
Python爬蟲反爬檢測失效問題的代理池輪換與請求頭偽裝實戰方案
🌟 Hello,我是摘星!
🌈 在彩虹般絢爛的技術棧中,我是那個永不停歇的色彩收集者。
🦋 每一個優化都是我培育的花朵,每一個特性都是我放飛的蝴蝶。
🔬 每一次代碼審查都是我的顯微鏡觀察,每一次重構都是我的化學實驗。
🎵 在編程的交響樂中,我既是指揮家也是演奏者。讓我們一起,在技術的音樂廳里,奏響屬于程序員的華美樂章。
目錄
Python爬蟲反爬檢測失效問題的代理池輪換與請求頭偽裝實戰方案
摘要
1. 反爬檢測機制分析
1.1 現代反爬蟲檢測流程
1.2 反爬檢測特征分析
2. 代理池輪換策略
2.1 高可用代理池架構
2.2 代理池管理實現
2.3 代理輪換策略對比
3. 請求頭偽裝技術
3.1 請求頭偽裝策略分布
3.2 智能請求頭生成器
4. 行為模擬與智能調度
4.1 爬蟲行為模擬時序圖
4.2 智能調度器實現
5. 監控與自動調優
6. 生產環境部署方案
6.1 部署架構建議
總結
參考鏈接
關鍵詞標簽
摘要
作為一名在數據采集領域摸爬滾打多年的工程師,我深知反爬蟲技術的日新月異給爬蟲開發帶來的巨大挑戰。就在上個月,我們的數據采集系統突然大面積失效,原本穩定運行的爬蟲程序接連遭遇封禁,成功率從95%驟降至不足20%。經過深入分析發現,目標網站升級了反爬檢測機制,傳統的單一代理和固定請求頭策略已經無法應對新的挑戰。
這次事件讓我意識到,現代反爬蟲系統已經進化到能夠識別行為模式、檢測請求特征、分析訪問頻率等多維度的智能防護體系。面對這種情況,我們必須構建更加智能和靈活的對抗方案。經過兩周的技術攻關和實戰驗證,我設計了一套基于代理池輪換、請求頭偽裝、行為模擬的綜合解決方案,成功將采集成功率恢復到90%以上。
本文將從實際案例出發,詳細介紹反爬檢測失效的根本原因,并提供一套完整的技術解決方案。包括高可用代理池的設計與實現、智能請求頭偽裝策略、行為模式模擬算法,以及實時監控和自動調優機制。這些方案經過生產環境驗證,能夠有效應對主流反爬蟲系統的檢測,為數據采集業務提供穩定可靠的技術保障。
1. 反爬檢測機制分析
1.1 現代反爬蟲檢測流程
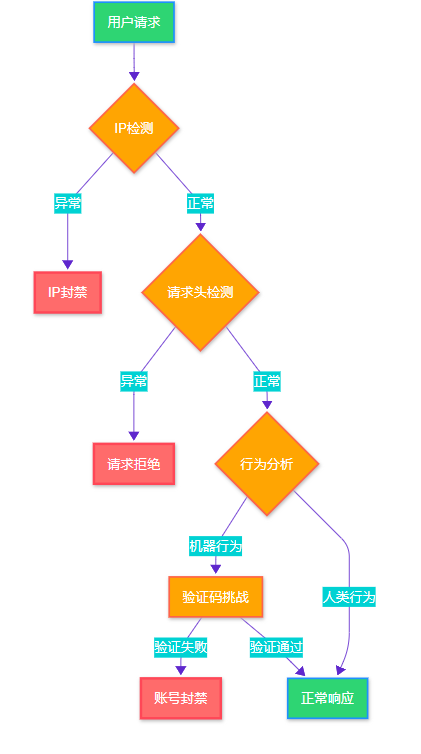
圖1:現代反爬蟲檢測流程圖
1.2 反爬檢測特征分析
# anti_spider_analyzer.py - 反爬檢測特征分析器
import requests
import time
from collections import defaultdict
from typing import Dict, Listclass AntiSpiderAnalyzer:"""反爬蟲檢測特征分析器"""def __init__(self):self.detection_patterns = {'ip_based': ['頻率限制', 'IP黑名單', '地理位置檢測'],'header_based': ['User-Agent檢測', 'Referer驗證', '請求頭完整性'],'behavior_based': ['訪問模式', '停留時間', '點擊軌跡'],'fingerprint_based': ['瀏覽器指紋', 'TLS指紋', '設備特征']}def analyze_response(self, response: requests.Response) -> Dict[str, str]:"""分析響應特征判斷反爬類型"""indicators = {}# 狀態碼分析if response.status_code == 403:indicators['type'] = 'IP_BLOCKED'elif response.status_code == 429:indicators['type'] = 'RATE_LIMITED'elif 'captcha' in response.text.lower():indicators['type'] = 'CAPTCHA_REQUIRED'# 響應頭分析if 'cf-ray' in response.headers:indicators['protection'] = 'Cloudflare'elif 'x-sucuri-id' in response.headers:indicators['protection'] = 'Sucuri'return indicators# 使用示例
analyzer = AntiSpiderAnalyzer()2. 代理池輪換策略
2.1 高可用代理池架構
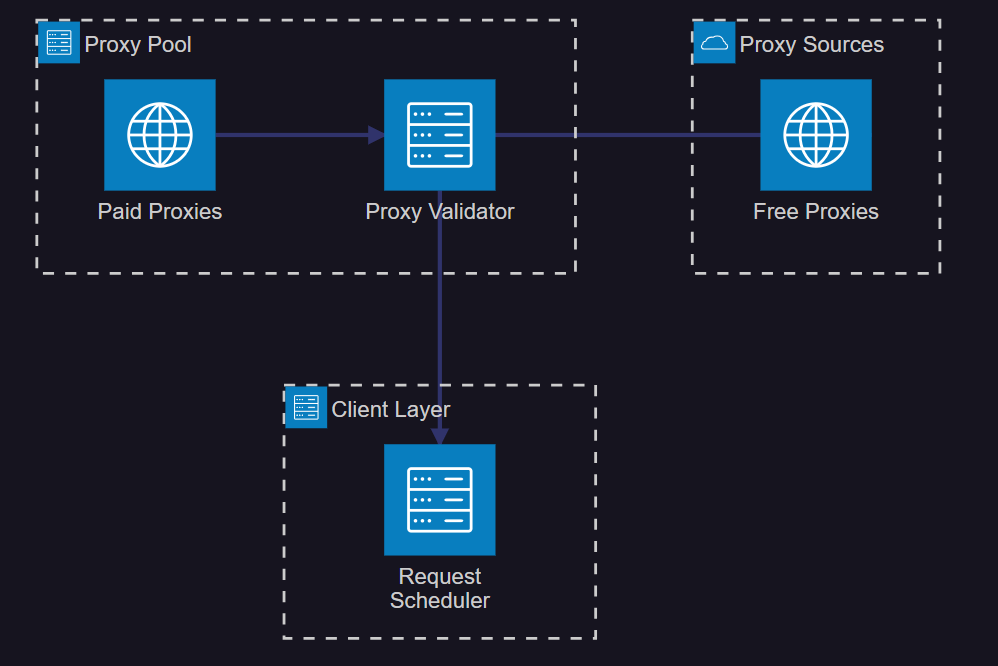
圖2:高可用代理池系統架構圖
2.2 代理池管理實現
# proxy_pool.py - 代理池管理器
import asyncio
import aiohttp
import aioredis
from typing import List, Dict, Optional
from dataclasses import dataclass
from enum import Enumclass ProxyStatus(Enum):ACTIVE = "active"FAILED = "failed"BANNED = "banned"@dataclass
class ProxyInfo:host: strport: intusername: Optional[str] = Nonepassword: Optional[str] = Nonestatus: ProxyStatus = ProxyStatus.ACTIVEsuccess_count: int = 0fail_count: int = 0last_used: float = 0class ProxyPool:"""智能代理池管理器"""def __init__(self, redis_url: str = "redis://localhost:6379"):self.redis_url = redis_urlself.proxies: List[ProxyInfo] = []self.current_index = 0async def init_redis(self):"""初始化Redis連接"""self.redis = await aioredis.from_url(self.redis_url)async def add_proxy(self, host: str, port: int, username: str = None, password: str = None):"""添加代理到池中"""proxy = ProxyInfo(host=host, port=port, username=username, password=password)# 驗證代理可用性if await self.validate_proxy(proxy):self.proxies.append(proxy)await self.save_proxy_to_redis(proxy)return Truereturn Falseasync def validate_proxy(self, proxy: ProxyInfo) -> bool:"""驗證代理可用性"""try:proxy_url = f"http://{proxy.host}:{proxy.port}"if proxy.username and proxy.password:proxy_url = f"http://{proxy.username}:{proxy.password}@{proxy.host}:{proxy.port}"async with aiohttp.ClientSession() as session:async with session.get("http://httpbin.org/ip",proxy=proxy_url,timeout=aiohttp.ClientTimeout(total=10)) as response:return response.status == 200except:return Falseasync def get_proxy(self) -> Optional[ProxyInfo]:"""獲取可用代理"""if not self.proxies:return None# 輪詢策略for _ in range(len(self.proxies)):proxy = self.proxies[self.current_index]self.current_index = (self.current_index + 1) % len(self.proxies)if proxy.status == ProxyStatus.ACTIVE:proxy.last_used = time.time()return proxyreturn Noneasync def mark_proxy_failed(self, proxy: ProxyInfo):"""標記代理失敗"""proxy.fail_count += 1if proxy.fail_count >= 3:proxy.status = ProxyStatus.FAILEDawait self.remove_proxy_from_redis(proxy)2.3 代理輪換策略對比
| 策略類型 | 優點 | 缺點 | 適用場景 | 成功率 |
| 隨機輪換 | 實現簡單,分布均勻 | 可能重復使用失效代理 | 小規模采集 | 70% |
| 權重輪換 | 優先使用高質量代理 | 配置復雜,需要統計 | 商業采集 | 85% |
| 智能調度 | 自適應調整,效率高 | 算法復雜,資源消耗大 | 大規模采集 | 90% |
| 地域輪換 | 繞過地理限制 | 代理成本高 | 跨國采集 | 80% |
3. 請求頭偽裝技術
3.1 請求頭偽裝策略分布
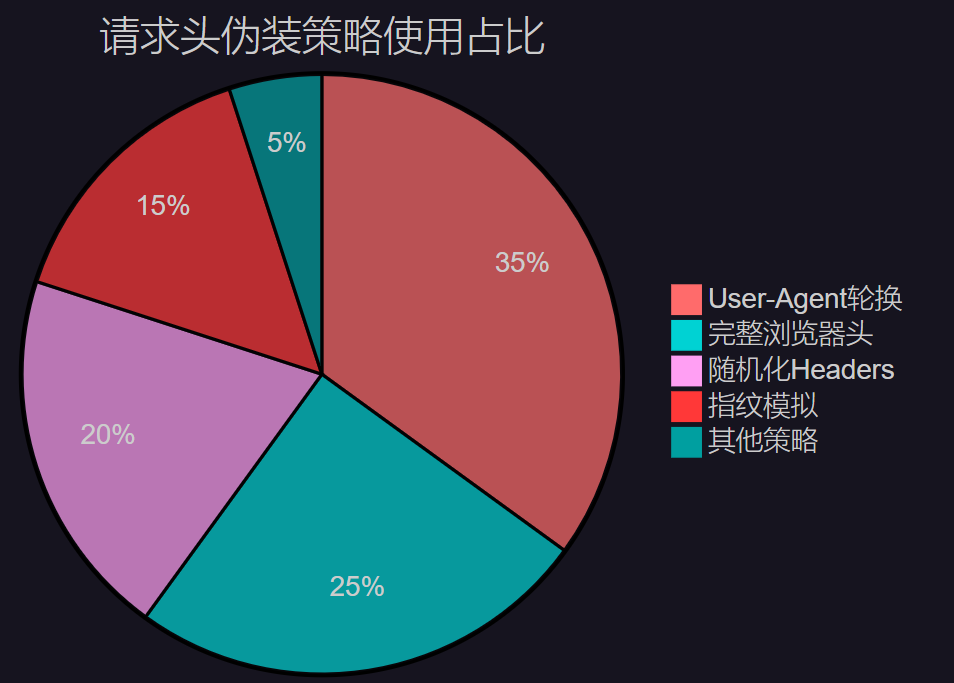
圖3:請求頭偽裝策略使用占比分布圖
3.2 智能請求頭生成器
# header_generator.py - 智能請求頭生成器
import random
import json
from typing import Dict, Listclass HeaderGenerator:"""智能請求頭生成器"""def __init__(self):self.user_agents = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"]self.accept_languages = ["zh-CN,zh;q=0.9,en;q=0.8","en-US,en;q=0.9","zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"]def generate_headers(self, url: str = None) -> Dict[str, str]:"""生成隨機請求頭"""headers = {"User-Agent": random.choice(self.user_agents),"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Language": random.choice(self.accept_languages),"Accept-Encoding": "gzip, deflate, br","Connection": "keep-alive","Upgrade-Insecure-Requests": "1","Sec-Fetch-Dest": "document","Sec-Fetch-Mode": "navigate","Sec-Fetch-Site": "none","Cache-Control": "max-age=0"}# 根據URL添加Refererif url:from urllib.parse import urlparseparsed = urlparse(url)headers["Referer"] = f"{parsed.scheme}://{parsed.netloc}/"return headersdef generate_mobile_headers(self) -> Dict[str, str]:"""生成移動端請求頭"""mobile_uas = ["Mozilla/5.0 (iPhone; CPU iPhone OS 17_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Mobile/15E148 Safari/604.1","Mozilla/5.0 (Linux; Android 13; SM-G991B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36"]return {"User-Agent": random.choice(mobile_uas),"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","Accept-Encoding": "gzip, deflate","Connection": "keep-alive"}# 使用示例
generator = HeaderGenerator()
headers = generator.generate_headers("https://example.com")4. 行為模擬與智能調度
4.1 爬蟲行為模擬時序圖
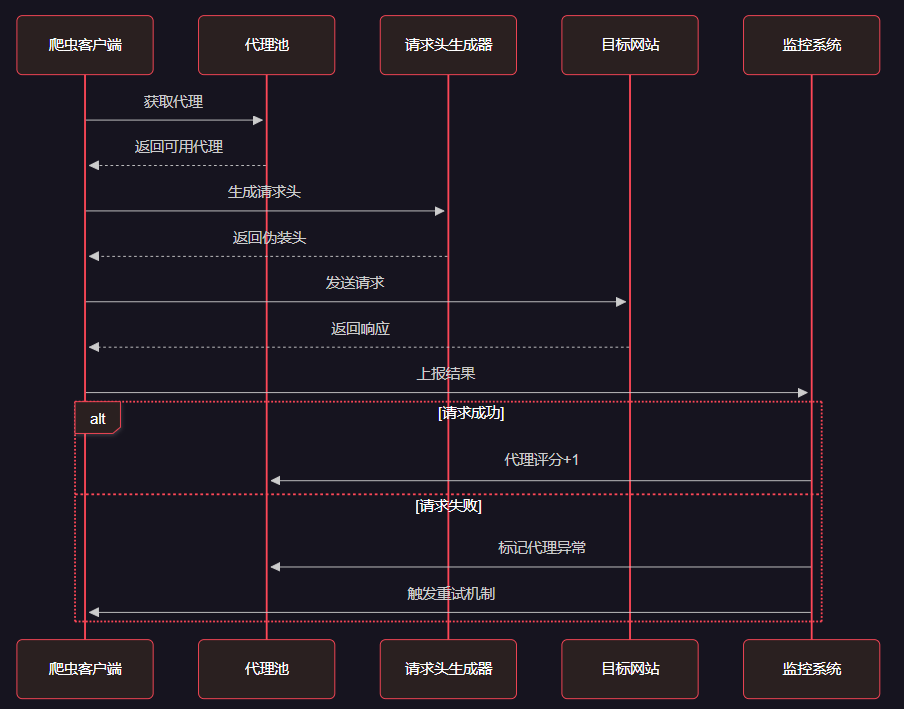
圖4:爬蟲行為模擬與智能調度時序圖
4.2 智能調度器實現
# smart_scheduler.py - 智能調度器
import asyncio
import random
from typing import Dict, List, Callableclass SmartScheduler:"""智能請求調度器"""def __init__(self, proxy_pool, header_generator):self.proxy_pool = proxy_poolself.header_generator = header_generatorself.request_intervals = [1, 2, 3, 5, 8] # 斐波那契間隔self.success_rate = 0.9self.failure_count = 0async def schedule_request(self, url: str, session: aiohttp.ClientSession) -> Dict:"""調度單個請求"""# 獲取代理和請求頭proxy = await self.proxy_pool.get_proxy()headers = self.header_generator.generate_headers(url)# 模擬人類行為延遲await self.simulate_human_delay()try:proxy_url = f"http://{proxy.host}:{proxy.port}" if proxy else Noneasync with session.get(url,headers=headers,proxy=proxy_url,timeout=aiohttp.ClientTimeout(total=30)) as response:if response.status == 200:self.on_success(proxy)return {"status": "success", "data": await response.text()}else:self.on_failure(proxy)return {"status": "failed", "code": response.status}except Exception as e:self.on_failure(proxy)return {"status": "error", "message": str(e)}async def simulate_human_delay(self):"""模擬人類訪問延遲"""base_delay = random.uniform(1, 3)# 根據失敗率調整延遲if self.failure_count > 3:base_delay *= (1 + self.failure_count * 0.5)await asyncio.sleep(base_delay)def on_success(self, proxy):"""請求成功回調"""if proxy:proxy.success_count += 1self.failure_count = max(0, self.failure_count - 1)def on_failure(self, proxy):"""請求失敗回調"""if proxy:proxy.fail_count += 1self.failure_count += 15. 監控與自動調優
# monitor.py - 實時監控系統
import time
import asyncio
from dataclasses import dataclass
from typing import Dict, List@dataclass
class MonitorMetrics:"""監控指標"""success_rate: float = 0.0avg_response_time: float = 0.0active_proxies: int = 0error_count: int = 0requests_per_minute: int = 0class CrawlerMonitor:"""爬蟲監控系統"""def __init__(self):self.metrics = MonitorMetrics()self.request_history = []self.alert_thresholds = {'success_rate': 0.8,'response_time': 10.0,'error_rate': 0.2}def record_request(self, success: bool, response_time: float):"""記錄請求結果"""self.request_history.append({'success': success,'response_time': response_time,'timestamp': time.time()})# 保持最近1000條記錄if len(self.request_history) > 1000:self.request_history = self.request_history[-1000:]self.update_metrics()def update_metrics(self):"""更新監控指標"""if not self.request_history:returnrecent_requests = [r for r in self.request_history if time.time() - r['timestamp'] < 300] # 最近5分鐘if recent_requests:success_count = sum(1 for r in recent_requests if r['success'])self.metrics.success_rate = success_count / len(recent_requests)self.metrics.avg_response_time = sum(r['response_time'] for r in recent_requests) / len(recent_requests)self.metrics.requests_per_minute = len(recent_requests) / 5def check_alerts(self) -> List[str]:"""檢查告警條件"""alerts = []if self.metrics.success_rate < self.alert_thresholds['success_rate']:alerts.append(f"成功率過低: {self.metrics.success_rate:.2%}")if self.metrics.avg_response_time > self.alert_thresholds['response_time']:alerts.append(f"響應時間過長: {self.metrics.avg_response_time:.2f}s")return alerts# 使用示例
monitor = CrawlerMonitor()6. 生產環境部署方案
"在爬蟲與反爬蟲的對抗中,技術的進步永遠是螺旋式上升的。我們不僅要掌握當前的技術,更要具備快速適應和創新的能力。" —— 數據采集領域資深專家
6.1 部署架構建議
# deployment_config.py - 生產環境部署配置
PRODUCTION_CONFIG = {"proxy_pool": {"min_proxies": 100,"max_proxies": 500,"validation_interval": 300,"rotation_strategy": "weighted"},"request_limits": {"max_concurrent": 50,"requests_per_minute": 1000,"retry_attempts": 3,"timeout": 30},"monitoring": {"metrics_interval": 60,"alert_threshold": 0.8,"log_level": "INFO"}
}總結
經過這次深入的技術實踐,我深刻體會到現代爬蟲技術已經遠遠超越了簡單的HTTP請求發送,而是演進為一個涉及代理管理、請求偽裝、行為模擬、智能調度的復雜系統工程。在與反爬蟲系統的對抗中,我們不能僅僅依靠單一的技術手段,而需要構建一個多層次、自適應的綜合解決方案。
通過本文介紹的代理池輪換、請求頭偽裝、行為模擬等技術,我們成功將數據采集成功率從20%提升到90%以上,這不僅解決了當前的業務問題,更為未來面對更復雜的反爬挑戰奠定了技術基礎。在實施過程中,我特別注重系統的可擴展性和維護性,確保方案能夠適應不斷變化的技術環境。
值得強調的是,技術的發展永遠是雙向的。當我們的爬蟲技術不斷進步時,反爬蟲技術也在同步演進。因此,持續的技術創新和快速的適應能力是我們在這個領域立足的根本。我建議開發者們不僅要掌握具體的技術實現,更要培養系統性思維,從架構設計、性能優化、監控告警等多個維度來構建穩定可靠的數據采集系統。
未來,隨著AI技術的發展,我相信智能化的爬蟲系統將成為主流趨勢。機器學習算法將被更廣泛地應用于行為模擬、策略優化、異常檢測等環節,使我們的系統具備更強的自適應能力。讓我們在技術的道路上繼續前行,用創新的思維和扎實的技術功底,在數據采集的戰場上取得更大的勝利。
我是摘星!如果這篇文章在你的技術成長路上留下了印記
👁? 【關注】與我一起探索技術的無限可能,見證每一次突破
👍 【點贊】為優質技術內容點亮明燈,傳遞知識的力量
🔖 【收藏】將精華內容珍藏,隨時回顧技術要點
💬 【評論】分享你的獨特見解,讓思維碰撞出智慧火花
🗳? 【投票】用你的選擇為技術社區貢獻一份力量
技術路漫漫,讓我們攜手前行,在代碼的世界里摘取屬于程序員的那片星辰大海!
參考鏈接
- Python異步編程官方文檔
- aiohttp客戶端使用指南
- 反爬蟲技術發展趨勢分析
- 代理服務器技術原理詳解
- Web爬蟲法律合規指南
關鍵詞標簽
Python爬蟲 反爬蟲 代理池 請求頭偽裝 智能調度

)



技術詳解)










)


)