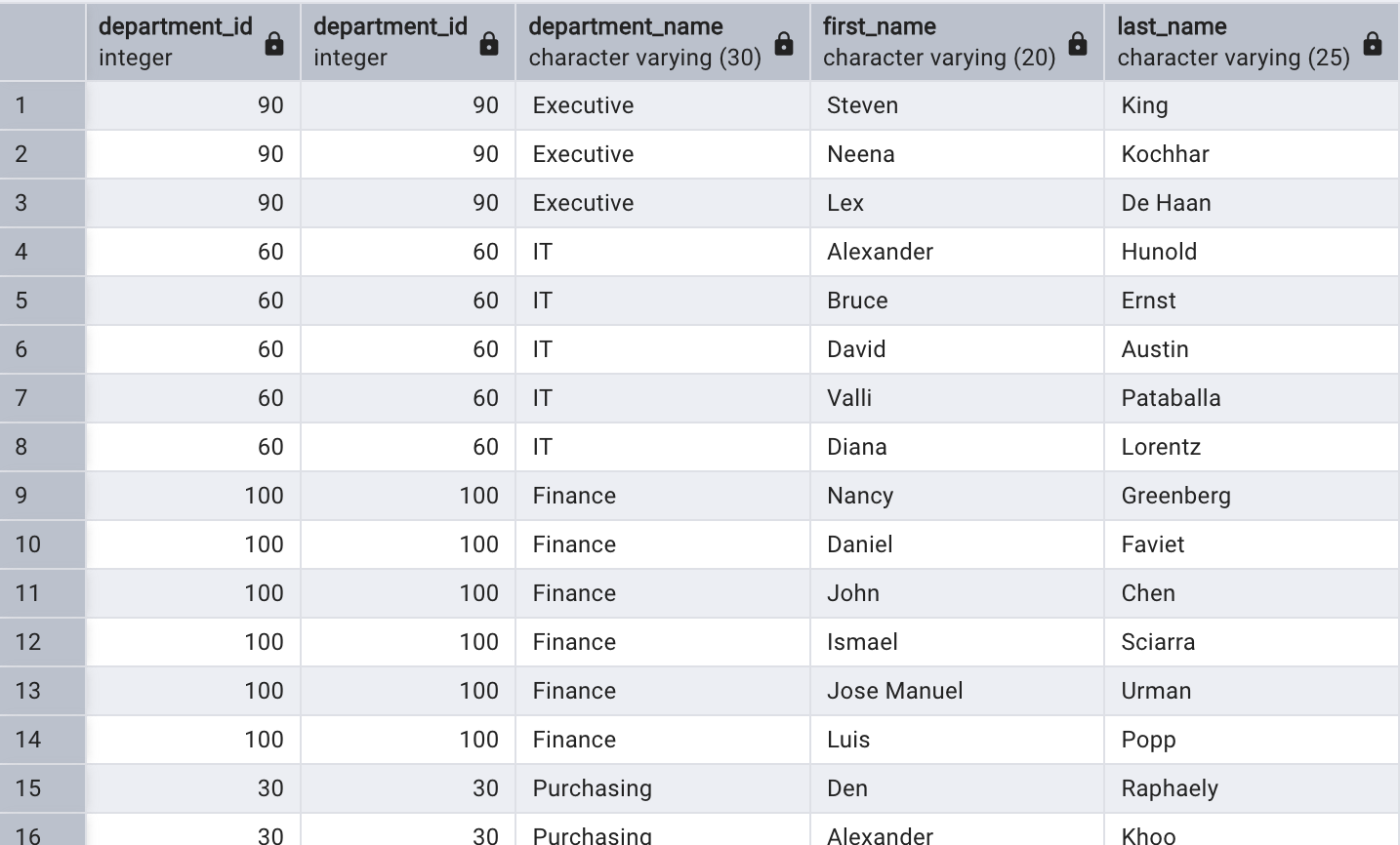
USING 條件中的字段不需要指定表名,它是公共的字段。
如果USING 子句中包含了兩個表中所有的這種同名同類型字段,可以使用更加簡單的自然連接(NATURAL JOIN)表示。例如,employees 表和departments 表擁有2 個同名同類型字段:department_id 和manager_id,如果基于這 2 個字段進行等值連接,可以使用自然連接:
SELECT d.department_id,d.department_name,e.first_name,e.last_name
FROM departments d
NATURAL JOIN employees e;
6.6、自連接
連接(Self Join)是指連接操作符的兩邊都是同一個表,即把一個表和它自己進行連接。自連接本質上并沒有什么特殊之處,主要用于處理那些對自己進行了外鍵引用的表。
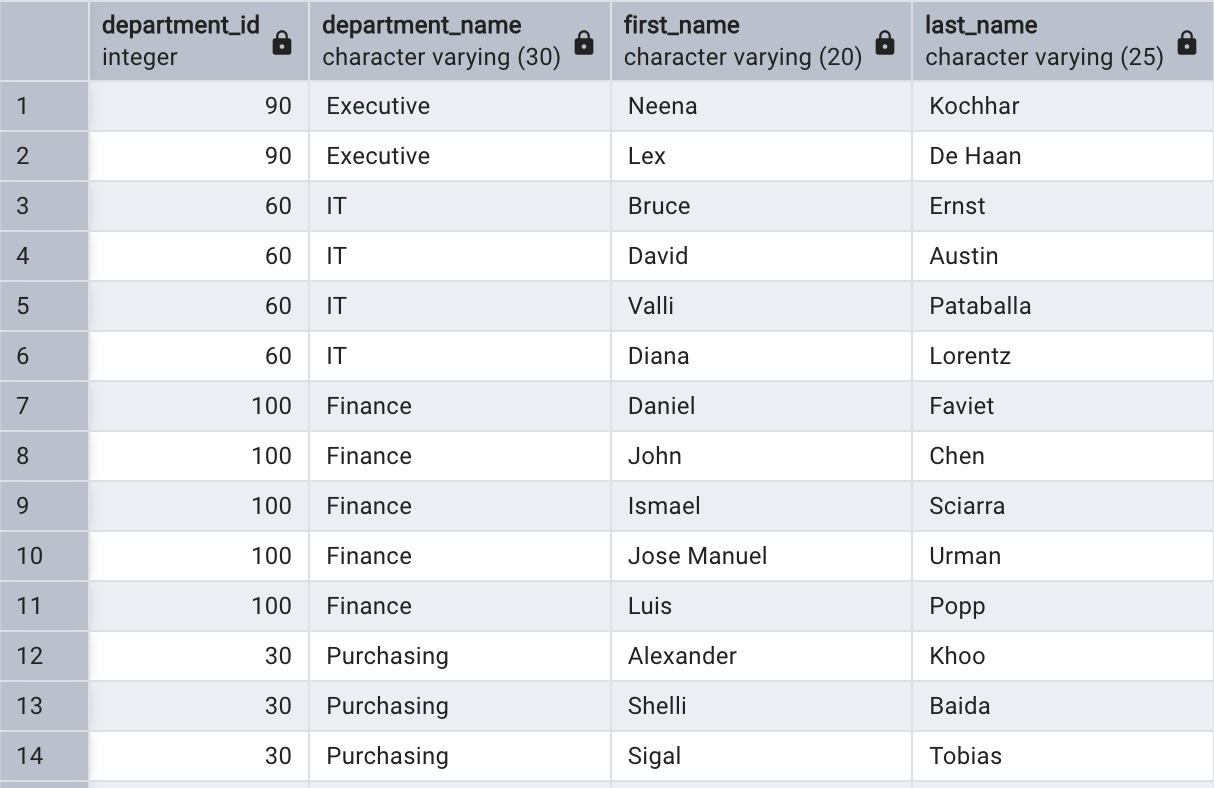
例如,員工表中的經理字段(manager_id)是一個外鍵列,指向了員工表自身的員工編號字段(employee_id)。如果要顯示員工姓名以及他們經理的姓名,可以通過自連接實現:
SELECT e.first_name||', '||e.last_name AS employee_name,
m.first_name||', '||m.last_name AS manageer_name
FROM employees m
JOIN employees e
ON m.employee_id = e.manager_id;
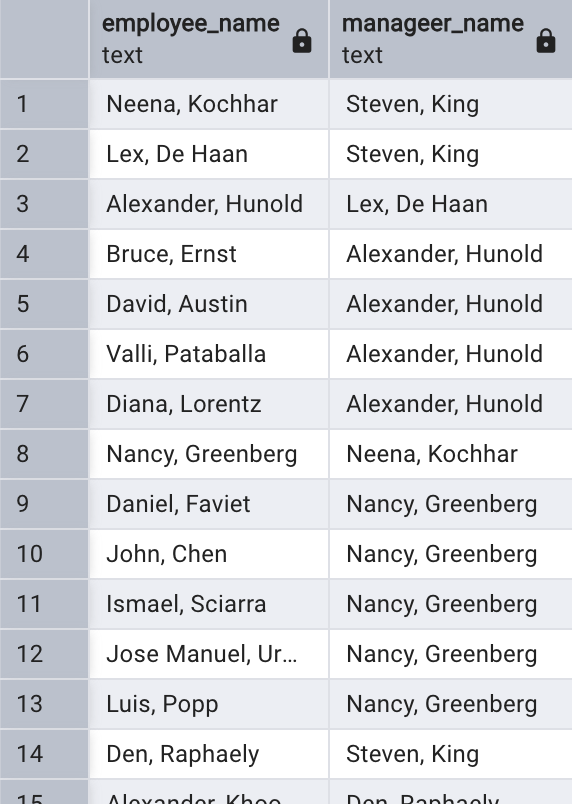
如果還需要知道員工的職位信息,比如職位名稱,可以在連接查詢中加上 jobs 表。以下是三個表連接查詢的示例:
SELECT d.department_name,e.first_name||', '||e.last_name AS employee_name,j.job_title
FROM departments d
JOIN employees e ON d.department_id = e.department_id
JOIN jobs j ON j.job_id = e.job_id;

)

















